A. A. A. A. A. A. A.
Pernahkah Anda memikirkan pengaruh metro terdekat dengan harga flat Anda? A.
A. A. Bagaimana dengan beberapa taman kanak-kanak di sekitar apartemen Anda? Apakah Anda siap untuk terjun dalam dunia data geo-spasial?
A. 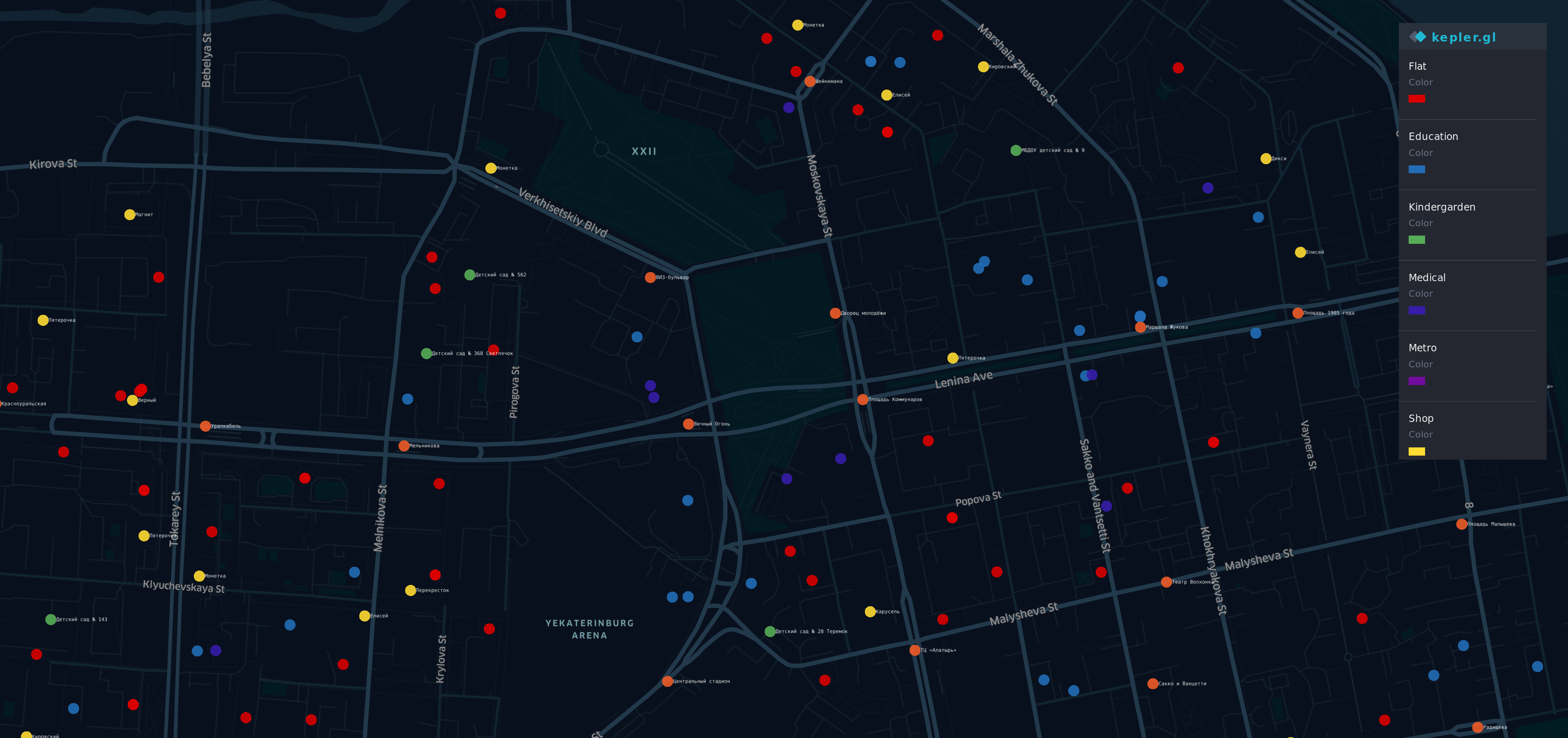 A.
A.
A. A.
A.
Tentang apa semua ini?
A.
Pada bagian sebelumnya , kami memiliki beberapa data dan mencoba menemukan penawaran yang cukup bagus di pasar real estat di Yekaterinburg.
Kami tiba di suatu titik ketika kami memiliki akurasi pada validasi silang dekat 73%. Namun, setiap koin memiliki 2 sisi. Dan akurasi 73% itu adalah 27% kesalahan. Bagaimana kita bisa mengurangi itu? Apa langkah selanjutnya?
A.
Data spasial akan membantu
Bagaimana dengan mendapatkan lebih banyak data dari lingkungan? Kita dapat menggunakan geo-konteks dan beberapa data spasial.
A.
Jarang orang menghabiskan seluruh hidup mereka di rumah. A. Terkadang mereka pergi ke toko, mengambil anak-anak dari tempat penitipan anak. Anak-anak mereka tumbuh dan pergi ke sekolah, universitas, dll. A.
Atau ... kadang-kadang mereka membutuhkan bantuan medis dan mereka mencari rumah sakit. Dan yang sangat penting adalah angkutan umum, metro setidaknya. A. Dengan kata lain, ada banyak hal di dekat sana, yang berdampak pada harga.
Biarkan saya menunjukkan kepada Anda daftar mereka:
- Transportasi umum berhenti
- Toko
- Taman kanak-kanak
- Rumah sakit / institusi medis A. A. A. A. A. A. A. A. A.
- Lembaga pendidikan A. A. A. A. A. A. A. A. A.
- Metro
Visualisasi untuk data baru
Setelah mendapatkan informasi itu dari A. Sumber berbeda A. A. , Saya membuat visualisasi.
A.
A.  A. A. A. A.
A. A. A. A.
Ada beberapa titik di peta distrik Yek aterinburg paling bergengsi (dan mahal). A. A. A. A. A.
A. A.
- A. A. A. A. Poin ed - flat
- O jalankan ge - stop
- Y ellow - toko
- G TK - TK
- B lue - pendidikan
- Saya ndigo - medis
- V iolet - Metro
Ya, ada pelangi di sini.
Ikhtisar
Sekarang kami memiliki dataset yang dibatasi dengan geodata dan memiliki beberapa informasi baru
df.head(10)

df.describe()

Model lama yang bagus
Coba dengan cara yang sama seperti sebelumnya
y = df.cost X = df.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
Kemudian kami melatih model kami lagi, menyilangkan jari kami dan mencoba memprediksi harga flat lagi.
from sklearn.linear_model import LinearRegression regressor = LinearRegression() model = regressor.fit(X_train, y_train) do_cross_validation(X_test, y_test, model)

Hmm ... itu terlihat lebih baik dari hasil sebelumnya dengan akurasi 73%.
Bagaimana dengan mencoba interpretasi? Model kami sebelumnya memiliki kemampuan yang cukup baik untuk menjelaskan harga flat.
estimate_model(regressor)

Ups ... Model baru kami berfungsi baik dengan fitur lama, tetapi perilaku dengan yang baru tampak aneh.
Sebagai contoh, semakin banyak institusi pendidikan atau medis menyebabkan penurunan harga flat. Oleh karena itu, jumlah pemberhentian di dekat flat adalah situasi yang identik dan harus mendapatkan kontribusi tambahan pada harga flat.
Model baru lebih akurat, tetapi tidak cocok dengan kehidupan nyata.
Ada yang rusak
Mari pertimbangkan apa yang terjadi.
Pertama-tama - saya ingin mengingatkan Anda bahwa fitur utama dari regresi linier kami adalah ... erm ... linearitas. Ya, Kapten Obvious ada di sini.
Jika data Anda kompatibel dengan gagasan "Semakin besar / sewa adalah X semakin besar / sewa akan Y" - regresi linier akan menjadi alat yang baik. Tetapi geodata lebih kompleks dari yang kita duga.
Misalnya:
- Ketika dekat flat Anda adalah halte bus itu baik, tetapi jika jumlahnya sekitar 5, itu mengarah ke jalan yang bising dan orang-orang ingin menghindari untuk membeli flat di dekatnya.
- Jika ada universitas, itu harus memiliki pengaruh yang baik pada harga,
pada saat yang sama kerumunan siswa di dekat rumah Anda tidak begitu senang jika Anda bukan orang yang sangat ramah. - Metro di dekat rumah Anda baik, tetapi jika Anda tinggal dalam satu jam dengan berjalan kaki
dari metro terdekat - itu tidak masuk akal.
Seperti yang Anda lihat - itu tergantung pada banyak faktor dan sudut pandang. Dan sifat geodata kita tidak linier, kita tidak bisa memperkirakan dampaknya.
Pada saat yang sama, mengapa model dengan koefisien aneh bekerja lebih baik daripada yang sebelumnya?
plot.figure(figsize=(10,10)) corr = df.corr()*100.0 sns.heatmap(corr[['cost']], cmap= sns.diverging_palette(220, 10), center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")

Itu terlihat menarik. Kami telah melihat gambar serupa di bagian sebelumnya.
Ada korelasi negatif antara jarak ke metro terdekat dan harga. Dan faktor ini berdampak pada akurasi lebih dari beberapa yang lebih tua.
Sementara itu , model kami bekerja berantakan dan tidak melihat ketergantungan antara data yang dikumpulkan dan variabel target. Kesederhanaan regresi linier memiliki batasnya sendiri. A.
Raja sudah mati, umur panjang raja!
Dan jika regresi linier tidak cocok untuk kasus kami, apa yang bisa lebih baik? Kalau saja model kami bisa "lebih pintar" ...
Untungnya, kami memiliki pendekatan yang seharusnya lebih baik karena lebih ... fleksibel dan memiliki mekanisme bawaan "lakukan jika itu melakukan ini lagi lakukan itu".
Decision Tree muncul di tempat kejadian.
from sklearn.tree import DecisionTreeRegressor A decision tree can have a different depth, usually, it works well when depth is 3 and bigger. And the parameter of max depth has the biggest influence on the result. Let's do some code for checking depth from 3 to 32 data = [] for x in range(3,32): regressor = DecisionTreeRegressor(max_depth=x,random_state=42) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) ax = sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Nah ... untuk situasi ketika m A. Ax_depth dari pohon sama dengan 8 akurasi di atas 77.
Dan itu akan menjadi pencapaian yang baik jika kita tidak memikirkan batasan dari pendekatan itu. Mari kita lihat bagaimana cara kerjanya A. A. M ax_depht = 2 A. A. A.
from IPython.core.display import Image, SVG from sklearn.tree import export_graphviz from graphviz import Source 2_level_regressor = DecisionTreeRegressor(max_depth=2, random_state=42) model = 2_level_regressor.fit(X_train, y_train) graph = Source(export_graphviz(model, out_file=None , feature_names=X.columns , filled = True)) SVG(graph.pipe(format='svg'))

Pada gambar ini, kita dapat melihat bahwa hanya ada 4 varian prediksi. Ketika Anda menggunakan DecisionTreeRegressor , ia bekerja secara berbeda dari Regresi Linier . Hanya berbeda. Itu tidak menggunakan kontribusi faktor (koefisien), bukannya itu DecisionTreeRegressor menggunakan "kemungkinan". Dan harga flat akan sama dengan flat yang paling mirip pada prediksi.
Kami dapat menunjukkannya dengan memperkirakan harga kami dengan pohon itu.
y = two_level_regressor.predict(X_test) errors = pd.DataFrame(data=y,columns=['errors']) f, ax = plot.subplots(figsize=(12, 12)) sns.countplot(x="errors", data=errors)

Dan setiap prediksi Anda akan cocok dengan salah satu dari nilai-nilai ini. Dan ketika kita menggunakan max_depth = 8 kita dapat mengharapkan tidak lebih dari 256 opsi berbeda untuk lebih dari 2000 flat. Mungkin itu bagus untuk masalah klasifikasi, tetapi tidak cukup fleksibel untuk kasus kami.
Kebijaksanaan orang banyak
Jika Anda mencoba memprediksi skor di final Piala Dunia - ada kemungkinan besar Anda akan salah. Pada saat yang sama, jika Anda meminta pendapat semua juri di Kejuaraan - Anda akan memiliki peluang lebih baik untuk menebak. Jika Anda bertanya pada pakar, pelatih, juri independen dan kemudian melakukan beberapa keajaiban dengan jawaban - peluang Anda akan meningkat secara signifikan. Sepertinya pemilihan presiden.
Sebuah ensemble dari beberapa pohon "primitif" dapat memberikan lebih dari masing-masing. Dan rando mForestRegressor adalah alat yang akan kita gunakan
Pertama-tama, mari kita pertimbangkan params dasar - max_depth , max_features dan sejumlah pohon dalam model.
A.
Jumlah pohon
Sesuai dengan "Berapa Banyak Pohon di Hutan Acak?" pilihan terbaik adalah 128 pohon . Peningkatan jumlah pohon lebih lanjut tidak mengarah pada peningkatan akurasi yang signifikan, tetapi menambah waktu untuk pelatihan.
Jumlah fitur maksimal
Saat ini model kami memiliki 12 fitur. Setengah dari mereka adalah yang lama yang terkait dengan fitur flat, lainnya terkait dengan geo-konteks. Jadi saya memutuskan untuk memberikan kesempatan kepada mereka masing-masing. Biarkan itu menjadi 6 fitur untuk pohon.
Kedalaman maksimal pohon
Untuk parameter itu, kita bisa menganalisis kurva belajar.
from sklearn.ensemble import RandomForestRegressor data = [] for x in range(1,32): regressor = RandomForestRegressor(random_state=42, max_depth=x, n_estimators=128,max_features=6)model = regressor.fit(X_train, y_train)accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Whoa ... akurasi lebih dari 86% pada max_depth = 16 melawan 77% pada satu pohon desain. Terlihat luar biasa, bukan?
Kesimpulan
Baiklah ... sekarang kita memiliki hasil prediksi yang lebih baik daripada prediksi sebelumnya, 86% mendekati garis finish. Langkah terakhir untuk memeriksa - mari kita lihat pentingnya fitur. Apakah geodata memberi manfaat pada model kami?
feat_importances = model.feature_importances_ feat_importances = pd.Series(feat_importances, index=X.columns) feat_importances.nlargest(5).plot(kind='barh')

Beberapa fitur lama masih mempengaruhi hasilnya. Pada saat yang sama jarak ke metro dan taman kanak-kanak terdekat juga telah terpengaruh. Dan itu terdengar masuk akal.
Tanpa ragu, geodata membantu kami meningkatkan model kami.
Terima kasih sudah membaca!
PS
Perjalanan kita belum selesai. Keakuratan 86% adalah hasil yang luar biasa untuk data nyata. Sementara itu, di sini ada celah kecil antara 14% dan 10% dari kesalahan rata-rata, yang kami harapkan. Dalam bab selanjutnya dari kisah kami, kami akan mencoba untuk mengatasi penghalang ini atau setidaknya untuk mengurangi kesalahan ini. A. A. A. A. A. A. A. A.
Ada IPython-notebook