
Ini adalah instruksi langkah demi langkah untuk klasifikasi citra multispektral dari satelit Landsat 5. Saat ini, di sejumlah area, pembelajaran mendalam mendominasi sebagai alat untuk memecahkan masalah yang kompleks, termasuk yang geospasial. Saya harap Anda terbiasa dengan dataset satelit, khususnya, Landsat 5 TM. Jika Anda sedikit terbiasa dengan algoritma pembelajaran mesin, ini akan membantu Anda dengan cepat mempelajari manual ini. Dan bagi mereka yang tidak mengerti, itu akan cukup untuk mengetahui bahwa, pada kenyataannya, pembelajaran mesin terdiri dalam membangun hubungan antara beberapa karakteristik (seperangkat atribut X) dari suatu objek dengan properti lainnya (nilai atau label, variabel target Y). Kami memberi makan model dengan banyak objek yang karakteristik dan nilai indikator target / kelas objek (data berlabel) diketahui dan melatihnya sehingga dapat memprediksi nilai variabel target Y untuk data baru (tidak ditandai).
Apa masalah utama dengan citra satelit?
Dua atau lebih kelas objek (misalnya, bangunan, tanah kosong, dan lubang pondasi) dalam citra satelit dapat memiliki karakteristik spektral nilai yang sama, oleh karena itu, dalam dua puluh tahun terakhir, klasifikasi mereka merupakan tugas yang sulit.
Karena itu, dimungkinkan untuk menggunakan model pembelajaran mesin klasik dengan dan tanpa guru, tetapi kualitasnya akan jauh dari ideal. Mereka selalu memiliki kekurangan yang sama. Pertimbangkan sebuah contoh:

Jika Anda menggunakan garis vertikal sebagai classifier dan memindahkannya di sepanjang sumbu X, maka mengklasifikasikan gambar rumah tidak akan mudah. Data didistribusikan sehingga tidak mungkin untuk memisahkan mereka ke dalam kelas menggunakan satu garis vertikal (dalam kasus seperti itu dikatakan bahwa "objek dari kelas yang berbeda tidak dapat dipisahkan secara linear"). Tetapi ini tidak berarti bahwa rumah tidak dapat diklasifikasikan sama sekali!
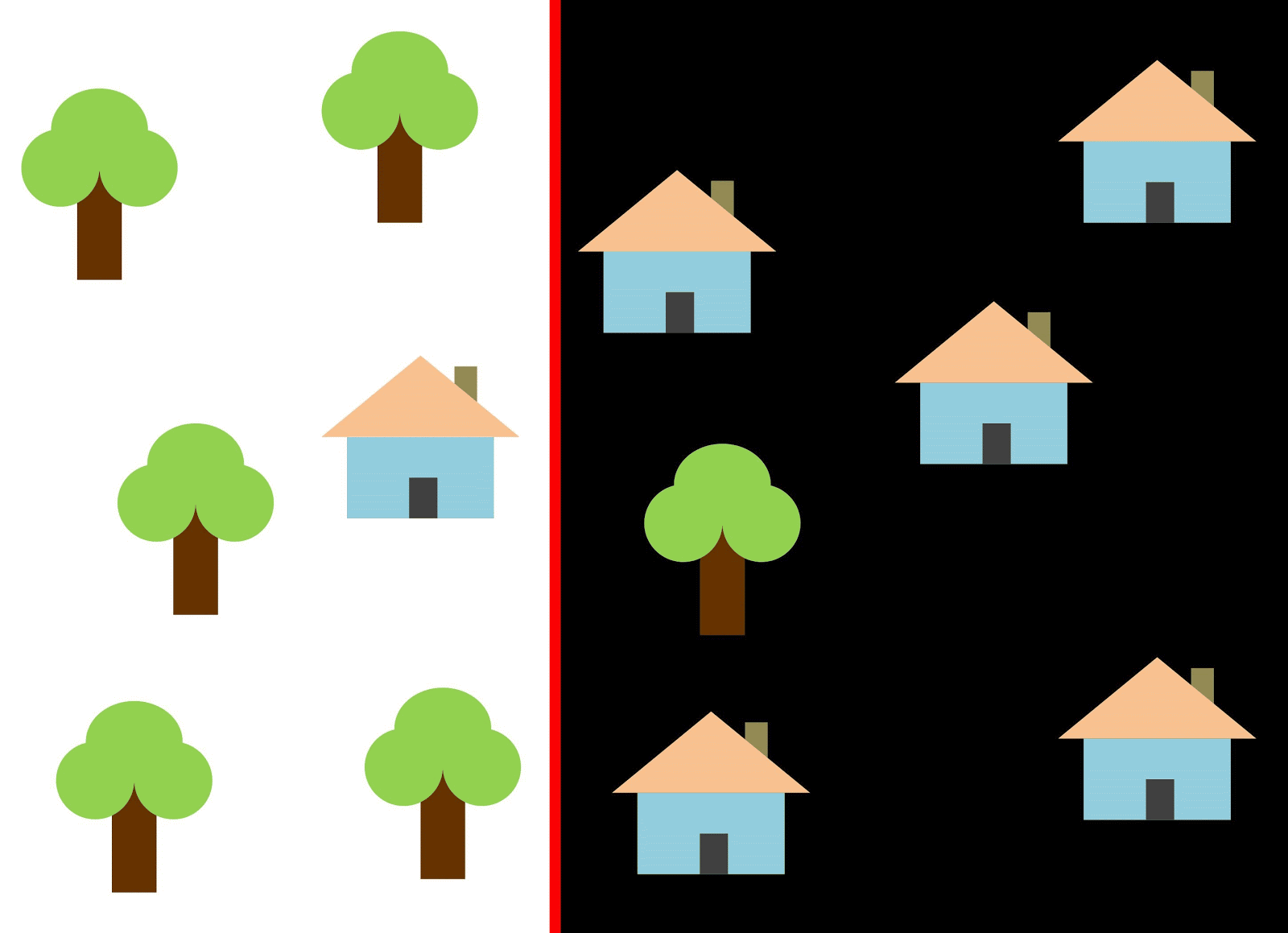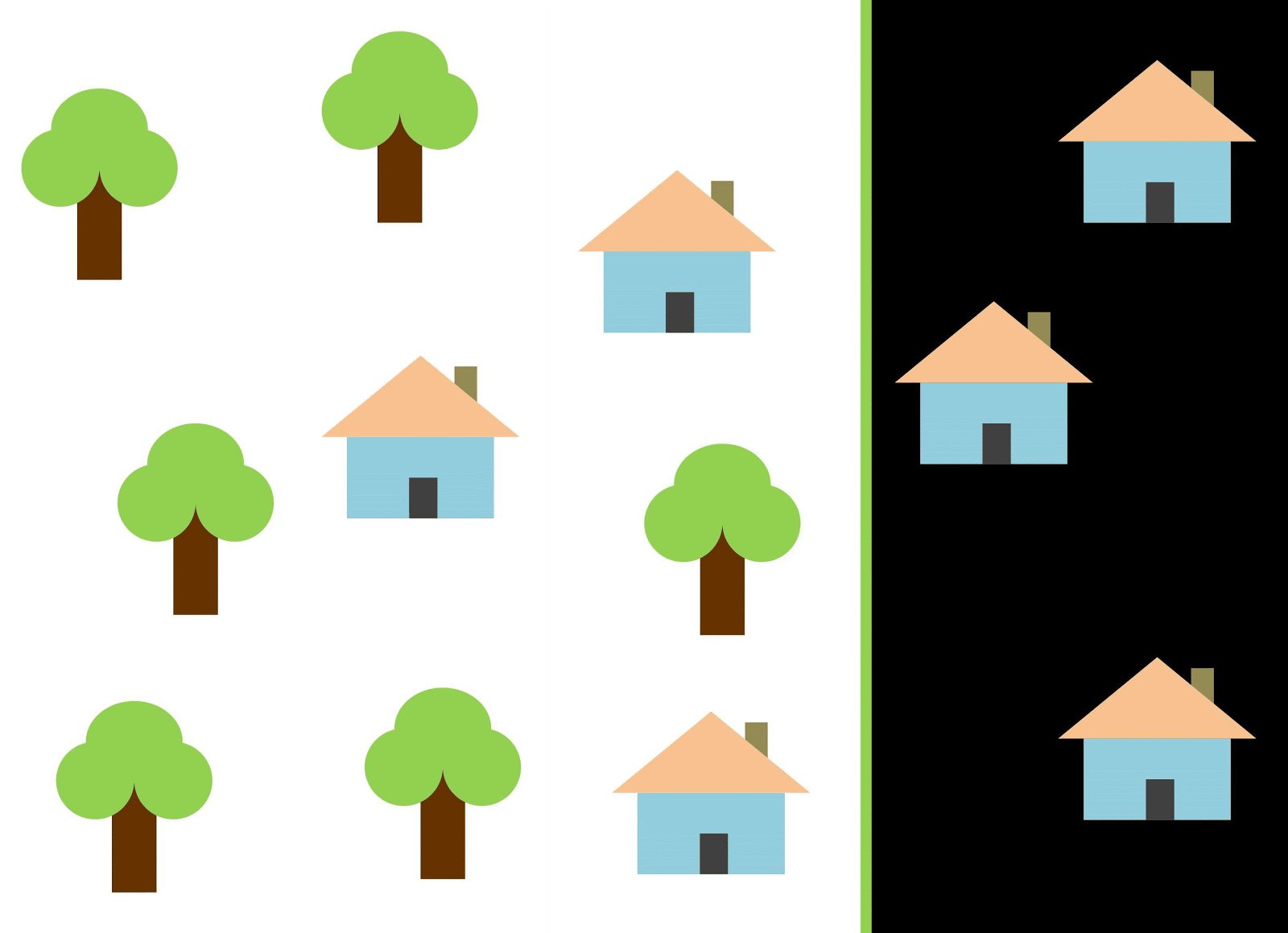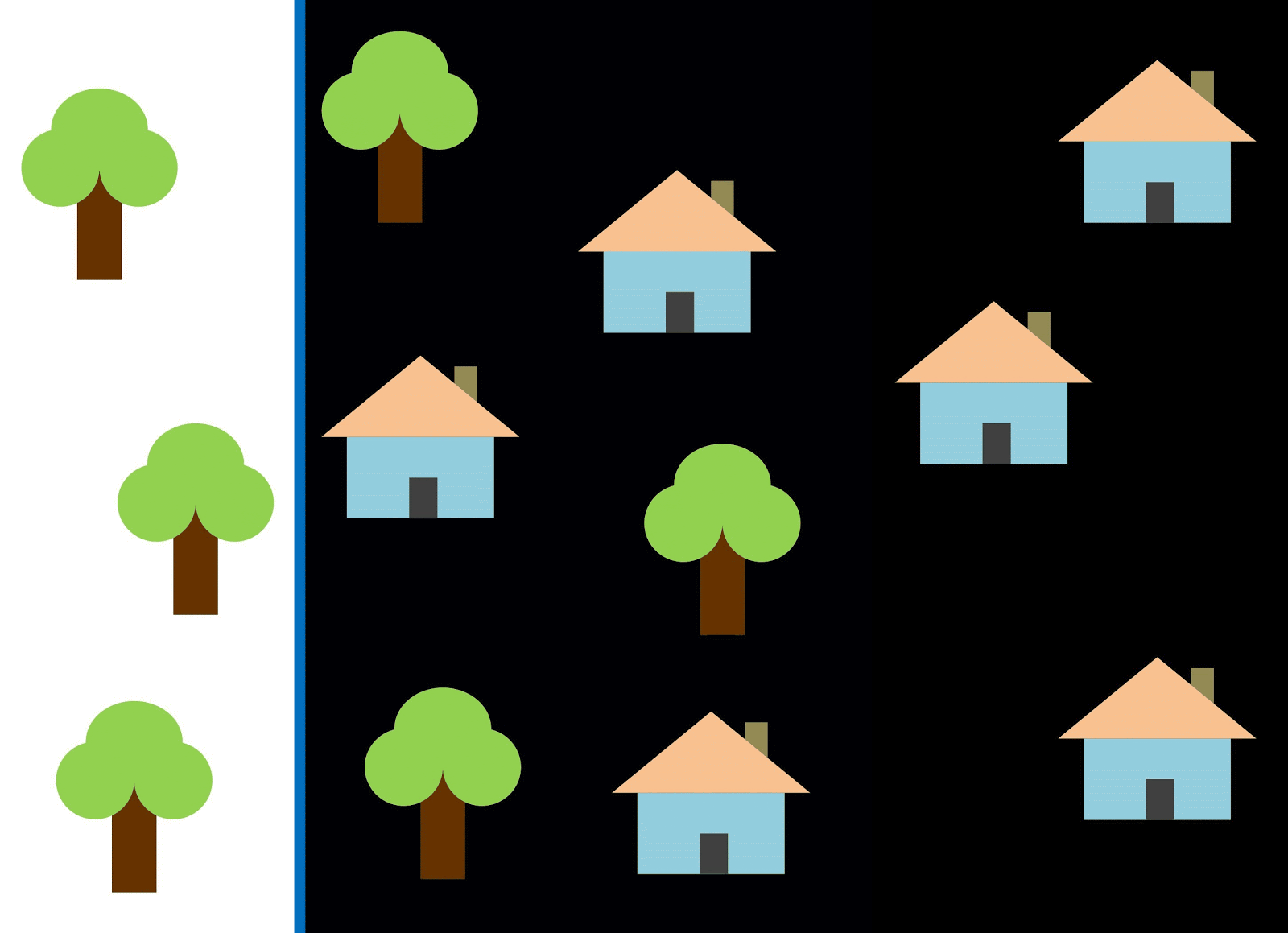
Mari kita gunakan garis merah untuk memisahkan dua kelas. Dalam hal ini, penggolong mengidentifikasi sebagian besar rumah, tetapi satu rumah tidak ditugaskan ke kelasnya, dan tiga pohon lagi secara keliru ditugaskan ke "rumah". Agar tidak ketinggalan satu rumah, Anda dapat menggunakan classifier dalam bentuk garis biru. Maka semuanya akan dibahas di rumah, yaitu, kita katakan bahwa metrik recall (kepenuhan) tinggi. Namun, tidak semua nilai yang diklasifikasikan ternyata rumah, yaitu, pada saat yang sama kami mendapat nilai rendah dari metrik presisi. Jika kita menggunakan garis hijau, maka semua gambar yang diklasifikasikan sebagai rumah akan benar-benar rumah, yaitu, penggolong akan menunjukkan akurasi yang tinggi. Dalam hal ini, kepenuhannya akan lebih sedikit, karena ketiga rumah tersebut akan dilupakan. Dalam kebanyakan kasus, kita harus menemukan kompromi antara akurasi dan kelengkapan.
Masalah rumah dan pohon ini mirip dengan masalah bangunan, tanah kosong, dan lubang. Prioritas metrik klasifikasi citra satelit dapat bervariasi tergantung pada tugas. Misalnya, jika Anda perlu memastikan bahwa semua wilayah yang dibangun diklasifikasikan sebagai bangunan tanpa kecuali, dan Anda siap untuk memasang piksel kelas lain dengan tanda tangan serupa, yang juga akan diklasifikasikan sebagai bangunan, maka Anda akan memerlukan model dengan kelengkapan tinggi. Dan jika lebih penting bagi Anda untuk mengklasifikasikan bangunan, tanpa menambahkan piksel dari kelas lain, dan Anda siap untuk meninggalkan klasifikasi wilayah campuran, maka pilihlah classifier dengan akurasi tinggi. Dalam kasus rumah dan pohon, model yang biasa akan menggunakan garis merah, menjaga keseimbangan antara akurasi dan kelengkapan.
Data yang digunakan
Sebagai tanda, kita akan menggunakan nilai enam rentang (pita 2 - pita 7) gambar dari Landsat 5 TM, dan mencoba memprediksi kelas pengembangan biner. Untuk pelatihan dan pengujian, data multispektral (gambar dan lapisan dengan kelas bangunan biner) dengan Landsat 5 untuk 2011 untuk Bangalore akan digunakan. Dan untuk prediksi akan digunakan data Landsat 5 multispektral yang diperoleh pada tahun 2005 di Hyderabad.
Karena kami menggunakan data yang ditandai untuk mengajar, ini disebut mengajar dengan guru.
 Data pelatihan multispektral dan lapisan biner terkait dengan pengembangan.
Data pelatihan multispektral dan lapisan biner terkait dengan pengembangan.Untuk membuat jaringan saraf, kita akan menggunakan Python - perpustakaan Google Tensorflow. Kami juga membutuhkan perpustakaan ini:
- pyrsgis - untuk membaca dan menulis GeoTIFF.
- scikit-learn - untuk preprocessing data dan penilaian akurasi.
- numpy - untuk operasi dasar dengan array.
Dan sekarang, tanpa basa-basi lagi, mari kita menulis kode.
Masukkan ketiga file dalam direktori, tulis jalur dan nama file input dalam skrip, dan kemudian baca file GeoTIFF.
import os from pyrsgis import raster os.chdir("E:\\yourDirectoryName") mxBangalore = 'l5_Bangalore2011_raw.tif' builtupBangalore = 'l5_Bangalore2011_builtup.tif' mxHyderabad = 'l5_Hyderabad2011_raw.tif'
Modul
raster dari paket
pyrsgis membaca data geolokasi GeoTIFF dan nilai nomor digital (DN) sebagai array NumPy yang terpisah. Jika Anda tertarik pada detail, baca di
sini .
Sekarang kami menampilkan ukuran data yang dibaca.
print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Hasil:
Bangalore multispectral image shape: 6, 2054, 2044 Bangalore binary built-up image shape: 2054, 2044 Hyderabad multispectral image shape: 6, 1318, 1056
Seperti yang Anda lihat, gambar Bangalore memiliki jumlah baris dan kolom yang sama seperti pada layer biner (sesuai dengan bangunan). Jumlah lapisan dalam gambar multispektral di Bangalore dan Hyderabad juga bersamaan. Model akan belajar menentukan piksel mana yang termasuk dalam bangunan dan mana yang tidak, berdasarkan nilai yang sesuai untuk semua 6 spektrum. Oleh karena itu, gambar multispektral harus memiliki jumlah fitur (rentang) yang sama yang tercantum dalam urutan yang sama.
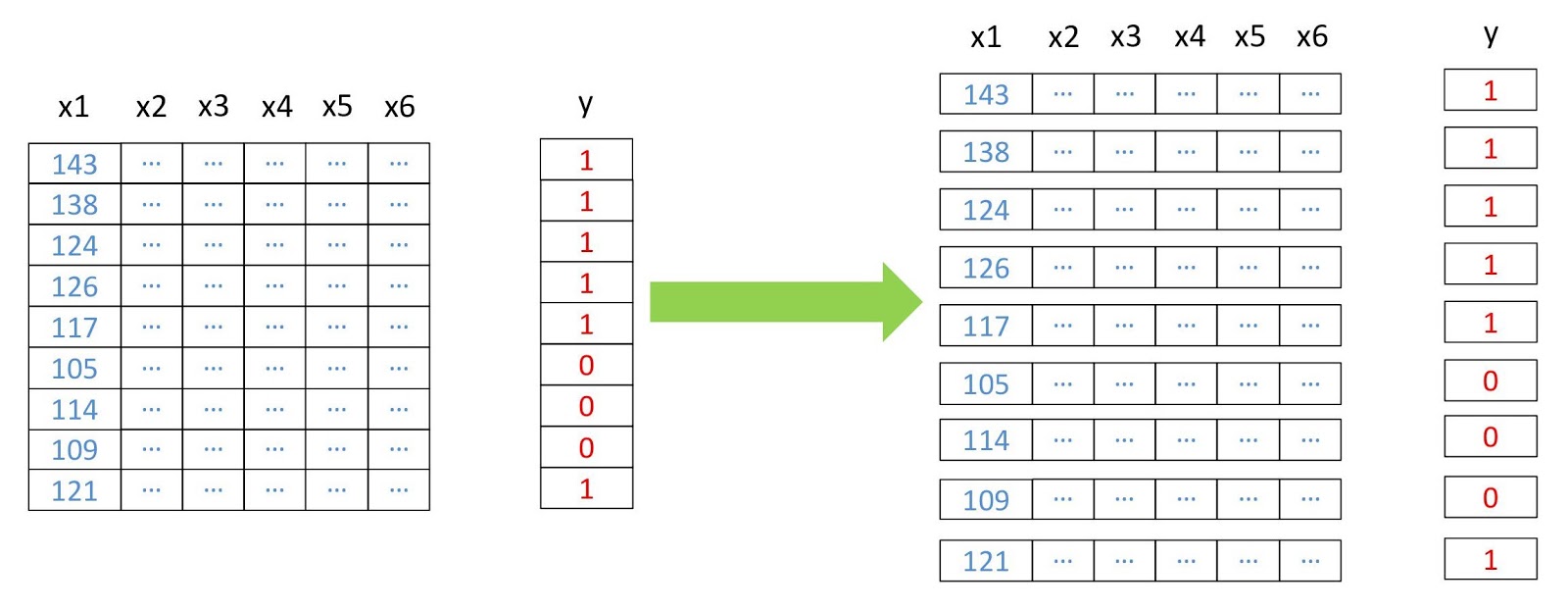
Sekarang kita mengubah array menjadi dua dimensi, di mana setiap baris mewakili piksel yang terpisah, karena ini diperlukan untuk operasi sebagian besar algoritma pembelajaran mesin. Kami akan melakukan ini menggunakan modul
convert dari paket
pyrsgis .
 Skema restrukturisasi data.
Skema restrukturisasi data. from pyrsgis.convert import changeDimension featuresBangalore = changeDimension(featuresBangalore) labelBangalore = changeDimension (labelBangalore) featuresHyderabad = changeDimension(featuresHyderabad) nBands = featuresBangalore.shape[1] labelBangalore = (labelBangalore == 1).astype(int) print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Hasil:
Bangalore multispectral image shape: 4198376, 6 Bangalore binary built-up image shape: 4198376 Hyderabad multispectral image shape: 1391808, 6
Di baris ketujuh, kami mengekstraksi semua piksel dengan nilai 1. Ini membantu menghindari masalah dengan piksel tanpa informasi (NoData), yang seringkali memiliki nilai sangat tinggi atau rendah.
Sekarang kita akan membagi data menjadi sampel pelatihan dan validasi. Ini diperlukan agar model tidak melihat data uji dan berfungsi dengan baik dengan informasi baru. Jika tidak, model akan dilatih ulang dan hanya akan berfungsi dengan baik pada data pelatihan.
from sklearn.model_selection import train_test_split xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42) print(xTrain.shape) print(yTrain.shape) print(xTest.shape) print(yTest.shape)
Hasil:
(2519025, 6) (2519025,) (1679351, 6) (1679351,) test_size=0.4
berarti bahwa data dibagi menjadi pelatihan dan validasi dalam rasio 60/40.
Banyak algoritma pembelajaran mesin, termasuk jaringan saraf, membutuhkan data yang dinormalisasi. Ini berarti bahwa mereka harus didistribusikan dalam kisaran yang diberikan (dalam hal ini, dari 0 hingga 1). Oleh karena itu, untuk memenuhi persyaratan ini, kami menormalkan gejala. Ini dapat dilakukan dengan mengekstraksi nilai minimum dan kemudian membaginya dengan spread (perbedaan antara nilai maksimum dan minimum). Karena dataset Landsat adalah delapan-bit, nilai minimum dan maksimum akan menjadi 0 dan 255 (2
⁸ = 256 nilai).
Perhatikan bahwa untuk normalisasi selalu lebih baik untuk menghitung nilai minimum dan maksimum berdasarkan data. Untuk menyederhanakan tugas, kami akan mematuhi rentang delapan-bit secara default.
Tahap pra-pemrosesan lainnya adalah transformasi matriks atribut dari dua dimensi menjadi tiga dimensi, sehingga model menganggap setiap baris sebagai piksel terpisah (objek pembelajaran terpisah).
Hasil:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)
Semuanya siap, mari kumpulkan model kita dengan
keras . Untuk memulai, mari kita gunakan model sekuensial, menambahkan lapisan satu demi satu. Kami akan memiliki satu layer input dengan jumlah node yang sama dengan jumlah rentang (
nBands ) - dalam kasus kami ada 6. Kami juga akan menggunakan satu layer tersembunyi dengan 14 node dan
ReLu aktivasi
ReLu . Lapisan terakhir terdiri dari dua node untuk mendefinisikan kelas bangunan biner dengan
softmax aktivasi
softmax , yang cocok untuk menampilkan hasil yang dikategorikan. Baca lebih lanjut tentang fungsi aktivasi di
sini .
from tensorflow import keras
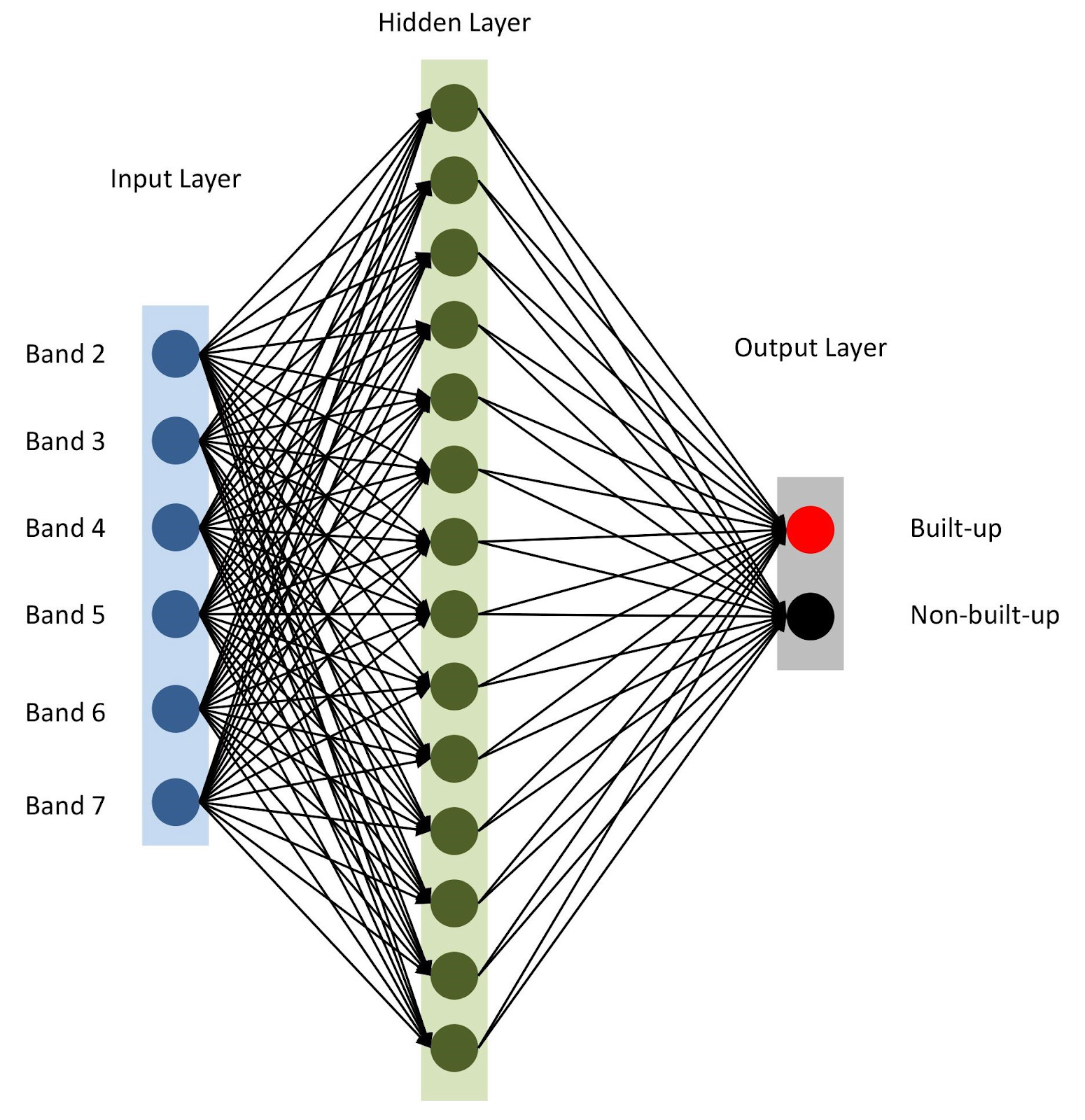 Arsitektur jaringan saraf
Arsitektur jaringan sarafSeperti disebutkan dalam baris 10, kami menetapkan
adam sebagai pengoptimal model (ada beberapa
lainnya ). Dalam hal ini, kita akan menggunakan cross entropy sebagai fungsi kerugian (id.
categorical-sparse-crossentropy - lebih lanjut tentang ini ditulis di
sini ). Untuk menilai kualitas model, kami akan menggunakan metrik
accuracy .
Akhirnya, kita akan mulai melatih model kita untuk dua era (atau iterasi) pada
xTrain dan
yTrain . Ini akan memakan waktu, tergantung pada ukuran data dan kekuatan pemrosesan. Inilah yang akan Anda lihat setelah kompilasi:

Mari kita memprediksi nilai untuk data validasi yang kami simpan secara terpisah dan menghitung berbagai metrik akurasi.
from sklearn.metrics import confusion_matrix, precision_score, recall_score
Fungsi
softmax menghasilkan kolom terpisah untuk nilai probabilitas untuk setiap kelas. Kami hanya menggunakan nilai untuk kelas pertama ("ada bangunan"), seperti yang dapat dilihat dari baris keenam kode di atas. Mengevaluasi pekerjaan model analisis geospasial tidak begitu sederhana, tidak seperti masalah klasik pembelajaran mesin. Tidaklah adil untuk mengandalkan kesalahan total umum. Kunci untuk model yang sukses adalah tata ruang. Dengan demikian, matriks kebingungan, akurasi dan kelengkapan dapat memberikan gagasan yang lebih benar tentang kualitas model.
 Jadi konsol menampilkan matriks kesalahan, akurasi dan kelengkapan.
Jadi konsol menampilkan matriks kesalahan, akurasi dan kelengkapan.Seperti yang dapat Anda lihat dari matriks kebingungan, ada ribuan piksel yang terkait dengan bangunan, tetapi diklasifikasikan secara berbeda, dan sebaliknya. Namun, bagian mereka dari total volume data tidak terlalu besar. Keakuratan dan kelengkapan data uji melebihi ambang batas 0,8.
Anda dapat menghabiskan lebih banyak waktu dan melakukan beberapa iterasi untuk menemukan jumlah optimal lapisan tersembunyi, jumlah node di setiap lapisan tersembunyi, serta jumlah era untuk mencapai akurasi yang diinginkan. Sesuai kebutuhan, indeks penginderaan jauh seperti NDBI atau NDWI dapat digunakan sebagai fitur. Saat mencapai akurasi yang diinginkan, gunakan model untuk memprediksi pengembangan berdasarkan data baru dan ekspor hasilnya ke GeoTIFF. Untuk tugas-tugas seperti itu, Anda dapat menggunakan model serupa dengan perubahan kecil.
predicted = model.predict(feature2005) predicted = predicted[:,1]
Harap perhatikan bahwa kami mengekspor GeoTIFF dengan nilai probabilitas yang diprediksi, dan tidak dengan versi yang dipisah-pindahkan ambangnya. Kemudian di lingkungan GIS, kita dapat mengatur nilai ambang batas dari tipe float, seperti yang ditunjukkan pada gambar di bawah ini.
 Lapisan bawaan Hyderabad diprediksi oleh model berdasarkan data multispektral.
Lapisan bawaan Hyderabad diprediksi oleh model berdasarkan data multispektral.Akurasi model telah diukur dengan presisi dan daya ingat. Anda juga dapat melakukan pemeriksaan tradisional (misalnya, menggunakan koefisien kappa) pada layer yang baru diprediksi. Selain kesulitan yang disebutkan di atas dengan klasifikasi citra satelit, batasan jelas lainnya termasuk ketidakmungkinan perkiraan berdasarkan gambar yang diambil pada waktu yang berbeda dalam setahun dan di wilayah yang berbeda, karena mereka akan memiliki tanda tangan spektral yang berbeda.
Model yang dijelaskan dalam artikel ini memiliki arsitektur paling sederhana untuk jaringan saraf. Hasil yang lebih baik dapat dicapai dengan model yang lebih kompleks, termasuk jaringan saraf convolutional. Keuntungan utama dari klasifikasi tersebut adalah skalabilitasnya (penerapan) setelah pelatihan model.
Data yang digunakan dan semua kode ada di
sini .