Perkembangan telah banyak berubah dalam beberapa tahun terakhir. Alih-alih aplikasi monolitik, layanan microser dan fungsi datang. Database dari monster industri universal telah merosot menjadi sasaran sempit. Docker berubah pikiran tentang penyebaran. Tetapi apakah ide kita tentang log berubah?
Salah satu masalah besar di Yandex. Vertikal adalah log - 18 TB per hari dan 250.000 log per detik, semuanya ditulis ke file. Log bersifat heterogen karena ada banyak bahasa: Scala, Java, Python, Go. Kemudian mereka dikumpulkan oleh Fluent Bit, menulis di Kafka, penangan bekerja pada satu mesin besi, berkumpul dari Kafka dan menulis semuanya ke disk. Selain itu, ini adalah versi log yang kedua.

Akibatnya, masalah pencarian yang panjang muncul. Log ini dicari menggunakan grep. Pada beberapa layanan, grep bisa mencapai berjam-jam. Jika Anda memiliki masalah dalam produksi, Anda tidak akan mencari log Anda selama berjam-jam. Untuk mengatasi masalah tersebut, Yandex memutuskan untuk menulis sepeda pengiriman log sendiri untuk pencarian. Apa yang datang dari ini, akan memberitahu
Alexei Danilov (
danevge ) - pengembang tim infrastruktur di Yandex.Verticals. Mengembangkan, menulis, dan mendukung proyek auto.ru dan Yandex.Real Estate.
Penafian. Artikel ini berbicara tentang perkembangan modern dan cocok untuk arsitektur layanan mikro. Berbagai produk disajikan di sini - ini adalah alat yang digunakan dalam Yandex. Vertikal. Dalam kondisi lain, analog mungkin lebih berhasil, tetapi mereka melakukan fungsi yang hampir sama. Catatan Artikel ini adalah versi diperpanjang dari laporan Alexey Danilov "Log tidak diperlukan" di RIT ++ 2019 DevOps Conf, yang dimodifikasi secara stylistically dan dilengkapi dengan materi baru. Anda dapat menemukan rekaman video pidato Alexey di tautan di saluran YouTube kami.
Tim Yandex. Tim Vertikal memiliki 300 orang, sekitar 100 di antaranya adalah pengembang. Dalam pengembangan, kami tidak berbeda dengan kebanyakan perusahaan yang membuat solusi produk mereka sendiri. Microservices, semua orang tinggal di Docker, sebuah monolith di PHP mengumpulkan debu di sudut yang gelap, digunakan melalui Hashicorp Nomad dan kami memelihara kebun binatang bahasa: Scala, Java, Go, Node.js, Python.
Salah satu masalah infrastruktur besar di Yandex. Vertikal adalah log aplikasi. Ketika kami secara serius mendekati masalah ini, kami menggunakan versi ketiga dari pengumpulan dan pemrosesan mereka. Sederhana, ini berfungsi seperti ini:
- aplikasi menulis ke file;
- Fluent Bit membaca file dan mengirimkannya baris demi baris ke Kafka filebeat;
- Pada mesin besi khusus ada aplikasi yang membaca topik Kafka dan menulis ke file pada disk.
Di musim panas, kami memiliki 18 TB log per hari, atau 250.000 baris per detik. Ini adalah jumlah yang sangat besar, yang mempersulit pekerjaan dengan data ini. Satu-satunya cara untuk menganalisis ini adalah grep, karena semuanya disimpan dalam file. Untuk aplikasi besar, analisis bisa memakan waktu berjam-jam. Untuk masalah dalam produksi, Anda tidak punya waktu ini.
Solusi siap pakai tidak sesuai dengan harga, sumber daya atau kecepatan. Mereka tidak bisa menangani aliran kami dengan baik. Sulit untuk menghitung jumlah upaya untuk memasak Elasticsearch. Saya kira kita tidak tahu cara memasaknya. Tetapi ini bukan yang kita butuhkan, jika untuk menggunakannya sebagai tempat penyimpanan log, diperlukan kemampuan khusus (keterampilan).
Dalam situasi ini, kami memutuskan untuk menerapkan sistem kami sendiri untuk mengumpulkan dan menganalisis log.
Sepeda
 Catatan: Jika sepeda berikutnya tidak menarik, maka segera lanjutkan ke bagian "Typification".
Catatan: Jika sepeda berikutnya tidak menarik, maka segera lanjutkan ke bagian "Typification".Format
Kami menggunakan beberapa PL dan suka microservices. Untuk bekerja dengan log, kami secara seragam membentuk format JSON kami sendiri. Ini mencakup sebagian besar kebutuhan untuk pekerjaan lebih lanjut dengan log.
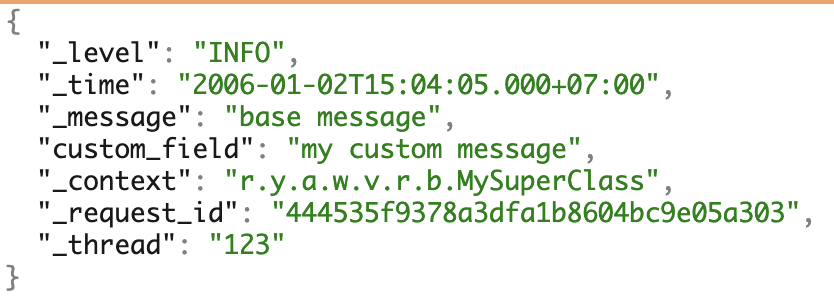 Contoh log dengan semua bidang yang memungkinkan.
Contoh log dengan semua bidang yang memungkinkan.Driver log Docker
Untuk mengumpulkan log, kami menulis
driver log buruh pelabuhan kami sendiri - aplikasi di Go. Itu dirakit dengan cara khusus, disampaikan oleh perintah plugin docker, disimpan dalam registri, dan berjalan dalam satu contoh menjalankan Docker.
Karena masalah dengan driver log dapat memengaruhi semua pekerjaan secara negatif, kami mencoba menulis implementasi yang minimal. Pengemudi kami mendengarkan stdout wadah dan segera meneruskan log ke aplikasi yang ada di dekatnya. Itu sudah berurusan dengan bagian yang lebih kompleks dari pengiriman.
Masalahnya
Saya secara terpisah akan menyebutkan masalah memperbarui versi driver log buruh pelabuhan.
 Cuplikan layar dari internal Grafana.
Cuplikan layar dari internal Grafana.Di sebelah kiri adalah rasio versi yang diinstal ke mesin. Sekarang tiga versi diinstal pada semua perangkat keras - tidak ada mobil yang hilang di mana pun dan tidak ada instalasi yang tidak perlu. Di sebelah kanan adalah jumlah kontainer yang menggunakan versi ini atau itu.
Driver buruh pelabuhan tidak dapat pergi dan memperbarui segera. Untuk melakukan ini, Anda harus memulai kembali semua wadah dan semua layanan, yang dapat menyebabkan masalah. Oleh karena itu, untuk menginstal versi baru, kami hanya menunggu semua wadah untuk memperbarui sendiri.
Skema umum
Pertimbangkan skema umum sistem baru untuk mengumpulkan dan mengirimkan log. Detail lainnya tidak begitu menarik.
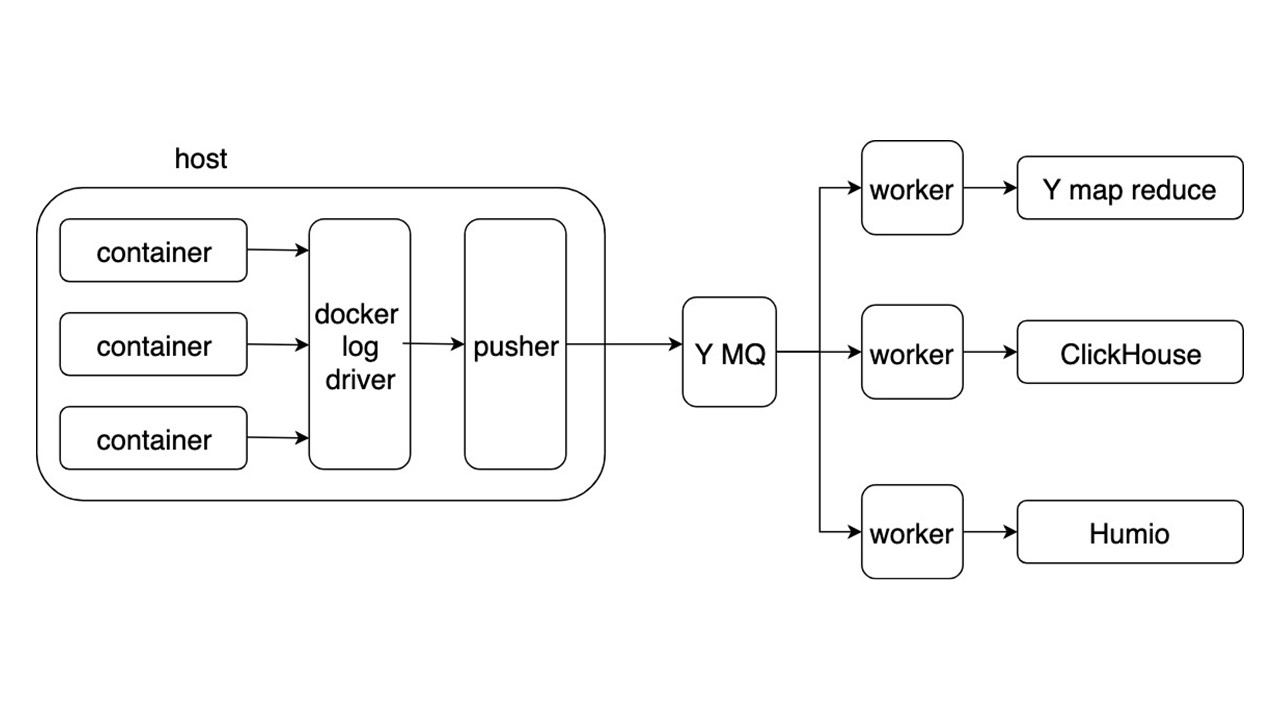
Aplikasi menulis log dalam format JSON di stdout. Docker mendengarkan pipa dari wadah dan mengarahkannya ke driver Docker. Driver Docker membaca dan secara tidak sinkron mencairkan kembali semua yang ada di Pusher.
Pusher berdiri di setiap mobil besi. Dia menyiapkan, menjenuhkan, membalik dan mendorong log ke Antrian Pesan Yandex. Aliran log dari MQ diurai oleh tiga jenis pekerja dan ditulis ke repositori.
Ada tiga repositori untuk merekam log.
- Yandex mapReduce untuk menyimpan dan menganalisis log dalam periode waktu yang lama. Ini adalah analog dari Hadoop.
- ClickHouse untuk menyimpan log selama hari terakhir.
- Humio (sebagai percobaan) untuk menyimpan log untuk hari terakhir.
Untung
Format umum memungkinkan Anda untuk menulis dan memproses log dengan cara yang sama. Pengumpulan log otomatis, tanpa menggunakan disk, dan pengiriman berada di area beberapa detik. Pencarian kunci dari 2 detik hingga 5 detik. Penyimpanan dan pengambilan untuk periode waktu yang lama.
Untuk volume yang lebih kecil, pertimbangkan alternatif: Humio, Splunk, dan Elastic. Dua yang terakhir memiliki driver Docker resmi. Jika Anda tinggal di AWS, itu adalah Amazon CloudWatch.
Amazon cloudwatch
Amazon CloudWatch menangani metrik, acara, dan log. Dia tidak mencari yang terakhir, tidak memberikan item pencarian super dan tidak memprosesnya dalam bentuk yang biasa. Amazon CloudWatch memproses log, analisis, filter, dan tampilan pada grafik.
 Amazon CloudWatch mengonversi log ke metrik dan grafik.
Amazon CloudWatch mengonversi log ke metrik dan grafik.Apa yang harus dilakukan dengan log?
Kembali ke sepeda kami - apakah ini memuaskan semua kasus? Tidak, solusi kami memungkinkan Anda menemukan log, tetapi mereka membutuhkan heterogenitas informasi dan jenisnya yang jauh lebih besar. Log digunakan dalam lebih banyak kasus.
Segera setelah Anda mengumpulkan log, kalimat berikut akan menjadi: "Mari kita parsing sesuatu, entah bagaimana memprosesnya, menuliskannya di suatu tempat dan mulai ditampilkan pada grafik, di dashboard." Ini jalan menuju neraka. Apalagi jika kita berbicara tentang alat umum.
Jika Anda membayangkan log sebagai kekacauan atau log peristiwa tertentu dari data apa pun, maka mereka tidak akan berfungsi.
Ini akan menjadi kekacauan besar informasi yang tidak dapat diproses. Sebuah permainan akan dimulai dalam formalisasi log: "Mari kita tulis baris ini dalam format khusus sehingga akan mudah untuk menguraikannya nanti!" Itu juga tidak berhasil. Percayalah, kami sudah mencoba.
Mengetik
Jika Anda memecah log menjadi tipe dan memprosesnya secara terpisah, Anda dapat menemukan alat yang akan membuatnya lebih mudah untuk bekerja dengannya. Bekerja tidak lagi dengan log, tetapi seperti data yang berguna - pekerjaan seperti itu lebih transparan dan nyaman. Beberapa jenis log dapat dibuang sama sekali.
Untuk jaga-jaga
Jenis log "menjadi" ini adalah favorit saya. Jika tidak mungkin untuk menjawab dengan jelas mengapa garis ini atau itu diperlukan, maka mereka harus. Tipe ini juga bisa disebut "log berjaga-jaga."
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
Log bukan komentar yang bisa dihapus. Ini adalah bagian dari kode yang lebih sulit untuk dimodifikasi, dikelola, dan bahkan dihapus.
Dalam kasus terbaik, log seperti itu dapat berubah menjadi debug atau jejak. Jenis ini
mengacaukan kode . Karena pencatatan yang terburu-buru, saya bisa memasukkan data pribadi, kata sandi, dan cookie pengguna ke dalamnya.
Cara yang benar adalah
membuangnya dan melupakannya . Tapi kemudian kita dihadapkan dengan masalah baru. Bagaimana cara mengurai situasi dengan kesalahan?
Kesalahan fatal / kritis
Untuk memulainya, kami hanya mempertimbangkan kesalahan kritis. Ini adalah kesalahan yang diderita pengguna dan pengembang. Yang pertama - ketika mereka tidak dapat menyelesaikan operasi. Yang kedua - ketika Anda perlu melakukan koreksi dengan tangan.
Mengapa log tidak pas?
Tidak ada respons cepat . Jika tim pengembangan mempelajari tentang kesalahan dari pengguna melalui dukungan atau dari Twitter, maka inilah saatnya untuk mengubah sesuatu.
Tidak ada konteks . Baris terpisah dari log kesalahan tidak berguna. Kita harus mengumpulkan konteksnya sedikit demi sedikit. Meski begitu, itu mungkin tidak cukup, karena ini adalah konteks dari proses, bukan kesalahan.
Tidak ada gambaran besar . Tidak ada jawaban untuk pertanyaan:
- seberapa sering kesalahan seperti itu terjadi;
- itu terjadi pada replika yang tersisa dari layanan;
- apakah itu sebelumnya?
Untuk memperbaiki masalah ini, gunakan alat yang sesuai, misalnya,
sentry.io . Ini memungkinkan Anda untuk bekerja dengan informasi kesalahan yang representatif, lengkap (kontekstual) dengan
alerting rule dapat disesuaikan.
Situs web penjaga menjelaskan perbedaan log dari menggunakan sentry.io.
Bukan kesalahan kritis
Kami melemparkan kesalahan fatal dan kritis dan sekarang semuanya ditulis dalam Sentry. Tetapi ada kesalahan internal - berbagai perpustakaan atau jawaban dari layanan pihak ketiga.
Contoh yang baik adalah coba lagi yang sukses. Misalkan layanan A beralih ke layanan B, tetapi, karena masalah jaringan, tidak bisa mendapatkan jawaban. Setelah kesalahan, layanan A kembali beralih ke layanan B dan menerima respons yang valid. Apakah kesalahan pada panggilan pertama penting? Tidak. Dalam hal ini, proses selesai dengan sukses, dan pengguna dapat menggunakan layanan ini.
Jika kesalahan semacam itu tidak penting untuk layanan agar berfungsi dan mereka tidak memengaruhi pengguna dengan pengulangan yang jarang, maka ini sama sekali bukan kesalahan. Ini adalah degradasi dari layanan, walaupun respons terhadap pengguna datang 50 ms kemudian. Jenis log ini merujuk pada peringatan - Peringatan.
Peringatan
Lansiran adalah informasi tentang degradasi layanan.
Di sini kita akan melihat masalah yang sama yang melekat pada kesalahan kritis, tetapi dengan reservasi. Reaksi terhadap suatu peristiwa individu tidak penting - kuantitasnya dari waktu ke waktu adalah penting.
Pertimbangkan contoh di mana layanan tidak dapat mengambil entri cache dan mengakses penyimpanan dingin. Jika ini terjadi satu menit sekali, maka ini dapat diambil untuk operasi normal dari layanan.
Emisi langka tidak penting .
Tetapi pada saat yang sama, Anda perlu memiliki alat untuk melihat gambaran besar, Anda perlu
analisis waktu nyata . Untuk melacak perubahan dalam jangka waktu yang lama, alangkah baiknya untuk memiliki
analisis retrospektif juga. Degradasi di atas tingkat tertentu (ambang batas) dapat berdampak buruk bagi pengguna - Anda memerlukan
reaksi dengan degradasi parah .
Kita tidak perlu log bertanda Peringatan, tetapi metrik degradasi.
Alat pengumpul metrik paling populer adalah Prometheus, dan Anda dapat menggunakan Grafana untuk visualisasi. Jika Anda memerlukan konteks besar (sama dengan kesalahan), maka Sentry yang sama akan melakukannya, tetapi dengan peringatan dimatikan. Namun, dalam kebanyakan kasus akan ada konteks yang cukup. Ini akan digunakan untuk grafik - label Prometheus.
Contohnya.
Tiga peristiwa terjadi di
user_service bersyarat. Mereka memengaruhi operasi layanan: permintaan panjang ke database, akses berulang ke API
service_b dan tidak ada hak pengguna yang ditemukan dalam cache. Bagan dan peringatan akan dikonfigurasikan sebagai hal penting bagi pengembang layanan, berkat konteksnya.
Menelusuri
Ini adalah hal pertama yang harus Anda mulai jika kami memilih jalur tempat Anda perlu mengurai log. Dengan sendirinya, informasi dalam log ini tidak berguna, karena Anda perlu membuat rantai panggilan, melihat data di dalam permintaan, kesalahan dalam rantai panggilan, waktu respons, jumlah RPS.
Ada alat hebat untuk melacak - Jaeger atau Zipkin. Saya sarankan menggunakan OpenTracing, yang keduanya dukung.
Anda dapat mengumpulkan penelusuran dari tiga sumber.
- Jika Anda menggunakan balancer bersama, parsing log dari mereka dan kirim ke Jaeger.
- Layanan sendiri , jika mereka menerima alamat melalui Service Discovery dan langsung pergi. Dalam hal ini, jejak dari layanan dikirim langsung ke Jaeger.
- Mesh layanan cerdas. Dia tahu cara mengumpulkan dan mengirim jejak, misalnya, Istio.
Informasi awal
Informasi ini adalah tentang panggilan layanan API, peluncuran Cron, permintaan basis data, atau panggilan ke layanan lain.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
Informasi ini termasuk dalam blok "Hanya dalam kasus", tetapi terpisah karena lebih umum. Informasi ini diperlukan untuk mengurai kesalahan dan
Anda dapat membuangnya .
Jika informasi tentang panggilan ke metode internal sangat penting dan Anda tidak dapat melakukannya tanpa itu, bahkan dengan konteks yang dikumpulkan jika terjadi kesalahan, maka perlu menginstruksikan panggilan metode sebagai jejak.
Waktu eksekusi
Informasi ini tentang waktu eksekusi metode, API, kueri basis data, atau layanan lainnya.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
Tidak ada nilai dalam log dari itu, karena Anda perlu menganalisis informasi ini, menampilkannya pada grafik, dan mengkonfigurasi ambang batas. Jenis log ini perlu diganti dengan
metrik , misalnya, di Prometheus.
Info bisnis
Informasi ini diperlukan untuk analisis bisnis, analisis perilaku pelanggan, perhitungan keuangan. Di tempat ini, kami secara historis menggunakan pendekatan yang berlawanan - log yang diuraikan. Tapi ini adalah contoh yang baik dari apa yang bisa membuat aplikasi log merosot jika Anda bekerja dengan mereka dengan cara ini.
Untuk log dengan data bisnis, perjanjian dibuat dengan bidang tetap dalam format TSKV, yang diperlukan untuk analitik. Aplikasi menulis log bisnis ke file khusus. Kemudian log dibaca dan dikirim baris demi baris ke MQ, dan aplikasi terpisah memprosesnya dan menulisnya ke database. Ini adalah contoh dari apa yang berubah menjadi parsing.
Ini tidak akan berhasil mengurai seluruh aliran log dengan harapan bahwa data akan bertemu.
Persyaratan konvensi, format, aturan, dan keandalan sedang muncul. Ini sudah terlihat sedikit seperti log aplikasi. Dalam hal ini, log menjadi antrian pengiriman data dengan semua persyaratan berikutnya untuk MQ. Terlihat bahwa middleware dalam bentuk log adalah berlebihan di sini.
Solusi yang baik adalah mengirim data ini langsung ke MQ. Sudah ada mereka akan diproses, disimpan di penyimpanan yang sesuai dan digunakan oleh tim analisis. Sebagai contoh, untuk tampilan kami menggunakan Tableau.
Performa
Jenis log ini jarang ditemukan dalam log aplikasi dan lebih sering dikumpulkan sebagai metrik. Secara terpisah, saya menambahkan bahwa untuk mengumpulkan metrik dasar yang spesifik untuk bahasa, cukup menggunakan perpustakaan Prometheus. Dia secara default akan mengumpulkan semua yang dia raih. Biaya menambahkan metrik ini kecil.

Hasil pengetikan
Setelah mengurutkan log berdasarkan jenis, kita dapat mengambil alat yang lebih kuat untuk bekerja dengannya. Tidak ada sistem yang kompleks atau teknologi ruang angkasa seperti Amazon, tidak ada yang tidak bisa dimunculkan besok. Anda mungkin sudah memiliki beberapa sistem atau analog ini: Sentry mengumpulkan debu di suatu tempat, Prometheus bekerja di suatu tempat.

Masalahnya bukan dalam teknologi, tetapi dalam perangkap kognitif ketika kita mempercayai log sebagai cara representasi yang andal dari kondisi sistem kita. Ini tidak demikian, log adalah serangkaian peristiwa kacau.
Ada pengecualian - Debug-log, yang dapat digunakan dalam kasus yang jarang terjadi.
Debug log
Debug-log harus berupa informasi terperinci. Mereka tidak boleh menduplikasi apa yang sudah dikirim ke sistem yang kami jelaskan di atas. Jenis ini ada untuk parsing kasus khusus. Misalnya, bug yang tidak dapat dipahami terjadi saat produksi, dan saat ini tidak jelas dengan metrik apa yang terjadi.
Nyalakan debug-log di hot, tanpa me-restart layanan . Karena kita berbicara tentang beberapa layanan, tidak akan banyak dari mereka. Infrastruktur canggih tidak diperlukan. Stack ELK yang cukup tanpa "persiapan" yang rumit. Masuk akal juga untuk menambahkan lansiran ke Sentry dengan semua konteks yang diperlukan.
Debug log dapat digunakan untuk pengembangan . Tetapi mereka diganti dengan sempurna dengan debugging.
Untuk meringkas
Kami menulis pengiriman log sepeda kami untuk pencarian . Kami tidak memuaskan pelanggan layanan - mereka semua datang kepada kami untuk memilah, mengumpulkan, dan mengagregasi mereka di suatu tempat. Ini dapat dihindari - sistem pemrosesan log yang kompleks tidak diperlukan.
Log mentah tidak berguna, tetapi dapat diubah menjadi metrik yang bermanfaat.
Cukup untuk membuat infrastruktur untuk memberikan metrik dan data yang berguna di sekitar layanan. Akibatnya, metrik yang berguna akan muncul yang berbicara tentang layanan dan secara transparan menunjukkan semua yang terjadi pada mereka.
Kesalahan harus mengandung konteks kesalahan itu sendiri.
Ini akan membantu mengatasinya dan segera memperbaikinya.
Kesalahan dan degradasi harus mengarah ke tindakan , sehingga pengembang langsung belajar tentang masalah dan memperbaikinya bahkan sebelum permintaan pengguna marah.
Alat yang tepat akan membuat bekerja dengan layanan Anda lebih menyenangkan dan transparan . Debug memiliki tempat untuk menjadi, tetapi Anda harus tegas dengan itu.
Di HighLoad ++ 2019 pada bulan November akan ada bagian DevOps - 13 laporan tentang muatan di AWS, sistem pemantauan di Lamoda, konveyor untuk pengiriman model, kehidupan tanpa Kubernetes, dan banyak lagi. Lihat daftar lengkap topik dan abstrak di halaman terpisah " Laporan ". Dan kami akan bertemu di DevOpsConf di musim semi - daftar untuk buletin , beri tahu kami kapan kami menentukan tanggal dan lokasi.