- Seberapa besar cluster yang saya butuhkan?
- Yah, itu tergantung ... (cekikikan marah)
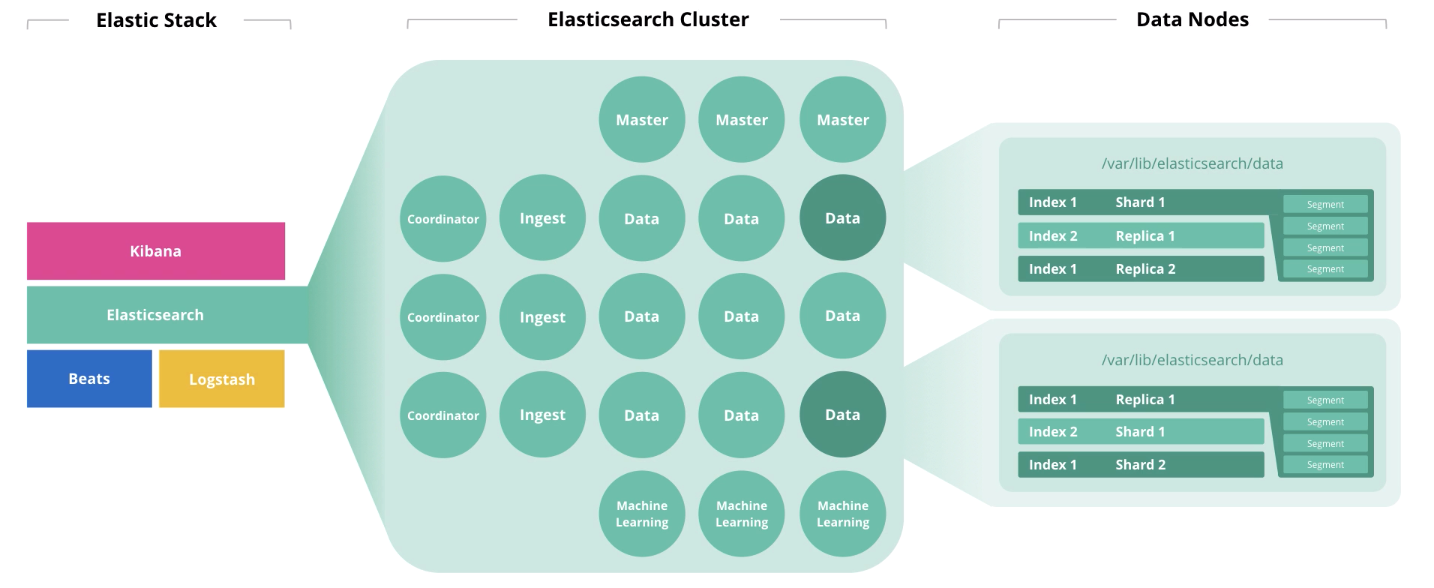
Elasticsearch adalah jantung dari Elastic Stack, tempat semua keajaiban dengan dokumen terjadi: mengeluarkan, menerima, memproses, dan menyimpan. Kinerja tergantung pada jumlah node yang tepat dan arsitektur solusi. Dan harganya, omong-omong, juga, jika langganan Anda adalah Emas atau Platinum.
Karakteristik utama dari perangkat keras adalah disk (penyimpanan), memori (memori), prosesor (komputasi) dan jaringan (jaringan). Masing-masing komponen ini bertanggung jawab atas tindakan yang dilakukan Elasticsearch pada dokumen, yang masing-masing adalah penyimpanan, membaca, menghitung dan menerima / mentransmisikan. Mari kita bicara tentang prinsip umum ukuran dan mengungkapkan "itu tergantung". Dan di akhir artikel ada tautan ke webinar dan artikel terkait. Ayo pergi!
Artikel ini didasarkan pada
Perencanaan Ukuran dan Kapasitas Webinar David Moore . Kami melengkapi alasannya dengan tautan dan komentar agar lebih jelas. Di akhir artikel, trek bonus adalah tautan ke materi-materi elastis bagi mereka yang ingin membenamkan diri dalam topik. Jika Anda memiliki pengalaman yang baik dengan Elasticsearch, silakan berbagi di komentar cara mendesain sebuah cluster. Kami dan semua rekan kerja akan tertarik untuk mengetahui pendapat Anda.
Arsitektur dan Operasi Elasticsearch
Di awal artikel, kami berbicara tentang 4 komponen yang membentuk perangkat keras: disk, memori, prosesor, dan jaringan. Peran sebuah node mempengaruhi pembuangan masing-masing komponen ini. Satu node dapat melakukan beberapa peran sekaligus, tetapi dengan pertumbuhan cluster, peran ini harus didistribusikan di node yang berbeda.
Master node memantau kesehatan cluster secara keseluruhan. Dalam pekerjaan master node, kuorum harus diperhatikan, yaitu jumlah mereka harus ganjil (mungkin 1, tetapi lebih baik 3).
Node data menjalankan fungsi penyimpanan. Untuk meningkatkan kinerja cluster, node harus dibagi menjadi
"panas", "panas", dan "dingin" (beku) . Yang pertama adalah untuk akses online, yang kedua untuk penyimpanan, dan yang ketiga untuk arsip. Oleh karena itu, untuk "panas" masuk akal untuk menggunakan drive SSD lokal, dan untuk array HDD "hangat" dan "dingin" cocok secara lokal atau di SAN.
Untuk menentukan kapasitas penyimpanan node untuk penyimpanan, Elastic merekomendasikan untuk menggunakan logika berikut: "hot" → 1:30 (30GB ruang disk per gigabyte memori), "warm" → 1: 100, "cold" → 1: 500). Di bawah
JVM Heap, tidak lebih dari 50% dari total memori dan tidak lebih dari 30GB untuk menghindari serangan pengumpul sampah. Memori yang tersisa akan digunakan sebagai cache sistem operasi.
Indikator kinerja instance elastisearch seperti
kolam ulir dan antrian ulir lebih dipengaruhi oleh
pemanfaatan inti prosesor. Yang pertama dibentuk berdasarkan tindakan yang dilakukan node: pencarian, analisis, tulis, dan lain-lain. Yang kedua adalah antrian permintaan yang sesuai dari berbagai jenis. Jumlah prosesor Elasticsearch yang tersedia untuk digunakan ditentukan secara otomatis, tetapi Anda dapat menentukan nilai ini secara manual dalam pengaturan (ini dapat berguna ketika Anda memiliki 2 atau lebih instance Elasticsearch berjalan pada host yang sama). Jumlah maksimum kumpulan utas dan antrian utas dari setiap jenis dapat diatur dalam pengaturan. Metrik kumpulan utas adalah metrik kinerja utama untuk Elasticsearch.
Node ingest mengambil input dari pengumpul (Logstash, Beats, dll.), Melakukan konversi pada mereka, dan menulis ke indeks target.
Node pembelajaran mesin dimaksudkan untuk analisis data. Seperti yang kami tulis dalam sebuah
artikel tentang pembelajaran mesin di Elastic Stack , mekanismenya ditulis dalam C ++ dan bekerja di luar JVM, yang menjalankan Elasticsearch sendiri, sehingga masuk akal untuk melakukan analitik tersebut pada node yang terpisah.
Simpul koordinator menerima permintaan pencarian dan merutekannya. Kehadiran jenis node ini mempercepat pemrosesan permintaan pencarian.
Jika kita mempertimbangkan beban pada node dalam hal kapasitas infrastruktur, distribusi akan menjadi seperti ini:
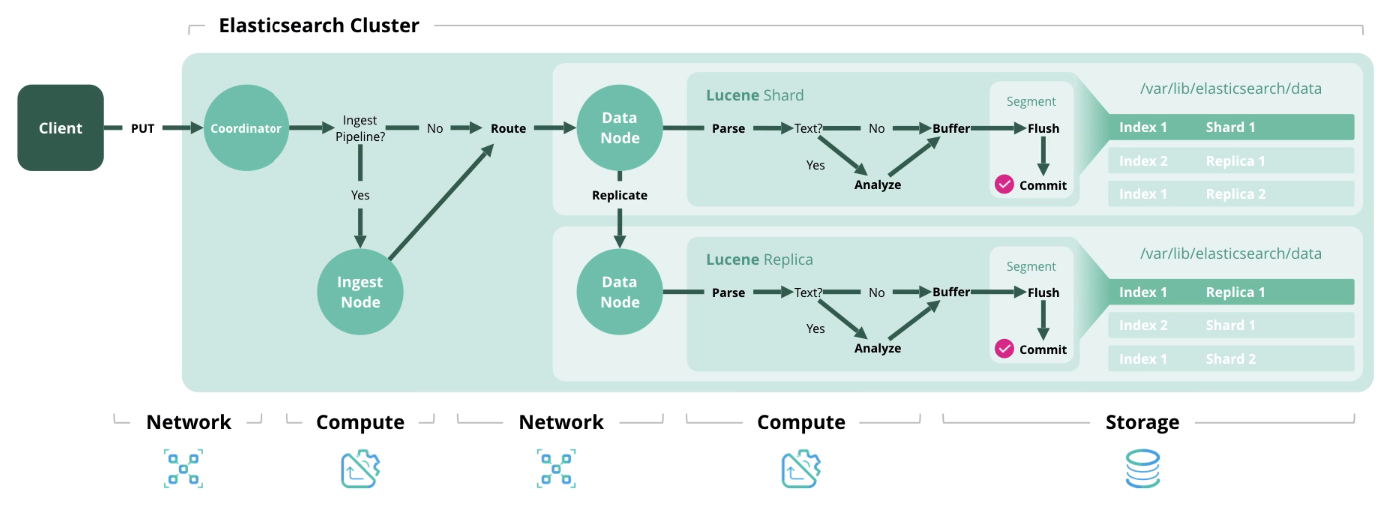
Selanjutnya, kami menyajikan 4 jenis operasi utama di Elasticsearch, yang masing-masing memerlukan jenis sumber daya tertentu.
Indeks - memproses dan menyimpan dokumen dalam indeks. Diagram di bawah ini menunjukkan sumber daya yang digunakan pada setiap tahap.
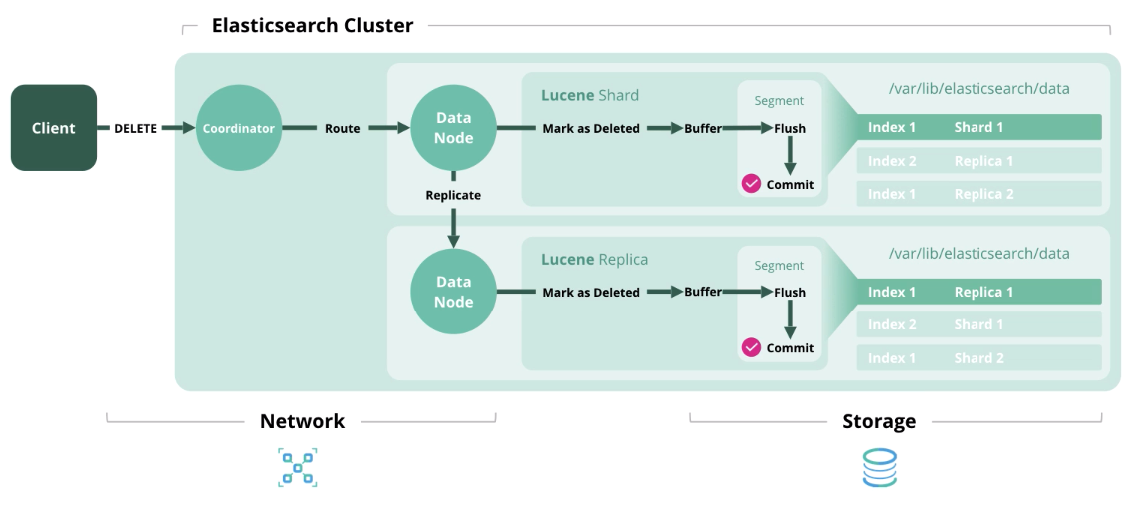
 Hapus
Hapus - hapus dokumen dari indeks.
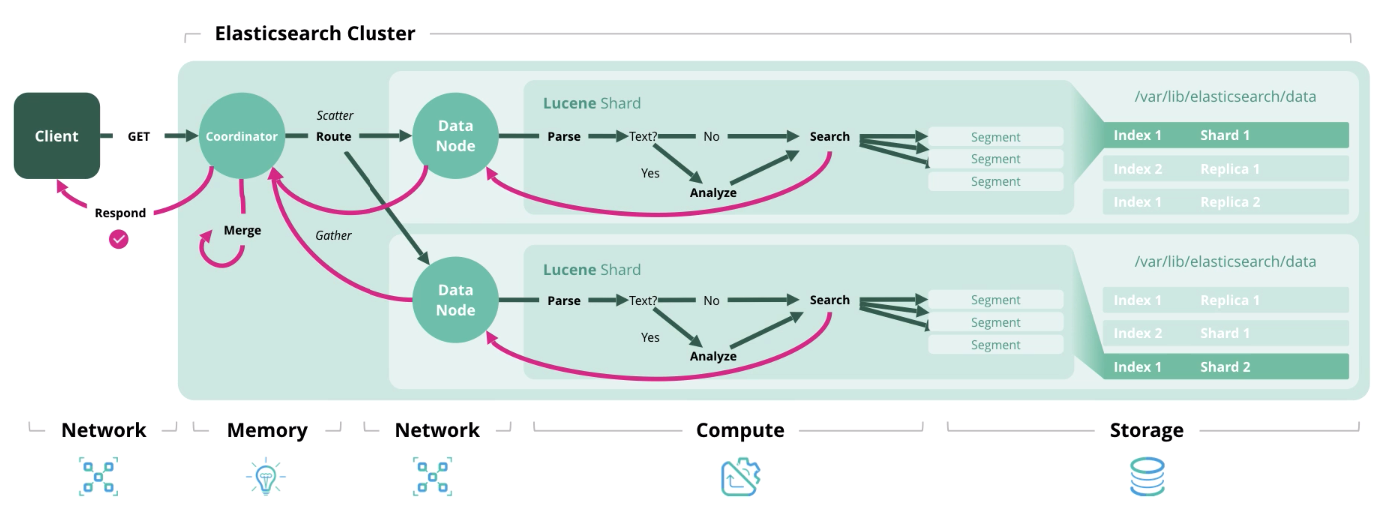
 Pembaruan
Pembaruan - Berfungsi seperti Indeks dan Hapus, karena dokumen di Elasticsearch tidak dapat diubah.
Cari - dapatkan satu atau lebih dokumen atau agregasi dari satu atau lebih indeks.
Kami menemukan arsitektur dan jenis beban, sekarang mari kita beralih ke pembentukan model ukuran.
Sizing Elasticsearch dan pertanyaan sebelum pembentukannya
Elastis merekomendasikan menggunakan dua strategi ukuran: berorientasi penyimpanan dan throughput. Dalam kasus pertama, sumber daya disk dan memori sangat penting, dan dalam kasus kedua, memori, daya prosesor, dan jaringan.
Ukuran arsitektur Elasticsearch berdasarkan ukuran penyimpanan
Sebelum perhitungan, kami mendapatkan data awal. Membutuhkan:
- Jumlah data mentah per hari;
- Periode penyimpanan data dalam beberapa hari;
- Faktor Transformasi Data (faktor json + faktor pengindeksan + faktor kompresi);
- Jumlah replikasi beling;
- Jumlah node data memori;
- Rasio memori terhadap data (1:30, 1: 100, dll.).
Sayangnya, faktor transformasi data hanya dihitung secara empiris dan tergantung pada berbagai hal: format data mentah, jumlah bidang dalam dokumen, dll. Untuk mengetahuinya, Anda perlu memuat sebagian data uji ke dalam indeks. Pada topik tes tersebut, ada
video yang menarik dari konferensi dan
diskusi di komunitas Elastis . Secara umum, Anda dapat membiarkannya sama dengan 1.
Secara default,
Elasticsearch memampatkan data menggunakan algoritma LZ4, tetapi ada juga DEFLATE, yang menekan 15% lebih banyak. Secara umum, kompresi 20-30% dapat dicapai, tetapi ini juga dihitung secara empiris. Saat beralih ke algoritma DEFLATE, beban daya komputasi meningkat.
Masih ada rekomendasi tambahan:
- Setor 15% untuk memiliki cadangan pada ruang disk;
- Ikrar 5% untuk kebutuhan tambahan;
- Letakkan 1 ekuivalen dari simpul data untuk memastikan migrasi cepat.
Sekarang mari kita beralih ke formula. Tidak ada yang rumit di sini, dan kami pikir, akan menarik bagi Anda untuk memeriksa kluster Anda untuk kepatuhan dengan rekomendasi ini.
Total jumlah data (GB) = Data mentah per hari * Jumlah hari penyimpanan * Faktor transformasi data * (jumlah replika - 1)
Total penyimpanan data (GB) = Total data (GB) * (stok 1 + 0,15 + 0,05 kebutuhan tambahan)
Total jumlah node = OK (Total penyimpanan data (GB) / Volume memori per node / rasio memori ke data + 1 setara dengan node data)
Ukuran arsitektur Elasticsearch untuk menentukan jumlah pecahan dan data node tergantung pada ukuran penyimpanan
Sebelum perhitungan, kami mendapatkan data awal. Membutuhkan:
- Jumlah pola indeks yang akan Anda buat;
- Jumlah pecahan dan replika inti;
- Setelah berapa hari rotasi indeks akan dilakukan, jika sama sekali;
- Jumlah hari untuk menyimpan indeks
- Jumlah memori untuk setiap node.
Masih ada rekomendasi tambahan:
- Jangan melebihi 20 pecahan per 1 GB JVM Heap pada setiap node;
- Jangan melebihi ruang penyimpanan pecahan 40 GB.
Rumusnya adalah sebagai berikut:
Jumlah pecahan = Jumlah pola indeks * Jumlah pecahan utama * (Jumlah pecahan yang direplikasi + 1) * Jumlah hari penyimpanan
Jumlah data node = OK (Jumlah pecahan / (20 * Memori untuk setiap node))
Ukuran bandwidth pencarian elastics
Kasus yang paling umum ketika bandwidth tinggi diperlukan adalah sering dan dalam jumlah besar permintaan pencarian.
Data awal yang diperlukan untuk perhitungan:
- Pencarian puncak per detik;
- Rata-rata waktu respons yang diijinkan dalam milidetik;
- Jumlah inti dan utas per inti prosesor pada simpul data.
Nilai puncak utas = OK (jumlah puncak kueri penelusuran per detik * jumlah rata-rata waktu untuk menanggapi kueri penelusuran dalam milidetik / 1000 milidetik)
Kumpulan thread volume = OKRUP ((jumlah inti fisik per node * jumlah utas per inti * 3/2) +1)
Jumlah simpul data = OK (Nilai utas puncak / volume kumpulan utas)
Mungkin tidak semua data awal akan ada di tangan Anda saat mendesain arsitektur, tetapi setelah melihat
webinar atau membaca artikel ini, akan muncul pemahaman yang pada prinsipnya memengaruhi jumlah sumber daya perangkat keras.
Harap dicatat bahwa tidak perlu mematuhi arsitektur yang diberikan (misalnya, membuat node coord dan node handler). Cukup mengetahui bahwa arsitektur referensi seperti itu ada dan dapat memberikan peningkatan kinerja yang tidak dapat Anda capai dengan cara lain.
Dalam salah satu artikel berikut, kami akan menerbitkan daftar pertanyaan lengkap yang perlu dijawab untuk menentukan ukuran cluster.
Untuk menghubungi kami, Anda dapat menggunakan pesan pribadi di Habré atau
formulir umpan balik di situs .
Bahan tambahanWebinar "Ukuran penelitian Elastik dan perencanaan kapasitas"Webinar Perencanaan Kapasitas ElasticsearchPidato di ElasticON dengan tema "Quantitative Cluster Sizing"Webinar tentang utilitas Rally untuk menentukan indikator kinerja clusterArtikel Ukuran Pencarian ElasticsWebinar tumpukan elastis