
Halo semuanya! Baru-baru ini, webinar terbuka
"Menyediakan penyimpanan yang tahan terhadap kesalahan" diadakan . Ini memeriksa masalah apa yang muncul dalam desain arsitektur, mengapa kegagalan server bukan alasan untuk server crash dan bagaimana mengurangi downtime seminimal mungkin. Webinar ini diselenggarakan oleh
Ivan Remen , kepala pengembangan server di Citimobil dan seorang guru dalam kursus
“Arsitek Beban
Tinggi” .
Mengapa repot dengan ketahanan penyimpanan?
Berpikir tentang ketahanan penyimpanan yang dapat diskalakan dan memahami masalah-masalah caching dasar harus
pada tahap startup . Jelas bahwa ketika Anda menulis startup, di awal Anda membuat versi minimum produk. Tetapi semakin Anda tumbuh, semakin cepat Anda mengalami produktivitas, yang dapat menyebabkan berhenti totalnya bisnis. Dan jika Anda mendapatkan uang dari investor, maka, tentu saja, mereka juga akan membutuhkan pertumbuhan konstan dan fitur bisnis baru. Untuk menemukan keseimbangan yang tepat, Anda harus memilih antara kecepatan dan kualitas. Pada saat yang sama, Anda tidak dapat mengorbankan satu atau yang lain, dan jika Anda berkorban - maka secara sadar dan dalam batas-batas tertentu. Namun, tidak ada resep universal di sini, serta solusi ideal.
Kami bersandar pada dasar untuk membaca
Ini adalah skenario pertama. Bayangkan kita memiliki 1 server, beban pada prosesor atau hard drive yang 99%. Dalam hal ini:
- 90% permintaan dibaca;
- 10% permintaan adalah catatan.
Solusi terbaik dalam situasi ini adalah memikirkan replika. Mengapa Ini adalah solusi termurah dan termudah.
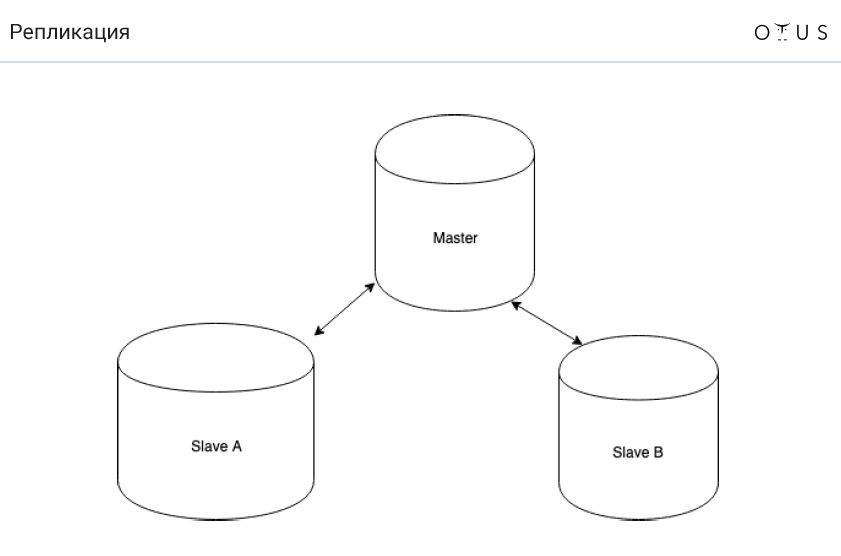
Replikasi diklasifikasikan:
1. Dengan sinkronisasi:
- sinkron;
- tidak sinkron;
- semi-sinkron.
2. Menurut data portabel:
- logis (berbasis baris, berbasis pernyataan, campuran);
- fisik.
3. Dengan jumlah node per catatan:
- tuan / budak;
- master / master
4. Oleh inisiator:
Dan sekarang
tugasnya adalah tentang seember air . Bayangkan kita memiliki replikasi master-slave MySQL dan asynchronous. Pembersihan sedang berlangsung di DC, sebagai akibatnya pembersih tersandung dan menuangkan seember air di server dengan pangkalan utama. Otomasi berhasil mengalihkan salah satu mode slave ke master terbaru. Dan semuanya terus bekerja. Di mana tangkapannya?
Jawabannya sederhana - kami kehilangan transaksi yang tidak berhasil kami tiru. Akibatnya, properti D dari ACID dilanggar.
Sekarang mari kita bicara tentang cara replikasi asinkron (MySQL) bekerja:
- merekam transaksi ke mesin penyimpanan (InnoDB);
- merekam transaksi dalam log biner;
- penyelesaian transaksi di mesin penyimpanan;
- konfirmasi pengembalian kepada pelanggan;
- mentransfer sebagian log ke replika;
- pelaksanaan transaksi pada replika (hlm. 1-3).
Dan sekarang pertanyaannya adalah, apa yang perlu diubah dalam paragraf di atas agar kita tidak pernah berakhir dengan replikasi?
Dan hanya dua poin yang perlu dipertukarkan: 4 dan 5 (“mentransfer sebagian log ke replika” dan “mengembalikan konfirmasi kepada klien”). Jadi, jika master node terbang keluar, kita akan selalu memiliki log transaksi di suatu tempat (poin 2). Dan jika transaksi dicatat dalam log biner, maka transaksi juga akan terjadi kapan-kapan.
Hasilnya, kami mendapatkan replikasi semi-sinkron (MySQL), yang berfungsi sebagai berikut:
- merekam transaksi ke mesin penyimpanan (InnoDB);
- merekam transaksi dalam log biner;
- penyelesaian transaksi di mesin penyimpanan;
- mentransfer sebagian log ke replika;
- konfirmasi pengembalian kepada pelanggan;
- pelaksanaan transaksi pada replika (hlm. 1-3).
Sinkronisasi vs semi-sinkronisasi dan async vs semi-sinkronisasi
Untuk beberapa alasan, di Rusia, kebanyakan orang belum pernah mendengar tentang replikasi semi-sinkron. By the way, ini diterapkan dengan baik di PostgreSQL dan tidak terlalu di MySQL. Baca lebih lanjut tentang ini di
sini , tetapi tesis dapat dirumuskan sebagai berikut:
- replikasi semi-sinkron masih di belakang (tetapi tidak sebanyak) sebagai asinkron;
- kami tidak kehilangan transaksi;
- itu cukup untuk membawa data hanya ke satu budak.
Omong-omong, replikasi semi-sinkron digunakan di Facebook.
Kami bersandar pada basis rekor
Mari kita bicara tentang masalah yang berlawanan secara diametris ketika kita memiliki:
- 90% dari permintaan - catatan;
- 10% permintaan dibaca;
- 1 server;
- memuat - 99% (prosesor atau hard disk).
Pecahan yang terkenal datang untuk menyelamatkan di sini. Tapi sekarang mari kita bicara tentang hal lain:

Sangat sering dalam kasus seperti itu, mereka mulai menggunakan master-master. Namun,
itu tidak membantu dalam situasi ini . Mengapa Sederhana: catatan di server tidak menjadi lebih kecil. Bagaimanapun, replikasi menyiratkan bahwa ada data pada semua node. Dengan replikasi berbasis pernyataan, pada dasarnya, SQL akan berjalan pada SEMUA node. Berbasis baris C sedikit lebih mudah, tetapi masih mahal. Dan juga master-master memiliki masalah dengan konflik.
Bahkan, masuk akal untuk menggunakan master-master dalam situasi berikut:
- toleransi kesalahan tulis-tulis (idenya adalah bahwa Anda selalu menulis hanya kepada satu master). Anda dapat menerapkan menggunakan alamat IP Virtual ;
- sistem geo-didistribusikan.
Namun, ingat bahwa replikasi master-master selalu sulit. Dan seringkali master-master membawa lebih banyak masalah daripada menyelesaikannya.
Sharding
Kami telah menyebutkan sharding. Singkatnya, sharding adalah cara ampuh untuk skala catatan. Idenya adalah bahwa kami mendistribusikan data di server independen (tetapi tidak selalu). Setiap pecahan dapat mereplikasi secara independen.
Aturan pertama dari sharding adalah bahwa data yang digunakan bersama harus dalam shard yang sama. Formula
sharding_key -> shard_id bekerja di
sharding_key -> shard_id . Dengan demikian,
sharding_key untuk data yang digunakan bersama harus cocok. Kesulitan pertama adalah bahwa jika Anda memilih
sharding_key salah, maka akan sangat sulit bagi Anda untuk mengacak ulang semuanya. Kedua, jika Anda memiliki semacam
sharding_key , beberapa permintaan akan sangat sulit dieksekusi. Misalnya, Anda tidak dapat menemukan nilai rata-rata.
Untuk menunjukkan ini, mari kita bayangkan bahwa kita memiliki dua pecahan dengan tiga nilai di masing-masing: (1; 2; 3) (0; 0; 500). Nilai rata-rata akan sama dengan (1 + 2 + 3 + 500) / 6 = 84.33333.
Sekarang bayangkan kita memiliki dua server independen. Dan hitung ulang nilai rata-rata secara terpisah untuk setiap pecahan. Yang pertama kita dapatkan 2, yang kedua - 166.66667. Dan bahkan jika kita kemudian nilai rata-rata ini, kita masih akan mendapatkan angka yang akan berbeda dari yang benar: (2 + 166.66667) / 2 = 86.33334.
Artinya,
rata -
rata sarana tidak sama dengan rata-rata segalanya: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Matematika sederhana, tetapi penting untuk diingat.
Tugas sharding
Misalkan kita memiliki sistem dialog di jejaring sosial. Hanya ada 2 orang dalam dialog. Semua pesan berada dalam satu tabel, di mana ada:
- ID pesan
- ID pengirim
- ID Penerima
- teks pesan;
- tanggal pesan dikirim;
- beberapa bendera.
Apa kunci sharding yang harus dipilih berdasarkan fakta bahwa kita memiliki aturan sharding pertama yang dijelaskan di atas?
Ada beberapa opsi untuk menyelesaikan masalah klasik ini:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (dari + ke)% n;
- crc32 (min (dari, ke) .maks (dari, ke))% n.
Cache
Dan beberapa kata tentang cache. Kita dapat mengatakan bahwa
cache adalah antipattern , meskipun orang dapat membantah pernyataan ini (banyak orang suka menggunakan cache). Tetapi pada umumnya, cache hanya diperlukan untuk meningkatkan tingkat respons. Dan mereka tidak dapat diatur untuk menahan beban.
Kesimpulannya sederhana - kita harus hidup dengan tenang tanpa cache. Satu-satunya alasan mereka diperlukan adalah untuk alasan yang persis sama mengapa mereka diperlukan dalam prosesor: untuk meningkatkan kecepatan respons. Jika database tidak menahan beban karena cache menghilang, ini buruk. Ini adalah pola arsitektur yang sangat tidak berhasil, jadi seharusnya tidak demikian. Dan sumber daya apa pun yang Anda miliki, suatu hari nanti cache Anda pasti akan jatuh, apa pun yang Anda lakukan.
Masalah cache adalah tesis:- mulai dengan cache yang dingin;
- masalah pembatalan cache;
- konsistensi cache.
Jika Anda masih menggunakan cache, hashing yang konsisten akan membantu Anda. Ini adalah cara untuk membuat tabel hash terdistribusi, di mana kegagalan satu atau lebih server penyimpanan tidak menyebabkan perlunya relokasi lengkap dari semua kunci dan nilai yang tersimpan. Namun, Anda dapat membaca lebih lanjut tentang ini di
sini .

Terima kasih sudah menonton! Agar tidak ketinggalan apa pun dari kuliah terakhir, lebih baik untuk
menonton seluruh webinar .