Selama setahun terakhir, saya dihadapkan pada kebutuhan untuk menggambar histogram dan grafik batang cukup sering untuk membuat saya ingin dan dapat menulis tentang hal itu. Selain itu, saya sendiri kurang banyak informasi seperti itu. Artikel ini menyediakan ikhtisar 3 metode untuk membuat grafik seperti itu di Python.
Pada awalnya, saya sendiri tidak tahu untuk waktu yang sangat lama dari pengalaman saya: bagan batang dan histogram adalah dua hal yang berbeda. Perbedaan utama adalah bahwa histogram menunjukkan distribusi frekuensi - kami menentukan satu set nilai untuk sumbu Ox, dan frekuensi selalu diplot pada Oy. Dalam bagan batang (yang akan lebih tepat untuk memanggil barplot dalam literatur bahasa Inggris) kami menentukan absis dan ordinatnya.
Untuk demonstrasi, saya akan menggunakan dipukul scikit belajar dataset perpustakaan Iris. Mari kita mulai dengan impor:
import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt from sklearn import datasets iris = datasets.load_iris()
Kami akan mengubah set data iris menjadi kerangka data - sehingga akan lebih mudah bagi kami untuk bekerja dengannya di masa mendatang.
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']], columns= iris['feature_names'] + ['target'])
Dari parameter kami tertarik, data berisi informasi tentang panjang sepal dan kelopak dan lebar sepal dan kelopak.
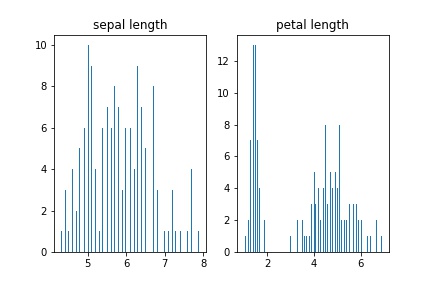
Menggunakan MatplotlibHistogramMari kita membuat histogram teratur yang menunjukkan distribusi frekuensi panjang kelopak dan sepal:
fig, axs = plt.subplots(1, 2) n_bins = len(data) axs[0].hist(data['sepal length (cm)'], bins=n_bins) axs[0].set_title('sepal length') axs[1].hist(data['petal length (cm)'], bins=n_bins) axs[1].set_title('petal length')
 Membangun grafik batang
Membangun grafik batangKami menggunakan metode matplotlib untuk membandingkan lebar daun dan sepal. Ini tampaknya paling mudah dilakukan pada satu grafik:
x = np.arange(len(data[:50])) width = 0.35
Misalnya, dan untuk menyederhanakan gambar, ambil 50 baris pertama dari kerangka data.
fig, ax = plt.subplots(figsize=(40,5)) rects1 = ax.bar(x - width/2, data['sepal width (cm)'][:50], width, label='sepal width') rects2 = ax.bar(x + width/2, data['petal width (cm)'][:50], width, label='petal width') ax.set_ylabel('cm') ax.set_xticks(x) ax.legend()
 Menggunakan metode seaborn
Menggunakan metode seabornMenurut pendapat saya, banyak tugas untuk membuat histogram lebih mudah dan lebih efisien untuk dilakukan menggunakan metode seaborn
(selain itu, seaborn juga menang dengan kemampuan grafisnya, menurut saya) .
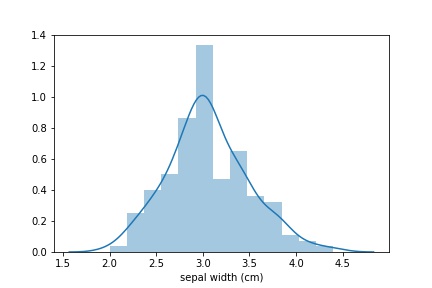
Saya akan memberikan contoh tugas yang diselesaikan di seaborn dengan satu baris kode. Terutama seaborn menang ketika Anda perlu membangun distribusi. Katakanlah kita perlu membangun distribusi panjang sepal. Solusi untuk masalah ini adalah sebagai berikut:
sns_plot = sns.distplot(data['sepal width (cm)']) fig = sns_plot.get_figure()
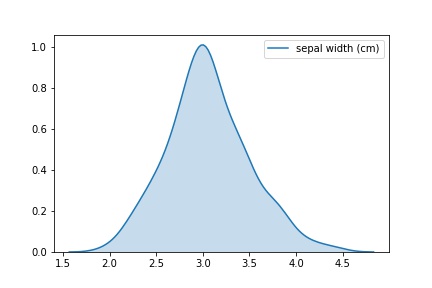
Jika Anda hanya perlu jadwal distribusi, Anda dapat melakukannya seperti ini:
snsplot = sns.kdeplot(data['sepal width (cm)'], shade=True) fig = snsplot.get_figure()
Baca lebih lanjut tentang membangun distribusi di seaborn di
sini.Grafik Bar PandasSemuanya sederhana di sini. Sebenarnya, ini adalah shell dari matplotlib.pyplot.hist (), tetapi memanggil fungsi melalui pd.hist () terkadang lebih nyaman daripada konstruksi matplotlib-a yang kurang gesit.
Anda dapat membaca lebih lanjut di dokumentasi perpustakaan panda.Ini berfungsi seperti ini:
h = data['petal width (cm)'].hist() fig = h.get_figure()

Terima kasih sudah membaca sampai akhir! Saya akan dengan senang hati memberikan ulasan dan komentar!