
Hai, para pembaca Habr. Dengan artikel ini kami membuka siklus yang akan berbicara tentang sistem hyperconverged AERODISK vAIR yang kami kembangkan. Awalnya, kami ingin artikel pertama menceritakan segalanya tentang segalanya, tetapi sistemnya cukup rumit, jadi kami akan memakan gajah di beberapa bagian.
Mari kita mulai cerita dengan sejarah sistem, masuk lebih dalam ke sistem file ARDFS, yang merupakan dasar dari vAIR, dan juga berbicara sedikit tentang memposisikan solusi ini di pasar Rusia.
Dalam artikel mendatang, kita akan berbicara lebih banyak tentang komponen arsitektur yang berbeda (klaster, hypervisor, load balancer, sistem pemantauan, dll.), Proses konfigurasi, kami akan mengangkat masalah lisensi, secara terpisah menunjukkan tes kerusakan dan, tentu saja, menulis tentang pengujian beban dan ukuran. Kami juga akan menyediakan artikel terpisah untuk versi komunitas vAIR.
Apakah airdisc adalah cerita tentang penyimpanan? Atau mengapa kita bahkan mulai hyperconverging?
Awalnya, ide untuk membuat hyperconvergent kita sendiri muncul di sekitar tahun 2010. Lalu tidak ada Aerodisk dan solusi serupa (sistem komersial kotak hyperconverged) di pasar. Tugas kami adalah sebagai berikut: dari sekumpulan server dengan disk lokal yang terhubung oleh interkoneksi melalui Ethernet, kami harus membuat penyimpanan yang lebih lama dan menjalankan mesin virtual dan jaringan perangkat lunak di tempat yang sama. Semua ini harus diterapkan tanpa sistem penyimpanan (karena tidak ada uang untuk penyimpanan dan bundlingnya, dan kami belum menemukan sistem penyimpanan kami sendiri).
Kami mencoba banyak solusi open source dan masih menyelesaikan masalah ini, tetapi solusinya sangat rumit, dan sulit untuk diulang. Selain itu, keputusan ini berasal dari kategori “Pekerjaan? Jangan disentuh! " Oleh karena itu, setelah menyelesaikan masalah itu, kami tidak mengembangkan gagasan untuk mengubah hasil pekerjaan kami menjadi produk yang lengkap.
Setelah kejadian itu, kami menjauh dari ide ini, tetapi kami masih memiliki perasaan bahwa tugas ini sepenuhnya dapat dipecahkan, dan manfaat dari solusi semacam itu lebih dari jelas. Selanjutnya, produk HCI dari perusahaan asing yang dirilis hanya mengkonfirmasi perasaan ini.
Karenanya, pada pertengahan 2016, kami kembali ke tugas ini sebagai bagian dari penciptaan produk lengkap. Kemudian kami belum memiliki hubungan dengan investor, jadi kami harus membeli dudukan pengembangan untuk uang kami yang tidak terlalu besar. Setelah mengetik di server dan sakelar Avito BU-shyh, kami mulai berfungsi.

Tugas awal utama adalah untuk membuat sendiri, meskipun sederhana, tetapi sistem file Anda sendiri, yang akan dapat secara otomatis dan merata mendistribusikan data dalam bentuk blok virtual pada jumlah node cluster yang terhubung melalui Ethernet. Dalam hal ini, FS harus diskalakan dengan baik dan mudah dan tidak tergantung pada sistem yang berdekatan, mis. diasingkan dari VAIR dalam bentuk "hanya penyimpanan."

VAIR First Concept

Kami sengaja menolak untuk menggunakan solusi open source siap pakai untuk mengatur penyimpanan tambahan (ceph, gluster, kilau dan sejenisnya) yang mendukung pengembangan kami, karena kami sudah memiliki banyak pengalaman proyek dengan mereka. Tentu saja, solusi ini sendiri luar biasa, dan sebelum kami bekerja di Aerodisk, kami menerapkan lebih dari satu proyek integrasi dengan mereka. Tapi itu satu hal untuk mewujudkan tugas khusus dari satu pelanggan, untuk melatih staf dan, mungkin, membeli dukungan untuk vendor besar, dan itu adalah hal lain untuk membuat produk yang mudah direplikasi yang akan digunakan untuk berbagai tugas, yang kita, sebagai vendor, bahkan mungkin tahu sendiri kami tidak akan. Untuk tujuan kedua, produk open source yang ada tidak cocok untuk kami, jadi kami memutuskan untuk melihat sendiri sistem file yang didistribusikan.
Dua tahun kemudian, beberapa pengembang (yang menggabungkan pekerjaan pada vAIR dengan pekerjaan pada Storage Engine klasik) mencapai hasil tertentu.
Pada tahun 2018, kami telah menulis sistem file paling sederhana dan menambahkannya dengan pengikatan yang diperlukan. Sistem mengintegrasikan disk fisik (lokal) dari server yang berbeda ke dalam satu kumpulan datar melalui interkoneksi internal dan "memotongnya" menjadi blok virtual, kemudian memblokir perangkat dengan berbagai tingkat toleransi kesalahan dibuat dari blok virtual, di mana hypervisor KVM virtual dibuat dan dieksekusi mobil.
Kami tidak repot-repot dengan nama sistem file dan secara ringkas menyebutnya ARDFS (tebak bagaimana ia mendekripsi))
Prototipe ini terlihat bagus (tidak secara visual, tentu saja, tidak ada desain visual saat itu) dan menunjukkan hasil yang baik dalam kinerja dan penskalaan. Setelah hasil nyata pertama, kami menetapkan arah untuk proyek ini, setelah mengorganisir lingkungan pengembangan yang lengkap dan tim terpisah yang hanya terlibat dalam vAIR.
Tepat pada saat itu, arsitektur umum dari solusi telah matang, yang sampai sekarang belum mengalami perubahan besar.
Menyelam ke sistem file ARDFS
ARDFS adalah dasar dari vAIR, yang menyediakan penyimpanan failover terdistribusi dari seluruh cluster. Satu (tetapi bukan satu-satunya) fitur ARDFS yang membedakan adalah tidak menggunakan server khusus tambahan untuk meta dan manajemen. Ini pada awalnya dimaksudkan untuk menyederhanakan konfigurasi solusi dan untuk keandalannya.
Struktur penyimpanan
Dalam semua node cluster, ARDFS mengatur kumpulan logis dari semua ruang disk yang tersedia. Penting untuk dipahami bahwa kumpulan belum data dan bukan ruang yang diformat, tetapi hanya markup, yaitu setiap node dengan vAIR yang diinstal ketika ditambahkan ke cluster secara otomatis ditambahkan ke kumpulan ARDFS bersama dan sumber daya disk secara otomatis dibagi di seluruh cluster (dan tersedia untuk penyimpanan data masa depan). Pendekatan ini memungkinkan Anda untuk menambah dan menghapus node dengan cepat tanpa dampak serius pada sistem yang sudah berjalan. Yaitu sistem ini sangat mudah untuk skala dengan "batu bata", menambah atau menghapus node di cluster jika perlu.
Disk virtual (objek penyimpanan untuk mesin virtual) ditambahkan di atas kumpulan ARDFS, yang dibangun dari blok virtual berukuran 4 megabita. Disk virtual menyimpan data secara langsung. Pada tingkat disk virtual, skema toleransi kesalahan juga ditentukan.
Seperti yang mungkin sudah Anda duga, untuk toleransi kesalahan subsistem disk, kami tidak menggunakan konsep RAID (Redundant array of independent Disk), tetapi gunakan RAIN (Redundant array of Independent Nodes). Yaitu toleransi kesalahan diukur, diotomatisasi dan dikelola berdasarkan node, bukan disk. Disk, tentu saja, juga merupakan objek penyimpanan, mereka, seperti yang lainnya, dimonitor, Anda dapat melakukan semua operasi standar dengan mereka, termasuk membangun RAID perangkat keras lokal, tetapi cluster beroperasi dengan node.
Dalam situasi di mana Anda benar-benar menginginkan RAID (misalnya, skenario yang mendukung beberapa kegagalan pada kelompok kecil), tidak ada yang mencegah Anda menggunakan pengontrol RAID lokal, dan melakukan penyimpanan yang diperluas dan arsitektur HUJAN di atas. Skenario ini cukup hidup dan didukung oleh kami, jadi kami akan membicarakannya dalam artikel tentang skenario khas untuk menggunakan vAIR.
Skema Kegagalan Penyimpanan
Mungkin ada dua skema ketahanan disk virtual vAIR:
1) Faktor replikasi atau hanya replikasi - metode toleransi kesalahan ini sederhana "seperti tongkat dan tali". Replikasi sinkron antara node dengan faktor 2 (2 salinan per cluster) atau 3 (3 salinan, masing-masing) dilakukan. RF-2 memungkinkan disk virtual untuk menahan kegagalan satu node dalam sebuah cluster, tetapi "makan" setengah dari volume yang dapat digunakan, dan RF-3 akan menahan kegagalan 2 node dalam sebuah cluster, tetapi ia akan memesan 2/3 volume yang dapat digunakan untuk kebutuhannya. Skema ini sangat mirip dengan RAID-1, yaitu, disk virtual yang dikonfigurasi dalam RF-2 tahan terhadap kegagalan salah satu node cluster. Dalam hal ini, data akan baik-baik saja dan bahkan I / O tidak akan berhenti. Ketika simpul yang jatuh kembali ke operasi, pemulihan / sinkronisasi data otomatis akan dimulai.
Berikut ini adalah contoh distribusi data RF-2 dan RF-3 dalam mode normal dan dalam situasi kegagalan.
Kami memiliki mesin virtual dengan kapasitas 8MB data unik (berguna) yang berjalan pada 4 node vAIR. Jelas bahwa dalam kenyataannya tidak mungkin ada jumlah yang kecil, tetapi untuk skema yang mencerminkan logika ARDFS, contoh ini paling dapat dimengerti. AB adalah blok virtual 4MB yang berisi data mesin virtual unik. Dengan RF-2, masing-masing dua salinan dari blok ini A1 + A2 dan B1 + B2 dibuat. Blok-blok ini "diletakkan" oleh node, menghindari persimpangan data yang sama pada node yang sama, yaitu, salin A1 tidak akan berada pada catatan yang sama dengan salin A2. Dengan B1 dan B2 mirip.
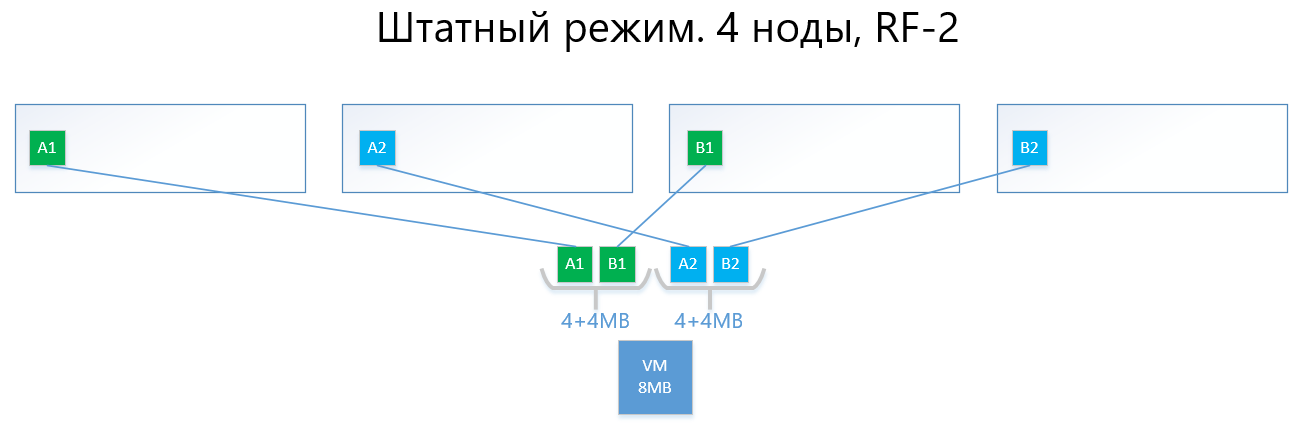
Dalam hal terjadi kegagalan dari salah satu node (misalnya, simpul 3, yang berisi salinan B1), salinan ini secara otomatis diaktifkan pada simpul di mana tidak ada salinan dari salinannya (yaitu, salinan B2).
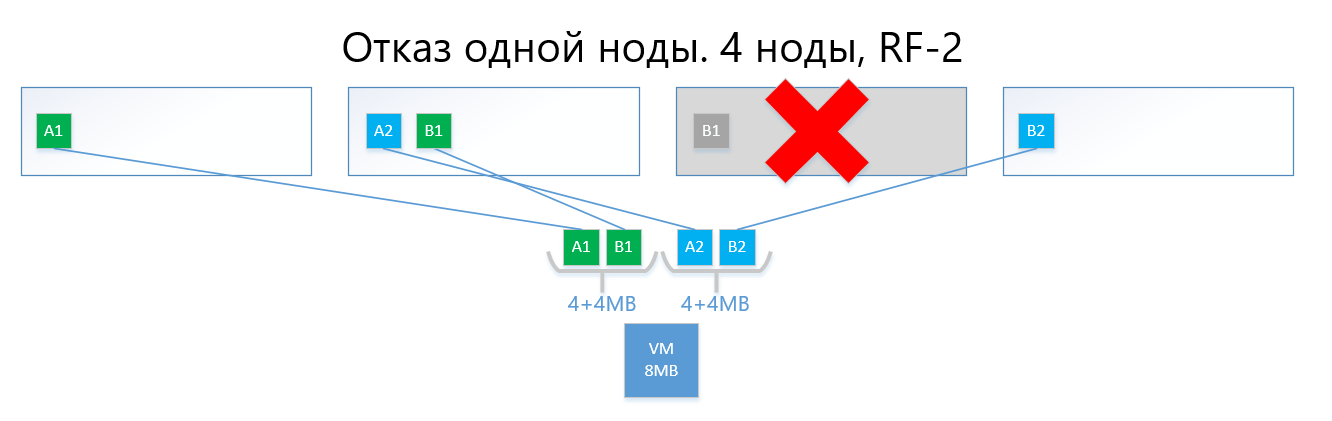
Dengan demikian, disk virtual (dan VM, masing-masing) akan dengan mudah selamat dari kegagalan satu node dalam skema RF-2.
Sebuah sirkuit dengan replikasi, dengan kesederhanaan dan keandalannya, menderita sakit yang sama seperti RAID1 - ada sedikit ruang yang dapat digunakan.
2) Erasure coding atau deletion coding (juga dikenal sebagai "redundant coding", "erasure coding" atau "redundancy code") baru saja ada untuk menyelesaikan masalah di atas. EC adalah skema redundansi yang menyediakan ketersediaan data tinggi dengan overhead disk lebih sedikit dibandingkan dengan replikasi. Prinsip operasi mekanisme ini mirip dengan RAID 5, 6, 6P.
Saat encoding, proses EC membagi blok virtual (4 MB secara default) menjadi beberapa “bagian data” yang lebih kecil tergantung pada skema EC (misalnya, skema 2 +1 membagi setiap blok 4 MB menjadi 2 bagian 2 MB). Lebih jauh, proses ini menghasilkan "parity chunk" untuk "potongan data" tidak lebih dari satu bagian yang sebelumnya terpisah. Ketika decoding, EC menghasilkan potongan-potongan yang hilang, membaca data "selamat" di seluruh cluster.
Sebagai contoh, disk virtual dengan skema EC 2 + 1, diimplementasikan pada 4 node cluster, dapat dengan mudah menahan kegagalan node tunggal dalam sebuah cluster dengan cara yang sama seperti RF-2. Pada saat yang sama, biaya overhead akan lebih rendah, khususnya, faktor kapasitas dengan RF-2 adalah 2, dan dengan EC 2 +1 akan menjadi 1,5.
Jika lebih mudah dijelaskan, intinya adalah bahwa blok virtual dibagi menjadi 2-8 (mengapa dari 2 hingga 8 lihat di bawah) "potongan", dan untuk potongan ini "potongan" paritas volume yang sama dihitung.
Akibatnya, data dan paritas didistribusikan secara merata di semua node cluster. Pada saat yang sama, seperti replikasi, ARDFS secara otomatis mendistribusikan data antar node sedemikian rupa untuk mencegah penyimpanan data yang sama (salinan data dan paritasnya) pada satu node untuk menghilangkan kemungkinan kehilangan data karena fakta bahwa data dan paritas tiba-tiba akan berakhir pada simpul penyimpanan yang sama, yang akan gagal.
Di bawah ini adalah contoh, dengan mesin virtual yang sama pada 8 MB dan 4 node, tetapi sudah dengan skema EC 2 +1.
Blok A dan B dibagi menjadi dua bagian masing-masing 2 MB (dua karena 2 + 1), yaitu, A1 + A2 dan B1 + B2. Berbeda dengan replika, A1 bukan salinan A2, itu adalah blok virtual A, dibagi menjadi dua bagian, juga dengan blok B. Secara total, kami mendapatkan dua set 4MB, yang masing-masing berisi dua potongan dua megabyte. Selanjutnya, untuk masing-masing set paritas ini dihitung dengan volume tidak lebih dari satu bagian (mis. 2 MB), kami mendapatkan tambahan + 2 bagian paritas (AP dan BP). Total kami memiliki data 4x2 + paritas 2x2.
Selanjutnya, potongan-potongan itu "diletakkan" oleh node sehingga data tidak tumpang tindih dengan paritasnya. Yaitu A1 dan A2 tidak akan terletak pada simpul yang sama dengan AP.

Dalam hal terjadi kegagalan satu simpul (misalnya, juga simpul ketiga), blok B1 yang jatuh akan secara otomatis dikembalikan dari paritas BP, yang disimpan pada simpul No. 2, dan akan diaktifkan pada simpul di mana tidak ada B-paritas, yaitu. potongan BP. Dalam contoh ini, ini adalah simpul # 1

Saya yakin pembaca memiliki pertanyaan:
"Segala sesuatu yang Anda uraikan telah lama diterapkan oleh pesaing dan solusi open source, apa perbedaan antara penerapan EC Anda di ARDFS?"
Dan kemudian akan ada fitur menarik dari karya ARDFS.
Menghapus kode dengan penekanan pada fleksibilitas
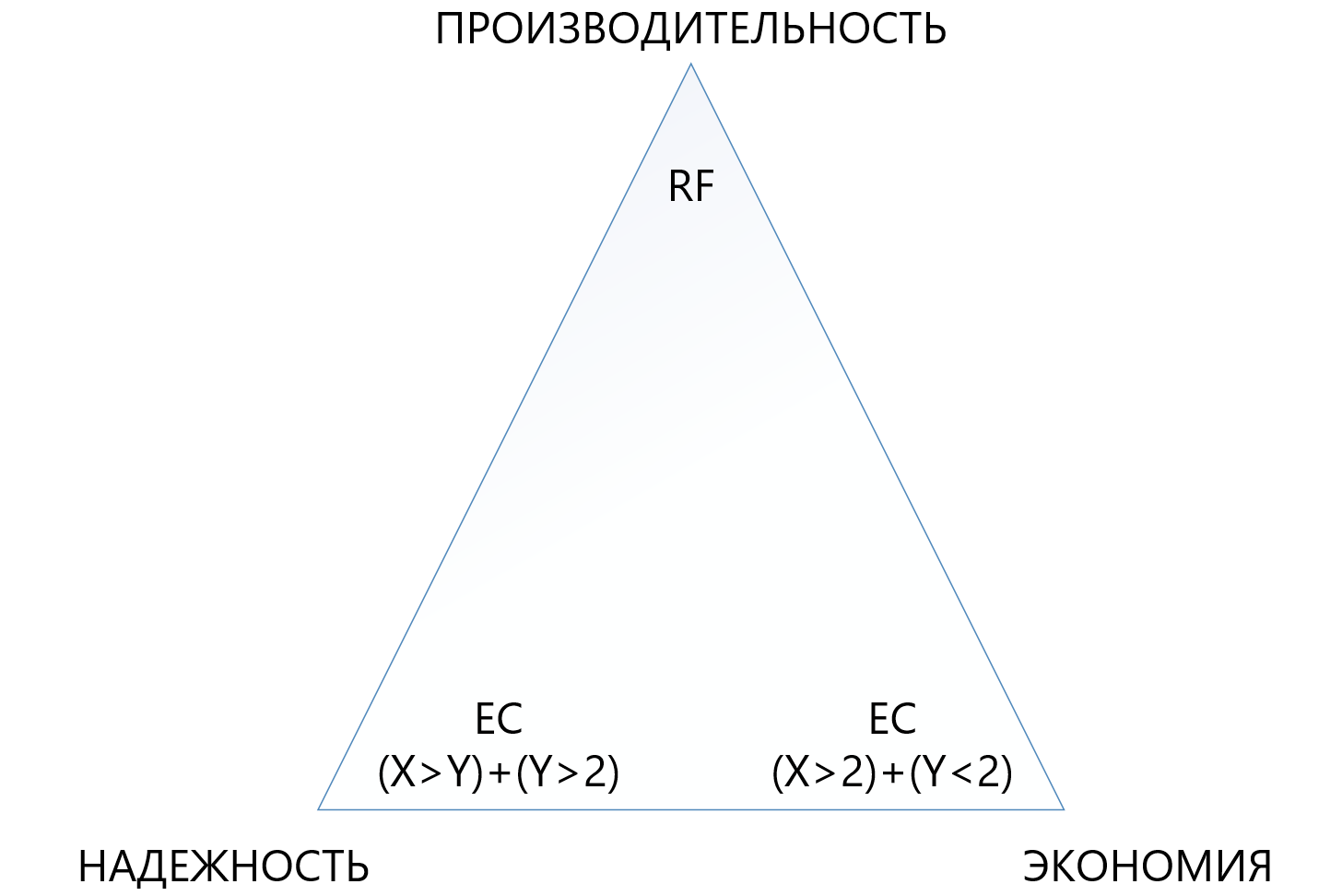
Awalnya, kami menyediakan skema EC X + Y yang agak fleksibel, di mana X sama dengan angka dari 2 hingga 8, dan Y sama dengan angka dari 1 hingga 8, tetapi selalu kurang dari atau sama dengan X. Skema semacam itu disediakan untuk fleksibilitas. Meningkatkan jumlah potongan data (X) ke mana unit virtual dibagi memungkinkan untuk mengurangi overhead, yaitu, untuk menambah ruang yang dapat digunakan.
Peningkatan jumlah potongan paritas (Y) meningkatkan keandalan disk virtual. Semakin besar nilai Y, semakin banyak node dalam gugus yang dapat gagal. Tentu saja, meningkatkan jumlah paritas mengurangi jumlah kapasitas yang dapat digunakan, tetapi ini merupakan biaya untuk keandalan.
Ketergantungan kinerja pada sirkuit EC hampir langsung: semakin banyak "potongan", semakin rendah kinerjanya, di sini, tentu saja, Anda perlu tampilan yang seimbang.
Pendekatan ini memungkinkan administrator cara paling fleksibel untuk mengonfigurasi penyimpanan yang diperluas. Di dalam kumpulan ARDFS, Anda dapat menggunakan skema toleransi kesalahan dan kombinasinya, yang juga, menurut pendapat kami, sangat berguna.
Tabel di bawah membandingkan beberapa (tidak semua kemungkinan) sirkuit RF dan EC.

Tabel menunjukkan bahwa bahkan kombinasi paling "terry" dari EC 8 + 7, yang memungkinkan hilangnya hingga 7 node sekaligus dalam satu cluster, "memakan" ruang yang kurang dapat digunakan (1.875 berbanding 2) daripada replikasi standar, dan melindungi 7 kali lebih baik, yang membuat mekanisme perlindungan ini, meskipun lebih kompleks, tetapi jauh lebih menarik dalam situasi di mana Anda perlu memastikan keandalan maksimum dalam kondisi kurangnya ruang disk. Pada saat yang sama, Anda perlu memahami bahwa setiap "plus" ke X atau Y akan menjadi overhead tambahan untuk produktivitas, jadi Anda harus memilih dengan sangat hati-hati dalam segitiga antara keandalan, ekonomi dan kinerja. Untuk alasan ini, kami akan menyediakan artikel terpisah untuk mengubah ukuran penghapusan kode.
Keandalan dan otonomi sistem file
ARDFS berjalan secara lokal di semua node cluster dan menyinkronkannya dengan caranya sendiri melalui antarmuka Ethernet khusus. Poin penting adalah bahwa ARDFS secara independen menyinkronkan tidak hanya data, tetapi juga metadata yang terkait dengan penyimpanan. Saat bekerja pada ARDFS, kami secara simultan mempelajari sejumlah solusi yang ada dan kami menemukan bahwa banyak yang melakukan sinkronisasi meta sistem file menggunakan DBMS terdistribusi eksternal, yang juga kami gunakan untuk menyinkronkan, tetapi hanya konfigurasi, bukan metadata FS (tentang ini dan subsistem terkait lainnya dalam artikel selanjutnya).
Sinkronisasi metadata FS menggunakan DBMS eksternal, tentu saja, solusi yang berfungsi, tetapi kemudian konsistensi data yang disimpan pada ARDFS akan tergantung pada DBMS eksternal dan perilakunya (dan dia, sejujurnya, adalah wanita yang berubah-ubah), yang buruk menurut pendapat kami. Mengapa Jika metadata FS rusak, data FS itu sendiri juga dapat dikatakan “selamat tinggal”, jadi kami memutuskan untuk menempuh jalur yang lebih rumit namun andal.
Kami membuat subsistem sinkronisasi metadata untuk ARDFS secara independen, dan ia hidup sepenuhnya terlepas dari subsistem yang berdekatan. Yaitu tidak ada subsistem lain yang dapat merusak data ARDFS. Menurut pendapat kami, ini adalah cara yang paling dapat diandalkan dan benar, dan apakah memang demikian - waktu akan memberi tahu. Selain itu, dengan pendekatan ini, keuntungan tambahan muncul. ARDFS dapat digunakan secara independen dari vAIR, seperti halnya penyimpanan yang diperluas, yang tentunya akan kami gunakan dalam produk-produk mendatang.
Sebagai hasilnya, setelah mengembangkan ARDFS, kami mendapatkan sistem file yang fleksibel dan andal yang memberi Anda pilihan di mana Anda dapat menghemat kapasitas atau memberikan segalanya pada kinerja, atau menjadikan penyimpanan sangat andal dengan biaya moderat, tetapi mengurangi persyaratan kinerja.
Bersama dengan kebijakan lisensi sederhana dan model pengiriman fleksibel (melihat ke depan, itu dilisensikan oleh vAIR oleh node, dan dikirimkan baik oleh perangkat lunak atau sebagai PAC) ini memungkinkan Anda untuk menyesuaikan solusi dengan kebutuhan pelanggan yang paling berbeda dan di masa depan mudah untuk menjaga keseimbangan ini.
Siapa yang butuh keajaiban ini?
Di satu sisi, kita dapat mengatakan bahwa sudah ada pemain di pasar yang memiliki keputusan serius di bidang hyperconvergence, dan ke mana kita benar-benar pergi. Pernyataan ini tampaknya benar, TAPI ...
Di sisi lain, pergi ke ladang dan berkomunikasi dengan pelanggan, kami dan mitra kami melihat bahwa ini sama sekali tidak terjadi. Ada banyak masalah bagi hiper konvergensi, di suatu tempat orang tidak tahu bahwa ada solusi seperti itu, di suatu tempat itu tampak mahal, di suatu tempat ada tes solusi alternatif yang gagal, tetapi di suatu tempat mereka umumnya melarang pembelian, karena sanksi. Secara umum, lapangan tidak dibajak, jadi kami pergi untuk meningkatkan tanah perawan)))).
Kapan penyimpanan lebih baik dari GCS?
Dalam perjalanan bekerja dengan pasar, kita sering ditanya kapan lebih baik menggunakan skema klasik dengan sistem penyimpanan, dan kapan hyperconvergent? Banyak perusahaan - produsen GCS (terutama yang tidak memiliki penyimpanan dalam portofolionya) mengatakan: "Penyimpanan lebih lama, hanya hyperconvergent!" Ini adalah pernyataan yang berani, tetapi tidak cukup mencerminkan kenyataan.
Sebenarnya, pasar penyimpanan, memang, berenang menuju solusi hyperconvergent dan serupa, tetapi selalu ada "tetapi".
Pertama, pusat data dan infrastruktur TI yang dibangun sesuai dengan skema klasik dengan sistem penyimpanan tidak dapat dengan mudah dibangun kembali seperti ini, sehingga modernisasi dan penyelesaian infrastruktur tersebut masih merupakan warisan 5-7 tahun.
Kedua, infrastruktur yang sedang dibangun sekarang sebagian besar (artinya Federasi Rusia) sedang dibangun sesuai dengan skema klasik menggunakan sistem penyimpanan dan bukan karena orang tidak tahu tentang hyper konvergen, tetapi karena pasar hyper konvergen adalah baru, solusi dan standar belum ditetapkan , Karyawan TI belum dilatih, ada sedikit pengalaman, dan kita perlu membangun pusat data di sini dan sekarang. Dan tren ini adalah untuk 3-5 tahun lagi (dan kemudian warisan yang lain, lihat paragraf 1).
Ketiga, pembatasan murni teknis dalam penundaan kecil tambahan 2 milidetik per tulis (tentu saja tidak termasuk cache lokal), yang merupakan biaya untuk penyimpanan terdistribusi.
Nah, jangan lupa tentang menggunakan server fisik besar yang suka penskalaan vertikal subsistem disk.
Ada banyak tugas penting dan populer di mana sistem penyimpanan berperilaku lebih baik daripada GCS. Di sini, tentu saja, pabrikan yang tidak memiliki sistem penyimpanan dalam portofolio produk mereka akan tidak setuju dengan kami, tetapi kami siap untuk berdebat dengan wajar. Tentu saja, kami, sebagai pengembang kedua produk di salah satu publikasi di masa mendatang, pasti akan membuat perbandingan sistem penyimpanan dan GCS, di mana kami akan dengan jelas menunjukkan apa yang lebih baik dalam kondisi apa.
Dan di mana solusi hyperconverged akan bekerja lebih baik daripada sistem penyimpanan?
Berdasarkan tesis di atas, ada tiga kesimpulan yang jelas:
- Jika tambahan 2 milidetik dari keterlambatan rekaman yang stabil terjadi pada produk apa pun (sekarang kita tidak berbicara tentang sintetis, Anda dapat menunjukkan nanodetik pada sintesis) tidak penting, hiper konvergen akan dilakukan.
- Di mana beban dari server fisik besar dapat diubah menjadi banyak server virtual kecil dan didistribusikan oleh node, hyperconvergent juga akan berfungsi dengan baik di sana.
- Jika penskalaan horizontal lebih penting daripada penskalaan vertikal, GCS juga akan berfungsi dengan baik di sana.
Apa solusi ini?
- Semua layanan infrastruktur standar (layanan direktori, surat, EDS, server file, sistem ERP dan BI kecil atau menengah, dll.). Kami menyebutnya "komputasi umum."
- Infrastruktur penyedia cloud, di mana perlu untuk secara cepat dan membakukan secara horizontal memperluas dan dengan mudah "mengiris" sejumlah besar mesin virtual untuk klien.
- Infrastruktur virtual desktop (VDI), di mana banyak virtuala pengguna kecil diluncurkan dan diam-diam "mengambang" di dalam gugus seragam.
- Cabang jaringan di mana di setiap cabang Anda perlu mendapatkan infrastruktur standar, toleran terhadap kesalahan, tetapi pada saat yang sama murah dari 15-20 mesin virtual.
- Setiap komputasi terdistribusi (layanan data besar, misalnya). Di mana beban tidak masuk "dalam", tetapi "luas".
- Uji lingkungan di mana penundaan kecil tambahan dapat diterima, tetapi ada kendala anggaran, karena ini adalah tes.
Saat ini, kami telah membuat AERODISK vAIR hanya untuk tugas-tugas ini, dan kami fokus pada mereka (sejauh ini berhasil). Mungkin ini akan segera berubah. dunia tidak tinggal diam.
Jadi ...
Ini melengkapi bagian pertama dari serangkaian besar artikel, pada artikel selanjutnya kita akan berbicara tentang arsitektur solusi dan komponen yang digunakan.
Kami menerima pertanyaan, saran, dan perselisihan yang membangun.