Halo, Habr! Teman-teman kami dari Softpoint telah menyiapkan artikel menarik tentang Microsoft SQL Server. Ini mem-parsing dua contoh praktis menggunakan pencarian teks lengkap:
- Cari di baris "tak terbatas" (mis. Komentar) sebagai lawan dari pencarian reguler melalui LIKE;
- Cari berdasarkan nomor dokumen dengan awalan. Di mana biasanya pencarian teks lengkap tidak dapat digunakan: awalan konstan mengganggu itu. 2 pendekatan dianalisis: preprocessing nomor dokumen dan menambahkan library-word breaker Anda sendiri.
Bergabunglah sekarang!
 Saya memberikan lantai kepada penulis
Saya memberikan lantai kepada penulisPencarian efektif dalam gigabytes data yang terakumulasi adalah semacam "cawan suci" dari sistem akuntansi. Semua orang ingin menemukannya dan mendapatkan kemuliaan abadi, tetapi dalam proses pencarian berulang kali ternyata tidak ada solusi ajaib yang tunggal.
Situasi ini diperumit oleh fakta bahwa pengguna biasanya ingin mencari substring - di suatu tempat ternyata nomor kontrak yang diinginkan "dikubur" di tengah komentar; di suatu tempat, operator tidak ingat persis nama klien, tetapi dia ingat bahwa namanya adalah "Alexey Evgrafovich"; di suatu tempat, Anda hanya perlu menghilangkan bentuk kepemilikan berulang BYUBL dan segera mencari dengan nama organisasi. Untuk DBMS relasional klasik, pencarian semacam itu adalah berita yang sangat buruk. Paling sering, pencarian substring seperti itu dikurangi menjadi pengguliran metodis dari setiap baris tabel. Bukan strategi yang paling efektif, terutama jika ukuran tabel tumbuh hingga beberapa puluh gigabytes.
Dalam mencari alternatif, saya sering mengingat "pencarian teks lengkap". Kegembiraan menemukan solusi biasanya berlalu dengan cepat setelah tinjauan singkat dari praktik yang ada. Ternyata dengan cepat, menurut pendapat populer, pencarian teks lengkap:
- Sulit dikonfigurasikan
- Diperbarui secara perlahan
- Menggantung sistem saat memperbarui
- Memiliki semacam sintaks yang tidak biasa
bodoh - Tidak menemukan apa yang mereka minta
Seperangkat mitos dapat berlanjut untuk waktu yang lama, tetapi bahkan Plato mengajarkan kita untuk menjadi skeptis dan tidak secara buta menerima pendapat orang lain tentang iman. Mari kita lihat apakah iblis begitu mengerikan saat ia dilukis?
Dan, sementara kita tidak tenggelam dalam penelitian ini, kita akan
langsung menyetujui kondisi penting . Mesin pencarian teks lengkap dapat melakukan lebih dari sekadar pencarian string biasa. Misalnya, Anda dapat menentukan kamus sinonim dan menggunakan kata "kontak" untuk menemukan "telepon". Atau cari kata-kata tanpa memperhatikan bentuk dan akhir. Opsi ini bisa sangat berguna bagi pengguna, tetapi dalam artikel ini kami menganggap pencarian teks lengkap hanya sebagai alternatif dari pencarian baris klasik. Artinya,
kami hanya akan mencari substring yang akan ditentukan di bilah pencarian , tanpa mempertimbangkan sinonim akun, tanpa membawa kata-kata ke bentuk "normal" dan sihir lainnya.
Cara Kerja Pencarian Teks Lengkap MS SQL
Fungsionalitas pencarian teks lengkap dalam MS SQL telah dihapus sebagian dari layanan DBMS utama (di dekat akhir artikel kita akan melihat mengapa ini bisa sangat berguna). Untuk pencarian, indeks khusus dibentuk dengan strukturnya, tidak seperti pohon seimbang biasa.
Adalah penting bahwa untuk membuat indeks pencarian teks lengkap, penting bahwa indeks unik ada di tabel kunci, yang terdiri dari hanya satu kolom - itu adalah pencarian teks lengkap yang akan digunakan untuk mengidentifikasi baris tabel. Seringkali tabel sudah memiliki indeks seperti pada Kunci Utama, tetapi kadang-kadang harus dibuat tambahan.
Indeks pencarian teks lengkap diisi secara asinkron dan keluar dari transaksi. Setelah mengubah satu baris tabel, itu antri untuk diproses. Proses memperbarui indeks menerima dari baris tabel (baris) semua nilai string, "berlangganan" ke indeks, dan memecahnya menjadi kata-kata terpisah. Setelah ini, kata-kata dapat direduksi menjadi bentuk "standar" tertentu (misalnya, tanpa akhir), sehingga lebih mudah untuk mencari berdasarkan bentuk kata. "Stop words" dibuang (kata depan, artikel, dan kata-kata lain yang tidak memiliki makna). Tautan kata-ke-string yang tersisa cocok dengan indeks pencarian teks lengkap.
Ternyata setiap kolom dari tabel yang termasuk dalam indeks melewati pipa seperti itu:
Garis panjang -> wordbreaker -> set bagian (kata) -> stemmer -> kata yang dinormalisasi -> [opsional] berhenti pengecualian kata -> tulis untuk mengindeks
Seperti disebutkan, proses pembaruan indeks asinkron. Berikut dari ini:
- Pembaruan tidak memblokir tindakan pengguna
- Pembaruan menunggu selesainya transaksi perubahan baris dan mulai menerapkan perubahan tidak lebih awal dari komit
- Perubahan pada indeks teks lengkap diterapkan dengan beberapa penundaan relatif terhadap transaksi utama. Yaitu, antara menambahkan baris dan saat ketika dapat ditemukan, akan ada penundaan tergantung pada panjang antrian pembaruan indeks
- Jumlah elemen yang terkandung dalam indeks dapat dipantau oleh kueri:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
Tes praktis. Cari fisik orang dengan nama
Mengisi tabel dengan data
Untuk percobaan, kami akan membuat basis kosong baru dengan satu tabel tempat "rekanan" akan disimpan. Di dalam bidang "deskripsi" akan ada garis dengan nama kontrak, di mana nama rekanan akan disebutkan. Sesuatu seperti ini:
"Kontrak dengan Borovik Demyan Emelyanovich"
Atau lebih:
"Anjing. dengan Borovik-Romanov Anatoly Avdeevich "
Ya, saya ingin memotret diri sendiri langsung dari "arsitektur" seperti itu, tetapi, sayangnya, aplikasi "komentar" atau "deskripsi" seperti itu sering di antara pengguna bisnis.
Selain itu, kami menambahkan beberapa bidang "untuk berat": jika hanya ada 2 kolom dalam tabel, pemindaian sederhana akan membacanya dalam beberapa saat. Kita perlu "mengembang" tabel agar pemindaian panjang. Ini membawa kita lebih dekat ke kasus bisnis nyata: kita tidak hanya menyimpan "deskripsi" dalam tabel, tetapi juga banyak informasi berguna [iblis] lainnya.
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
Pertanyaan selanjutnya adalah di mana bisa mendapatkan begitu banyak nama belakang unik, nama depan, dan patronimik? Saya, menurut kebiasaan lama, bertindak sebagai siswa Rusia yang normal, yaitu pergi ke wikipedia:
- Nama diambil dari halaman Kategori: Nama pria Rusia
- Menulis ulang nama tengah secara manual dari nama, mengubah ujung
- Dengan nama keluarga itu ternyata sedikit lebih rumit. Pada akhirnya, kategori "namesakes" ditemukan. Sedikit perdukunan dengan Python dan di meja terpisah ternyata 46,5 ribu nama. (skrip untuk mengunduh nama keluarga tersedia di sini)
Tentu saja, ada variasi aneh di antara nama keluarga, tetapi untuk tujuan penelitian ini cukup dapat diterima.
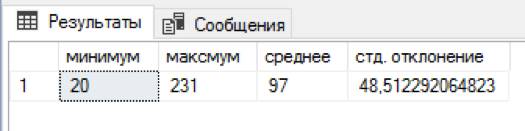
Saya menulis skrip sql yang melampirkan nomor acak nama dan patronimik untuk setiap nama belakang. 5 menit menunggu dan di meja terpisah sudah ada 4,5 juta kombinasi. Tidak buruk! Untuk setiap nama keluarga ada 20 hingga 231 kombinasi nama + nama tengah, rata-rata 97 kombinasi diperoleh. Distribusi berdasarkan nama dan patronimik ternyata sedikit bias “ke kiri,” tetapi tampaknya berlebihan untuk menghasilkan algoritma yang lebih seimbang.
Data sudah disiapkan, kita bisa memulai eksperimen kita.
Pengaturan Pencarian Teks Lengkap
Buat indeks teks lengkap di tingkat MS SQL. Pertama, kita perlu membuat repositori untuk indeks ini - katalog teks lengkap.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
Ada katalog, kami mencoba menambahkan indeks teks lengkap untuk tabel kami ... dan tidak ada yang berhasil.
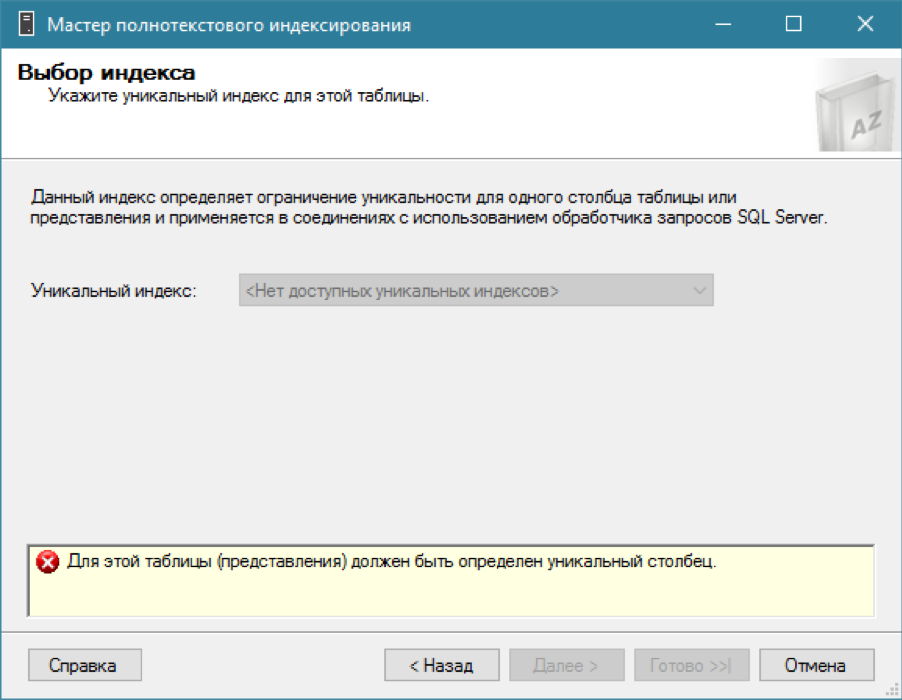
Seperti yang saya katakan, untuk indeks teks lengkap Anda memerlukan indeks reguler dengan satu kolom unik. Kami ingat bahwa kami sudah memiliki bidang yang diperlukan - id pengidentifikasi unik. Mari kita buat indeks cluster unik di atasnya (meskipun yang tidak tercakup akan cukup):
create unique clustered index ndx1 on partners (id)
Setelah membuat indeks baru, kami akhirnya dapat menambahkan indeks pencarian teks lengkap. Mari kita tunggu beberapa menit sampai indeks penuh (ingat bahwa itu diperbarui secara tidak sinkron!). Anda dapat melanjutkan ke tes.
Pengujian
Mari kita mulai dengan skenario paling sederhana, dekat dengan aplikasi sebenarnya dari pencarian. Kami mensimulasikan "tampilan daftar" - pilihan jendela 45 baris dengan pemilihan berdasarkan topeng pencarian. Kami mengeksekusi permintaan dengan indeks teks lengkap baru, kami mencatat waktu - 0 detik - luar biasa!
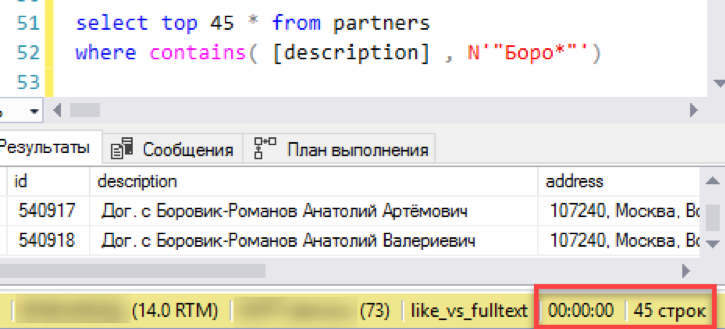
Sekarang pencarian lama dan terbukti melalui "suka". Butuh 3 detik untuk membentuk hasilnya. Tidak terlalu buruk, kekalahan total tidak berhasil. Mungkin saat itu tidak masuk akal untuk mengatur pencarian teks lengkap - apakah semuanya bekerja dengan baik?
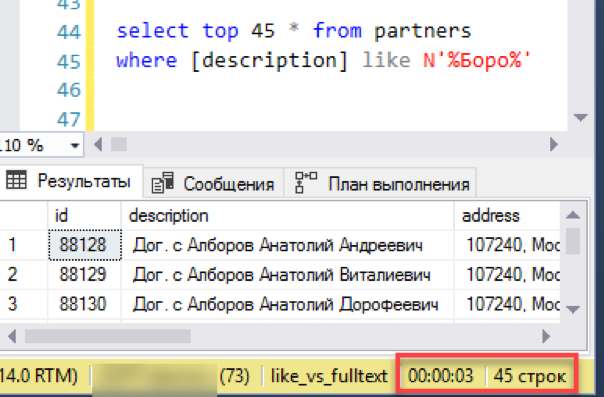
Bahkan, kami melewatkan satu detail penting: permintaan dieksekusi tanpa penyortiran. Pertama, permintaan seperti itu dipasangkan dengan "memilih catatan N pertama" mengembalikan hasil yang tidak beralasan. Setiap awal dapat mengembalikan catatan N acak dan tidak ada jaminan bahwa dua mulai berturut-turut akan memberikan kumpulan data yang sama. Kedua, jika kita berbicara tentang "melihat daftar dengan jendela geser" - biasanya "jendela" ini diurutkan berdasarkan kolom mana saja, misalnya, dengan nama. Lagi pula, operator perlu tahu apa yang akan ia dapatkan ketika ia pindah ke "jendela" berikutnya.
Perbaiki eksperimen. Tambahkan penyortiran, katakanlah, dengan nomor telepon:
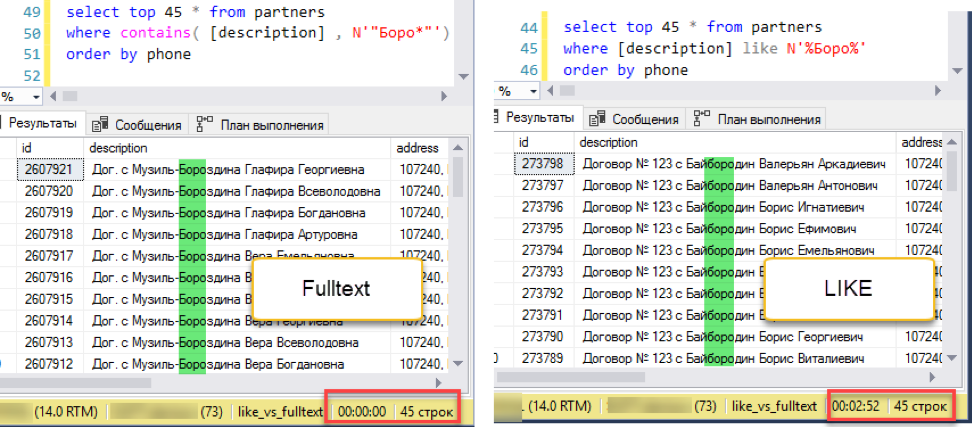 Pencarian teks lengkap menang dengan skor memekakkan: 0 detik versus 172 detik!
Pencarian teks lengkap menang dengan skor memekakkan: 0 detik versus 172 detik!Jika Anda melihat rencana kueri, menjadi jelas mengapa demikian. Karena penambahan pemesanan ke teks kueri, operasi pengurutan muncul selama eksekusi. Ini adalah operasi yang disebut "pemblokiran", yang tidak dapat menyelesaikan permintaan sampai menerima seluruh jumlah data untuk disortir. Kami tidak dapat mengambil 45 catatan pertama yang kami miliki, kami perlu mengurutkan seluruh kumpulan data.
Dan pada tahap memperoleh data untuk disortir, perbedaan dramatis terjadi. Pencarian dengan "suka" harus menelusuri seluruh tabel yang tersedia. Ini membutuhkan 172 detik. Tetapi pencarian teks lengkap memiliki struktur yang dioptimalkan sendiri, yang segera mengembalikan tautan ke semua entri yang diperlukan.
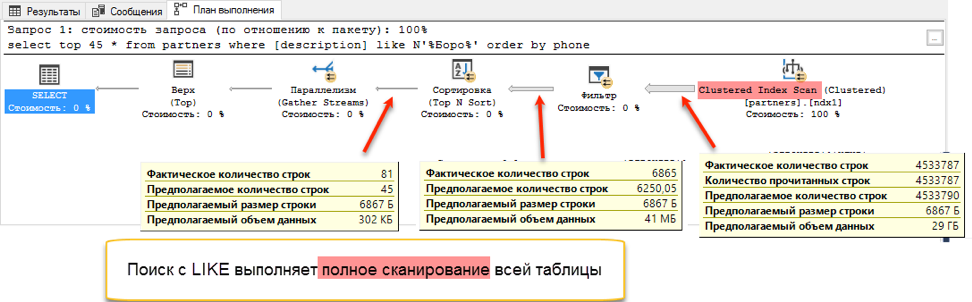
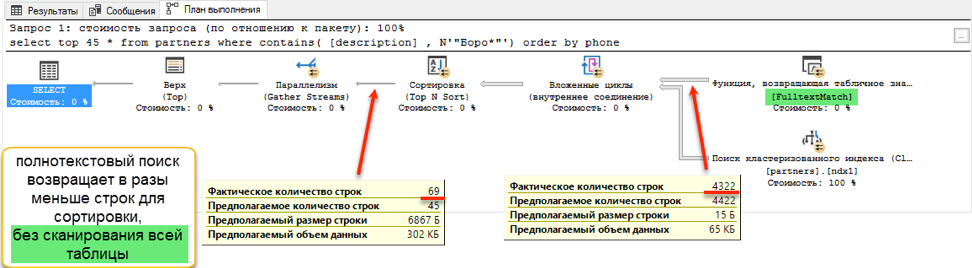
Tetapi apakah harus ada lalat di salep? Ada satu. Seperti yang dinyatakan di awal, pencarian teks lengkap hanya dapat mencari dari awal kata. Dan jika kita ingin menemukan "Ivan Poddubny" oleh substring "* oak *", pencarian teks lengkap tidak akan menunjukkan sesuatu yang berguna.
Untungnya, untuk mencari berdasarkan nama, ini bukan skenario paling populer.
Cari dokumen berdasarkan nomor
Mari kita coba sesuatu yang lebih rumit. Kasus penggunaan populer kedua untuk mencari adalah menemukan dokumen berdasarkan bagian dari nomornya. Selain itu, seringkali nomor dokumen terdiri dari dua bagian: awalan huruf dan angka aktual yang mengandung angka nol di depan.
Tidak ada spasi atau karakter layanan di antara bagian-bagian ini. Pada saat yang sama, mencari dengan angka penuh sangat merepotkan - Anda harus ingat berapa banyak angka nol di depan setelah awalan harus sebelum bagian awal yang penting. Ternyata pencarian teks lengkap "out of the box" sama sekali tidak berguna dalam skenario seperti itu. Mari kita coba memperbaikinya.
Untuk pengujian, saya membuat tabel baru yang disebut dokumen, di mana saya menambahkan 13,5 juta catatan dengan nomor unik dari tipe "ORG". Penomoran berjalan berurutan, semua angka dimulai dengan "ORG". Anda bisa mulai.
Pra-pemisahan nomor
Pencarian teks lengkap dapat secara efisien mencari kata-kata. Nah, mari kita bantu dia dan memecah nomor "tidak nyaman" menjadi kata-kata yang nyaman di muka. Rencana tindakan adalah sebagai berikut:
- Tambahkan kolom tambahan ke tabel sumber tempat nomor yang dikonversi secara khusus akan disimpan
- Tambahkan pemicu, yang ketika mengubah nomor akan memecahnya menjadi beberapa bagian kecil, dipisahkan oleh spasi
- Pencarian teks lengkap sudah tahu cara membagi string menjadi bagian-bagian dengan spasi, sehingga akan mengindeks nomor yang dimodifikasi tanpa masalah
Mari kita lihat bagaimana ini akan bekerja.
Tambahkan kolom tambahan ke tabel.
alter table document add number_parts nvarchar(128) not null default ''
Pemicu yang mengisi kolom baru dapat ditulis "dahi", mengabaikan kemungkinan duplikat (berapa kali lipat tiga kali lipat dalam angka "0000012"?) Dan Anda dapat menambahkan beberapa sihir XML dan merekam hanya bagian-bagian unik. Implementasi pertama akan lebih cepat, yang kedua akan memberikan hasil yang lebih kompak. Bahkan, pilihannya adalah antara kecepatan menulis dan kecepatan membaca, pilih apa yang lebih penting dalam situasi Anda. Sekarang cukup gunakan
skrip yang memproses angka yang ada.
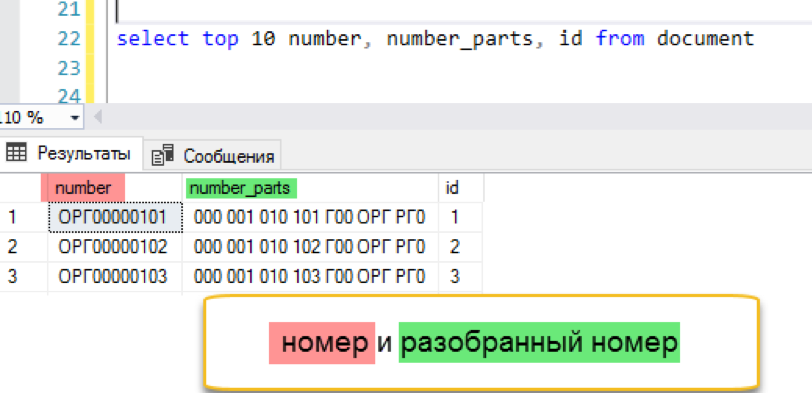
Tambahkan indeks teks lengkap
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
Dan periksa hasilnya. Eksperimennya sama - memodelkan pilihan "jendela" dari daftar dokumen. Kami tidak mengulangi kesalahan sebelumnya dan segera menjalankan permintaan dengan penyortiran, dalam hal ini berdasarkan tanggal.
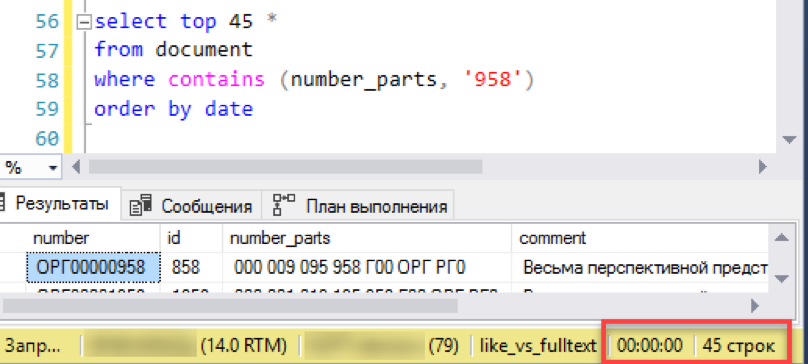
Itu berhasil! Sekarang mari kita coba nomor yang lebih otentik:
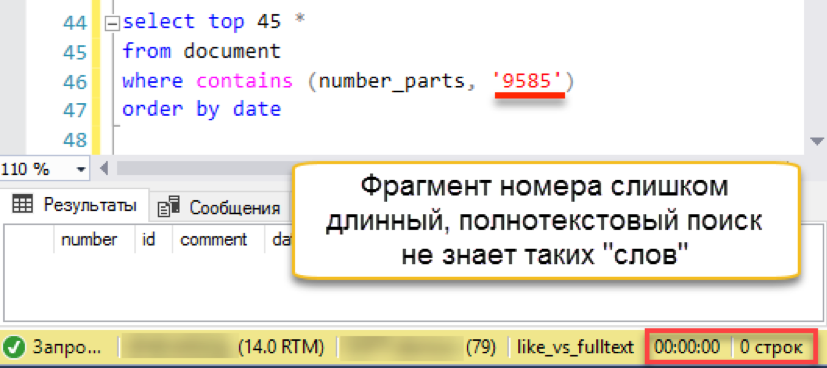
Dan kemudian misfire terjadi. Panjang string pencarian lebih panjang dari panjang "kata" yang disimpan. Faktanya, basis data pencarian tidak memiliki satu baris pun dari 4 karakter, sehingga dengan jujur mengembalikan hasil yang kosong. Kami harus mengalahkan string pencarian menjadi beberapa bagian:
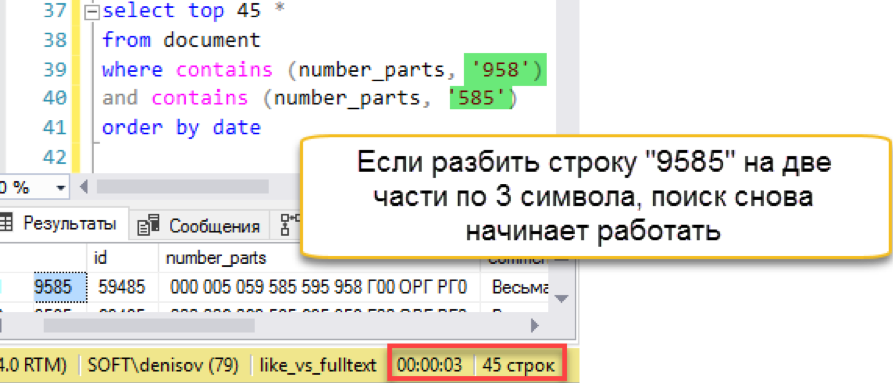
Hal lain! Kami lagi memiliki pencarian cepat. Ya, ia membebankan biaya overhead pada pemeliharaan, tetapi hasilnya ratusan kali lebih cepat daripada pencarian klasik. Kami mencatat upaya yang dihitung, tetapi cobalah untuk menyederhanakan pemeliharaan entah bagaimana - di bagian selanjutnya.
Kami akan memecahnya menjadi kata-kata dengan cara kita sendiri!
Sebenarnya, siapa yang mengatakan bahwa kata-kata harus dipisahkan dengan spasi? Mungkin saya ingin nol di antara kata-kata! (dan, jika mungkin, awalan sehingga itu juga entah bagaimana diabaikan dan tidak mengganggu langkah kaki). Secara umum, tidak ada yang mustahil dalam hal ini. Mari kita ingat skema operasi pencarian teks lengkap dari awal artikel - komponen terpisah, wordbreaker, bertanggung jawab untuk membobol kata-kata, dan, untungnya, Microsoft memungkinkan Anda untuk menerapkan "pemecah kata" Anda sendiri.
Dan di sini yang menarik dimulai. Wordbreaker adalah dll terpisah yang menghubungkan ke mesin pencarian teks lengkap.
Dokumentasi resmi mengatakan bahwa membuat perpustakaan ini sangat sederhana - cukup terapkan antarmuka IWordBreaker. Dan berikut adalah beberapa daftar inisialisasi singkat di C ++. Sangat berhasil, saya baru saja menemukan tutorial yang sesuai!

(
sumber )
Serius, dokumentasi untuk membuat pemecah masalah Anda sendiri di Internet semakin kecil. Contoh dan templat yang lebih sedikit. Tapi saya masih menemukan
proyek orang baik yang menulis di C ++ implementasi yang memecah kata-kata bukan oleh pemisah, tetapi hanya dengan tiga kali lipat (ya, seperti di bagian sebelumnya!) Selain itu, folder proyek sudah berisi biner yang disusun dengan hati-hati, yang hanya Anda perlukan terhubung ke mesin pencari.
Cukup mencolokkan ... Sebenarnya tidak terlalu mudah. Mari kita ikuti langkah-langkahnya:
Anda perlu menyalin pustaka ke folder dengan SQL Server:

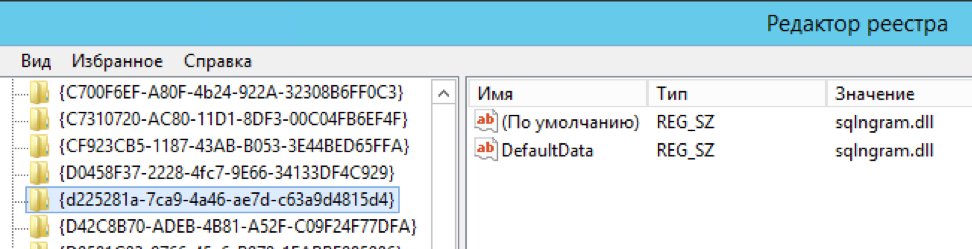
Daftarkan "bahasa" baru dalam pencarian teks lengkap
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
Secara manual mengedit beberapa kunci dalam registri (penulis akan mengotomatiskan proses, tetapi tidak ada berita sejak 2016. Namun, ini awalnya merupakan "contoh implementasi", terima kasih untuk itu juga)
Langkah-langkahnya dijelaskan secara rinci di halaman proyek.
Selesai Mari kita hapus indeks teks lengkap lama, karena tidak ada dua indeks teks lengkap untuk satu tabel. Buat yang baru dan indeks nomor dokumen kami. Sebagai kolom kunci, kami menunjukkan angka-angka itu sendiri, tidak ada lagi kolom pra-patah pengganti yang diperlukan. Pastikan untuk menentukan "nomor bahasa 1" untuk menggunakan wordbreaker yang baru diinstal.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
Periksa?
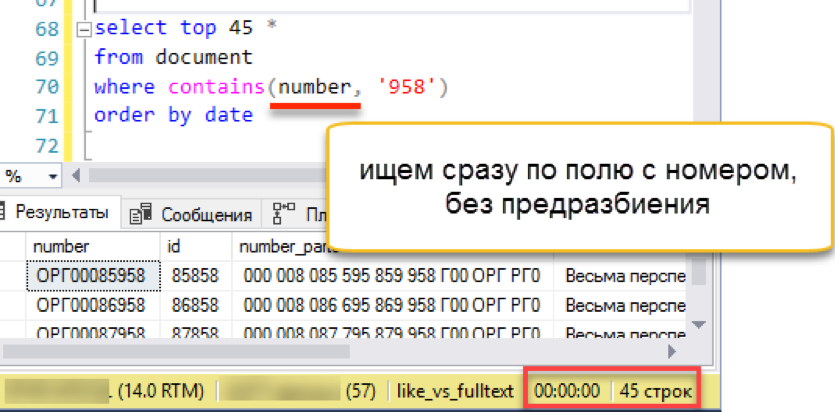
Itu berhasil! Ini bekerja secepat semua contoh yang dibahas di atas.
Mari kita periksa garis panjang di mana opsi sebelumnya tersandung:
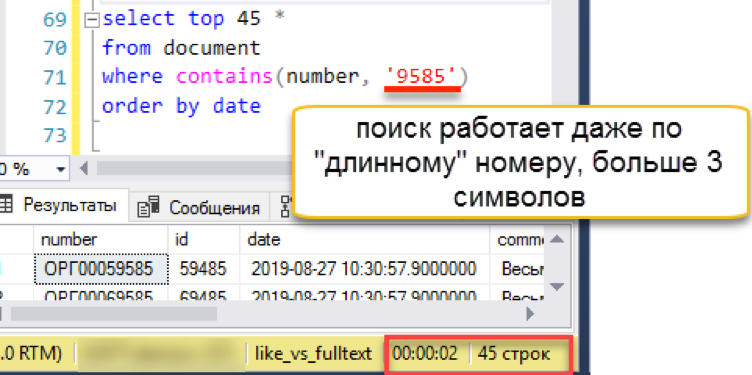
Pencarian berfungsi secara transparan untuk pengguna dan pemrogram. Wordbreaker secara terpisah memecah string pencarian menjadi beberapa bagian dan menemukan hasil yang diinginkan.
Ternyata sekarang kita tidak perlu kolom dan pemicu tambahan, yaitu solusinya lebih sederhana (baca: lebih dapat diandalkan) daripada upaya kami sebelumnya. Nah, dalam hal dukungan, implementasi seperti itu lebih sederhana dan lebih transparan, ada sedikit kemungkinan kesalahan.
Jadi, hentikan, saya bilang "lebih bisa diandalkan"? Kami baru saja menghubungkan beberapa perpustakaan pihak ketiga ke DBMS kami! Dan apa yang akan terjadi jika dia jatuh? Bahkan secara tidak sengaja menyeret seluruh layanan basis data!
Di sini Anda perlu mengingat bagaimana pada awal artikel saya menyebutkan layanan pencarian teks lengkap, terpisah dari proses DBMS utama. Di sinilah menjadi jelas mengapa ini penting. Perpustakaan terhubung ke layanan pengindeksan teks lengkap, yang dapat beroperasi dengan hak berkurang. Dan, yang lebih penting, jika komponen pihak ketiga jatuh, hanya layanan pengindeksan akan jatuh. Pencarian akan berhenti untuk sementara waktu (tetapi sudah tidak sinkron), dan mesin basis data akan terus bekerja seolah-olah tidak ada yang terjadi.
Untuk meringkas. Menambahkan wordbreaker Anda sendiri bisa menjadi tantangan. Tetapi ketika bermain "dalam jangka panjang", upaya ini membuahkan hasil dengan fleksibilitas yang lebih besar dan kemudahan perawatan. Pilihan, seperti biasa, adalah milikmu.
Mengapa semua ini perlu?
Seorang pembaca yang ingin tahu mungkin bertanya-tanya lebih dari sekali: "semua ini bagus, tetapi bagaimana saya bisa menggunakan fitur ini jika saya tidak dapat mengubah permintaan pencarian dari aplikasi saya?" Pertanyaan yang masuk akal Dimasukkannya teks pencarian MS SQL penuh membutuhkan perubahan sintaks dari query, dan seringkali ini tidak mungkin dalam arsitektur yang ada.
Anda dapat mencoba mengelabui aplikasi dengan "menyelipkan" fungsi bernilai-tabel dengan nama yang sama dan bukan tabel biasa, yang sudah akan melakukan pencarian seperti yang kita inginkan. Anda dapat mencoba mengikat pencarian sebagai semacam sumber data eksternal. Ada solusi lain - Softpoint Data Cluster - layanan khusus yang menginstal "penerusan" antara aplikasi sumber dan layanan SQL Server, mendengarkan lalu lintas dan dapat mengubah permintaan "dengan cepat" sesuai dengan aturan khusus. Dengan menggunakan aturan ini, kami dapat menemukan kueri reguler dengan LIKE dan mengonversinya menjadi WADAH dengan pencarian teks lengkap.
Mengapa kesulitan seperti itu? Namun, kecepatan pencariannya sangat menawan. Dalam sistem yang sarat muatan, di mana operator sering mencari catatan dalam jutaan tabel, kecepatan respons sangat penting. Menghemat waktu pada operasi yang paling sering menghasilkan puluhan aplikasi tambahan yang diproses, dan ini adalah uang sungguhan, yang membuat bisnis senang. Pada akhirnya, beberapa hari atau bahkan berminggu-minggu untuk mempelajari dan mengimplementasikan teknologi akan terbayar dengan peningkatan efisiensi operator.
Semua skrip yang disebutkan dalam artikel tersedia di repositori
github.com/frrrost/mssql_fulltextTentang penulis
 Alexander Denisov
Alexander Denisov - Analis Kinerja Database MS SQL Server. Selama 6 tahun terakhir, sebagai bagian dari tim Softpoint, saya telah membantu menemukan kemacetan dalam permintaan orang lain dan memanfaatkan basis data klien sebaik-baiknya.