Saat ini, kata "kecerdasan buatan" berarti banyak sistem yang berbeda - dari jaringan saraf untuk pengenalan gambar ke bot untuk bermain Quake. Wikipedia memberikan definisi yang luar biasa tentang AI - ini adalah "properti sistem cerdas untuk melakukan fungsi kreatif yang secara tradisional dianggap sebagai hak prerogatif manusia." Artinya, jelas terlihat dari definisi - jika fungsi tertentu berhasil diotomatisasi, maka tidak lagi dianggap kecerdasan buatan.
Namun, ketika tugas "menciptakan kecerdasan buatan" pertama kali ditetapkan, AI berarti sesuatu yang berbeda. Sasaran ini sekarang disebut AI Kuat atau AI Tujuan Umum.
Pernyataan masalah
Sekarang ada dua rumusan masalah yang terkenal. Yang pertama adalah AI Kuat. Yang kedua adalah AI tujuan umum (alias Kecerdasan Umum Buatan, disingkat AGI).
Pembaruan. Dalam komentar, mereka mengatakan kepada saya bahwa perbedaan ini lebih cenderung pada tingkat bahasa. Di Rusia, kata "intelijen" tidak berarti persis apa kata "kecerdasan" dalam bahasa Inggris
AI yang kuat adalah
AI hipotetis yang dapat melakukan segala hal yang dapat dilakukan seseorang. Biasanya disebutkan bahwa ia harus lulus tes Turing dalam pengaturan awal (hmm, apakah orang lulus?), Sadar akan dirinya sebagai orang yang terpisah dan dapat mencapai tujuannya.
Artinya, itu seperti orang buatan. Menurut pendapat saya, kegunaan AI semacam itu terutama adalah penelitian, karena definisi AI yang Kuat tidak mengatakan di mana pun tujuannya.
AGI atau AI tujuan umum adalah "mesin hasil." Dia menerima penetapan tujuan tertentu pada input - dan memberikan beberapa tindakan kontrol pada motor / laser / kartu jaringan / monitor. Dan tujuannya tercapai. Pada saat yang sama, AGI awalnya tidak memiliki pengetahuan tentang lingkungan - hanya sensor, aktuator dan saluran yang melaluinya ia menetapkan tujuan. Sistem manajemen akan dianggap sebagai AGI jika dapat mencapai tujuan apa pun di lingkungan apa pun. Kami menempatkannya untuk mengendarai mobil dan menghindari kecelakaan - dia akan menanganinya. Kami menempatkannya dalam kendali reaktor nuklir sehingga ada lebih banyak energi, tetapi tidak meledak - ia dapat mengatasinya. Kami akan memberikan kotak surat dan memerintahkan untuk menjual penyedot debu - juga akan mengatasinya. AGI adalah pemecah "masalah terbalik". Untuk memeriksa berapa banyak penyedot debu yang dijual adalah masalah sederhana. Tetapi untuk mengetahui bagaimana meyakinkan seseorang untuk membeli penyedot debu ini sudah merupakan tugas bagi intelek.
Pada artikel ini saya akan berbicara tentang AGI. Tidak ada tes Turing, tidak ada kesadaran diri, tidak ada kepribadian buatan - AI sangat pragmatis dan tidak ada operator pragmatis.
Keadaan saat ini
Sekarang ada kelas sistem seperti Reinforcement Learning, atau pembelajaran yang diperkuat. Ini seperti AGI, hanya tanpa fleksibilitas. Mereka mampu belajar, dan karena itu, mencapai tujuan di berbagai lingkungan. Tetapi mereka masih sangat jauh dari mencapai tujuan di lingkungan apa pun.
Secara umum, bagaimana sistem Pembelajaran Penguatan diatur dan apa masalahnya?
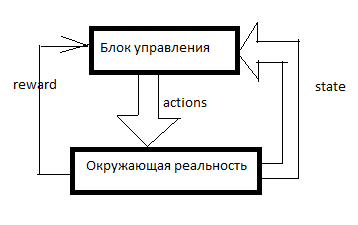
Setiap RL diatur seperti ini. Ada sistem kontrol, beberapa sinyal tentang realitas di sekitarnya memasukinya melalui sensor (keadaan) dan melalui badan-badan yang mengatur (tindakan) yang bekerja pada realitas di sekitarnya. Hadiah adalah sinyal penguatan. Dalam sistem RL, tulangan dibentuk dari luar unit kontrol dan ini menunjukkan seberapa baik AI mengatasi pencapaian tujuan. Berapa banyak penyedot debu yang terjual pada menit terakhir, misalnya.
Kemudian sebuah tabel terbentuk dari sesuatu seperti ini (saya akan menyebutnya tabel SAR):

Sumbu waktu diarahkan ke bawah. Tabel menunjukkan semua yang AI lakukan, semua yang dia lihat dan semua sinyal penguatan. Biasanya, agar RL melakukan sesuatu yang bermakna, ia pertama-tama perlu membuat gerakan acak untuk sementara waktu, atau melihat gerakan orang lain. Secara umum, RL dimulai ketika sudah ada setidaknya beberapa baris dalam tabel SAR.
Apa yang terjadi selanjutnya?
Sarsa
Bentuk paling sederhana dari pembelajaran penguatan.
Kami mengambil beberapa jenis model pembelajaran mesin dan, menggunakan kombinasi S dan A (status dan tindakan), kami memperkirakan total R untuk beberapa siklus clock berikutnya. Sebagai contoh, kita akan melihat bahwa (berdasarkan tabel di atas) jika Anda memberi tahu seorang wanita “jadilah seorang pria, belilah alat penyedot debu!”, Maka hadiahnya akan rendah, dan jika Anda mengatakan hal yang sama kepada seorang pria, maka tinggi.
Apa model spesifik yang dapat digunakan - saya akan jelaskan nanti, untuk saat ini saya hanya akan mengatakan bahwa ini bukan hanya jaringan saraf. Anda bisa menggunakan pohon keputusan atau bahkan mendefinisikan suatu fungsi dalam bentuk tabel.
Dan kemudian terjadi hal berikut. AI menerima pesan atau tautan lain ke klien lain. Semua data pelanggan dimasukkan ke AI dari luar - kami akan mempertimbangkan basis pelanggan dan penghitung pesan sebagai bagian dari sistem sensor. Artinya, tetap untuk menetapkan beberapa A (aksi) dan menunggu bala bantuan. AI mengambil semua tindakan yang mungkin dan pada gilirannya memprediksi (menggunakan model Machine Learning yang sama) - apa yang akan terjadi jika saya melakukan itu? Bagaimana jika itu? Dan berapa banyak penguatan untuk ini? Dan kemudian RL melakukan tindakan di mana hadiah maksimum diharapkan.
Saya memperkenalkan sistem yang sederhana dan canggung ke dalam salah satu permainan saya. SARSA mempekerjakan unit dalam game, dan beradaptasi jika terjadi perubahan aturan permainan.
Selain itu, dalam semua jenis pelatihan yang diperkuat, ada diskon hadiah dan dilema mengeksplorasi / mengeksploitasi.
Pemberian diskon adalah suatu pendekatan ketika RL mencoba untuk memaksimalkan bukan jumlah hadiah untuk gerakan N berikutnya, tetapi jumlah tertimbang menurut prinsip "100 rubel sekarang lebih baik daripada 110 dalam setahun". Misalnya, jika faktor diskonto adalah 0,9, dan horizon perencanaan adalah 3, maka kami akan melatih model bukan pada total R untuk 3 siklus jam berikutnya, tetapi pada R1 * 0,9 + R2 * 0,81 + R3 * 0,729. Mengapa ini perlu? Lalu, AI itu, menciptakan untung di suatu tempat di sana tanpa batas, kita tidak perlu. Kami membutuhkan AI yang menghasilkan keuntungan di sini dan sekarang.
Jelajahi / manfaatkan dilema. Jika RL melakukan apa yang dianggap optimal oleh modelnya, RL tidak akan pernah tahu apakah ada strategi yang lebih baik. Eksploitasi adalah strategi di mana RL melakukan apa yang menjanjikan imbalan maksimal. Jelajahi adalah strategi di mana RL melakukan sesuatu untuk mengeksplorasi lingkungan dalam mencari strategi yang lebih baik. Bagaimana cara menerapkan kecerdasan yang efektif? Misalnya, Anda dapat melakukan tindakan acak setiap beberapa langkah. Atau Anda dapat membuat tidak hanya satu model prediksi, tetapi beberapa model dengan pengaturan yang sedikit berbeda. Mereka akan menghasilkan hasil yang berbeda. Semakin besar perbedaannya, semakin besar tingkat ketidakpastian opsi ini. Anda dapat melakukan tindakan sehingga memiliki nilai maksimum: M + k * std, di mana M adalah perkiraan rata-rata semua model, std adalah standar deviasi perkiraan, dan k adalah koefisien keingintahuan.
Apa kerugiannya?Katakanlah kita memiliki opsi. Pergi ke tujuan (yang berjarak 10 km dari kami, dan jalan menuju itu bagus) dengan mobil atau berjalan kaki. Dan kemudian, setelah pilihan ini, kami memiliki opsi - bergerak dengan hati-hati atau mencoba menabrak setiap pilar.
Orang tersebut akan segera mengatakan bahwa biasanya lebih baik mengendarai mobil dan bersikap hati-hati.
Tapi SARSA ... Dia akan melihat keputusan apa yang akan diambil dengan mobil sebelumnya. Tapi itu mengarah ke ini. Pada tahap set statistik awal, AI melaju dengan ceroboh dan jatuh di suatu tempat dalam setengah kasus. Ya, dia bisa mengemudi dengan baik. Tetapi ketika dia memilih apakah akan pergi dengan mobil, dia tidak tahu apa yang akan dia pilih langkah selanjutnya. Dia memiliki statistik - kemudian dalam setengah kasus dia memilih opsi yang sesuai, dan dalam setengah bunuh diri. Karena itu, rata-rata, lebih baik berjalan.
SARSA percaya bahwa agen akan mematuhi strategi yang sama yang digunakan untuk mengisi tabel. Dan bertindak atas dasar ini. Tetapi bagaimana jika kita berasumsi sebaliknya - bahwa agen akan mematuhi strategi terbaik dalam langkah selanjutnya?
Q-learning
Model ini menghitung untuk setiap negara bagian, total hadiah maksimum yang dapat dicapai darinya. Dan dia menulisnya di kolom khusus Q. Artinya, jika dari negara S Anda bisa mendapatkan 2 poin atau 1, tergantung pada langkahnya, maka Q (S) akan sama dengan 2 (dengan kedalaman prediksi 1). Apa hadiah yang bisa diperoleh dari negara S, kita belajar dari model prediksi Y (S, A). (S-state, A-action).
Kemudian kita membuat model prediktif Q (S, A) - yaitu, keadaan Q yang akan terjadi jika kita melakukan tindakan A dari S. Dan membuat kolom berikutnya dalam tabel - Q2. Artinya, Q maksimum yang dapat diperoleh dari negara S (kami memilah-milah semua kemungkinan A).
Kemudian kita membuat model regresi Q3 (S, A) - yaitu, untuk keadaan dengan Q2 kita akan pergi jika kita melakukan tindakan A dari S.
Dan sebagainya. Dengan demikian, kami dapat mencapai kedalaman perkiraan yang tidak terbatas.
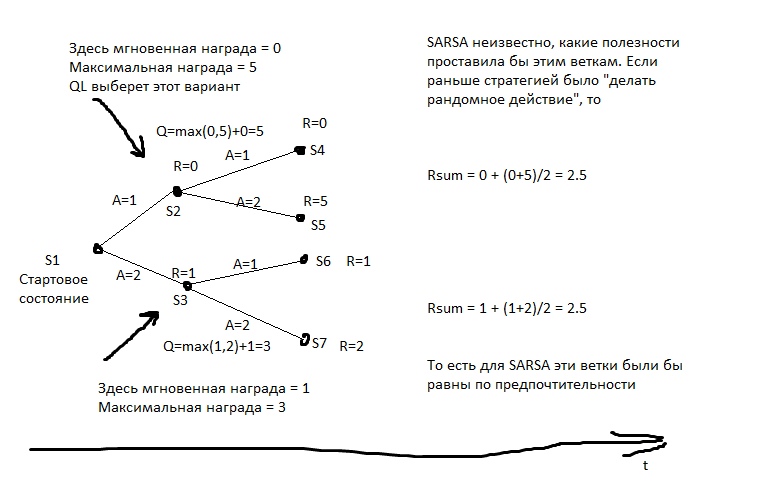
Dalam gambar, R adalah penguat.
Dan kemudian setiap langkah kita memilih tindakan yang menjanjikan Qn terhebat. Jika kita menerapkan algoritma ini ke catur, kita akan mendapatkan sesuatu seperti minimax yang ideal. Sesuatu yang hampir setara dengan kesalahan perhitungan bergerak ke kedalaman.
Contoh umum perilaku belajar-q. Pemburu memiliki tombak, dan dia pergi bersamanya ke beruang, atas inisiatifnya sendiri. Dia tahu bahwa sebagian besar langkahnya di masa depan memiliki hadiah negatif yang sangat besar (ada banyak cara untuk kalah daripada cara untuk menang), dia tahu bahwa ada gerakan dengan hadiah positif. Pemburu percaya bahwa di masa depan dia akan membuat gerakan terbaik (dan tidak diketahui yang seperti di SARSA), dan jika dia membuat gerakan terbaik, dia akan mengalahkan beruang itu. Artinya, untuk pergi ke beruang, sudah cukup baginya untuk dapat membuat setiap elemen yang diperlukan untuk berburu, tetapi tidak perlu memiliki pengalaman kesuksesan yang segera.
Jika pemburu bertindak dengan gaya SARSA, ia akan menganggap bahwa tindakannya di masa depan akan sama dengan sebelumnya (terlepas dari kenyataan bahwa ia sekarang memiliki bagasi pengetahuan yang berbeda), dan ia hanya akan pergi ke beruang jika ia sudah pergi ke beruang. dan dia menang, misalnya, dalam> 50% kasus (baik, atau jika pemburu lain menang di lebih dari setengah kasus, jika dia belajar dari pengalaman mereka).
Apa kerugiannya?- Model ini tidak mengatasi kenyataan yang terus berubah. Jika seumur hidup kita, kita telah diberikan penghargaan untuk menekan tombol merah, dan sekarang mereka menghukum kita, dan tidak ada perubahan yang terlihat telah terjadi ... QL akan menguasai pola ini untuk waktu yang sangat lama.
- Qn bisa menjadi fungsi yang sangat kompleks. Misalnya, untuk menghitungnya, Anda perlu menggulir siklus iterasi N - dan itu tidak akan berhasil lebih cepat. Model prediksi biasanya memiliki kompleksitas terbatas - bahkan jaringan saraf besar memiliki batas kompleksitas, dan hampir tidak ada model pembelajaran mesin yang dapat memutar siklus.
- Realitas biasanya memiliki variabel tersembunyi. Misalnya, jam berapa sekarang? Mudah untuk mengetahui apakah kita melihat arloji, tetapi segera setelah kita mengalihkan pandangan, ini sudah menjadi variabel tersembunyi. Untuk memperhitungkan nilai-nilai yang tidak dapat diobservasi ini, perlu bahwa model memperhitungkan tidak hanya keadaan saat ini, tetapi juga semacam sejarah. Di QL, Anda dapat melakukan ini - misalnya, untuk memberi makan tidak hanya S saat ini, tetapi juga beberapa yang sebelumnya ke dalam neuron-atau-apa-yang-kita-miliki di sana. Ini dilakukan di RL, yang memainkan game Atari. Selain itu, Anda dapat menggunakan jaringan saraf berulang untuk peramalan - biarkan berjalan secara berurutan pada beberapa frame sejarah dan menghitung Qn.
Sistem berbasis model
Tetapi bagaimana jika kita memprediksi tidak hanya R atau Q, tetapi umumnya semua data sensorik? Kami akan terus memiliki salinan realitas dan kami akan dapat memeriksa rencana kami di atasnya. Dalam hal ini, kami tidak terlalu khawatir tentang kesulitan menghitung fungsi-Q. Ya, ini membutuhkan banyak jam untuk menghitung - yah, jadi, untuk setiap rencana, kami akan berulang kali menjalankan model perkiraan. Merencanakan 10 langkah maju? Kami meluncurkan model 10 kali, dan setiap kali kami mengumpankan outputnya ke inputnya.
Apa kerugiannya?- Intensitas sumber daya. Misalkan kita perlu membuat pilihan dua alternatif pada setiap ukuran. Kemudian untuk 10 siklus clock kita akan memiliki 2 ^ 10 = 1024 rencana yang memungkinkan. Setiap rencana adalah 10 peluncuran model. Jika kita mengendalikan pesawat dengan lusinan badan pemerintahan? Dan apakah kita mensimulasikan kenyataan dengan periode 0,1 detik? Apakah Anda ingin memiliki horizon perencanaan setidaknya selama beberapa menit? Kami harus menjalankan model berkali-kali, ada banyak siklus clock prosesor untuk satu solusi. Bahkan jika Anda entah bagaimana mengoptimalkan enumerasi paket, semuanya sama, ada urutan perhitungan yang lebih besar daripada di QL.
- Masalah kekacauan. Beberapa sistem dirancang sehingga bahkan ketidakakuratan kecil dari simulasi input menyebabkan kesalahan output yang sangat besar. Untuk mengatasi ini, Anda dapat menjalankan beberapa simulasi realitas - sedikit berbeda. Mereka akan menghasilkan hasil yang sangat berbeda, dan dari sini akan mungkin untuk memahami bahwa kita berada dalam zona ketidakstabilan seperti itu.
Metode Pencacahan Strategi
Jika kami memiliki akses ke lingkungan pengujian AI, jika kami menjalankannya tidak dalam kenyataan, tetapi dalam simulasi, maka kami dapat menuliskan dalam beberapa bentuk strategi perilaku agen kami. Dan kemudian pilih - dengan evolusi atau sesuatu yang lain - strategi seperti itu yang menghasilkan keuntungan maksimum.
“Pilih strategi” berarti pertama-tama kita perlu belajar bagaimana menuliskan strategi sedemikian rupa sehingga dapat didorong ke dalam algoritma evolusi. Artinya, kita dapat menulis strategi dengan kode program, tetapi di beberapa tempat meninggalkan koefisien, dan biarkan evolusi mengambilnya. Atau kita dapat menuliskan strategi dengan jaringan saraf - dan biarkan evolusi mengambil bobot dari koneksinya.
Artinya, tidak ada perkiraan di sini. Tidak ada tabel SAR. Kami cukup memilih strategi, dan segera memberikan Tindakan.
Ini adalah metode yang kuat dan efektif, jika Anda ingin mencoba RL dan tidak tahu harus mulai dari mana, saya merekomendasikannya. Ini adalah cara yang sangat murah untuk "melihat keajaiban".
Apa kerugiannya?- Kemampuan untuk menjalankan eksperimen yang sama berkali-kali diperlukan. Artinya, kita harus dapat memutar ulang kenyataan ke titik awal - puluhan ribu kali. Untuk mencoba strategi baru.
Hidup jarang memberikan peluang seperti itu. Biasanya, jika kita memiliki model proses yang kita minati, kita tidak dapat membuat strategi yang licik - kita dapat dengan mudah menyusun rencana, seperti dalam pendekatan berbasis model, bahkan dengan kekuatan kasar yang tumpul. - Intoleransi terhadap pengalaman. Apakah kami memiliki tabel SAR selama bertahun-tahun pengalaman? Kita bisa melupakannya, itu tidak cocok dengan konsepnya.
Metode penghitungan strategi, tetapi "hidup"
Pencacahan strategi yang sama, tetapi pada kenyataan hidup. Kami mencoba 10 langkah dari satu strategi. Lalu 10 mengukur yang lain. Lalu 10 langkah ketiga. Lalu kami memilih yang mana ada lebih banyak penguatan.
Hasil terbaik untuk humanoids berjalan diperoleh dengan metode ini.

Bagi saya, ini kedengarannya agak tidak terduga - tampaknya pendekatan berbasis Model QL + secara matematis ideal. Tapi tidak ada yang seperti itu. Keuntungan dari pendekatan ini kurang lebih sama dengan yang sebelumnya - tetapi mereka kurang jelas, karena strategi tidak diuji sangat lama (well, kami tidak memiliki ribuan tahun pada evolusi), yang berarti bahwa hasilnya tidak stabil. Selain itu, jumlah tes juga tidak dapat diangkat hingga tak terbatas - yang berarti bahwa strategi harus dicari dalam ruang pilihan yang tidak terlalu rumit. Tidak hanya dia akan memiliki "pena" yang dapat "diputar". Nah, intoleransi pengalaman belum dibatalkan. Dan, dibandingkan dengan QL atau Berbasis Model, model ini menggunakan pengalaman secara tidak efisien. Mereka membutuhkan lebih banyak interaksi dengan kenyataan daripada pendekatan yang menggunakan pembelajaran mesin.
Seperti yang Anda lihat, setiap upaya untuk membuat AGI dalam teori harus mengandung pembelajaran mesin untuk memperkirakan penghargaan, atau beberapa bentuk notasi parametrik dari strategi - sehingga Anda dapat mengambil strategi ini dengan sesuatu seperti evolusi.
Ini adalah serangan yang kuat terhadap orang-orang yang menawarkan untuk membuat AI berdasarkan pada basis data, logika, dan grafik konseptual. Jika Anda, para pendukung pendekatan simbolik, baca ini - selamat datang di komentar, saya akan senang mengetahui apa yang bisa dilakukan AGI tanpa mekanisme yang dijelaskan di atas.
Model Pembelajaran Mesin untuk RL
Hampir semua model ML dapat digunakan untuk pembelajaran yang diperkuat. Jaringan saraf tentu saja bagus. Tetapi ada, misalnya, KNN. Untuk setiap pasangan S dan A, kami mencari yang paling mirip, tetapi di masa lalu. Dan kami mencari apa yang akan menjadi R. Bodoh setelah itu? Ya, tapi berhasil. Ada pohon yang menentukan - di sini lebih baik berjalan-jalan di kata kunci "meningkatkan gradien" dan "hutan yang menentukan." Apakah pohon miskin dalam menangkap ketergantungan kompleks? Gunakan pengerjaan fitur. Ingin AI Anda lebih dekat dengan Jenderal? Gunakan FE otomatis! Telusuri sekelompok formula berbeda, kirimkan sebagai fitur untuk meningkatkan Anda, buang formula yang meningkatkan kesalahan, dan tinggalkan formula yang meningkatkan akurasi. Kemudian kirimkan formula terbaik sebagai argumen untuk formula baru, dan seterusnya, berkembang.
Anda dapat menggunakan regresi simbolis untuk perkiraan - yaitu, cukup memilah rumus dalam upaya untuk mendapatkan sesuatu yang mendekati Q atau R. Mungkin untuk mencoba memilah algoritma - maka Anda mendapatkan sesuatu yang disebut induksi Solomonov, yang secara teoritis optimal, tetapi hampir sangat sulit untuk dilatih perkiraan fungsi.
Tetapi jaringan saraf biasanya kompromi antara ekspresif dan kompleksitas belajar. Regresi algoritmik idealnya mengambil ketergantungan apa pun - selama ratusan tahun. Pohon keputusan akan bekerja dengan sangat cepat - tetapi itu tidak akan dapat meramalkan y = a + b. Jaringan saraf adalah sesuatu di antaranya.
Prospek pengembangan
Apa cara untuk melakukan persis AGI sekarang? Setidaknya secara teoritis.
Evolusi
Kita dapat membuat banyak lingkungan uji yang berbeda dan memulai evolusi beberapa jaringan saraf.
Konfigurasi yang total skornya lebih banyak untuk semua uji coba akan berlipat ganda.Jaringan saraf harus memiliki memori dan akan diinginkan untuk memiliki setidaknya sebagian dari memori dalam bentuk kaset, seperti mesin Turing atau seperti pada hard disk.Masalahnya adalah bahwa dengan bantuan evolusi, Anda dapat menumbuhkan sesuatu seperti RL, tentu saja. Tetapi seperti apa seharusnya bahasa di mana RL terlihat kompak - sehingga evolusi menemukannya - dan pada saat yang sama evolusi tidak menemukan solusi seperti "tetapi saya akan membuat neuron untuk seratus lima puluh lapisan sehingga Anda semua mendapatkan kacang saat saya mengajarnya!" . Evolusi seperti kerumunan pengguna yang buta huruf - ia akan menemukan kekurangan dalam kode dan membuang seluruh sistem.Aixi
Anda dapat membuat sistem Berbasis Model berdasarkan pada paket banyak regresi algoritmik. Algoritma dijamin akan selesai Turing - yang berarti tidak akan ada pola yang tidak dapat diambil. Algoritma ini ditulis dalam kode - yang berarti bahwa kompleksitasnya dapat dengan mudah dihitung. Ini berarti bahwa secara matematis dimungkinkan untuk memperbaiki hipotesis Anda tentang perangkat dunia untuk kompleksitas. Dengan jaringan saraf, misalnya, trik ini tidak akan berhasil - di sana hukuman untuk kompleksitas sangat tidak langsung dan heuristik.Tetap hanya mempelajari cara cepat melatih regresi algoritmik. Sejauh ini, yang terbaik untuk ini adalah evolusi, dan itu sangat panjang.Benih AI
Akan lebih keren untuk membuat AI yang akan memperbaiki dirinya sendiri. Tingkatkan kemampuan Anda untuk memecahkan masalah. Ini mungkin tampak seperti ide yang aneh, tetapi masalah ini telah dipecahkan untuk sistem optimasi statis, seperti evolusi . Jika Anda berhasil menyadari hal ini ... Apakah segalanya tentang peserta pameran diketahui? Kami akan mendapatkan AI yang sangat kuat dalam waktu yang sangat singkat.Bagaimana cara melakukannya?Anda dapat mencoba mengatur bahwa di RL beberapa tindakan mempengaruhi pengaturan RL itu sendiri.Atau berikan beberapa alat kepada sistem RL untuk membuat sendiri prosesor pra dan pasca data. Biarkan RL menjadi bodoh, tetapi itu akan dapat membuat kalkulator, notebook, dan komputer untuk dirinya sendiri.Pilihan lain adalah membuat semacam AI menggunakan evolusi, di mana bagian dari tindakan akan mempengaruhi perangkatnya di tingkat kode.Tapi saat ini saya belum melihat opsi yang bisa diterapkan untuk Seed AI - meskipun sangat terbatas. Apakah pengembangnya bersembunyi? Atau apakah opsi-opsi ini begitu lemah sehingga mereka tidak layak mendapatkan perhatian umum dan melewatiku?Namun, sekarang Google dan DeepMind bekerja terutama dengan arsitektur jaringan saraf. Rupanya, mereka tidak ingin terlibat dalam pencacahan kombinatorial dan mencoba untuk membuat ide-ide mereka cocok untuk metode kembali menyebarkan kesalahan.Saya harap artikel ulasan ini bermanfaat =) Komentar diterima, terutama komentar seperti “Saya tahu bagaimana membuat AGI lebih baik”!