Pada November 2018, sebuah departemen pendukung informasi dibentuk di Lithuania dan mengundang
Andrei Yumashev untuk memimpin. Tahun lalu, departemen membantu perusahaan untuk bekerja dan mengembangkan serta menjaga seluruh infrastruktur tetap terkendali. Tapi itu tidak selalu terjadi. Sebelum menyiapkan pekerjaan, Andrei mengalami puing-puing: Nagio yang setengah mati, Cacti dan Wayang koma yang hidup dengan kondisional, Wiki yang mati 120 halaman, tabel tugas yang tidak koheren dan daftar besi, arsitektur usang, 340 core tidak aktif, 2 TB RAM dan 17 TB ruang disk yang karena alasan tertentu tidak dicatat dalam tabel inventaris. Rencana yang tidak berfungsi, tenggat waktu yang terputus, lingkungan kerja dan peralatan yang tidak ada - semua ini menunggu Andrei dalam proyek baru.

Di
DevOpsConf 2019, Andrei membuat laporan di mana ia menunjukkan pada contoh langsung apa yang layak dan apa yang tidak boleh dilakukan ketika Anda memasuki sebuah proyek yang belum Anda lihat atau ketahui dengan buruk. Di bawah potongan adalah versi terbaru dari cerita - bagaimana menganalisis dengan benar berbagai masalah dan membangun rencana kegiatan, cara menghitung KPI dengan benar dan kapan harus berhenti dalam waktu.
Andrey Yumashev adalah pemilik perusahaan pengembangannya sendiri di berbagai bidang (online dan offline), seorang konsultan untuk pembangunan proses, dan kepala departemen pendukung informasi di LiteRes.
Sedikit tentang LiteRes. Ini adalah pemasok terbesar buku elektronik dan audio di Rusia, sebuah penerbit dan sekelompok proyek kemitraan. Ini adalah ratusan ribu baris Perl, beberapa kelompok basis data dan repositori. Ini adalah 2 GB lalu lintas keluar per detik, ratusan ribu permintaan unik per hari, beberapa rak di pusat data yang berbeda dan lebih dari 100 server. Secara keseluruhan, ini bukan hanya toko buku elektronik.
Langkah pertama
Saya dulu bekerja di LiteRes berdasarkan besaran per satuan. Perusahaan mempraktikkan pengembangan staf dengan pendaftaran karyawan jarak jauh di negara bagian.
Sistem pemenuhan tugas dalam liter bekerja berdasarkan prinsip “lelang”. Dalam pelacak tugas internal, manajer dan arsitek menggambarkan tugas untuk proyek internal dan mengevaluasinya dalam mata uang lokal. Mata uangnya adalah "jamur, rumput, dan pohon".
Kemudian mulailah "pelelangan mudah" - pengembang mana pun dapat mengambil tugas atau tawar-menawar. Bagus sekali - Anda dibayar. Saya tidak bekerja sama sekali - Anda tidak mengerti. Dengan cara yang menyenangkan, orang-orang tertarik untuk menyelesaikan tugas. Untuk mempelajari lebih lanjut tentang sistem ini, lihat
presentasi Dmitry Gribov.
 Bekerja untuk jamur.
Bekerja untuk jamur.Sistem ini cocok untuk saya - saya mendukung pengalaman pemrograman Perl, bekerja dengan nyaman dan tidak menghabiskan terlalu banyak waktu untuk itu. Dalam mode ini, saya menghabiskan beberapa tahun hingga November tahun lalu dan berpikir bahwa saya memahami struktur ekosistem.
Saya salah
Saya diundang ke perusahaan dan diberi tahu bahwa layanan saya sebagai pengembang Perl tidak diperlukan, dan saya ditawari untuk memimpin departemen baru. Pada November 2018, saya menjadi kepala departemen informasi.
Di depan saya terbentang ruang terbuka: beberapa rak dengan besi di beberapa pusat data di Moskow, arsitektur usang, sumber daya asing, dan hampir tidak adanya dokumentasi yang relevan untuk itu semua. Pendahuluannya berbunyi seperti ini: "Sekarang ini warisanmu, perbaiki, jangan putus dan dukung." Ada beberapa tugas yang sudah jadi dan rencana kasar untuk tahun yang akan datang. Itu perlu untuk memahami semua ini dan membawanya ke bentuk manusia.
Ada perasaan bahwa saya sedang melihat ke dalam jurang, dan jurang itu menatap saya.
Pengalaman beberapa tahun terakhir banyak membantu saya ketika saya mengembangkan posisi yang jelas ketika bekerja dengan orang asing atau tidak dapat dipahami. Pertama-tama, ini adalah studi menyeluruh dan rencana tindakan minimal. Di sinilah saya mulai.
Kebersihan adalah kunci kesehatan
Ketertiban adalah yang pertama dan terpenting.
Untuk bulan pertama berhasil menemukan:
- Google Spread tersebar dengan tugas saat ini dan sedikit informasi bermanfaat;
- dokumen yang tersebar: Word, teks, memo dari halaman Wiki 120 lama;
- Nagios setengah mati;
- pemantauan langsung Cacti secara kondisional;
- boneka yang sangat tua dengan tanda-tanda kehidupan yang langka.
Semua reruntuhan ini juga mengumpulkan 400 metrik.
 Reruntuhan yang saya temukan di bulan pertama.
Reruntuhan yang saya temukan di bulan pertama.Saya sedikit bersenang-senang, membaca semuanya dengan lancar dan terjebak pada proses Trello. Dia mentransfer tugas rekan-rekannya saat ini kepadanya dan mulai bermimpi - untuk menulis rencana untuk kuartal dan tahun.
Kesalahan pertama
Tidak ada rencana sampai Anda menjelajahi daerah tersebut.
Rencana itu bersinar dengan panas dan kesehatan, tetapi tidak memperhitungkan kenyataan. Itu indah dan sederhana: mengimplementasikan pemantauan, menganalisis log dan mentransfer penyebaran ke CI / CD. Di suatu tempat pada akhirnya ada "analisis kelemahan proyek" yang lemah. Langkah pertama klasik.
Saya lupa tentang hal utama. Prioritas pertama saya bukan untuk mengimplementasikan alat untuk implementasi alat, tetapi untuk memastikan kelangsungan dan stabilitas layanan secara keseluruhan.
Sementara saya menulis rencana dan tersiksa oleh pertanyaan rekan-rekan saya, masalah pertama tiba. Salah satu node dari salah satu cluster cluster kehabisan ruang, dan SSD secara keseluruhan berakhir pada node lain dari cluster yang sama. Saya segera membeli disk baru yang lebih besar dan departemen kami dengan cepat memperoleh pengalaman dalam mengganti disk ini dengan menyalin sistem dari disk ke disk. Setelah mengganti disk, kami membangun cluster dari awal melalui SST. Cluster dibangun di atas Percona dan Galera, dan hiburan seperti itu tidak pergi kepadanya secara gratis.
Saat saya bepergian antara pusat data,
kecambah keraguan pertama tentang rencana itu muncul.
 Ahhhhhh!
Ahhhhhh!Pada saat yang sama, intensitas pekerjaan hitam begitu tinggi sehingga saya bahkan tidak berpikir untuk mengumpulkan riwayat medis yang lengkap, tetapi hanya mengambil beberapa foto untuk studi lebih lanjut.
Secara paralel, pengantar lain muncul. Dalam liter ada versi audio buku. Agar pendengar tidak memundurkan rekaman setiap kali lagi, kami memiliki mekanisme yang melacak saat berhenti. Lain kali Anda mendengarkan, versi audio diputar dari bagian yang diinginkan. Untuk tugas ini, dibutuhkan untuk menemukan sekitar 500 core lebih cepat, satu terabyte RAM dan sedikit analisis di Jawa.
Saya mulai memberi pengarahan kepada Azure, Google, DigitalOcean, dan semua hal lain yang diberikan solusi tetesan. Containerisasi memohon, mengapa tidak menerapkannya dengan riang? Terlebih lagi, dalam rencana "besar" ada poin terpisah tentang ini.
Sebulan telah lewat dalam korespondensi dan penawaran, semuanya ditambahkan ke tugas-tugas di Trello, yang mana saya menghasilkan bagian yang penting, tetapi hasilnya tidak berkembang. Saya bertanya-tanya apakah saya pergi ke sana. Sebelum saya, semuanya bekerja entah bagaimana dan tidak akan berhenti, tidak peduli berapa banyak aktivitas kosong yang saya tunjukkan. Saya duduk dengan hati-hati untuk mempelajari inventaris yang berhasil saya kumpulkan sedikit demi sedikit. Kemudian dia bangkit dan pergi ke pusat data putaran kedua.
Kunjungan tenang kedua ke pusat data menempatkan semuanya pada tempatnya. Ketika saya melihat ini semua tidak di konsol, tidak di Excel, tapi hidup, kesadaran saya tentang kenyataan berubah secara radikal. Saya menyadari bahwa saya sama sekali tidak sibuk dengan apa yang seharusnya. Karena pertama-tama Anda perlu memahami apa yang saya kerjakan.
Sampai saya mengerti apa yang saya kerjakan, semua rencana adalah buang-buang waktu.
Saya mempelajari rak-rak itu, membandingkan kenyataan dengan daftar, melakukan pengeditan, dan menemukan unit semi dengan 20 bilah. Dari 20, hanya 4 yang berhasil. Aku menyentak pedang dan menyadari bahwa kami tidak membutuhkan tetesan untuk solusi. Karena saya menemukan 340 core tidak aktif, 2 terabyte RAM dan 17 terabyte ruang disk! Ini adalah backend lama, node cluster lama yang hanya berhenti digunakan, dan waktu telah menghapus memori keberadaan mereka. Saya menggulung Kubernet pada bilah-bilah ini dan menyingkirkan satu tugas besar.
Output kesalahan pertama
Analisis dan pelajari. Tanpa analisis awal terhadap situasi, kereta tidak bergerak.
Berkat perjalanan penuh pertimbangan ke ladang, saya sudah punya rencana yang cukup relevan untuk peralatan dan arsitektur keseluruhan sistem. Di halaman adalah Januari. Saya menghabiskan dua bulan untuk hal ini, setengahnya baru saya lewati dari sisi ke sisi. Saya tidak tahu api mana yang harus dipadamkan terlebih dahulu, tugas apa yang harus dipecahkan pertama - aliran dukungan tidak kemana-mana.
Secara paralel, saya menyimpulkan tiga aturan. Ini adalah konsekuensi dari kesalahan pertama.
 Tiga akibat wajar.
Tiga akibat wajar.Rencana kedua
Saya membuang tugas-tugas sekunder dari foreground-log analysis dan implementasi CI / CD. Pada skala bencana umum, hal-hal kecil ini tidak penting. Liter telah bekerja selama bertahun-tahun dan telah mengembangkan logikanya sendiri untuk bekerja dengan log, dan telah memperoleh setan bergulir buatan sendiri. Saya mendorong ke dalam rencana kelima apa yang berhasil dan tidak memerlukan intervensi.
Rencana kedua terlihat seperti ini.
Menangani pemantauan . Dalam bentuknya saat ini, itu tidak mencerminkan setidaknya sepertiga dari masalah, meskipun berhasil.
Jelaskan logika umum seluruh liter . Nama server sangat bagus, tetapi bundel kunci adalah pengetahuan kritis: apa, di mana, di mana, mengapa dan mengapa. Kesalahan sebelumnya membuatnya jelas bahwa tanpa ini dengan cara apa pun.
Scaling . Hampir sumber daya gratis terakhir mengambil Kubernetes. Menurut perkiraan minimal, ia seharusnya menyelesaikan seluruh kumpulan pekerjaan dalam enam bulan.
Inventarisasi dan kondisi peralatan . Sebagai bagian dari perjalanan, saya benar-benar menggosok web dari sejumlah server yang takut dengan tag mereka - "cadangan", "berlangganan", "bgp". Sekali lagi, cakram, menjatuhkan disk.
Menyesuaikan panduan dengan kenyataan . Sebagian besar instruksi sudah usang atau tidak lengkap.
Enam bulan pertama berlalu tanpa disadari dalam pergantian, pembelian peralatan dan masalah, dan akhirnya saya membuktikan diri dalam kesalahan kedua.
Kesalahan kedua
Jangan remehkan.
Istilah apa pun yang muncul dalam pikiran diremehkan . Tentu, Anda dapat dengan cepat mendapat manfaat dari proyek ini. Tetapi untuk memaksimalkan pengembalian, gandakan waktu yang direncanakan dengan
setidaknya dua kali . Terutama pada proyek yang kompleks dan sangat padat, yang terus tumbuh dalam lalu lintas lebih dari 100% per tahun.
Kenapa setidaknya dua kali? Jika proyek tidak stabil dan tidak diteliti, bersiaplah untuk kenyataan bahwa setiap kegiatan akan menimbulkan kegiatan lain di tempat-tempat tetangga. Tampaknya mengganti disk - mana yang lebih mudah? Prosedurnya sederhana sampai Anda menemukan pembelian, kemudian menjadwalkan waktu untuk node spesifik downtime, lalu melakukan servis setelah mengganti disk. Saya memperkirakan operasi sederhana ini seminggu. Pada akhirnya, butuh dua setengah minggu - bahkan dengan skema pengadaan sederhana.
Contoh lain adalah pembelian dan pemasangan peralatan baru. Beli dan pertahankan, apa yang sulit? Saya mengambil tidak lebih dari sebulan untuk ini tanpa memperhitungkan waktu pengiriman. Bahkan, satu dari tiga sasis masih berdiri di depan meja saya. Ini karena peralatan tidak memiliki cukup ruang - kami menghitung tempat di dalam lubang di antara pemasangan saat ini. Ketika kami tiba di salah satu pusat data dengan maksud mengguncang rak, kami tiba-tiba menyadari bahwa kedua server itu "tidak tersentuh". Yang pertama adalah tuan rumah, dan sama sekali tidak aman untuk menyentuhnya. Yang kedua adalah sekeranjang 16 disk, mematikan yang penuh dengan tumpukan data. Sedotan tidak diletakkan, analisis tidak dilakukan, dan bagus bahwa mereka dapat menempel dua dari tiga.
Jika tampaknya semuanya akan sederhana - segera Anda akan memiliki masalah . Instalasi ini menimbulkan pertanyaan baru - jika semuanya sangat buruk dengan tempat itu, lalu bagaimana kita akan berkembang? Sebuah tugas kecil sekarang melahirkan keringat raksasa. Pada tahun 2020, menurut rencana, pemindahan satu pusat data ke pusat data lainnya dan perluasan sisanya dengan rak. Ini berarti migrasi dalam pusat data antara modul. Migrasi ini dilengkapi dengan restrukturisasi jaringan dan transfernya ke 10G.
Jangan meremehkan waktu, ambang masuk dan konsekuensi.
Konsep dasar
Tentu saja, esensi kesalahan sudah dijelaskan dalam Wiki sebagai konsep dasar.
Setiap proses birokrasi berlangsung setidaknya sebulan . Ini berlaku untuk pengadaan, kesimpulan dari kondisi baru dengan pusat data atau kontraktor lainnya - untuk semuanya. Anggap itu sebagai fakta.
Setelah kontrak dan pembayaran berakhir, pengiriman apa pun berlangsung setidaknya satu setengah minggu , dari disk ke prosesor. Belajarlah untuk bernegosiasi dengan pemasok untuk tanggal pra-pengiriman. Sebagai contoh, disk dikirimkan dalam batch kecil kepada kami sekarang sampai pembayaran dan bahkan sebelum persetujuan aplikasi.
Meskipun tidak ada pemahaman yang jelas tentang implementasi, rencana apa pun untuk mengimplementasikan sesuatu tetap merupakan rencana. Semakin pendek langkah, semakin baik.
Misalnya, untuk beralih dari MySQL ke ClickHouse, langkah lebar terlihat seperti ini: "Ayo mengisi beberapa server, lalu menggambar tiket untuk reintegrasi dan terbang!" Bahkan, sebuah studi terperinci tentang masalah ini mengarah pada langkah-langkah baru: pembelian peralatan tambahan, misalnya, prosesor dan disk, tiket terperinci untuk mengubah logika pelacak perilaku pengguna, mempertahankan integrasi terbalik, server antrian, dan banyak lainnya.
Semakin detail rencananya, semakin baik. Untuk menulis dengan sapuan kuas yang luas adalah jaminan 100% kesalahan dalam tenggat waktu.
Tunduk rencana apa pun untuk kritik maksimum dan harapkan risiko maksimum . Pastikan untuk melihat rencana dari sudut pandang bisnis - untung apa yang akan dihasilkan setiap langkah.
Kami harus melaksanakan implementasi wajib: pemantauan, Dapat dilakukan, tetapi kami tidak melupakan komponen bisnis.
- Dengan mengubah arsitektur jaringan, kami akan dapat menerima lalu lintas tambahan dan menyelesaikan banyak masalah saat ini.
- Dengan mengubah jenis penyimpanan konten, kami akan mengurangi jumlah bug dengan pengembalian buku dan meningkatkan kecepatan bekerja dengan data.
- Pindahkan backend ke cloud - skala langsung beban selama kampanye pemasaran.
- Menerjemahkan pelacakan ke ClickHouse adalah peluang bagi analis untuk lebih memahami kebutuhan pembaca dan pendengar tercinta kami.
Cara terbaik untuk menghadapi situasi di mana Anda kurang berpengalaman dalam topik ini adalah dengan meminta bantuan spesialis, bukan Stack Overflow . Kontak suara memecahkan masalah berkali-kali lebih cepat daripada korespondensi panjang atau membaca dokumentasi.
Enam bulan kemudian
Terlepas dari kenyataan bahwa tugas root yang saya fokuskan pada awalnya masih tergelincir, berkat penelitian dan koreksi, sesuatu yang baik muncul di tangan saya.
Alat yang ditulis sendiri untuk inventaris jaringan dan alamat. Dia secara teratur mengetuk semua subnet kami dan juga memeriksa data dengan konfigurasi BIND. Ini membuatnya mudah dan cepat untuk memesan layanan baru dan memahami beban nyata kumpulan jaringan. Saya benar-benar tidak ingin menghabiskan waktu untuk hal ini, tetapi saya tidak dapat menemukan alternatif yang sudah jadi, dan menemukan alamat untuk dialokasikan ke sumber daya baru memerlukan banyak waktu. Saat menulis alat, draf pertama rencana muncul di jaringan.
Wayang tidak lagi mati dan bingung . Saya dipersenjatai dengan kesimpulan dari kesalahan nomor satu dan bahkan tidak mencoba untuk pindah ke Ansible, yang lebih nyaman bagi saya.
Kurang lebih nagios yang dicurangi . Saya memindahkannya dari kantor ke pusat data dan membagikannya di tiga titik. Itu jauh lebih cepat dan lebih murah daripada mengimplementasikan Zabbix. Kami memasang lubang dengan peringatan yang tidak benar dalam waktu dan acara, konfigurasi ulang aturan yang sederhana dan pengenalan node kontrol tambahan.
Memahami pemeliharaan cluster database yang digunakan.
Wiki yang sangat bengkak . Dia "menjadi gemuk" dari komentar dan instruksi bekerja dengan lingkungan.
Tiga sasis HP yang kami beli untuk pemasangan di masa mendatang.
Memahami jalan menuju sisa tahun 2019 dalam pendekatan yang lebih jelas.
Ekosistem daur ulang untuk pekerjaan departemen.
Semua enam bulan ini saya bekerja hampir sendirian. Karyawan yang mewarisi lebih banyak administrator sistem. Mereka tidak benar-benar ingin mempelajari esensi DevOps.
Dengan susah payah, saya menemukan dua spesialis di tim - junior dan menengah. Saya mengumpulkan jumlah maksimum pengetahuan, penampilan dan kata sandi dari administrator saat ini dan berpisah dengan mereka dengan berat hati.
Sistem kerja, lingkungan dan peralatan
Saya akan memberi tahu Anda tentang pentingnya memperkenalkan ekosistem dan lingkungan yang berfungsi. Saya sudah menyebutkan Trello, tetapi tidak mengatakan mengapa dan mengapa saya menerapkannya. Tidak ada pekerjaan yang akan dibangun tanpa menetapkan tujuan dan data terstruktur. Ini sebagian dibuktikan dengan kesalahan pertama - kumpulkan semua yang ada.
Ambil semuanya, jangan berikan apa pun.
Prosesnya adalah mesin kemajuan . Oleh karena itu, selama ini saya bekerja pada sistem, meskipun ada hambatan penelitian dan alur kerja. Berkat sistem ini, enam bulan kemudian saya menempatkan lokomotif uap departemen pada rel yang stabil.
Pengenalan alat pendukung dan kursus singkat tentang penggunaannya sangat menghemat waktu untuk Anda dan kolega Anda. Terutama jika Anda bahkan di atas mengerti dalam manajemen dan sedikit mampu menjaga ketertiban pada desktop dan kehidupan.
Kami tidak menyulitkan alat, kami pergi dari yang sederhana dan memperkenalkan yang diperlukan . Pada awal tahun, saya pikir pelacak tugas mana yang cocok untuk kita. Segera memecat Jira dan Redmine - terlalu banyak kendali. Kami akan menghabiskan waktu mengisi formulir, bukan tugas. Google Sheets - Saya pikir tidak ada gunanya menjelaskan mengapa tidak.
Trello sempurna . Beberapa kolom sederhana: "Tunggakan" - di mana semua kesalahan atau tugas yang diperhatikan untuk masa depan dijumlahkan, "Sampai selesai" - tugas utama yang perlu dilakukan, dan "Selesai". Beberapa saat kemudian, ada lima kolom: "Backlog", "Jeda", "Sprint", "Finish" dan "Study".
Dalam "Jeda" dilakukan hal-hal yang kehilangan relevansi dalam proses sprint. Dalam "Belajar" - tugas yang membutuhkan penelitian dan tidak boleh hilang sampai saat memahami dan mentransfer pengetahuan ke Wiki. Sprint telah menjadi bukti bahwa kami telah beralih ke sistem sprint. Kami bereksperimen dan memilih waktu optimal - 2 minggu. Kami menggunakan segmen ini sekarang, tetapi yang lain cocok untuk Anda.
Waktu lari adalah individual untuk setiap perusahaan .
Pertemuan mingguan wajib adalah inovasi berikutnya setelah Trello. Kami praktis tidak bekerja di kantor. Waktu yang bisa kita habiskan di jalan, kita curahkan untuk bekerja. Tetapi sekali seminggu, seluruh departemen berkumpul di kantor selama 2-3 jam secara terputus-putus, dan membahas jalannya sprint dan tugas-tugas yang muncul. Dengan demikian, sebagai tambahan setiap dua minggu sekali kami merencanakan sprint berikutnya.
Kemudian pergi mengimplementasikan alat yang diperlukan minimum. Semua repositori layanan dengan konfigurasi - Wayang, Nagios, DNS - dikeluarkan dari SVN menjadi GitLab baru. Mereka mengaitkan Jenkins dengannya. Sekarang konfigurasi DNS diperbarui secara otomatis, dan suntingan kolega Wayang dapat dibaca melalui permintaan penggabungan lebih mudah dan lebih nyaman. Sebelumnya, kata sandi ditransmisikan dari orang ke orang, kini kata sandi itu dikumpulkan dengan rapi di 1Password. Sekarang ini adalah satu-satunya solusi berbayar dalam infrastruktur.
Mudah diimplementasikan dan dikonfigurasikan alat memunculkan proses, dan lebih mudah dikendalikan.
Masalahnya
Dalam liter lalu lintas tumbuh dan menambah pekerjaan: klaster yang rusak, pecahan besi, komponen. Paruh kedua tahun ini semakin dekat, untuk mana pengembangan penskalaan direncanakan.
Pada saat ini, dua buku terlaris muncul - sebuah buku baru oleh seorang penulis populer dan sebuah dekrit presiden negara sahabat tentang pemblokiran liter. Massively menuangkan keluhan tentang tidak dapat diaksesnya situs. Dekrit itu dikeluarkan sejak lama, tetapi kami mengetahuinya hanya ketika mereka mulai benar-benar memblokir kami di seluruh kumpulan alamat. Untungnya, dekrit tersebut hanya merujuk satu nama domain - “litres.ru”.
Peningkatan lalu lintas (semua orang menginginkan buku terlaris) melalui proxy, kami mengira serangan DDoS dan membayarnya dengan mata uang keras. Saya ingat bagaimana kami membayar tagihan satu perusahaan yang menjanjikan kami perlindungan terhadap DDoS. Segera setelah pembayaran, saya mengganti DNS ke alamat mereka, dan setelah 10 menit saya ingat kesalahan pertama dan dengan panik membalik kembali DNS. Tidak ada lalu lintas sampah, tetapi ada label harga kuda untuk lalu lintas yang melewati mereka - buku, audio, sampul. Saya tidak akan mengatakan berapa biaya hidup kita 20 menit di alamat orang lain.
Malam itu saya menelepon Cloudflare dan berbicara tentang masalah kami. Anti-DDoS . , Cloudflare . . , DDoS' , .
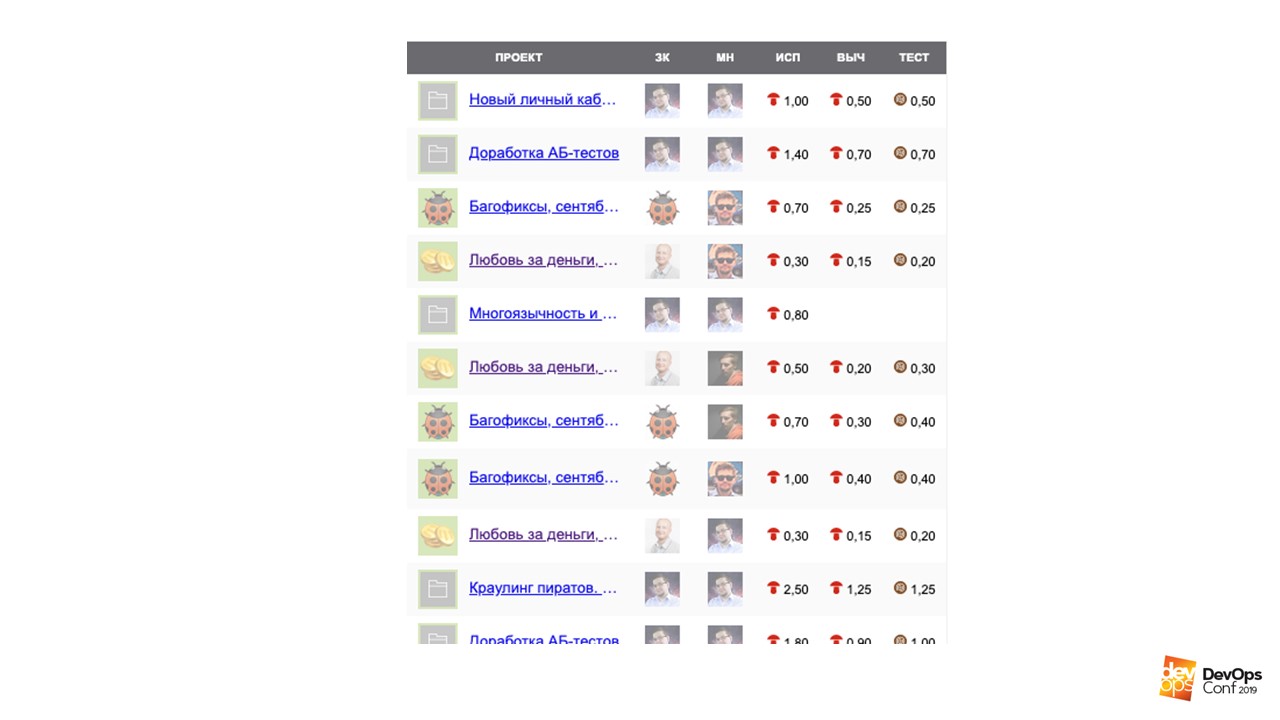
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:DevOpsConf . — , , . DevOps- HighLoad++ 2019 . DevOps 13 AWS, Lamoda, , Kubernetes, Kubernetes, Kubernetes . « » . HighLoad++ — , -. . — .