
Banyak aplikasi jaringan terdiri dari server web yang memproses lalu lintas waktu nyata dan penangan tambahan yang berjalan di latar belakang secara tidak sinkron. Ada banyak kiat bagus untuk memeriksa status lalu lintas, dan komunitas tidak berhenti mengembangkan alat seperti Prometheus yang membantu penilaian. Tetapi penangan terkadang tidak kurang - dan bahkan lebih penting -. Mereka juga membutuhkan perhatian dan evaluasi, tetapi ada sedikit panduan tentang bagaimana melakukan ini sambil menghindari perangkap umum.
Artikel ini dikhususkan untuk jebakan yang paling umum dalam proses mengevaluasi penangan tak sinkron, menggunakan contoh insiden di lingkungan produksi di mana, bahkan dengan metrik, tidak mungkin untuk menentukan dengan tepat apa yang dilakukan penangan. Penggunaan metrik telah mengubah fokus sehingga metrik itu sendiri secara terbuka berbohong, kata mereka, penangan Anda ke neraka.
Kami akan melihat cara menggunakan metrik sedemikian rupa untuk memberikan perkiraan yang akurat, dan sebagai kesimpulan kami akan menunjukkan implementasi referensi dari open source prometheus-client-tracer , yang dapat Anda gunakan dalam aplikasi Anda.
Insiden
Peringatan tiba pada kecepatan senapan mesin: jumlah kesalahan HTTP meningkat tajam, dan panel kontrol mengkonfirmasi bahwa antrian permintaan bertambah dan waktu respons habis. Sekitar 2 menit kemudian, antrian dibersihkan, dan semuanya kembali normal.
Setelah diperiksa lebih dekat, ternyata server API kami berdiri, menunggu respons DB, yang menyebabkannya berhenti dan tiba-tiba mendapatkan semua aktivitas. Dan ketika Anda menganggap bahwa beban terberat jatuh lebih sering pada tingkat prosesor asinkron, mereka telah menjadi tersangka utama. Pertanyaan logisnya adalah: apa yang mereka lakukan di sana?!
Metrik Prometheus menunjukkan proses yang membutuhkan waktu, ini dia:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
Dengan melacak total waktu pelaksanaan setiap tugas dan frekuensi perubahan metrik, kami akan mengetahui berapa banyak waktu kerja yang telah dihabiskan. Jika untuk jangka waktu 15 detik. jumlahnya meningkat 15, ini berarti 1 penangan sibuk (satu detik untuk setiap detik terakhir), sementara peningkatan 30 berarti 2 penangan, dll.
Jadwal kerja selama kejadian akan menunjukkan apa yang kita hadapi. Hasilnya mengecewakan; waktu kejadian (16: 02–16: 04) ditandai dengan garis merah yang mengkhawatirkan:

Aktivitas pawang selama kejadian: celah yang nyata terlihat.
Sangat menyakitkan bagi saya, sebagai orang yang men-debug setelah mimpi buruk ini, untuk melihat bahwa kurva aktivitas berada di bagian paling bawah tepat selama insiden. Ini adalah waktu untuk bekerja dengan kait web, di mana kami memiliki 20 penangan khusus. Dari log, saya tahu bahwa mereka semua dalam bisnis, dan saya perkirakan kurva berada sekitar 20 detik, dan saya melihat garis yang hampir lurus. Apalagi, lihat puncak biru besar ini jam 16:05? Dilihat dari jadwal, 20 prosesor single-threaded menghabiskan waktu 45 detik. untuk setiap detik aktivitas, tetapi apakah ini mungkin?!
Dimana dan apa yang salah?
Jadwal kejadian itu bohong: itu menyembunyikan kegiatan kerja dan pada saat yang sama menunjukkan berlebihan - tergantung di mana harus mengukur. Untuk mengetahui mengapa hal ini terjadi, Anda harus mempertimbangkan penerapan pelacakan metrik dan bagaimana interaksi dengan metrik pengumpul Prometheus.
Dimulai dengan cara penangan mengumpulkan metrik, Anda dapat membuat sketsa perkiraan skema implementasi alur kerja (lihat di bawah). Catatan: penangan hanya memperbarui metrik setelah menyelesaikan tugas .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
Prometheus (dengan filosofi penggalian metrik) mengirimkan permintaan GET ke setiap handler setiap 15 detik, mencatat nilai metrik pada saat permintaan. Handler terus-menerus memperbarui metrik dari tugas yang diselesaikan, dan seiring waktu kami dapat secara grafik menampilkan dinamika perubahan nilai.
Masalah dengan under- dan revaluasi mulai muncul setiap kali waktu yang dibutuhkan untuk menyelesaikan tugas melebihi waktu tunggu untuk permintaan yang tiba setiap 15 detik. Misalnya, tugas dimulai 5 detik sebelum permintaan dan berakhir 1 detik setelah. Secara keseluruhan dan umum, ini berlangsung 6 detik, tetapi waktu ini hanya terlihat ketika memperkirakan biaya waktu yang dibuat setelah permintaan, sedangkan 5 dari 6 detik ini dihabiskan sebelum permintaan.
Indikator berbohong bahkan lebih tidak bertuhan jika tugas lebih lama dari periode pelaporan (15 detik). Selama pelaksanaan tugas selama 1 menit, Prometheus akan memiliki waktu untuk mengirim 4 permintaan ke prosesor, tetapi metrik akan diperbarui hanya setelah keempat.
Setelah menggambar garis waktu aktivitas kerja, kita akan melihat bagaimana saat metrik diperbarui memengaruhi apa yang dilihat Prometheus. Dalam diagram di bawah ini, kami memecah garis waktu dua penangan menjadi beberapa segmen yang menampilkan tugas dengan durasi berbeda. Tag merah (15 detik) dan biru (30 detik) menunjukkan 2 sampel data Prometheus; Tugas-tugas yang berfungsi sebagai sumber data untuk penilaian disorot masing-masing dalam warna.
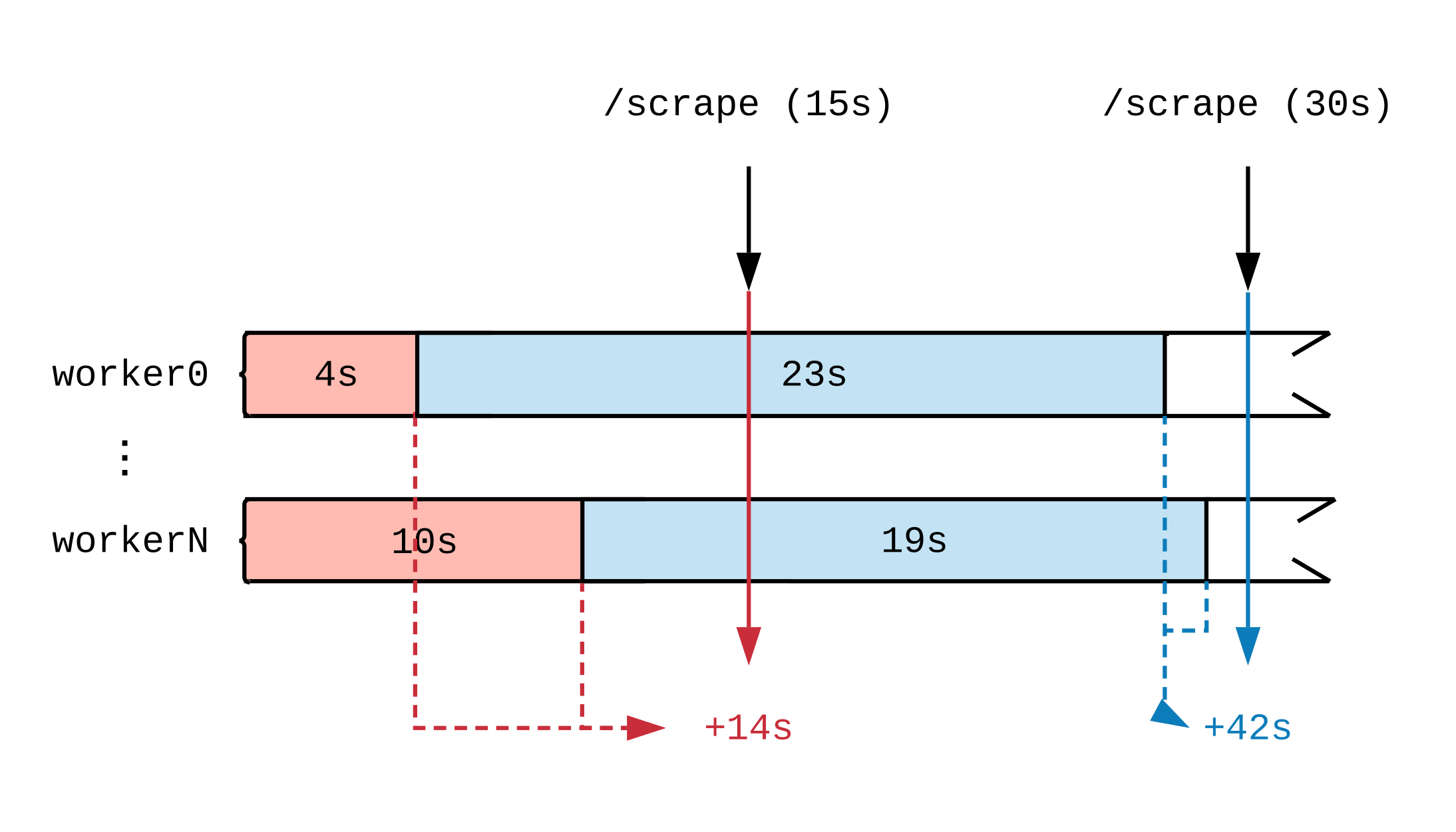
Terlepas dari apa yang dilakukan pawang pada beban penuh, mereka akan melakukan pekerjaan 30 detik setiap interval 15 detik. Karena Prometheus tidak melihat pekerjaan sampai selesai, dilihat dari metrik, 14 detik pekerjaan diselesaikan dalam interval waktu pertama dan 42 detik di detik. Jika setiap pawang mengambil tugas yang banyak, maka bahkan setelah beberapa jam, sampai akhir, kami tidak akan melihat laporan bahwa pekerjaan sedang berlangsung.
Untuk menunjukkan efek ini, saya melakukan percobaan dengan sepuluh penangan yang terlibat dalam tugas yang panjangnya berbeda dan semi normal didistribusikan antara 0,1 detik dan nilai yang sedikit lebih tinggi (lihat tugas acak ). Di bawah ini adalah 3 grafik yang menggambarkan aktivitas kerja; panjang waktu ditampilkan dalam urutan yang meningkat.
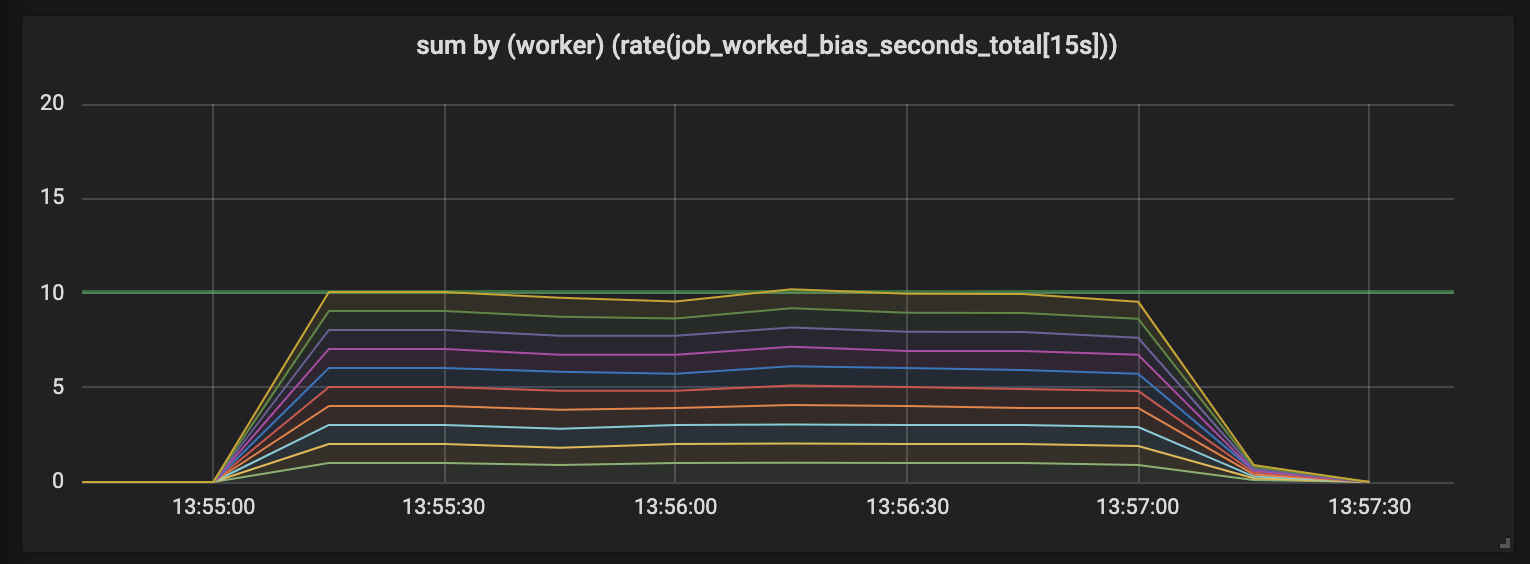
Tugas berlangsung hingga 1 detik.
Grafik pertama menunjukkan bahwa setiap penangan memenuhi sekitar 1 detik pekerjaan dalam setiap detik waktu - ini terlihat pada garis datar, dan jumlah total pekerjaan sama dengan kemampuan kami (10 penangan memberikan pekerjaan kedua per detik waktu). Sebenarnya, ini, terlepas dari panjang tugas, kami berharap: hanya pada tugas pendek dan panjang, prosesor dengan beban konstan harus memberikan.
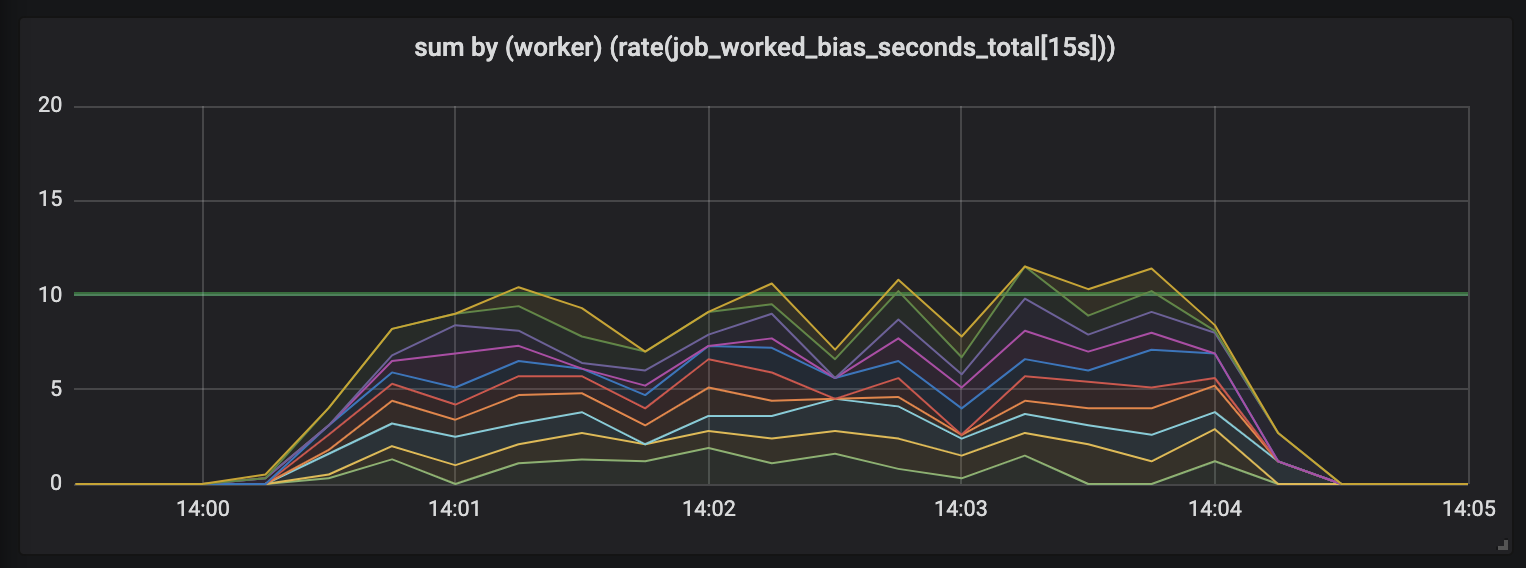
Tugas berlangsung hingga 15 detik.
Durasi tugas bertambah, dan kekacauan muncul dalam jadwal: kami masih memiliki 10 prosesor, semuanya sudah terisi penuh, tetapi jumlah total lompatan pekerjaan - baik yang lebih rendah atau lebih tinggi dari batas kapasitas yang berguna (10 detik).
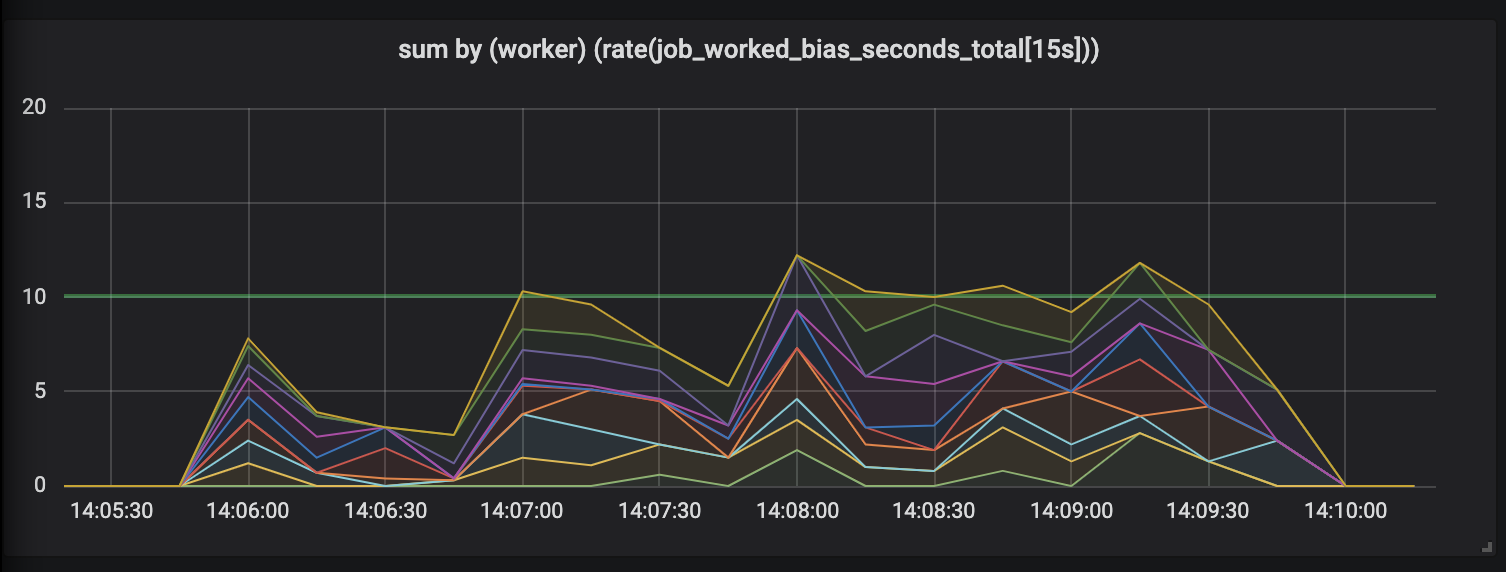
Tugas berlangsung hingga 30 detik.
Evaluasi karya yang berlangsung hingga 30 detik itu konyol. Metrik terikat waktu menunjukkan nol aktivitas untuk tugas terlama dan, hanya ketika tugas selesai, menarik kami puncak aktivitas.
Kembalikan Kepercayaan
Ini tidak cukup bagi kami, jadi ada masalah lain yang jauh lebih berbahaya dengan tugas jangka panjang yang merusak metrik kami. Setiap kali tugas jangka panjang selesai - katakanlah, jika Kubernetes melempar pod keluar dari pool, atau ketika sebuah node mati - lalu apa yang terjadi pada metrik? Layak memperbarui mereka segera setelah menyelesaikan tugas, karena mereka menunjukkan bahwa mereka tidak melakukan pekerjaan sama sekali .
Metrik seharusnya tidak berbohong. Laptop melolong tidak percaya, menyebabkan horor eksistensial, dan alat pengintai yang mendistorsi gambar dunia adalah jebakan dan tidak cocok untuk bekerja.
Untungnya, masalahnya bisa diperbaiki. Distorsi data terjadi karena Prometheus melakukan pengukuran terlepas dari kapan prosesor memperbarui metrik. Jika kami meminta penangan untuk memperbarui metrik saat Prometheus mengirimkan permintaan, kami akan melihat bahwa Prometheus tidak lagi unik dan menunjukkan aktivitas saat ini.
Memperkenalkan ... Pelacak
Salah satu solusi untuk masalah metrik yang terdistorsi adalah Tracer , yang dirancang secara abstrak yang mengevaluasi aktivitas pada tugas-tugas jangka panjang dengan secara bertahap memperbarui metrik terkait Prometheus.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
Pelacak menyediakan metode penelusuran yang menggunakan metrik Prometheus dan tugas untuk dilacak. Perintah trace akan mengeksekusi blok yang diberikan (fungsi anonim Ruby) dan memastikan bahwa permintaan untuk tracer.collect selama eksekusi akan secara bertahap memperbarui metrik terkait, tidak peduli berapa banyak waktu telah berlalu sejak permintaan terakhir untuk collect .
Kita perlu menghubungkan tracer ke penangan untuk melacak durasi tugas dan titik akhir melayani permintaan metrik Prometheus. Kami mulai dengan penangan, menginisialisasi pelacak baru dan memintanya untuk melacak eksekusi dari acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
Pada tahap ini, pelacak hanya akan memperbarui metrik dalam hitungan detik yang dihabiskan untuk tugas yang diselesaikan - seperti yang kami lakukan dalam implementasi awal metrik. Kami harus meminta pelacak untuk memperbarui metrik kami sebelum kami menjalankan permintaan dari Prometheus. Ini dapat dilakukan dengan menyiapkan Rak middleware.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack adalah antarmuka untuk server web Ruby yang memungkinkan Anda untuk menggabungkan beberapa penangan Rack ke dalam satu titik akhir. Perintah config.ru menentukan bahwa aplikasi Rack - setiap kali menerima permintaan - mengirim perintah collect ke handler terlebih dahulu, dan hanya kemudian memberitahu klien Prometheus untuk menggambar hasil pengumpulan.
Adapun bagan kami, kami memperbarui metrik setiap kali tugas selesai atau ketika kami menerima permintaan untuk metrik. Tugas yang memiliki beberapa kueri sama-sama mengirim data di semua segmen: seperti yang ditunjukkan oleh tugas yang durasinya dibagi menjadi interval 15 detik.

Apakah ini lebih baik?
Menggunakan pelacak 24 jam sehari memengaruhi bagaimana aktivitas dicatat. Berbeda dengan pengukuran awal, yang menunjukkan "gergaji," ketika jumlah puncak melebihi jumlah prosesor yang dipicu dan periode keheningan tumpul, percobaan dengan sepuluh prosesor memberikan grafik yang jelas menunjukkan bahwa setiap prosesor dimasukkan ke dalam pekerjaan yang dipantau secara seragam.

Metrik dibangun berdasarkan perbandingan (kiri) dan dikendalikan oleh pelacak (kanan), diambil dari satu percobaan yang bekerja.
Dibandingkan dengan jadwal pengukuran awal yang tidak akurat dan kacau, metrik yang dikumpulkan oleh pelacak ini halus dan konsisten. Kami sekarang tidak hanya secara akurat mengikat pekerjaan dengan setiap permintaan metrik, tetapi juga tidak khawatir tentang kematian mendadak dari salah satu penangan: Prometheus mencatat metrik sampai pawang menghilang, mengevaluasi semua pekerjaannya.
Bisakah ini digunakan?
Ya! Antarmuka Tracer terbukti bermanfaat bagi saya di banyak proyek, jadi ini adalah permata Ruby terpisah, prometheus-client-tracer . Jika Anda menggunakan klien Prometheus di aplikasi Ruby Anda, cukup tambahkan prometheus-client-tracer ke Gemfile Anda:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
Jika ini ternyata bermanfaat bagi Anda dan jika Anda ingin klien resmi Prometheus Ruby muncul di Tracer , tinggalkan ulasan di client_ruby # 135 .
Dan akhirnya, beberapa pemikiran
Saya harap ini membantu orang lain secara lebih sadar mengumpulkan metrik untuk tugas yang sudah berjalan lama dan menyelesaikan salah satu masalah umum. Jangan salah, itu terkait tidak hanya dengan pemrosesan asinkron: jika permintaan HTTP Anda melambat, mereka juga akan mendapat manfaat dari menggunakan pelacak ketika mengevaluasi waktu yang dihabiskan untuk memproses.
Seperti biasa, umpan balik dan koreksi dipersilahkan: tulis ke Twitter atau PR terbuka . Jika Anda ingin berkontribusi pada tracer gem, kode sumbernya ada di prometheus-client-tracer-ruby .