Kadang-kadang terjadi seperti ini:
- Ayo, kita telah jatuh. Jika Anda tidak menaikkannya sekarang, itu akan ditampilkan di TV.
Dan kita akan pergi. Di malam hari. Ke sisi lain negara.
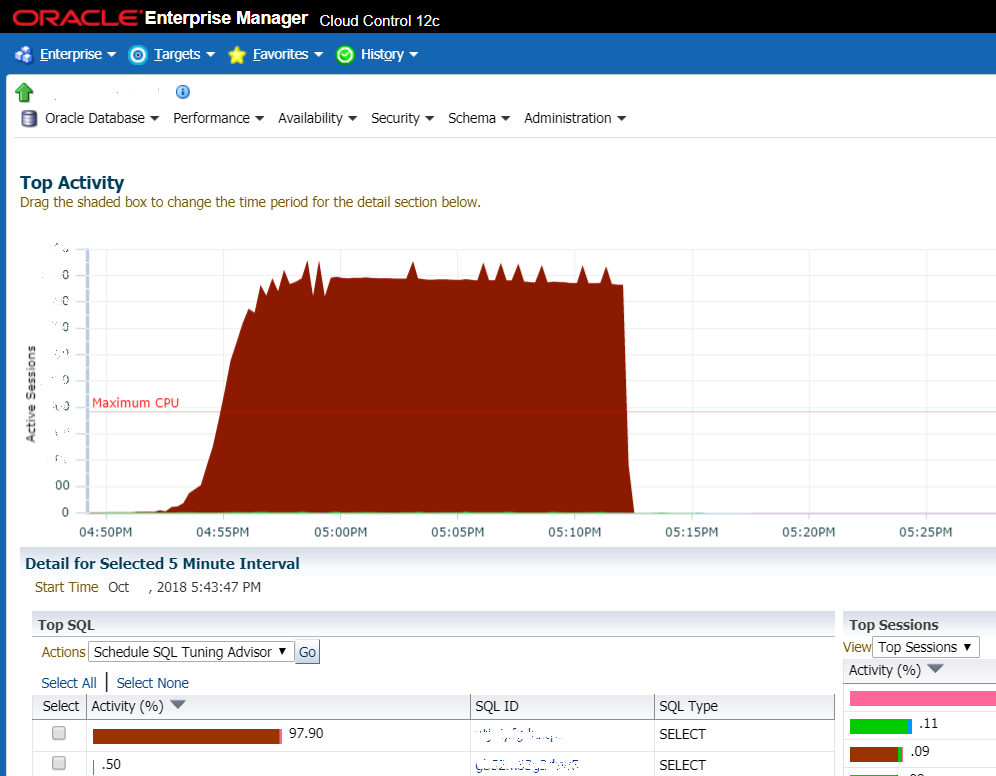 Situasi ketika tidak beruntung: grafik menunjukkan peningkatan tajam pada beban pada DBMS. Sangat sering ini adalah hal pertama yang dilihat oleh administrator sistem dan ini adalah tanda pertama bahwa keledai telah datang
Situasi ketika tidak beruntung: grafik menunjukkan peningkatan tajam pada beban pada DBMS. Sangat sering ini adalah hal pertama yang dilihat oleh administrator sistem dan ini adalah tanda pertama bahwa keledai telah datangTetapi lebih sering kita berbicara tentang beberapa hal yang khas. Misalnya, pelanggan dihadapkan dengan sistem alur kerja yang buruk. Pada hari Senin dan Selasa, sistem macet, mereka me-reboot server, dan kemudian semuanya berjalan. Basis data tersedak. Mereka ingin membeli peralatan (yang panjang dan mahal), mereka memanggil kami untuk menghitung estimasi. Kami menghitung perkiraan mereka dan pada saat yang sama menawarkan untuk mencari tahu apa yang sebenarnya memperlambat. Dalam tiga hingga empat jam, sumber masalahnya dilokalisasi. Kami menemukan bahwa ini adalah permintaan basis data yang lambat dan skema pengindeksan suboptimal. Kami membuat indeks yang hilang, mencari-cari di optimizer kueri di Oracle, beberapa masalah diperlukan mengubah kode - kami mengubah kondisi pencarian (tanpa mengubah fungsionalitas), menggantikan beberapa permintaan dengan menggunakan tampilan pra-perhitungan. Jika mereka memiliki orang normal dalam database - mereka dapat melakukan hal yang sama sendiri. Tapi alih-alih orang normal, database diaudit setiap enam bulan sekali oleh oracleis keren - mereka mengeluarkan rekomendasi umum tentang pengaturan dan perangkat keras.
Bagaimana itu bisa terjadi?
Detailnya sedikit berubah atas permintaan keamanan. Ada sistem manajemen dokumen di ratusan fasilitas industri. Dia terkadang jatuh, dan pekerjaan meningkat. Artinya, objek dapat bekerja, tetapi tidak satu dokumen pun lolos dan tidak ditandatangani. Dan ini, khususnya, pengiriman bahan baku, gaji dan pesanan, apa dan berapa banyak yang harus diproduksi per shift. Setiap musim gugur adalah rasa sakit, air mata, cognac untuk CIO, karena sulit baginya: banyak kerugian.
Direktur, omong-omong, baru berusia enam bulan di tempat ini setelah masa lalu. Dan tahun lalu berlangsung. Dan keduanya bekerja pada sistem yang diperkenalkan oleh sutradara tiga generasi yang lalu. Yang kedua dari akhir berusaha memperkenalkan miliknya, tetapi tidak punya waktu sebelum pemecatan. Situasinya sangat realistis.
Sekilas, kinerjanya tidak cukup. Profil beban terkunci (Tunggu Kelas "Aplikasi"). Artinya, persaingan untuk garis. Kami mulai menyelidiki insiden itu. Sesi dibuka untuk setiap transaksi pengguna. Itu dengan cepat masuk ke dalam keadaan memblokir pesanan, yang menurutnya tugas dan instruksi untuk eksekusi dituliskan, karena pengguna harus meletakkan visa "Akrab" minimal.
Kasus terakhir - mereka menggulirkan standar baru tentang seberapa sering karyawan harus menjalani pemeriksaan medis. Petugas personil tingkat atas menulis perintah dan mengirimkannya ke semua organisasi. Artinya, setiap karyawan dari setiap produksi. Puluhan ribu pengguna menerima transaksi visa. Mereka mulai membuka pesanan hampir bersamaan, memasukkan rantai kunci panjang ke dalam basis data. Karena bukan kode yang paling optimal, "kecil" meluap terjadi sebagai hasilnya, dan semuanya tersendat. Sekitar 40 ribu pengguna tidak bekerja. Dari skema cadangan - hanya telepon dan surat. Produksi tidak berhenti, tetapi efisiensi turun sangat banyak, yang menyebabkan kerugian finansial spesifik. Dan kemudian panggilan dimulai dari masing-masing perusahaan secara pribadi ke direktur TI dengan pidato. Dalam praktiknya, mereka memiliki SLA, tetapi belum ada kesepakatan. Dan situasinya mengambil fitur akhir dari sejarah murni Rusia.
Masalah perbaikan cepat diselesaikan dengan membuat profil, menganalisis logika memblokir objek, menghilangkan objek yang tidak perlu di mana kunci ditetapkan, meskipun itu tidak perlu karena objek tidak berubah (misalnya, direktori, hak akses, dll.). Kemudian, dalam beberapa bulan, bagian utama dari kode itu di-refactored.
Bagaimana bagian-bagian kode ini dicari?
Selain alat standar (dump benang, log, metrik, AWR, data dari representasi sistem, dll.), Kami menggunakan lebih banyak alat sipil, termasuk yang komersial.
Contoh 1: Log Transaksi LambatKeluhan dari pengguna telah diterima tentang pengoperasian jurnal yang lambat (masalah yang diketahui dan sering terjadi).
Kami menemukan tampilan masalah, lalu kami mencari permintaan di operasi untuk tampilan deal_journal_view. Kami mencari semua transaksi di mana ada permintaan seperti itu di dalam.

Untuk setiap operasi, Anda dapat melihat rinciannya dan menemukan permintaan itu sendiri dengan parameter eksekusi, yang memungkinkan Anda untuk menganalisis operasi permintaan, memvalidasi dan menyesuaikan rencana. Ditemukan permintaan lambat spesifik.

Mereka sendiri menganalisis dan mengusulkan opsi optimasi. Dan hanya kemudian, untuk melacak grup operasi bisnis ini (melihat log transaksi), buat Jenis Transaksi dan konfigurasikan peringatan.
 Contoh 2: menemukan alasan untuk kerja pengguna yang lambat 1
Contoh 2: menemukan alasan untuk kerja pengguna yang lambat 1Pengguna 1 menerima keluhan tentang pengoperasian aplikasi yang lambat. Kami melihat:

Semua operasi pengguna dicari dan diurutkan berdasarkan durasi. Selanjutnya, operasi paling lambat dianalisis, dan permintaan lambat ke sistem eksternal (SAP) terdeteksi.

Menunjuknya ke tim yang berdekatan, memperbaikinya.
Contoh 3: pengguna lain mengeluh tentang pengoperasian aplikasi yang lambatKami melihat dengan cara yang sama. Kali ini kami melihat sejumlah besar panggilan ke layanan penandatanganan eksternal. Ternyata, dalam kondisi tertentu, mereka menandatangani beberapa dokumen dua kali. Dikoreksi.
 Contoh 4: ketika tidak ada detail yang cukup
Contoh 4: ketika tidak ada detail yang cukupTerkadang, untuk menganalisis bagian kode yang lebih kompleks, kami menggunakan profiler khusus, yang memungkinkan kami mempelajari perilaku aplikasi lebih dalam. Sebagai contoh, seperti di sini: banyak logika yang tidak dapat dipahami selama pengoperasian logika dalam sistem. Kami menemukan logikanya, menambahkan beberapa cache, permintaan yang dioptimalkan.
 Contoh 5: lebih banyak rem
Contoh 5: lebih banyak remPengguna mengeluh tentang kerja lambat dengan kartu kontrak.

Operasi pengguna yang lambat (parameter = 'userlogin = ”...”') selama satu minggu dianalisis. Sebagian besar masalah adalah dengan permintaan pencarian di bawah kontrak, tetapi operasi dengan kartu dokumen juga ditemukan. Sebagian besar waktu dihabiskan untuk membuat sejumlah besar tugas pada tugas. Identifier ditemukan (kolom Nilai Parameter pada tangkapan layar) dari tugas tersimpan dan waktu penyimpanannya.
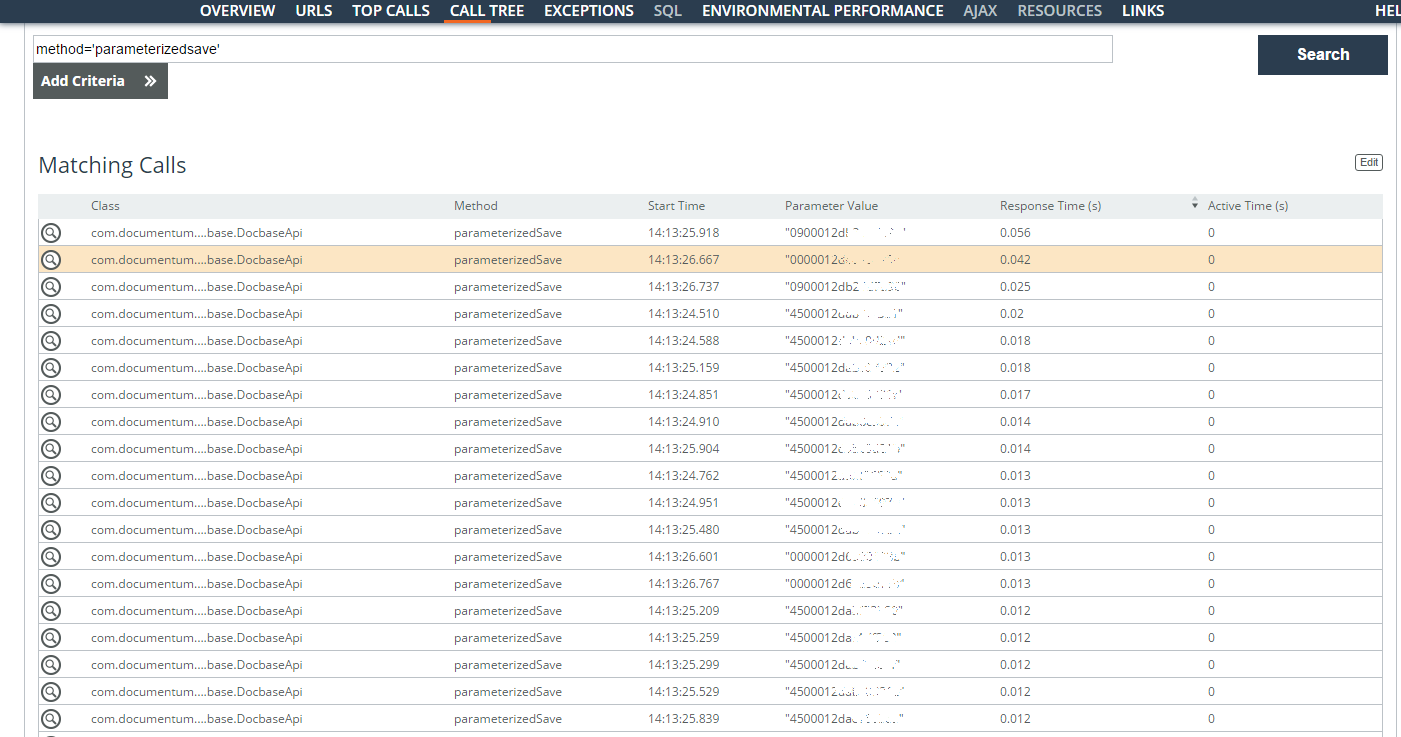
Logikanya, ketika mereka dapat dibuat secara tidak sinkron, tetapi sekarang mereka sedang antri dan membutuhkan kunci yang luar biasa. Di sini Anda sudah perlu mempelajari arsitektur lebih dalam.
Begitulah sederhananya: Anda perlu menemukan hambatan - dan hanya itu?
Tidak.
Dan lagi, tidak.
Ini semua pengobatan untuk gejalanya.
Itu benar untuk dengan cepat menyelamatkan situasi, yang sekarang terbakar. Dan kemudian masukkan prosesnya. Jarang orang yang bekerja dengan sistem tidak mengerti apa yang mereka lakukan. Hanya saja mereka perlu membenarkan cara untuk mengurangi hutang teknis mereka (dan tidak ada yang percaya mereka), atau mengubah proses menjadi lebih modern (yang tidak ada sumber daya baik), atau melakukan hal lain seperti itu.
Secara umum, kami datang dari tingkat atas dan melihat rasa sakit pada pelanggan. Lalu kami menangkap kemacetan. Terkadang diakhiri dengan pengenalan sistem pemantauan. Dan jika pelanggan memahami bahwa perlu untuk mengubah proses pengembangan perangkat lunak, maka tahapannya dimulai "panjang, mahal, dan bahkan sama sekali tidak mengagumkan."
Kami melihat dua atau tiga proyek, mengambil semua dokumen, repositori, mewawancarai orang-orang. Selanjutnya, kami menyiapkan templat untuk dokumen baru, menyiapkan prosedur, melihat alat untuk mengelola persyaratan, pengujian. Dan kami membantu menerapkannya. Terkadang cukup untuk memberi pendapat tentang apa yang harus diubah, dan CIO bersayap dengan kertas mendapat anggaran. Terkadang perlu disuntikkan langsung dengan darah dan air mata.
Apa pun bisa berubah menjadi rasa sakit, mulai dari pilihan arsitektur yang salah hingga beberapa fitur alur kerja.
Contoh-contoh ini adalah tentang permainan dalam proses di berbagai perusahaan di seluruh negeri.
Mengenai optimasi basis data, berikut adalah contoh tipikal. Ada sistem medis (salah satunya yang jatuh). Mereka memanggil kami untuk menonton. Kami tiba ketika mereka sudah mematikan semua modul, kecuali alur kerja dokter, sehingga setidaknya entah bagaimana analisis akan pergi dan rekaman melalui registri akan. Rekaman online, khususnya, adalah salah satu modul yang dinonaktifkan. Saya berhasil memperbaiki semuanya dalam satu minggu. Awalnya, pelanggan berpikir bahwa masalahnya ada pada lapisan aplikasi: ada kegagalan batas waktu, dan utas menggantung. Kami menemukan bahwa masalahnya ada pada basis data. Ada struktur yang kompleks, sekelompok pembagian berdasarkan hari dan bulan. Ternyata mereka lupa tentang beberapa indeks, para pengembang tidak sepenuhnya tahu apa yang akan berubah dari waktu ke waktu - dan inilah hasilnya. Kira-kira seperangkat operasi yang sama ditambah pembatasan pencarian (ketika Anda perlu membongkar sesuatu dalam rentang tanggal, alangkah baiknya untuk melihat di antara tanggal-tanggal ini, dan tidak di seluruh basis data).
Jelas bahwa optimasi seperti itu tidak selalu menyelesaikan masalah. Sebagai contoh, (berdasarkan arsitektur) sektor energi: pelanggan meminta untuk melihat apa yang terjadi dengan sistem. Dan di sana semuanya terbang saat pengiriman, tetapi setelah beberapa tahun ada lebih banyak dokumen, dan semuanya mengerem dengan baik. Pelanggan duduk dengan stopwatch di tempat kerja operator dan berkata: operasi ini sekarang membutuhkan waktu 31 detik, kami ingin 3. Ini adalah 40 detik, kami ingin 2. Dan seterusnya. Jelas bahwa mengukur cara ini tidak terlalu benar, tetapi tugasnya cukup spesifik dan dapat dengan mudah disajikan dalam bentuk kriteria objektif. Kami tidak melakukan segalanya, butuh sekitar enam bulan untuk "membersihkan". Sebagian besar, logika ditransfer ke eksekusi asinkron, beberapa database diubah menjadi noSQL, mesin pencari Solar dipasang, di satu bagian itu perlu untuk memilih database terpanas dan membuatnya dalam memori. Akibatnya, sekitar 90% dari kebutuhan ditutup, tetapi di beberapa tempat mereka tidak dapat mengurangi penundaan. Ini adalah karya perpustakaan pihak ketiga, batasan fisik platform, dan sebagainya. Semua ini dipantau dengan pemantauan dan mampu membuktikan dengan jelas di mana dan apa yang melambat.
Mengapa pemantauan seperti itu dibutuhkan?
Kami menggunakan perangkat lunak pemantauan yang berbeda untuk dengan cepat menemukan proses penghambatan dan mengoptimalkannya. Tim IT dari salah satu pelanggan utama melihat bagaimana kami melakukan ini, dan meminta untuk mengimplementasikannya di salah satu fasilitas sebagai alat permanen. OK, memonitor semua proses dan node, menyesuaikan sistem mereka untuk tugas, bekerja selama hampir empat bulan, tetapi membuat seperangkat alat untuk mendukung mereka. Dan ada 80 ribu pengguna, ada baris pertama dan kedua di dalam dan yang ketiga sering - dengan kontraktor atau juga di dalam.
Di baris kedua hanyalah seperangkat alat ini. Sekarang di sekitar 50% kasus, mereka menggunakan pemantauan untuk mendiagnosis, mencari kemacetan dan penyebab pembekuan, sehingga pengembang mereka sendiri dapat melihat, memahami, dan mengoptimalkan. Banyak waktu dukungan disimpan dengan mengidentifikasi penyebab masalah dengan cepat. Setelah pilot diskalakan berdasarkan transaksi. Itulah yang memakan waktu empat bulan: ada operasi bisnis untuk tindakan apa pun. Membuka kartu dokumen adalah transaksi bisnis. Masuk ke sistem alur kerja adalah transaksi bisnis. Laporkan unggahan atau cari juga. 1.500 operasi bisnis seperti itu dalam empat bulan dijelaskan untuk memahami di mana dan apa yang berhasil. Pemantauan sebelum ini melihat panggilan http dan melihat metode dan fungsi yang dipanggil, melihat permintaan spesifik. Sebelum ini, hanya pengembang yang mengerti bahwa ini adalah perjanjian atau pencarian perjanjian. Agar sistem pemantauan dapat menampilkan data yang relevan untuk jalur dukungan yang berbeda dan untuk bisnis, kami telah menyiapkan semua bundel ini.

Bisnis ini juga mulai memotong laporan tentang pengembangan TInya sendiri. Lebih banyak tentang log tidak ada yang mengambil terutama.
Ngomong-ngomong, tentang segala hal mengapa sistem kelas
APM diperlukan sama sekali, dan bagaimana memilihnya, kita akan berbicara di
webinar pada 1 Oktober .
Apa lagi ada "colokan" dari sisi teknis?
Beberapa contoh lagi. Bank asing besar dengan kantor perwakilan di Rusia. Kami mendukung Oracle DB dan Oracle Weblogic. Penurunan bertahap dalam produktivitas diamati dalam sistem, operasi bisnis dilakukan lebih lambat, pekerjaan operator menjadi kurang dan kurang efektif, dan selama periode impor dan sinkronisasi dengan NSI semuanya benar-benar membeku. Dalam kasus seperti itu, kami menggunakan alat Java dan Oracle standar untuk mengumpulkan data: kami mengumpulkan dump thread, menganalisisnya dalam layanan gratis atau menggunakan alat analisis yang ditulis sendiri, melihat AWR, melacak eksekusi query SQL, menganalisis rencana dan statistik eksekusi. Akibatnya, selain hal-hal standar, seperti mengoptimalkan komposisi indeks dan menyesuaikan rencana kueri, kami mengusulkan untuk memperkenalkan partisi dengan membagi data. Ternyata dua segmen: historis (meninggalkannya di HDD) dan operasional - ditempatkan pada SSD. Sebelum ini, cukup sulit untuk memahami data apa yang terkait dengan apa, karena data historis masih harus turun secara teratur, baik pada laporan panjang dan dalam operasi biasa. Sebagai hasil dari pemisahan yang benar, lebih dari 98% operasi utama tidak masuk ke data historis yang lambat. Yang penting, tidak ada kode yang masuk ke sistem. Kebetulan beberapa rekomendasi kami memerlukan perubahan pada kode aplikasi, yang tidak didukung oleh kami, maka kami biasanya setuju.
Contoh kedua: produsen internasional di bidang industri ringan dan segmen FMCG secara umum. Waktu henti situs utama menghabiskan biaya sekitar 20 juta rubel. Beban rata-rata di pangkalan adalah 200 AS (sesi aktif) dengan puncak hingga 800-1000. Tidak jarang pengoptimal kueri kehilangan akal, rencana mulai mengambang bukan untuk yang lebih baik, dan persaingan liar untuk cache buffer dimulai. Tidak ada yang aman dari ini, tetapi Anda dapat mengurangi kemungkinan: selama dua bulan kami memantau sistem, menganalisis profil beban, memadamkan api di sepanjang jalan, menyesuaikan skema pengindeksan dan partisi, logika pemrosesan data dari sisi kode PL / SQL. Di sini Anda perlu memahami bahwa dalam sistem yang hidup dan berkembang, audit semacam itu harus dilakukan secara teratur, meskipun pengujian stres membantu, tetapi tidak selalu. Dan perusahaan melakukan audit dengan mengundang oracleis pihak ketiga, tetapi jarang ada yang jatuh ke tingkat logika bisnis dan siap untuk menggali data, berinteraksi dengan pengembang. Kami melakukannya.
Yah, saya ingin mengatakan bahwa masalahnya tidak selalu kurangnya pembersihan rutin atau dukungan yang tepat. Seringkali masalah sedang dalam proses.
Mengapa kita membutuhkan layanan seperti itu dengan pengembang live mereka?
Karena bisnis menyukai keputusan, bukan proses. Inilah alasan utamanya.
Yang kedua adalah bahwa tidak semua orang dapat mengalokasikan sumber daya untuk mencari hambatan dalam suatu aplikasi, terutama jika itu adalah aplikasi pihak ketiga. Dan jauh dari selalu dalam satu tim ada orang-orang dengan kompetensi yang diperlukan. Saat ini kami memiliki insinyur sistem, insinyur jaringan, spesialis di Oracle dan 1C, orang-orang yang dapat mengoptimalkan Java, dan antarmuka dalam tim kami.
Nah, jika Anda tertarik untuk menyelami rinciannya, maka
pada 1 Oktober akan ada webinar kami tentang apa yang dapat Anda lakukan sebelumnya, sebelum semuanya jatuh. Dan ini surat saya untuk pertanyaan - sstrelkov@croc.ru.