Tidak perlu secara khusus mewakili basis FIAS:

Anda dapat mengunduhnya dengan mengklik
tautan , basis data ini terbuka dan berisi semua alamat objek di Rusia (register alamat). Ketertarikan pada database ini disebabkan oleh fakta bahwa file yang dikandungnya cukup banyak. Jadi, misalnya, yang terkecil adalah 2,9 GB. Disarankan untuk menghentikannya dan melihat apakah panda dapat mengatasinya jika Anda bekerja pada mesin dengan hanya 8 GB RAM. Dan jika Anda tidak bisa mengatasinya, apa saja opsi untuk memberi makan panda file ini.
Di tangan, saya tidak pernah menemui pangkalan ini dan ini merupakan kendala tambahan, karena format data yang disajikan di dalamnya sama sekali tidak jelas.
Setelah mengunduh arsip fias_xml.rar dengan basis, kami mendapatkan file darinya - AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. File ini dalam format xml.
Untuk pekerjaan yang lebih nyaman di panda, disarankan untuk mengonversi xml ke csv atau json.
Namun, semua upaya untuk mengonversi program pihak ketiga dan python itu sendiri menyebabkan kesalahan atau pembekuan "MemoryError".
Hm Bagaimana jika saya memotong file dan mengubahnya menjadi beberapa bagian? Itu ide yang bagus, tetapi semua "pemotong" juga mencoba membaca seluruh file ke dalam memori dan menggantung, python itu sendiri, yang mengikuti jalur "pemotong", tidak memotongnya. Apakah 8 GB jelas tidak cukup? Baiklah, mari kita lihat.
Program Vedit
Anda harus menggunakan program vedit pihak ketiga.
Program ini memungkinkan Anda untuk membaca file xml 2,9 GB dan bekerja dengannya.
Ini juga memungkinkan Anda untuk membaginya. Tapi ada sedikit trik.
Seperti yang dapat Anda lihat saat membaca file, file itu, di antaranya, memiliki tag AddressObjects pembuka:

Jadi, membuat bagian dari file besar ini, jangan lupa untuk menutupnya (tag).
Artinya, awal dari setiap file xml akan seperti ini:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
dan berakhir:
</AddressObjects>
Sekarang potong bagian pertama file (untuk bagian yang tersisa langkah-langkahnya sama).
Dalam program vedit:
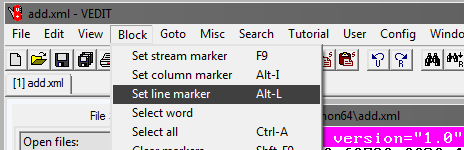
Selanjutnya, pilih Goto dan Line #. Di jendela yang terbuka, tulis nomor baris, misalnya, 1.000.000:

Selanjutnya, Anda perlu menyesuaikan blok yang dipilih sehingga menangkap hingga akhir objek dalam database sebelum tag penutup:
Tidak apa-apa jika ada sedikit tumpang tindih pada objek berikutnya.
Selanjutnya, dalam program vedit, simpan fragmen yang dipilih - File, Save as.
Dengan cara yang sama, kita membuat bagian file yang tersisa, menandai bagian awal dari blok pilihan dan bagian akhir dengan penambahan 1 juta baris.
Akibatnya, Anda harus mendapatkan file xml ke-4 dengan ukuran sekitar 610 MB.
Kami menyelesaikan bagian xml
Sekarang Anda perlu menambahkan tag di file xml yang baru dibuat agar dibaca sebagai xml.
Buka file dalam vedit satu per satu dan tambahkan di awal setiap file:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
dan pada akhirnya:
</AddressObjects>
Dengan demikian, kami sekarang memiliki 4 xml bagian dari file sumber split.
Xml-to-csv
Sekarang terjemahkan xml ke csv dengan menulis program python.
Kode program
.
Dengan menggunakan program ini, Anda perlu mengkonversi semua 4 file ke csv.
Ukuran file akan berkurang, masing-masing akan 236 MB (bandingkan dengan 610 MB dalam xml).
Pada prinsipnya, sekarang Anda sudah dapat bekerja dengan mereka, melalui excel atau notepad ++.
Namun, file masih ke-4 dan bukan satu, dan kami belum mencapai tujuan - memproses file dalam panda.
Lem file menjadi satu
Di Windows, ini bisa menjadi tugas yang sulit, jadi kami akan menggunakan utilitas konsol dengan python yang disebut csvkit. Diinstal sebagai modul python:
pip install csvkit
* Sebenarnya ini adalah satu set seluruh utilitas, tetapi satu akan dibutuhkan dari sana.
Setelah memasukkan folder dengan file untuk direkatkan di konsol, kami akan melakukan perekatan menjadi satu file. Karena semua file tanpa header, kami akan menetapkan nama kolom standar saat menempel: a, b, c, dll .:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
Outputnya adalah file csv yang sudah jadi.
Mari kita bekerja dalam panda untuk mengoptimalkan penggunaan memori
Jika Anda segera mengunggah file ke panda
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
dan periksa berapa banyak memori yang dibutuhkan, hasilnya mungkin mengejutkan:

3 GB! Dan ini terlepas dari kenyataan bahwa ketika membaca data, kolom pertama "pergi" sebagai kolom indeks *, dan volumenya akan lebih besar.
* Secara default, panda menetapkan indeks kolomnya sendiri.
Kami akan melakukan optimasi menggunakan metode dari
pos dan
artikel sebelumnya:
- objek dalam kategori;
- int64 di uint8;
- float64 di float32.
Untuk melakukan ini, ketika membaca file, tambahkan dtypes dan membaca kolom dalam kode akan terlihat seperti ini:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
Sekarang, dengan membuka file panda, penggunaan memori akan lebih bijaksana:

Masih menambahkan file csv, jika diinginkan, nama kolom baris-aktual sehingga data masuk akal:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* Anda dapat mengganti nama kolom dengan baris ini, tetapi kemudian Anda harus mengubah kode.
Simpan baris pertama file dari panda
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
dan lihat apa yang terjadi di excel:

Kode program untuk pembukaan optimal file csv dengan database:
kode import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
Sebagai kesimpulan, mari kita lihat ukuran dataset:
gl.shape
(3348644, 28)
3,3 juta baris, 28 kolom.
Intinya: dengan ukuran file csv awal 890 MB, "dioptimalkan" untuk keperluan bekerja dengan panda, ini menempati memori 1,2 GB.
Dengan demikian, dengan perhitungan kasar, dapat diasumsikan bahwa file berukuran 7,69 GB dapat dibuka dalam panda, setelah sebelumnya "dioptimalkan" itu.