Apa itu pengenalan suara End2End, dan mengapa itu diperlukan? Apa perbedaannya dari pendekatan klasik? Dan mengapa, untuk melatih model berbasis End2End yang bagus, kami membutuhkan sejumlah besar data - di pos kami hari ini.
Pendekatan klasik untuk pengenalan suara
Sebelum berbicara tentang pendekatan End2End, Anda harus terlebih dahulu berbicara tentang pendekatan klasik untuk pengenalan suara. Seperti apa dia?

Ekstraksi fitur
Faktanya, ini bukan urutan blok aksi yang sepenuhnya linier. Mari kita membahas masing-masing blok dengan lebih detail. Kami memiliki beberapa jenis input ucapan, itu jatuh pada blok pertama - Ekstraksi Fitur. Ini adalah blok yang menarik tanda-tanda dari ucapan. Harus diingat bahwa pidato itu sendiri adalah hal yang agak rumit. Anda harus dapat bekerja dengannya, jadi ada metode standar untuk mengisolasi fitur dari teori pemrosesan sinyal. Misalnya, koefisien Mel-cepstral (MFCC) dan sebagainya.
Model akustik
Komponen selanjutnya adalah model akustik. Ini dapat didasarkan pada jaringan saraf yang dalam, atau berdasarkan campuran distribusi Gaussian dan model Markov tersembunyi. Tujuan utamanya adalah untuk memperoleh dari satu bagian sinyal akustik distribusi probabilitas berbagai fonem di bagian ini.
Berikutnya adalah dekoder, yang mencari jalur yang paling mungkin dalam grafik berdasarkan hasil dari langkah terakhir. Penyelamatan merupakan sentuhan terakhir dalam pengakuan, yang tugas utamanya adalah menimbang ulang hipotesis dan menghasilkan hasil akhir.
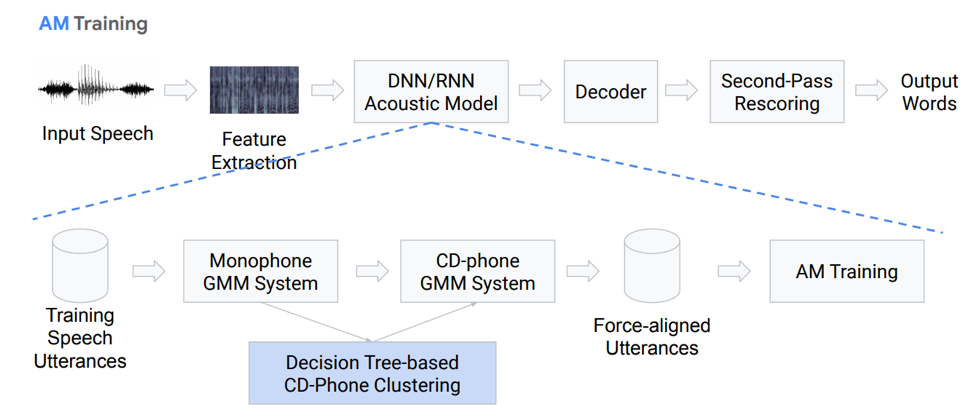
Mari kita membahas lebih rinci tentang model akustik. Seperti apa dia? Kami memiliki beberapa rekaman suara yang memasuki sistem tertentu berdasarkan GMM (monaural Gausovy mix) atau HMM. Yaitu, kita memiliki representasi dalam bentuk fonem, kita menggunakan monofon, yaitu, fonem konteks-independen. Lebih jauh dari ini, kami membuat campuran distribusi Gaussian berdasarkan fonem konteks-sensitif. Ini menggunakan pengelompokan berdasarkan pohon keputusan.
Kemudian kami mencoba membangun penyelarasan. Metode yang sangat sepele seperti itu memungkinkan kita untuk mendapatkan model akustik. Itu tidak terdengar sangat sederhana, bahkan lebih rumit, ada banyak nuansa, fitur. Tetapi sebagai hasilnya, model yang dilatih ratusan jam sangat baik untuk mensimulasikan akustik.

Dekoder
Apa itu decoder? Ini adalah modul yang memilih jalur transisi paling mungkin menurut grafik HCLG, yang terdiri dari 4 bagian:
Modul H berdasarkan HMM
Modul ketergantungan konteks C
Modul pengucapan L
Modul model bahasa G
Kami membuat grafik pada empat komponen ini, dengan dasar itu kami akan mendekode fitur akustik kami menjadi konstruksi verbal tertentu.
Plus atau minus, jelas bahwa pendekatan klasik agak rumit dan sulit, sulit untuk dilatih, karena terdiri dari sejumlah besar bagian yang terpisah, untuk masing-masing Anda perlu menyiapkan data Anda sendiri untuk pelatihan.
II Pendekatan End2End
Jadi apa itu pengenalan suara End2End dan mengapa itu diperlukan? Ini adalah sistem tertentu, yang dirancang untuk secara langsung mencerminkan urutan tanda akustik dalam urutan grapheme (huruf) atau kata-kata. Anda juga dapat mengatakan bahwa ini adalah sistem yang mengoptimalkan kriteria yang secara langsung mempengaruhi metrik akhir penilaian kualitas. Sebagai contoh, tugas kita secara khusus adalah tingkat kesalahan kata. Seperti yang saya katakan, hanya ada satu motivasi - untuk menyajikan komponen-komponen multi-tahap yang kompleks ini sebagai satu komponen sederhana yang akan langsung menampilkan, menampilkan kata-kata atau gambar-gambar dari pidato input.
Masalah simulasi
Di sini kita memiliki masalah segera: ucapan suara adalah urutan, dan pada output kita juga perlu memberikan urutan. Dan hingga 2006, tidak ada cara yang memadai untuk memodelkan ini. Apa masalah pemodelan? Ada kebutuhan untuk setiap rekaman untuk membuat markup yang kompleks, yang menyiratkan pada detik kami mengucapkan bunyi atau huruf tertentu. Ini adalah tata letak rumit yang sangat rumit dan oleh karena itu sejumlah besar studi tentang topik ini belum dilakukan. Pada tahun 2006, sebuah artikel menarik dari Alex Graves “Connectionist temporal klasifikasi” (CTC) diterbitkan, di mana masalah ini, pada prinsipnya, dipecahkan. Tetapi artikel itu diterbitkan, dan tidak ada daya komputasi yang cukup pada waktu itu. Dan algoritma pengenalan suara yang bekerja nyata muncul jauh kemudian.
Secara total, kami memiliki: algoritma CTC diusulkan oleh Alex Graves tiga belas tahun yang lalu, sebagai alat yang memungkinkan Anda untuk melatih / melatih model akustik tanpa perlu markup kompleks ini - penyelarasan frame input dan output urutan. Berdasarkan algoritma ini, pekerjaan awalnya muncul yang tidak menyelesaikan end2end; fonem dikeluarkan sebagai hasilnya. Perlu dicatat bahwa fonem konteks-sensitif berdasarkan STS mencapai salah satu hasil terbaik dalam pengakuan kebebasan berbicara. Tetapi perlu juga dicatat bahwa algoritma ini, yang diterapkan langsung pada kata-kata, masih ada di belakang saat ini.

Apa itu STS?
Sekarang kita akan berbicara sedikit lebih detail tentang apa STS itu, dan mengapa itu diperlukan, apa fungsinya. STS diperlukan untuk melatih model akustik tanpa perlu perataan frame-by-frame antara suara dan transkripsi. Penyelarasan frame-by-frame adalah ketika kita mengatakan bahwa frame tertentu dari suara sesuai dengan frame dari transkripsi. Kami memiliki encoder konvensional yang menerima tanda-tanda akustik sebagai input - itu memberikan semacam penyembunyian negara, atas dasar yang kita dapatkan probabilitas bersyarat menggunakan softmax. Encoder biasanya terdiri dari beberapa lapisan LSTM atau variasi RNN lainnya. Perlu dicatat bahwa STS beroperasi selain karakter biasa dengan karakter khusus yang disebut karakter kosong atau simbol kosong. Untuk menyelesaikan masalah yang timbul karena fakta bahwa tidak setiap bingkai akustik memiliki bingkai dalam transkripsi dan sebaliknya (yaitu, kami memiliki huruf atau suara yang terdengar lebih lama dan ada suara pendek, suara berulang), dan ada simbol kosong ini.
STS itu sendiri dimaksudkan untuk memaksimalkan probabilitas akhir dari urutan karakter dan untuk menggeneralisasi kemungkinan penyelarasan. Karena kita ingin menggunakan algoritme ini dalam jaringan saraf, dipahami bahwa kita harus memahami bagaimana mode operasi maju dan mundurnya bekerja. Kami tidak akan memikirkan pembenaran matematis dan fitur pengoperasian algoritma ini, jika tidak maka akan memakan waktu yang sangat lama.
Apa yang kita miliki: ASR pertama berdasarkan algoritma STS muncul pada tahun 2014. Sekali lagi, Alex Graves mempresentasikan publikasi berdasarkan karakter demi karakter STS yang secara langsung menampilkan input input dalam urutan kata-kata. Salah satu komentar yang mereka buat dalam artikel ini adalah bahwa menggunakan model suara eksternal penting untuk mendapatkan hasil yang baik.
5 cara untuk meningkatkan algoritma
Ada banyak variasi dan peningkatan pada algoritma di atas. Inilah, misalnya, lima yang paling populer baru-baru ini.
• Model bahasa dimasukkan dalam decoding selama pass pertama
o [Hannun et al., 2014] [Maas et al., 2015]: Pengodean ulang first-pass langsung dengan LM yang bertentangan dengan penyelamatan seperti pada [Graves & Jaitly, 2014]
o [Miao et al., 2015]: Kerangka kerja EESEN untuk decoding dengan WFSTs, toolkit open source
• Pelatihan skala besar pada GPU; Augmentasi Data beberapa bahasa
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: Pelatihan GPU skala besar; Augmentasi Data; Mandarin dan Inggris
• Penggunaan unit panjang: kata dan bukan karakter
o [Soltau et al., 2017]: Target CTC tingkat-kata, dilatih selama 125.000 jam bicara. Kinerja mendekati atau lebih baik daripada sistem konvensional, bahkan tanpa menggunakan LM!
o [Audhkhasi et al., 2017]: Model Akustik-ke-Kata Langsung pada Switchboard
Perlu memperhatikan penerapan DeepSpeach sebagai contoh yang baik dari solusi CTC end2end dan untuk variasi yang menggunakan level verbal. Tapi ada satu peringatan: untuk melatih model seperti itu, Anda perlu 125 ribu jam data berlabel, yang sebenarnya cukup banyak dalam kenyataan pahit.
Yang penting diperhatikan tentang STS
- Masalah atau kelalaian. Untuk efisiensi, penting untuk membuat asumsi tentang independensi. Artinya, STS mengasumsikan bahwa output jaringan dalam bingkai yang berbeda tergantung kondisi, yang sebenarnya salah. Tetapi asumsi ini dibuat untuk menyederhanakan, tanpa itu, semuanya menjadi jauh lebih rumit.
- Untuk mencapai kinerja yang baik dari model STS, penggunaan model bahasa eksternal diperlukan, karena decoding serakah langsung tidak berfungsi dengan baik.
Perhatian
Apa alternatif yang kita miliki untuk STS ini? Mungkin bukan rahasia bagi siapa pun bahwa ada yang namanya Perhatian atau "Perhatian", yang merevolusi sampai batas tertentu dan langsung beralih dari tugas penerjemahan mesin. Dan sekarang sebagian besar dari semua keputusan pemodelan urutan-urutan didasarkan pada mekanisme ini. Seperti apa dia? Mari kita coba mencari tahu. Untuk pertama kalinya tentang Perhatian dalam tugas pengenalan ucapan, publikasi muncul pada tahun 2015. Seseorang Chen dan Cherowski menerbitkan dua publikasi yang serupa dan berbeda pada saat yang sama.
Mari kita memikirkan yang pertama - ini disebut Dengarkan, hadiri, dan eja. Dalam simulasi klasik kami, dalam urutan di mana kami memiliki encoder dan decoder, elemen lain ditambahkan, yang disebut perhatian. Echnoder akan melakukan fungsi yang digunakan model akustik. Tugasnya adalah mengubah input ucapan menjadi fitur akustik tingkat tinggi. Dekoder kami akan melakukan tugas-tugas yang sebelumnya kami lakukan model bahasa dan model pengucapan (leksikon), itu akan secara otomatis memprediksi setiap token keluaran, sebagai fungsi dari yang sebelumnya. Dan perhatian itu sendiri akan secara langsung mengatakan frame input mana yang paling relevan / penting untuk memprediksi output ini.
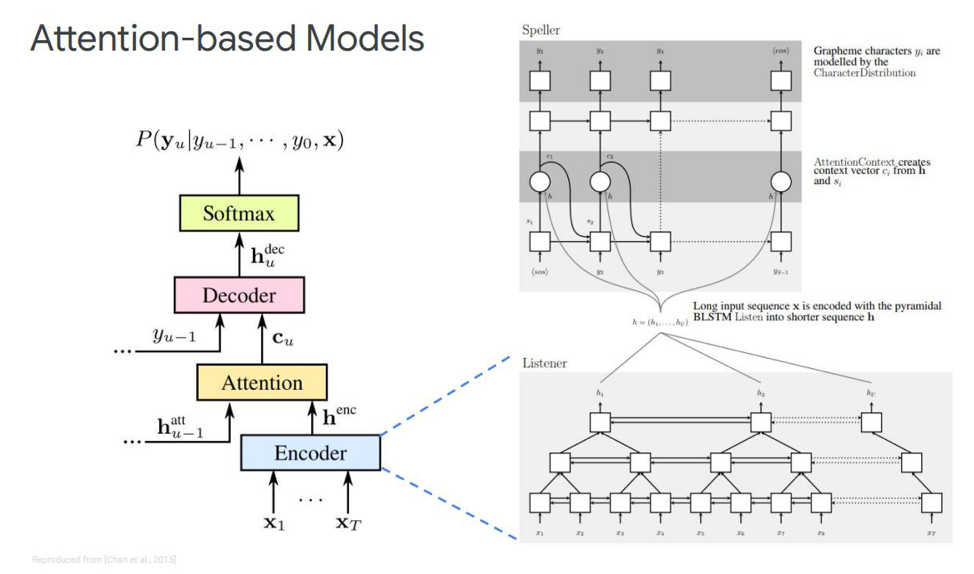
Apa saja blok ini? Eco-encoder dalam artikel ini digambarkan sebagai pendengar, itu adalah RNN dua arah klasik berdasarkan LSTMs atau sesuatu yang lain. Secara umum, tidak ada yang baru - sistem hanya mensimulasikan urutan input ke fitur yang kompleks.
Perhatian, di sisi lain, menciptakan vektor konteks C tertentu dari vektor-vektor ini, yang akan membantu memecahkan kode decoder secara langsung, decoder itu sendiri, yang, misalnya, juga beberapa LSTM yang akan diterjemahkan ke dalam urutan input dari lapisan perhatian ini, yang telah menyoroti tanda-tanda keadaan paling penting, beberapa urutan output karakter.
Ada juga representasi berbeda dari Perhatian ini sendiri - yang merupakan perbedaan antara dua publikasi yang dikeluarkan oleh Chen dan Charowski. Mereka menggunakan Perhatian yang berbeda. Chen menggunakan Perhatian dot-produk, dan Charowski menggunakan Additive Attention.

Ke mana harus pergi selanjutnya?
Ini adalah plus atau minus semua pencapaian utama yang diterima hingga saat ini dalam hal pengenalan ucapan non-online. Perbaikan apa yang mungkin dilakukan di sini? Ke mana harus pergi selanjutnya? Yang paling jelas adalah penggunaan model pada potongan kata daripada menggunakan grapheme secara langsung. Ini bisa berupa beberapa morfem yang terpisah atau sesuatu yang lain.
Apa motivasi untuk menggunakan kata slice? Biasanya, model bahasa tingkat verbal memiliki kebingungan jauh lebih sedikit dibandingkan dengan tingkat grafik. Memodelkan potongan kata memungkinkan Anda membangun dekoder model bahasa yang lebih kuat. Dan memodelkan elemen yang lebih lama dapat meningkatkan efisiensi memori dalam decoder berdasarkan LSTMs. Ini juga memungkinkan Anda untuk berpotensi mengingat kemunculan kata-kata frekuensi. Elemen yang lebih panjang memungkinkan decoding dalam beberapa langkah, yang secara langsung mempercepat inferensi model ini.
Selain itu, model potongan kata memungkinkan kita untuk menyelesaikan masalah kata OOV (out of vocabulary) yang muncul dalam model bahasa, karena kita dapat memodelkan kata apa saja menggunakan potongan kata. Dan perlu dicatat bahwa model-model semacam itu dilatih untuk memaksimalkan kemungkinan model bahasa dibandingkan set data pelatihan. Model-model ini tergantung pada posisi, dan kita dapat menggunakan algoritma serakah untuk decoding.
Perbaikan apa lagi selain model potongan kata yang bisa dilakukan? Ada mekanisme yang disebut multi-head attention. Ini pertama kali dijelaskan pada tahun 2017 untuk terjemahan mesin. Perhatian multi-kepala menyiratkan suatu mekanisme yang memiliki beberapa yang disebut kepala yang memungkinkan Anda untuk menghasilkan distribusi yang berbeda dari perhatian yang sama ini, yang meningkatkan hasil secara langsung.
Model online
Kami beralih ke bagian yang paling menarik - ini adalah model online. Penting untuk dicatat bahwa LAS tidak mengalir. Artinya, model ini tidak dapat bekerja dalam mode decoding online. Kami akan mempertimbangkan dua model online paling populer saat ini. RNN Transduser dan Neural Transducer.
Transduser RNN diusulkan oleh Graves pada 2012-2017. Gagasan utamanya adalah menyulitkan model STS kami sedikit dengan bantuan model rekursif.
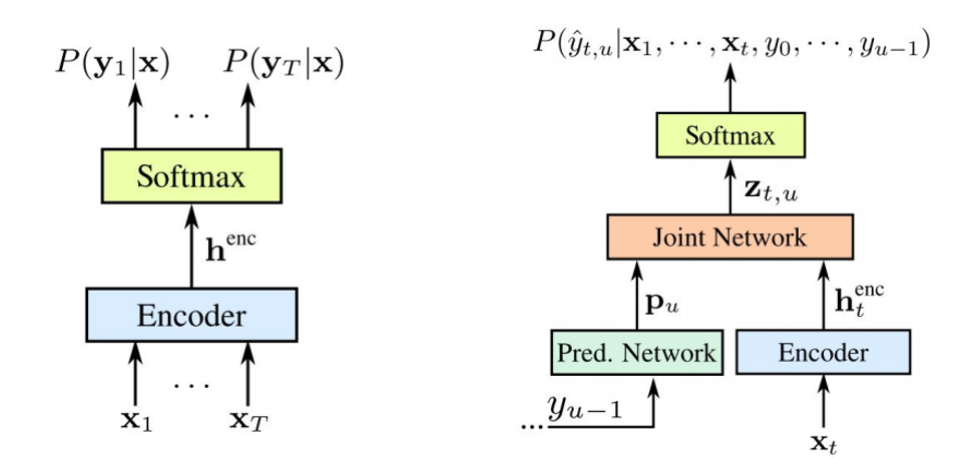
Perlu dicatat bahwa kedua komponen dilatih bersama tentang data akustik yang tersedia. Seperti STS, pendekatan ini tidak memerlukan perataan bingkai dalam set data pelatihan. Seperti yang kita lihat dalam gambar: di sebelah kiri adalah STS klasik kami, dan di sebelah kanan adalah Transduser RNN. Dan kami memiliki dua elemen baru -
Jaringan Terprediksi dan
Jaringan Gabung .
Encoder STS persis sama - ini adalah level input RNN, yang menentukan distribusi atas semua keberpihakan dengan semua urutan output yang tidak melebihi panjang urutan input - ini dijelaskan oleh Graves pada 2006. Namun, tugas konversi text-to-speech tersebut juga dikecualikan, di mana urutan input lebih panjang dari urutan input dari STS tidak memodelkan hubungan antara output. Transduser memperluas STS ini, menentukan distribusi urutan output dari semua panjang dan bersama-sama memodelkan ketergantungan input-output dan output-output.
Ternyata model kami pada akhirnya mampu menangani ketergantungan output dari input dan output dari output dari langkah terakhir.
Jadi apa itu
Jaringan Prediksi atau jaringan prediktif? Dia mencoba mensimulasikan setiap elemen dengan mempertimbangkan elemen sebelumnya, oleh karena itu, ini mirip dengan RNN standar dengan peramalan langkah selanjutnya. Hanya dengan kemampuan ditambahkan untuk melakukan hipotesis nol.
Seperti yang kita lihat dalam gambar, kita memiliki Jaringan yang Diprediksi, yang menerima nilai output sebelumnya, dan ada Encoder, yang menerima nilai input saat ini. Dan pada output kita lagi, memiliki nilai saat ini
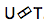
.
Transduser saraf . Ini adalah komplikasi dari pendekatan seq-2seq klasik. Urutan akustik input diproses oleh encoder untuk membuat vektor keadaan tersembunyi pada setiap langkah waktu. Semua tampak seperti biasa. Tetapi ada elemen Transduser tambahan yang menerima blok input pada setiap langkah dan menghasilkan hingga token M-output menggunakan model berbasis seq-2seq di atas input ini. Transduser mempertahankan kondisinya dalam blok dengan menggunakan koneksi periodik dengan langkah waktu sebelumnya.
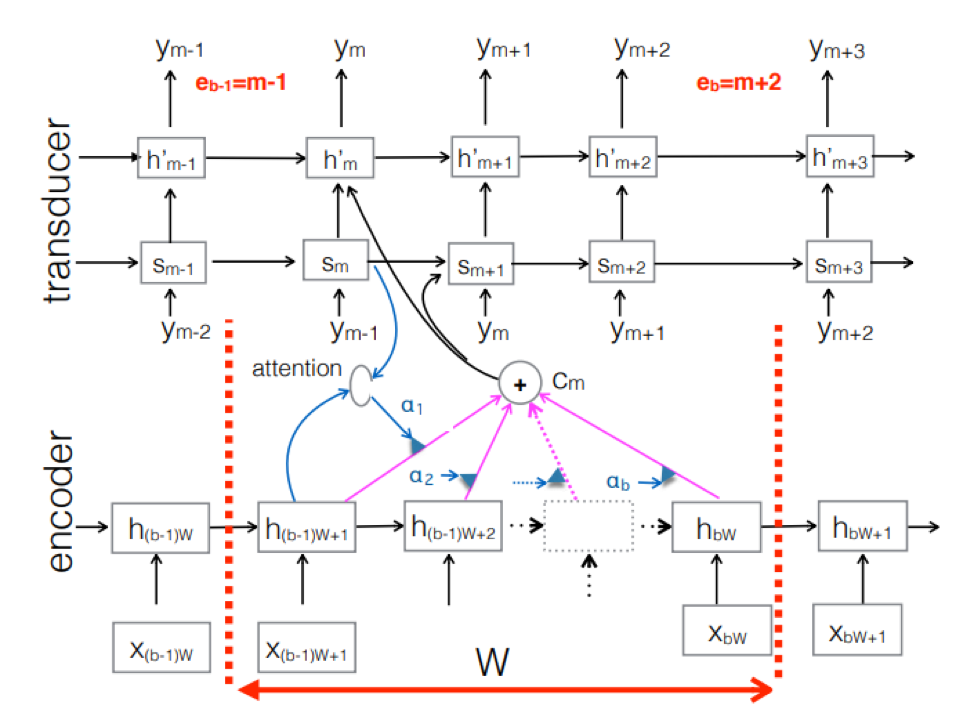 Gambar menunjukkan Transduser, menghasilkan token untuk blok untuk urutan yang digunakan dalam blok Ym yang sesuai.
Gambar menunjukkan Transduser, menghasilkan token untuk blok untuk urutan yang digunakan dalam blok Ym yang sesuai.Jadi, kami memeriksa keadaan pengenalan ucapan saat ini berdasarkan pendekatan End2End. Perlu dikatakan bahwa, sayangnya, pendekatan ini saat ini membutuhkan sejumlah besar data. Dan hasil nyata yang dicapai oleh pendekatan klasik, membutuhkan 200 hingga 500 jam rekaman suara yang ditandai untuk melatih model yang baik berdasarkan End2End, akan membutuhkan beberapa, atau mungkin puluhan kali lebih banyak data. Sekarang ini adalah masalah terbesar dengan pendekatan ini. Tapi mungkin sebentar lagi semuanya akan berubah.
Pengembang terkemuka pusat AI MTS Nikita Semenov.