Halo semuanya! Nama saya Lyudmila, saya terlibat dalam pengujian beban, saya ingin berbagi bagaimana kami melakukan otomatisasi analisis komparatif dari profil regresi sistem pengujian beban dari database untuk DBMS Oracle bersama dengan salah satu pelanggan kami.
Tujuan artikel ini bukan untuk menemukan pendekatan "baru" untuk membandingkan kinerja database, tetapi untuk menggambarkan pengalaman kami dan upaya untuk mengotomatiskan perbandingan hasil yang diperoleh dan
mengurangi jumlah panggilan ke DBA Oracle.
Melakukan pengujian beban terhadap basis data apa pun, kami terutama tertarik pada:
- Apakah ada yang rusak setelah memasang perakitan baru?
- Dinamika basis data selama pengujian.
Membandingkan laporan AWR saja tidak cukup untuk mencapai tujuan Anda.
Penyimpanan terpusat untuk pembuangan AWR juga merupakan praktik yang baik. AWR dumps mempertahankan semua pandangan historis (dba_hist).
Praktik ini sudah diterapkan oleh klien kami.
Setelah sesi pengujian beban berikutnya, kami membandingkan hasilnya:
- dump uji saat ini dengan dump industri;
- dump tes saat ini dengan dump tes sebelumnya.
Mengapa ini dibutuhkan?
Sasarannya berbeda:
- Terkadang, mengisi pangkalan itu sendiri dalam lingkungan uji berbeda dari yang operasional, yang berarti akan ada perbedaan yang mengganggu analisis ("gangguan" untuk menjawab pertanyaan utama, "ada sesuatu yang rusak?"). Saya ingin mengidentifikasi perbedaan-perbedaan ini;
- Perbandingan tes saat ini dengan pekerjaan pangkalan industri membantu untuk memahami seberapa benar tes stres saat ini (di suatu tempat kita memuat terlalu banyak, tetapi kita lupa tentang sesuatu sama sekali);
- Membandingkan tes saat ini dengan tes sebelumnya membantu untuk memahami apakah perilaku sistem saat ini normal. Apakah ada yang berubah dalam perilaku sistem dibandingkan dengan tes sebelumnya.
Untuk mencapai semua tujuan ini, kami sering memecahkan masalah membandingkan kesedihan yang berbeda antara satu sama lain. Tanggal biasanya sangat ketat ketika mereka seharusnya diperkenalkan kemarin! Waktu untuk sepenuhnya memeriksa setiap tes regresi sangat kurang. Dan jika Anda menjalankan uji reliabilitas selama sehari, maka Anda dapat menghabiskan banyak waktu menganalisis hasilnya ...
Tentu saja, Anda dapat menonton segala sesuatu secara online di Enterprise Manager (atau dengan permintaan untuk mendapatkan $ view) selama tes: jangan pergi merokok, makan dan tidur ...

Mungkin Anda juga punya alat kustom sendiri, dibuat untuk diri sendiri? Anda dapat berbagi di komentar. Dan kami akan membagikan apa yang kami gunakan untuk tugas kami.
Laporan AWR memiliki banyak informasi berguna:

Ada informasi yang bermanfaat di sini, misalnya: berapa banyak permintaan dieksekusi, sql_id, modul, dan teks disingkat. Meskipun teks ada di sana, itu dipotong dan versi lengkap dapat diambil dari Daftar Lengkap paragraf SQL Text.
Adapun kekurangannya: dalam laporan AWR tidak jelas kapan permintaan ini terjadi, pada titik mana ada lebih banyak, dan pada apa yang kurang ... Bagaimanapun, untuk menganalisis hasil tes, memahami apa yang terjadi dan pada saat yang kira-kira penting: merata untuk keseluruhan tes atau puncak / lonjakan seolah-olah sesuai jadwal. Kami juga akan melihat hanya top terbatas di sini. Ini dapat dilihat dengan lebih mudah dengan menanyakan tabel sejarah.
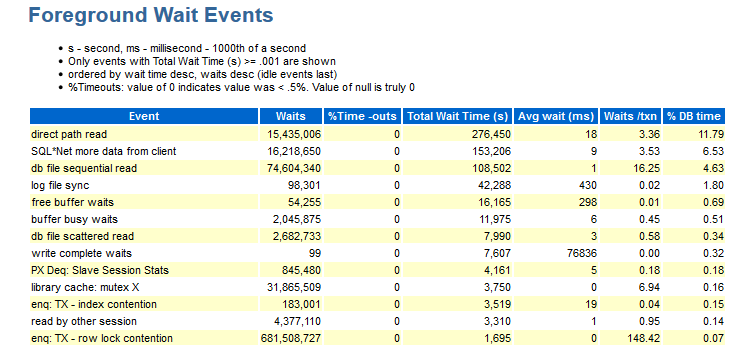
Di sini Anda dapat melihat peristiwa apa saja selama ujian. Data dalam bagian ini diurutkan berdasarkan waktu DB.
Bagi saya, di bagian ini informasi berikut tidak ada:
- Wait_class (ya, Anda ingat dengan pengalaman seperti apa harapan dari acara ini).
- Distribusi berdasarkan modul (jika saya melihat, misalnya, menunggu enq: TX - pertikaian kunci baris: informasi diperlukan, di bawah modul mana hal ini terjadi).
Ada pekerjaan di mana ada angka yang tidak membawa bagian semantik, yaitu, Anda perlu mengelompokkan modul yang sama dan mendapatkan jawaban untuk grup, misalnya: module_A_1, module_A_2, module_A_3 dan module_B_1, module_ B_2, module_ B_3. Artinya, ada dua modul semantik, tetapi mereka semua memiliki nama yang berbeda.
- Objek yang kita maksudkan (CURRENT_OBJ # - jika, misalnya, suatu peristiwa terjadi enq: TX - pertikaian indeks, alangkah baiknya mengetahui indeks mana yang harus disalahkan).
- Sql_id - yang meminta teks dari permintaan ini mencoba dieksekusi.
- Informasi tentang distribusi jumlah per foto (seperti dijelaskan di atas ...).
Untuk membandingkan dua tes, Anda dapat menggunakan perbandingan laporan AWR:
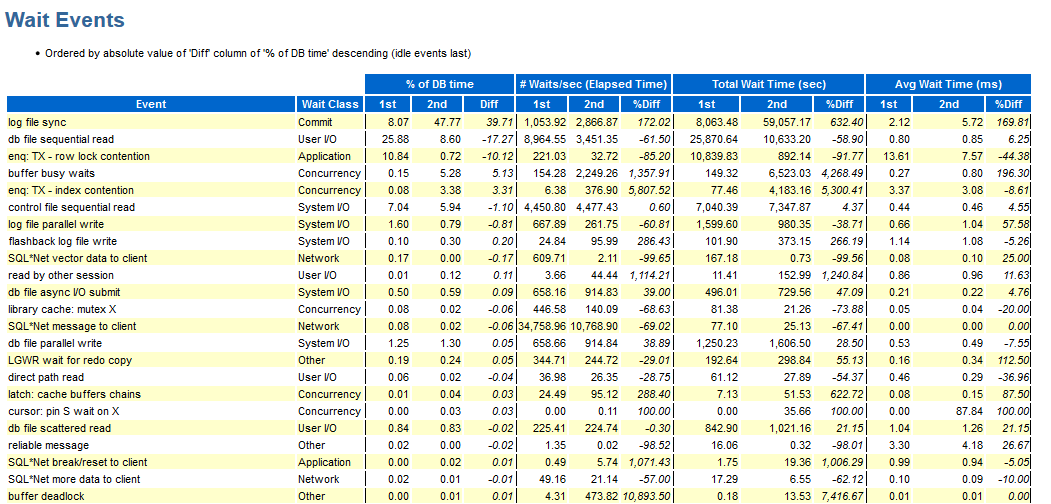
Hore, di sini kita memiliki wait_class ditampilkan, jika tidak, minusnya sama seperti yang dijelaskan di atas.
Terkadang tidak ada Enterprise Manager pada proyek, dan Anda dapat, misalnya, menggunakan Enterprise Manager Express atau ASH Viewer. Di Enterprise Manager, banyak orang menggunakan Aktivitas Top untuk data historis, tetapi bagi saya, banyak hal lebih mudah dilihat dengan kueri. Semua hal di atas harus dibandingkan dengan tes / beban kerja lainnya. Kami sudah memiliki perbandingan khusus dalam hal runtime, tetapi kami tidak memiliki perbandingan khusus, dan kami memeriksa secara manual dengan kueri di tabel historis.
Setelah setiap tes regresi, kami harus membandingkan hasil dalam tabel historis dengan pertanyaan ke database, melihat laporan AWR, melokalisasi harapan yang bermasalah (pada modul mana hal itu terjadi, pada jam berapa hal itu terjadi, objek apa yang menggantungnya), sehingga sebagai hasilnya bug dapat dihasilkan untuk tim pengembangan yang tepat.
Basis data pelanggan telah mencapai 190 TB, sejumlah besar permintaan diproses dalam sistem: jumlah modul paralel adalah 16237.
Dan kemudian saya punya ide bagaimana menyederhanakan proses membandingkan dump AWR. Dengan ide ini, saya pergi ke
Fred . Bersama-sama, kami menciptakan portal yang nyaman.
Pada awalnya, pernyataan masalah dari saya terlihat seperti ini:

Namun, kemudian, saya memutuskan untuk mensistematiskan untuk memulai pertanyaan apa ke tabel sejarah yang paling sering saya gunakan ... Fred mulai mengencangkan ini ke portal dan kemudian mulai ...
Pertama-tama, saya tertarik pada perbandingan peristiwa, karena perbandingan kecepatan eksekusi permintaan dalam beberapa bentuk sudah ada. Langkah selanjutnya saya membutuhkan informasi terperinci tentang setiap peristiwa: misalnya, jika acara tersebut merupakan pertikaian indeks, maka Anda perlu memahami indeks mana yang sebenarnya kami gantung.
Kemudian saya tertarik pada jam berapa saat kejadian-kejadian ini adalah yang paling, karena dalam pelaksanaannya ada banyak tugas (pekerjaan) yang dijadwalkan dan perlu untuk memahami pada titik waktu berapa semuanya retak pada lapisan.
Secara umum, inilah yang ingin saya dapatkan:
- perbandingan kuantitatif peristiwa antara tes yang berbeda (tanpa squat tambahan);
- semua informasi yang relevan yang saya butuhkan untuk analisis: sql_id, teks kueri, distribusi selama pengujian, yang menolak sesi yang dimaksud, modul;
- filter yang nyaman untuk Anda sendiri untuk melihat apa yang berubah;
- GUI GUI, semuanya sangat berwarna sehingga langsung terlihat (Anda dapat menyaring pihak yang tertarik dari sisi pengembangan)
- pengelompokan modul: seperti yang dijelaskan sebelumnya, modul 16237, tetapi, dari sudut pandang fungsi yang dilakukan, berkali-kali lebih sedikit.
Fred dan saya membuat portal nyaman untuk kami gunakan untuk membandingkan AWR dump pengujian beban, yang akan saya bahas lebih detail di bawah ini.
Tentang portal
Jadi, AWR dumps dibuat dalam sistem, yang dituangkan ke dalam database dan dibandingkan di portal.
Kami menggunakan tumpukan berikut:
- Oracle DB - untuk menyimpan kesedihan AWR
- Python 2+
Antarmuka portal terlihat seperti ini:

Pada portal Anda dapat memilih jenis dump, test test atau test-prom yang dibandingkan.
Setiap dump memiliki pengidentifikasi unik - DBID.
Anda juga dapat memfilter menurut parameter berikut:
- Instance (instance) - kami memiliki database cluster;
- Permintaan (Sql_id);
- Jenis menunggu (Wait_Class);
- Acara
Di kiri atas, Anda memilih dumps, dan di sebelah kanan Anda dapat mengatur filter yang diperlukan untuk segera memilih modul yang diinginkan - ini memungkinkan Anda untuk menentukan masalah dalam fungsi yang telah diubah / ditingkatkan sehingga tidak ada masalah dengan degradasi pada versi sebelumnya.
Tabel di tengah adalah hasil dari membandingkan kesedihan. Judul kolom segera menunjukkan data apa yang sedang dihasilkan. Dua kolom kanan menunjukkan perbedaan antara dua kesedihan:
- peristiwa yang disorot dengan warna merah lebih dari dibandingkan dengan tempat pembandingan untuk foto;
- kuning - acara baru;
- hijau - peristiwa yang sudah ada di tempat sampah asli.
Segera jelas seberapa baik kami menguji. Jika peristiwa itu terjadi sangat sering, maka kemungkinan besar:
- sistem kelebihan beban;
- atau kondisi untuk pelaksanaan pekerjaan latar belakang berubah dan acara mulai bermain lebih sering. Sekali dengan cara ini kesalahan ditemukan dalam kode: acara terjadi terus-menerus, dan bukan pada cabang kondisi yang diinginkan.
Jika kita memiliki acara baru - kuning - maka ini menunjukkan semacam perubahan dalam sistem, dan kita perlu menganalisis konsekuensinya. Di sini Anda dapat melihat distribusi acara dengan foto dan menampilkan informasi rinci tentang menunggu.
Pernah ada kasus: sebuah acara baru ditemukan yang cukup langka dan tidak termasuk dalam acara teratas, tetapi karena itu ada perlambatan dalam fungsi, yang memiliki SLA kritis. Analisis hanya kueri teratas dalam laporan AWR tidak dapat mengungkapkan ini.
Untuk setiap permintaan, Anda bisa mendapatkan informasi lebih rinci:
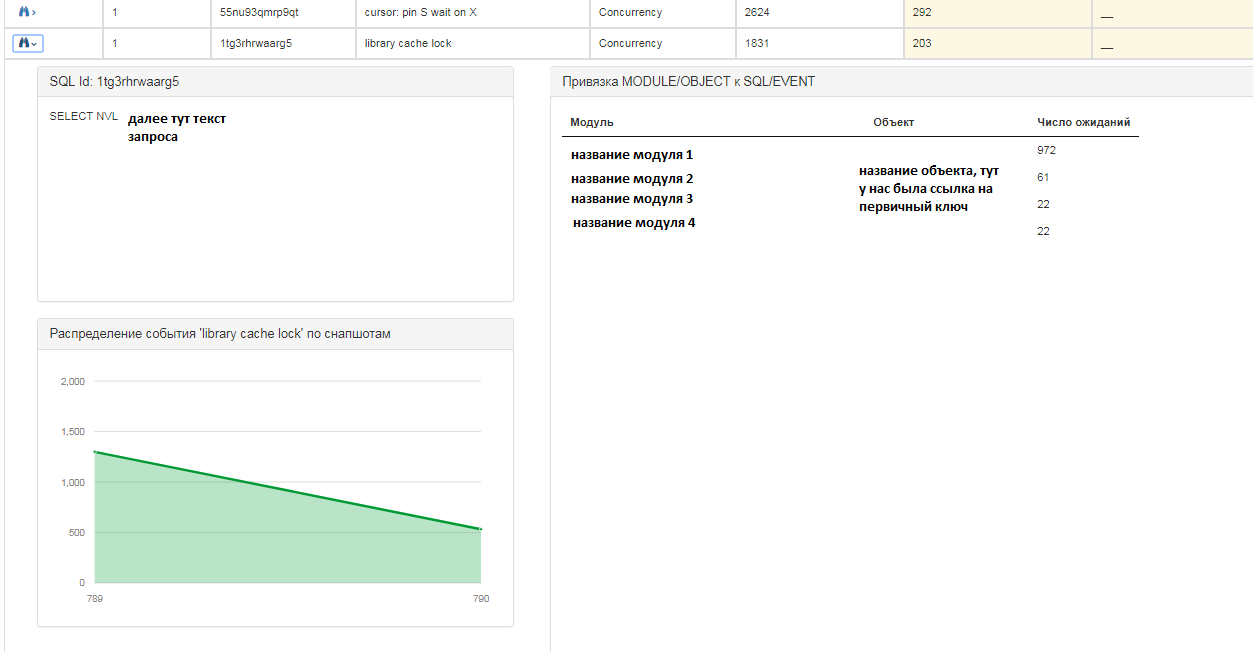
Untuk setiap entri, Anda juga dapat melihat informasi berikut:
- kueri teks sql;
- distribusi peristiwa pada snapshot dalam rasio kuantitatif, mis. pada titik waktu ada lebih banyak atau lebih sedikit peristiwa;
- di mana modul dan objek yang "menggantung" menunggu.
Pandangan sistem Oracle terlibat dalam membandingkan hasil:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED - tabel layanannya sendiri (telah diterapkan oleh pelanggan), ini berisi informasi tentang dump yang dimuat.
Beberapa pertanyaan:
Distribusi acara pada gambar:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
Pengelompokan berdasarkan modul (modul yang merupakan grup logis tunggal digabungkan ke dalamnya), objek yang diblokir:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
Apa yang Anda dapatkan pada akhirnya?
Portal memungkinkan kami menghemat waktu membandingkan dump AWR. Perbandingan manual memakan waktu 4-6 jam, dan sekarang kami menghabiskan 2-3 jam. Kami selalu memiliki kesempatan untuk membandingkan hasil tes yang berbeda baik di antara mereka sendiri maupun dengan tempat pembuangan industri, serta mengatur filter yang kami butuhkan sekarang. Artinya, kita dapat dengan mudah membandingkan data historis di antara kita sendiri, dan tidak hanya menonton hasil online saat ini.
Sebelumnya, setelah setiap regresi, perlu untuk membandingkan hasil dalam tabel historis dengan pertanyaan ke database, melihat laporan AWR, melokalisasi harapan yang bermasalah (pada modul mana hal itu terjadi, berapa kali itu terjadi, apa benda itu tergantung), sehingga pada akhirnya itu dapat menyebabkan cacat pada tim pengembangan yang tepat. Dan sekarang cukup pilih dump untuk perbandingan, atur filter - dan hasil perbandingan segera siap. Anda juga dapat mengirim tautan kepada pengembang ke portal yang menunjukkan DBID dari test dump, dan mereka sendiri akan disaring oleh modul mereka.
Hanya butuh dua minggu untuk membuat portal, karena satu bagian sudah siap: memuat dump ke dalam basis data. Tentu saja, solusi portal semacam itu tidak diperlukan untuk proyek apa pun dengan basis Oracle. Ini berguna untuk produk yang dibagi menjadi beberapa modul dengan nama berbeda. Untuk sistem sederhana atau sistem di mana mereka tidak menganggap penting untuk mengisi modul, portal akan menjadi berlebihan.
Karena portal menganalisis gambar yang diambil sekali dalam periode tertentu, portal tidak sepenuhnya bebas dari pemantauan online dari database, karena beberapa peristiwa mungkin tidak dapat masuk ke dalam gambar.
Ini adalah alat yang mudah untuk menganalisis data historis dari hasil pengujian, tetapi dapat berguna dalam situasi lain, ketika banyak gambar dibuat dan volume data yang besar perlu diperiksa. Berkat kombinasi filter dan grafik, Anda dapat segera melihat rentetan peristiwa yang dalam laporan AWR normal (jangan dikelirukan dengan dump) akan disembunyikan dalam informasi yang dikelompokkan. Cukup untuk memilih dump untuk perbandingan, mengatur filter - dan hasil perbandingan siap segera, atau Anda dapat mengirim tautan ke pengembang di portal yang menunjukkan DBID dari test dump, mereka sendiri akan disaring oleh modul mereka.
Jika Anda memutuskan untuk mengembangkan portal serupa untuk proyek Anda, maka pilih set filter yang tepat untuk Anda. Jika Anda memfilter menurut kondisi yang berbeda setiap kali, maka akan jauh lebih mudah untuk membuat filter yang sesuai untuk ini.
Solusi yang dihasilkan masih dapat diselesaikan, misalnya:
- membandingkan durasi permintaan;
- membandingkan rencana kueri;
- membandingkan permintaan dengan rencana yang sama, tetapi dengan teks yang berbeda;
- membongkar ke dalam laporan pengujian (eksekusi sebagai dokumen Word / Exel).
Atau, secara umum, beri tahu portal untuk terhubung ke database yang diuji sehingga membangun gambar yang serupa daring menggunakan tampilan dalam memori, dan bukan hanya data historis. Dan simpan ke basis data Anda.
Kami telah menggunakan portal selama lebih dari setahun. Fred, terima kasih banyak!
Diposting oleh Lyudmila Matskus,
Jet Infosystems