Hai, Habr. Pada artikel ini, kita akan membahas persamaan Navier-Stokes untuk fluida yang tidak dapat dimampatkan, menyelesaikannya secara numerik, dan membuat simulasi yang indah yang bekerja dengan komputasi paralel pada CUDA. Tujuan utamanya adalah untuk menunjukkan bagaimana Anda dapat menerapkan matematika yang mendasari persamaan dalam praktik saat memecahkan masalah pemodelan cairan dan gas.

PeringatanArtikel ini mengandung banyak matematika, sehingga mereka yang tertarik pada sisi teknis masalah dapat langsung menuju ke bagian implementasi dari algoritma. Namun, saya masih menyarankan Anda membaca seluruh artikel dan mencoba memahami prinsip solusinya. Jika Anda memiliki pertanyaan di akhir bacaan, saya akan dengan senang hati menjawabnya di komentar di pos.
Catatan: jika Anda membaca Habr dari perangkat seluler, dan Anda tidak melihat formula, gunakan versi lengkap dari situsPersamaan Navier-Stokes untuk fluida yang tidak dapat dimampatkan
partial bf vecu over partialt=−( bf vecu cdot nabla) bf vecu−1 over rho nabla bfp+ nu nabla2 bf vecu+ bf vecF
Saya pikir setiap orang setidaknya pernah mendengar tentang persamaan ini, beberapa, bahkan mungkin secara analitis menyelesaikan kasus-kasus khusus, tetapi secara umum masalah ini tetap belum terselesaikan sampai sekarang. Tentu saja, kami tidak menetapkan tujuan untuk menyelesaikan masalah milenium dalam artikel ini, namun kami masih dapat menerapkan metode iteratif untuk itu. Tetapi sebagai permulaan, mari kita lihat notasi dalam rumus ini.
Secara konvensional, persamaan Navier-Stokes dapat dibagi menjadi lima bagian:
- partial bf vecu over partialt - menunjukkan laju perubahan kecepatan fluida pada suatu titik (kami akan mempertimbangkannya untuk setiap partikel dalam simulasi kami).
- −( bf vecu cdot nabla) bf vecu - Pergerakan fluida di ruang angkasa.
- −1 lebihdari rho nabla bfp Apakah tekanan diberikan pada partikel (di sini rho - koefisien densitas fluida).
- nu nabla2 bf vecu - viskositas medium (semakin besar itu, semakin kuat cairan menahan gaya yang diterapkan pada bagiannya), nu - koefisien viskositas).
- bf vecF - kekuatan eksternal yang kami terapkan ke fluida (dalam kasus kami, gaya akan memainkan peran yang sangat spesifik - itu akan mencerminkan tindakan yang dilakukan oleh pengguna.
Juga, karena kami akan mempertimbangkan kasus fluida yang tidak dapat dimampatkan dan homogen, kami memiliki persamaan lain:
nabla cdot bf vecu=0 . Energi di lingkungan itu konstan, tidak ke mana-mana, tidak datang dari mana pun.
Akan salah untuk menghilangkan semua pembaca yang tidak terbiasa dengan
analisis vektor , jadi pada saat yang sama dan secara singkat memeriksa semua operator yang ada dalam persamaan (namun, saya sangat menyarankan mengingat apa turunan, diferensial dan vektor, karena mereka mendasari semua itu. apa yang akan dibahas di bawah).
Kita mulai dengan operator nabla, yang merupakan vektor seperti itu (dalam kasus kami, itu akan menjadi dua komponen, karena kami akan memodelkan fluida dalam ruang dua dimensi):
nabla= beginpmatrix partial over partialx, partial over partialy endpmatrix
Operator nabla adalah
operator diferensial vektor dan dapat diterapkan baik pada fungsi skalar maupun ke vektor. Dalam kasus skalar, kita mendapatkan gradien fungsi (vektor turunan parsialnya), dan dalam kasus vektor, jumlah turunan parsial sepanjang sumbu. Fitur utama dari operator ini adalah bahwa melalui itu Anda dapat mengekspresikan operasi utama analisis vektor -
grad (
gradien ),
div (
divergence ),
rot (
rotor ) dan
nabla2 (
Operator Laplace ). Perlu dicatat segera bahwa ungkapan
( bf vecu cdot nabla) bf vecu tidak sama dengan ( nabla cdot bf vecu) bf vecu - operator nabla tidak memiliki komutatif.
Seperti yang akan kita lihat nanti, ungkapan-ungkapan ini terasa disederhanakan ketika beralih ke ruang diskrit di mana kita akan melakukan semua perhitungan, jadi jangan khawatir jika saat ini Anda tidak begitu jelas tentang apa yang harus dilakukan dengan semua ini. Setelah membagi tugas menjadi beberapa bagian, kami akan menyelesaikannya secara berurutan dan mempresentasikan semua ini dalam bentuk aplikasi berurutan dari beberapa fungsi untuk lingkungan kita.
Solusi numerik dari persamaan Navier-Stokes
Untuk mewakili fluida kita dalam program, kita perlu mendapatkan representasi matematis dari keadaan setiap partikel fluida pada titik waktu yang berubah-ubah. Metode yang paling mudah untuk ini adalah membuat bidang vektor partikel yang menyimpan keadaannya dalam bentuk bidang koordinat:

Di setiap sel array dua dimensi kami, kami akan menyimpan kecepatan partikel pada suatu waktu
t: bf vecu=u( bf vecx,t), bf vecx= beginpmatrixx,y endpmatrix , dan jarak antara partikel dilambangkan dengan
deltax dan
deltay sesuai. Dalam kode tersebut, cukup bagi kita untuk mengubah nilai kecepatan setiap iterasi, menyelesaikan serangkaian persamaan.
Sekarang kami menyatakan gradien, divergensi, dan operator Laplace dengan mempertimbangkan kordinat kami (
i,j - indeks dalam array,
bf vecu(x), vecu(y) - mengambil komponen yang sesuai dari vektor):
Kami selanjutnya dapat menyederhanakan formula diskrit dari operator vektor jika kami menganggap itu
deltax= deltay=1 . Asumsi ini tidak akan banyak mempengaruhi keakuratan algoritma, namun, itu mengurangi jumlah operasi per iterasi, dan umumnya membuat ekspresi lebih menyenangkan bagi mata.
Gerakan partikel
Pernyataan ini hanya berfungsi jika kita dapat menemukan partikel terdekat relatif terhadap yang sedang dipertimbangkan saat ini. Untuk meniadakan semua kemungkinan biaya yang terkait dengan menemukannya, kami tidak akan melacak pergerakannya, tetapi dari
mana partikel berasal pada awal iterasi dengan memproyeksikan lintasan pergerakan mundur dalam waktu (dengan kata lain, kurangi vektor kecepatan kali perubahan waktu dari posisi saat ini). Dengan menggunakan teknik ini untuk setiap elemen array, kami akan yakin bahwa setiap partikel akan memiliki "tetangga":
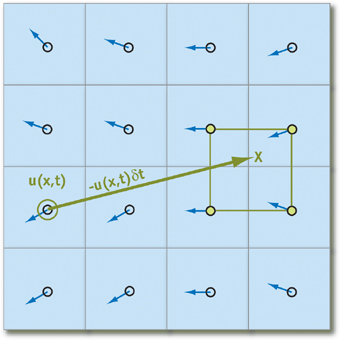
Puting itu
q - elemen array yang menyimpan status partikel, kami mendapatkan rumus berikut untuk menghitung kondisinya dari waktu ke waktu
deltat (kami percaya bahwa semua parameter yang diperlukan dalam bentuk akselerasi dan tekanan telah dihitung):
q( vec bfx,t+ deltat)=q( bf vecx− bf vecu deltat,t)
Kami segera mencatat bahwa untuk yang cukup kecil
deltat dan kita tidak pernah bisa melampaui batas sel, oleh karena itu sangat penting untuk memilih momentum yang tepat yang akan diberikan pengguna kepada partikel.
Untuk menghindari hilangnya keakuratan dalam hal proyeksi mengenai batas sel atau dalam kasus koordinat non-integer, kami akan melakukan interpolasi bilinear dari keadaan empat partikel terdekat dan menganggapnya sebagai nilai sebenarnya pada titik tersebut. Pada prinsipnya, metode seperti itu praktis tidak akan mengurangi keakuratan simulasi, dan pada saat yang sama itu cukup sederhana untuk diimplementasikan, jadi kami akan menggunakannya.
Viskositas
Setiap cairan memiliki viskositas tertentu, kemampuan untuk mencegah pengaruh kekuatan eksternal pada bagian-bagiannya (madu dan air akan menjadi contoh yang baik, dalam beberapa kasus koefisien viskositasnya berbeda dengan urutan besarnya). Viskositas secara langsung mempengaruhi percepatan yang diperoleh oleh cairan, dan dapat dinyatakan dengan rumus di bawah ini, jika untuk singkatnya kita menghilangkan istilah lain untuk sementara waktu:
partial vec bfu over partialt= nu nabla2 bf vecu
. Dalam kasus ini, persamaan iteratif untuk kecepatan mengambil bentuk berikut:
u( bf vecx,t+ deltat)=u( bf vecx,t)+ nu deltat nabla2 bf vecu
Kami akan sedikit mengubah kesetaraan ini, membawanya ke formulir
bfA vecx= vecb (bentuk standar dari sistem persamaan linear):
( bfI− nu deltat nabla2)u( bf vecx,t+ deltat)=u( bf vecx,t)
dimana
bfSAYA Apakah matriks identitas. Kita perlu transformasi semacam itu untuk kemudian menerapkan
metode Jacobi untuk menyelesaikan beberapa sistem persamaan yang serupa. Kami juga akan membahasnya nanti.
Kekuatan eksternal
Langkah paling sederhana dari algoritma adalah penerapan kekuatan eksternal ke medium. Untuk pengguna, ini akan tercermin dalam bentuk klik di layar dengan mouse atau gerakannya. Kekuatan eksternal dapat dijelaskan dengan rumus berikut, yang kami terapkan untuk setiap elemen matriks (
vec bfG - vektor momentum
xp,yp - posisi mouse
x,y - Koordinat sel saat ini,
r - radius aksi, parameter penskalaan):
vec bfF= vec bfG deltat bfexp kiri(−(x−xp)2+(y−yp)2 overr benar)
Vektor impuls dapat dengan mudah dihitung sebagai perbedaan antara posisi mouse sebelumnya dan yang sekarang (jika ada), dan di sini Anda masih bisa berkreasi. Di bagian algoritme inilah kita bisa memperkenalkan penambahan warna pada cairan, iluminasi, dll. Kekuatan eksternal juga dapat mencakup gravitasi dan suhu, dan meskipun tidak sulit untuk menerapkan parameter tersebut, kami tidak akan mempertimbangkannya dalam artikel ini.
Tekanan
Tekanan dalam persamaan Navier-Stokes adalah gaya yang mencegah partikel mengisi semua ruang yang tersedia bagi mereka setelah menerapkan gaya eksternal apa pun kepada mereka. Segera, perhitungannya sangat sulit, tetapi masalah kita dapat sangat disederhanakan dengan menerapkan
teorema dekomposisi Helmholtz .
Panggil
bf vecW bidang vektor diperoleh setelah menghitung perpindahan, kekuatan eksternal dan viskositas. Ini akan memiliki divergensi bukan-nol, yang bertentangan dengan kondisi ketidakmampatan cairan (
nabla cdot bf vecu=0 ), dan untuk memperbaikinya, perlu untuk menghitung tekanan. Menurut teorema dekomposisi Helmholtz,
bf vecW dapat direpresentasikan sebagai jumlah dari dua bidang:
bf vecW= vecu+ nablap
dimana
bfu - ini adalah bidang vektor yang kita cari dengan nol divergensi. Tidak ada bukti kesetaraan ini akan diberikan dalam artikel ini, tetapi pada akhirnya Anda dapat menemukan tautan dengan penjelasan terperinci. Kita dapat menerapkan operator nabla di kedua sisi ekspresi untuk mendapatkan rumus berikut untuk menghitung bidang tekanan skalar:
nabla cdot bf vecW= nabla cdot( vecu+ nablap)= nabla cdot vecu+ nabla2p= nabla2p
Ungkapan yang ditulis di atas adalah
persamaan Poisson untuk tekanan. Kita juga bisa menyelesaikannya dengan metode Jacobi yang disebutkan di atas, dan dengan demikian menemukan variabel terakhir yang tidak diketahui dalam persamaan Navier-Stokes. Pada prinsipnya, sistem persamaan linear dapat diselesaikan dalam berbagai cara yang berbeda dan canggih, tetapi kita masih akan memikirkan yang paling sederhana dari mereka, agar tidak semakin membebani artikel ini.
Batas dan kondisi awal
Setiap persamaan diferensial yang dimodelkan pada domain terbatas memerlukan kondisi awal atau batas yang ditentukan dengan benar, jika tidak, kita sangat mungkin mendapatkan hasil yang secara fisik salah. Kondisi batas ditetapkan untuk mengontrol perilaku fluida di dekat tepi kisi koordinat, dan kondisi awal menentukan parameter yang dimiliki partikel pada saat program dimulai.
Kondisi awal akan sangat sederhana - awalnya fluida stasioner (kecepatan partikel nol), dan tekanannya juga nol. Kondisi batas akan ditetapkan untuk kecepatan dan tekanan oleh rumus yang diberikan:
bf vecu0,j+ bf vecu1,j lebihdari2 deltay=0, bf vecui,0+ bf vecui,1 lebihdari2 deltax=0
bfp0,j− bfp1,j over deltax=0, bfpi,0− bfpi,1 over deltay=0
Dengan demikian, kecepatan partikel di tepi akan berlawanan dengan kecepatan di tepi (dengan demikian mereka akan mengusir dari tepi), dan tekanannya sama dengan nilai tepat di sebelah batas. Operasi ini harus diterapkan ke semua elemen pembatas dari array (misalnya, ada ukuran kisi
N kaliM , lalu kami menerapkan algoritme untuk sel yang ditandai dengan warna biru pada gambar):

Pewarna
Dengan apa yang kita miliki sekarang, Anda sudah dapat menemukan banyak hal menarik. Misalnya, sadari penyebaran pewarna dalam cairan. Untuk melakukan ini, kita hanya perlu memelihara bidang skalar lain, yang akan bertanggung jawab untuk jumlah cat pada setiap titik simulasi. Formula untuk memperbarui pewarna sangat mirip dengan kecepatan, dan dinyatakan sebagai:
partiald over partialt=−( vec bfu cdot nabla)d+ gamma nabla2d+S
Dalam formula
S bertanggung jawab untuk mengisi kembali area tersebut dengan pewarna (mungkin tergantung di mana pengguna mengklik),
d langsung adalah jumlah pewarna pada titik tersebut, dan
gamma - koefisien difusi. Memecahkannya tidak sulit, karena semua pekerjaan dasar tentang derivasi formula telah dilakukan, dan cukup untuk membuat beberapa pergantian. Cat dapat diimplementasikan dalam kode sebagai warna dalam format RGB, dan dalam hal ini tugas dikurangi menjadi operasi dengan beberapa nilai nyata.
Vortisitas
Persamaan vortisitas bukan bagian langsung dari persamaan Navier-Stokes, tetapi merupakan parameter penting untuk simulasi yang masuk akal dari gerakan pewarna dalam cairan. Karena fakta bahwa kami memproduksi algoritme pada bidang diskrit, serta karena kerugian dalam akurasi nilai floating-point, efek ini hilang, dan oleh karena itu kami perlu mengembalikannya dengan menerapkan gaya tambahan ke setiap titik dalam ruang. Vektor gaya ini ditetapkan sebagai
bf vecT dan ditentukan oleh rumus berikut:
bf omega= nabla times vecu
vec eta= nabla| omega|
bf vec psi= vec eta over| vec eta|
bf vecT= epsilon( vec psi times omega) deltax
omega ada hasil penerapan
rotor ke vektor kecepatan (definisinya diberikan di awal artikel),
vec eta - gradien bidang skalar dari nilai absolut
omega .
vec psi mewakili vektor yang dinormalisasi
vec eta , dan
epsilon Merupakan konstanta yang mengontrol seberapa besar vortisitas dalam cairan kita nantinya.
Metode Jacobi untuk memecahkan sistem persamaan linear
Dalam menganalisis persamaan Navier-Stokes, kami menemukan dua sistem persamaan - satu untuk viskositas dan yang lainnya untuk tekanan. Mereka dapat diselesaikan dengan algoritma iteratif, yang dapat dijelaskan dengan rumus iteratif berikut:
x(k+1)i,j=x(k)i−1,j+x(k)i+1,j+x(k)i,j−1+x(k)i,j+1+ alphabi,j lebihdari beta
Untuk kita
x - elemen array yang mewakili bidang skalar atau vektor.
k - nomor iterasi, kita dapat menyesuaikannya untuk meningkatkan akurasi perhitungan atau sebaliknya untuk menguranginya dan meningkatkan produktivitas.
Untuk menghitung viskositas, kami mengganti:
x=b= bf vecu ,
alpha=1 over nu deltat ,
beta=4+ alpha , di sini adalah parameternya
beta - jumlah bobot. Jadi, kita perlu menyimpan setidaknya dua bidang kecepatan vektor untuk membaca nilai-nilai satu bidang secara independen dan menulisnya ke bidang lain. Rata-rata, untuk menghitung bidang kecepatan dengan metode Jacobi, perlu dilakukan 20-50 iterasi, yang cukup banyak jika kita melakukan perhitungan pada CPU.
Untuk persamaan tekanan, kami membuat substitusi berikut:
x=p ,
b= nabla bf cdot vecW ,
alpha=−1 ,
beta=4 . Hasilnya, kami mendapat nilai
pi,j deltat pada intinya. Tetapi karena ini hanya digunakan untuk menghitung gradien yang dikurangi dari bidang kecepatan, transformasi tambahan dapat dihilangkan. Untuk bidang tekanan, yang terbaik adalah melakukan iterasi 40-80, karena dengan jumlah yang lebih kecil perbedaannya menjadi terlihat.
Implementasi algoritma
Kami akan mengimplementasikan algoritme di C ++, kami juga membutuhkan
Cuda Toolkit (Anda dapat membaca cara menginstalnya di situs web Nvidia), serta
SFML . Kami membutuhkan CUDA untuk memparalelkan algoritme, dan SFML hanya akan digunakan untuk membuat jendela dan menampilkan gambar di layar (Pada prinsipnya, ini dapat ditulis dalam OpenGL, tetapi perbedaan dalam kinerjanya tidak signifikan, tetapi kode akan bertambah 200 baris lainnya).
Toolkit Cuda
Pertama, kita akan berbicara sedikit tentang cara menggunakan Cuda Toolkit untuk memparalelkan tugas.
Panduan yang lebih rinci disediakan oleh Nvidia sendiri, jadi di sini kami membatasi diri hanya untuk yang paling diperlukan. Diasumsikan bahwa Anda dapat menginstal kompilator, dan Anda dapat membangun proyek pengujian tanpa kesalahan.
Untuk membuat fungsi yang berjalan pada GPU, pertama-tama Anda harus mendeklarasikan berapa banyak kernel yang ingin kita gunakan, dan berapa blok kernel yang perlu kita alokasikan. Untuk ini, Cuda Toolkit memberi kita struktur khusus -
dim3 , dengan menetapkan semua nilai x, y, z secara default ke 1. Dengan menetapkannya sebagai argumen saat memanggil fungsi, kita dapat mengontrol jumlah kernel yang dialokasikan. Karena kita bekerja dengan array dua dimensi, kita hanya perlu mengatur dua bidang dalam konstruktor:
x dan
y :
dim3 threadsPerBlock(x_threads, y_threads); dim3 numBlocks(size_x / x_threads, y_size / y_threads);
di mana
size_x dan
size_y adalah ukuran array yang sedang diproses. Tanda tangan dan panggilan fungsi adalah sebagai berikut (tanda kurung tiga sudut diproses oleh kompiler Cuda):
void __global__ deviceFunction();
Dalam fungsi itu sendiri, Anda dapat mengembalikan indeks array dua dimensi melalui nomor blok dan nomor kernel di blok ini menggunakan rumus berikut:
int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y;
Perlu dicatat bahwa fungsi yang dieksekusi pada kartu video harus ditandai dengan tag
__global__ , dan juga mengembalikan
batal , sehingga paling sering hasil perhitungan ditulis ke array yang dilewatkan sebagai argumen dan pra-dialokasikan dalam memori kartu video.
Fungsi
CudaMalloc dan
CudaFree bertanggung jawab untuk membebaskan dan mengalokasikan memori pada kartu video. Kami dapat beroperasi pada pointer ke area memori yang mereka kembalikan, tetapi kami tidak dapat mengakses data dari kode utama. Cara termudah untuk mengembalikan hasil perhitungan adalah dengan menggunakan
cudaMemcpy , mirip dengan
memcpy standar, tetapi dapat menyalin data dari kartu video ke memori utama dan sebaliknya.
SFML dan render jendela
Berbekal semua pengetahuan ini, kita akhirnya bisa beralih ke menulis kode secara langsung. Untuk memulai, mari buat file
main.cpp dan letakkan semua kode tambahan untuk render jendela di sana:
main.cpp #include <SFML/Graphics.hpp> #include <chrono> #include <cstdlib> #include <cmath> //SFML REQUIRED TO LAUNCH THIS CODE #define SCALE 2 #define WINDOW_WIDTH 1280 #define WINDOW_HEIGHT 720 #define FIELD_WIDTH WINDOW_WIDTH / SCALE #define FIELD_HEIGHT WINDOW_HEIGHT / SCALE static struct Config { float velocityDiffusion; float pressure; float vorticity; float colorDiffusion; float densityDiffusion; float forceScale; float bloomIntense; int radius; bool bloomEnabled; } config; void setConfig(float vDiffusion = 0.8f, float pressure = 1.5f, float vorticity = 50.0f, float cDiffuion = 0.8f, float dDiffuion = 1.2f, float force = 1000.0f, float bloomIntense = 25000.0f, int radius = 100, bool bloom = true); void computeField(uint8_t* result, float dt, int x1pos = -1, int y1pos = -1, int x2pos = -1, int y2pos = -1, bool isPressed = false); void cudaInit(size_t xSize, size_t ySize); void cudaExit(); int main() { cudaInit(FIELD_WIDTH, FIELD_HEIGHT); srand(time(NULL)); sf::RenderWindow window(sf::VideoMode(WINDOW_WIDTH, WINDOW_HEIGHT), ""); auto start = std::chrono::system_clock::now(); auto end = std::chrono::system_clock::now(); sf::Texture texture; sf::Sprite sprite; std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4); texture.create(FIELD_WIDTH, FIELD_HEIGHT); sf::Vector2i mpos1 = { -1, -1 }, mpos2 = { -1, -1 }; bool isPressed = false; bool isPaused = false; while (window.isOpen()) { end = std::chrono::system_clock::now(); std::chrono::duration<float> diff = end - start; window.setTitle("Fluid simulator " + std::to_string(int(1.0f / diff.count())) + " fps"); start = end; window.clear(sf::Color::White); sf::Event event; while (window.pollEvent(event)) { if (event.type == sf::Event::Closed) window.close(); if (event.type == sf::Event::MouseButtonPressed) { if (event.mouseButton.button == sf::Mouse::Button::Left) { mpos1 = { event.mouseButton.x, event.mouseButton.y }; mpos1 /= SCALE; isPressed = true; } else { isPaused = !isPaused; } } if (event.type == sf::Event::MouseButtonReleased) { isPressed = false; } if (event.type == sf::Event::MouseMoved) { std::swap(mpos1, mpos2); mpos2 = { event.mouseMove.x, event.mouseMove.y }; mpos2 /= SCALE; } } float dt = 0.02f; if (!isPaused) computeField(pixelBuffer.data(), dt, mpos1.x, mpos1.y, mpos2.x, mpos2.y, isPressed); texture.update(pixelBuffer.data()); sprite.setTexture(texture); sprite.setScale({ SCALE, SCALE }); window.draw(sprite); window.display(); } cudaExit(); return 0; }
baris di awal fungsi
utama std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4);
menciptakan gambar RGBA dalam bentuk array satu dimensi dengan panjang konstan. Kami akan meneruskannya bersama dengan parameter lain (posisi mouse, perbedaan antara frame) ke fungsi
computeField . Yang terakhir, serta beberapa fungsi lainnya, dideklarasikan di
kernel.cu dan memanggil kode yang dieksekusi pada GPU. Anda dapat menemukan dokumentasi tentang salah satu fungsi di situs web SFML, tidak ada yang super menarik terjadi dalam kode file, jadi kami tidak akan berhenti di situ lama.
Komputasi GPU
Untuk mulai menulis kode di bawah GPU, pertama buat file kernel.cu dan tentukan beberapa kelas tambahan di dalamnya:
Color3f, Vec2, Config, SystemConfig :
kernel.cu (struktur data) struct Vec2 { float x = 0.0, y = 0.0; __device__ Vec2 operator-(Vec2 other) { Vec2 res; res.x = this->x - other.x; res.y = this->y - other.y; return res; } __device__ Vec2 operator+(Vec2 other) { Vec2 res; res.x = this->x + other.x; res.y = this->y + other.y; return res; } __device__ Vec2 operator*(float d) { Vec2 res; res.x = this->x * d; res.y = this->y * d; return res; } }; struct Color3f { float R = 0.0f; float G = 0.0f; float B = 0.0f; __host__ __device__ Color3f operator+ (Color3f other) { Color3f res; res.R = this->R + other.R; res.G = this->G + other.G; res.B = this->B + other.B; return res; } __host__ __device__ Color3f operator* (float d) { Color3f res; res.R = this->R * d; res.G = this->G * d; res.B = this->B * d; return res; } }; struct Particle { Vec2 u;
Atribut
__host__ di depan nama metode berarti bahwa kode dapat dieksekusi pada CPU,
__device__ , sebaliknya, mewajibkan kompiler untuk mengumpulkan kode di bawah GPU. Kode menyatakan primitif untuk bekerja dengan vektor dua komponen, warna, konfigurasi dengan parameter yang dapat diubah dalam runtime, serta beberapa pointer statis ke array, yang akan kita gunakan sebagai buffer untuk perhitungan.
cudaInit dan
cudaExit juga didefinisikan dengan sangat sepele:
kernel.cu (init) void cudaInit(size_t x, size_t y) { setConfig(); colorArray[0] = { 1.0f, 0.0f, 0.0f }; colorArray[1] = { 0.0f, 1.0f, 0.0f }; colorArray[2] = { 1.0f, 0.0f, 1.0f }; colorArray[3] = { 1.0f, 1.0f, 0.0f }; colorArray[4] = { 0.0f, 1.0f, 1.0f }; colorArray[5] = { 1.0f, 0.0f, 1.0f }; colorArray[6] = { 1.0f, 0.5f, 0.3f }; int idx = rand() % colorArraySize; currentColor = colorArray[idx]; xSize = x, ySize = y; cudaSetDevice(0); cudaMalloc(&colorField, xSize * ySize * 4 * sizeof(uint8_t)); cudaMalloc(&oldField, xSize * ySize * sizeof(Particle)); cudaMalloc(&newField, xSize * ySize * sizeof(Particle)); cudaMalloc(&pressureOld, xSize * ySize * sizeof(float)); cudaMalloc(&pressureNew, xSize * ySize * sizeof(float)); cudaMalloc(&vorticityField, xSize * ySize * sizeof(float)); } void cudaExit() { cudaFree(colorField); cudaFree(oldField); cudaFree(newField); cudaFree(pressureOld); cudaFree(pressureNew); cudaFree(vorticityField); }
Dalam fungsi inisialisasi, kami mengalokasikan memori untuk array dua dimensi, menentukan array warna yang akan kami gunakan untuk mengecat cairan, dan juga menetapkan nilai default dalam konfigurasi. Di
cudaExit, kami hanya membebaskan semua buffer. Kedengarannya paradoks, untuk menyimpan array dua dimensi, paling menguntungkan untuk menggunakan array satu dimensi, akses yang akan dilakukan dengan ekspresi berikut:
array[y * size_x + x];
Kami memulai implementasi algoritma langsung dengan fungsi pergerakan partikel. Bidang
oldField dan
newField (bidang tempat data
berasal dan dari mana mereka dituliskan), ukuran array, serta waktu delta dan koefisien densitas (digunakan untuk mempercepat pembubaran pewarna dalam cairan dan membuat media tidak terlalu sensitif untuk
memajukan, ditransfer untuk
maju tindakan pengguna). Fungsi
interpolasi bilinear diimplementasikan dengan cara klasik melalui perhitungan nilai-nilai antara:
Diputuskan untuk membagi fungsi difusi viskositas menjadi beberapa bagian:
computeDiffusion dipanggil dari kode utama, yang memanggil
diffuse dan
computeColor beberapa kali yang telah ditentukan, dan kemudian menukar array dari tempat kami mengambil data dan yang mana kami menulisnya. Ini adalah cara termudah untuk mengimplementasikan pemrosesan data paralel, tetapi kami menghabiskan memori dua kali lebih banyak.
Kedua fungsi menyebabkan variasi metode Jacobi. Tubuh
jacobiColor dan
jacobiVelocity segera memeriksa bahwa elemen saat ini tidak di perbatasan - dalam hal ini, kita harus mengaturnya sesuai dengan rumus yang dijelaskan di bagian
Batas dan kondisi awal .
Penggunaan kekuatan eksternal diimplementasikan melalui fungsi tunggal -
applyForce , yang mengambil sebagai argumen posisi mouse, warna pewarna, serta radius aksi. Dengan bantuannya, kita dapat memberi kecepatan pada partikel-partikel tersebut, serta mengecatnya. Eksponen persaudaraan memungkinkan Anda untuk membuat area tidak terlalu tajam, dan pada saat yang sama cukup jelas dalam radius yang ditentukan.
Perhitungan vortisitas sudah merupakan proses yang lebih rumit, oleh karena itu kami mengimplementasikannya dalam
computeVorticity dan
applyVorticity , kami juga mencatat bahwa bagi mereka perlu mendefinisikan dua operator vektor seperti
curl (rotor) dan
absGradient (gradien dari nilai medan absolut). Untuk menentukan efek vortex tambahan, kami mengalikan
y komponen vektor gradien aktif
−1 , dan kemudian menormalkannya dengan membaginya dengan panjang (tanpa lupa untuk memeriksa bahwa vektor itu bukan nol):
Langkah selanjutnya dalam algoritma akan menjadi perhitungan medan tekanan skalar dan proyeksi pada bidang kecepatan. Untuk melakukan ini, kita perlu mengimplementasikan 4 fungsi:
divergensi , yang akan mempertimbangkan divergensi kecepatan,
jacobiPressure , yang mengimplementasikan metode Jacobi untuk tekanan, dan
computePressure dengan
computePressureImpl , yang
mengulangi perhitungan lapangan:
Proyeksi ini cocok dalam dua fungsi kecil -
proyek dan
gradien yang
membutuhkan tekanan. Ini bisa dikatakan tahap terakhir dari algoritma simulasi kami:
Setelah proyeksi, kita dapat dengan aman melanjutkan render gambar ke buffer dan berbagai efek pasca. Fungsi
cat menyalin warna dari bidang partikel ke array RGBA. Fungsi
applyBloom juga diterapkan, yang menyoroti cairan ketika kursor
diletakkan di atasnya dan tombol mouse ditekan. Dari pengalaman, teknik ini membuat gambar lebih menyenangkan dan menarik bagi mata pengguna, tetapi tidak perlu sama sekali.
Dalam post-processing, Anda juga dapat menyorot tempat-tempat di mana fluida memiliki kecepatan tertinggi, mengubah warna tergantung pada vektor gerakan, menambahkan berbagai efek, dll., Tetapi dalam kasus kami, kami akan membatasi diri pada jenis minimum, karena bahkan dengan itu gambarnya sangat menarik (terutama dalam dinamika) :
Dan pada akhirnya, kita masih memiliki satu fungsi utama yang kita panggil dari
main.cpp -
computeField . Ini menghubungkan semua potongan algoritma, memanggil kode pada kartu video, dan juga menyalin data dari gpu ke cpu. Ini juga berisi perhitungan vektor momentum dan pilihan warna pewarna, yang kami sampaikan untuk
menerapkan Force :
Kesimpulan
Pada artikel ini, kami menganalisis algoritma numerik untuk menyelesaikan persamaan Navier-Stokes dan menulis sebuah program simulasi kecil untuk fluida yang tidak dapat dimampatkan. Mungkin kami tidak memahami semua seluk-beluknya, tetapi saya berharap bahwa materi tersebut ternyata menarik dan bermanfaat bagi Anda, dan setidaknya berfungsi sebagai pengantar yang baik untuk bidang pemodelan cairan.
Sebagai penulis artikel ini, saya akan dengan tulus menghargai komentar dan tambahan, dan akan mencoba menjawab semua pertanyaan Anda di bawah posting ini.
Materi tambahan
Anda dapat menemukan semua kode sumber dalam artikel ini di
repositori Github saya. Setiap saran untuk perbaikan dipersilahkan.
Bahan asli yang dijadikan dasar untuk artikel ini dapat ditemukan di situs web resmi Nvidia. Ini juga menyajikan contoh-contoh implementasi bagian-bagian algoritma dalam bahasa shader:
developer.download.nvidia.com/books/HTML/gpugems/gpugems_ch38.htmlBukti teorema dekomposisi Helmholtz dan sejumlah besar bahan tambahan tentang mekanika fluida dapat ditemukan dalam buku ini (Bahasa Inggris, lihat bagian 1.2):
Chorin, AJ, dan JE Marsden. 1993. Pengantar Matematika untuk Mekanika Fluida. Edisi ke-3. SpringerSaluran satu YouTube berbahasa Inggris, membuat konten berkualitas yang berkaitan dengan matematika, dan menyelesaikan persamaan diferensial khususnya (Bahasa Inggris). Video yang sangat visual yang membantu memahami esensi banyak hal dalam matematika dan fisika:3Blue1Brown -Persamaan Diferensial YouTube (3Blue1Brown)Saya juga berterima kasih kepada WhiteBlackGoose atas bantuannya dalam menyiapkan materi untuk artikel.
Dan pada akhirnya, bonus kecil - beberapa tangkapan layar yang indah diambil dalam program: Streaming langsung (pengaturan default)
Streaming langsung (pengaturan default) Whirlpool (radius besar dalam berlaku Force)
Whirlpool (radius besar dalam berlaku Force) Gelombang (vortisitas tinggi + difusi)Juga, dengan permintaan populer, saya menambahkan video dengan simulasi:
Gelombang (vortisitas tinggi + difusi)Juga, dengan permintaan populer, saya menambahkan video dengan simulasi: