Mereka yang bekerja dengan data sangat menyadari bahwa kebahagiaan tidak ada dalam jaringan saraf, tetapi bagaimana memproses data dengan benar. Tetapi untuk memprosesnya, Anda harus terlebih dahulu menganalisis korelasinya, memilih data yang diperlukan, membuang yang tidak perlu, dan sebagainya. Untuk tujuan tersebut, visualisasi menggunakan perpustakaan matplotlib sering digunakan.

Temui aku "di dalam"!
Kustomisasi
Jalankan kode berikut untuk mengonfigurasi. Namun, bagan individual menimpa pengaturan mereka sendiri.
Korelasi
Plot korelasi digunakan untuk memvisualisasikan hubungan antara 2 atau lebih variabel. Artinya, bagaimana satu variabel berubah dalam hubungannya dengan yang lain.
1. Plot pencar
Scatteplot adalah tampilan bagan klasik dan fundamental yang digunakan untuk menguji hubungan antara dua variabel. Jika Anda memiliki beberapa grup dalam data Anda, Anda dapat memvisualisasikan setiap grup dalam warna yang berbeda. Di matplotlib Anda dapat dengan mudah melakukan ini menggunakan plt.scatterplot ().

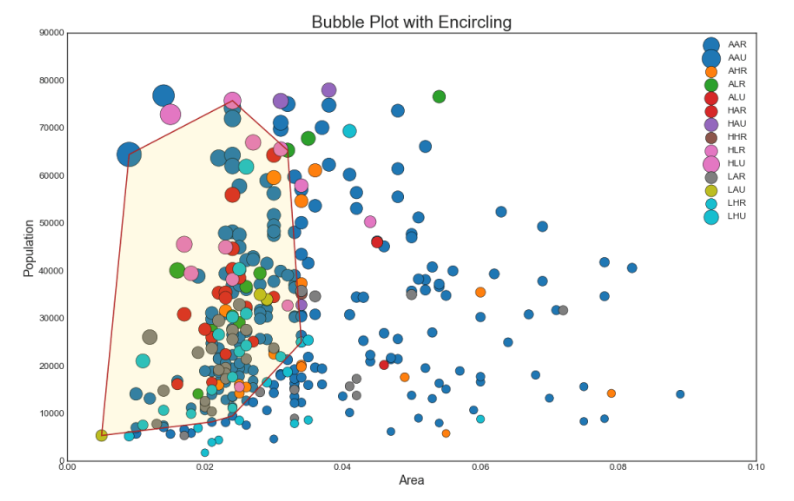
2. Bagan gelembung dengan tangkapan kelompok
Terkadang Anda ingin menunjukkan sekelompok titik di dalam perbatasan untuk menekankan pentingnya mereka. Dalam contoh ini, kami mendapatkan catatan dari bingkai data yang harus dialokasikan, dan meneruskannya ke melingkari () yang dijelaskan dalam kode di bawah ini.
Tampilkan kode from matplotlib import patches from scipy.spatial import ConvexHull import warnings; warnings.simplefilter('ignore') sns.set_style("white")
3. Grafik regresi linier paling sesuai
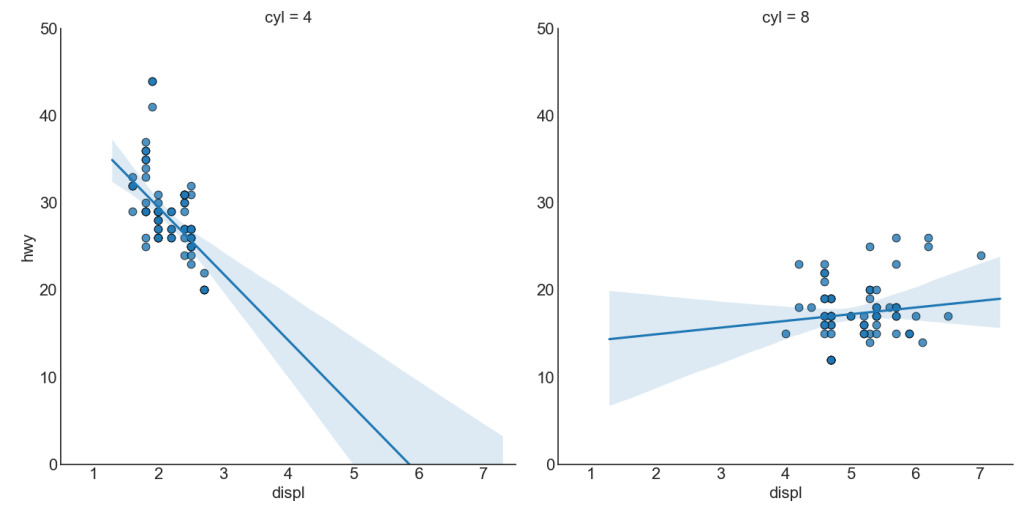
Jika Anda ingin memahami bagaimana dua variabel berubah dalam hubungannya satu sama lain, garis paling cocok adalah yang terbaik. Grafik di bawah ini menunjukkan bagaimana paling cocok berbeda di antara kelompok data yang berbeda. Untuk menonaktifkan pengelompokan dan cukup menggambar satu baris paling cocok untuk seluruh dataset, hapus parameter hue = 'cyl' dari sns.lmplot () di bawah ini.

Setiap baris regresi di kolomnya sendiri
Selain itu, Anda dapat menunjukkan garis paling cocok untuk setiap grup dalam kolom terpisah. Anda ingin melakukan ini dengan mengatur parameter col = groupingcolumn di dalam sns.lmplot ().
4. Stripplot
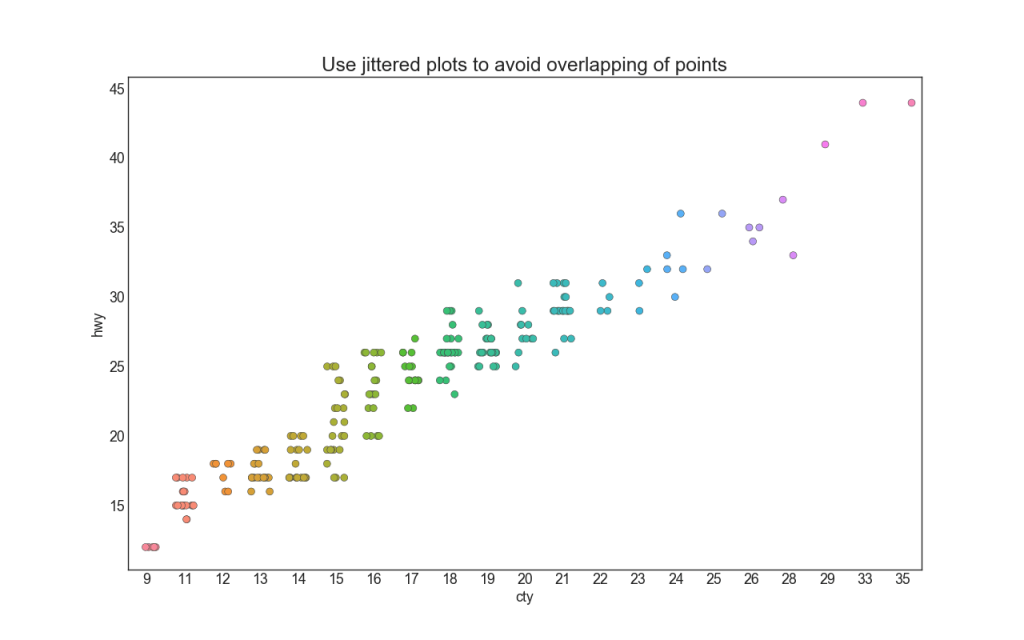
Seringkali beberapa titik data memiliki nilai X dan Y yang sama. Akibatnya, banyak titik diplot satu sama lain dan disembunyikan. Untuk menghindari ini, pisahkan kedua titik sedikit agar Anda dapat melihatnya secara visual. Ini mudah dilakukan menggunakan stripplot ().
5. Menghitung Plot
Pilihan lain yang menghindari masalah titik yang tumpang tindih adalah menambah ukuran titik, tergantung pada berapa banyak titik yang terletak di tempat ini. Dengan demikian, semakin besar ukuran titik, semakin besar konsentrasi titik di sekitarnya.

6. Grafik batang
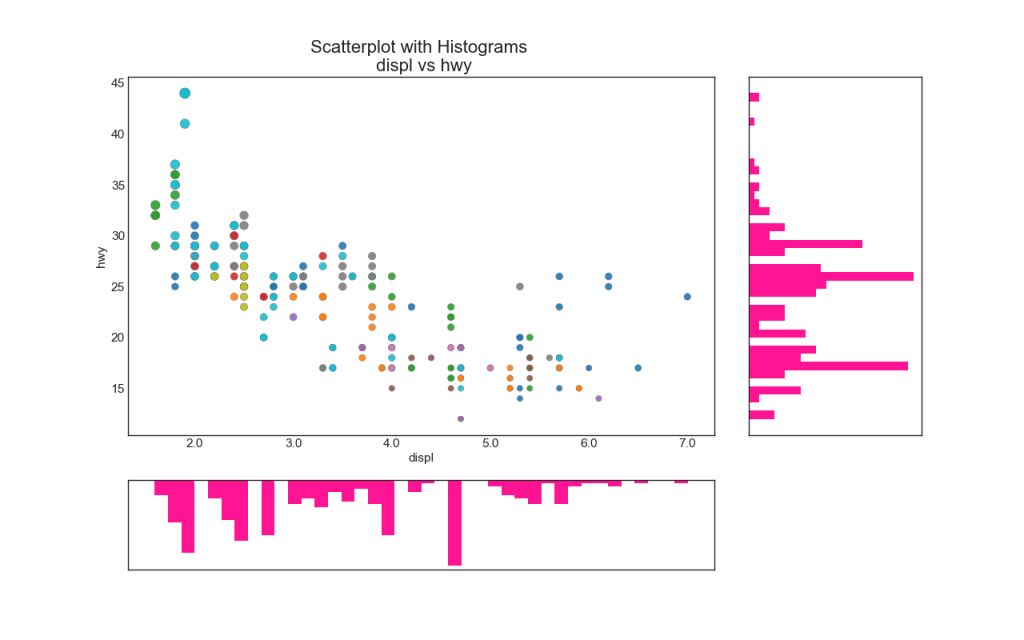
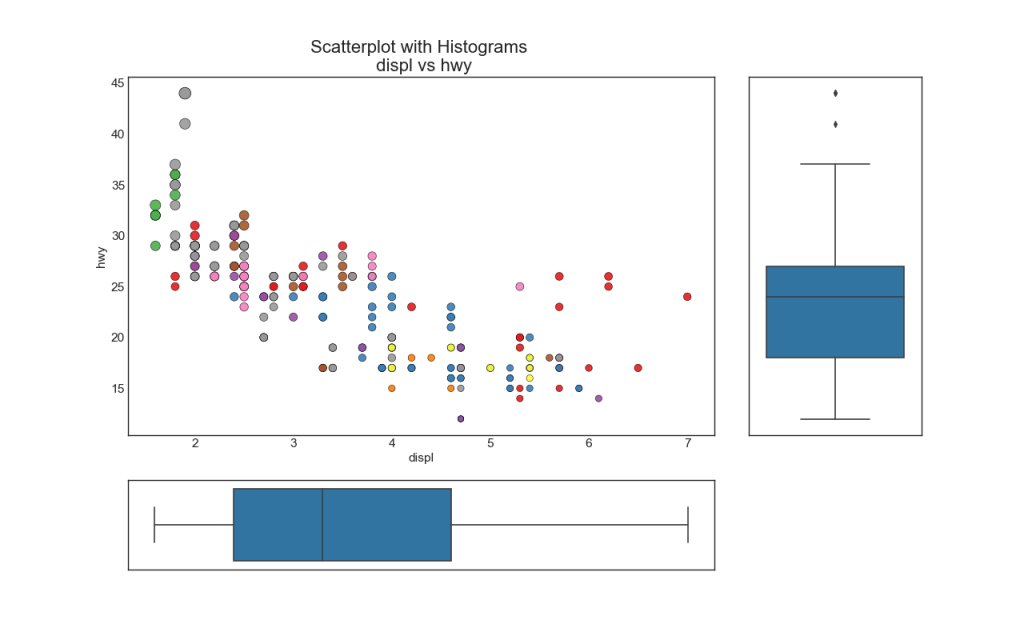
Garis histogram memiliki histogram di sepanjang variabel sumbu X dan Y. Ini digunakan untuk memvisualisasikan hubungan antara X dan Y bersama-sama dengan distribusi satu dimensi X dan Y secara individual. Grafik ini sering digunakan dalam analisis data (EDA).
7. Boxplot
Boxplot memiliki tujuan yang sama dengan histogram garis demi garis. Namun, grafik ini membantu menunjukkan median, persentil X dan Y ke-25 dan ke-75.
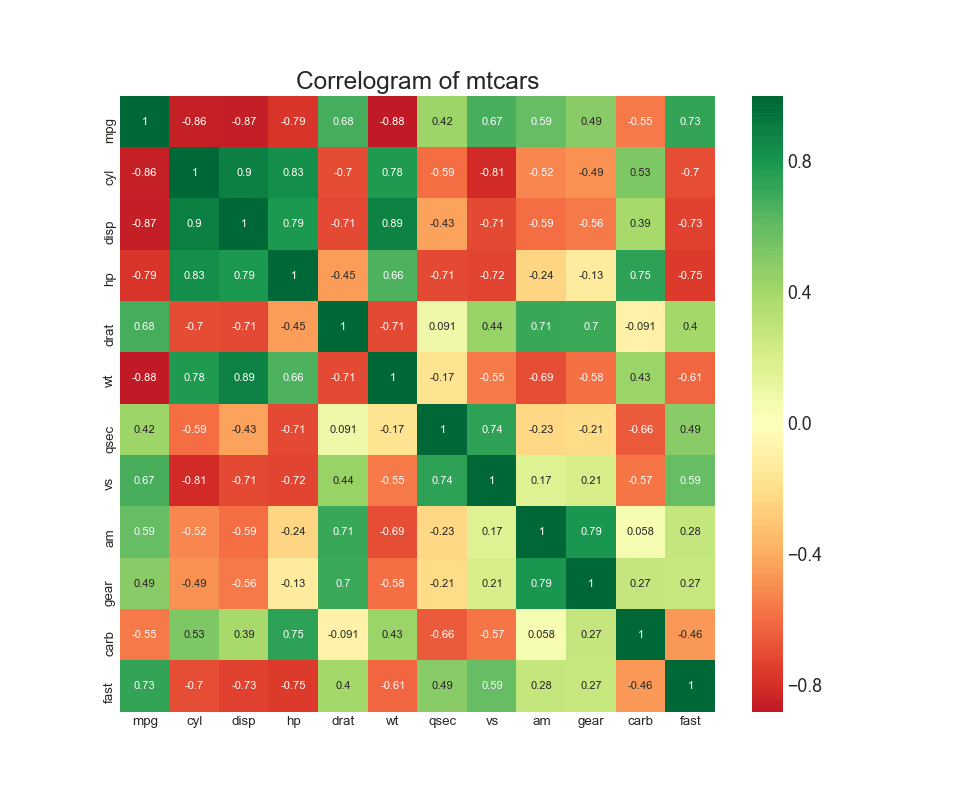
8. Diagram korelasi
Diagram korelasi digunakan untuk melihat secara visual metrik korelasi di antara semua pasangan variabel numerik yang mungkin ada dalam kumpulan data yang diberikan (atau array dua dimensi).
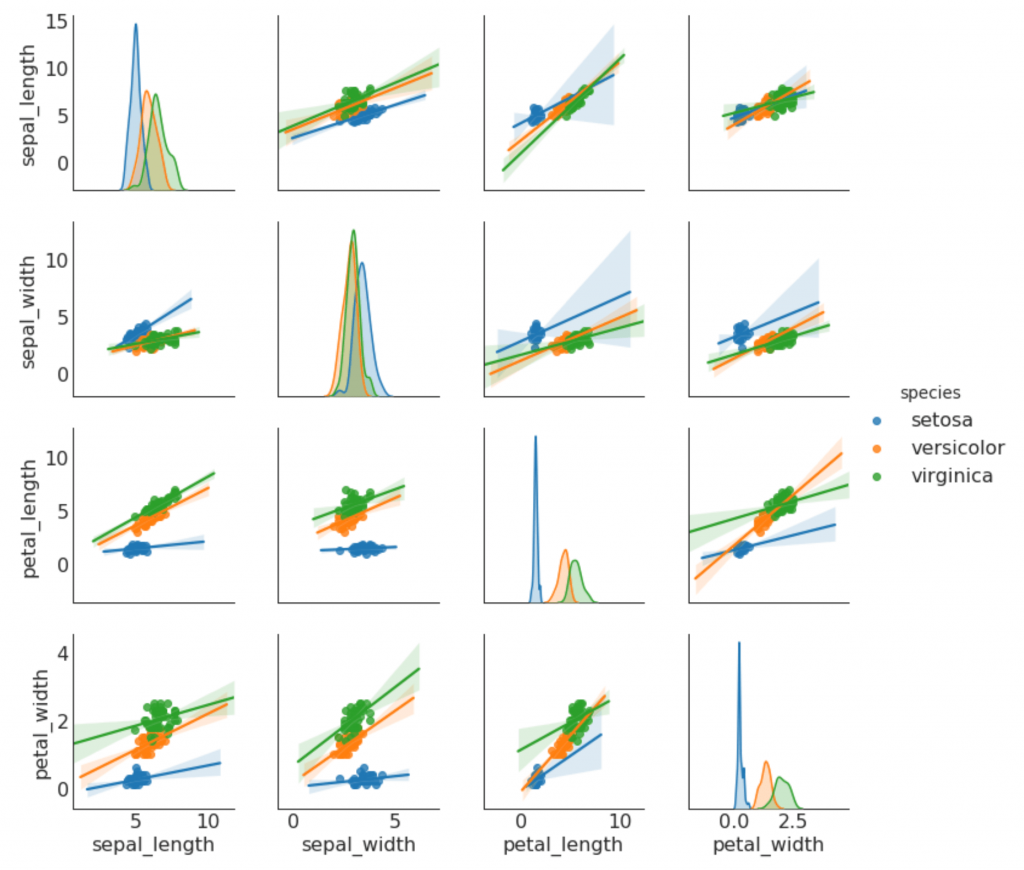
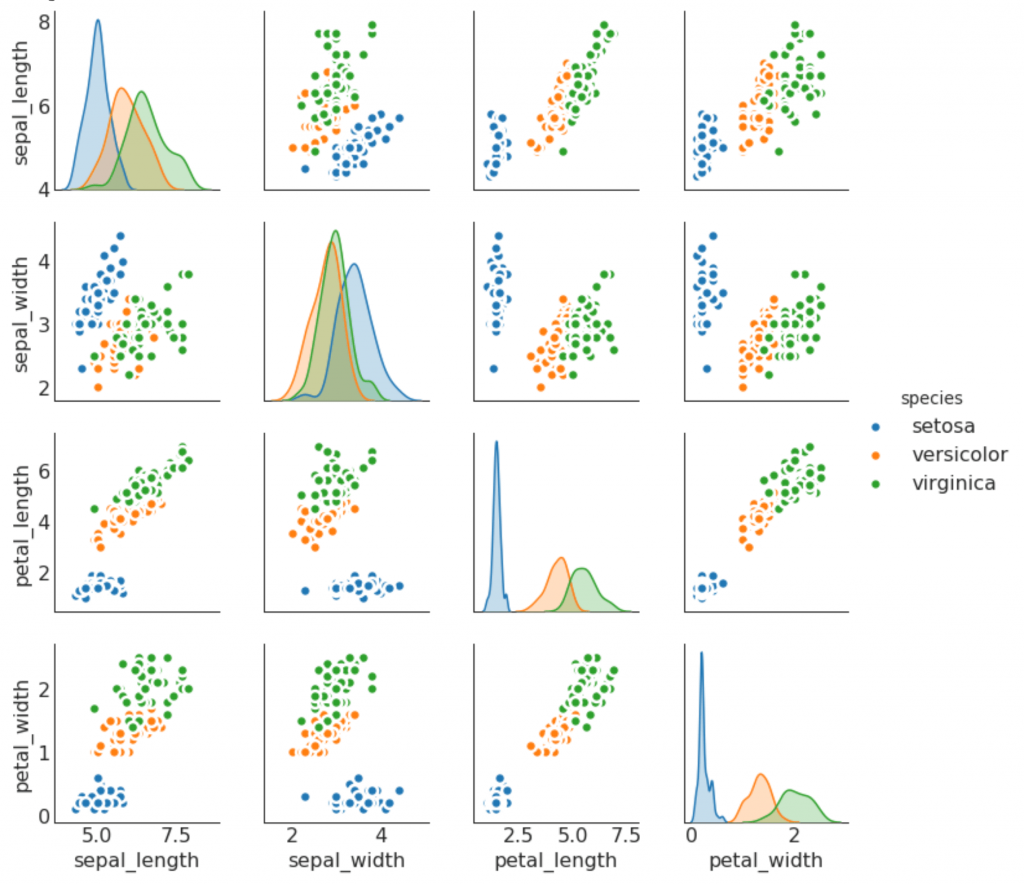
9. Jadwal pasangan
Sering digunakan dalam analisis penelitian untuk memahami hubungan antara semua pasangan yang mungkin dari variabel numerik. Ini adalah alat yang harus dimiliki untuk analisis dua dimensi.
Penyimpangan
10. Kolom yang menyimpang
Jika Anda ingin melihat bagaimana elemen berubah tergantung pada satu metrik, dan untuk memvisualisasikan urutan dan besarnya dispersi ini, kolom yang berbeda adalah alat yang hebat. Ini membantu untuk dengan cepat membedakan kinerja grup dalam data Anda, cukup intuitif dan langsung menyampaikan makna.

11. Membagi kolom dengan teks
- terlihat seperti kolom yang berbeda, dan ini lebih disukai jika Anda ingin menunjukkan signifikansi setiap elemen dalam bagan dengan cara yang baik dan rapi.
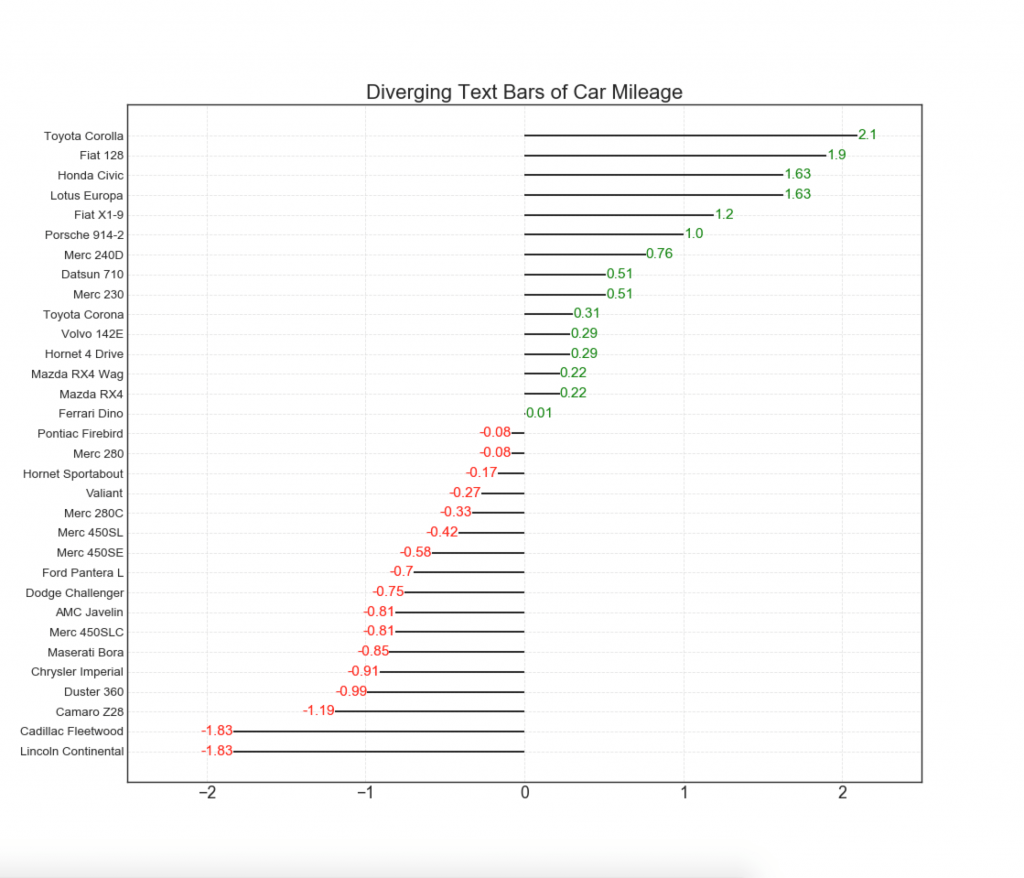
12. Poin yang berbeda
Grafik titik divergen juga mirip dengan kolom divergen. Namun, dibandingkan dengan kolom yang berbeda, tidak adanya kolom mengurangi tingkat kontras dan perbedaan antara kelompok.
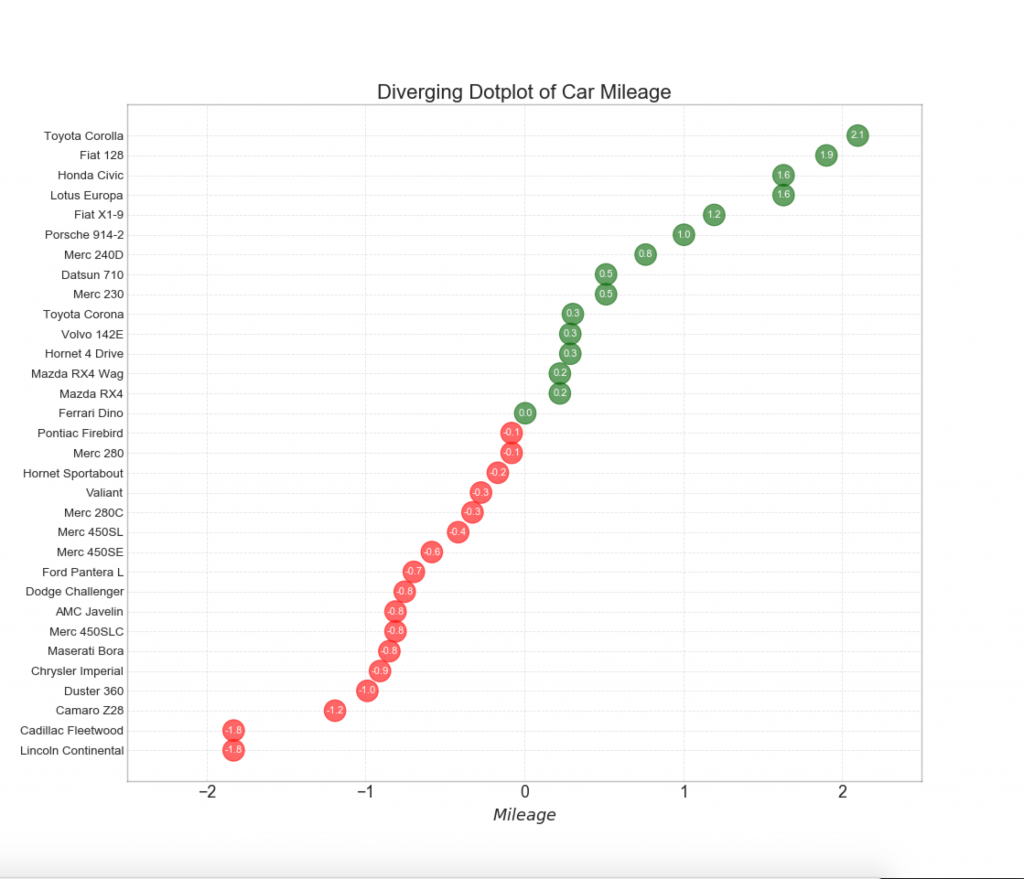
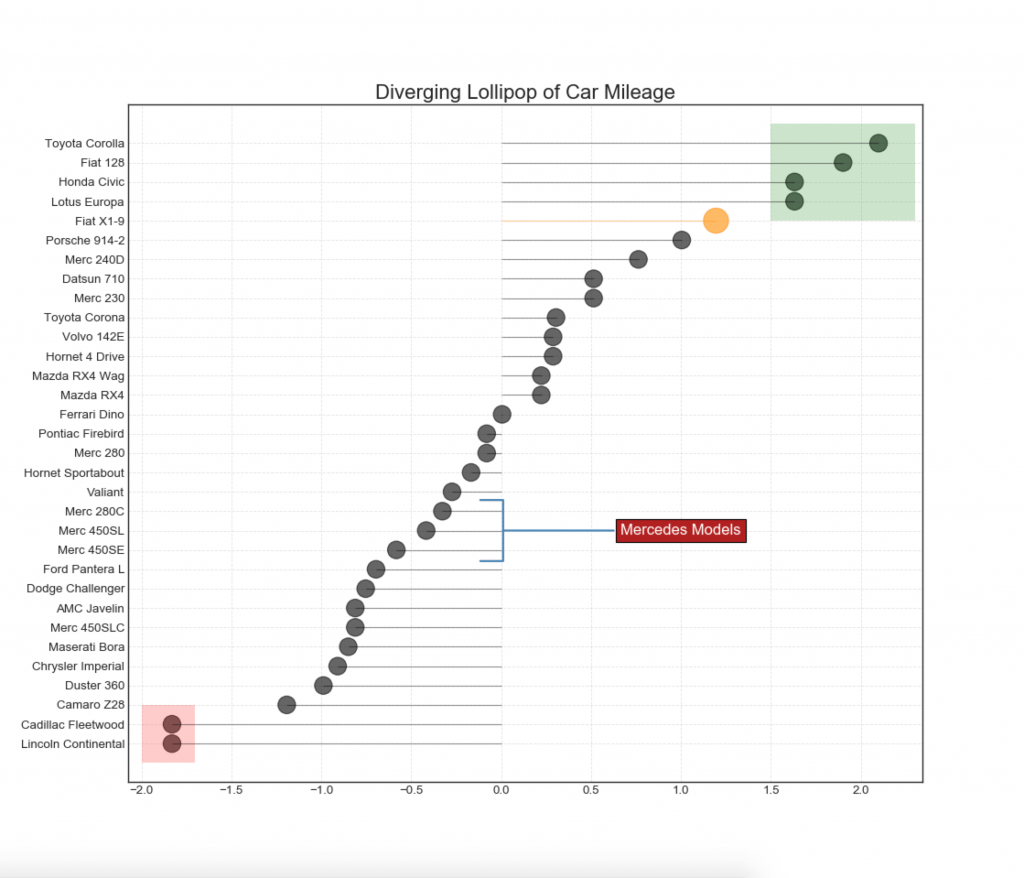
13. Diollent Lollipop chart dengan spidol
Lollipop menyediakan cara yang fleksibel untuk memvisualisasikan perbedaan, dengan fokus pada setiap poin data yang relevan yang ingin Anda perhatikan.
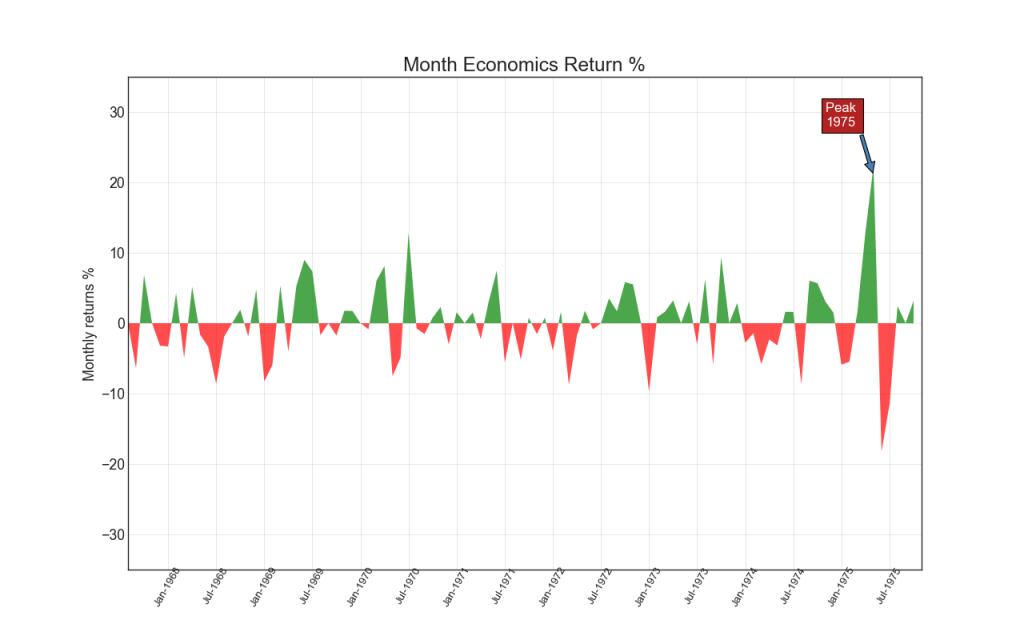
14. Bagan area
Mewarnai area antara sumbu dan garis, diagram area menekankan puncak dan palung, tetapi juga pada durasi tinggi dan rendah. Semakin tinggi, semakin besar area di bawah garis.
Tampilkan kode import numpy as np import pandas as pd
Peringkat
15. Memesan histogram
Histogram terurut secara efektif menyampaikan urutan peringkat elemen. Tetapi dengan menambahkan nilai metrik di atas bagan, pengguna menerima informasi yang akurat dari bagan itu sendiri.
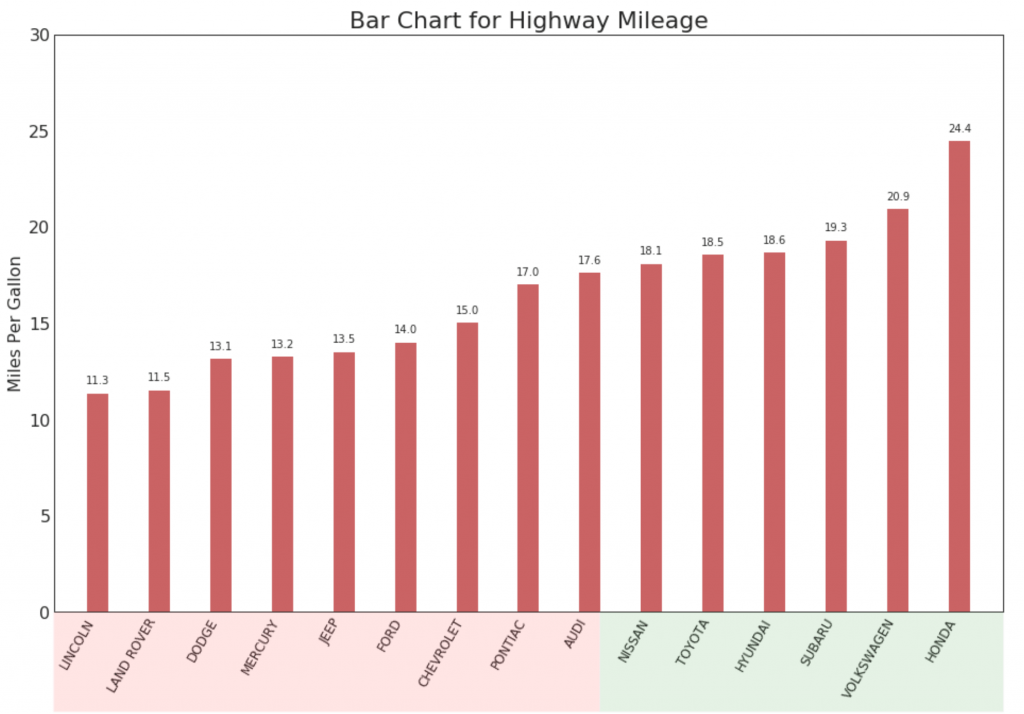
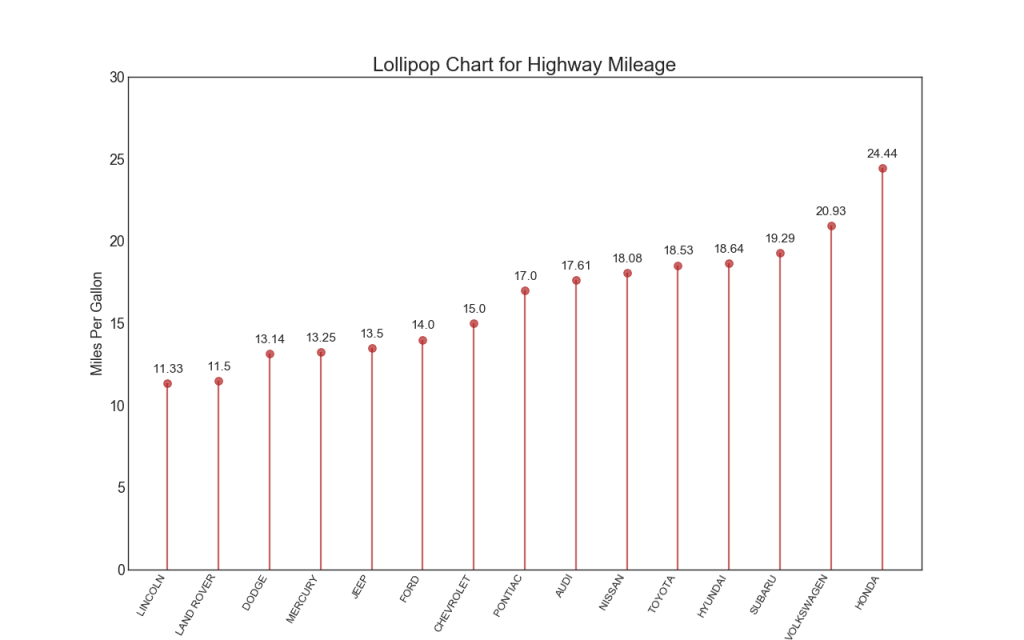
16. Grafik Lollipop
Grafik Lollipop memiliki tujuan yang sama dengan histogram yang dipesan dengan cara yang menyenangkan secara visual.
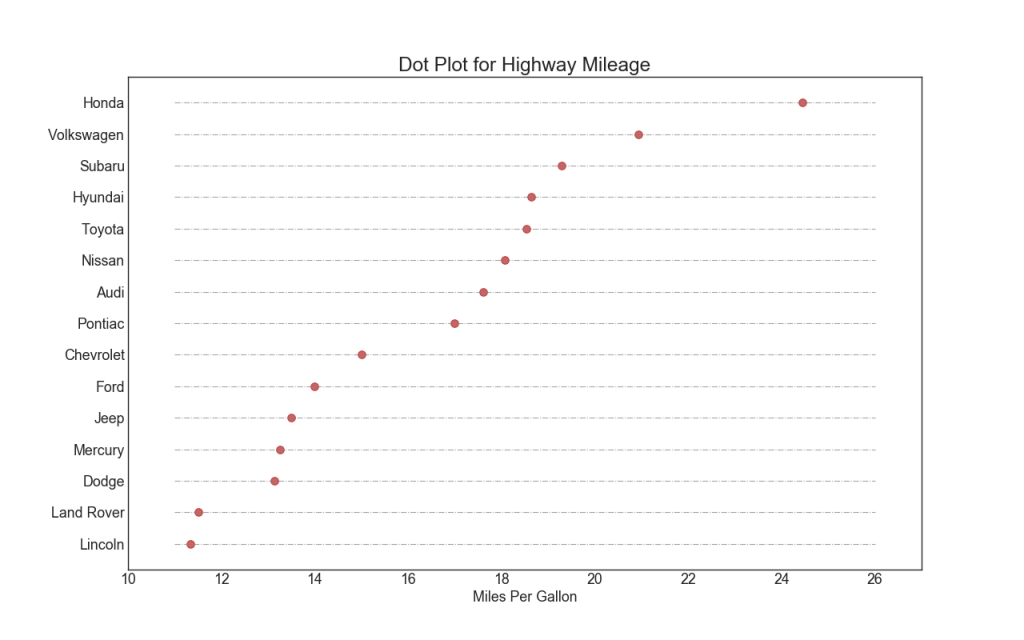
17. Dotted chart dengan tanda tangan
Plot sebar menyampaikan peringkat item. Dan karena disejajarkan di sepanjang sumbu horizontal, Anda dapat secara visual mengevaluasi seberapa jauh titik-titik tersebut dari satu sama lain.
18. Peta miring
Grafik kemiringan paling cocok untuk membandingkan posisi "Sebelum" dan "Setelah" dari orang / subjek tertentu.
Tampilkan kode import matplotlib.lines as mlines

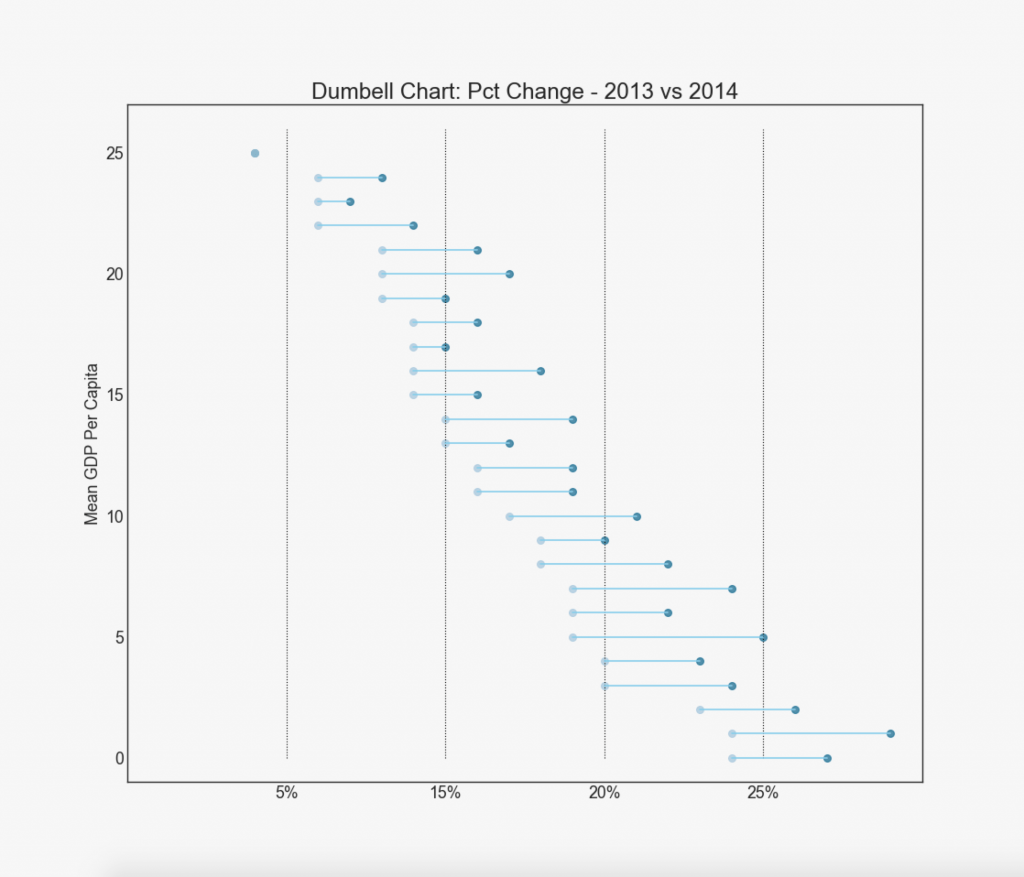
19. "Dumbel"
Grafik "Dumbbell" menyampaikan posisi "sebelum" dan "setelah" dari berbagai pengaruh, serta urutan peringkat item. Ini sangat berguna jika Anda ingin memvisualisasikan efek sesuatu pada objek yang berbeda.
Tampilkan kode import matplotlib.lines as mlines
Distribusi
20. Histogram untuk variabel kontinu
Histogram menunjukkan distribusi frekuensi variabel ini. Kelompok-kelompok frekuensi presentasi berikut ini berdasarkan pada variabel kategori.
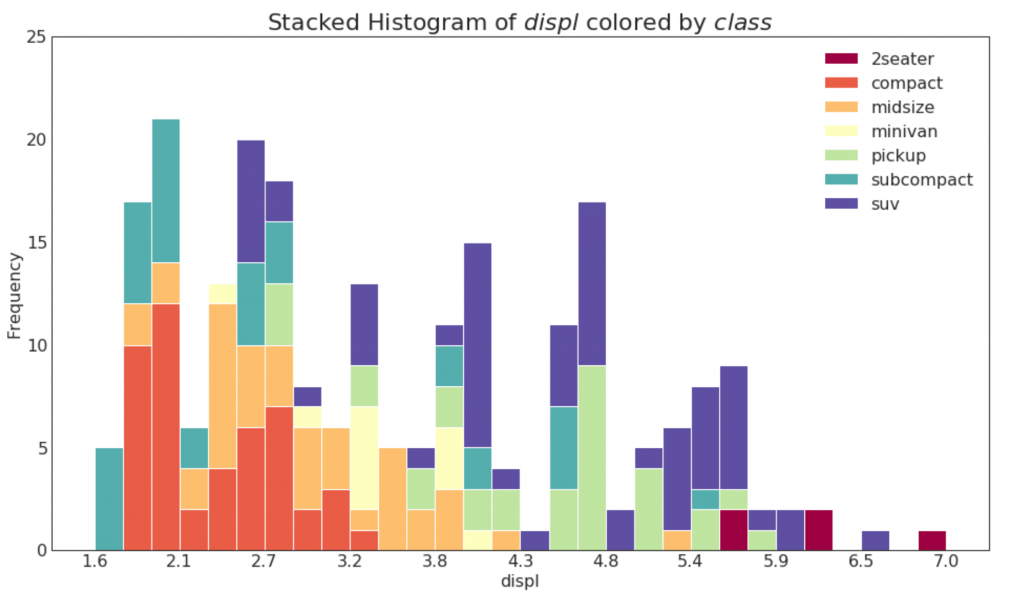
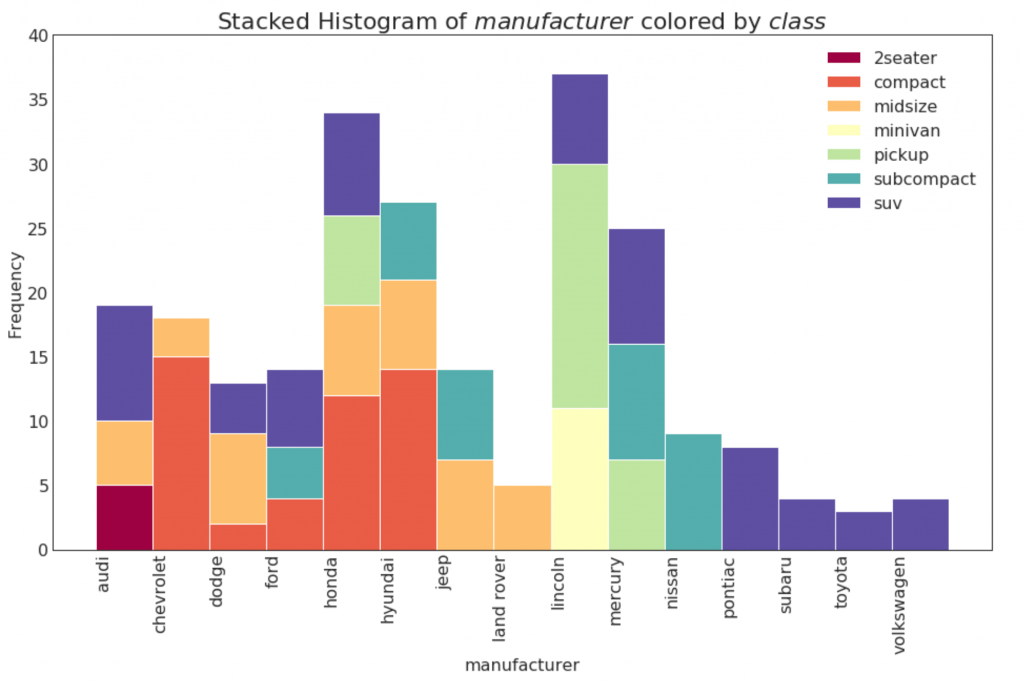
21. Histogram untuk variabel kategori
Histogram dari suatu variabel kategori menunjukkan distribusi frekuensi dari variabel ini. Dengan mewarnai kolom, Anda dapat memvisualisasikan distribusi dalam kaitannya dengan variabel kategori lain yang mewakili warna.
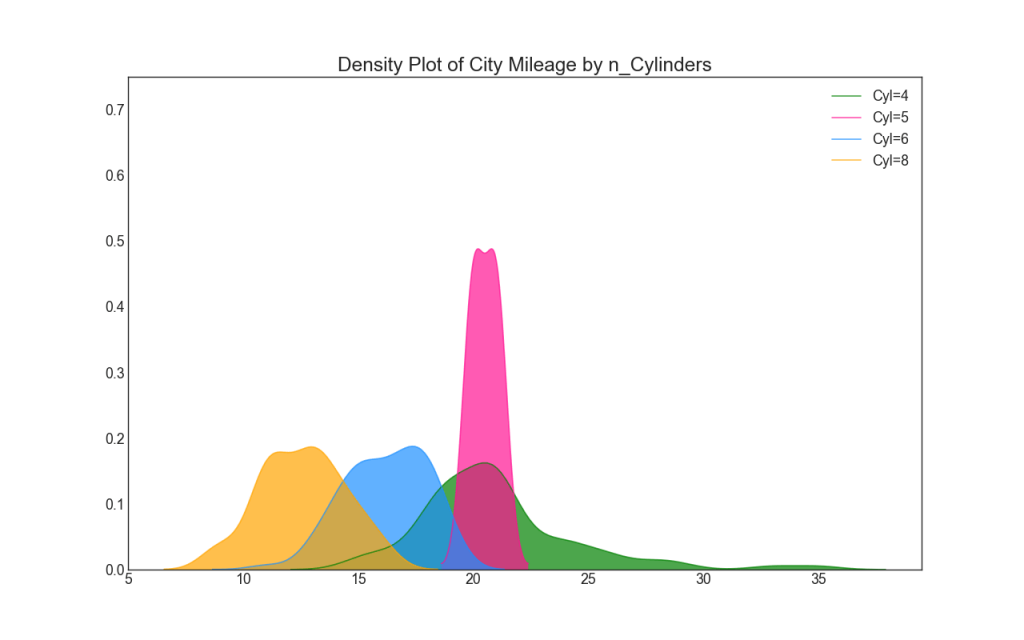
22. Grafik kepadatan
Grafik kepadatan adalah alat yang banyak digunakan untuk memvisualisasikan distribusi variabel kontinu. Setelah mengelompokkannya berdasarkan variabel "respons", Anda dapat memeriksa hubungan antara X dan Y. Berikut ini adalah contoh jika, untuk kejelasan, kami menggambarkan bagaimana distribusi jarak tempuh di kota bervariasi tergantung pada jumlah silinder.
23. Kurva Kepadatan dengan Histogram
Kurva kepadatan dengan histogram menggabungkan informasi ringkasan yang dikirimkan oleh dua grafik sehingga Anda dapat melihat keduanya di satu tempat.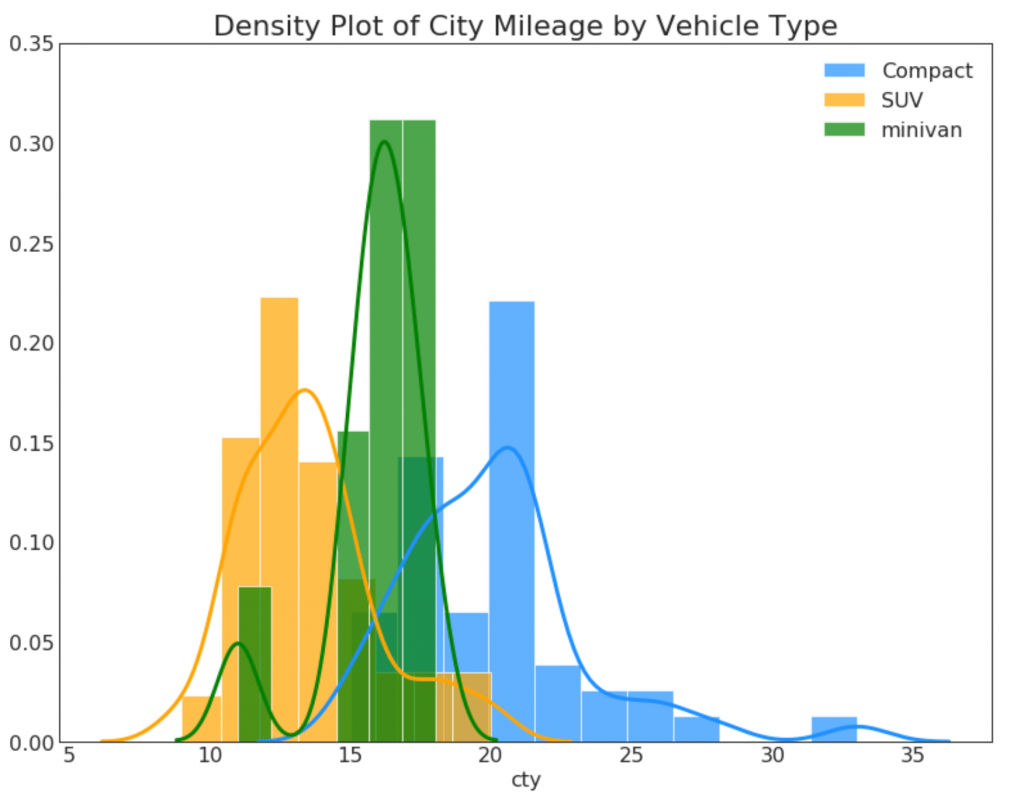
24. Joy chart
Bagan Joy memungkinkan Anda untuk tumpang tindih kurva kepadatan kelompok yang berbeda, ini adalah cara yang bagus untuk memvisualisasikan distribusi sejumlah besar kelompok dalam hubungannya satu sama lain. Itu terlihat enak dipandang dan jelas hanya menyampaikan informasi yang benar.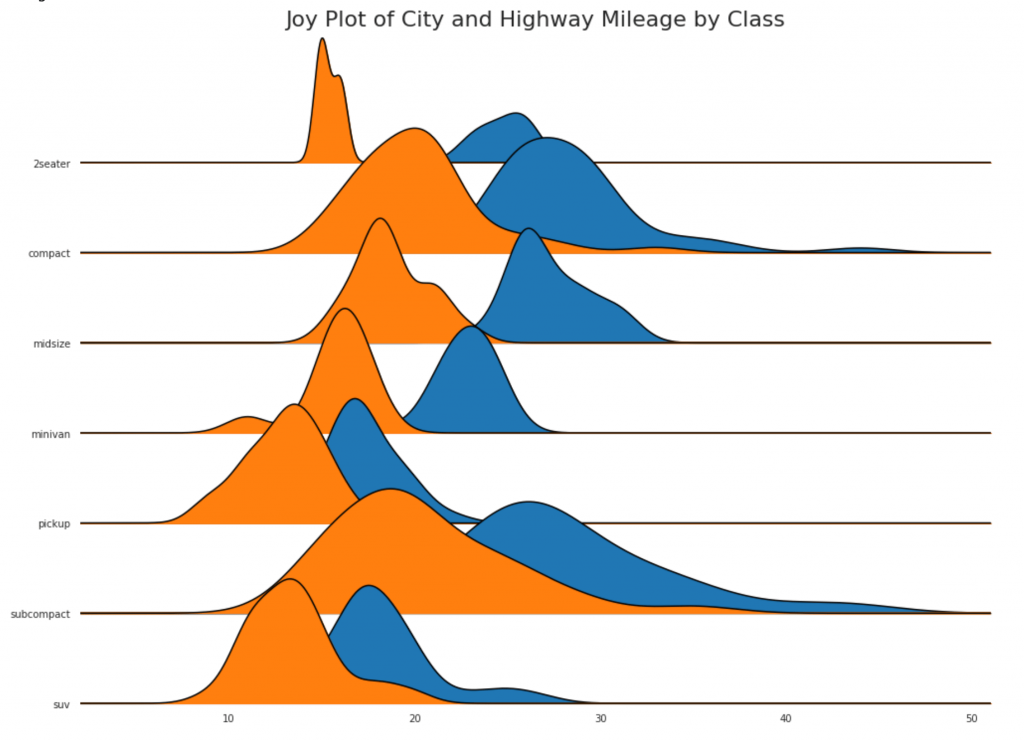
25. Bagan Sebar Terdistribusi
Plot sebaran terdistribusi menunjukkan distribusi satu dimensi dari poin yang tersegmentasi ke dalam kelompok. Semakin gelap titik, semakin besar konsentrasi titik data di wilayah ini. Dengan mewarnai median dengan cara yang berbeda, susunan kelompok yang sebenarnya menjadi jelas secara instan.Tampilkan kode import matplotlib.patches as mpatches

26. Grafik dengan persegi panjang
Bagan tersebut adalah cara yang bagus untuk memvisualisasikan distribusi, mengetahui median, kuartil ke-25, ke-75 dan tertinggi dengan posisi terendah. Namun, Anda harus berhati-hati ketika menginterpretasikan ukuran bidang, yang berpotensi dapat mendistorsi jumlah titik yang terkandung dalam grup ini. Dengan demikian, indikasi manual dari jumlah pengamatan di setiap sel akan membantu mengatasi kelemahan ini.Sebagai contoh, dua persegi panjang pertama di sebelah kiri memiliki ukuran yang sama, meskipun mereka masing-masing memiliki 5 dan 47 elemen data. Karena itu, perlu diperhatikan jumlah pengamatan.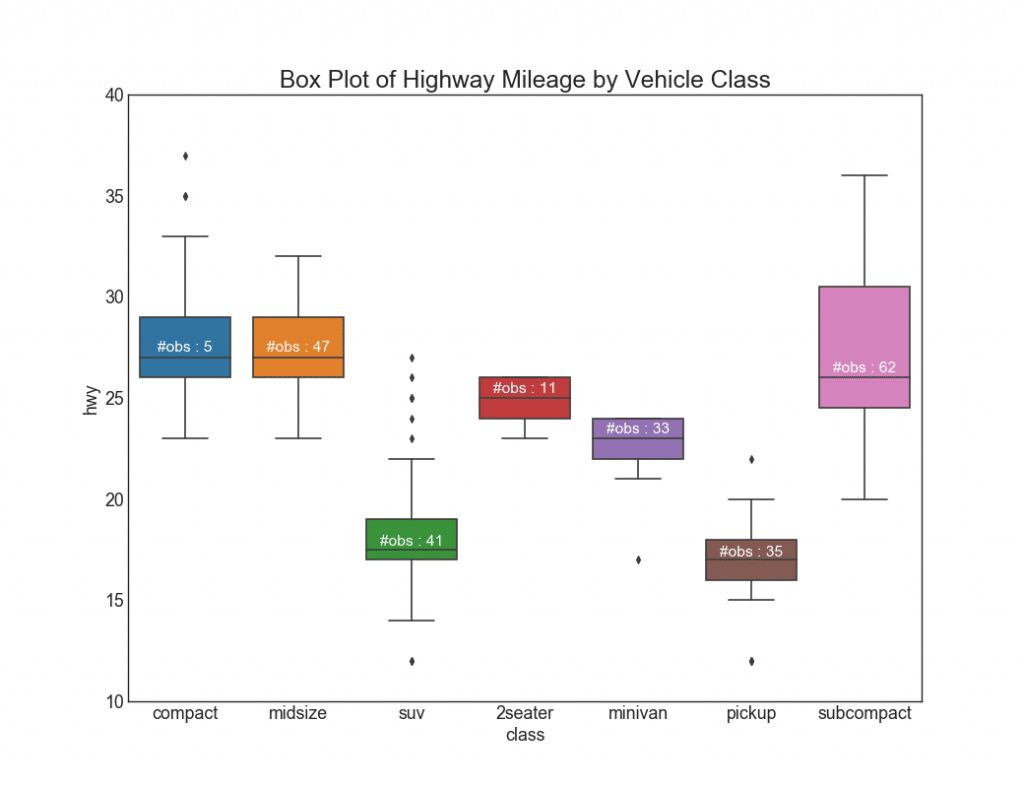
27. Grafik dengan persegi panjang dan titik-titik
Plot Dot + Box mentransmisikan informasi serupa, seperti boxplot, dibagi menjadi beberapa kelompok. Selain itu, titik-titik memberi gambaran tentang jumlah elemen data dalam setiap kelompok.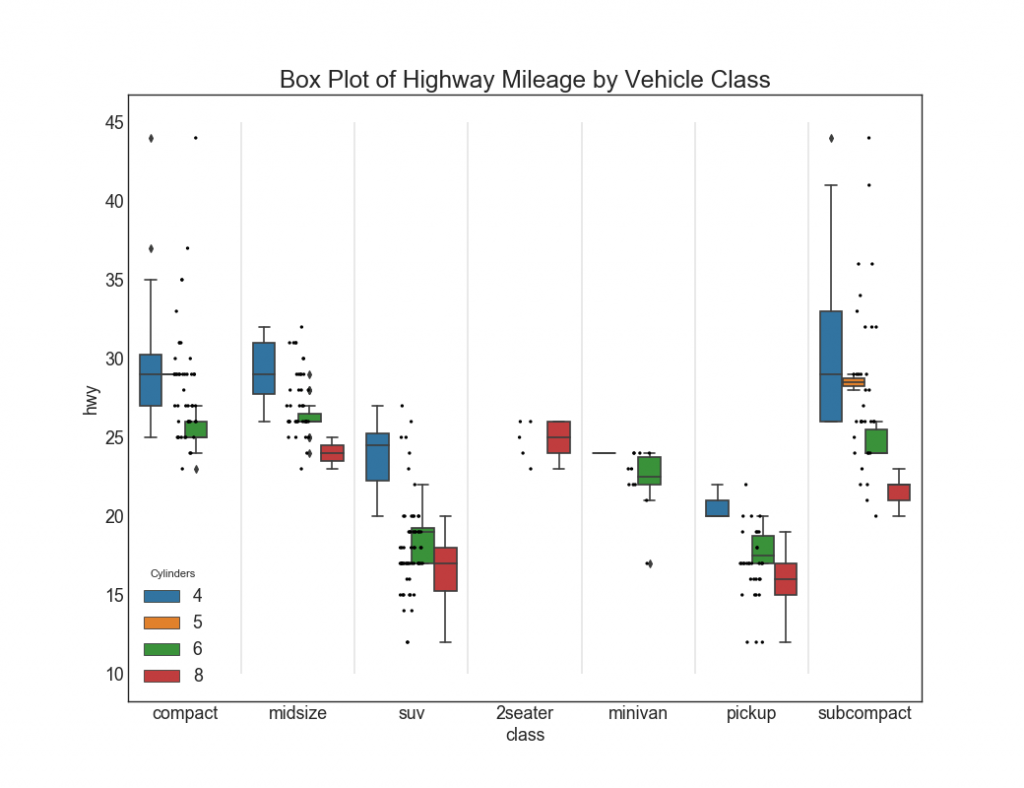
28. Jadwalkan “biola”
Jadwal seperti itu adalah alternatif yang menyenangkan secara visual daripada boxplot. Bentuk atau area "biola" tergantung pada jumlah data dalam grup ini. Namun, grafik semacam itu bisa lebih sulit dibaca, dan biasanya tidak digunakan dalam pengaturan profesional.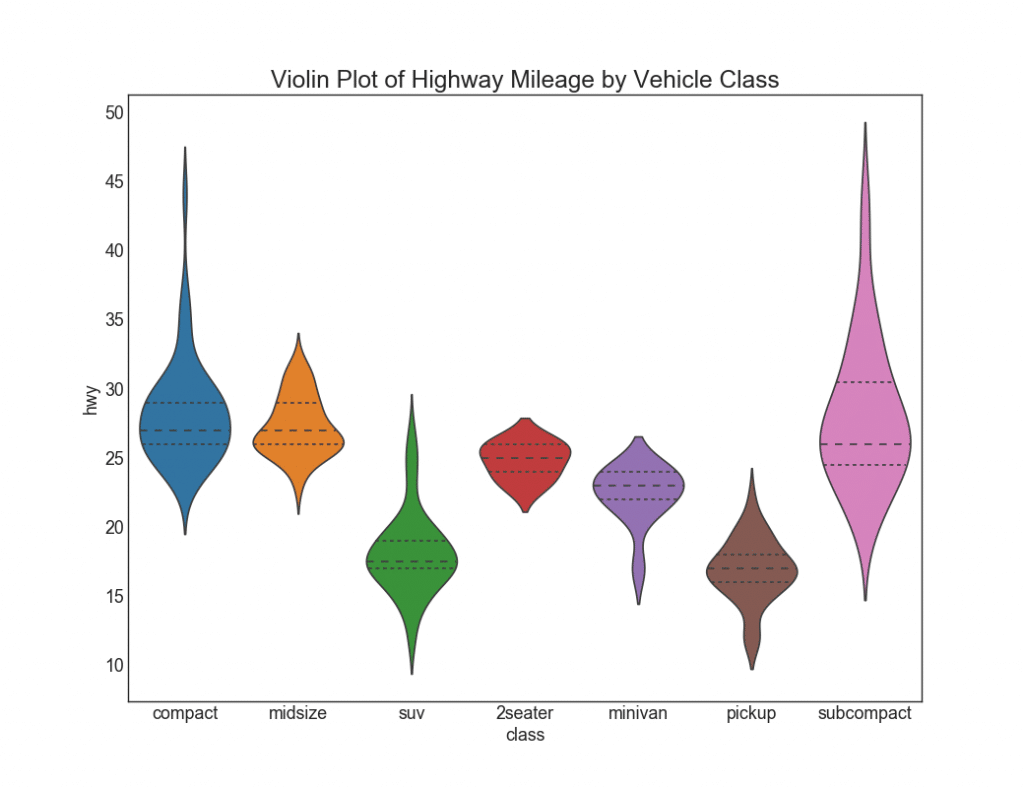
29. Piramida populasi
Piramida populasi dapat digunakan untuk menunjukkan distribusi kelompok yang dipesan berdasarkan volume, atau untuk menunjukkan penyaringan bertahap dari populasi, seperti yang ditunjukkan di bawah ini, untuk memvisualisasikan berapa banyak orang yang melalui setiap tahap corong pemasaran.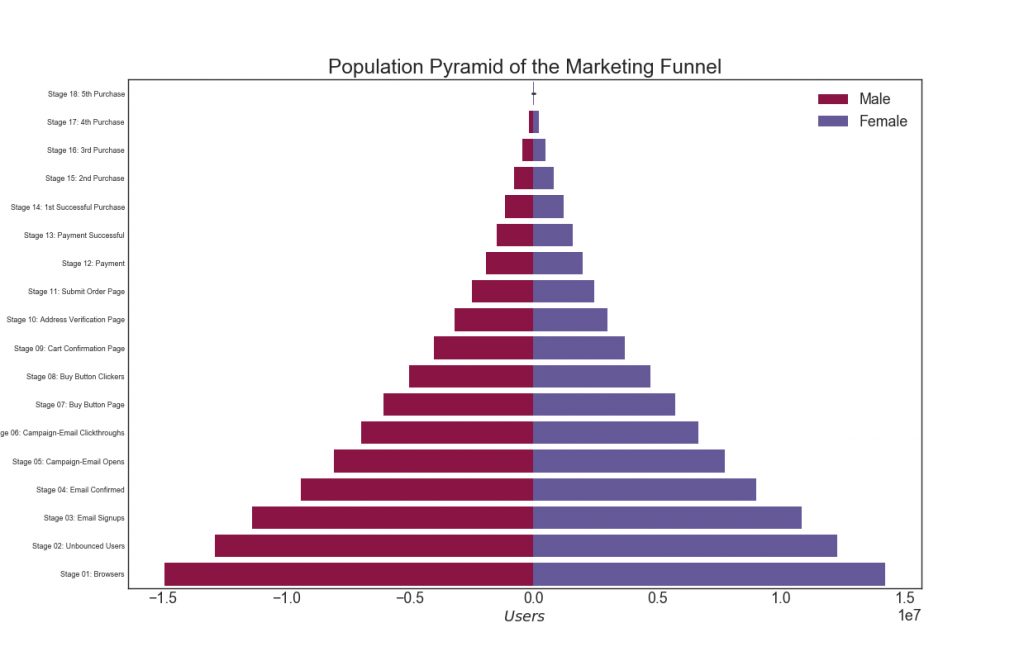
30. Grafik kategorikal
Grafik kategorikal yang disediakan oleh perpustakaan seaborn dapat digunakan untuk memvisualisasikan distribusi jumlah dua atau lebih variabel kategorikal relatif satu sama lain.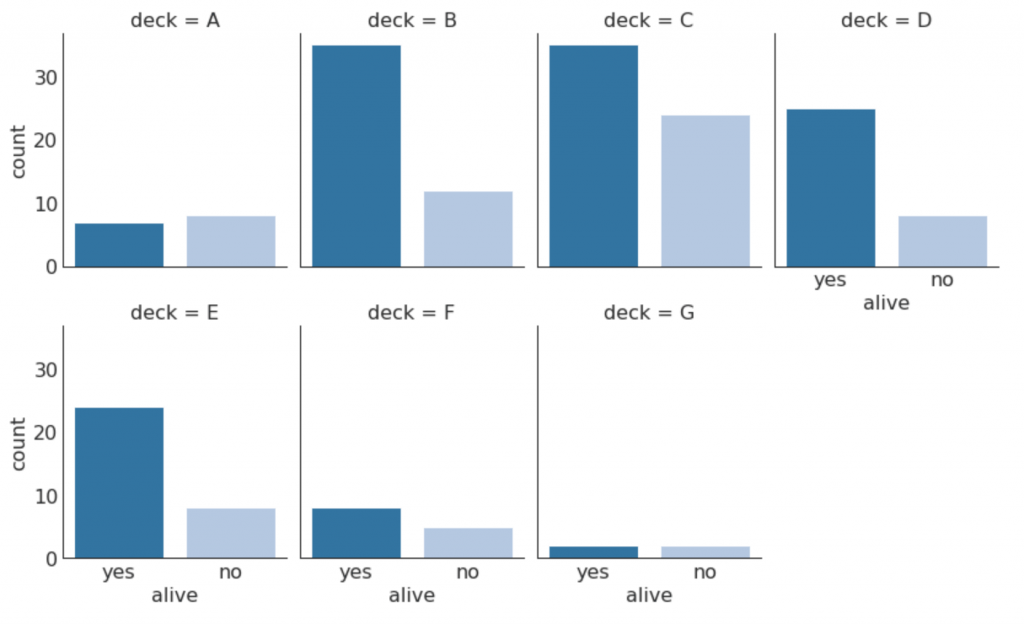
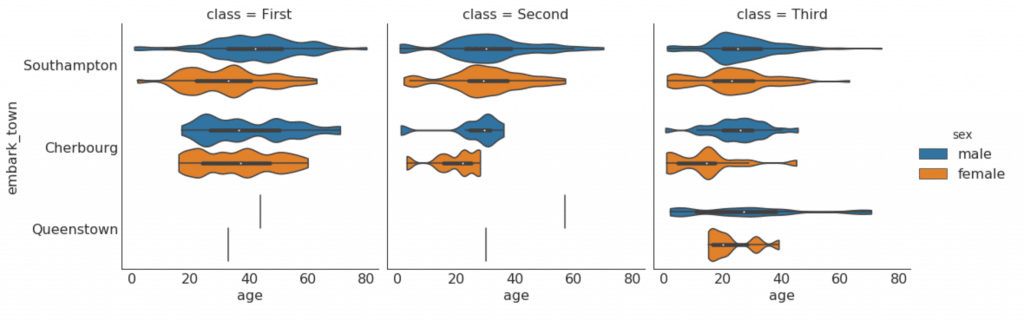
Perakitan, komposisi
31. Diagram wafel
Grafik wafel dapat dibuat menggunakan paket pywaffle dan digunakan untuk menampilkan komposisi grup di sebagian besar populasi.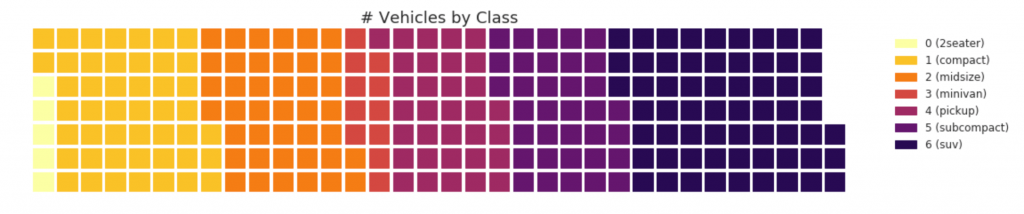
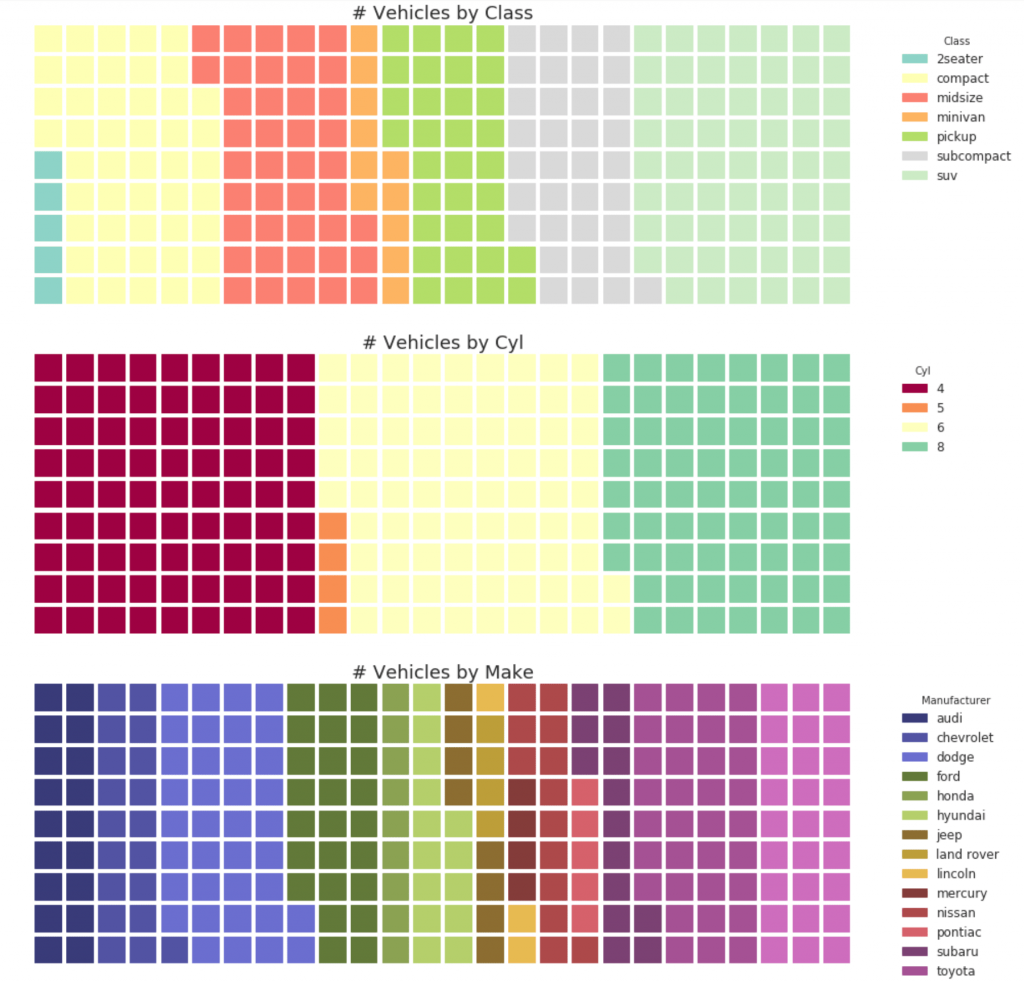
32. Grafik pie
Bagan pai adalah cara klasik untuk menunjukkan komposisi grup. Namun, saat ini umumnya tidak disarankan untuk menggunakan grafik ini karena area segmen terkadang dapat menyesatkan. Karena itu, jika Anda ingin menggunakan diagram lingkaran, sangat disarankan agar Anda secara eksplisit mencatat persentase atau angka untuk setiap bagian diagram lingkaran.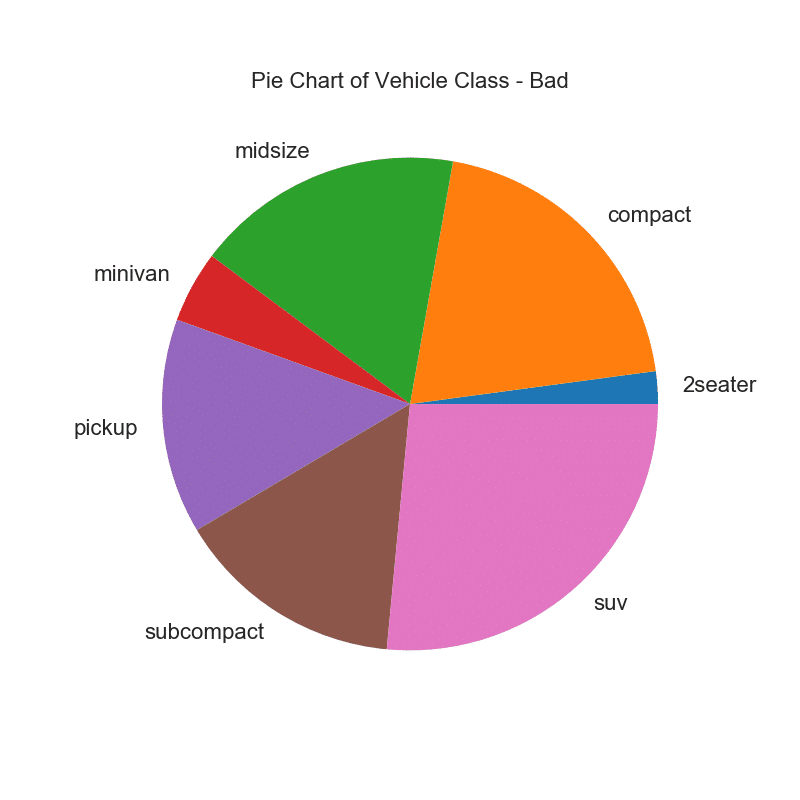
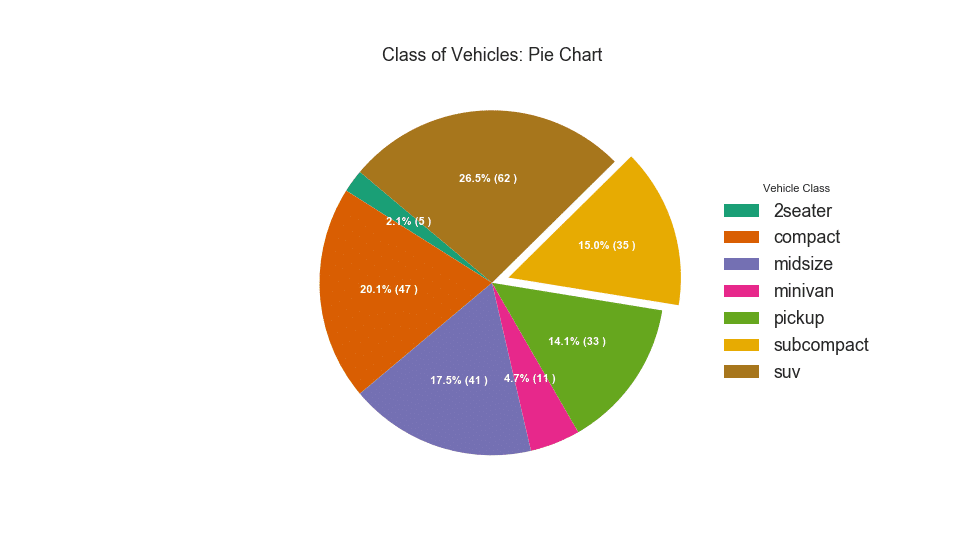
33. Peta pohon
Peta pohon tampak seperti bagan pai dan berfungsi lebih baik tanpa menyesatkan pangsa setiap kelompok.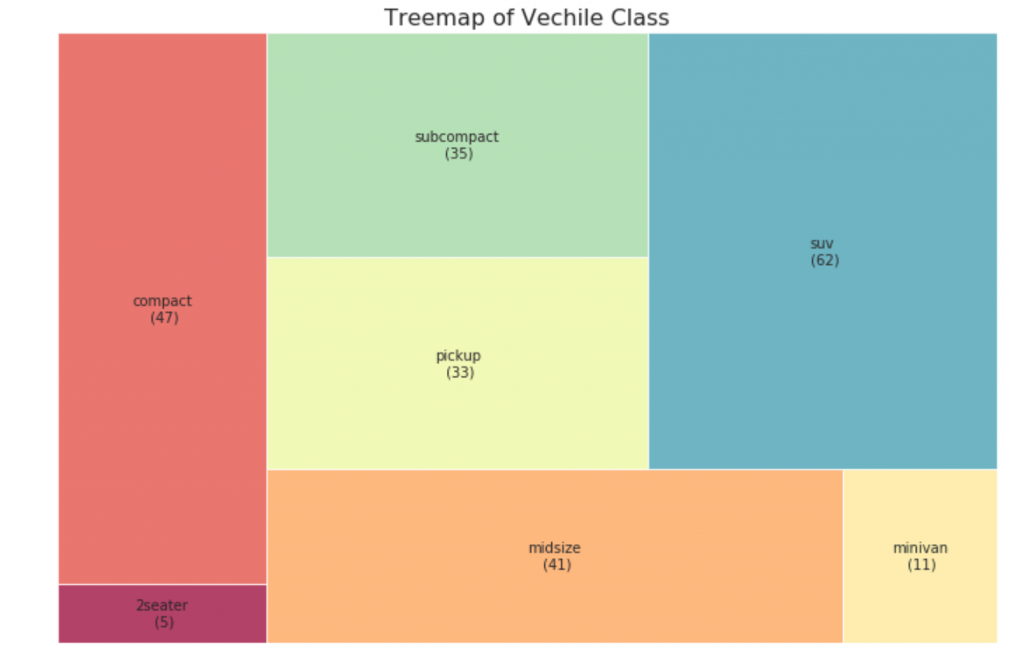
34. Histogram
Histogram adalah cara klasik untuk memvisualisasikan elemen berdasarkan kuantitas atau metrik yang diberikan. Dalam diagram di bawah ini, saya menggunakan warna yang berbeda untuk setiap elemen, tetapi Anda dapat memilih satu warna untuk semua elemen jika Anda tidak ingin mewarnai mereka dalam kelompok. Nama warna disimpan di dalam all_colors dalam kode di bawah ini. Anda dapat mengubah warna garis-garis dengan mengatur parameter warna di .plt.plot ()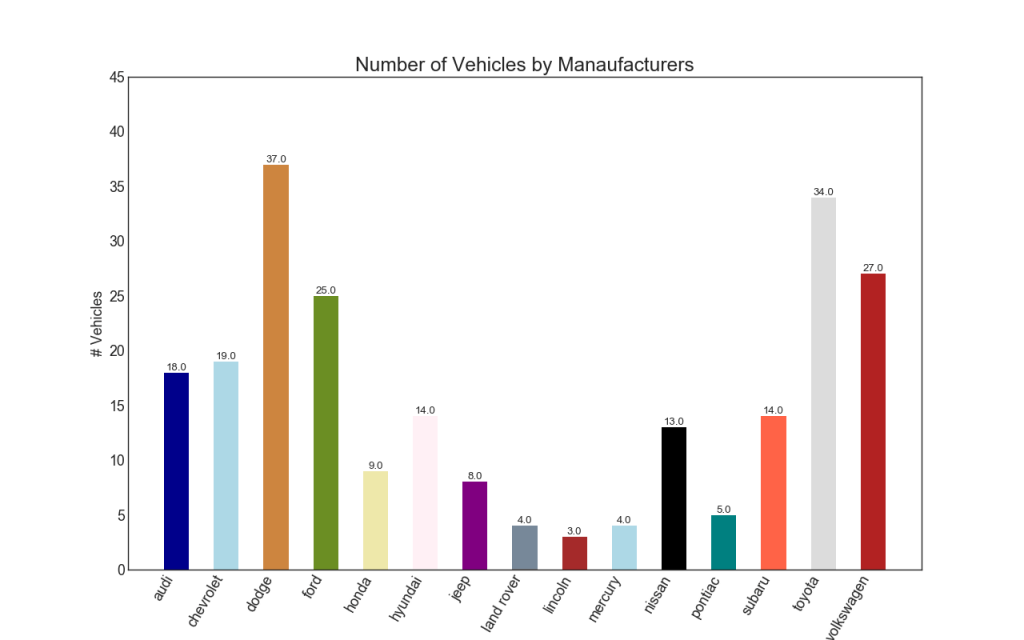
Ubah pelacakan
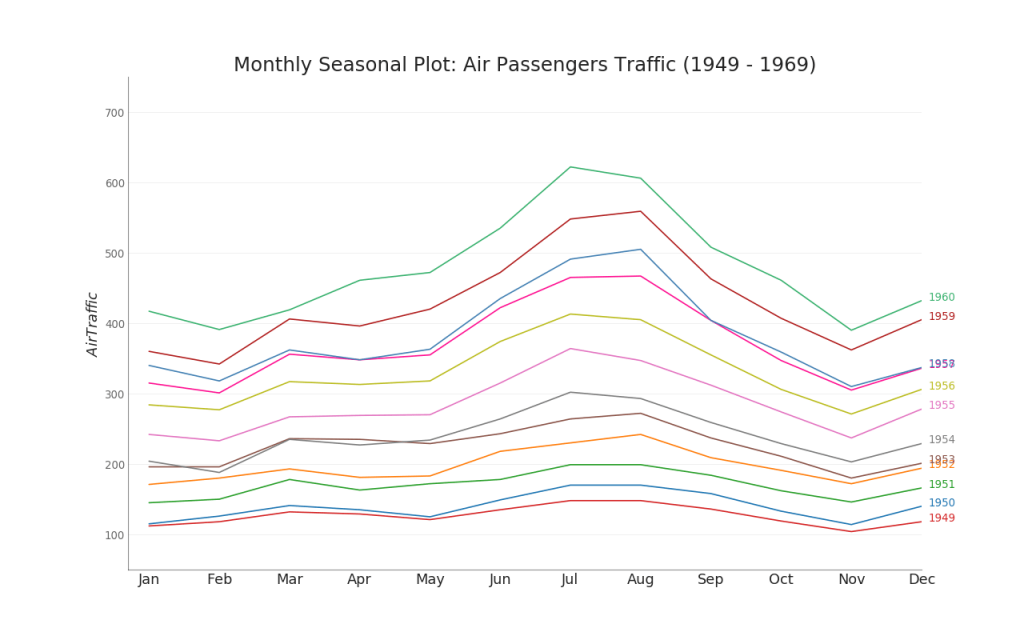
35. Bagan seri waktu
Bagan seri waktu digunakan untuk memvisualisasikan bagaimana indikator yang diberikan berubah seiring waktu. Di sini Anda dapat melihat bagaimana arus penumpang berubah dari tahun 1949 hingga 1969.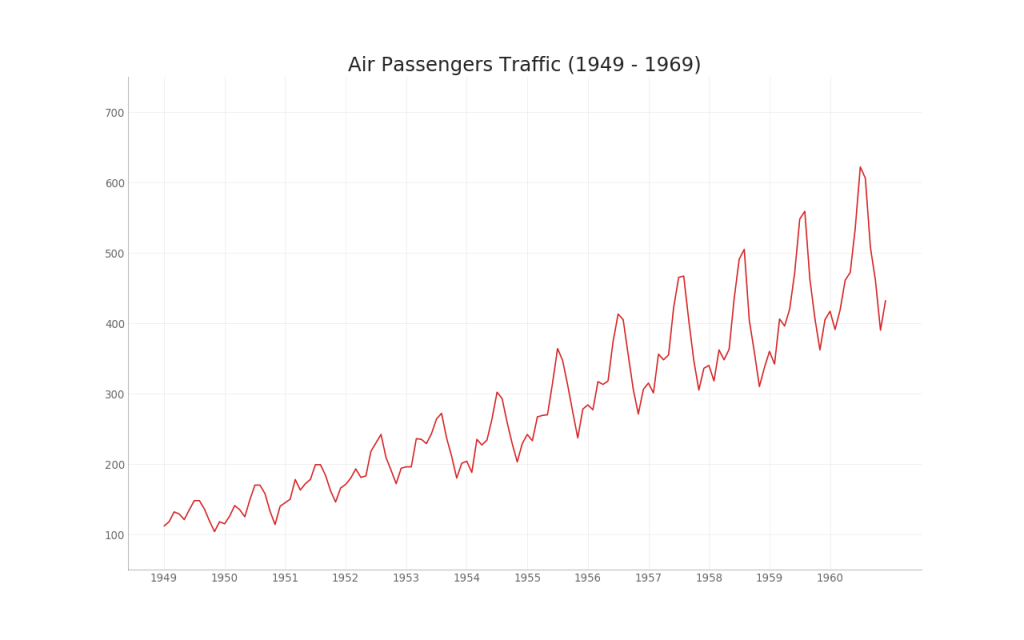
36. Rangkaian waktu dengan puncak dan palung
Rangkaian waktu di bawah ini menampilkan semua puncak dan palung dan menandai terjadinya peristiwa khusus individu.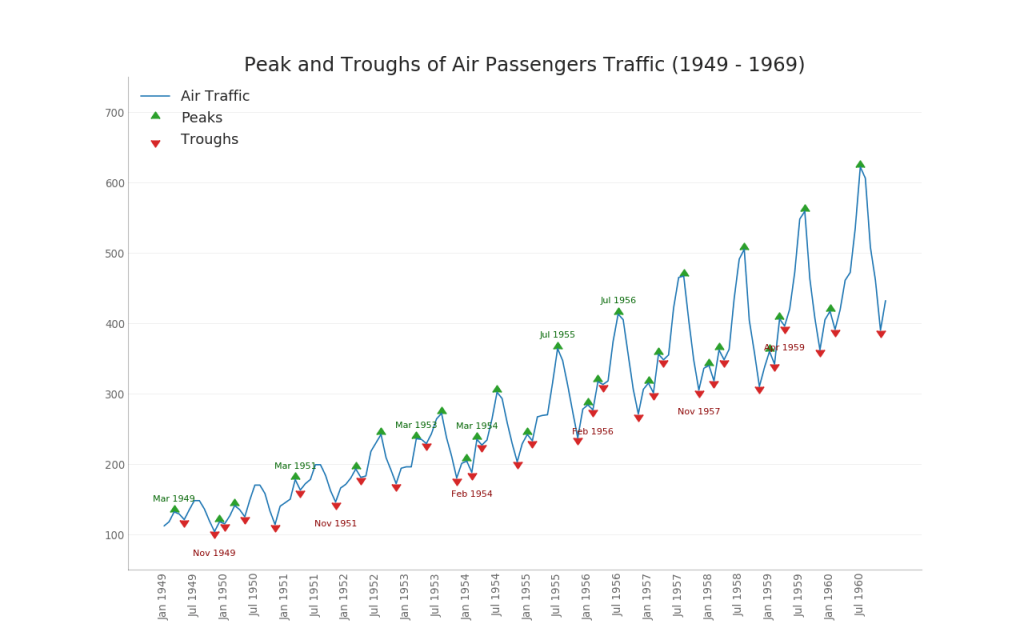
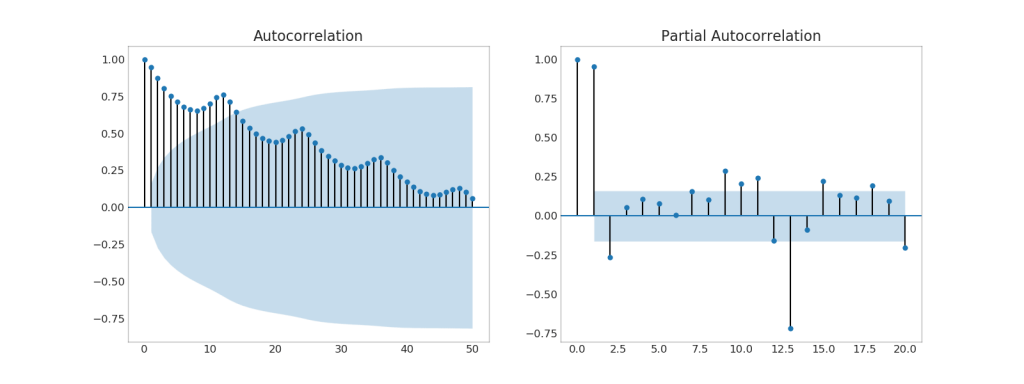
37. (ACF) (PACF)
Grafik ACF menunjukkan korelasi deret waktu dengan waktunya sendiri. Setiap garis vertikal (pada grafik autokorelasi) mewakili korelasi antara seri dan waktunya, dimulai pada waktu 0. Daerah yang diarsir biru pada grafik adalah tingkat signifikansi. Momen-momen yang terletak di atas garis biru itu penting.Jadi bagaimana Anda menafsirkan ini?Untuk AirPassengers, kita melihat bahwa pada x = 14, "lolipop" melintasi garis biru dan karenanya sangat penting. Ini berarti bahwa lalu lintas penumpang yang diamati hingga 14 tahun yang lalu berdampak pada lalu lintas yang diamati hari ini.PACF, di sisi lain, menunjukkan autokorelasi dari waktu tertentu (seri waktu) dengan seri saat ini, tetapi dengan menghilangkan pengaruh di antara mereka.Tampilkan kode from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
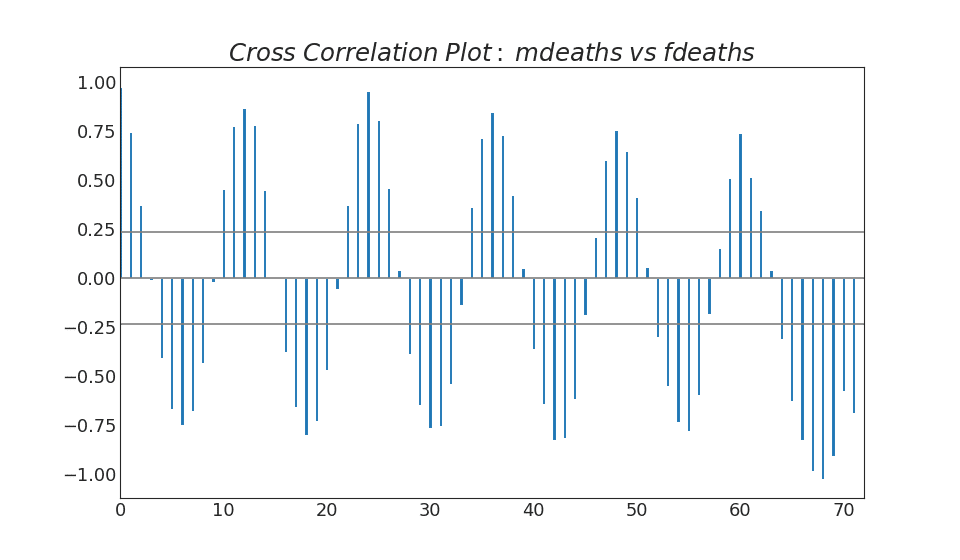
38. Grafik korelasi silang
Grafik korelasi silang menunjukkan penundaan dua deret waktu satu sama lain.Tampilkan kode import statsmodels.tsa.stattools as stattools
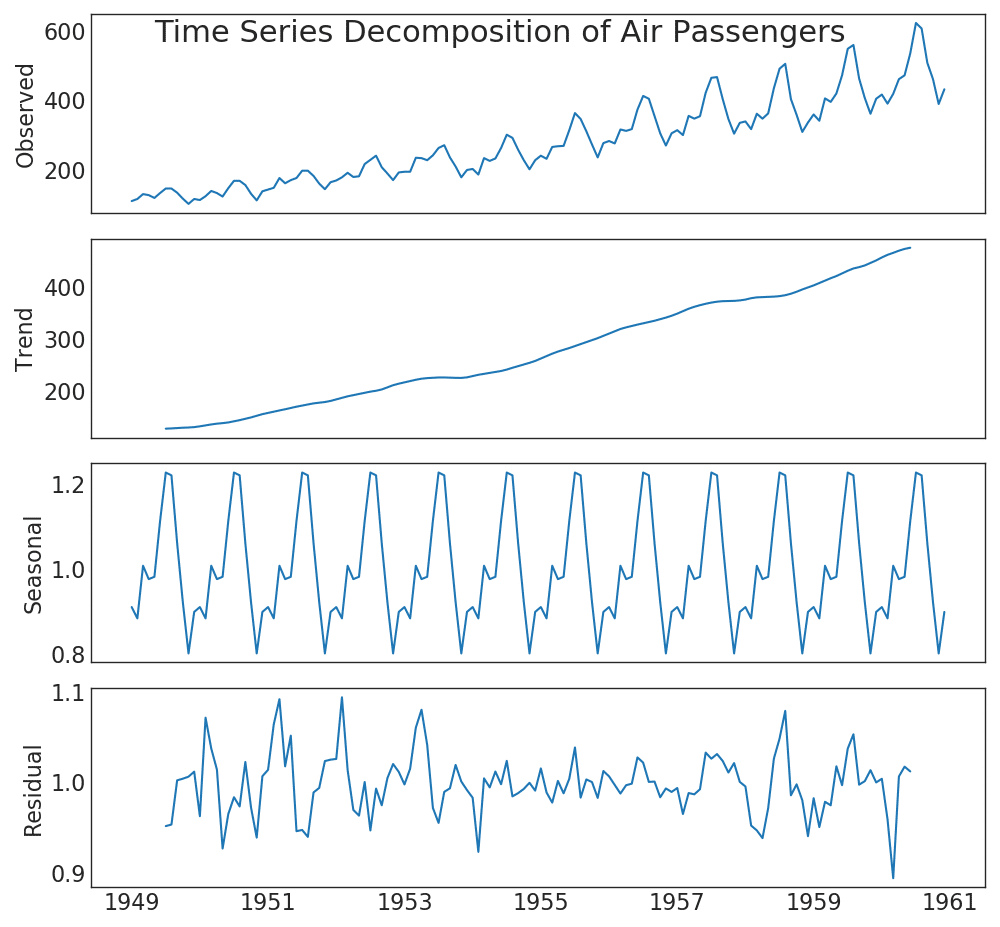
39. Perluasan deret waktu
Grafik ekspansi deret waktu menunjukkan rincian deret waktu menjadi komponen tren, musiman dan residual.Tampilkan kode from statsmodels.tsa.seasonal import seasonal_decompose from dateutil.parser import parse
40. Beberapa seri waktu
Anda dapat membuat beberapa seri waktu yang mengukur nilai yang sama pada satu grafik, seperti yang ditunjukkan di bawah ini.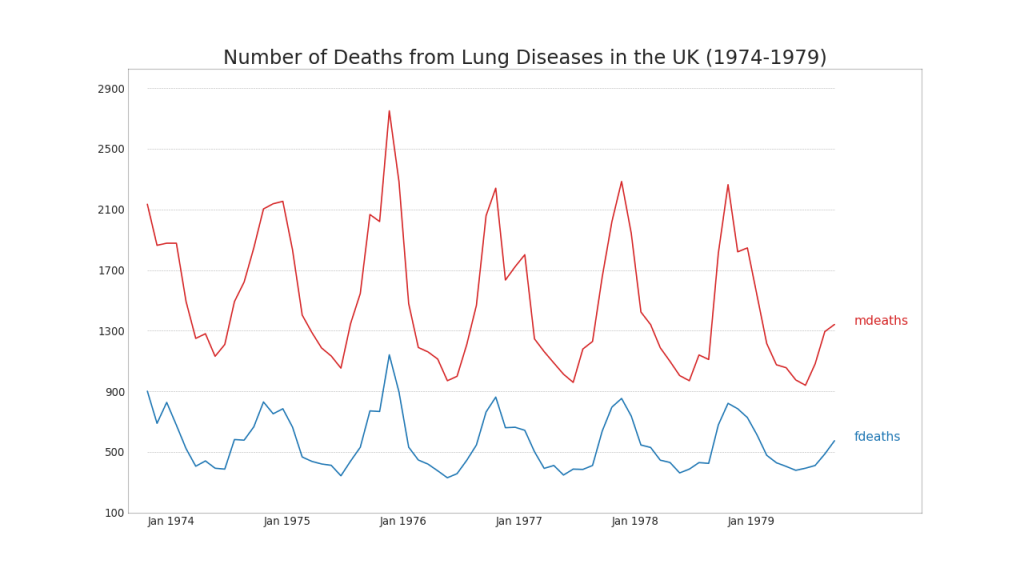
41. Bangunan pada skala yang berbeda menggunakan sumbu Y sekunder
Jika Anda ingin menampilkan dua seri waktu yang mengukur dua nilai yang berbeda secara bersamaan, Anda bisa membuat seri kedua lagi pada sumbu Y sekunder di sebelah kanan.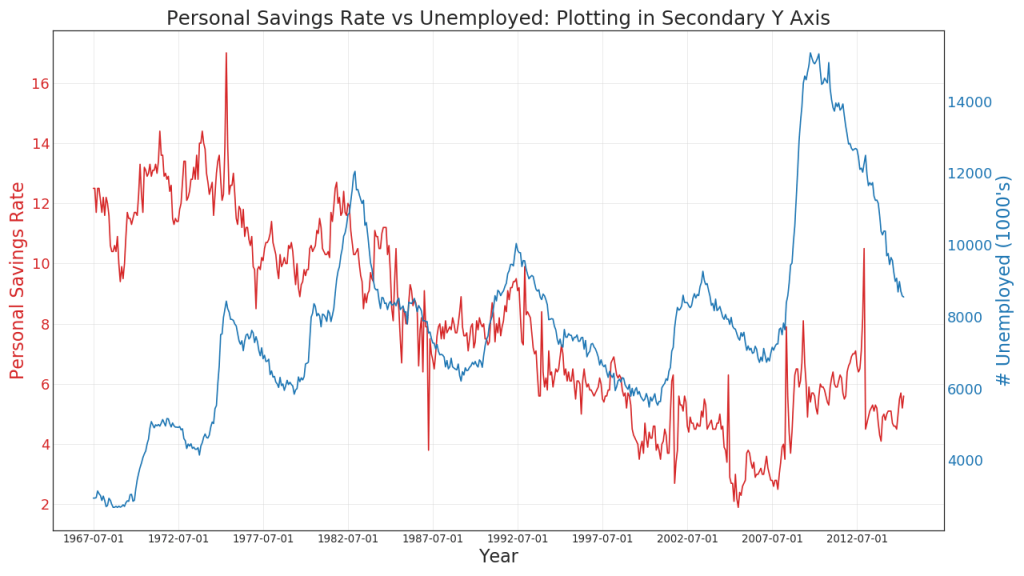
42. Rangkaian waktu dengan bilah kesalahan
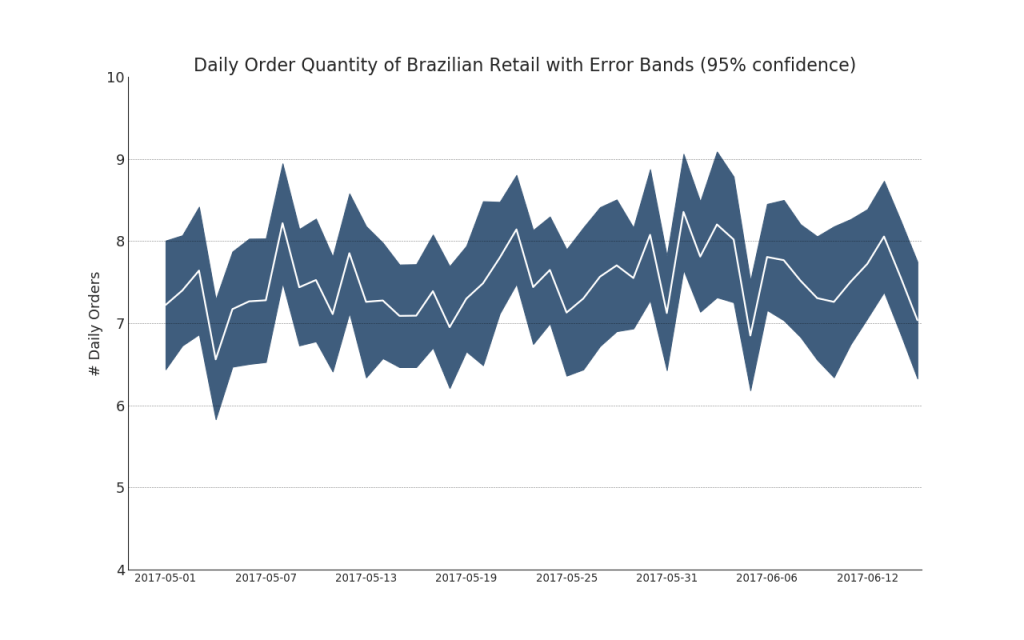
Rangkaian waktu dengan bilah kesalahan dapat dibangun jika Anda memiliki kumpulan data rangkaian waktu dengan beberapa pengamatan untuk setiap titik waktu (cap tanggal / waktu). Di bawah ini Anda dapat melihat beberapa contoh berdasarkan tanda terima pesanan pada waktu yang berbeda dalam sehari. Dan contoh lain dari jumlah pesanan yang diterima dalam waktu 45 hari.Dengan pendekatan ini, jumlah rata-rata pesanan ditunjukkan oleh garis putih. Dan interval 95% dihitung dan diplot di sekitar rata-rata.Tampilkan kode from scipy.stats import sem
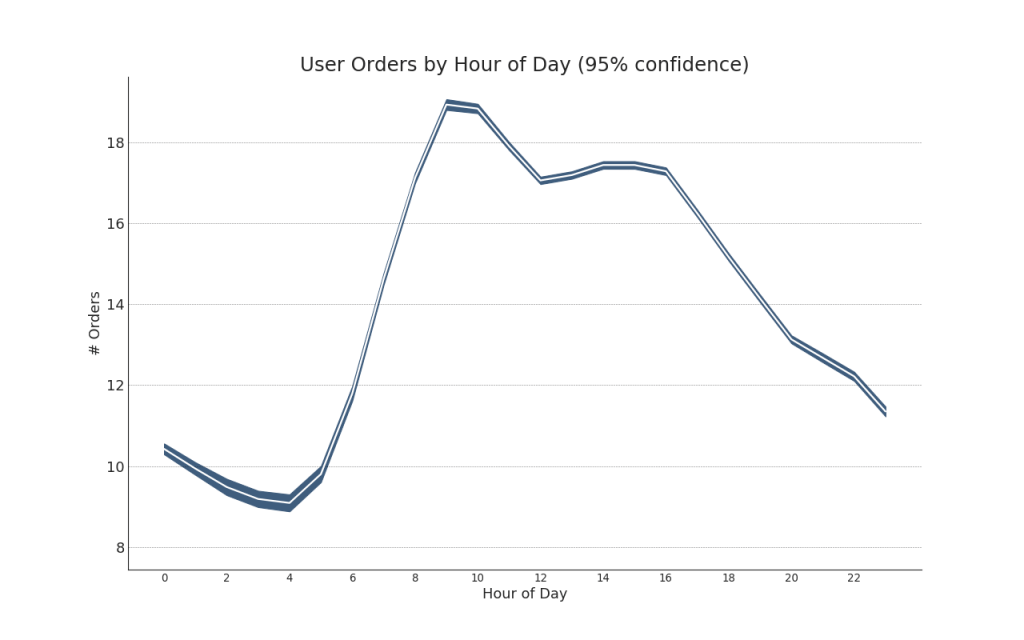
Tampilkan kode "Data Source: https://www.kaggle.com/olistbr/brazilian-ecommerce#olist_orders_dataset.csv" from dateutil.parser import parse from scipy.stats import sem
43. Bagan dengan akumulasi
Bagan area bertumpuk menyediakan representasi visual dari tingkat kontribusi dari beberapa seri waktu.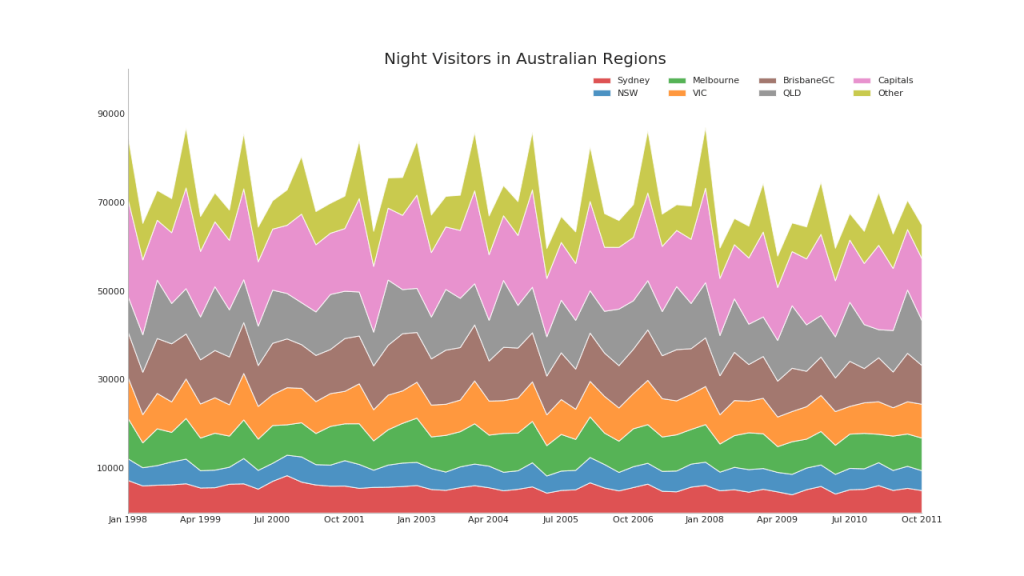
44. Bagan area tidak ditumpuk
Bagan area terbuka digunakan untuk memvisualisasikan kemajuan (naik turun) dari dua baris atau lebih relatif satu sama lain. Dalam diagram di bawah ini, Anda dapat dengan jelas melihat bagaimana tingkat tabungan pribadi berkurang dengan peningkatan durasi rata-rata pengangguran. Diagram dengan bagian terbuka menunjukkan fenomena ini dengan baik.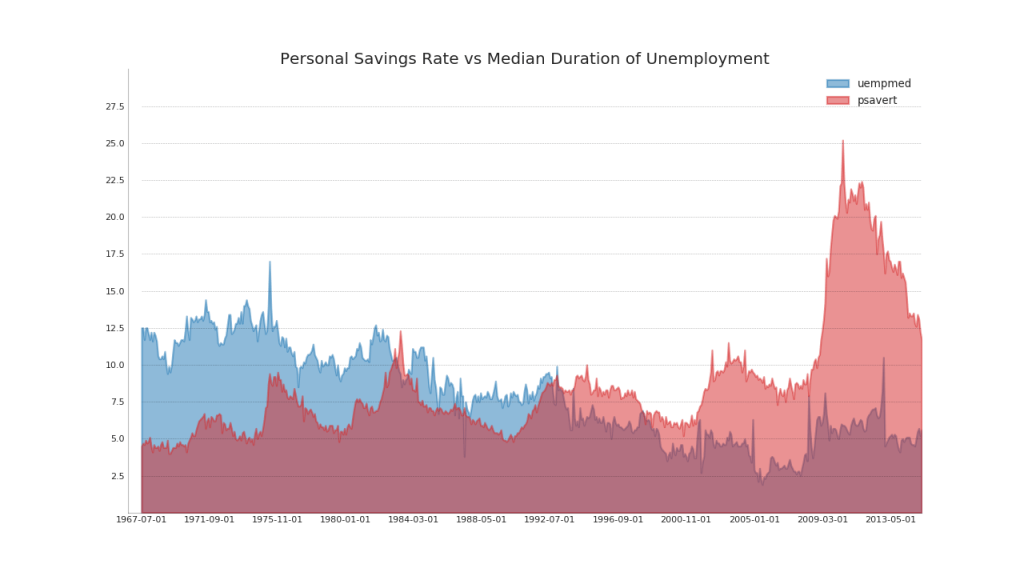
45. Peta panas kalender
Peta kalender adalah alternatif dan pilihan yang kurang disukai untuk memvisualisasikan data berdasarkan waktu dibandingkan dengan rangkaian waktu. Meskipun mereka mungkin menarik secara visual, nilai-nilai numeriknya tidak sepenuhnya jelas.Tampilkan kode import matplotlib as mpl import calmap

46. Grafik musiman
Jadwal musiman dapat digunakan untuk membandingkan seri waktu yang dilakukan pada hari yang sama di musim sebelumnya (tahun / bulan / minggu, dll.).Tampilkan kode from dateutil.parser import parse
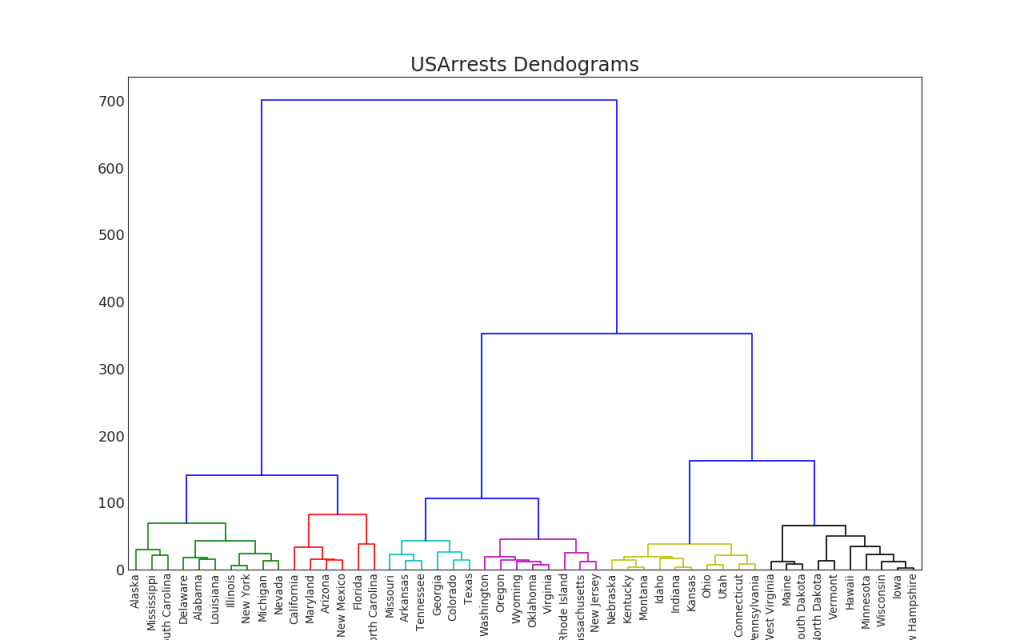
Grup
47. Dendrogram
Dendrogram mengelompokkan titik yang sama berdasarkan metrik jarak yang diberikan dan mengaturnya dalam bentuk tautan pohon berdasarkan kesamaan titik.Tampilkan kode import scipy.cluster.hierarchy as shc
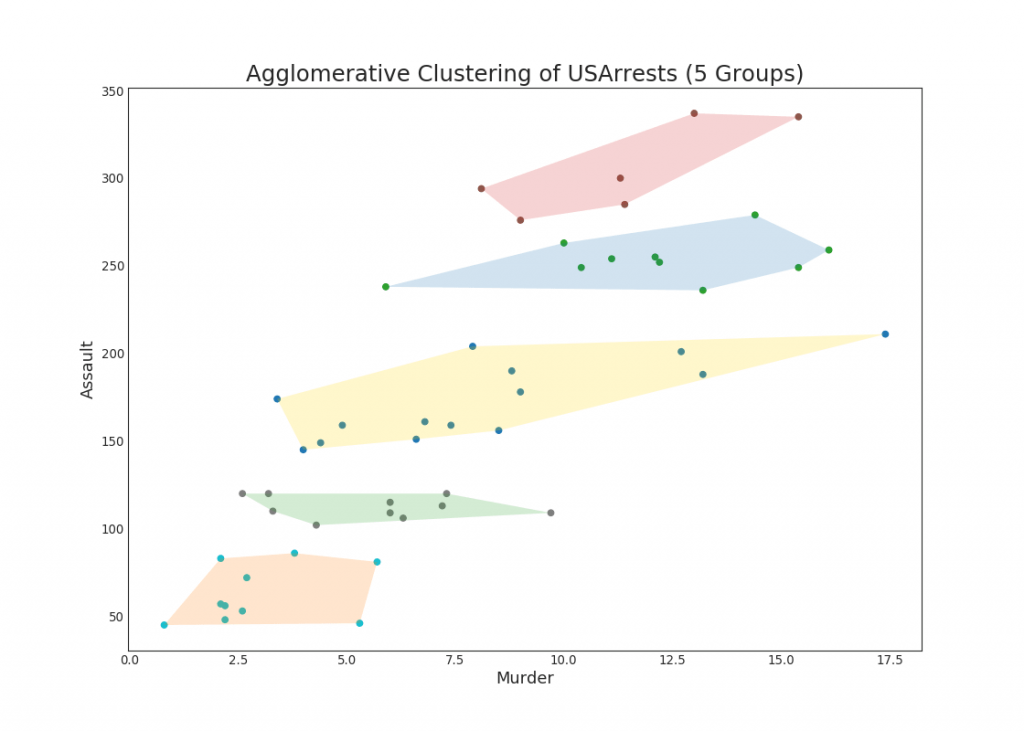
48. Diagram klaster
Grafik cluster dapat digunakan untuk membedakan titik-titik milik satu cluster. Berikut ini adalah contoh ilustratif dari pengelompokan negara bagian AS menjadi 5 kelompok berdasarkan pada dataset USArrests. Grafik kluster ini menggunakan kolom "bunuh" dan "serang" sebagai sumbu X dan Y. Atau, Anda dapat menggunakan komponen pertama hingga utama sebagai sumbu X dan Y.Tampilkan kode from sklearn.cluster import AgglomerativeClustering from scipy.spatial import ConvexHull
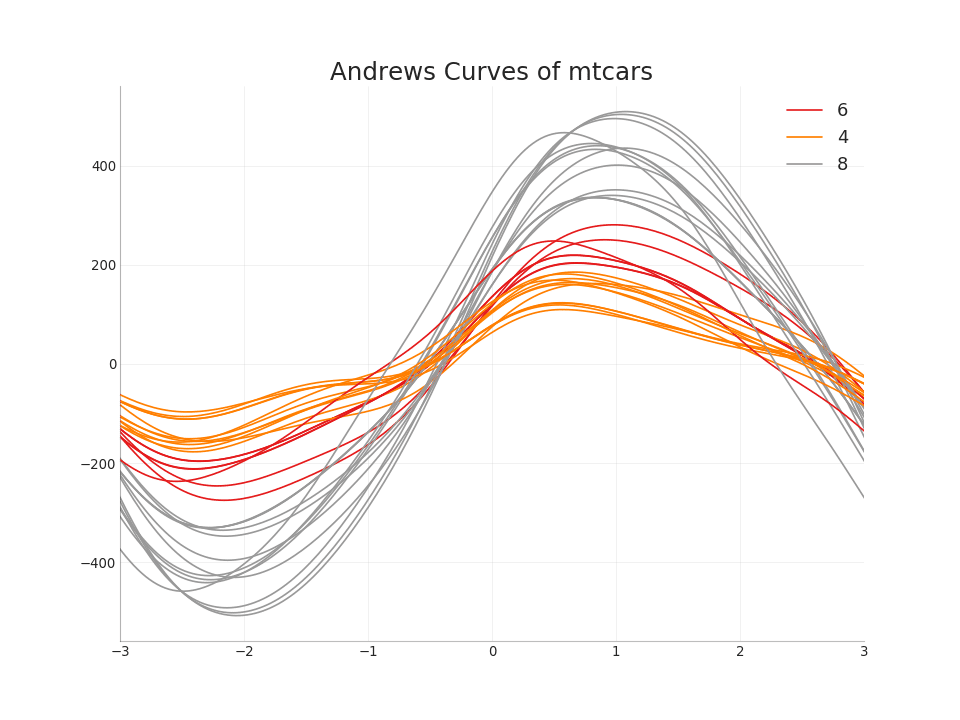
49. Kurva Andrews
Kurva Andrews membantu memvisualisasikan apakah fitur numerik yang melekat dalam pengelompokan ada berdasarkan pengelompokan yang diberikan. Jika objek (kolom dalam dataset) tidak membantu membedakan grup, maka garis tidak akan dipisahkan dengan baik, seperti yang ditunjukkan di bawah iniTampilkan kode from pandas.plotting import andrews_curves
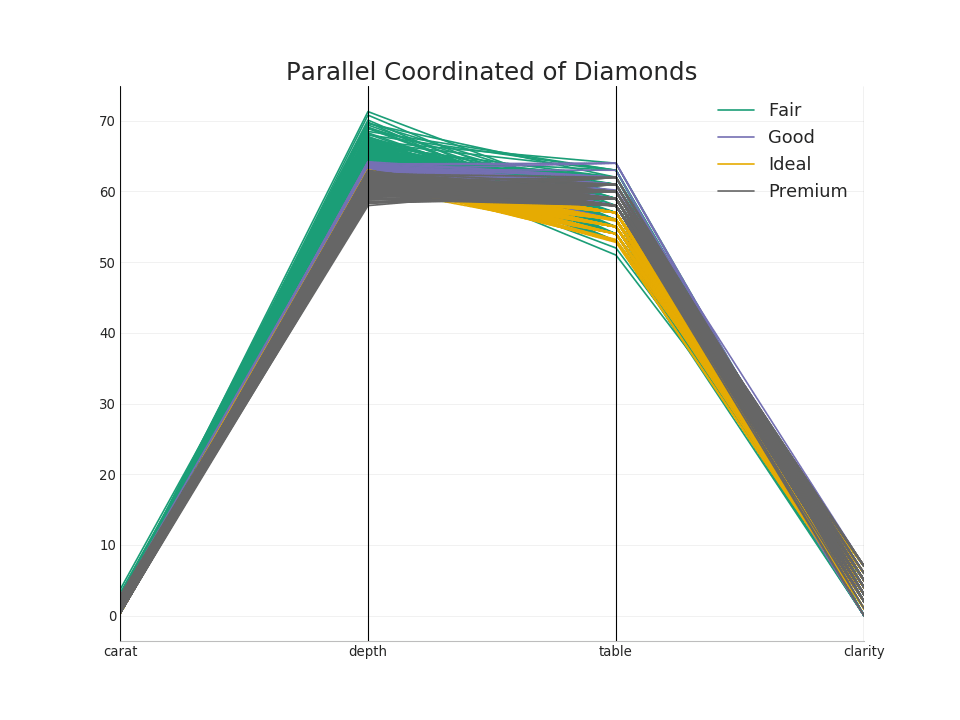
50. Koordinat paralel
Koordinat paralel membantu memvisualisasikan apakah suatu fungsi membantu memisahkan kelompok secara efektif. Jika pemisahan terjadi, fitur ini kemungkinan akan sangat berguna untuk memprediksi grup ini.Tampilkan kode from pandas.plotting import parallel_coordinates
 Kode bonus di Jupiter
Kode bonus di JupiterAngsa, Anda berjanji getaran!