Bagaimana mengetahui dengan pasti apa yang ada di dalam sanggul itu?
Mungkin Anda menelannya, dan di dalamnya ada sungai? © Tanya Zadorozhnaya
Apa itu Ilmu Data saat ini, tampaknya, tidak hanya anak-anak, tetapi juga hewan peliharaan yang tahu. Tanyakan kucing mana pun, dan ia akan berkata: statistik, Python, R, BigData, pembelajaran mesin, visualisasi, dan banyak kata lainnya, tergantung pada kualifikasi. Tetapi tidak semua kucing, serta mereka yang ingin menjadi spesialis dalam Ilmu Data, tahu persis bagaimana proyek Ilmu Data terstruktur, tahapan apa yang terdiri dari dan bagaimana masing-masing memengaruhi hasil akhir, seberapa intensif sumber daya setiap tahap proyek. Metodologi biasanya digunakan untuk menjawab pertanyaan-pertanyaan ini. Namun, sebagian besar kursus pelatihan yang ditujukan untuk Ilmu Data tidak mengatakan apa-apa tentang metodologi, tetapi hanya lebih atau kurang secara konsisten mengungkapkan esensi dari teknologi yang disebutkan di atas, dan setiap pemula Ilmuwan Data dapat mengetahui struktur proyek dari pengalamannya sendiri (dan menyapu). Tetapi secara pribadi, saya suka pergi ke hutan dengan peta dan kompas, dan saya suka membayangkan sebelumnya rencana rute yang Anda pindahkan. Setelah beberapa pencarian, saya berhasil menemukan metodologi yang baik dari IBM, produsen panduan dan metode yang terkenal untuk mengelola apa pun.
Jadi, dalam proyek Ilmu Data, ada 3 blok 3 tahap di masing-masing, total 9 tahap. Singkatnya, proyek terdiri dari bekerja dengan persyaratan bisnis, data, dan model itu sendiri.
Bekerja dengan persyaratan bisnis
Pada langkah ini, kita tidak tahu apa-apa tentang data apa yang kita miliki. Kita harus mempelajari pernyataan masalah, memahami hasil apa yang diperlukan untuk mendapatkan dari proyek, mempelajari semua tentang peserta dan pemangku kepentingan. Selanjutnya, sesuai dengan tugas tertentu, kita harus memutuskan dengan metode apa masalah akan dipecahkan. Hasil dari langkah ini adalah persyaratan data: ok, tugasnya jelas, metode telah dipilih, sekarang kita akan berpikir tentang apa yang mungkin kita butuhkan untuk solusi yang berhasil?
Bekerja dengan data
Pada langkah kedua, kami mulai mencari data untuk menyelesaikan masalah: kami mencari tahu sumber mana yang tersedia bagi kami, dan membentuk sampel yang akan terus kami gunakan untuk bekerja. Setelah data dikumpulkan, perlu untuk melakukan serangkaian penelitian untuk lebih memahami bagaimana sampel diorganisasikan: untuk menyelidiki posisi sentral dan variabilitas, untuk mengidentifikasi korelasi antara fitur, dan untuk membangun grafik distribusi. Setelah tahap ini, Anda dapat mulai menyiapkan data. Sebagai aturan, tahap ini adalah yang paling padat karya dan dapat memakan waktu hingga 90% dari seluruh waktu proyek, tetapi keberhasilan seluruh proyek tergantung pada seberapa baik penyelesaiannya.
Pengembangan dan implementasi
Akhirnya, langkah ketiga. Setelah data siap, Anda dapat melanjutkan dengan pengembangan dan implementasi yang sebenarnya. Kami memprogram model, mengaturnya pada sampel pelatihan, memeriksanya pada pengujian, jika hasilnya memuaskan, kemudian menunjukkannya kepada pelanggan, menerapkannya, mengumpulkan umpan balik dan ... Anda dapat memulai dari awal lagi.
Seluruh proses disajikan dalam bentuk lingkaran setan: dengan cara yang baik, proyek DS tidak pernah dapat dianggap selesai (kira-kira, seperti perbaikan, yang, seperti yang Anda tahu, tidak dapat diselesaikan, tetapi hanya dapat dihentikan):
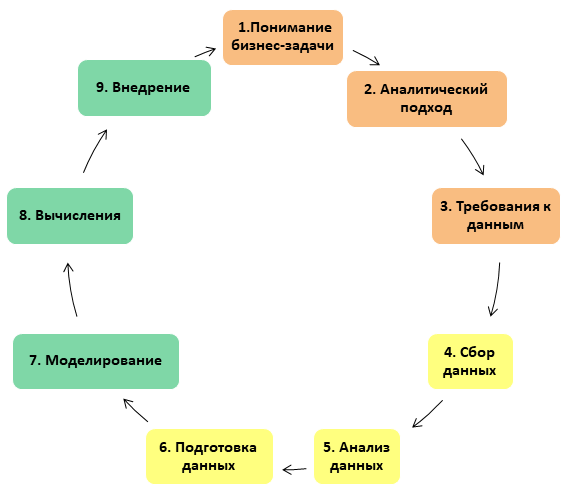
Mari kita bahas lebih detail pada setiap tahapan.
1. Memahami tantangan bisnis
Tahap ini adalah dasar untuk semua pekerjaan selanjutnya: tanpanya Anda tidak dapat membangun apa pun. Penting untuk mendefinisikan dengan jelas tujuan penelitian: apa masalahnya? Mengapa masalah ini harus dipecahkan? Siapa yang terkena masalah? Apa alternatifnya? Dan yang paling penting: dengan metrik apa keberhasilan proyek diukur?
Dengan kata lain, perlu untuk mengidentifikasi dengan jelas tujuan pelanggan. Misalnya, pemilik bisnis bertanya: dapatkah kita mengurangi biaya aktivitas tertentu? Perlu diklarifikasi: apakah tujuannya untuk meningkatkan efektivitas kegiatan ini? Atau meningkatkan pendapatan bisnis?
Setelah sasaran ditentukan, Anda dapat melanjutkan ke langkah berikutnya.
2. Pendekatan analitis
Sekarang Anda harus memilih pendekatan analitis untuk menyelesaikan masalah bisnis. Pilihan pendekatan tergantung pada jenis jawaban apa yang Anda butuhkan pada akhirnya: jika jawabannya ya / tidak, classifier Bayes naif cocok. Jika Anda membutuhkan jawaban dalam bentuk tanda numerik, maka model regresi cocok. Pohon keputusan dapat menangani data numerik dan kategorikal. Jika pertanyaannya adalah menentukan probabilitas hasil tertentu, perlu menggunakan model prediksi. Jika tautan perlu diidentifikasi, pendekatan deskriptif digunakan.
3. Persyaratan Data
Ketika tujuan penelitian didefinisikan dengan jelas dan pendekatannya dipilih, yaitu, kami memahami dengan jelas jawaban seperti apa dari pertanyaan yang kami cari, perlu untuk menentukan data apa yang memungkinkan kami memberikan jawaban yang diinginkan. Kita harus menyiapkan persyaratan data: konten, format, dan sumber yang akan digunakan pada tahap proyek selanjutnya.
4. Pengumpulan data
Pada tahap ini, kami mengumpulkan data dari sumber yang tersedia: kami memastikan bahwa sumber tersedia, dapat diandalkan dan dapat digunakan untuk mendapatkan data yang diperlukan dalam kualitas yang diperlukan. Setelah pengumpulan data awal selesai, perlu dipahami apakah kami menerima data yang kami inginkan. Pada tahap ini, Anda dapat merevisi persyaratan data dan membuat keputusan tentang perlunya data tambahan (yaitu, kemungkinan Anda harus kembali ke tahap 3). Lacunae dapat diidentifikasi dalam data dan rencana dapat disusun tentang cara menutupnya atau menemukan penggantinya.
5. Analisis Data
Analisis data mencakup semua pekerjaan desain sampel. Pada tahap ini perlu untuk mendapatkan jawaban atas pertanyaan: apakah data yang dikumpulkan mewakili tugas?
Di sini kita membutuhkan statistik deskriptif. Ini berlaku untuk semua variabel yang akan digunakan dalam model yang dipilih: posisi sentral (rata-rata, median, mode) diperiksa, pencilan dicari dan variabilitas diperkirakan (sebagai aturan, ini adalah besarnya, varians dan standar deviasi). Histogram distribusi variabel juga dibangun. Histogram adalah alat yang baik untuk memahami bagaimana nilai data didistribusikan dan persiapan seperti apa yang diperlukan agar variabel paling berguna saat membangun model. Alat visualisasi lain, seperti kotak kumis, mungkin juga berguna.
Selanjutnya, perbandingan berpasangan dilakukan: korelasi antara variabel dihitung untuk menentukan mana yang terkait dan berapa banyak. Jika ada korelasi yang signifikan antara variabel, beberapa dari mereka mungkin dibuang sebagai berlebihan.
6. Persiapan data
Bersama dengan pengumpulan dan analisis data, persiapan data adalah salah satu kegiatan proyek yang paling intensif sumber daya: fase-fase ini dapat memakan waktu 70, atau bahkan 90% dari waktu proyek. Pada tahap ini, kami memproses data sedemikian rupa sehingga nyaman untuk bekerja dengannya: menghapus duplikat, memproses data yang hilang atau salah, memeriksa dan, jika perlu, memperbaiki kesalahan pemformatan.
Juga pada tahap ini kami membangun satu set faktor yang pembelajaran mesin akan bekerja dengan pada tahap berikutnya: kami mengekstrak dan memilih fitur yang berpotensi membantu memecahkan masalah bisnis. Kesalahan pada tahap ini mungkin menjadi sangat penting untuk keseluruhan proyek, oleh karena itu perlu memberikan perhatian khusus padanya: sejumlah atribut yang berlebihan dapat menyebabkan model dilatih ulang, dan tidak cukup untuk model yang kurang terlatih.
7. Membangun model
Pilihan model, seperti yang Anda lihat, dilakukan pada awal pekerjaan dan tergantung pada tugas bisnis. Jadi, ketika jenis model ditentukan dan ada sampel pelatihan, analis mengembangkan model dan memeriksa cara kerjanya pada set fitur yang dibuat pada langkah 6.
8. Penerapan model
Penerapan model terkait erat dengan konstruksi aktual model: perhitungan bergantian dengan konfigurasi model. Pada tahap ini, kita harus menjawab pertanyaan apakah model yang dibangun memenuhi tugas bisnis.
Perhitungan model memiliki dua fase: pengukuran diagnostik dilakukan yang membantu untuk memahami apakah model berfungsi sebagaimana dimaksud. Jika model prediktif digunakan, pohon keputusan dapat digunakan untuk memahami bahwa output model cocok dengan rencana asli. Pada fase kedua, signifikansi statistik dari hipotesis diperiksa. Penting untuk memastikan bahwa data dalam model digunakan dan ditafsirkan dengan benar dan hasil yang diperoleh di luar kesalahan statistik.
9. Implementasi
Jika model memberi kita jawaban yang memuaskan untuk pertanyaan itu, jawaban ini harus mulai bermanfaat. Ketika model dikembangkan, dan analis yakin dengan hasil karyanya, perlu untuk memperkenalkan pelanggan ke alat yang dikembangkan. Masuk akal untuk menarik tidak hanya pemilik produk, tetapi juga pihak lain yang berkepentingan: pemasaran, pengembang, administrator sistem: semua orang yang entah bagaimana dapat mempengaruhi penggunaan lebih lanjut dari hasil proyek. Selanjutnya, Anda perlu beralih ke implementasi. Implementasi dapat terjadi secara bertahap, misalnya, untuk sekelompok pengguna terbatas atau dalam lingkungan pengujian. Penting juga untuk membangun sistem umpan balik untuk melacak seberapa berhasil model yang dikembangkan mengatasi tugas tersebut. Setelah beberapa waktu, umpan balik ini akan berguna untuk meningkatkan model. Sumber data baru, pemangku kepentingan baru juga dapat muncul, belum lagi fakta bahwa tugas bisnis itu sendiri dapat ditentukan. Dengan demikian, tidak ada batasan untuk kesempurnaan: bahkan model tertanam tidak pernah dapat dianggap ideal.