Artikel ini adalah upaya saya untuk mengekspresikan pandangan saya tentang aspek-aspek berikut:
- Apa itu faktor kecepatan belajar dan apa nilainya?
- Bagaimana memilih koefisien ini saat model pelatihan?
- Mengapa perlu mengubah koefisien kecepatan belajar selama pelatihan model?
- Apa yang harus dilakukan dengan faktor kecepatan belajar saat menggunakan model yang sudah dilatih sebelumnya?
Sebagian besar posting ini didasarkan pada bahan yang disiapkan oleh
fast.ai : [1], [2], [5] dan [3], mewakili versi ringkas dari pekerjaan mereka yang dimaksudkan untuk pemahaman tercepat tentang esensi masalah. Untuk membiasakan diri dengan rinciannya, disarankan untuk mengklik tautan yang diberikan di bawah ini.
Apa itu faktor kecepatan belajar?
Koefisien kecepatan pembelajaran adalah hiperparameter yang menentukan urutan di mana kami akan menyesuaikan skala kami dengan mempertimbangkan fungsi kehilangan dalam gradient descent. Semakin rendah nilainya, semakin lambat kita bergerak di sepanjang tanjakan. Meskipun ketika menggunakan koefisien kecepatan belajar yang rendah, kita bisa mendapatkan efek positif dalam arti bahwa kita tidak kehilangan satu minimum lokal, ini juga bisa berarti bahwa kita harus menghabiskan banyak waktu untuk konvergensi, terutama jika kita berada di wilayah dataran tinggi.
Hubungan tersebut diilustrasikan oleh rumus berikut
 Keturunan gradien dengan faktor kecepatan belajar kecil (atas) dan besar (bawah). Sumber: Kursus Pembelajaran Mesin Andrew Ng di Coursera
Keturunan gradien dengan faktor kecepatan belajar kecil (atas) dan besar (bawah). Sumber: Kursus Pembelajaran Mesin Andrew Ng di Coursera
Paling sering, faktor kecepatan belajar diatur oleh pengguna secara sewenang-wenang. Dalam kasus terbaik, untuk pemahaman intuitif tentang nilai apa yang paling cocok untuk menentukan koefisien kecepatan belajar, ia dapat mengandalkan eksperimen sebelumnya (atau jenis materi pelatihan lainnya).
Intinya, cukup sulit untuk memilih nilai yang tepat. Diagram di bawah ini menggambarkan berbagai skenario yang mungkin muncul ketika pengguna secara mandiri menyesuaikan tingkat kecepatan belajar.
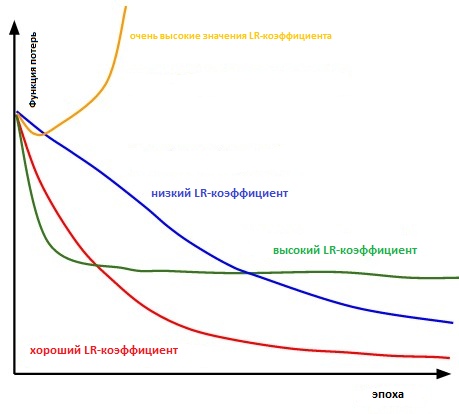 Pengaruh berbagai faktor tingkat pembelajaran pada konvergensi. (Kredit Img: cs231n)
Pengaruh berbagai faktor tingkat pembelajaran pada konvergensi. (Kredit Img: cs231n)
Selanjutnya, faktor kecepatan belajar memengaruhi seberapa cepat model kami mencapai minimum lokal (alias akan mencapai akurasi terbaik). Dengan demikian, pilihan yang tepat sejak awal menjamin lebih sedikit buang waktu untuk melatih model. Semakin sedikit waktu pelatihan, semakin sedikit uang yang dihabiskan untuk daya komputasi GPU di cloud.
Apakah ada cara yang lebih mudah untuk menentukan tingkat koefisien pembelajaran?
Dalam paragraf 3.3. "
Koefisien laju pembelajaran siklis untuk jaringan saraf, " Leslie Smith menganjurkan hal berikut: efisiensi pembelajaran dapat diperkirakan dengan melatih model dengan kecepatan belajar rendah yang awalnya ditetapkan, yang kemudian meningkat (linear atau eksponensial) di setiap iterasi.
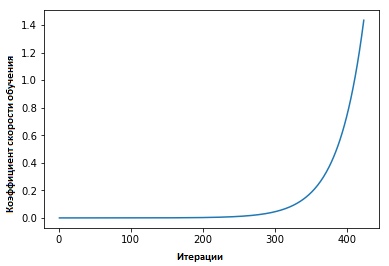 Faktor kecepatan belajar meningkat setelah setiap paket mini.
Faktor kecepatan belajar meningkat setelah setiap paket mini.
Memperbaiki nilai-nilai indikator pada setiap iterasi, kita akan melihat bahwa ketika kecepatan belajar meningkat, suatu titik tercapai (di mana) nilai-nilai fungsi kerugian berhenti menurun dan mulai meningkat. Dalam praktiknya, kecepatan belajar kita idealnya berada di suatu tempat di sebelah kiri titik bawah pada grafik (seperti yang ditunjukkan pada grafik di bawah). Dalam hal ini (nilainya akan) dari 0,001 menjadi 0,01.
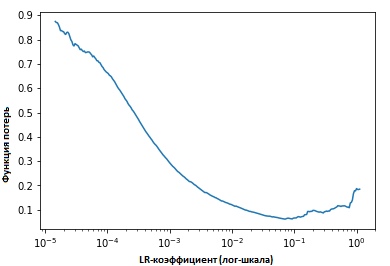
Di atas terlihat bermanfaat. Bagaimana cara menggunakannya?
Saat ini ada fungsi siap pakai dalam paket
fast.ia yang dikembangkan oleh Jeremy Howard, ini adalah semacam abstraksi / add-on di atas perpustakaan pytorch (mirip dengan bagaimana hal itu dilakukan dalam kasus Keras dan Tensorflow).
Anda hanya perlu memasukkan perintah berikut untuk memulai pencarian koefisien kecepatan belajar yang optimal sebelum (memulai) melatih jaringan saraf.
learn.lr_find() learn.sched.plot_lr()
Memperbaiki model
Jadi, kita berbicara tentang apa itu koefisien kecepatan belajar, berapa nilainya dan bagaimana mencapai nilai optimalnya sebelum mulai melatih model itu sendiri.
Sekarang kita akan fokus pada bagaimana faktor kecepatan belajar dapat digunakan untuk model tuning.
Kebijaksanaan Konvensional
Biasanya, ketika pengguna menetapkan koefisien kecepatan belajarnya dan mulai melatih model, ia perlu menunggu sampai koefisien kecepatan belajar mulai turun dan model mencapai nilai optimal.
Namun, dari saat gradien mencapai dataran tinggi, menjadi lebih sulit untuk meningkatkan nilai-nilai fungsi kehilangan saat melatih model. Dalam [3], Dauphin menunjukkan bahwa kesulitan dalam meminimalkan fungsi kerugian berasal dari titik sadel, dan bukan dari minimum lokal.
 Titik pelana di permukaan kesalahan. Titik pelana adalah titik dari domain definisi fungsi yang diam untuk fungsi yang diberikan, tetapi bukan ekstrem lokalnya
Titik pelana di permukaan kesalahan. Titik pelana adalah titik dari domain definisi fungsi yang diam untuk fungsi yang diberikan, tetapi bukan ekstrem lokalnya . (ImgCredit: safaribooksonline)
Jadi bagaimana ini bisa dihindari?
Saya mengusulkan untuk mempertimbangkan beberapa opsi. Salah satunya, umum, menggunakan kutipan dari [1],
... alih-alih menggunakan nilai tetap untuk koefisien kecepatan belajar dan menguranginya seiring waktu, jika pelatihan tidak lagi memperlancar kerugian kita, kita akan mengubah koefisien kecepatan belajar di setiap iterasi sesuai dengan beberapa fungsi siklik f. Setiap loop memiliki - dalam hal jumlah iterasi - panjang yang tetap. Metode ini memungkinkan koefisien kecepatan belajar bervariasi antara nilai batas yang masuk akal. Ini sangat membantu, karena, terjebak dalam poin sadel, dengan meningkatkan koefisien kecepatan belajar kita mendapatkan persimpangan lebih cepat dari dataran tinggi poin sadel
Dalam [2], Leslie mengusulkan "metode segitiga", di mana koefisien kecepatan belajar direvisi setelah masing-masing beberapa iterasi.

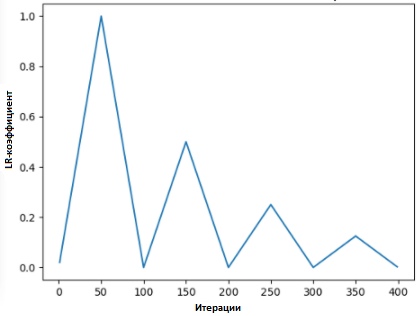 "Metode segitiga" dan "metode segitiga-2" adalah metode untuk pengujian siklus dari koefisien tingkat pembelajaran, yang diusulkan oleh Leslie N. Smith. Pada grafik atas, Ir minimum dan maksimum dijaga tetap sama.
"Metode segitiga" dan "metode segitiga-2" adalah metode untuk pengujian siklus dari koefisien tingkat pembelajaran, yang diusulkan oleh Leslie N. Smith. Pada grafik atas, Ir minimum dan maksimum dijaga tetap sama.Metode lain, yang tidak kalah populer dan disebut "keturunan gradien stokastik dengan reset hangat," diusulkan oleh Lonchilov & Hutter [6]. Metode ini, yang didasarkan pada penggunaan fungsi cosinus sebagai fungsi siklik, memulai kembali koefisien kecepatan belajar pada titik maksimum dalam setiap siklus. Kemunculan bit “Hot” disebabkan oleh fakta bahwa ketika koefisien laju pembelajaran dimulai kembali, itu dimulai bukan dari level nol, tetapi dari parameter yang modelnya telah mencapai langkah sebelumnya.
Karena metode ini memiliki variasi, grafik di bawah ini menunjukkan salah satu metode penerapannya, di mana setiap siklus terikat pada interval waktu yang sama.
 SGDR - grafik, koefisien tingkat pembelajaran vs. iterasi
SGDR - grafik, koefisien tingkat pembelajaran vs. iterasi
Dengan demikian, kita mendapatkan cara untuk mempersingkat durasi pelatihan dengan hanya melompati "puncak" dari waktu ke waktu (seperti yang ditunjukkan di bawah).
 Perbandingan koefisien tingkat pembelajaran tetap dan siklik
Perbandingan koefisien tingkat pembelajaran tetap dan siklik (kredit img:
arxiv.org/abs/1704.00109Selain menghemat waktu, metode ini, menurut penelitian, meningkatkan akurasi klasifikasi tanpa penyetelan dan untuk iterasi yang lebih sedikit.
Rasio belajar transfer dalam Transfer belajar
Dalam perjalanan
fast.ai, penekanannya adalah pada pengelolaan model pra-terlatih dalam memecahkan masalah kecerdasan buatan. Misalnya, ketika menyelesaikan masalah klasifikasi gambar, siswa dilatih menggunakan model pra-terlatih seperti VGG dan Resnet50 dan menghubungkannya dengan sampel data gambar yang perlu diprediksi.
Untuk meringkas bagaimana model dibangun dalam program
fast.ai (jangan bingung dengan
paket Ai. Paket - paket dari program), di bawah ini adalah langkah-langkah yang akan kita ambil dalam situasi biasa:
- Aktifkan augmentasi data dan precompute = True
- Gunakan Ir_find () untuk menemukan koefisien tingkat pembelajaran tertinggi, di mana kerugian masih jelas meningkat.
- Latih lapisan terakhir dari aktivasi yang sudah dihitung sebelumnya untuk era 1-2.
- Latih lapisan terakhir dengan penguatan data (mis., Hitung = salah) selama 1-2 zaman dengan siklus _len 1.
- Lelehkan semua lapisan.
- Tempatkan layer sebelumnya pada faktor kecepatan belajar yaitu 3x-10x di bawah layer tinggi berikutnya
- Gunakan kembali Ir_find ()
- Latih jaringan lengkap dengan siklus _mult = 2 = 2 hingga mulai pelatihan ulang.
Anda mungkin memperhatikan bahwa langkah dua, lima dan tujuh (di atas) terkait dengan tingkat faktor pembelajaran. Di bagian awal posting kami, kami menyoroti poin dari langkah-langkah yang disebutkan kedua - di mana kami menyentuh tentang cara mendapatkan koefisien kecepatan belajar terbaik sebelum Anda mulai melatih model.
Dalam paragraf berikutnya, kita berbicara tentang bagaimana Anda dapat mengurangi waktu pelatihan dengan menggunakan SGDR, dan dengan secara berkala memulai ulang faktor kecepatan belajar, meningkatkan akurasi sehingga Anda dapat menghindari area di mana gradien mendekati nol.
Pada bagian terakhir, kita akan menyentuh pada konsep pembelajaran yang dibedakan dan menjelaskan bagaimana itu digunakan untuk menentukan koefisien kecepatan belajar ketika model yang terlatih dikaitkan dengan ...
Apa itu pembelajaran diferensial
Ini adalah metode di mana berbagai faktor kecepatan pelatihan ditetapkan pada jaringan selama pelatihan. Ini memberikan alternatif cara pengguna biasanya menyesuaikan faktor kecepatan belajar - yaitu, menggunakan faktor kecepatan belajar yang sama melalui jaringan selama pelatihan.
 Alasan saya suka Twitter adalah tanggapan langsung dari orang itu sendiri.
Alasan saya suka Twitter adalah tanggapan langsung dari orang itu sendiri.
(Pada saat menulis posting ini, Jeremy menerbitkan sebuah artikel dengan Sebastian Ruder, yang terjun lebih jauh ke dalam topik ini. Jadi, saya percaya, koefisien diferensial kecepatan belajar sekarang memiliki nama lain - penyetelan tepat diskriminatif :)
Untuk mendemonstrasikan konsep lebih jelas, kita dapat merujuk pada diagram di bawah ini, di mana model yang sebelumnya dilatih "dibagi" menjadi 3 kelompok, di mana masing-masing disesuaikan dengan peningkatan nilai koefisien kecepatan belajar.
 Contoh CNN dengan koefisien tingkat pembelajaran yang dibedakan
Contoh CNN dengan koefisien tingkat pembelajaran yang dibedakan . Kredit gambar dari [3]
Metode konfigurasi ini didasarkan pada pemahaman berikut: beberapa lapisan pertama biasanya berisi detail data yang sangat kecil, seperti garis dan sudut - dari mana kami tidak akan mencoba untuk mengubah banyak dan mencoba menyimpan informasi yang terkandung di dalamnya. Secara umum, tidak ada kebutuhan serius untuk mengubah berat badan mereka ke jumlah besar.
Sebaliknya, untuk lapisan berikutnya - seperti yang ada di gambar dicat hijau, di mana kita mendapatkan tanda-tanda detail data, seperti putih mata, atau mulut, atau hidung - kebutuhan untuk menyelamatkan mereka menghilang.
Bagaimana ini dibandingkan dengan metode fine tuning lainnya?
Dalam [9], terbukti bahwa fine tuning seluruh model akan terlalu mahal, karena pengguna bisa mendapatkan lebih dari 100 lapisan. Paling sering, orang resor untuk mengoptimalkan model satu lapis pada suatu waktu.
Namun, ini adalah alasan untuk sejumlah persyaratan, yang disebut mengganggu konkurensi, dan membutuhkan banyak input melalui satu set data, yang mengarah pada pelatihan berlebih pada set-set kecil.
Kami juga menunjukkan bahwa metode yang disajikan dalam [9] mampu meningkatkan akurasi dan mengurangi jumlah kesalahan dalam berbagai tugas yang berkaitan dengan klasifikasi NRL.
 Hasil diambil dari sumber [9]
Hasil diambil dari sumber [9]Referensi:
[1] Meningkatkan cara kami bekerja dengan tingkat pembelajaran.
[2] Teknik Tingkat Pembelajaran Siklik.
[3] Transfer Pembelajaran menggunakan tingkat pembelajaran diferensial.
[4] Leslie N. Smith. Tarif Belajar Siklus untuk Pelatihan Jaringan Saraf Tiruan.
[5] Memperkirakan Tingkat Pembelajaran Optimal untuk Jaringan Saraf Jauh
[6] Keturunan Gradien Stochastic dengan Menghidupkan Kembali dengan Hangat
[7] Optimalisasi untuk Sorotan Pembelajaran Jauh di 2017
[8] Pelajaran 1 Notebook, fast.ai Bagian 1 V2
[9] Model Bahasa yang Disetel untuk Klasifikasi Teks