Hai, Habr.
Artikel ini akan sedikit berformat "Jumat", hari ini kita akan membahas NLP. Bukan NLP tentang buku mana yang dijual dengan underpass, tetapi buku yang
Natural Processing sedang memproses bahasa alami. Sebagai contoh dari pemrosesan tersebut, pembuatan teks menggunakan jaringan saraf akan digunakan. Kami dapat membuat teks dalam bahasa apa pun, dari Rusia atau Inggris, hingga C ++. Hasilnya sangat menarik, Anda mungkin bisa menebak dari gambar.

Bagi mereka yang tertarik dengan apa yang terjadi, hasil dan kode sumber berada di bawah potongan.
Persiapan data
Untuk pemrosesan, kita akan menggunakan kelas khusus jaringan saraf - jaringan saraf berulang (RNN). Jaringan ini berbeda dari yang biasa selain sel yang biasa, ia memiliki sel memori. Ini memungkinkan kita untuk menganalisis data dari struktur yang lebih kompleks, dan pada kenyataannya, lebih dekat ke memori manusia, karena kita juga tidak memulai setiap pemikiran "dari awal". Untuk menulis kode, kita akan menggunakan
jaringan LSTM (Memori Jangka Pendek), karena sudah didukung oleh Keras.
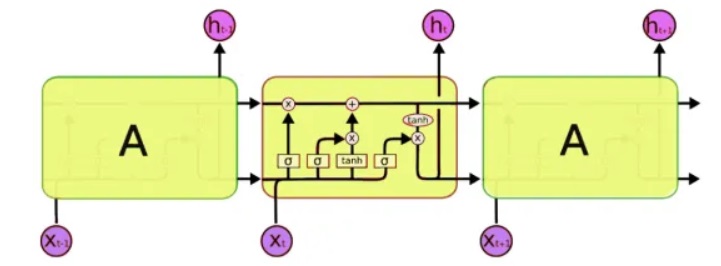
Masalah selanjutnya yang perlu dipecahkan adalah, pada kenyataannya, bekerja dengan teks. Dan di sini ada dua pendekatan - untuk mengirim simbol atau seluruh kata ke input. Prinsip pendekatan pertama adalah sederhana: teks dibagi menjadi blok pendek, di mana "input" adalah bagian dari teks, dan "output" adalah karakter berikutnya. Misalnya, untuk frasa terakhir, 'input adalah bagian dari teks':
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
Dan sebagainya. Dengan demikian, jaringan saraf menerima fragmen teks pada input, dan pada output karakter yang harus dibentuk.
Pendekatan kedua pada dasarnya sama, hanya seluruh kata yang digunakan, bukan kata-kata. Pertama, kamus kata dikompilasi, dan angka dimasukkan alih-alih kata pada input jaringan.
Ini, tentu saja, adalah deskripsi yang agak disederhanakan. Keras
sudah memiliki contoh pembuatan teks, tetapi pertama-tama, mereka tidak dijelaskan secara mendetail, dan kedua, semua tutorial berbahasa Inggris menggunakan teks yang agak abstrak seperti Shakespeare, yang sulit dipahami oleh penduduk asli. Ya, kami sedang menguji jaringan saraf pada jaringan kami yang besar dan kuat, yang, tentu saja, akan lebih jelas dan dapat dimengerti.
Pelatihan jaringan
Sebagai teks input, saya menggunakan ... komentar Habr, ukuran file sumber adalah 1 MB (tentu saja ada lebih banyak komentar, tentu saja, tetapi saya harus menggunakan hanya satu bagian, jika tidak, jaringan saraf akan dilatih selama seminggu dan pembaca tidak akan melihat teks ini pada hari Jumat). Biarkan saya mengingatkan Anda bahwa hanya surat yang dimasukkan ke input jaringan saraf, jaringan "tidak tahu" tentang bahasa atau strukturnya. Ayo, mulai pelatihan jaringan.
5 menit pelatihan:Sejauh ini, tidak ada yang jelas, tetapi Anda sudah dapat melihat beberapa kombinasi huruf yang dapat dikenali:
. . . «
15 menit pelatihan:Hasilnya sudah terasa lebih baik:
« » — « » » —Untuk beberapa alasan, semua teks ternyata tanpa titik dan tanpa huruf kapital, mungkin pemrosesan utf-8 tidak dilakukan dengan benar. Namun secara keseluruhan, ini mengesankan. Dengan menganalisis dan mengingat hanya kode simbol, program ini benar-benar "secara mandiri" mempelajari kata-kata Rusia, dan dapat menghasilkan teks yang terlihat cukup dapat dipercaya.
Yang tidak kalah menariknya adalah kenyataan bahwa program menghafal gaya teks dengan cukup baik. Dalam contoh berikut, teks beberapa undang-undang digunakan sebagai alat bantu mengajar. Waktu pelatihan jaringan 5 menit.
"" , , , , , , , ,
Dan di sini, penjelasan medis untuk obat-obatan digunakan sebagai set input. Waktu pelatihan jaringan 5 menit.
, ,
Di sini kita melihat hampir seluruh frasa. Ini disebabkan oleh fakta bahwa teks aslinya pendek, dan jaringan saraf sebenarnya "menghafal" beberapa frasa secara keseluruhan. Efek ini disebut "pelatihan ulang," dan harus dihindari. Idealnya, Anda perlu menguji jaringan saraf pada set data besar, tetapi pelatihan dalam hal ini bisa memakan waktu berjam-jam, dan sayangnya saya tidak memiliki komputer super.
Contoh menyenangkan menggunakan jaringan seperti itu adalah pembuatan nama. Setelah mengunggah daftar nama pria dan wanita ke file, saya mendapat opsi baru yang cukup menarik yang akan sangat cocok untuk novel fiksi ilmiah: Rlar, Laaa, Aria, Arera, Aelia, Ninran, Air. Sesuatu di dalamnya merasakan gaya Efremov dan Nebula Andromeda ...
C ++
Yang menarik adalah bahwa pada umumnya, jaringan saraf seperti mengingat. Langkah selanjutnya adalah memeriksa bagaimana program menangani kode sumber. Sebagai tes, saya mengambil berbagai sumber C ++ dan menggabungkannya menjadi satu file teks.
Jujur, hasilnya lebih mengejutkan daripada dalam kasus bahasa Rusia.
5 menit pelatihanSial, hampir nyata C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 menit pelatihan void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
Seperti yang Anda lihat, program telah "belajar" untuk menulis seluruh fungsi. Pada saat yang sama, itu sepenuhnya "manusiawi" memisahkan fungsi dengan komentar dengan tanda bintang, memberikan komentar dalam kode, dan semua itu. Saya ingin belajar bahasa pemrograman baru dengan kecepatan seperti itu ... Tentu saja, ada kesalahan dalam kode, dan tentu saja, itu tidak akan dikompilasi. Dan omong-omong, saya tidak memformat kode, program ini juga belajar untuk menempatkan tanda kurung dan lekukan "sendiri".
Tentu saja, program-program ini tidak memiliki
makna utama -
artinya , dan karenanya terlihat tidak nyata, seolah-olah ditulis dalam mimpi, atau tidak ditulis oleh orang yang benar-benar sehat. Meskipun demikian, hasilnya mengesankan. Dan mungkin studi yang lebih dalam tentang pembuatan teks yang berbeda akan membantu untuk lebih memahami beberapa penyakit mental pasien yang sebenarnya. Ngomong-ngomong, seperti yang disarankan dalam komentar, penyakit mental di mana seseorang berbicara dalam teks yang berhubungan dengan tata bahasa tetapi sama sekali tidak berarti (
skizofasia ) memang ada.
Kesimpulan
Jaringan saraf rekreasional dianggap sangat menjanjikan, dan ini memang merupakan langkah maju yang besar dibandingkan dengan jaringan "biasa" seperti MLP, yang tidak memiliki memori. Memang, kemampuan jaringan saraf untuk menyimpan dan memproses struktur yang cukup kompleks sangat mengesankan. Setelah tes-tes ini saya pertama kali berpikir bahwa Ilon Mask mungkin benar dalam sesuatu ketika saya menulis bahwa AI di masa depan bisa menjadi "risiko terbesar bagi umat manusia" - bahkan jika jaringan saraf sederhana dapat dengan mudah mengingat dan mereproduksi pola yang agak rumit, apa yang bisa dilakukan oleh jaringan miliaran komponen? Tetapi di sisi lain, jangan lupa bahwa jaringan saraf kita tidak dapat
berpikir , itu pada dasarnya hanya secara mekanis mengingat urutan karakter, tidak memahami maknanya. Ini adalah poin penting - bahkan jika Anda melatih jaringan saraf pada superkomputer dan kumpulan data besar, paling baik ia akan belajar menghasilkan kalimat yang tata bahasanya 100% benar, tetapi sama sekali tidak berarti.
Tetapi tidak akan dihapus dalam filosofi, artikel itu masih lebih banyak untuk praktisi. Bagi mereka yang ingin bereksperimen sendiri,
kode sumber dengan Python 3.7 ada di bawah spoiler. Kode ini adalah kompilasi dari berbagai proyek github, dan bukan contoh kode terbaik, tetapi tampaknya melakukan tugasnya.
Menggunakan program tidak memerlukan keterampilan pemrograman, cukup untuk mengetahui cara menginstal Python. Contoh mulai dari baris perintah:
- Membuat dan melatih model dan pembuatan teks:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
- Hanya pembuatan teks tanpa pelatihan model:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000 --hasilkan
Saya pikir itu menjadi generator teks yang sangat
funky ,
yang berguna untuk menulis artikel tentang Habr . Yang sangat menarik adalah pengujian pada teks besar dan sejumlah besar iterasi pelatihan, jika ada yang memiliki akses ke komputer cepat, akan menarik untuk melihat hasilnya.
Jika ada yang ingin mempelajari topik lebih detail, deskripsi yang baik tentang menggunakan RNN dengan contoh-contoh terperinci dapat ditemukan di
http://karpathy.imtqy.com/2015/05/21/rnn-effectiveness/ .
PS: Dan akhirnya, beberapa ayat;) Menarik untuk dicatat bahwa bukan saya yang melakukan pemformatan teks atau bahkan menambahkan bintang, "itu saya sendiri." Langkah selanjutnya menarik untuk memeriksa kemungkinan menggambar dan menyusun musik. Saya pikir jaringan saraf cukup menjanjikan di sini.
xxx
bagi sebagian orang, ditangkap dalam cookie - semuanya beruntung di pengadilan roti.
dan di bawah malam dari tamaki
di bawah lilin naik gunung.
xxx
segera putra mons di petachas di trem
cahaya yang tak kasatmata berbau sukacita
itu sebabnya saya mengetuk tumbuh bersama
Anda tidak akan muak dengan hal yang tidak dikenal.
hati untuk memetik ogora terhuyung,
tidak terlalu tua dari sereal yang dimakan,
Saya menjaga jembatan ke bola untuk mencuri.
dengan cara yang sama Darina di Doba,
Saya mendengar di hati saya salju di tangan saya.
kami bernyanyi putih berapa banyak dumina lembut
Aku berbalik volot binatang buas bijih.
xxx
dokter hewan menyalib dengan mantra
dan tumpah di bawah yang terlupakan.
dan Anda, put, seperti dengan cabang-cabang kuba
bersinar di dalamnya.
o bersenang-senang di zakoto
dengan penerbangan susu.
oh kamu mawar, cahaya
cloud light di tangan:
dan berguling di fajar
apa kabar, penunggang kuda saya!
dia melayani di malam hari, bukan ke tulang,
pada malam hari di Tanya lampu biru
seperti semacam kesedihan.Dan beberapa ayat terakhir dalam belajar dengan mode kata. Di sini sajak menghilang, tetapi beberapa makna muncul (?).
dan kamu, dari nyala api
bintang-bintang.
berbicara dengan individu yang jauh.
khawatir kamu rus ,, kamu ,, besok.
"Hujan merpati,
dan rumah bagi para pembunuh,
untuk putri puteri
wajahnya.
xxx
oh gembala, lambaikan kamar
di hutan di musim semi.
Saya akan pergi melalui jantung rumah ke kolam,
dan tikus giat
Nizhny Novgorod lonceng.
tapi jangan takut, angin pagi,
dengan jalan, dengan tongkat besi,
dan berpikir dengan tiram
berlabuh di sebuah kolam
di rakit miskin.