Hai Kami memiliki 15.260+ objek dan 38.000 perangkat jaringan yang perlu dikonfigurasi, diperbarui, dan diverifikasi agar operasional. Memelihara armada peralatan semacam itu cukup sulit dan membutuhkan banyak waktu, tenaga, dan manusia. Oleh karena itu, kami perlu mengotomatiskan pekerjaan dengan peralatan jaringan dan kami memutuskan untuk mengadaptasi konsep Jaringan sebagai Kode untuk mengelola jaringan di perusahaan kami. Di bawah potongan, bacalah riwayat otomatisasi kami, kesalahan yang dibuat dan rencana lebih lanjut untuk membangun sistem.
Singkat cerita, kami ingin mengotomatiskan jaringan
Hai Nama saya Alexander Prokhorov, dan bersama-sama dengan tim insinyur jaringan di departemen kami, kami
mengerjakan jaringan di
#IT X5 . Departemen kami mengembangkan infrastruktur jaringan, pemantauan, otomatisasi jaringan, dan arah Jaringan yang trendi sebagai Kode.
Awalnya, saya tidak benar-benar percaya pada otomatisasi pada jaringan kami pada prinsipnya. Ada banyak kesalahan warisan dan konfigurasi - tidak di mana-mana ada otorisasi pusat, tidak semua perangkat keras mendukung SSH, tidak di mana-mana
SNMP dikonfigurasi. Semua ini sangat merusak kepercayaan pada otomatisasi. Karena itu, pertama-tama, kami mengatur apa yang diperlukan untuk memulai otomatisasi, yaitu: standardisasi koneksi SSH, otorisasi tunggal (
AAA ) dan profil SNMP. Semua fondasi ini memungkinkan Anda untuk menulis alat untuk pengiriman massal konfigurasi ke perangkat, tetapi muncul pertanyaan: bisakah saya mendapatkan lebih banyak? Jadi kami sampai pada kebutuhan untuk menyusun rencana pengembangan otomatisasi dan konsep Jaringan sebagai Kode, khususnya.
Konsep Jaringan sebagai Kode, menurut Cisco, berarti prinsip-prinsip berikut:
- Menyimpan konfigurasi target dalam repositori, Kontrol Sumber
- Perubahan konfigurasi melalui repositori, Single Source of Truth
- Menanamkan konfigurasi melalui API

Dua poin pertama memungkinkan Anda untuk menerapkan pendekatan DevOps atau NetDevOps untuk mengelola infrastruktur jaringan Anda. Dengan paragraf ketiga ada kesulitan, misalnya, apa yang harus dilakukan jika tidak ada API? Tentu saja, SSH dan CLI, kami adalah penggiat jejaring!
Dan apakah itu yang kita butuhkan?Penerapan prinsip-prinsip ini saja tidak menyelesaikan semua masalah infrastruktur jaringan, seperti halnya penerapannya membutuhkan fondasi tertentu dengan data jaringan.
Pertanyaan yang muncul ketika kami memikirkan hal ini:
- OK, saya menyimpan konfigurasi sebagai kode, bagaimana saya harus menerapkannya pada objek tertentu?
- Oke, saya memiliki template konfigurasi di repositori, tetapi bagaimana saya bisa secara otomatis mengkonfigurasi konfigurasi untuk objek yang didasarkan padanya?
- Bagaimana cara mengetahui model dan vendor mana yang harus ada pada objek ini? Bisakah saya melakukannya secara otomatis?
- Bagaimana saya bisa mengecek apakah pengaturan objek saat ini cocok dengan parameter dalam repositori?
- Bagaimana cara bekerja dengan perubahan dalam repositori dan mereplikasi mereka di jaringan yang produktif?
- Perangkat data dan sistem apa yang perlu saya pikirkan tentang Penyediaan Zero Touch?
- Bagaimana dengan perbedaan dalam vendor, dan bahkan model dari vendor yang sama?
- Bagaimana cara menyimpan subnet untuk konfigurasi otomatis?
Berdasarkan semua pertanyaan di atas, menjadi jelas bahwa kita membutuhkan seperangkat sistem yang menyelesaikan berbagai masalah, bekerja bersama satu sama lain dan memberi kita informasi lengkap tentang infrastruktur jaringan.

Selain mencoba menerapkan pendekatan baru pada manajemen jaringan, kami ingin menyelesaikan beberapa masalah yang lebih akut dalam infrastruktur jaringan, seperti integritas data, pembaruan, dan, tentu saja, otomatisasi. Maksud kami bukan hanya pengiriman massal konfigurasi ke peralatan, tetapi juga konfigurasi otomatis, pengumpulan otomatis data inventaris peralatan jaringan, integrasi dengan sistem pemantauan. Tetapi hal pertama yang pertama.
Fungsi yang kami tuju adalah:
- Basis data peralatan jaringan (+ penemuan, + pembaruan otomatis)
- Alamat jaringan dasar (pemeriksaan validasi IPAM +)
- Integrasi sistem pemantauan dengan data inventaris
- Penyimpanan standar konfigurasi dalam sistem kontrol versi
- Pembentukan konfigurasi target secara otomatis untuk suatu objek
- Pengiriman massal konfigurasi ke peralatan jaringan
- Menerapkan proses CI / CD untuk mengelola perubahan konfigurasi jaringan
- Menguji konfigurasi jaringan dengan CI / CD
- ZTP (Zero Touch Provisioning) - pengaturan otomatis peralatan untuk suatu objek
Ceritanya panjang, kami mencoba otomatisasiKami mulai mencoba mengotomatiskan pekerjaan pengaturan jaringan 2 tahun yang lalu. Mengapa sekarang pertanyaan ini muncul lagi dan perlu perhatian?
Sangat membosankan dan membosankan untuk mengkonfigurasi lebih dari beberapa lusin perangkat dengan tangan Anda. Terkadang tangan sang insinyur berkedut, dan ia melakukan kesalahan. Untuk beberapa lusin, skrip yang ditulis oleh satu insinyur biasanya cukup, yang menggulung pengaturan yang diperbarui ke peralatan jaringan.
Kenapa tidak berhenti di situ saja? Faktanya, banyak insinyur jaringan sudah tahu bagaimana melakukan semua jenis ular sanca, dan mereka yang tidak tahu bagaimana akan dapat melakukannya segera (Natalya Samoilenko, bagaimanapun, telah menerbitkan
karya yang luar biasa tentang Python , terutama untuk penggiat jejaring). Siapa pun yang bertugas mengkonfigurasi n + 1 router dapat menulis skrip dan menjalankan pengaturan dengan sangat cepat. Jauh lebih cepat dari itu mampu mengembalikan semuanya. Menurut pengalaman otomatisasi "setiap orang untuk dirinya sendiri", kesalahan terjadi ketika Anda dapat memulihkan komunikasi hanya dengan tangan Anda, dan hanya dengan penderitaan besar dari seluruh tim.

Contoh
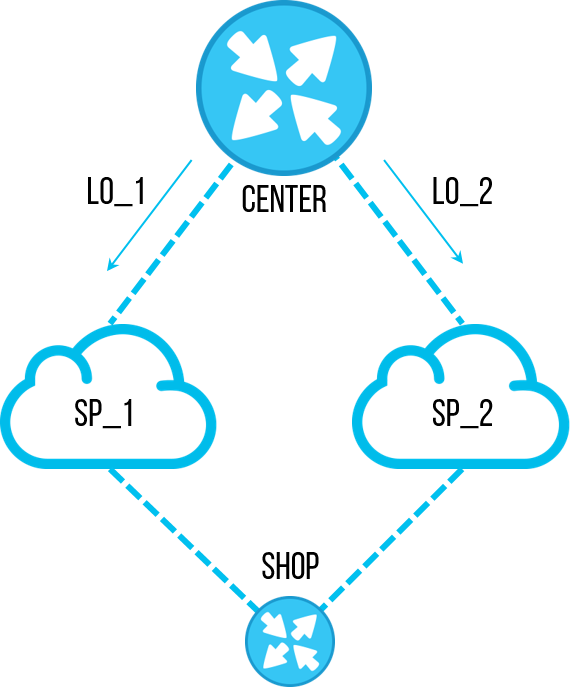
Suatu ketika, salah satu insinyur memutuskan untuk melakukan tugas penting - untuk memulihkan ketertiban dalam konfigurasi router. Sebagai hasil audit pada beberapa objek,
daftar awalan usang dengan subnet spesifik ditemukan, yang tidak lagi kami perlukan. Sebelumnya, ini digunakan untuk memfilter alamat
loopback dari situs pusat sehingga hanya melalui satu saluran, dan kami dapat menguji koneksi pada saluran ini. Tetapi mekanismenya dioptimalkan, dan mereka berhenti menggunakan skema pengujian saluran semacam itu. Karyawan memutuskan untuk menghapus
daftar awalan ini sehingga tidak muncul dalam konfigurasi dan menyebabkan kebingungan di masa depan. Semua orang setuju untuk menghapus daftar
awalan yang tidak digunakan, tugasnya sederhana, mereka langsung lupa. Tetapi menghapus daftar
awalan yang sama dengan tangan Anda pada lusinan objek cukup membosankan dan memakan waktu. Dan insinyur itu menulis sebuah skrip yang akan dengan cepat melewati peralatan, membuat
"no prefix-list pl-cisco-primer" dan dengan sungguh-sungguh menyimpan konfigurasi.
Beberapa waktu setelah diskusi, beberapa jam, atau sehari, saya tidak ingat, satu benda jatuh. Setelah beberapa menit, yang lain, serupa. Jumlah objek yang tidak dapat diakses terus bertambah, dalam setengah jam menjadi 10, dan setiap 2-3 menit satu yang baru ditambahkan. Semua insinyur terhubung untuk diagnosis. 40-50 menit setelah dimulainya kecelakaan, semua orang ditanyai tentang perubahan itu, dan karyawan itu menghentikan skripnya. Saat itu, sudah ada sekitar 20 objek dengan saluran rusak. Pemulihan penuh memakan waktu 7 insinyur selama beberapa jam.
Sisi teknis
Prefix-list digunakan untuk memfilter
loopbacks - satu difilter pada satu saluran, yang kedua pada cadangan. Ini digunakan untuk menguji komunikasi tanpa mengalihkan lalu lintas produktif antara saluran. Oleh karena itu, aturan pertama dari
rute-peta yang masuk pada tetangga
BGP adalah
DENY dengan
"mencocokkan daftar awalan alamat ip" . Aturan-aturan lainnya dalam
rute-peta adalah
IZIN .
Ada beberapa nuansa yang mungkin perlu diperhatikan:
- Aturan rute-peta di mana tidak ada kecocokan - melewatkan segalanya
- Pada akhir awalan-daftar adalah implisit deny , tetapi hanya jika tidak kosong
- Daftar awalan kosong adalah izin tersirat
Semua hal di atas berlaku untuk
Cisco IOS .
Daftar awalan kosong dapat muncul saat Anda mendeklarasikan
peta rute , menjadikannya
"cocok dengan daftar awalan alamat ip pl-test-cisco" .
Daftar awalan ini tidak akan secara eksplisit dinyatakan dalam konfigurasi (selain baris dengan
kecocokan ), tetapi dapat ditemukan di
show ip prefix-list .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Kembali ke apa yang terjadi, ketika daftar
awalan dihapus oleh skrip, itu menjadi kosong, karena itu masih dalam aturan
DENY pertama di
rute-peta .
Daftar awalan kosong memungkinkan semua subnet, sehingga segala sesuatu yang diberikan oleh rekan
BGP kepada kami termasuk dalam aturan
DENY pertama.
Mengapa insinyur itu tidak segera menyadari bahwa ia telah memutuskan koneksi? Di sini memainkan peran timer
BGP di Cisco.
BGP sendiri tidak bertukar rute pada suatu jadwal, dan jika Anda memperbarui kebijakan perutean
BGP , Anda perlu mengatur ulang sesi BGP untuk menerapkan perubahan,
"hapus ip bgp <peer-ip>" ke Cisco.
Agar tidak mengatur ulang sesi, ada dua mekanisme:
- Cisco Soft-Reconfiguration
- Rute Refresh sebagai RFC2918
Soft-konfigurasi ulang menyimpan informasi yang diterima di
UPDATE dari tetangga tentang rute sampai kebijakan diterapkan
dalam tabel
adj-RIB-in lokal . Saat memperbarui kebijakan, dimungkinkan untuk meniru
UPDATE dari tetangga.
Route Refresh adalah "kemampuan" rekan kerja untuk mengirim
UPDATE berdasarkan permintaan. Ketersediaan kesempatan ini disepakati saat membangun lingkungan. Pro - Tidak perlu menyimpan salinan
UPDATE secara lokal. Kontra - dalam praktek, setelah permintaan
PEMBARUAN dari tetangga, Anda perlu menunggu sampai dia mengirimkannya. Omong-omong, Anda dapat menonaktifkan fitur di Cisco dengan perintah tersembunyi:
neighbor <peer-ip> dont-capability-negotiate
Ada fitur Cisco yang tidak berdokumen - pengatur waktu 30 detik, yang dipicu oleh perubahan kebijakan
BGP . Setelah mengubah kebijakan, dalam 30 detik proses memperbarui rute menggunakan salah satu teknologi di atas akan dimulai. Saya tidak dapat menemukan deskripsi yang terdokumentasi tentang timer ini, tetapi ada disebutkan di
BUG CSCvi91270 . Anda dapat mempelajari ketersediaannya dalam praktik,

setelah melakukan perubahan di lab dan mencari
debug untuk permintaan
UPDATE ke tetangga atau
proses konfigurasi ulang lunak . (Jika ada informasi tambahan tentang topik - Anda dapat meninggalkan komentar)
Untuk
Soft-Reconfiguration , timer berfungsi seperti ini:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
Untuk
Route-Refresh dari sisi tetangga seperti ini:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Jika
Route-Refresh tidak didukung oleh salah satu rekan dan
konfigurasi ulang inbound tidak diaktifkan, maka memperbarui rute dengan kebijakan baru tidak akan secara otomatis terjadi.
Jadi,
daftar awalan dihapus, koneksi tetap, setelah 30 detik menghilang. Script berhasil mengubah konfigurasi, memeriksa koneksi, dan menyimpan konfigurasi. Jatuhnya naskah tidak langsung terhubung, dengan latar belakang sejumlah besar objek.
Semua ini dapat dengan mudah dihindari dengan pengujian, replikasi parsial pengaturan.Ada pemahaman bahwa otomatisasi harus dipusatkan dan dikendalikan.

Sistem yang kami butuhkan dan koneksi mereka
Kesimpulan singkat dari spoiler - lebih baik untuk mensistematisasikan dan mengontrol proses pengiriman massal konfigurasi agar tidak sampai pada pengiriman massal kesalahan dalam konfigurasi.
- DevOps: 50ms 4 - : ", !@#$%"
Skema yang kami datangi terdiri dari blok data master "bisnis", blok data master "jaringan", sistem pemantauan infrastruktur jaringan, sistem pengiriman konfigurasi, sistem kontrol versi dengan unit pengujian.
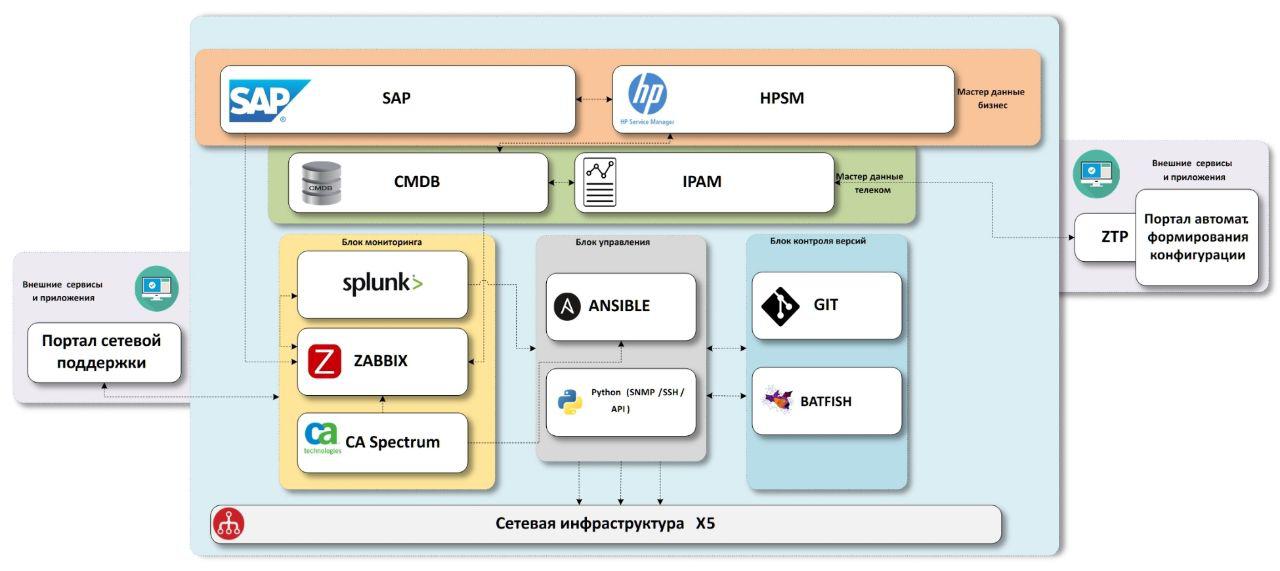
Yang kita butuhkan hanyalah Data
Pertama kita perlu tahu benda apa yang ada di perusahaan.
SAP - sistem perusahaan
ERP . Data tentang hampir semua fasilitas ada di sana, dan lebih tepatnya di semua toko dan pusat distribusi. Serta ada data tentang peralatan yang melewati gudang TI dengan nomor inventaris, yang juga akan berguna bagi kita di masa depan. Hanya kantor yang hilang, mereka tidak memulai dalam sistem. Kami mencoba menyelesaikan masalah ini dalam proses terpisah, mulai dari saat pembukaan, kami memerlukan koneksi pada setiap objek, dan kami memilih pengaturan untuk komunikasi, jadi di suatu tempat pada saat ini kami perlu membuat data master. Tetapi kekurangan data adalah topik yang terpisah, lebih baik untuk menempatkan deskripsi ini di artikel terpisah jika ada minat dalam hal ini.
HPSM - sistem yang berisi
CMDB umum untuk TI, manajemen kejadian, manajemen perubahan. Karena sistem ini umum untuk semua TI, ia harus memiliki semua peralatan TI, termasuk peralatan jaringan. Ini adalah tempat di mana kami akan menambahkan semua data akhir melalui jaringan. Dengan manajemen insiden dan perubahan, kami berencana untuk berinteraksi dari sistem pemantauan di masa depan.
Kami tahu benda apa yang kami miliki, memperkaya mereka dengan data melalui jaringan. Untuk tujuan ini, kami memiliki dua sistem -
IPAM dari
SolarWinds dan sistem CMDB.noc kami sendiri.
IPAM adalah repositori dari subnet IP, data yang paling benar dan benar tentang kepemilikan alamat IP di perusahaan harus ada di sini.
CMDB.noc adalah database dengan antarmuka WEB tempat data statis pada peralatan jaringan disimpan - router, switch, titik akses, serta penyedia dan karakteristiknya. Di bawah statis berarti bahwa perubahan mereka dilakukan hanya dengan partisipasi manusia. Dengan kata lain, autodiscovering tidak membuat perubahan pada database ini, kita perlu memahami apa yang "harus" diinstal pada objek. Basisnya diperlukan sebagai penyangga antara sistem produktif yang bekerja dengan seluruh perusahaan dan alat jaringan internal. Mempercepat pengembangan, menambahkan bidang yang diperlukan, hubungan baru, menyesuaikan parameter, dll. Plus, solusi ini tidak hanya dalam kecepatan pengembangan, tetapi juga di hadapan hubungan-hubungan antara data yang kita butuhkan, tanpa kompromi. Sebagai contoh kecil, kami menggunakan beberapa
exid dalam database untuk komunikasi antara IPAM, SAP dan HPSM.
Sebagai hasilnya, kami menerima data lengkap tentang semua objek, dengan peralatan jaringan yang terlampir dan alamat IP. Sekarang kita memerlukan templat konfigurasi, atau layanan jaringan yang kami sediakan di situs-situs ini.

Sumber kebenaran tunggal
Di sini, kami baru saja mencapai penerapan prinsip NaaC pertama - menyimpan konfigurasi target dalam repositori. Dalam kasus kami, ini adalah Gitlab. Pilihan bagi kami sederhana:
- Pertama, kami sudah memiliki alat ini di perusahaan kami, kami tidak perlu menggunakannya dari awal
- Kedua, sangat cocok untuk semua tugas kita saat ini dan masa depan pada infrastruktur jaringan
Bagian utama yang menarik dari otomatisasi akan terjadi di Gitlab - proses mengubah standar konfigurasi atau, lebih sederhana, template.
Contoh Proses Perubahan Standar
Salah satu jenis objek yang kita miliki adalah toko Pyaterochka. Di sana, topologi tipikal terdiri dari satu router dan satu / dua sakelar. File konfigurasi template disimpan di Gitlab, di bagian ini semuanya sederhana. Tapi ini bukan NaaC.
Sekarang katakanlah proyek baru datang kepada kita. Tugas untuk proyek TI baru adalah membuat pilot di sejumlah toko tertentu. Menurut hasil uji coba - jika berhasil, buat replikasi untuk semua objek jenis ini; jika tidak runtuh pilot tanpa melakukan replikasi.
Proses ini sangat cocok dengan logika Git:
- Untuk proyek baru, kami membuat Cabang, tempat kami membuat perubahan pada konfigurasi.
- Di Cabang kami juga menyimpan daftar objek di mana proyek ini sedang diujicobakan
- Jika berhasil, kami membuat permintaan gabungan di cabang master, yang perlu direplikasi ke jaringan prod
- Jika gagal, tinggalkan Cabang untuk riwayat, atau cukup hapus

Dalam perkiraan pertama - bahkan tanpa otomatisasi, ini adalah alat yang sangat nyaman untuk bekerja bersama dalam konfigurasi jaringan. Terutama jika Anda membayangkan bahwa tiga proyek atau lebih muncul bersamaan. Ketika tiba saatnya untuk rilis proyek di prod, Anda harus menyelesaikan semua konflik konfigurasi dalam permintaan gabungan dan memeriksa bahwa perubahan pengaturan tidak saling eksklusif. Dan ini sangat mudah dilakukan di git.
Plus, pendekatan ini menambahkan kita fleksibilitas untuk menggunakan alat Gitlab CI / CD untuk menguji konfigurasi secara virtual, untuk mengotomatiskan pengiriman konfigurasi ke bangku tes atau sekelompok objek pilot. // Dan bahkan jika kau mau.
Menyebarkan konfigurasi ke lingkungan apa pun
Awalnya, tujuan utamanya adalah pengiriman konfigurasi secara massal, sebagai alat yang sangat jelas memungkinkan Anda menghemat waktu para insinyur dan mempercepat pelaksanaan tugas-tugas konfigurasi. Untuk melakukan ini, bahkan sebelum dimulainya kegiatan besar "Jaringan sebagai Kode", kami menulis solusi
python untuk menghubungkan ke peralatan baik untuk mengumpulkan konfigurasi peralatan atau mengkonfigurasinya. Ini
netmiko , ini
pysnmp , ini
jinja2 , dll.
Tapi sekarang saatnya bagi kita untuk membagi konfigurasi massal menjadi beberapa subspesies:
Pengiriman konfigurasi untuk menguji dan menguji coba zonaItem ini didasarkan pada Gitlab CI, yang memungkinkan Anda mengaktifkan pengiriman konfigurasi ke pilot dan zona uji di dalam pipa.
Duplikasi konfigurasi di prod- Item terpisah, paling sering replikasi ke perangkat 38k berlangsung dalam beberapa gelombang - meningkatkan volume - untuk memantau situasi di prod. Plus, pekerjaan sebesar ini membutuhkan koordinasi pekerjaan, oleh karena itu lebih baik memulai proses ini dengan tangan. Untuk ini, lebih mudah menggunakan Ansible + -AWX dan mempercepat kompilasi dinamis inventaris dari sistem data master kami ke sana.
- Sebagai tambahan, ini adalah solusi yang mudah ketika Anda perlu memberi baris kedua peluncuran playbook yang telah dikonfigurasi sebelumnya yang melakukan operasi yang kompleks dan penting, seperti mengalihkan lalu lintas antar situs.
Pengumpulan data- Autodiscover perangkat jaringan
- Konfigurasi cadangan
- Periksa konektivitas
Kami mengalokasikan tugas ini di blok yang terpisah, karena ada kalanya seseorang tiba-tiba membongkar sakelar atau memasang perangkat baru, tetapi kami tidak mengetahui hal ini sebelumnya. Dengan demikian, perangkat ini tidak akan berada dalam data master kami dan akan keluar dari proses pengiriman konfigurasi, pemantauan, dan, secara umum, pekerjaan operasional. Kebetulan bahwa peralatan itu diinstal secara sah, tetapi konfigurasi "dituangkan" salah di sana dan, untuk beberapa alasan,
ssh ,
snmp ,
aaa atau kata sandi non-standar untuk akses tidak berfungsi di sana. Untuk melakukan ini, kita memiliki python untuk mencoba semua metode koneksi
warisan yang mungkin kita miliki di perusahaan, membuat brute-force untuk semua kata sandi lama, dan semua untuk mendapatkan potongan besi dan mempersiapkannya untuk bekerja dengan
memungkinkan dan memantau .
Ada cara sederhana - untuk membuat beberapa file
inventaris untuk memungkinkan, di mana untuk menggambarkan semua data yang mungkin untuk koneksi (semua jenis vendor dengan semua pasangan nama pengguna / kata sandi yang mungkin) dan menjalankan
buku pedoman untuk setiap varian
inventaris . Kami berharap untuk solusi yang lebih baik, tetapi pada konferensi RedHat, arsitek Ansible menyarankan dengan cara yang sama. Secara umum diasumsikan bahwa Anda tahu sebelumnya apa yang Anda hubungkan.
Kami menginginkan solusi universal - ketika menghapus cadangan, cari peralatan baru dan, jika ditemukan, tambahkan ke semua sistem yang diperlukan. Oleh karena itu, kami memilih solusi dengan python - tahu apa yang bisa lebih indah daripada program yang dengan sendirinya dapat mendeteksi perangkat jaringan untuk menghubungkannya, terlepas dari apa yang dikonfigurasi di dalamnya (tentu saja, dalam batas yang wajar), konfigurasikan sesuai kebutuhan, hapus konfigurasi dan, pada saat yang sama, Tambahkan data API ke sistem yang diperlukan.
Verifikasi seperti Pemantauan
Salah satu tugas otomatisasi, tentu saja, untuk mengetahui apa yang jatuh dari otomatisasi ini. Tidak semua 38k dikonfigurasikan dengan sempurna pertama kali, bahkan ada yang mengatur peralatan dengan tangan mereka. Dan perlu untuk melacak perubahan ini dan mengembalikan
keadilan ke konfigurasi target.
Ada tiga pendekatan untuk memverifikasi kepatuhan konfigurasi dengan standar:
- Lakukan pemeriksaan sekali periode - bongkar keadaan saat ini, periksa terhadap target dan koreksi kekurangan yang diidentifikasi.
- Tanpa memeriksa apa pun, satu kali periode - roll out konfigurasi target. Benar, ada risiko melanggar sesuatu - mungkin tidak ada semuanya dalam konfigurasi target.
- Pendekatan yang mudah digunakan adalah ketika perbedaan dari konfigurasi target di Single Source of Truth dianggap sebagai peringatan dan dipantau oleh sistem pemantauan. Ini termasuk: ketidakcocokan dengan standar konfigurasi saat ini, perbedaan antara perangkat keras dan yang ditentukan dalam data master, ketidakcocokan dengan data dalam IPAM .
Dalam kasus ketiga, sebuah opsi muncul untuk mentransfer karya ini ke manajemen insiden (OS), sehingga ketidakkonsistenan dihilangkan dalam porsi kecil sepanjang waktu daripada sekali oleh darurat.
Zabbix , yang saya tulis sebelumnya dalam artikel
"Bagaimana kami memonitor 14.000 objek", adalah sistem pemantauan objek terdistribusi kami di mana kami dapat membuat pemicu dan peringatan yang dapat kami pikirkan. Sejak menulis artikel terakhir, kami telah meningkatkan ke Zabbix 4.0
LTS .
Berdasarkan
Web Zabbix, kami membuat pembaruan ke portal dukungan jaringan kami, di mana sekarang Anda dapat menemukan semua informasi tentang suatu objek dari semua sistem kami pada satu layar, serta menjalankan skrip untuk memeriksa masalah yang sering terjadi.
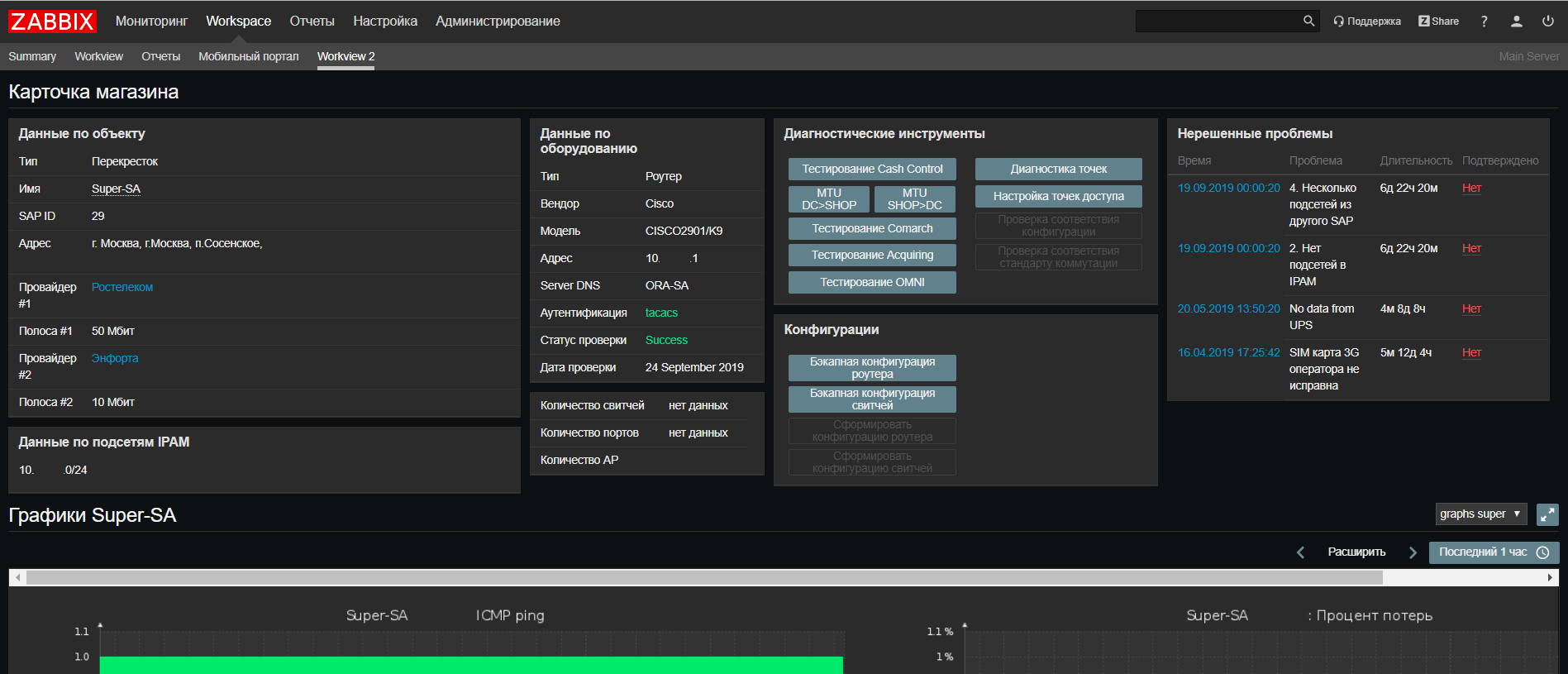
Kami juga memperkenalkan fitur baru - bagi kami, Zabbix telah menjadi, dalam beberapa cara,
CRON untuk meluncurkan skrip terjadwal, seperti skrip integrasi sistem, skrip autodiscover. Ini sangat nyaman ketika Anda perlu melihat skrip saat ini dan kapan dan di mana mereka berjalan tanpa memeriksa semua server. Benar, untuk skrip yang berjalan lebih dari 30 detik, Anda akan memerlukan
peluncur yang meluncurkannya tanpa menunggu akhir. Untungnya, ini sederhana:
 Splunk
Splunk adalah solusi yang memungkinkan Anda untuk mengumpulkan log peristiwa dari peralatan jaringan, dan ini juga dapat digunakan untuk memantau otomatisasi. Misalnya, mengumpulkan cadangan konfigurasi, skrip
python menghasilkan pesan
LOG CFG-5-BACKUP , router atau switch mengirim pesan ke Splunk, di mana kami menghitung jumlah pesan jenis ini dari peralatan jaringan. Ini memungkinkan kami untuk melacak jumlah peralatan yang terdeteksi oleh skrip. Dan kami melihat berapa banyak potongan besi yang dapat melaporkan ini ke
Splunk dan memverifikasi bahwa pesan dari semua potongan besi tiba.
Spectrum adalah sistem komprehensif yang kami gunakan untuk memantau objek kritis, alat yang agak kuat yang banyak membantu kami dalam memecahkan insiden jaringan kritis. Dalam otomatisasi, kami hanya menggunakannya untuk mengambil data darinya, itu bukan
open-source , jadi kemungkinannya agak terbatas.
Ceri di atas kue

Menggunakan sistem dengan data master pada peralatan, kita dapat berpikir tentang membuat ZTP, atau Zero Touch Provisioning. Seperti tombol "setel otomatis", tetapi hanya tanpa tombol.
Kami memiliki semua data yang diperlukan dari blok sebelumnya - kami tahu objek, jenisnya, peralatan apa yang ada (vendor dan model), apa alamatnya (IPAM), apa standar konfigurasi saat ini (Git). Dengan menyatukan semuanya, kita setidaknya bisa menyiapkan templat konfigurasi untuk mengunggah ke perangkat, itu akan lebih seperti Penyediaan One Touch, tetapi terkadang lebih banyak tidak diperlukan.
True Zero Touch memerlukan cara untuk secara otomatis mengirimkan konfigurasi ke perangkat keras yang tidak dikonfigurasi. Selain itu, diinginkan terlepas dari vendor. Ada beberapa opsi kerja - server konsol, jika semua peralatan melewati gudang pusat, solusi konsol seluler, jika peralatan tiba segera. Kami sedang mengerjakan solusi ini, tetapi begitu ada opsi yang berfungsi, kami dapat membagikannya.
Kesimpulan
Secara total, dalam konsep
Jaringan kami sebagai Kode , ada 5 tonggak utama:
- Data master (komunikasi sistem dan data satu sama lain, API sistem, kecukupan data untuk dukungan dan peluncuran)
- Memantau data dan konfigurasi (menemukan perangkat jaringan secara otomatis, memeriksa relevansi konfigurasi di fasilitas)
- Konfigurasi versi, pengujian dan konfigurasi uji coba (Gitlab CI / CD sebagaimana diterapkan pada jaringan, alat pengujian konfigurasi jaringan)
- Pengiriman konfigurasi (Anonim, AWX, skrip python untuk disambungkan)
- Zero Touch Provisioning (Data apa yang dibutuhkan, bagaimana membangun proses sehingga, bagaimana menghubungkan ke perangkat keras yang tidak dikonfigurasi)
Itu tidak berhasil memasukkan semuanya ke dalam satu artikel, setiap item layak untuk diskusi terpisah, kita bisa membicarakan sesuatu sekarang, tentang sesuatu ketika kita memeriksa solusi dalam praktek. Jika Anda tertarik pada salah satu topik - pada akhirnya akan ada survei di mana Anda dapat memilih artikel berikutnya. Jika topik tidak termasuk dalam daftar, tetapi menarik untuk membacanya, tinggalkan komentar sesegera mungkin, pastikan untuk berbagi pengalaman kami.
Terima kasih khusus kepada Virilin Alexander (
xscrew ) dan Sibgatulin Marat (
eucariot ) untuk kunjungan referensi pada musim gugur tahun 2018 ke cloud Yandex dan kisah tentang otomatisasi dalam infrastruktur jaringan cloud. Setelahnya, kami mendapat inspirasi dan banyak ide tentang penggunaan otomatisasi dan NetDevOps dalam infrastruktur Grup Ritel X5.