Alat baris perintah
Sloc Cloc dan Code (scc) yang saya tulis , yang sekarang diselesaikan dan didukung oleh banyak orang hebat, menghitung baris kode, komentar, dan mengevaluasi kompleksitas file di dalam direktori. Pilihan yang baik diperlukan di sini. Alat menghitung operator percabangan dalam kode. Tetapi apakah kompleksitas itu? Misalnya, pernyataan "File ini memiliki kesulitan 10" tidak terlalu berguna tanpa konteks. Untuk mengatasi masalah ini, saya menjalankan
scc pada semua sumber di Internet. Ini juga akan memungkinkan Anda menemukan beberapa kasus ekstrem yang tidak saya pertimbangkan dalam alat itu sendiri. Tes brute force yang kuat.
Tetapi jika saya akan menjalankan tes pada semua sumber di dunia, itu akan membutuhkan banyak sumber daya komputasi, yang juga merupakan pengalaman yang menarik. Karena itu, saya memutuskan untuk menuliskan semuanya - dan artikel ini muncul.
Singkatnya, saya mengunduh dan memproses banyak sumber.
Tokoh telanjang:
- 9.985.051 total repositori
- 9.100.083 repositori dengan setidaknya satu file
- 884 968 repositori kosong (tanpa file)
- 3.500.000.000 file di semua repositori
- Diproses 40 736 530 379 778 byte (40 TB)
- 1.086.723.618.560 baris diidentifikasi
- 816.822.273.469 baris dengan kode yang dikenali
- 124 382 152 510 baris kosong
- 145 519 192 581 baris komentar
- Kompleksitas total menurut aturan scc: 71 884 867 919
- 2 bug baru ditemukan di scc
Sebut saja satu detail. Tidak ada 10 juta proyek, seperti yang ditunjukkan dalam judul profil tinggi. Saya melewatkan 15.000, jadi saya mengitarinya. Saya minta maaf untuk ini.
Butuh waktu sekitar lima minggu untuk mengunduh semuanya, melewati scc dan menyimpan semua data. Kemudian sedikit lebih dari 49 jam untuk memproses 1 TB JSON dan mendapatkan hasil di bawah ini.
Perhatikan juga bahwa saya bisa keliru dalam beberapa perhitungan. Saya akan segera memberi tahu Anda jika ada kesalahan yang terdeteksi, dan memberikan dataset.
Daftar isi
Metodologi
Sejak meluncurkan
searchcode.com, saya telah mengumpulkan koleksi lebih dari 7.000.000 proyek di git, mercurial, subversi dan sebagainya. Jadi mengapa tidak memprosesnya? Bekerja dengan git biasanya merupakan solusi termudah, jadi kali ini saya mengabaikan mercurial dan subversi dan mengekspor daftar lengkap proyek git. Ternyata saya sebenarnya melacak 12 juta repositori git, dan saya mungkin perlu me-refresh halaman utama untuk mencerminkan ini.
Jadi sekarang saya memiliki 12 juta repositori git untuk diunduh dan diproses.
Ketika Anda menjalankan scc, Anda dapat memilih output dalam JSON dengan menyimpan file ke disk:
scc --format json --output myfile.json main.go Hasilnya adalah sebagai berikut (untuk satu file):
[ { "Blank": 115, "Bytes": 0, "Code": 423, "Comment": 30, "Complexity": 40, "Count": 1, "Files": [ { "Binary": false, "Blank": 115, "Bytes": 20396, "Callback": null, "Code": 423, "Comment": 30, "Complexity": 40, "Content": null, "Extension": "go", "Filename": "main.go", "Hash": null, "Language": "Go", "Lines": 568, "Location": "main.go", "PossibleLanguages": [ "Go" ], "WeightedComplexity": 0 } ], "Lines": 568, "Name": "Go", "WeightedComplexity": 0 } ]
Untuk contoh yang lebih besar, lihat hasil untuk proyek
redis :
redis.json . Semua hasil di bawah ini diperoleh dari hasil seperti itu tanpa data tambahan.
Harus diingat bahwa scc biasanya mengklasifikasikan bahasa berdasarkan ekstensi (kecuali ekstensi itu umum, seperti Verilog dan Coq). Jadi, jika Anda menyimpan file HTML dengan ekstensi java, itu akan dianggap sebagai file java. Ini biasanya bukan masalah, karena mengapa melakukan ini? Tapi, tentu saja, dalam skala besar, masalahnya menjadi nyata. Saya menemukan ini nanti ketika beberapa file disamarkan sebagai ekstensi yang berbeda.
Beberapa waktu lalu saya menulis
kode untuk membuat tag github berbasis scc . Karena proses diperlukan untuk menyimpan hasil, saya mengubahnya sedikit untuk menyimpannya dalam format JSON pada AWS S3.
Dengan kode untuk label di AWS pada lambda, saya mengambil daftar proyek yang diekspor, menulis sekitar 15 baris python untuk menghapus format agar sesuai dengan lambda saya, dan membuat permintaan untuk itu. Menggunakan multiprosesor python, saya memparalelkan permintaan ke 32 proses sehingga titik akhir merespons cukup cepat.
Semuanya bekerja dengan sangat baik. Namun, masalahnya adalah, pertama, dalam biaya, dan kedua, lambda memiliki batas waktu 30 detik untuk API Gateway / ALB, sehingga tidak dapat memproses repositori besar dengan cukup cepat. Saya tahu bahwa ini bukan solusi yang paling ekonomis, tetapi saya pikir harganya sekitar $ 100, dan saya siapkan. Setelah memproses satu juta repositori, saya memeriksa - dan biayanya sekitar $ 60. Karena saya tidak senang dengan prospek akun AWS akhir sebesar $ 700, saya memutuskan untuk mempertimbangkan kembali keputusan saya. Perlu diingat bahwa ini pada dasarnya adalah penyimpanan dan CPU yang digunakan untuk mengumpulkan semua informasi ini. Pemrosesan dan ekspor data secara signifikan meningkatkan harga.
Karena saya sudah menggunakan AWS, solusi cepat adalah membuang URL sebagai pesan di SQS dan menariknya menggunakan instance EC2 atau Fargate untuk diproses. Kemudian skala seperti orang gila. Namun terlepas dari pengalaman sehari-hari dengan AWS, saya selalu percaya pada
prinsip -
prinsip pemrograman Taco Bell . Selain itu, hanya ada 12 juta repositori, jadi saya memutuskan untuk mengimplementasikan solusi yang lebih sederhana (lebih murah).
Memulai penghitungan secara lokal tidak dimungkinkan karena internet yang mengerikan di Australia. Namun, searchcode.com saya berfungsi dengan menggunakan server khusus dari Hetzner dengan hati-hati. Ini adalah mesin i7 Quad Core 32 GB RAM yang cukup kuat, seringkali dengan ruang penyimpanan 2 TB (biasanya tidak digunakan). Mereka biasanya memiliki suplai daya komputasi yang baik. Sebagai contoh, server front-end sebagian besar waktu menghitung akar kuadrat dari nol. Jadi mengapa tidak mulai memproses di sana?
Ini sebenarnya bukan pemrograman Taco Bell karena saya menggunakan alat bash dan gnu. Saya menulis sebuah
program sederhana di Go untuk menjalankan 32 go-rutin yang membaca data dari saluran, menghasilkan subproses git dan scc sebelum menulis output ke JSON dalam S3. Saya benar-benar menulis solusinya dengan Python, tetapi kebutuhan untuk menginstal dependensi pip pada server bersih saya sepertinya ide yang buruk, dan sistemnya crash dengan cara yang aneh sehingga saya tidak ingin melakukan debug.
Menjalankan semua ini di server menghasilkan metrik berikut di htop, dan beberapa proses git / scc yang berjalan (scc tidak muncul dalam tangkapan layar ini) mengasumsikan bahwa semuanya berfungsi seperti yang diharapkan, yang dikonfirmasi oleh hasil dalam S3.

Presentasi dan perhitungan hasil
Baru
- baru ini saya membaca
artikel - artikel ini , jadi saya mempunyai ide untuk meminjam format tulisan-tulisan ini sehubungan dengan penyajian informasi. Namun, saya juga ingin menambahkan
jQuery DataTables ke tabel besar untuk mengurutkan dan mencari / memfilter hasil. Dengan demikian, dalam
artikel asli, Anda dapat mengklik judul untuk mengurutkan dan menggunakan kolom pencarian untuk memfilter.
Ukuran data yang perlu diproses memunculkan pertanyaan lain. Bagaimana memproses 10 juta file JSON, menempati sedikit lebih dari 1 TB ruang disk dalam bucket S3?
Pikiran pertama adalah AWS Athena. Tetapi karena biayanya sekitar $ 2,50
per permintaan untuk dataset seperti itu, saya segera mulai mencari alternatif. Namun, jika Anda menyimpan data di sana dan jarang memprosesnya, ini mungkin solusi termurah.
Saya memposting pertanyaan di obrolan perusahaan (mengapa menyelesaikan masalah sendiri).
Satu ide adalah untuk membuang data ke dalam database SQL yang besar. Namun, ini berarti memproses data dalam database, dan kemudian menjalankan kueri beberapa kali. Plus, struktur data berarti beberapa tabel, yang berarti kunci dan indeks asing untuk memberikan tingkat kinerja tertentu. Ini sepertinya boros, karena kita hanya bisa memproses data saat kita membacanya dari disk - dalam satu pass. Saya juga khawatir membuat database sebesar itu. Hanya dengan data, ukurannya akan lebih dari 1 TB sebelum menambahkan indeks.
Melihat bagaimana saya membuat JSON dengan cara yang sederhana, saya pikir, mengapa tidak memproses hasilnya dengan cara yang sama? Tentu saja ada satu masalah. Menarik 1 TB data dari S3 akan menghabiskan banyak biaya. Jika program macet, itu akan mengganggu. Untuk mengurangi biaya, saya ingin menarik semua file secara lokal dan menyimpannya untuk diproses lebih lanjut. Saran bagus: lebih baik tidak menyimpan
banyak file kecil dalam satu direktori . Ini menyebalkan untuk kinerja runtime, dan sistem file tidak suka itu.
Jawaban saya untuk ini adalah
program Go sederhana lainnya untuk menarik file dari S3 dan kemudian menyimpannya dalam file tar. Lalu saya bisa memproses file ini lagi dan lagi. Prosesnya sendiri menjalankan
program Go yang sangat jelek untuk memproses file tar sehingga saya dapat menjalankan kembali kueri tanpa harus menarik data dari S3 berulang kali. Saya tidak repot dengan rutinitas di sini karena dua alasan. Pertama, saya tidak ingin memuat server sebanyak mungkin, jadi saya membatasi diri pada satu inti agar CPU bekerja keras (yang lain kebanyakan terkunci pada prosesor untuk membaca file tar). Kedua, saya ingin menjamin keamanan benang.
Ketika ini dilakukan, satu set pertanyaan diperlukan untuk dijawab. Saya kembali menggunakan pikiran kolektif dan menghubungkan rekan-rekan saya sementara saya datang dengan ide-ide saya sendiri. Hasil dari penggabungan pikiran ini disajikan di bawah ini.
Anda dapat menemukan
semua kode yang saya gunakan untuk memproses JSON, termasuk kode untuk pemrosesan lokal, dan
skrip Python jelek yang saya gunakan untuk menyiapkan sesuatu yang berguna untuk artikel ini: tolong jangan mengomentarinya, saya tahu bahwa kode itu jelek , dan ini ditulis untuk tugas satu kali, karena saya tidak akan pernah melihatnya lagi.
Jika Anda ingin melihat kode yang saya tulis untuk penggunaan umum, lihat
sumber scc .
Biaya
Saya menghabiskan sekitar $ 60 untuk komputasi sambil mencoba bekerja dengan lambda. Saya belum melihat biaya penyimpanan S3, tetapi harus mendekati $ 25, tergantung pada ukuran data. Namun, ini tidak termasuk biaya transmisi, yang saya juga tidak tonton. Harap dicatat bahwa saya membersihkan ember setelah selesai, jadi ini bukan biaya tetap.
Tetapi setelah beberapa saat saya masih meninggalkan AWS. Jadi berapa biaya yang sebenarnya jika saya ingin melakukannya lagi?
Semua perangkat lunak yang kami miliki adalah gratis dan gratis. Jadi tidak ada yang perlu dikhawatirkan.
Dalam kasus saya, biayanya nol, karena saya menggunakan daya komputasi "bebas" yang tersisa dari searchcode.com. Namun, tidak semua orang memiliki sumber daya gratis seperti itu. Karena itu, mari kita asumsikan bahwa orang lain ingin mengulang ini dan harus menaikkan server.
Ini dapat dilakukan untuk € 73 menggunakan
dedicated server baru termurah
dari Hetzner , termasuk biaya pemasangan server baru. Jika Anda menunggu dan mempelajari
bagian dengan lelang , Anda dapat menemukan server yang jauh lebih murah tanpa biaya instalasi. Pada saat penulisan, saya menemukan mobil yang sempurna untuk proyek ini, seharga € 25,21 sebulan tanpa biaya pemasangan.
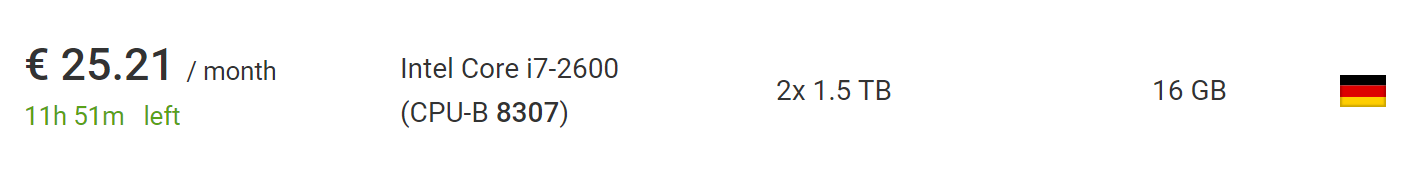
Apa yang lebih baik, di luar Uni Eropa, PPN akan dihapus dari harga ini, jadi silakan mengambil 10% lagi.
Oleh karena itu, jika Anda mengangkat layanan seperti itu dari awal pada perangkat lunak saya, pada akhirnya akan dikenakan biaya hingga $ 100, tetapi lebih dari $ 50, jika Anda sedikit sabar atau sukses. Ini mengasumsikan bahwa Anda telah menggunakan server kurang dari dua bulan, yang cukup untuk mengunduh dan memproses. Ada juga waktu yang cukup untuk mendapatkan daftar 10 juta repositori.
Jika saya menggunakan tar zip (yang sebenarnya tidak terlalu sulit), saya bisa memproses repositori 10 kali lebih banyak pada mesin yang sama, dan file yang dihasilkan masih akan tetap cukup kecil untuk muat pada HDD yang sama. Meskipun prosesnya mungkin memakan waktu beberapa bulan, karena pengunduhan akan memakan waktu lebih lama.
Untuk melampaui 100 juta repositori, bagaimanapun, semacam sharding diperlukan. Namun demikian, aman untuk mengatakan bahwa Anda akan mengulangi proses pada skala saya atau jauh lebih besar, pada peralatan yang sama tanpa banyak usaha atau perubahan kode.
Sumber data
Berikut ini berapa banyak proyek yang berasal dari masing-masing dari tiga sumber: github, bitbucket, dan gitlab. Harap dicatat bahwa ini sebelum mengecualikan repositori kosong, oleh karena itu, jumlahnya melebihi jumlah repositori yang benar-benar diproses dan diperhitungkan dalam tabel berikut.
Saya minta maaf kepada staf GitHub / Bitbucket / GitLab jika Anda membaca ini. Jika skrip saya menyebabkan masalah (walaupun saya ragu), saya minum pilihan Anda saat bertemu dengan saya.
Berapa banyak file dalam repositori?
Mari kita beralih ke masalah nyata. Mari kita mulai dengan yang sederhana. Berapa banyak file dalam repositori rata-rata? Sebagian besar proyek hanya memiliki beberapa file atau lebih? Setelah mengulang-ulang repositori, kami mendapatkan jadwal berikut:

Di sini, sumbu x menunjukkan bucket dengan jumlah file, dan sumbu y menunjukkan jumlah proyek dengan begitu banyak file. Batasi sumbu horizontal hingga seribu file, karena grafiknya terlalu dekat dengan sumbu.
Sepertinya kebanyakan repositori memiliki kurang dari 200 file.
Tetapi bagaimana dengan visualisasi hingga persentil ke-95, yang akan menunjukkan gambaran nyata? Ternyata dalam sebagian besar (95%) proyek - kurang dari 1000 file. Sementara 90% proyek memiliki kurang dari 300 file dan 85% memiliki kurang dari 200.

Jika Anda ingin membuat bagan sendiri dan melakukannya lebih baik dari saya, berikut ini
tautan ke data mentah di JSON .
Apa gangguan bahasa?
Misalnya, jika file Java diidentifikasi, maka kami menambah jumlah Java dalam proyek dengan satu, dan kami tidak melakukan apa pun untuk file kedua. Ini memberikan gambaran singkat tentang bahasa apa yang paling umum digunakan. Tidak mengherankan, bahasa yang paling umum termasuk penurunan harga, .gitignore, dan plaintext.
Penurunan harga adalah bahasa yang paling umum digunakan, itu terlihat di lebih dari 6 juta proyek, yaitu sekitar 2⁄3 dari total. Ini masuk akal, karena hampir semua proyek menyertakan README.md yang ditampilkan dalam HTML untuk halaman repositori.
Berapa banyak file dalam repositori menurut bahasa?
Selain tabel sebelumnya, tetapi dirata-rata dengan jumlah file untuk setiap bahasa di repositori. Artinya, berapa banyak file Java rata-rata ada untuk semua proyek di mana ada Java?
Berapa banyak baris kode dalam file bahasa yang khas?
Saya kira itu masih menarik untuk melihat bahasa mana yang memiliki file terbesar rata-rata? Menggunakan rata-rata aritmatika menghasilkan angka abnormal tinggi karena proyek-proyek seperti sqlite.c, yang termasuk dalam banyak repositori, menggabungkan banyak file menjadi satu, tetapi tidak ada yang pernah bekerja pada satu file besar ini (saya harap!)Oleh karena itu, saya menghitung rata-rata median. Namun, bahasa dengan nilai sangat tinggi, seperti Bosque dan JavaScript, masih ada.Jadi saya berpikir, mengapa tidak melakukan gerakan ksatria? Atas saran Darrell (seorang penduduk Kablamo dan seorang ilmuwan data hebat), saya membuat satu perubahan kecil dan mengubah rata-rata aritmatika, menjatuhkan file lebih dari 5.000 baris untuk menghapus anomali.Kompleksitas file rata-rata dalam setiap bahasa?
Apa kompleksitas file rata-rata untuk setiap bahasa?Faktanya, peringkat kompleksitas tidak dapat secara langsung dikorelasikan antar bahasa. Kutipan dari readme sendiri scc:Skor kompleksitas hanyalah angka yang hanya dapat dicocokkan antara file dalam bahasa yang sama. Seharusnya tidak digunakan untuk membandingkan bahasa secara langsung. Alasannya adalah bahwa itu dihitung dengan mencari operator cabang dan loop untuk setiap file.
Dengan demikian, bahasa tidak dapat dibandingkan satu sama lain di sini, meskipun ini dapat dilakukan antara bahasa yang sama seperti Java dan C, misalnya.Ini adalah metrik yang lebih berharga untuk file individual dalam bahasa yang sama. Dengan demikian, Anda dapat menjawab pertanyaan "Apakah file yang saya gunakan lebih mudah atau lebih sulit daripada rata-rata?"Saya harus menyebutkan bahwa saya akan senang dengan saran untuk meningkatkan metrik ini di scc . Untuk komit, biasanya cukup dengan menambahkan beberapa kata kunci saja ke file languages.json, sehingga setiap programmer dapat membantu.Jumlah rata-rata komentar untuk file dalam setiap bahasa?
Berapa jumlah rata-rata komentar dalam file dalam setiap bahasa?Mungkin pertanyaannya dapat diulangi: pengembang di mana bahasa menulis komentar paling banyak, menunjukkan kesalahpahaman pembaca.Apa nama file yang paling umum?
Nama file apa yang paling umum di semua basis kode, mengabaikan ekstensi dan huruf besar-kecil?Jika Anda bertanya kepada saya sebelumnya, saya akan mengatakan: README, utama, indeks, lisensi. Hasilnya cukup mencerminkan asumsi saya. Meski ada banyak hal menarik. Saya tidak tahu mengapa begitu banyak proyek berisi file bernama 15atau s15.Makefile yang paling umum mengejutkan saya sedikit, tetapi kemudian saya ingat bahwa itu digunakan dalam banyak proyek JavaScript baru. Hal lain yang menarik untuk dicatat: tampaknya jQuery masih di atas kuda, dan laporan kematiannya sangat dibesar-besarkan, dan ia berada di tempat keempat dalam daftar.Harap dicatat bahwa karena keterbatasan memori, saya membuat proses ini sedikit kurang akurat. Setelah setiap 100 proyek, saya memeriksa peta dan menghapus nama-nama file yang terjadi kurang dari 10 kali dari daftar. Mereka dapat kembali ke tes berikutnya, dan jika mereka bertemu lebih dari 10 kali, mereka tetap ada dalam daftar. Mungkin beberapa hasil memiliki kesalahan jika beberapa nama umum jarang muncul di batch pertama repositori sebelum menjadi umum. Singkatnya, ini bukan angka absolut, tetapi harus cukup dekat dengan mereka.Saya bisa menggunakan pohon awalan untuk "memeras" ruang dan mendapatkan angka absolut, tetapi saya tidak ingin menulisnya, jadi saya sedikit menyalahgunakan peta untuk menghemat memori yang cukup dan mendapatkan hasilnya. Namun, akan sangat menarik untuk mencoba pohon awalan nanti.Berapa banyak repositori yang kehilangan lisensi?
Ini sangat menarik. Berapa banyak repositori yang memiliki setidaknya beberapa file lisensi eksplisit? Harap dicatat bahwa tidak adanya file lisensi di sini tidak berarti bahwa proyek tidak memilikinya, karena dapat ada dalam file README atau dapat ditunjukkan melalui tag komentar SPDX dalam baris. Ini hanya berarti bahwa sccia tidak dapat menemukan file lisensi eksplisit menggunakan kriteria sendiri. Saat ini, file-file tersebut dianggap sebagai "lisensi", "lisensi", "menyalin", "menyalin3", "tidak berlisensi", "tidak berlisensi", "lisensi-mit", "lisensi-mit" atau "hak cipta".Sayangnya, sebagian besar repositori tidak memiliki lisensi. Saya akan mengatakan bahwa ada banyak alasan mengapa perangkat lunak memerlukan lisensi, tetapi orang lain mengatakannya untuk saya.
Berapa banyak proyek yang menggunakan banyak file .gitignore?
Beberapa mungkin tidak mengetahui hal ini, tetapi mungkin ada beberapa file .gitignore di proyek git. Dengan pemikiran ini, berapa banyak proyek yang menggunakan banyak file .gitignore? Dan pada saat yang sama, berapa banyak yang tidak memiliki satu pun?Saya menemukan proyek yang agak menarik dengan 25.794 file .gitignore di repositori. Hasil selanjutnya adalah 2547. Saya tidak tahu apa yang sedang terjadi di sana. Saya melirik sebentar: sepertinya mereka digunakan untuk memeriksa direktori, tetapi saya tidak dapat mengkonfirmasi ini.Kembali ke data, berikut adalah grafik repositori dengan hingga 20 file .gitignore, yang mencakup 99% dari semua proyek. Seperti yang diharapkan, sebagian besar proyek memiliki 0 atau 1 file .gitignore. Ini dikonfirmasi oleh penurunan besar sepuluh kali lipat dalam jumlah proyek dengan 2 file. Yang mengejutkan saya adalah berapa banyak proyek yang memiliki lebih dari satu file .gitignore. Ekor panjang dalam hal ini sangat panjang.Saya ingin tahu mengapa beberapa proyek memiliki ribuan file seperti itu. Salah satu pembuat masalah utama adalah garpu https://github.com/PhantomX/slackbuilds : masing-masing memiliki sekitar 2.547 file .gitignore. Repositori lain dengan lebih dari seribu file .gitignore tercantum di bawah ini.
Seperti yang diharapkan, sebagian besar proyek memiliki 0 atau 1 file .gitignore. Ini dikonfirmasi oleh penurunan besar sepuluh kali lipat dalam jumlah proyek dengan 2 file. Yang mengejutkan saya adalah berapa banyak proyek yang memiliki lebih dari satu file .gitignore. Ekor panjang dalam hal ini sangat panjang.Saya ingin tahu mengapa beberapa proyek memiliki ribuan file seperti itu. Salah satu pembuat masalah utama adalah garpu https://github.com/PhantomX/slackbuilds : masing-masing memiliki sekitar 2.547 file .gitignore. Repositori lain dengan lebih dari seribu file .gitignore tercantum di bawah ini.?
Bagian ini bukan ilmu pasti, tetapi milik kelas masalah pemrosesan bahasa alami. Mencari istilah yang kasar atau kasar dalam daftar file tertentu tidak akan pernah efektif. Jika Anda mencari dengan pencarian sederhana, Anda akan menemukan banyak file biasa seperti assemble.shdan sebagainya. Jadi saya mengambil daftar kutukan dan kemudian memeriksa apakah ada file di setiap proyek mulai dengan salah satu dari nilai-nilai ini diikuti oleh sebuah titik. Ini berarti bahwa file yang dinamai gangbang.javaakan diperhitungkan, tetapi assemble.shtidak. Namun, ia akan kehilangan banyak opsi berbeda, seperti nama pu55syg4rgle.javalain yang sama kasarnya.Daftar saya berisi beberapa kata di leetspeak, seperti b00bsdan b1tch, untuk menangkap beberapa kasus menarik. Daftar lengkapnya di sini.Meskipun ini tidak sepenuhnya akurat, seperti yang telah disebutkan, sangat menarik untuk melihat hasilnya. Mari kita mulai dengan daftar bahasa di mana kutukan paling banyak. Mungkin, Anda harus menghubungkan hasil dengan jumlah total kode dalam setiap bahasa. Jadi inilah para pemimpinnya.Menarik! Pikiran pertama saya adalah: "Oh, pengembang C nakal ini!" Tetapi terlepas dari sejumlah besar file seperti itu, mereka menulis begitu banyak kode sehingga persentase kutukan hilang dalam jumlah total. Namun, cukup jelas bahwa pengembang Dart memiliki beberapa kata di gudang senjata mereka! Jika Anda mengenal salah satu programmer Dart, Anda bisa menjabat tangannya.Saya juga ingin tahu kutukan apa yang paling umum digunakan. Mari kita lihat pikiran kolektif kotor yang umum. Beberapa yang terbaik yang saya temukan adalah nama normal (jika Anda menyipitkan mata), tetapi sebagian besar yang lain pasti akan mengejutkan kolega dan beberapa komentar dalam permintaan kolam.Harap perhatikan bahwa beberapa kata yang lebih menyinggung dalam daftar memang memiliki nama file yang cocok, yang menurut saya cukup mengejutkan. Untungnya, mereka tidak terlalu umum dan tidak termasuk dalam daftar di atas, yang terbatas pada file dengan jumlah lebih dari 100. Saya harap file-file ini hanya ada untuk pengujian daftar allow / deny dan sejenisnya.File terbesar dengan jumlah baris di setiap bahasa
Seperti yang diharapkan, plaintext, SQL, XML, JSON, dan CSV menempati posisi teratas: mereka biasanya berisi metadata, dump database, dan sejenisnya.Catatan Beberapa tautan di bawah ini mungkin tidak berfungsi karena beberapa informasi tambahan saat membuat file. Sebagian besar harus berfungsi, tetapi bagi sebagian orang, Anda mungkin perlu sedikit memodifikasi URL.Apa file paling kompleks dalam setiap bahasa?
Sekali lagi, nilai-nilai ini tidak sebanding secara langsung satu sama lain, tetapi menarik untuk melihat apa yang dianggap paling sulit di setiap bahasa.Beberapa file ini adalah monster absolut. Sebagai contoh, pertimbangkan file C ++ paling kompleks yang saya temukan: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp : ini adalah kompiler neraka 28,3 megabyte (dan, untungnya, tampaknya dihasilkan secara otomatis).Catatan Beberapa tautan di bawah ini mungkin tidak berfungsi karena beberapa informasi tambahan saat membuat file. Sebagian besar harus berfungsi, tetapi bagi sebagian orang, Anda mungkin perlu sedikit memodifikasi URL.File paling rumit mengenai jumlah baris?
Kedengarannya bagus secara teori, tetapi pada kenyataannya ... sesuatu yang diperkecil atau tanpa jeda baris mendistorsi hasil, membuat mereka tidak berarti. Karena itu, saya tidak mempublikasikan hasil perhitungan. Namun, saya membuat sebuah tiket di sccdeteksi dukungan minification adalah untuk menghapusnya dari hasil perhitungan.Anda mungkin dapat menarik beberapa kesimpulan berdasarkan data yang tersedia, tetapi saya ingin semua pengguna mendapat manfaat dari fitur ini scc.Apa file yang paling banyak dikomentari dalam setiap bahasa?
Saya tidak tahu informasi berharga apa yang dapat Anda ambil dari ini, tetapi menarik untuk dilihat.Catatan Beberapa tautan di bawah ini mungkin tidak berfungsi karena beberapa informasi tambahan saat membuat file. Sebagian besar harus berfungsi, tetapi bagi sebagian orang, Anda mungkin perlu sedikit memodifikasi URL.Berapa banyak proyek "bersih"
Di bawah "murni" dalam jenis proyek murni dalam satu bahasa. Tentu saja, ini tidak terlalu menarik dalam dirinya sendiri, jadi mari kita melihat mereka dalam konteksnya. Ternyata, sebagian besar proyek memiliki kurang dari 25 bahasa, dan sebagian besar memiliki kurang dari sepuluh bahasa.Puncak pada grafik di bawah ini dalam empat bahasa.Tentu saja, dalam proyek bersih hanya ada satu bahasa pemrograman, tetapi ada dukungan untuk format lain, seperti penurunan harga, json, yml, css, .gitignore, yang diperhitungkan scc. Mungkin masuk akal untuk mengasumsikan bahwa proyek apa pun dengan kurang dari lima bahasa adalah "bersih" (untuk beberapa tingkat kebersihan), dan ini hanya lebih dari setengah dari total dataset. Tentu saja, definisi kebersihan Anda mungkin berbeda dengan definisi saya, sehingga Anda dapat fokus pada nomor apa pun yang Anda suka.Yang mengejutkan saya adalah gelombang aneh sekitar 34-35 bahasa. Saya tidak punya penjelasan yang masuk akal dari mana asalnya, dan ini mungkin layak untuk penyelidikan terpisah.
Proyek dengan TypeScript tetapi bukan JavaScript
Ah, dunia modern dari TypeScript. Tetapi untuk proyek-proyek TypeScript, berapa banyak yang murni dalam bahasa ini?Harus saya akui, saya sedikit terkejut dengan nomor ini. Meskipun saya mengerti bahwa mencampur JavaScript dengan TypeScript cukup umum, saya akan berpikir akan ada lebih banyak proyek dalam bahasa bermodel baru. Tetapi ada kemungkinan bahwa kumpulan repositori yang lebih baru akan secara dramatis meningkatkan jumlahnya.Adakah yang menggunakan CoffeeScript dan TypeScript?
Saya merasa seperti beberapa pengembang TypeScript sakit karena memikirkannya. Jika ini membantu mereka, saya dapat berasumsi bahwa sebagian besar proyek ini adalah program seperti sccdengan contoh dari semua bahasa untuk tujuan pengujian.Berapakah panjang jalur tipikal dalam setiap bahasa
Mengingat Anda dapat mengunggah semua file yang Anda butuhkan ke satu direktori atau membuat sistem direktori, berapakah panjang jalur tipikal dan jumlah direktori?Untuk melakukan ini, hitung jumlah garis miring di jalur untuk setiap file dan rata-rata. Saya tidak tahu apa yang diharapkan di sini, kecuali bahwa Java bisa menjadi yang teratas dalam daftar, karena biasanya ada jalur file yang panjang.YAML atau YML?
Pernah ada "diskusi" di Slack - menggunakan .yaml atau .yml. Banyak yang terbunuh di sana di kedua sisi.Debat akhirnya dapat (?) Berakhir. Meskipun saya curiga ada yang masih lebih suka mati dalam pertikaian.Wadah atas, bawah, atau campuran?
Daftar apa yang digunakan untuk nama file? Karena masih ada perpanjangan, kita bisa berharap, terutama, kasus campuran.Yang, tentu saja, tidak terlalu menarik, karena biasanya ekstensi file lebih kecil. Bagaimana jika mengabaikan ekstensi?Bukan yang saya harapkan. Sekali lagi, sebagian besar campuran, tetapi saya akan berpikir bahwa bagian bawah akan lebih populer.Pabrik di Jawa
Gagasan lain yang muncul dari kolega ketika melihat beberapa kode Java lama. Saya pikir, mengapa tidak menambahkan cek untuk kode Java apa pun di mana Factory, FactoryFactory, atau FactoryFactoryFactory muncul dalam judul. Idenya adalah memperkirakan jumlah pabrik semacam itu.Jadi, hanya 2% dari kode Java yang berubah menjadi pabrik atau pabrik. Untungnya, tidak ada pabrik pabrik yang ditemukan. Mungkin lelucon ini akhirnya akan mati, meskipun saya yakin bahwa setidaknya satu multi-rekursif tingkat ketiga yang serius masih bekerja di suatu tempat di semacam Java 5 monolith, dan itu menghasilkan lebih banyak uang setiap hari daripada yang saya lihat dalam seluruh karier saya. .File .Ignore
Ide file .ignore dikembangkan oleh burntsushi dan ggreer dalam sebuah diskusi di Hacker News . Mungkin ini adalah salah satu contoh terbaik dari alat open source "bersaing" yang bekerja bersama dengan hasil yang baik dan diselesaikan dalam waktu singkat. Ini telah menjadi standar de facto untuk menambahkan kode yang akan diabaikan alat. sccjuga memenuhi aturan .ignore, tetapi juga tahu bagaimana cara menghitungnya. Mari kita lihat seberapa baik ide itu menyebar.Gagasan untuk masa depan
Saya suka melakukan beberapa analisis untuk masa depan. Akan menyenangkan untuk memindai hal-hal seperti kunci AWS AKIA dan sejenisnya. Saya juga ingin memperluas cakupan proyek Bitbucket dan Gitlab dengan analisis untuk masing-masing, untuk melihat apakah mungkin ada tim pengembangan dari berbagai bidang yang tergantung di sana.Jika saya pernah mengulangi proyek, saya ingin mengatasi kekurangan berikut dan mempertimbangkan ide-ide berikut.- Simpan URL di suatu tempat di metadata dengan benar. Menggunakan nama file untuk menyimpannya adalah ide yang buruk, karena informasi hilang dan sulit untuk menentukan sumber dan lokasi file.
- Jangan repot-repot dengan S3. Tidak masuk akal untuk membayar lalu lintas jika saya menggunakannya hanya untuk penyimpanan. Lebih baik dari awal untuk memalu semuanya menjadi file tar.
- , .
- -n , , , .
- scc, , . , CIDE.C C, , HTML. .
- , scc, , , . .
- Saya ingin menambahkan deteksi shebang ke scc .
- Entah bagaimana mempertimbangkan jumlah bintang di Github dan jumlah komitmen.
- Saya ingin menambahkan perhitungan indeks rawatan. Akan sangat bagus untuk melihat proyek mana yang dianggap paling dapat diperbaiki tergantung pada ukurannya.
Kenapa ini semua?
Yah, saya dapat mengambil beberapa informasi ini dan menggunakannya di mesin pencari dan program searchcode.com saya scc. Setidaknya beberapa titik data berguna. Awalnya, proyek ini disusun dalam banyak hal demi ini. Selain itu, sangat berguna untuk membandingkan proyek Anda dengan orang lain. Itu juga cara yang menarik untuk menghabiskan beberapa hari menyelesaikan beberapa masalah menarik. Dan pemeriksaan reliabilitas yang baik untuk scc.Selain itu, saat ini saya sedang mengerjakan alat yang membantu pengembang atau manajer terkemuka menganalisis kode, mencari bahasa tertentu, file besar, cacat, dll ... dengan asumsi bahwa Anda perlu menganalisis beberapa repositori. Anda memasukkan beberapa jenis kode, dan alat tersebut mengatakan betapa dapat dipertahankannya dan keterampilan apa yang diperlukan untuk memeliharanya. Ini berguna ketika memutuskan apakah akan membeli semacam basis kode, untuk melayaninya, atau untuk mendapatkan ide tentang produk Anda sendiri yang diberikan oleh tim pengembangan. Secara teoritis, ini harus membantu tim skala melalui sumber daya bersama. Sesuatu seperti AWS Macie, tetapi untuk kode - sesuatu seperti ini yang sedang saya kerjakan. Saya sendiri membutuhkan ini untuk pekerjaan sehari-hari, dan saya curiga orang lain mungkin menemukan aplikasi untuk instrumen semacam itu, setidaknya itulah teorinya.Mungkin ada baiknya mendaftar di sini beberapa bentuk pendaftaran untuk mereka yang tertarik ...File yang belum diproses / diproses
Jika seseorang ingin membuat analisis sendiri dan melakukan koreksi, berikut adalah tautan ke file yang diproses (20 MB). Jika seseorang ingin memposting file mentah di domain publik, beri tahu saya. Ini adalah 83 GB tar.gz, dan di dalamnya lebih dari 1 TB. Konten terdiri dari lebih dari 9 juta file JSON dengan berbagai ukuran.UPD
Beberapa jiwa baik menyarankan untuk meletakkan file, tempat-tempat ditunjukkan di bawah ini:Dengan hosting file tar.gz ini, terima kasih kepada CNCF untuk server untuk xet7 dari proyek Wekan .