Mikhail Konovalov, Kepala Departemen Dukungan Proyek Integrasi, Direktorat IT ICDSelamat siang, Khabrovit!
Tujuan
Pendekatan sistematis untuk mengelola unduhan. Kami ingin memberi tahu cara merampingkan dan mengotomatiskan pengisian repositori dengan informasi, dan pada saat yang sama tidak menjadi bingung dalam aliran dari berbagai sumber.
Pembukaan
Cepat atau lambat, suatu saat muncul dalam basis data perusahaan dari perusahaan mana pun ketika tumbuh dengan ukuran yang mata arsiteknya berhenti untuk menangkap ketidakpastian (kekacauan) sistem, dan berubah menjadi massa yang tidak terkendali dari semua jenis unduhan dari berbagai sumber.
Anda beruntung jika sistem Anda dikembangkan dari awal (dari tabel pertama) dan dijalankan oleh satu arsitek, satu tim pengembang dan analis. Dan selain itu, arsitek ini kompeten memimpin model data warehouse. Tapi hidup ini beragam, dalam banyak kasus DWH tumbuh secara spontan, pada awalnya ada 30 tabel, kemudian kami menambahkan sedikit lebih banyak sesuai kebutuhan, dan kemudian kami menyukainya dan kami mulai menambahkan untuk setiap kesempatan, dan sekarang kami memiliki lebih dari lima ribu, ya layer, staging dan showcases masih muncul. Dan semua "kebahagiaan" ini jatuh pada kita sebagai hasil dari satu, tetapi proses yang sangat nyaman, yang merupakan hubungan kausal yang sulit:
- bisnis mengatakan: “Kami memiliki kebutuhan akan data ini dan itu. Butuh laporan baru »
- analis melihat
- implementasi pengembang
- arsitek mengoordinasikan dan berkontribusi pada model data
Tetapi, sebagai aturan, poin terakhir dalam kenyataan tidak ada. Dan itu muncul hanya pada saat tertentu di perusahaan besar yang telah berkembang menjadi DWH mereka, di mana seorang arsitek yang rapi kompeten mengelola integritas informasi dalam database. Repositori tersebut mewakili tinjauan struktur sebelumnya, yang didokumentasikan ulang, dan sering kali dibangun kembali, dengan memperhatikan versi sebelumnya (tidak didokumentasikan).
Jadi, ringkasan singkat:- tidak ada DWH yang lahir langsung dan sebelumnya tidak mewakili database reguler dengan seperangkat tabel;
- segala sesuatu yang ada sekarang, dan merupakan struktur yang jelas algoritmik dan terdokumentasi, diperoleh sebagai hasil dari "pengalaman pahit" dari perkembangan sebelumnya.
Jika Anda adalah pemilik bahagia dari DWH "benar", atau jika Anda adalah bagian dari tim pemilik bahagia ini, artikel ini "secara teori" mungkin tampak menarik bagi Anda. Dan jika Anda hanya perlu meninjau, atau (melarang Anda) membangun kembali, maka artikel ini dapat sangat menyederhanakan hidup Anda.
Karena dapat terdapat jumlah sumber informasi yang tidak terbayangkan, setidaknya ada jumlah unduhan dan aliran yang berlebih dari objek yang berbeda, dan seringkali lebih, karena setiap objek basis data dapat melalui lebih dari satu transformasi sebelum datanya dapat digunakan oleh pengguna akhir untuk membangun laporan bisnis. Tapi itu untuknya, untuk bisnis, dan bukan untuk kesenangannya sendiri bahwa seluruh ekosistem ini dibangun untuk "transfusi dari satu kapal ke kapal".
Oracle digunakan sebagai basis data penyimpanan kami. Suatu ketika, pada tahap pembuatan, inti pusat dari basis data kami terdiri dari beberapa ratus tabel. Kami tidak berpikir tentang pementasan dan jendela toko. Tetapi, seperti yang mereka katakan, "semuanya mengalir, semuanya berubah", dan sekarang kami telah tumbuh! Bisnis menentukan persyaratan baru, dan integrasi dengan berbagai database MS SQL, SyBASE, Vertica, Access telah muncul. Dari mana informasi tidak mengalir kepada kami, bahkan eksotis seperti pertukaran XML dan JSON dengan sistem pihak ketiga muncul, dan file XLS sebagai sumber informasi benar-benar ketinggalan zaman.
Life membuat kami melalui peninjauan dan memperbarui model data, mempertahankan dan memeliharanya. Inilah salah satu bagian inti utama:
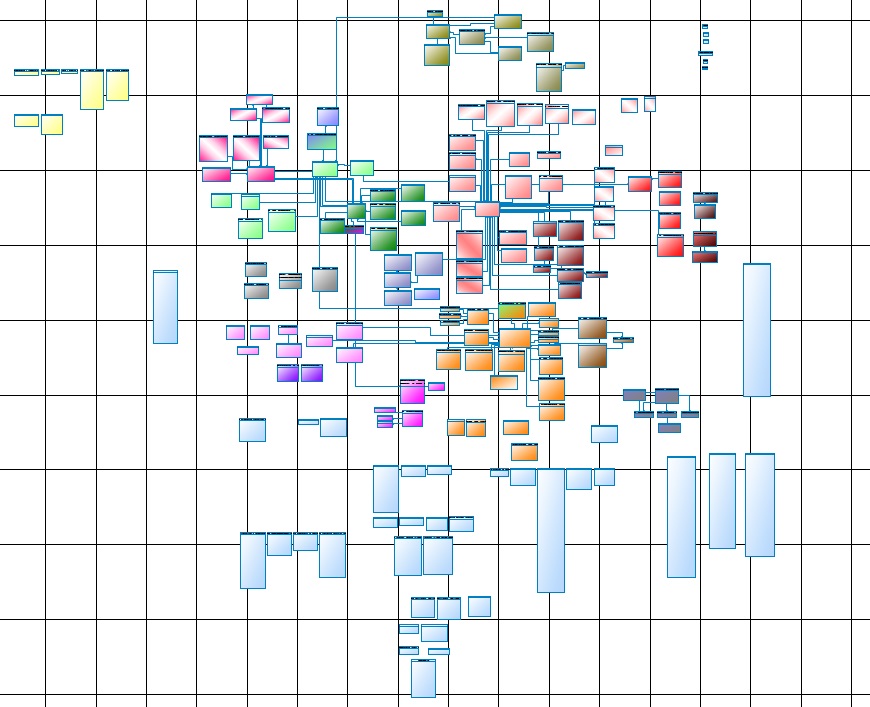 Fig. 1
Fig. 1Untuk siapa itu, tetapi bagi saya - itu hanya dapat dibaca di atas kertas Whatman, dan A0 akan sedikit kecil, lebih baik dari 4A0, di layar itu tidak menyerah pada mata atau imajinasi.
Sekarang ingat bahwa ini hanya inti (Core Data Layer), atau lebih tepatnya bagian utamanya, inti penuh terdiri dari beberapa subsistem yang tidak kalah dengan yang utama.
Lapisan Data Primer dan
Lapisan Data Mart juga ditambahkan ke sini. Selanjutnya - lebih lanjut, lapisan utama menerima informasinya dari sumber data, dan ini, sebagaimana disebutkan di atas, berbagai database dan file. Di sisi lain, ke lapisan jendela toko, berbagai sistem pelaporan bergabung dengan konsumen.
Pada awalnya, ketika ada beberapa tabel database dan algoritma pemuatan diimplementasikan dalam PL / SQL, tidak ada kesulitan khusus dalam memahami pembaruan data. Tetapi dengan munculnya DWH, keputusan strategis adalah untuk membeli Informatica PowerCenter. Dengan semua kemudahan dari alat ini, baik dalam hal keandalan pemuatan dan visualisasi pengembangan, alat ini memiliki beberapa kelemahan. Gambar di bawah ini menunjukkan model untuk urutan startup untuk memuat DWH.
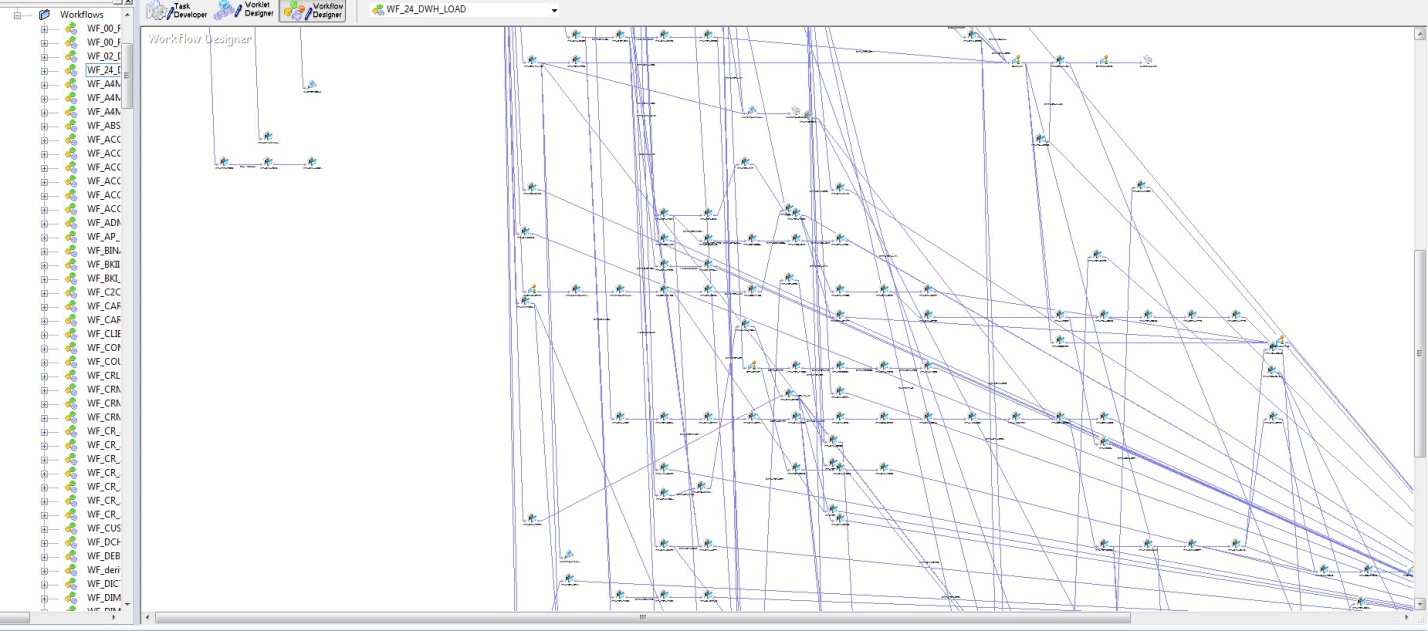 Fig. 2
Fig. 2Kerugian yang paling penting adalah subjektivitas, atau lebih tepatnya, hanya arsitek yang dapat menjamin bahwa posting tidak dimuat sebelum tagihan. Sayangnya, dengan pertumbuhan DWH, entropi informasi juga meningkat. Dengan mempertimbangkan model data fisik (Gbr. 1) dan logika memuat data ini (Gbr. 2), konstruksi masih diperoleh.
Apa yang harus dilakukan dan bagaimana mengarahkannya, Anda bertanya. Wajar: memiliki arsitek yang brilian yang mampu memahami semua koneksi seluk-beluk ini. Yang akan memonitor semua aliran, mengoordinasikan aliran baru, dan mencegah tabel posting dimuat lebih awal dari tabel akun. Tentu saja, semua ini dijahit ke dalam algoritma dan diatur oleh cutoffs unduhan, tetapi pada awalnya hanya seorang arsitek yang dapat memahami dan mengatur unduhan ke urutan yang ketat, dan dengan percabangan seperti itu, kemungkinan kesalahan sangat tinggi.
Teori
Sekarang saya akan mencoba untuk menyatakan ide-ide utama dari kamus model data, serta tugas-tugas apa yang dipecahkannya.
Karena data dalam penyimpanan berada dalam tabel, dan sumber data sebagian tabel, dan sebagian tampilan, yang terakhir itu sendiri adalah tabel. Kemudian ide sederhana berikut - untuk membuat struktur ketergantungan
TABEL - TABEL . Formulir
3NF sangat cocok untuk ini.
Pertama, mengisi data entitas DWH, kami menyebutnya
(target) , dalam kasus yang paling umum, dapat direpresentasikan sebagai
pilih dari tabel yang berbeda. Apakah itu tabel Oracle, SyBase, MSSQL, file xls atau yang lainnya, itu tidak begitu penting, semua ini, kami sebut sumbernya
(sumber) . Artinya, kami memiliki
sumber yang mengalir ke
target .
Kedua, setiap entitas DWH memiliki referensi satu sama lain.
Ketiga, ada kronologi memulai unduhan berbagai entitas DWH.
Tetap kecil, untuk menerapkan - bagaimana? Tampaknya sangat sederhana, dari dasar DWH Anda, sang arsitek, ketika tabel entitas berikutnya
(target) muncul, harus melihat dan memasukkan ke dalam kamus entitas penerima dan semua entitas yang berfungsi sebagai sumber. Selanjutnya, dalam tabel kedua kamus, tentukan tautan antara sumber entitas ini di pilih, serta semua tabel bawahan yang referensi tertaut. Selanjutnya, Anda dapat menanamkan pemuatan entitas ini dalam rantai unduhan penyimpanan. Hanya dua tabel - dan kemungkinan memperhitungkan urutan pengisian data dengan algoritme dalam algoritma diselesaikan.
Model data kamus akan menyelesaikan masalah-masalah berikut:
- Lihat dependensi. Anda dapat melihat data apa, dari mana mereka berasal. Ini cocok untuk analis yang selalu tersiksa oleh pertanyaan: "di mana, apa yang terletak dan dari mana segala sesuatu berasal." Hadir ini dalam aplikasi dalam bentuk pohon, baik dari sumber ke target , dan sebaliknya: dari target ke sumber .
- Pecahnya loop. Saat menanamkan muatan berikutnya ke aliran bersama yang sudah berfungsi, tanpa memiliki kamus model data, sangat mungkin untuk membuat kesalahan dan menetapkan waktu mulai untuk memuat target berikutnya di depan salah satu sumbernya. Ini menciptakan satu lingkaran. Kamus model data akan dengan mudah menghindari ini.
- Anda dapat menulis algoritme untuk mengisi penyimpanan berdasarkan kamus model. Dalam hal ini, tidak perlu menyematkan unduhan berikutnya di mana saja, cukup cantumkan dalam kamus dan algoritme akan menentukan tempatnya. Tetap mengklik tombol "Make ALL" yang didambakan. Bootloader akan meluncurkan unduhan seperti longsoran semua entitas penyimpanan - dari yang sederhana (independen) hingga kompleks (tergantung).
Implementasi
Secara teori, semuanya selalu sederhana dan indah, dalam praktiknya, segalanya agak berbeda. Apa yang ditulis di bagian sebelumnya adalah situasi yang ideal ketika DWH berkembang dari awal, ketika seorang arsitek tidak terpisahkan darinya. Jika Anda tidak beruntung, Anda telah melewati semua ini dengan aman, tidak ada arsitek, tetapi ada seperangkat meja raksasa, maka bagaimanapun, ada jalan keluar.
Sekarang, sebenarnya, saya akan memberi tahu Anda bagaimana kami berhasil mengejar ketinggalan dan membuat ulasan serta membangun kembali dengan cukup murah. DWH kami mulai berkembang dengan keputusan kepemimpinan tentang kebutuhan yang mendesak (DWH). Sebagai alat, PL / SQL pertama kali digunakan. Beberapa saat kemudian beralih ke Informatica. Secara alami, prioritasnya adalah waktu penciptaan. Model data di PowerDesigner muncul beberapa waktu kemudian, pada saat kepercayaan terbentuk dengan jelas bahwa tidak ada yang bisa membayangkan gambar DWH yang lengkap dan jelas. Kami hidup selama beberapa waktu dengan model di dinding, ketika menjadi jelas bahwa kami tidak dapat mengatasi pengelolaan seluruh sistem ini, kami mulai mencari solusi yang akan saya coba jelaskan secara singkat di sini.
Kamus model data itu sendiri sesederhana tongkat. Tetapi mengisinya adalah masalah. N-bulan yang melelahkan, dan yang paling penting, pertimbangan cermat dari tiga bagian di atas:
- apa sumber (sumber) setiap entitas repositori (target) terdiri dari;
- apa hubungan antara objek penyimpanan (referensi);
- kronologi mulai dari unduhan dan mengisi repositori.
Untungnya, Oracle dan Informatica membantu kami, dan ternyata repositori Informatica berada di database Oracle. Mengambil sebagai dasar bahwa satu Sesi Informatica adalah atom pemuatan entitas DWH, menggali sedikit dalam repositori, kami menemukan semua sumber dan target. Yaitu, dalam kerangka satu Sesi, untuk semua targetnya (sebagai aturan, itu adalah satu), semua sumbernya adalah sumber. Dengan demikian, kita dapat mengisi kondisi pertama dari masalah. Tapi jangan buru-buru bersukacita, sumber dapat disajikan dalam bentuk pilihan yang sangat pintar, jadi Anda harus menulis parser yang mengeluarkan semua tabel yang ditentukan dalam pilih - itu sama sekali tidak sulit. Tapi ini belum semuanya, tabel ini sendiri sebenarnya bisa menjadi representasi. Menggunakan DBA_VIEWS (atau melalui DBA_DEPENDENCIES) masalah ini juga diselesaikan. Kami menarik kondisi kedua dari trilogi ini dari model data (Gbr. 1) dan DBA_CONSTRAINTS. Kami juga mendapatkan kondisi ketiga dari repositori Informatica berdasarkan (Gbr. 2).
Apa yang terjadi dengan semua ini?- Pertama, kami mengurai semua loop yang kami berhasil memutar dalam evolusi DWH kami.
- Kedua, kami memiliki pohon yang bagus untuk analis:

Fig. 3 - Ketiga, superloader kami, disajikan dalam gambar. 2 berubah menjadi elegan (maaf, kolega, tetapi kekaburan gambar disengaja, karena ini adalah data yang berfungsi):
Fig. 4
Anda mungkin memiliki lebih banyak cara untuk menerapkan kamus model data.
Terima kasih semuanya!