
Hai teman-teman! Bagaimana cara menyoroti topik utama dari 20.000 berita dalam 30 detik? Gambaran umum pemodelan tematik yang kami lakukan dalam TASS, dengan pasangan dan kode.
Untuk mulai dengan, informasi yang disajikan dalam catatan ini adalah bagian dari prototipe yang sedang dikembangkan di Laboratorium Digital ITAR-TASS untuk mendukung "digitalisasi" bisnis. Solusi terus meningkat, saya akan menjelaskan bagian saat ini, itu, jelas, tidak akan menjadi mahkota penciptaan, tetapi lebih merupakan dukungan untuk pengembangan lebih lanjut.
Ide besar
Selain agenda berita, di mana kantor editorial TASS bekerja setiap hari, ada baiknya untuk memahami topik apa yang paling membuat latar belakang berita di media online Rusia. Untuk tujuan ini, kami mengumpulkan berita terbaru dari 300 situs paling populer setiap beberapa menit, 24/7; kemudian yang paling menarik datang - pilihan metode pemodelan dan eksperimen.
Ketika sesi sulap berakhir, kolega, editor, dan manajer saya akan mulai menggunakan laporan dengan topik berita. Saya percaya bahwa untuk orang-orang di luar bidang pengembangan perangkat lunak dan ilmu data, pemrosesan otomatis, analisis, dan visualisasi data teks terlihat sedikit ajaib. Karena keterasingan seseorang dari teknologi tinggi, berbagai ketidaksempurnaan dalam pekerjaan mereka dapat menyebabkan kurangnya pemahaman tentang apa yang ada di dalam dan kekecewaan. Untuk meminimalkan reaksi negatif, saya mencoba membuat produk lebih sederhana dan lebih dapat diandalkan. Dan memahami esensi pemodelan tematik dapat direduksi menjadi fakta bahwa berita yang terkait dengan satu topik dan berbeda dari berita di topik lain milik satu topik.
Saya telah bereksperimen dengan pemodelan tematik selama sekitar satu tahun sekarang. Sayangnya, sebagian besar pendekatan yang saya coba memberi saya kualitas yang sangat meragukan mengisi topik berita. Pada saat yang sama, saya melakukan tindakan sesuai dengan logika pemilihan parameter dalam metode dari perpustakaan pengelompokan populer. Tapi saya tidak punya dataset berlabel. Karena itu, setiap kali saya melihat pilihan teks yang termasuk dalam topik tertentu. Kasusnya agak suram dan tidak berterima kasih.
Suatu keseruan khusus dari tugas ini adalah bahwa beberapa spesialis, melihat berita yang termasuk dalam topik yang dipilih, akan menemukan mereka pada tingkat tertentu tidak sesuai. Misalnya, berita dengan pernyataan Erdogan tentang dimulainya operasi di Suriah dan berita dengan laporan pertama setelah dimulainya operasi di Suriah dapat dipahami sebagai satu atau beberapa topik. Dengan demikian, media, mengutip TASS atau kantor berita lain, akan menulis serangkaian teks tentang dan tentang ini dan itu. Dan hasil dari algoritma saya akan cenderung untuk menggabungkan atau memisahkan mereka berdasarkan ... cosinus sudut antara vektor frekuensi kata, jumlah apriori yang diterima, atau radius dalam metode menemukan tetangga terdekat.
Secara umum, gagasan besar ini rapuh dan indah.
Mengapa analisis faktor?
Melihat lebih dekat pada metode pengelompokan teks menunjukkan bahwa masing-masing didasarkan pada sejumlah asumsi. Jika asumsi tidak sesuai dengan masalah yang sedang dipelajari, maka hasilnya sangat dapat mengarah ke samping. Asumsi analisis faktor bagi saya - dan bagi banyak peneliti lain - dekat dengan tugas topik pemodelan.
Dibuat pada awal abad ke-20, pendekatan ini didasarkan pada gagasan bahwa, di samping variabel yang mencirikan pengamatan sampel, ada faktor-faktor tersembunyi yang, berbicara sedikit secara informal, berkorelasi dengan beberapa variabel yang dapat diamati. Sebagai contoh, jawaban atas pertanyaan “Apakah Anda percaya kepada Tuhan” dan “Apakah Anda pergi ke gereja” akan lebih tepatnya bertepatan daripada berbeda. Dapat diasumsikan bahwa ada "faktor religiusitas," yang memanifestasikan dirinya dalam serangkaian variabel yang saling terkait. Pada saat yang sama, ada juga kesempatan untuk mengukur seberapa kuat variabel terkait dengan faktor tersembunyi mereka.
Untuk teks, pernyataan masalah menjadi sebagai berikut. Dalam berita yang menggambarkan topik yang sama, kata-kata yang sama akan muncul. Misalnya, kata "Suriah", "Erdogan", "Operasi", "AS", "Penghukuman" akan ditemukan bersama lebih sering dalam berita yang dikhususkan untuk penyebaran intervensi militer Turki di Suriah, dan reaksi yang menyertainya terhadap masalah ini dari Amerika Serikat ( sebagai pemain geopolitik di wilayah yang sama).
Tetap mencari tahu semua faktor penting dari agenda berita untuk suatu periode. Ini akan menjadi topik berita. Tapi itu belum semuanya ...
Sedikit matematika
Bagi orang yang berpengalaman dalam teknik pemodelan subjek, saya bisa membuat pernyataan seperti itu. Versi analisis faktor yang saya coba adalah versi yang sangat disederhanakan dari
metodologi ARTM .
Tetapi saya memutuskan untuk bereksperimen dengan metode yang tingkat kebebasannya lebih sedikit, sehingga apa yang terjadi di dalam lebih dipahami.
(Besar) ARTM tumbuh dari pLSA, analisis semantik laten probabilistik, yang, pada gilirannya, merupakan alternatif untuk LSA berdasarkan dekomposisi matriks singular - SVD.
Analisis faktor intelijen melangkah lebih jauh dari SVD karena memberikan "struktur sederhana" hubungan antara variabel dan faktor, yang mungkin bukan masalah sederhana untuk SVD, tetapi terbatas karena tidak dirancang untuk secara akurat menghitung nilai faktor (skor), kemudian ada vektor nilai faktor yang dapat menggantikan 2 atau lebih variabel yang dapat diamati.
Secara formal, tugas analisis faktor intelijen adalah sebagai berikut:
Di mana variabel yang diamati
linear terkait dengan faktor-faktor tersembunyi
Perlu ditemukan
Itu saja! Koefisien beta ini disebut pemuatan di dunia analisis faktor. Pertimbangkan kepentingan mereka sedikit kemudian.
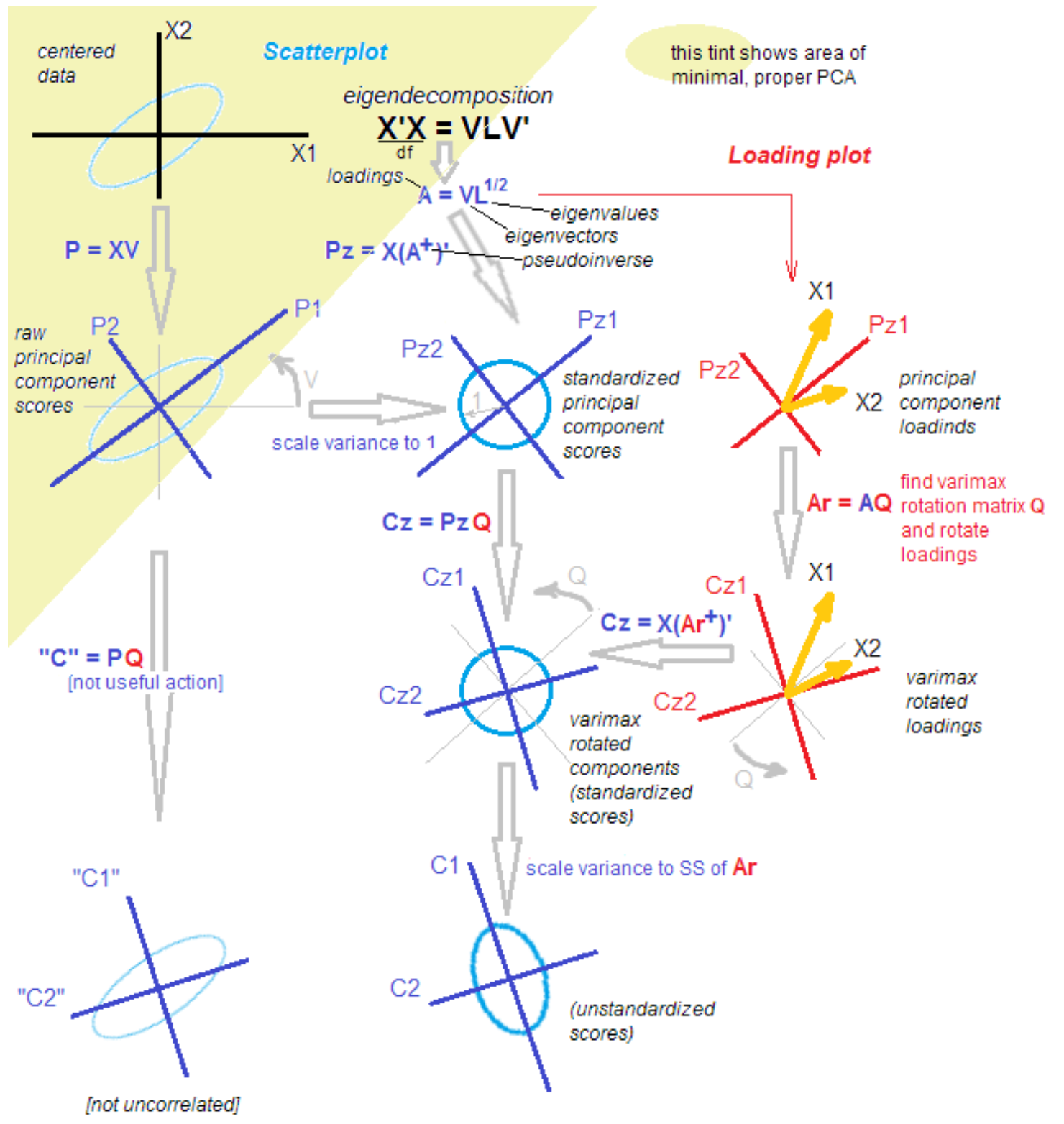
Untuk sampai pada hasil analisis, seseorang dapat bergerak dengan berbagai cara. Salah satunya yang saya gunakan adalah menemukan komponen utama dalam pengertian klasik, yang kemudian diputar untuk menyoroti "struktur sederhana". Komponen utama hanya membentang dari dekomposisi singular dari matriks, atau melalui dekomposisi dari matriks kovarian variasional menjadi vektor dan nilai eigen. Masalahnya juga dipecahkan dengan memaksimalkan fungsi kemungkinan. Secara umum, analisis faktor adalah “kebun binatang” besar metode, setidaknya 10 yang memberikan hasil yang berbeda, dan direkomendasikan untuk memilih metode yang paling sesuai dengan tugas.
Rotasi dari matriks beban juga dapat dilakukan dengan cara yang berbeda, saya mencoba varimax - rotasi orthogonal.
Mengapa semuanya begitu rumit?Faktanya adalah bahwa di antara ahli statistik dan pelamar diskusi tidak berhenti tentang perbedaan dan persamaan metode komponen utama, analisis faktor dan kombinasi mereka. Metodologi ini diisi kembali dengan pengetahuan baru bahkan setelah lebih dari 100 tahun sejak saat penemuan. Seorang ahli statistik yang terhormat membawakan saya gambar berikut untuk memudahkan pemahaman dengan kata-kata: "Itu saja, bereskan."
 sumber
sumber .
Semua bereskan!
Hanya bercanda). Untuk memahami langkah selanjutnya, cukup setelah mengisolasi komponen utama, kami memutarnya, mulai dari menjelaskan varians dalam variabel hingga menjelaskan kovarians variabel dan faktor.
Selanjutnya, saya melakukan semua ini menggunakan fungsi atom, dan tidak hanya menekan satu "tombol merah besar". Pendekatan ini memungkinkan kita untuk memahami transformasi dalam data pada tahap menengah.
Kemana LDA pergi?
PerbaruiSaya memutuskan untuk menambahkan pemikiran saya tentang pengaturan Dirichlet laten. Saya mencoba metode populer ini, tetapi tidak bisa mendapatkan hasil yang bersih dalam waktu singkat. Contoh sederhana tentang bagaimana menggunakannya, dan "Mari kita bagikan berita menjadi politik, ekonomi dan budaya" benar-benar berhasil, tetapi ... Dalam kasus saya, saya harus membagi, katakanlah, politik menjadi 50 topik siang hari, di mana Rusia, Putin dan Iran akan menjadi , dan topik sempit seperti "pembebasan Kokorin dan Mamaev." Semua ini, pada kenyataannya, 1-2 berita kantor berita, dikutip beberapa lusin kali di media.
Selain itu, asumsi tentang sifat data, karakteristik hipotesis bahwa setiap teks adalah distribusi probabilitas berdasarkan topik, bagi saya sedikit artifisial dalam konteks pekerjaan saya. Tidak ada editor yang setuju bahwa berita tentang "pemberhentian kasus terhadap Golunov" adalah campuran tema. Bagi kami, ini adalah 1 topik. Mungkin, dengan memilih hiperparameter adalah mungkin untuk mencapai fragmentasi seperti itu dari LDA, saya akan meninggalkan pertanyaan ini untuk masa depan.
Kode
Saya mencoba-coba dalam bahasa R lagi, jadi percobaan kecil ini akan menjadi Arya.
Kami bekerja dengan 3 pasang nilai acak berkorelasi. Set ini mengandung 3 faktor tersembunyi - hanya untuk kejelasan.
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
Kami mendapatkan matriks beban berikut:
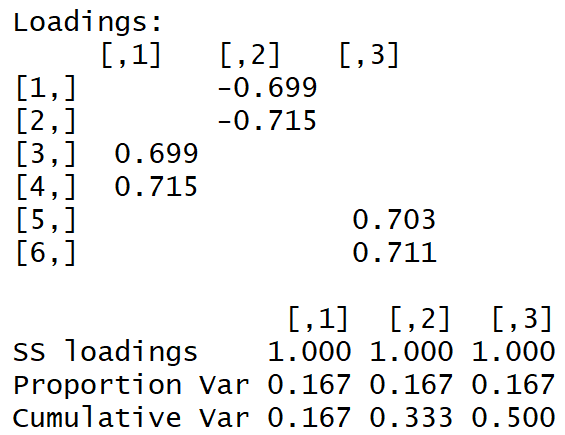
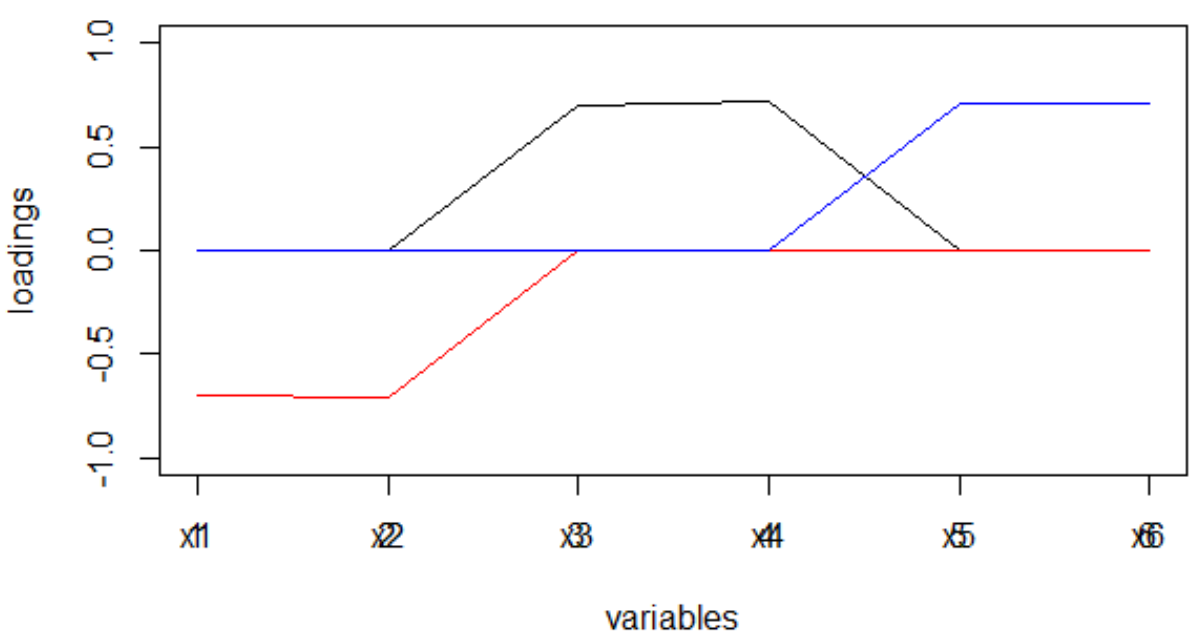
"Struktur sederhana" terlihat oleh mata telanjang.
Dan di sini adalah bagaimana beban tampak tepat setelah MGK selesai:
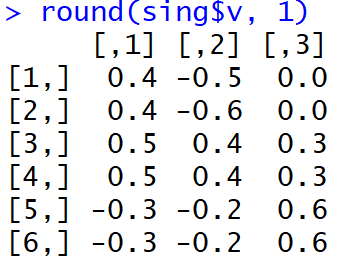
Tidak mudah bagi orang untuk memahami faktor-faktor apa yang terkait dengan variabel mana. Selain itu, bobot seperti itu, diambil modulo, dan dalam interpretasi mesin akan menyebabkan distribusi kata yang sangat aneh pada topik.
Tapi, bo !, Bagian dari dispersi yang dijelaskan dalam tiga komponen utama pertama (sebelum rotasi) mencapai 99%.

Bagaimana dengan beritanya?
Untuk berita, variabel kami x1, x2 ... xm menjadi frekuensi (atau tf-idf) dari kejadian token dalam teks. Ada banyak kata! Misalnya, 50.000 kata unik per minggu adalah normal. Bi-gram akan lebih besar, bisa dimengerti. Kompleksitas dekomposisi singular adalah rata-rata:
Itu sangat besar. Dekomposisi matriks 20.000 * 50.000 nilai dalam satu aliran membutuhkan beberapa jam ...
Untuk dapat membaca topik secara real time dan menampilkan Shiny di dasbor, saya sampai pada cutoff menyakitkan berikut:
- 10% kata paling umum
- pemilihan teks secara acak sesuai dengan rumus yang dipenuhi sendiri:
di mana n adalah semua teks.
Akibatnya, saya memproses data mingguan dalam 30 detik, satu hari dalam 5 detik. Tidak buruk! Tapi, Anda harus memahami bahwa tren berita hanya ditangkap oleh orang yang paling kaya.
Setelah menerima beban, yang, saya perhatikan, merupakan perkiraan kovarians dari variabel yang diamati dengan faktor-faktor, saya melepaskannya dari tanda (melalui modul, bukan melalui derajat), yang cenderung berubah tergantung pada metode rotasi yang digunakan.
Ingat bagaimana matriks beban berbeda setelah melakukan MHC dan setelah rotasi dengan varimax. Kelangkaan muatan, serta fakta bahwa dispersi mereka untuk setiap faktor dimaksimalkan: ada yang sangat besar dan sangat kecil, akan mengarah pada fakta bahwa kata-kata akan didistribusikan antara faktor-faktor dengan cukup bersih, yang, pada gilirannya, akan mengarah ke lebih jauh dan distribusi faktor pada teks berita akan memiliki puncak yang jelas.
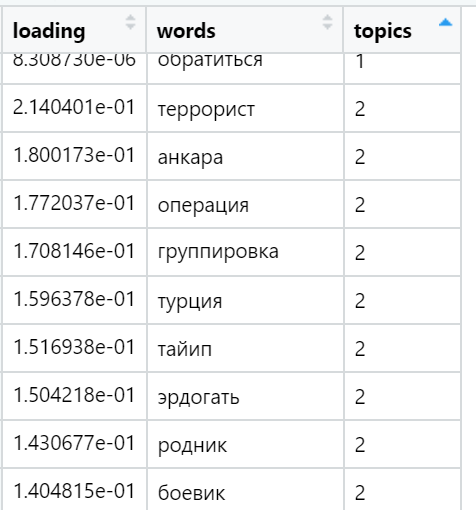
Contoh kata-kata yang paling banyak dimuat dalam berbagai topik yang ditemukan (dipilih secara acak):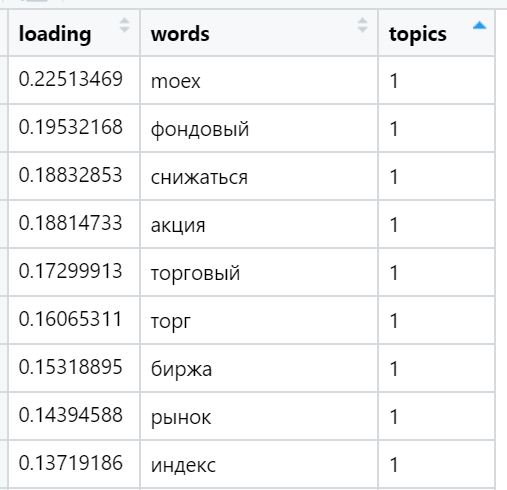

Dan akhirnya, saya mempertimbangkan jumlah muatan dalam teks dalam kaitannya dengan masing-masing faktor. Kemenangan terkuat: untuk setiap teks, faktor dipilih yang jumlah bebannya dimaksimalkan - dengan mempertimbangkan jumlah kata yang disertakan dalam dokumen, yang - seperti yang kami sediakan selama rotasi - memiliki distribusi yang sangat tidak merata antara faktor-faktor muatan. Dalam iterasi ini, semua teks (n) sudah terlibat, yaitu sampel lengkap.
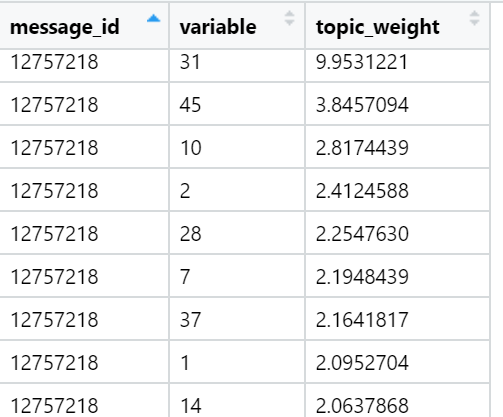
Contoh topik yang teratas dalam hal jumlah muatan dalam teks berita tertentu (dipilih secara acak):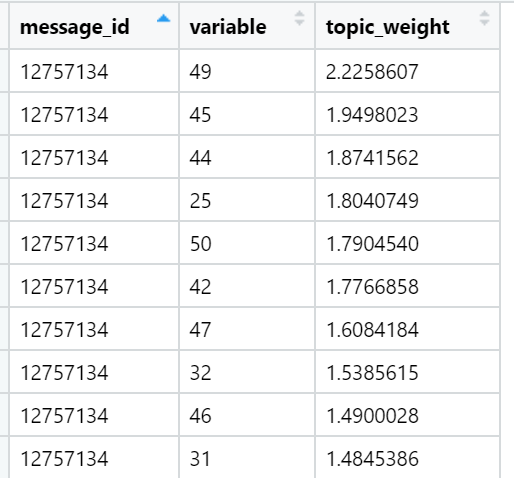
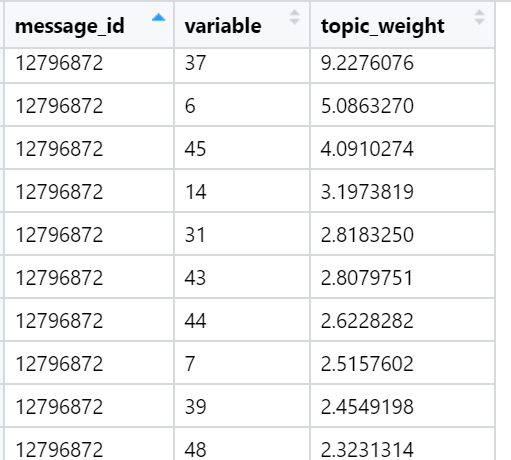 Hasilnya untuk hari ini.
Hasilnya untuk hari ini. Informasi tambahan
Informasi tambahan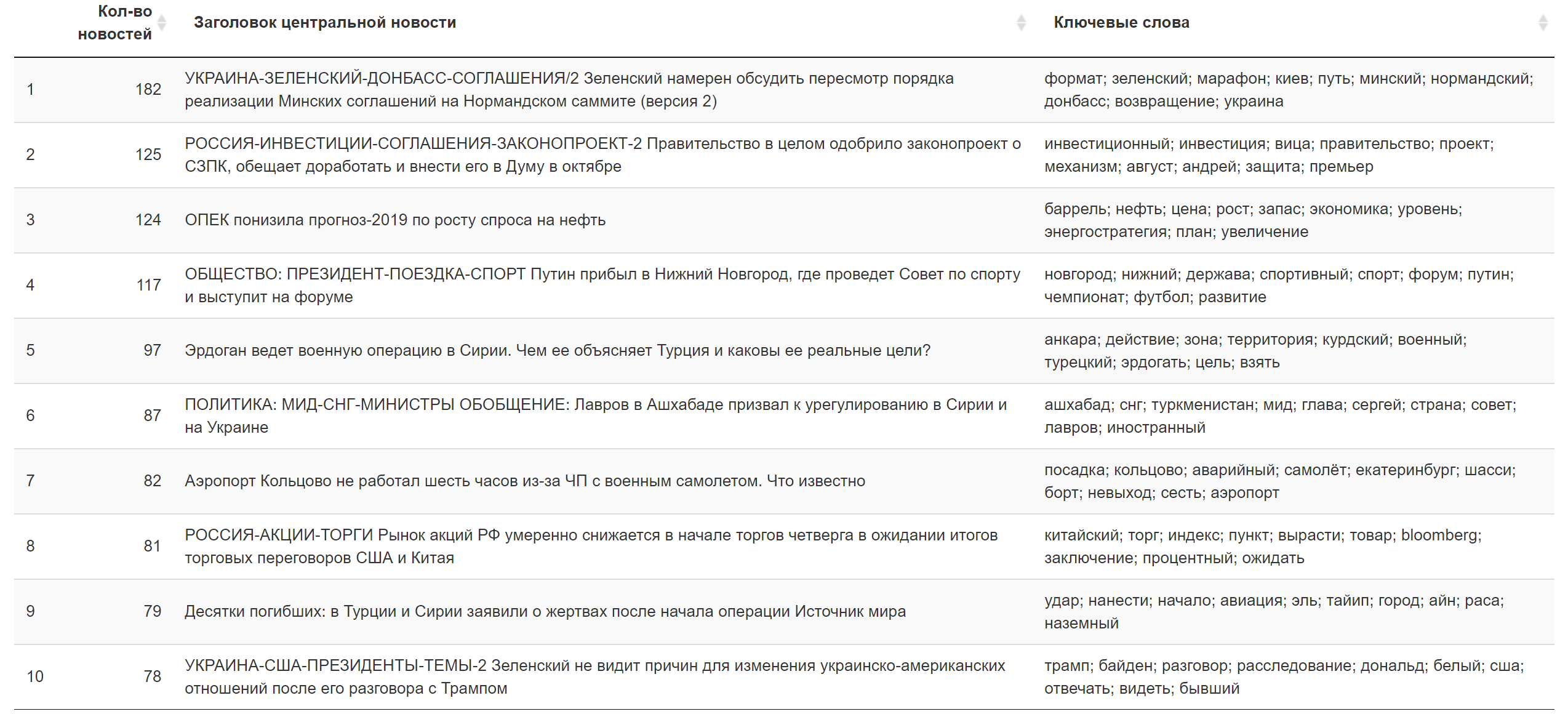
Apa yang harus dilakukan
Di sini, hal pertama yang akan saya lakukan ketika ... Secara umum, ketika inspirasi datang, saya akan mencoba mengkonfigurasi pekerjaan untuk pelatihan per jam dari jaringan saraf dengan leher sempit, yang akan memberi saya hanya perkiraan faktor non-linear - komponen utama terdistorsi - dalam bentuk neuron lapisan tersembunyi. Secara teori, pembelajaran dapat dilakukan dengan cepat menggunakan kecepatan belajar yang meningkat. Setelah ini, bobot lapisan tersembunyi (entah bagaimana dinormalisasi) akan memainkan peran beban token. Mereka sudah dapat dengan cepat dimuat ke lingkungan pemrosesan akhir dengan kecepatan yang dapat diterima. Mungkin trik ini dapat mengarah pada fakta bahwa minggu akan diproses dalam semua teks dalam 10 detik: waktu normal untuk kasus yang sulit.
Secara keseluruhan, itu saja yang ingin saya bahas. Saya harap kunjungan singkat ini ke metode pemodelan topik memungkinkan Anda untuk lebih memahami apa yang sedang dilakukan di bawah "tombol merah besar", mengurangi keterasingan dari teknologi dan membawa kepuasan. Jika Anda sudah tahu ini, saya akan senang mendengar pendapat dari segi teknis atau produk. Eksperimen kami terus berkembang dan berubah!