Tampaknya bidang periklanan online harus teknologi dan otomatisasi mungkin. Memang, raksasa dan pakar di bidangnya seperti Yandex, Mail.Ru, Google, dan Facebook bekerja di sana. Tetapi, ternyata, tidak ada batas untuk kesempurnaan dan selalu ada sesuatu untuk diotomatisasi.
 Sumber
SumberGrup komunikasi
Dentsu Aegis Network Rusia adalah pemain terbesar di pasar periklanan digital dan secara aktif berinvestasi dalam teknologi, berusaha untuk mengoptimalkan dan mengotomatiskan proses bisnisnya. Salah satu masalah yang belum terselesaikan dari pasar periklanan online adalah tugas mengumpulkan statistik kampanye iklan dari berbagai situs online. Solusi untuk masalah ini akhirnya menghasilkan penciptaan produk
D1.Digital (dibaca sebagai DiVan), yang ingin kita bicarakan tentang pengembangan.
Mengapa
1. Pada saat dimulainya proyek, tidak ada satu pun produk jadi di pasar yang menyelesaikan tugas mengotomatisasi pengumpulan statistik pada kampanye iklan.
Ini berarti bahwa tidak seorang pun kecuali diri kita akan menutup kebutuhan kita.Layanan seperti Improvado, Roistat, Supermetrics, SegmentStream, menawarkan integrasi dengan situs, jejaring sosial, dan Google Analitycs, dan juga menyediakan kemampuan untuk membangun dashboard analitik untuk analisis yang mudah dan kontrol kampanye iklan. Sebelum mulai mengembangkan produk kami, kami mencoba menggunakan beberapa sistem ini dalam pekerjaan kami untuk mengumpulkan data dari situs, tetapi, sayangnya, mereka tidak dapat menyelesaikan masalah kami.
Masalah utama adalah bahwa produk yang diuji ditolak dari sumber data, menampilkan statistik penempatan di bagian-bagian berdasarkan situs, dan tidak memungkinkan agregasi statistik pada kampanye iklan. Pendekatan ini tidak memungkinkan melihat statistik dari situs yang berbeda di satu tempat dan menganalisis keadaan kampanye secara keseluruhan.
Faktor lain adalah bahwa pada tahap awal produk berorientasi ke pasar Barat dan tidak mendukung integrasi dengan situs Rusia. Dan untuk situs yang menerapkan integrasi tersebut, semua metrik yang diperlukan dengan detail yang cukup tidak selalu diunggah, dan integrasi itu tidak selalu nyaman dan transparan, terutama ketika diperlukan untuk mendapatkan sesuatu yang tidak ada dalam antarmuka sistem.
Secara umum, kami memutuskan untuk tidak beradaptasi dengan produk pihak ketiga, tetapi mulai mengembangkan ...
2. Pasar iklan online tumbuh dari tahun ke tahun, dan pada tahun 2018, secara tradisional melampaui pasar iklan TV terbesar dalam hal anggaran iklan.
Jadi ada skala .
3. Berbeda dengan pasar periklanan TV, di mana penjualan iklan komersial dimonopoli, massa pemilik individu dari peralatan iklan berbagai ukuran dengan kantor periklanan mereka bekerja di Internet. Karena kampanye iklan, sebagai suatu peraturan, berjalan di beberapa situs sekaligus, untuk memahami keadaan kampanye iklan, perlu untuk mengumpulkan laporan dari semua situs dan menyatukannya menjadi satu laporan besar yang akan menampilkan seluruh gambar.
Jadi, ada potensi untuk optimasi.4. Tampaknya bagi kami bahwa pemilik inventaris iklan di Internet sudah memiliki infrastruktur untuk mengumpulkan statistik dan menampilkannya di kantor iklan, dan mereka dapat menyediakan API untuk data ini.
Jadi, ada kelayakan teknis. Kami akan segera mengatakan bahwa itu tidak sesederhana itu.
Secara umum, semua prasyarat untuk pelaksanaan proyek sudah jelas bagi kami, dan kami berlari untuk mengimplementasikan proyek ...
Rencana besar
Pertama, kami membentuk visi sistem yang ideal:
- Seharusnya secara otomatis memuat kampanye iklan dari sistem perusahaan 1C dengan nama, periode, anggaran, dan penempatannya di berbagai platform.
- Untuk setiap penempatan di dalam kampanye iklan, semua statistik yang mungkin dari situs tempat penempatan berlangsung, seperti jumlah tayangan, klik, tampilan, dll., Harus diunduh secara otomatis.
- Beberapa kampanye iklan dipantau oleh pemantauan pihak ketiga oleh apa yang disebut sistem adserving, seperti Adriver, Weborama, DCM, dll. Ada juga meteran Internet industri di Rusia - Mediascope. Menurut gagasan kami, data pemantauan independen dan industri juga harus secara otomatis diunggah ke kampanye iklan yang sesuai.
- Sebagian besar kampanye iklan di Internet ditujukan untuk tindakan bertarget tertentu (membeli, menelepon, merekam untuk test drive, dll.), Yang dilacak menggunakan Google Analytics, dan statistik yang juga penting untuk memahami status kampanye dan harus diunggah ke alat kami .
Pancake pertama kental
Mempertimbangkan komitmen kami terhadap prinsip-prinsip pengembangan perangkat lunak yang fleksibel (gesit, semuanya), kami memutuskan untuk mengembangkan MVP terlebih dahulu dan kemudian bergerak menuju tujuan yang diinginkan secara iteratif.
Kami memutuskan untuk membangun MVP berdasarkan produk kami
DANBo (Dentsu Aegis Network Board) , yang merupakan aplikasi web dengan informasi umum tentang kampanye iklan pelanggan kami.
Untuk MVP, proyek ini disederhanakan secara maksimal dalam hal implementasi. Kami telah memilih daftar situs terbatas untuk integrasi. Ini adalah platform utama, seperti Yandex.Direct, Yandex.Display, RB.Mail, MyTarget, Adwords, DBM, VK, FB, dan sistem iklan utama Adriver dan Weborama.
Untuk mengakses statistik di situs melalui API, kami menggunakan satu akun. Manajer grup klien, yang ingin menggunakan pengumpulan statistik otomatis pada kampanye iklan, harus terlebih dahulu mendelegasikan akses ke kampanye iklan yang diperlukan di situs ke akun platform.
Lebih lanjut, pengguna sistem
DANBo harus mengunggah file format tertentu ke sistem Excel, di mana semua informasi tentang penempatan (kampanye iklan, situs, format, periode penempatan, indikator yang direncanakan, anggaran, dll.) Dan pengidentifikasi kampanye iklan yang sesuai di situs ditulis dan penghitung dalam sistem adserving.
Itu tampak, terus terang, menakutkan:

Data yang diunduh disimpan dalam basis data, dan kemudian masing-masing layanan mengumpulkan pengidentifikasi kampanye dari mereka dari situs dan mengunduh statistik pada mereka.
Layanan windows terpisah ditulis untuk setiap situs, yang sekali sehari masuk dalam satu akun layanan di API situs dan mengunduh statistik pada pengidentifikasi kampanye yang ditentukan. Hal yang sama terjadi dengan sistem adserving.
Data yang diunduh ditampilkan pada antarmuka dalam bentuk dasbor kecil yang ditulis sendiri:
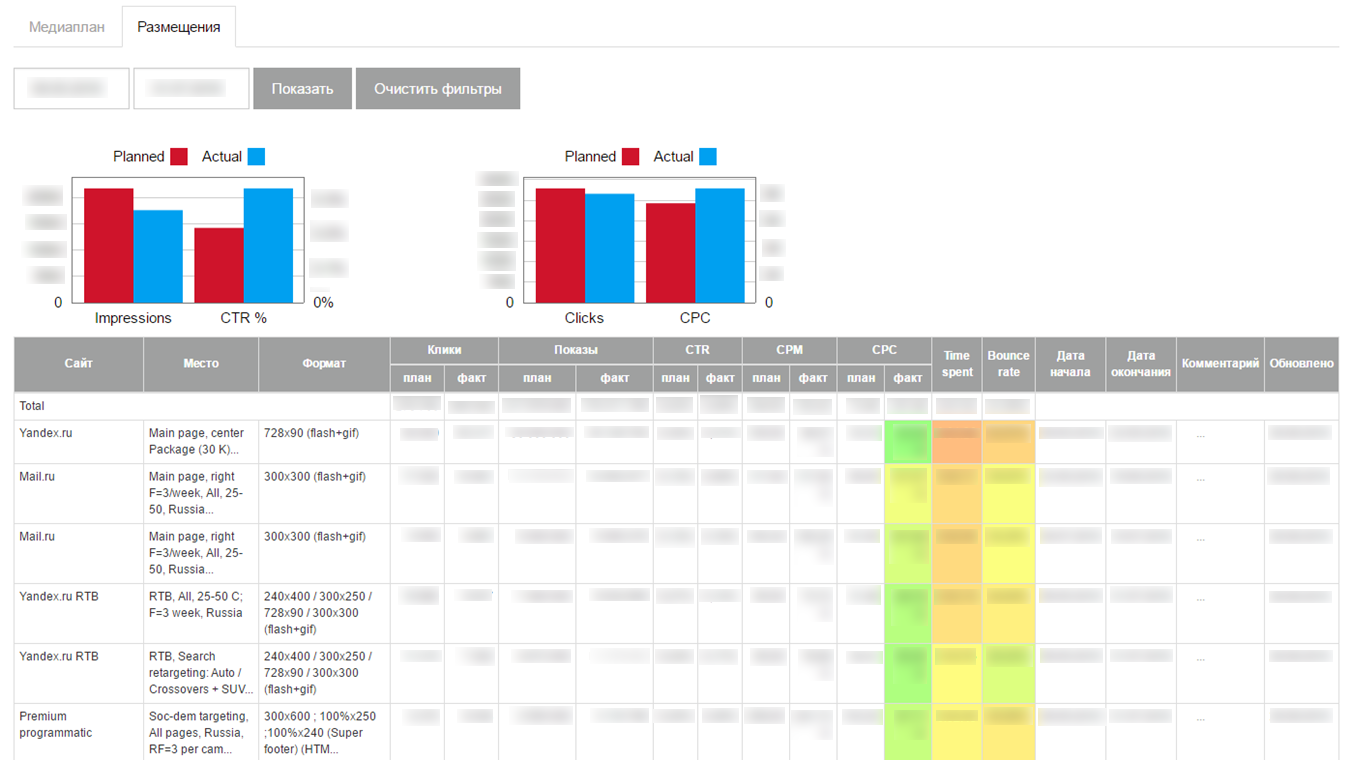
Tanpa diduga bagi kami, MVP memperoleh dan mulai mengunduh statistik terkini tentang kampanye iklan di Internet. Kami menerapkan sistem pada beberapa klien, tetapi ketika kami mencoba untuk meningkatkan skala, kami mengalami masalah serius:
- Masalah utama adalah kesulitan menyiapkan data untuk dimuat ke dalam sistem. Selain itu, data penempatan harus dikurangi menjadi format yang benar-benar diperbaiki sebelum mengunduh. Dalam file untuk memuat, perlu untuk mendaftarkan pengidentifikasi entitas dari situs yang berbeda. Kami dihadapkan dengan kenyataan bahwa sangat sulit bagi pengguna yang tidak terlatih secara teknis untuk menjelaskan di mana menemukan pengidentifikasi ini di situs dan di mana harus meletakkannya di file. Mengingat jumlah karyawan di divisi yang melakukan kampanye di situs, dan omset, ini menghasilkan sejumlah besar dukungan di pihak kami, yang pasti tidak cocok untuk kami.
- Masalah lain adalah tidak semua platform iklan memiliki mekanisme untuk mendelegasikan akses ke kampanye iklan ke akun lain. Tetapi bahkan jika mekanisme delegasi tersedia, tidak semua pengiklan bersedia memberikan akses akun pihak ketiga ke kampanye mereka.
- Faktor penting adalah kemarahan, yang menyebabkan pengguna bahwa semua indikator yang direncanakan dan detail penempatan yang telah mereka berkontribusi ke sistem akuntansi 1C kami harus dimasukkan kembali ke DANBo .
Ini memberi kami gagasan bahwa sumber utama informasi tentang lokasi harus sistem 1C kami, di mana semua data dimasukkan secara akurat dan tepat waktu (intinya adalah bahwa berdasarkan data 1C, akun dibentuk, oleh karena itu, entri data yang benar dalam 1C adalah untuk semua orang di KPI). Jadi konsep sistem baru muncul ...
Konsep
Hal pertama yang kami putuskan adalah memisahkan sistem pengumpulan statistik kampanye iklan di Internet menjadi produk terpisah -
D1.Digital .
Dalam konsep baru, kami memutuskan untuk memuat informasi tentang kampanye iklan dan penempatan di dalamnya dari 1C ke
D1.Digital , dan kemudian menarik statistik dari situs dan dari sistem AdServing ke penempatan ini. Ini seharusnya sangat menyederhanakan kehidupan pengguna (dan, seperti biasa, menambah pekerjaan ke pengembang) dan mengurangi jumlah dukungan.
Masalah pertama yang kami temui adalah sifat organisasi dan terkait dengan fakta bahwa kami tidak dapat menemukan kunci atau atribut yang dengannya kami dapat membandingkan entitas dari sistem yang berbeda dengan kampanye dan penempatan dari 1C. Faktanya adalah bahwa proses di perusahaan kami diatur sedemikian rupa sehingga kampanye iklan dimasukkan ke dalam sistem yang berbeda oleh orang yang berbeda (pemutar media, pembelian, dll.).
Untuk mengatasi masalah ini, kami harus menemukan kunci hash yang unik, DANBoID, yang akan menghubungkan entitas dalam sistem yang berbeda bersama-sama, dan yang dapat dengan mudah dan jelas diidentifikasi dalam dataset yang dimuat. Pengidentifikasi ini dihasilkan dalam sistem 1C internal untuk setiap penempatan individu dan dilemparkan ke kampanye, penempatan, dan penghitung di semua situs dan di semua sistem AdServing. Menerapkan praktik membubuhkan DANBoID ke semua penempatan butuh waktu, tapi kami berhasil :)
Kemudian kami menemukan bahwa tidak semua situs memiliki API untuk pengumpulan statistik otomatis, dan bahkan mereka yang memiliki API tidak mengembalikan semua data yang diperlukan.
Pada tahap ini, kami memutuskan untuk secara signifikan mengurangi daftar situs untuk integrasi dan fokus pada situs utama yang terlibat dalam sebagian besar kampanye iklan. Daftar ini mencakup semua pemain terbesar di pasar periklanan (Google, Yandex, Mail.ru), jejaring sosial (VK, Facebook, Twitter), sistem AdServing dan analisis utama (DCM, Adriver, Weborama, Google Analytics) dan platform lainnya.
Sebagian besar situs yang kami pilih memiliki API yang memberi kami metrik yang diperlukan. Dalam kasus-kasus ketika API tidak ada di sana, atau tidak memiliki data yang diperlukan, kami menggunakan laporan yang tiba di surat bisnis setiap hari untuk mengunduh data (dalam beberapa sistem dimungkinkan untuk mengkonfigurasi laporan seperti itu, di beberapa sistem lain mereka menyetujui pengembangan laporan tersebut untuk kami).
Saat menganalisis data dari situs yang berbeda, kami menemukan bahwa hierarki entitas tidak sama dalam sistem yang berbeda. Selain itu, informasi dari sistem yang berbeda harus dimuat secara berbeda.
Untuk mengatasi masalah ini, konsep SubDANBoID dikembangkan. Gagasan SubDANBoID cukup sederhana, kami menandai esensi utama kampanye di situs dengan DANBoID yang dihasilkan, dan kami mengunggah semua entitas bersarang dengan pengidentifikasi unik situs dan membentuk SubDANBoID sesuai dengan prinsip DANBoID + pengidentifikasi entitas bersarang dari tingkat pertama + pengidentifikasi entitas bersarang pada tingkat kedua + pendekatan yang diizinkan ... mengiklankan kampanye di berbagai sistem dan mengunggah statistik terperinci tentang mereka.
Kami juga harus menyelesaikan masalah akses ke kampanye di berbagai situs. Seperti yang kami tulis di atas, mekanisme pendelegasian akses ke kampanye ke akun teknis yang terpisah tidak selalu berlaku. Oleh karena itu, kami harus mengembangkan infrastruktur untuk otorisasi otomatis melalui OAuth menggunakan token dan memperbarui mekanisme untuk token ini.
Lebih lanjut dalam artikel ini kami akan mencoba untuk menjelaskan secara lebih rinci arsitektur solusi dan rincian teknis implementasi.
Arsitektur Solusi 1.0
Memulai implementasi produk baru, kami memahami bahwa perlu segera menyediakan kemungkinan untuk menghubungkan situs baru, jadi kami memutuskan untuk mengikuti jalur arsitektur layanan mikro.
Saat merancang arsitektur, kami memilih konektor layanan terpisah untuk semua sistem eksternal - 1C, platform iklan, dan sistem adserving.
Gagasan utamanya adalah bahwa semua konektor ke situs memiliki API yang sama dan merupakan adaptor yang membawa API situs ke antarmuka kami yang nyaman.
Di tengah-tengah produk kami adalah aplikasi web, yang merupakan monolith, yang dirancang sehingga dapat dengan mudah dibongkar menjadi layanan. Aplikasi ini bertanggung jawab untuk memproses data yang diunduh, membandingkan statistik dari berbagai sistem dan menyajikannya kepada pengguna sistem.
Untuk berkomunikasi konektor dengan aplikasi web, kami harus membuat layanan tambahan, yang kami sebut Connector Proxy. Itu melakukan fungsi Penemuan Layanan dan Penjadwal Tugas. Layanan ini menjalankan tugas pengumpulan data untuk setiap konektor setiap malam. Menulis lapisan layanan lebih mudah daripada menghubungkan pialang pesan, dan bagi kami penting untuk mendapatkan hasilnya secepat mungkin.
Untuk kesederhanaan dan kecepatan pengembangan, kami juga memutuskan bahwa semua layanan akan menjadi Web API. Ini memungkinkan untuk dengan cepat mengumpulkan bukti konsep dan memverifikasi bahwa seluruh desain berfungsi.
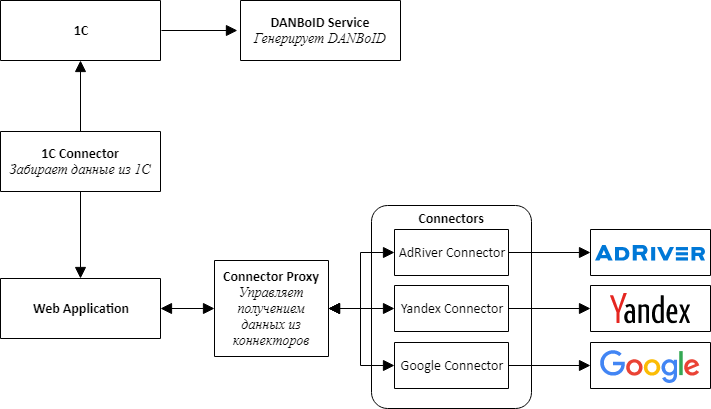
Tugas terpisah, agak sulit, adalah menyiapkan akses untuk mengumpulkan data dari kabinet yang berbeda, yang, seperti yang kami putuskan, harus dilakukan oleh pengguna melalui antarmuka web. Ini terdiri dari dua langkah terpisah: pertama, pengguna melalui OAuth menambahkan token untuk mengakses akun, dan kemudian mengatur pengumpulan data untuk klien dari akun tertentu. Diperolehnya token melalui OAuth, karena, seperti yang sudah kami tulis, tidak selalu mungkin mendelegasikan akses ke kabinet yang diinginkan di situs.
Untuk membuat mekanisme universal untuk memilih kabinet dari situs, kami harus menambahkan metode ke API konektor yang merender Skema JSON, yang dirender ke dalam formulir menggunakan komponen JSONEditor yang dimodifikasi. Jadi pengguna dapat memilih akun untuk mengunduh data.
Untuk mematuhi batas permintaan yang ada di situs, kami menggabungkan permintaan pengaturan dalam token yang sama, tetapi kami dapat memproses token yang berbeda secara paralel.
Kami memilih MongoDB sebagai repositori untuk data yang dapat diunduh baik untuk aplikasi web dan untuk konektor, yang memungkinkan kami untuk tidak terlalu peduli tentang struktur data pada tahap awal pengembangan, ketika model aplikasi berubah setelah sehari.
Segera kami menemukan bahwa tidak semua data cocok di MongoDB dan, misalnya, statistik harian lebih nyaman untuk disimpan dalam database relasional. Oleh karena itu, untuk konektor yang struktur datanya lebih cocok untuk database relasional, kami mulai menggunakan PostgreSQL atau MS SQL Server sebagai penyimpanan.
Arsitektur dan teknologi yang dipilih memungkinkan kami untuk secara relatif cepat membangun dan meluncurkan produk D1.Digital. Selama dua tahun pengembangan produk, kami mengembangkan 23 konektor situs, memperoleh pengalaman tak ternilai bekerja dengan API pihak ketiga, mempelajari cara memintas jebakan situs yang berbeda yang masing-masing miliki, berkontribusi pada pengembangan API setidaknya 3 situs, secara otomatis mengunduh informasi pada hampir 15.000 kampanye dan di lebih dari 80.000 penempatan, kami mengumpulkan banyak umpan balik dari pengguna tentang produk dan berhasil mengubah proses utama produk beberapa kali, berdasarkan umpan balik ini.
Arsitektur Solusi 2.0
Dua tahun telah berlalu sejak awal pengembangan
D1.Digital . Peningkatan konstan pada beban pada sistem dan kemunculan sumber data yang baru secara bertahap mengungkapkan masalah dalam arsitektur solusi yang ada.
Masalah pertama terkait dengan jumlah data yang diunduh dari situs. Kami dihadapkan dengan fakta bahwa mengumpulkan dan memperbarui semua data yang diperlukan dari situs terbesar mulai memakan terlalu banyak waktu. Misalnya, mengumpulkan data pada sistem iklan AdRiver, yang dengannya kami melacak statistik untuk sebagian besar penempatan, membutuhkan waktu sekitar 12 jam.
Untuk mengatasi masalah ini, kami mulai menggunakan semua jenis laporan untuk mengunduh data dari situs, kami mencoba mengembangkan API mereka bersama dengan situs sehingga kecepatannya memenuhi kebutuhan kami, dan memaralelkan pemuatan data sebanyak mungkin.
Masalah lain adalah pemrosesan data yang diunduh. Sekarang, dengan kedatangan statistik baru tentang penempatan, proses multi-tahap penghitungan ulang metrik diluncurkan, yang mencakup memuat data mentah, menghitung metrik gabungan untuk setiap situs, membandingkan data dari sumber yang berbeda satu sama lain, dan menghitung metrik ringkasan untuk kampanye. Ini menyebabkan beban besar pada aplikasi web, yang melakukan semua perhitungan. Beberapa kali, dalam proses penghitungan ulang, aplikasi memakan semua memori di server, sekitar 10-15 GB, yang memiliki efek paling merugikan pada pekerjaan pengguna dengan sistem.
Masalah yang teridentifikasi dan rencana muluk untuk pengembangan lebih lanjut dari produk membawa kami pada kebutuhan untuk merevisi arsitektur aplikasi.
Kami mulai dengan konektor.
Kami memperhatikan bahwa semua konektor bekerja sesuai dengan model yang sama, jadi kami membangun pipeline-conveyor di mana untuk membuat konektor Anda hanya perlu memprogram logika langkah, sisanya adalah universal. Jika ada konektor yang perlu diperbaiki, maka kami akan segera mentransfernya ke kerangka kerja baru sambil menyelesaikan konektor.
Secara paralel, kami mulai menempatkan konektor di docker dan Kubernetes.
Kami berencana untuk pindah ke Kubernetes untuk waktu yang lama, bereksperimen dengan pengaturan CI / CD, tetapi mulai bergerak hanya ketika satu konektor mulai memakan lebih dari 20 GB memori di server karena kesalahan, hampir membunuh seluruh proses. Selama penyelidikan, konektor dipindahkan ke kluster Kubernetes, di mana ia akhirnya tetap ada, bahkan ketika kesalahan telah diperbaiki.
Cukup cepat, kami menyadari bahwa Kubernetes nyaman, dan dalam enam bulan kami memindahkan 7 konektor dan Proxy Konektor ke kluster produksi, yang menghabiskan sebagian besar sumber daya.
Mengikuti konektor, kami memutuskan untuk mengubah arsitektur sisa aplikasi.
Masalah utama adalah bahwa data berasal dari konektor ke proxy dalam bundel besar, dan kemudian mereka mengalahkan DANBoID dan ditransfer ke aplikasi web pusat untuk diproses. Karena banyaknya metrik yang diceritakan, terjadi beban besar pada aplikasi.
, , web , , , - .
2.0.
, Web API RabbitMQ MassTransit . Connectors Proxy, Connectors Hub. , , .
web , . .
Kubernetes, .
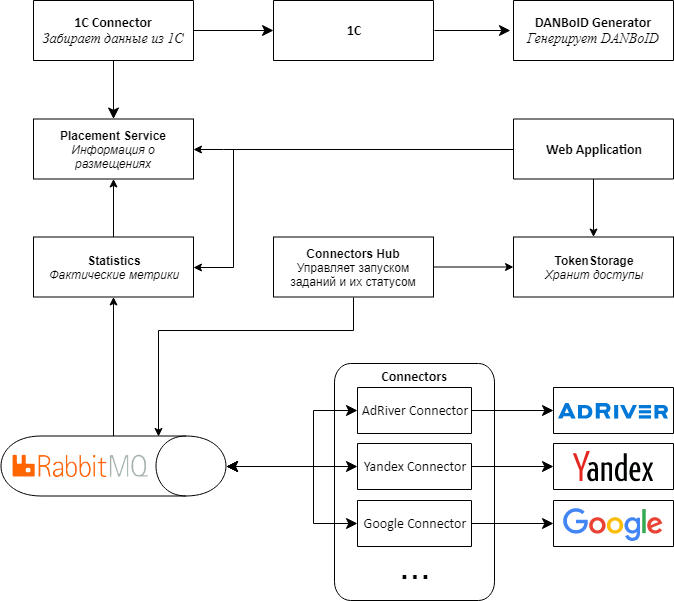
Proof-of-concept 2.0
D1.Digital . — 20 , , , , .
, API, .
, , adserving .
, web , Kubernetes. , , .
, MongoDB. SQL-, , , , .
, , :)
R&D Dentsu Aegis Network Russia: ( shmiigaa ), ( hitexx )