Sekitar setahun yang lalu, kolega saya dan saya ditugaskan memilah-milah menggunakan sistem pemantauan infrastruktur jaringan yang populer - Zabbix. Setelah mempelajari dokumentasi, kami segera melanjutkan untuk memuat pengujian: kami ingin mengevaluasi berapa banyak parameter Zabbix dapat bekerja tanpa penurunan kinerja yang nyata. Hanya PostgreSQL yang digunakan sebagai DBMS.
Selama pengujian, beberapa fitur arsitektur dari tata letak basis data dan perilaku sistem pemantauan itu sendiri diidentifikasi, yang secara default tidak memungkinkan sistem pemantauan untuk mencapai daya maksimumnya. Akibatnya, beberapa langkah optimasi dikembangkan, dilakukan, dan diuji terutama dalam hal menyetel basis data.
Saya ingin membagikan hasil pekerjaan yang dilakukan dalam artikel ini. Artikel ini akan berguna bagi administrator DBA Zabbix dan PostgreSQL, serta bagi semua orang yang ingin lebih memahami dan memahami DBMS PosgreSQL yang populer.
Spoiler kecil: pada mesin yang lemah dengan beban 200 ribu parameter per menit, kami berhasil mengurangi CPU iowait dari 20% menjadi 2%, mengurangi waktu perekaman dalam porsi menjadi tabel data primer sebanyak 250 kali dan tabel data teragregasi hingga 32 kali, mengurangi ukuran indeks 5-10 kali dan mempercepat penerimaan sampel historis dalam beberapa kasus hingga 18 kali.
Uji beban
Pengujian beban dilakukan sesuai dengan skema: satu server Zabbix, satu proksi Zabbix aktif, dua agen. Setiap agen dikonfigurasi untuk memberikan 50 ton integer dan 50 ton parameter string per menit (total 200 ton parameter per menit atau 3333 parameter per detik). Untuk menghasilkan parameter agen, kami menggunakan
plug-in untuk Zabbix. Untuk memeriksa berapa banyak parameter yang bisa dihasilkan oleh agen, Anda perlu menggunakan
skrip khusus dari pembuat plug-in yang sama zabbix_module_stress . Zabbix web-admin mengalami kesulitan mendaftarkan templat besar, jadi kami membagi parameter menjadi 20 templat dengan 5 ton parameter (2500 numerik dan 2500 string).
Template generator skrip untuk memuat pengujian dalam pythonimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
Metrik cpu iostat adalah indikator kinerja Zabbix yang baik - ini mencerminkan sebagian kecil dari satuan waktu selama prosesor menunggu akses disk. Semakin tinggi, semakin banyak disk ditempati dengan operasi baca dan tulis, yang secara tidak langsung mempengaruhi penurunan kinerja sistem pemantauan secara keseluruhan. Yaitu ini adalah pertanda pasti bahwa ada sesuatu yang salah dengan pemantauan. Ngomong-ngomong, di ruang terbuka jaringan, pertanyaan yang agak populer adalah "bagaimana menghapus pemicu iostat di Zabbix", jadi ini adalah titik pahit, karena ada banyak alasan untuk meningkatkan nilai metrik iowait.
Berikut adalah gambar untuk metrik cpu iowait yang kami dapatkan tiga hari kemudian pada awalnya:
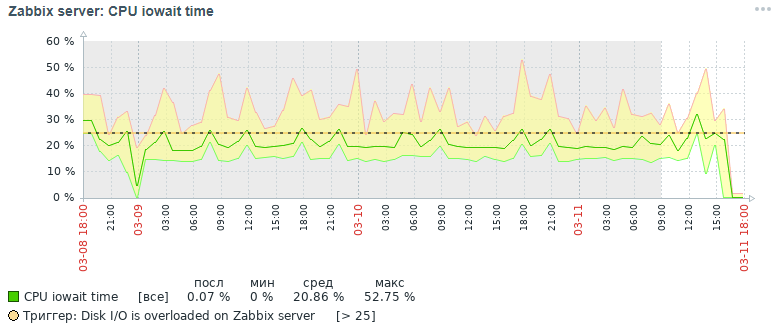
Namun gambaran apa untuk metrik yang sama yang juga kami dapatkan dalam tiga hari pada akhirnya setelah semua langkah optimasi yang telah dilakukan, yang akan dibahas di bawah:
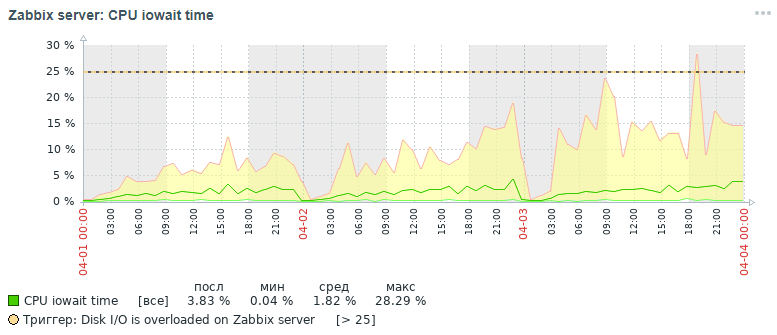
Seperti dapat dilihat dari grafik, indikator cpu iowait turun dari hampir 20% menjadi 2%, yang secara tidak langsung mempercepat waktu eksekusi semua permintaan untuk menambah dan membaca data. Sekarang mari kita lihat mengapa, dengan pengaturan basis data standar, kinerja keseluruhan sistem pemantauan turun dan bagaimana cara memperbaikinya.
Alasan untuk Penurunan Kinerja Zabbix
Dengan akumulasi lebih dari 10 juta nilai parameter di setiap tabel data primer, terlihat bahwa kinerja sistem pemantauan turun tajam, karena alasan berikut:
- metrik iowait untuk CPU server meningkat lebih dari 20%, yang menunjukkan peningkatan waktu selama CPU mengharapkan akses ke operasi baca dan tulis disk
- indeks tabel di mana data pemantauan sangat meningkat
- metrik pemanfaatan ditingkatkan menjadi 100% untuk disk dengan data pemantauan, yang menunjukkan muatan penuh disk dengan operasi baca dan tulis
- nilai-nilai usang tidak punya waktu untuk dihapus dari tabel sejarah saat membersihkan sesuai dengan jadwal pembantu rumah tangga
Situasi ini diperburuk pada awal setiap jam, ketika selain itu, statistik per jam agregat dihitung - pada saat yang sama, membaca dan menulis halaman indeks dari disk secara aktif, penghapusan data yang sudah ketinggalan zaman dari sejarah dilakukan, yang mengarah pada hasil yang sama - penurunan kinerja database dan peningkatan waktu eksekusi permintaan (dalam batas, permintaan yang bertahan hingga 5 menit telah dicatat!).
Sedikit bantuan dalam mengatur gudang data pemantauan di Zabbix. Ini menyimpan data primer dan data teragregasi dalam tabel yang berbeda, apalagi, dengan pemisahan jenis parameter. Setiap tabel menyimpan bidang itemid (referensi implisit ke item data terdaftar dalam sistem), cap waktu untuk mendaftarkan nilai jam dalam format cap waktu unix (milidetik dalam kolom terpisah) dan nilai dalam kolom terpisah (pengecualiannya adalah tabel log, memiliki lebih banyak bidang - seperti log peristiwa) ):
Kegiatan Optimasi
Untuk meningkatkan kinerja database PostgreSQL, berbagai langkah optimasi dilakukan, yang utamanya adalah mempartisi dan mengubah indeks. Namun, perlu disebutkan beberapa kata tentang beberapa langkah penting dan berguna yang dapat mempercepat pekerjaan setiap basis data di bawah sistem manajemen basis data PostgreSQL.
Catatan penting. Pada saat mengumpulkan materi artikel, kami menggunakan Zabbix versi 4.0, meskipun versi 4.2 telah dirilis dan versi 4.4 sedang disiapkan untuk rilis. Mengapa penting untuk menyebutkan ini? Karena mulai dari versi 4.2, Zabbix mulai mendukung ekstensi kuat khusus untuk bekerja dengan seri waktu TimescaleDB, tetapi sejauh ini dalam mode eksperimental: untuk semua keuntungan menggunakan ekstensi ini, diyakini bahwa beberapa permintaan mulai bekerja lebih lambat dan masih ada masalah kinerja yang belum terpecahkan (akan ada diselesaikan dalam versi 4.4) -
baca artikel ini .
Pada artikel selanjutnya saya berencana untuk menulis tentang hasil pengujian beban yang sudah menggunakan ekstensi TimescaleDB dibandingkan dengan kasus solusi ini. Versi PostgreSQL digunakan 10, tetapi semua informasi yang diberikan relevan untuk versi 11 dan 12 (kami menunggu!).
Karena itu, hal pertama yang pertama:
- mengatur file konfigurasi menggunakan utilitas pgtune
- menempatkan database ke disk fisik yang terpisah
- mempartisi tabel sejarah dengan pg_pathman
- mengubah tipe indeks tabel histori menjadi brin (clock) dan btree-gin (itemid)
- pengumpulan dan analisis statistik eksekusi permintaan pg_stat_statements
- mengatur parameter pemantauan disk fisik
- peningkatan kinerja perangkat keras
- pembuatan cluster terdistribusi (materi di luar lingkup artikel ini)
Mengkonfigurasi file konfigurasi menggunakan utilitas pgtune
Padahal, PostgreSQL adalah DBMS yang cukup ringan. File konfigurasi defaultnya dikonfigurasi sehingga, seperti kata rekan saya, "bahkan bekerja di mesin kopi", yaitu pada besi yang sangat sederhana. Oleh karena itu, perlu untuk mengonfigurasi PostgreSQL untuk konfigurasi server, dengan mempertimbangkan jumlah memori, jumlah prosesor, jenis tujuan penggunaan basis data, jenis disk (HDD atau SSD) dan jumlah koneksi.
Sayangnya, tidak ada formula tunggal untuk mengatur semua DBMS, tetapi ada aturan dan pola tertentu yang cocok untuk sebagian besar konfigurasi (penyetelan yang lebih halus sudah merupakan pekerjaan seorang ahli). Untuk menyederhanakan kehidupan DBA, utilitas
pgtune ditulis, yang dilengkapi oleh
versi web oleh
le0pard , penulis buku yang menarik dan bermanfaat tentang administrasi PostgreSQL.
Contoh menjalankan utilitas di konsol dengan 100 koneksi (Zabbix memiliki admin Web yang menuntut) untuk jenis aplikasi "Gudang data":
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Parameter konfigurasi yang utilitas pgtune berubah dengan deskripsi tujuan (nilai diberikan sebagai contoh) # Versi DB: 11
# Jenis OS: linux
# Jenis DB: web
# Total Memory (RAM): 8 GB
# CPU num: 1
# Koneksi num: 100
# Penyimpanan Data: hdd
max_connections = 100 # jumlah maksimum koneksi database bersamaan
shared_buffers = ukuran memori 2GB # untuk berbagai buffer (terutama cache blok tabel dan blok indeks) dalam memori bersama
effective_cache_size = 6GB # ukuran maksimum memori yang diperlukan untuk eksekusi permintaan menggunakan indeks
maintenance_work_mem = 512MB # memengaruhi kecepatan operasi VACUUM, ANALYZE, CREATE INDEX
checkpoint_completion_target = 0,7 # target waktu untuk menyelesaikan prosedur pos pemeriksaan
wal_buffers = 16 MB # jumlah memori yang digunakan oleh Memori Bersama untuk memelihara log transaksi
default_statistics_target = 100 # jumlah statistik yang dikumpulkan oleh perintah ANALYZE - ketika meningkat, optimizer membangun kueri lebih lambat, tetapi lebih baik
random_page_cost = 4 # biaya bersyarat dari akses indeks ke halaman data - memengaruhi keputusan untuk menggunakan indeks
effective_io_concurrency = 2 # jumlah operasi I / O asinkron yang akan dilakukan oleh DBMS dalam sesi terpisah
work_mem = 10485kB # jumlah memori yang digunakan untuk mengurutkan dan tabel hash sebelum menggunakan file sementara pada disk
min_wal_size = batas 1GB # di bawah jumlah file WAL yang akan didaur ulang untuk digunakan di masa mendatang
max_wal_size = batas 2GB # di atas jumlah file WAL yang akan didaur ulang untuk digunakan di masa mendatang
Beberapa opsi konfigurasi postgresql yang berguna # mengelola penangan permintaan bersamaan
max_worker_processes = 8 # jumlah maksimum proses latar belakang - setidaknya satu per basis data
max_parallel_workers_per_gather = 4 # jumlah maksimum proses paralel dalam satu permintaan
max_parallel_workers = 8 # jumlah maksimum proses kerja yang dapat didukung sistem untuk operasi paralel
# pengaturan logging (cara mudah untuk mengetahui tentang waktu eksekusi permintaan tanpa menggunakan ekstensi pg_stat_statements)
log_min_duration_statement = 3000 # tulis ke log, durasi pelaksanaan semua perintah yang waktu operasinya> = dari nilai yang ditentukan dalam ms
log_duration = off # catat durasi setiap perintah yang diselesaikan
log_statement = 'tidak ada' # yang perintah SQL untuk menulis ke log, nilai: tidak ada (dinonaktifkan), ddl, mod dan semua (semua perintah)
debug_print_plan = off # output dari pohon rencana kueri untuk analisis lebih lanjut
# peras maksimal dari database dan bersiaplah untuk kegagalan apa pun (untuk yang paling tertekan, yang mengabaikan keberadaan ssd dan gugus terdistribusi)
#fsync = off # tulis fisik ke disk perubahan, menonaktifkan fsync memberikan peningkatan kecepatan, tetapi dapat menyebabkan kegagalan permanen
#synchronous_commit = off # memungkinkan Anda untuk merespons klien bahkan sebelum informasi transaksi ada di WAL - sebuah alternatif yang hampir aman untuk menonaktifkan fsync
#full_page_writes = off # shutdown mempercepat operasi normal, tetapi dapat menyebabkan korupsi data atau korupsi data jika sistem macet
Daftar database pada disk fisik yang terpisah
Item ini opsional dan lebih merupakan solusi transisi untuk cluster terdistribusi lengkap, tetapi akan berguna untuk mengetahui tentang kemungkinan ini. Untuk mempercepat database, Anda bisa meletakkannya di disk terpisah. Kami memasang seluruh disk di direktori dasar, di mana semua database PostgreSQL disimpan, tetapi secara umum hal itu dapat dilakukan secara berbeda: membuat basis tabel baru dan mentransfer database (atau bahkan hanya sebagian darinya - tabel data pemantauan primer dan agregat) ke tablesbase ini pada disk terpisah.
Pasang contohPertama, Anda perlu memformat disk dengan sistem file ext4 dan menghubungkannya ke server. Pasang disk untuk database dengan label noatime:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
Untuk pemasangan permanen, tambahkan baris ke file / etc / fstab:
# di mana UUID adalah pengidentifikasi disk, Anda dapat melihatnya menggunakan utilitas blkid
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / base ext4 default, noatime 0 0
Mempartisi tabel sejarah dengan pg_pathman
Salah satu masalah yang kami temui selama pengujian stres Zabbix - PostgreSQL tidak berhasil menghapus data yang usang dari database. Menggunakan partisi, Anda dapat membagi tabel menjadi bagian-bagian penyusunnya, sehingga mengurangi ukuran indeks dan bagian-bagian penyusun tabel super, yang secara positif mempengaruhi kecepatan basis data secara keseluruhan.
Partisi memecahkan dua masalah sekaligus:
1. mempercepat penghapusan data yang usang dengan menghapus seluruh tabel
2. indeks pemisahan untuk setiap tabel komposit
Ada empat mekanisme untuk mempartisi di PostgreSQL:
1. constraint_exclusion standar
2. ekstensi pg_partman (
jangan bingung dengan pg_pathman )
3. ekstensi
pg_pathman4. secara manual membuat dan memelihara partisi sendiri
Solusi partisi yang paling nyaman, andal, dan optimal, menurut kami, adalah ekstensi
pg_pathman . Dengan metode partisi ini, perencana kueri secara fleksibel menentukan di mana partisi untuk mencari data.
Rumor mengatakan bahwa dalam versi 12 PostgreSQL akan ada partisi yang sangat baik sudah di luar kotak.Dengan demikian, kami mulai menulis data pemantauan untuk setiap hari dalam tabel yang diwarisi terpisah dari supertable dan penghapusan nilai parameter usang mulai terjadi melalui penghapusan semua tabel usang sekaligus, yang jauh lebih mudah untuk DBMS untuk biaya tenaga kerja. Penghapusan dilakukan dengan memanggil fungsi pengguna basis data sebagai parameter pemantauan server Zabbix pada jam 2 pagi dengan indikasi rentang penyimpanan statistik yang dapat diterima.
Instal dan konfigurasikan partisi untuk PostgreSQL 10Instal dan konfigurasikan ekstensi
pg_pathman dari repositori OS standar (untuk instruksi tentang cara membangun versi terbaru ekstensi dari sumber, lihat di repositori yang sama di github):
yum instal pg_pathman10
nano /var/pgsqldb/postgresql.conf
shared_preload_libraries = 'pg_pathman' # important - di sini tulis pg_pathman terakhir dalam daftar
Kami me-reboot DBMS, membuat ekstensi untuk database, dan mengkonfigurasi partisi (1 hari untuk data pemantauan utama dan 3 hari untuk data pemantauan agregat - ini dapat dilakukan selama 1 hari):
systemctl restart postgresql-10.service
psql -d zabbix -U postgres
BUAT EXTENSION pg_pathman;
# konfigurasikan satu hari untuk tabel data pemantauan utama
# 1552424400 - hitung mundur sebagai cap waktu unix, 86400 - detik dalam beberapa hari
pilih create_range_partitions ('history', 'clock', 1552424400, 86400);
pilih create_range_partitions ('history_uint', 'clock', 1552424400, 86400);
pilih create_range_partitions ('history_text', 'clock', 1552424400, 86400);
pilih create_range_partitions ('history_str', 'clock', 1552424400, 86400);
pilih create_range_partitions ('history_log', 'clock', 1552424400, 86400);
# konfigurasikan selama tiga hari untuk tabel data pemantauan teragregasi
# 1552424400 - hitung mundur sebagai cap waktu unix, 259200 - detik dalam tiga hari
pilih create_range_partitions ('tren', 'jam', 1545771600, 259200);
pilih create_range_partitions ('tren_uint', 'jam', 1545771600, 259200);
Jika belum ada data di salah satu tabel, maka saat memanggil fungsi create_range_partitions, satu argumen tambahan lagi p_count = 0_ harus dilewati.Pertanyaan yang berguna untuk memantau dan mengelola partisi:
# Daftar umum tabel yang dipartisi, penyimpanan konfigurasi utama:
pilih * dari pathman_config;
# representasi dengan semua bagian yang ada, serta orang tua dan batas jangkauan mereka:
pilih * dari pathman_partition_list;
# parameter tambahan yang menggantikan perilaku pg_pathman standar:
pilih * dari pathman_config_params;
# salin konten kembali ke tabel induk dan hapus partisi:
pilih drop_partitions ('table_name' :: regclass, false);
Skrip yang berguna untuk melihat statistik pada jumlah dan ukuran partisi:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
Setel otomatis untuk menghapus partisi usang (ahtung - fungsi SQL besar)Untuk mengkonfigurasi penghapusan otomatis partisi, Anda perlu membuat fungsi di database
(teks lebar, jadi saya harus menghapus penyorotan sintaks):
BUAT ATAU GANTI FUNGSI public.delete_old_partitions (integer history_days, integer trend_days, str_days integer)
RETURNS teks
Plpgsql BAHASA
AS $ fungsi $
/ *
Fungsi menghapus semua partisi yang lebih lama dari jumlah hari yang ditentukan:
history_days - untuk partisi history_x, history_uint_x
tren_hari - untuk partisi tren_x, tren_uint_x
str_days - untuk partisi history_str_x, history_text_x, history_log_x
* /
mendeklarasikan clock_today_start int;
mendeklarasikan clock_delete_less_history int = 0;
mendeklarasikan clock_delete_less_trends int = 0;
mendeklarasikan clock_delete_less_strings int = 0;
clock_delete_less int = 0;
mendeklarasikan iterator int = 0;
mendeklarasikan result_str text = '';
mendeklarasikan teks buf_table_size;
mendeklarasikan teks buf_table_len;
mendeklarasikan teks partisi_name;
mendeklarasikan teks clock_max;
mendeklarasikan err_detail teks;
mendeklarasikan t_start timestamp = clock_timestamp ();
mendeklarasikan cap waktu t_end;
mulai
jika $ 1 <= 0 lalu mengembalikan 'up, sesuatu yang salah: argumen history_days harus berupa nilai integer positif'; berakhir jika;
jika $ 2 <= 0 lalu mengembalikan 'up, sesuatu yang salah: argumen tren_days harus berupa nilai integer positif'; berakhir jika;
jika $ 3 <= 0 lalu mengembalikan 'up, sesuatu yang salah: argumen str_days harus berupa nilai integer positif'; berakhir jika;
clock_today_start = ekstrak (epoch from date_trunc ('day', now ())) :: int;
clock_delete_less_history = ekstrak (epoch from date_trunc ('day', now ()) - ($ 1 :: teks || 'days') :: interval) :: int;
clock_delete_less_trends = ekstrak (epoch from date_trunc ('day', now ()) - ($ 2 :: teks || 'days') :: interval) :: int;
clock_delete_less_strings = ekstrak (zaman dari date_trunc ('hari', sekarang ()) - ($ 3 :: teks || 'hari') :: interval) :: int;
clock_delete_less = sedikitnya (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings);
--meningkatkan pemberitahuan 'clock_today_start% (%)', to_timestamp (clock_today_start), clock_today_start;
--meningkatkan pemberitahuan 'clock_delete_less_history% (%)% days', to_timestamp (clock_delete_less_history), clock_delete_less_history, $ 1;
--meningkatkan pemberitahuan 'clock_delete_less_trends% (%)% days', to_timestamp (clock_delete_less_trends), clock_delete_less_trends, $ 2;
--meningkatkan pemberitahuan 'clock_delete_less_strings% (%)% days', to_timestamp (clock_delete_less_strings), clock_delete_less_strings, $ 3;
untuk partisi_name, clock_max di pilih partisi, range_max dari pathman_partition_list mana
range_max :: int <= terhebat (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings) dan
(partisi :: teks seperti 'history%' atau partisi :: teks seperti 'tren%') dipesan oleh partisi asc
lingkaran
if (partisi_name ~ 'history_uint_ \ d' dan clock_max :: int <= clock_delete_less_history)
atau (partisi_name ~ 'history_ \ d' dan clock_max :: int <= clock_delete_less_history)
atau (partisi_name ~ 'tren_ \ d' dan clock_max :: int <= clock_delete_less_trends)
atau (partisi_name ~ 'history_log_ \ d' dan clock_max :: int <= clock_delete_less_strings)
atau (partisi_name ~ 'history_str_ \ d' dan clock_max :: int <= clock_delete_less_strings)
atau (partisi_name ~ 'history_text_ \ d' dan clock_max :: int <= clock_delete_less_strings)
lalu
iterator = iterator +1;
naikkan pemberitahuan '%', format ('!!! delete% s% s', partisi_name, clock_max);
pilih max (reltuples :: int), pg_size_pretty (jumlah (pg_relation_size (pg_class.oid)))) sebagai "size" dari pg_class di mana relname seperti partisi_name || '%' menjadi buf_table_len ketat, buf_table_size;
jika result_str! = '' maka result_str = result_str || ','; berakhir jika;
result_str = result_str || format ('% s (dt <% s, len% s,% s)', partisi_name, to_char (to_timestamp (clock_max :: int), 'YYYY-MM-DD'), buf_table_len, buf_table_size);
jalankan format ('drop table jika ada% s', partisi_name);
berakhir jika;
loop akhir;
jika iterator = 0 lalu result_str = format ('tidak ada partisi untuk dihapus yang lebih lama, lalu% s date', to_char (to_timestamp (clock_delete_less), 'YYYY-MM-DD'));
else result_str = format ('dihapus% s partisi dalam% s detik:', iterator, trunc (ekstrak (detik dari (clock_timestamp () - t_start)) :: numeric, 3)) || result_str;
berakhir jika;
--menaikkan pemberitahuan '%', result_str;
return result_str;
pengecualian saat orang lain saat itu
dapatkan diagnosa bertumpuk err_detail = PG_EXCEPTION_CONTEXT;
format pengembalian ('ups, ada yang salah:% s [kode err% s],% s', sqlerrm, sqlstate, err_detail);
akhir;
$ function $;
Untuk secara otomatis memanggil fungsi partisi pembersihan-otomatis, Anda perlu membuat satu item data untuk host server zabbix dari tipe "Database Monitor" dengan pengaturan berikut:
- ketik: monitor basis data
- name: delete_old_history_partitions
- key: db.odbc.select [delete_old_history_partitions, zabbix]
- ekspresi sql: pilih delete_old_partitions (3, 30, 30);
# di sini, parameter panggilan fungsi delete_old_partitions menunjukkan waktu penyimpanan dalam beberapa hari
# untuk nilai numerik, nilai numerik teragregasi, dan nilai string
- tipe data: Teks
- interval pembaruan: 0
- Interval pengguna: dijadwalkan dalam h2
- periode penyimpanan riwayat: 90 hari
- grup elemen data: Database
Sebagai hasilnya, kami akan memperoleh statistik tentang pembersihan partisi dari jenis ini:
2019-09-16 02:00:00, menghapus 3 partisi dalam 0,024 detik: tren_78 (dt <2019-08-17, len 1, 48 kB), history_193 (dt <2019-09-13, len 85343, 9448 kB ), history_uint_186 (dt <2019-09-13, len 27969, 3480 kB)
Penting! Setelah mengatur penghapusan otomatis partisi melalui elemen data dan fungsi pengguna, Anda perlu mematikan riwayat dan tren pembersihan dalam penjadwal tugas pembantu rumah tangga Zabbix:
melalui item menu zabbix, pilih "Administrasi" -> "Umum" -> pilih "Hapus riwayat" dari daftar di sudut -> nonaktifkan semua kotak centang di bagian "Sejarah" dan "Dinamika perubahan". Mengubah tipe indeks dari tabel histori menjadi brin (clock) dan btree-gin (itemid)
Terima kasih khusus kepada
erogov untuk
serangkaian artikel ikhtisar yang luar biasa tentang indeks PostgreSQL .
Dan memang seluruh tim PostgresPRO. .
, btree(itemid, clock) — , , «» , — 10 .
, , .Selama pengujian berbagai indeks, kombinasi indeks yang paling berhasil terungkap: indeks brin pada bidang jam dan indeks btree-gin pada bidang itemid untuk semua tabel data pemantauan.Indeks brin sangat ideal untuk meningkatkan data secara monoton, seperti cap waktu fakta acara, yaitu untuk deret waktu. Dan indeks btree-gin pada dasarnya adalah indeks gin dibandingkan tipe data standar, yang umumnya jauh lebih cepat daripada indeks btree klasik karena Indeks gin tidak dibangun kembali selama penambahan nilai baru, tetapi hanya ditambah oleh mereka. Indeks btree-gin dimasukkan sebagai ekstensi ke PostgreSQL.Perbandingan kecepatan pengambilan sampel untuk strategi pengindeksan ini dan untuk indeks dalam database Zabbix secara default diberikan di bawah ini. Selama pengujian beban, kami mengumpulkan data selama tiga hari untuk tiga partisi:Tiga jenis pertanyaan dilakukan untuk mengevaluasi hasil:- untuk satu itemid parameter tertentu, data untuk bulan lalu, bahkan tiga hari terakhir (total 1660 catatan)
jelaskan analisis pilih * dari history_uint di mana itemid = 313300
dan jam> = ekstrak (zaman dari '2019-03-09 00:00:00' :: timestamp) :: int
dan jam <= ekstrak (zaman dari '2019-04-09 12:00:00' :: timestamp) :: int;
- untuk satu data parameter spesifik selama 12 jam sehari (total 649 entri)
jelaskan analisis pilih * dari history_text di mana itemid = 310650
dan jam> = ekstrak (zaman dari '2019-04-09 00:00:00' :: timestamp) :: int
dan jam <= ekstrak (zaman dari '2019-04-09 12:00:00' :: timestamp) :: int;
- untuk satu data parameter khusus selama satu jam (total 61 catatan):
jelaskan analisa pilih count (*) dari history_text di mana itemid = 336540
dan jam> = ekstrak (zaman dari '2019-04-08 11:00:00' :: timestamp) :: int
dan jam <= ekstrak (zaman dari '2019-04-08 12:00:00' :: timestamp) :: int;
Hasil tes ditabulasi di bawah ini:* ukuran dalam MB ditunjukkan total untuk tiga partisi** permintaan tipe 1 - data selama 3 hari, permintaan tipe 2 - data selama 12 jam, permintaan tipe 3 - data selama satu jamDari tabel perbandingan dapat dilihat bahwa untuk tabel data besar dengan jumlah catatan lebih dari 100 juta, jelas terlihat bahwa mengubah indeks komposit standar btree menjadi dua indeks brin dan btree-gin memiliki efek menguntungkan pada pengurangan ukuran indeks dan mempercepat waktu eksekusi permintaan.Efisiensi pengindeksan dan partisi ditunjukkan di bawah ini pada contoh permintaan untuk menambahkan catatan baru ke tabel history_uint dan tren_uint (penambahan terjadi pada rata-rata nilai 2000 per kueri).Meringkas hasil pengujian berbagai konfigurasi indeks untuk tabel data pemantauan sistem zabbix, kita dapat mengatakan bahwa perubahan serupa dalam indeks standar untuk tabel data pemantauan zabbix secara positif mempengaruhi kinerja sistem secara keseluruhan, yang paling terasa ketika volume data lebih dari 10 juta diakumulasikan. Anda harus melupakan tentang efek tidak langsung dari "pembengkakan" dari indeks btree standar secara default - sering membangun kembali indeks multi-gigabyte menyebabkan beban besar pada hard disk (utiliz metric ation), yang pada akhirnya meningkatkan waktu operasi disk dan waktu untuk menunggu akses ke disk dari CPU (iowait metric).Tapi agar indeks btree-gin dapat bekerja dengan tipe data bigint (in8), yang merupakan kolom itemid, Anda perlu mendaftarkan keluarga operator tipe bigint untuk indeks btree-gin.Mendaftarkan keluarga operator bigint untuk indeks btree-gin/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
Skrip ini mendistribusikan ulang semua indeks dalam database PostgreSQL untuk Zabbix dari konfigurasi default ke konfigurasi optimal yang dijelaskan di atas./*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
Untuk indeks brin untuk volume data kami pada intensitas 100 ton parameter per menit (100 ton dalam sejarah dan 100 ton dalam history_uint), terlihat bahwa indeks bekerja pada tabel data pemantauan primer dengan ukuran zona 512 halaman dua kali lebih cepat dibandingkan dengan ukuran standar 128 halaman, tetapi ini bersifat individual dan tergantung pada ukuran tabel dan konfigurasi server. Bagaimanapun, indeks brin membutuhkan ruang yang sangat kecil, tetapi kecepatannya dapat sedikit ditingkatkan dengan memperbaiki ukuran zona, tetapi dengan ketentuan bahwa laju aliran data tidak banyak berubah.Akibatnya, perlu dicatat bahwa ada batasan yang terkait dengan arsitektur Zabbix itu sendiri: pada tab "Data terbaru", dua nilai terakhir dikumpulkan untuk setiap parameter, dengan mempertimbangkan pemfilteran akun. Untuk setiap parameter, nilai diminta dalam database secara terpisah. Oleh karena itu, semakin banyak parameter yang dipilih, semakin lama kueri akan berjalan. Data terbaru dicari ketika indeks btree (itemid, clock desc) diatur pada tabel sejarah dengan penyortiran terbalik berdasarkan waktu, tetapi indeks itu sendiri tentu saja "membengkak" pada disk dan umumnya secara tidak langsung memperlambat database, yang menyebabkan masalah, dijelaskan di atas.Karena itu, ada tiga jalan keluar:- « » 100 (.. , « » )
- Zabbix , , « »
- biarkan indeks sebagaimana adanya secara default, dan batasi diri kita hanya untuk mempartisi hanya untuk mendapatkan pilihan yang cukup besar pada tab Data Terbaru pada saat yang sama untuk berbagai parameter (namun, diketahui bahwa server web Zabbix masih memiliki batasan pada jumlah nilai parameter yang ditampilkan secara bersamaan pada tab "Data Terbaru" - jadi, ketika saya mencoba menampilkan 5.000 nilai, database menghitung hasilnya, tetapi server tidak dapat menyiapkan halaman web dan menampilkan data dalam jumlah besar).
Pengumpulan dan analisis statistik eksekusi permintaan pg_stat_statements
Pg_stat_statements adalah ekstensi untuk mengumpulkan statistik tentang kinerja kueri di seluruh server. Keuntungan dari ekstensi ini adalah tidak perlu mengumpulkan dan mengurai log PostgreSQL.Menggunakan Ekstensi pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
Untuk memantau hard drive di Zabbix, hanya parameter vfs.dev.read dan vfs.dev.write yang disediakan di luar kotak. Opsi ini tidak memberikan informasi tentang pemanfaatan disk. Kriteria yang berguna untuk menemukan masalah dengan kinerja hard drive Anda adalah tingkat pemanfaatan utilisasi, menunggu waktu eksekusi permintaan, dan beban antrian permintaan ke disk.Sebagai aturan, beban disk yang tinggi berkorelasi dengan iowait tinggi cpu itu sendiri dan dengan peningkatan waktu eksekusi kueri sql, yang ditemukan selama pengujian stres server zabbix dengan konfigurasi standar tanpa partisi dan tanpa menyiapkan indeks alternatif. Anda dapat menambahkan parameter ini untuk memantau hard drive menggunakan langkah-langkah berikut, yang mengintip dalam sebuah artikel dari seorang temanlesovsky dan ditingkatkan: sekarang parameter iostat dikumpulkan secara terpisah untuk setiap disk dalam parameter waktu json, dari mana, menurut pengaturan pasca-pemrosesan, mereka sudah didekomposisi menjadi parameter pemantauan akhir.Sementara permintaan Tarik sedang menunggu, Anda dapat mencoba memperluas pemantauan parameter disk sesuai dengan instruksi terperinci melalui garpu saya .Setelah semua tindakan yang dijelaskan, Anda dapat menambahkan grafik khusus dengan iowait cpu dan parameter utilisasi ke disk sistem dan disk dari basis data (jika berbeda) di panel pemantauan server Zabbix utama Hasilnya mungkin terlihat seperti ini (sda adalah disk utama, sdc adalah disk dengan database):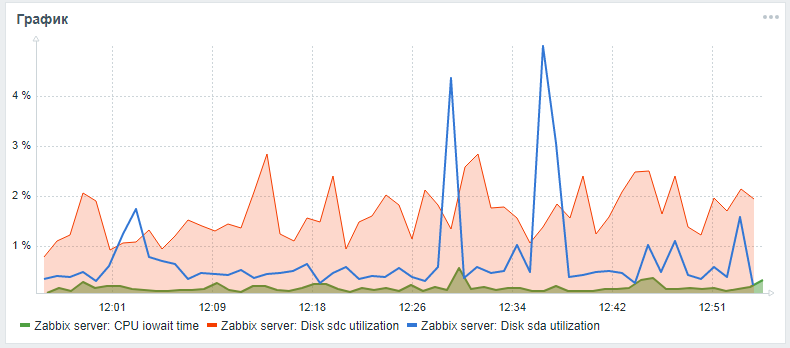
Peningkatan Kinerja Perangkat Keras
Setelah mengatur DBMS, pengindeksan dan pemartisian, Anda dapat melanjutkan ke penskalaan vertikal - untuk meningkatkan karakteristik perangkat keras server: tambahkan RAM, ubah drive menjadi solid-state dan tambahkan core prosesor. Ini adalah peningkatan kinerja yang dijamin, tetapi lebih baik melakukan ini hanya setelah optimasi perangkat lunak.Membuat Cluster Terdistribusi
Setelah penskalaan vertikal moderat, Anda harus mulai horisontal - membuat cluster terdistribusi: baik shard atau replikasi master slave. Tapi ini adalah topik dan materi yang terpisah dari artikel yang terpisah (bagaimana membentuk sekelompok kotoran dan tongkat) , serta perbandingan teknik optimasi basis data Zabbix yang dijelaskan di atas menggunakan pg_pathman dan pengindeksan dengan metode penerapan ekstensi TimescaleDB.Sementara itu, masih diharapkan bahwa materi dalam artikel ini bermanfaat dan informatif!