Zabbix adalah sistem pemantauan. Seperti sistem lainnya, sistem ini menghadapi tiga masalah utama dari semua sistem pemantauan: pengumpulan dan pemrosesan data, penyimpanan riwayat, dan pembersihannya.
Langkah-langkah untuk memperoleh, memproses, dan merekam data membutuhkan waktu. Tidak banyak, tetapi untuk sistem yang besar ini dapat menghasilkan penundaan yang besar. Masalah penyimpanan adalah masalah akses data. Mereka digunakan untuk laporan, cek, dan pemicu. Keterlambatan mengakses data juga memengaruhi kinerja. Ketika basis data tumbuh, data yang tidak relevan harus dihapus. Penghapusan adalah operasi yang sulit yang juga memakan beberapa sumber daya.

Masalah keterlambatan saat pengumpulan dan penyimpanan di Zabbix diselesaikan dengan caching: beberapa jenis cache, caching dalam database. Untuk mengatasi masalah ketiga, caching tidak cocok, oleh karena itu, Zabbix menggunakan TimescaleDB.
Andrey Gushchin , insinyur dukungan teknis di
Zabbix SIA, akan membicarakan hal ini. Andrey telah mendukung Zabbix selama lebih dari 6 tahun dan secara langsung menghadapi kinerja.
Bagaimana cara kerja TimescaleDB, kinerja apa yang dapat diberikannya dibandingkan dengan PostgreSQL biasa? Apa peran yang dimainkan Zabbix di TimescaleDB? Bagaimana menjalankan dari awal dan bagaimana bermigrasi dengan PostgreSQL dan kinerja mana yang lebih baik? Tentang semua ini di bawah potongan.
Tantangan kinerja
Setiap sistem pemantauan menghadapi tantangan kinerja spesifik. Saya akan berbicara tentang mereka bertiga: mengumpulkan dan memproses data, menyimpan, membersihkan riwayat.
Pengumpulan dan pemrosesan data yang cepat. Sistem pemantauan yang baik harus dengan cepat menerima semua data dan memprosesnya sesuai dengan pemicu ekspresi - sesuai dengan kriteria sendiri. Setelah diproses, sistem juga harus dengan cepat menyimpan data ini ke database untuk menggunakannya nanti.
Menyimpan cerita. Sistem pemantauan yang baik harus menyimpan riwayat dalam basis data dan menyediakan akses mudah ke metrik. Diperlukan sebuah cerita untuk menggunakannya dalam laporan, grafik, pemicu, ambang batas, dan item data yang dihitung untuk peringatan.
Bersihkan riwayat. Terkadang sehari tiba ketika Anda tidak perlu menyimpan metrik. Mengapa Anda memerlukan data yang dikumpulkan 5 tahun yang lalu, satu atau dua bulan: beberapa node dihapus, beberapa host atau metrik tidak lagi diperlukan, karena mereka sudah usang dan berhenti mengumpulkan. Sistem pemantauan yang baik harus menyimpan data historis dan menghapusnya dari waktu ke waktu sehingga basis data tidak bertambah.
Menghapus data yang sudah usang adalah masalah panas yang berdampak besar pada kinerja database.
Caching Zabbix
Di Zabbix, panggilan pertama dan kedua diselesaikan menggunakan caching. RAM digunakan untuk pengumpulan dan pemrosesan data. Untuk penyimpanan - cerita dalam pemicu, grafik, dan elemen data yang dihitung. Di sisi database, ada caching tertentu untuk sampel utama, misalnya, bagan.
Caching di sisi server Zabbix itu sendiri adalah:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Mari kita pertimbangkan secara lebih detail.
ConfigurationCache
Ini adalah cache utama tempat kami menyimpan metrik, host, item data, pemicu - semua yang diperlukan untuk PreProcessing dan untuk mengumpulkan data.
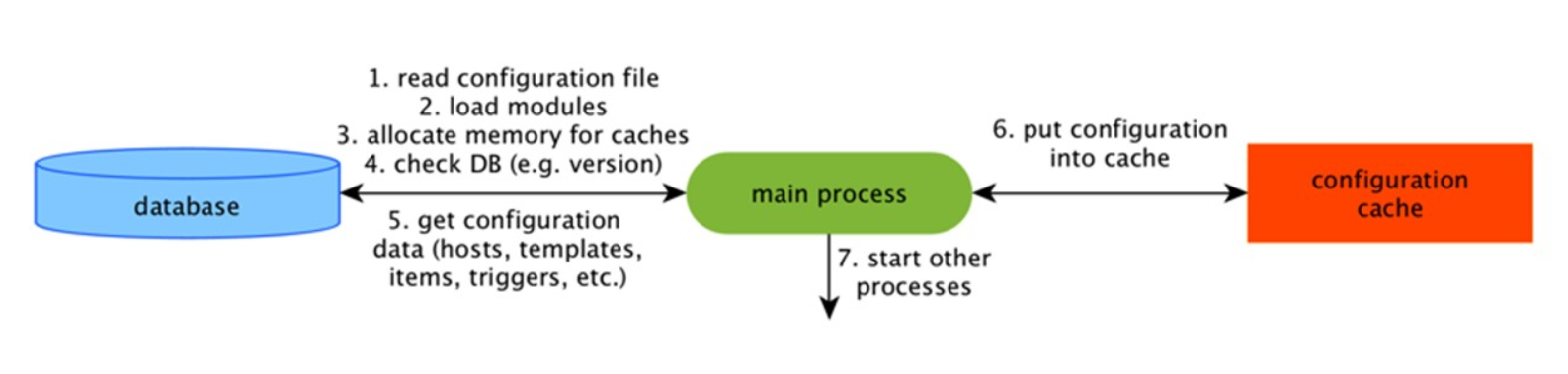
Semua ini disimpan dalam ConfigurationCache agar tidak membuat pertanyaan yang tidak perlu dalam database. Setelah server dimulai, kami memperbarui cache ini, membuat dan memperbarui konfigurasi secara berkala.
Pengumpulan data
Skema ini cukup besar, tetapi hal utama di dalamnya adalah
perakit . Ini adalah berbagai "poller" - proses perakitan. Mereka bertanggung jawab untuk berbagai jenis perakitan: mereka mengumpulkan data melalui SNMP, IPMI, dan mentransfer semuanya ke PreProcessing.
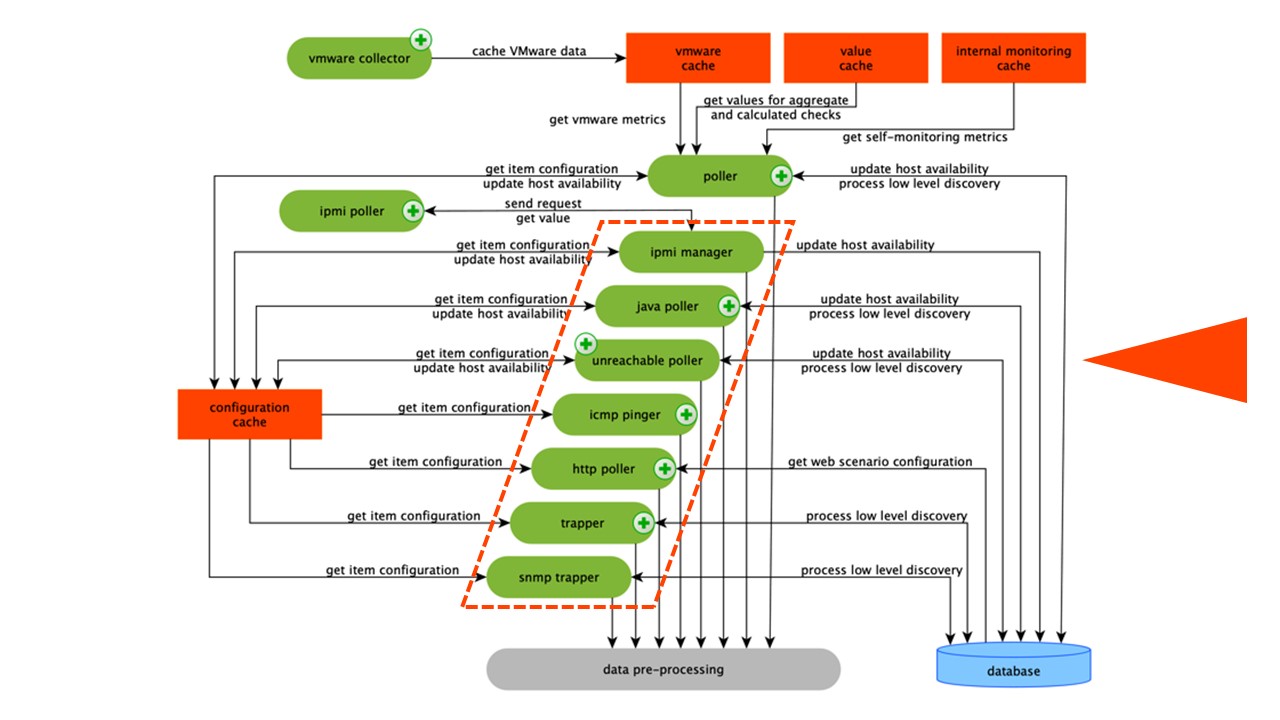 Kolektor dilingkari oranye.
Kolektor dilingkari oranye.Zabbix telah menghitung elemen data agregasi yang diperlukan untuk mengagregasi validasi. Jika kami memilikinya, kami mengambil datanya langsung dari ValueCache.
PreCiproses HistoryCache
Semua kolektor menggunakan ConfigurationCache untuk menerima pekerjaan. Kemudian mereka meneruskannya ke PreProcessing.

PreProcessing menggunakan ConfigurationCache untuk menerima langkah-langkah PreProcessing. Ini memproses data ini dengan berbagai cara.
Setelah memproses data menggunakan PreProcessing, kami menyimpannya di HistoryCache untuk memprosesnya. Ini mengakhiri pengumpulan data dan kami beralih ke proses utama di Zabbix -
syncer sejarah , karena ini adalah arsitektur monolitik.
Catatan: PreProcessing adalah operasi yang cukup sulit. Sejak v 4.2, ini telah diserahkan ke proksi. Jika Anda memiliki Zabbix yang sangat besar dengan sejumlah besar elemen data dan frekuensi pengumpulan, ini sangat memudahkan pekerjaan.ValueCache, riwayat & tren cache
Syncer sejarah adalah proses utama yang secara atomis memproses setiap elemen data, yaitu setiap nilai.
Syncer histori mengambil nilai dari HistoryCache dan memeriksa di Konfigurasi untuk pemicu perhitungan. Jika ya, itu menghitung.
Syncer sejarah membuat acara, peningkatan untuk membuat peringatan, jika diperlukan oleh konfigurasi, dan catatan. Jika ada pemicu untuk pemrosesan selanjutnya, maka ia mengingat nilai ini di ValueCache agar tidak mengakses tabel riwayat. Jadi ValueCache diisi dengan data yang diperlukan untuk menghitung pemicu, elemen yang dihitung.
Syncer sejarah menulis semua data ke database, dan itu ditulis ke disk. Proses pemrosesan berakhir di sini.
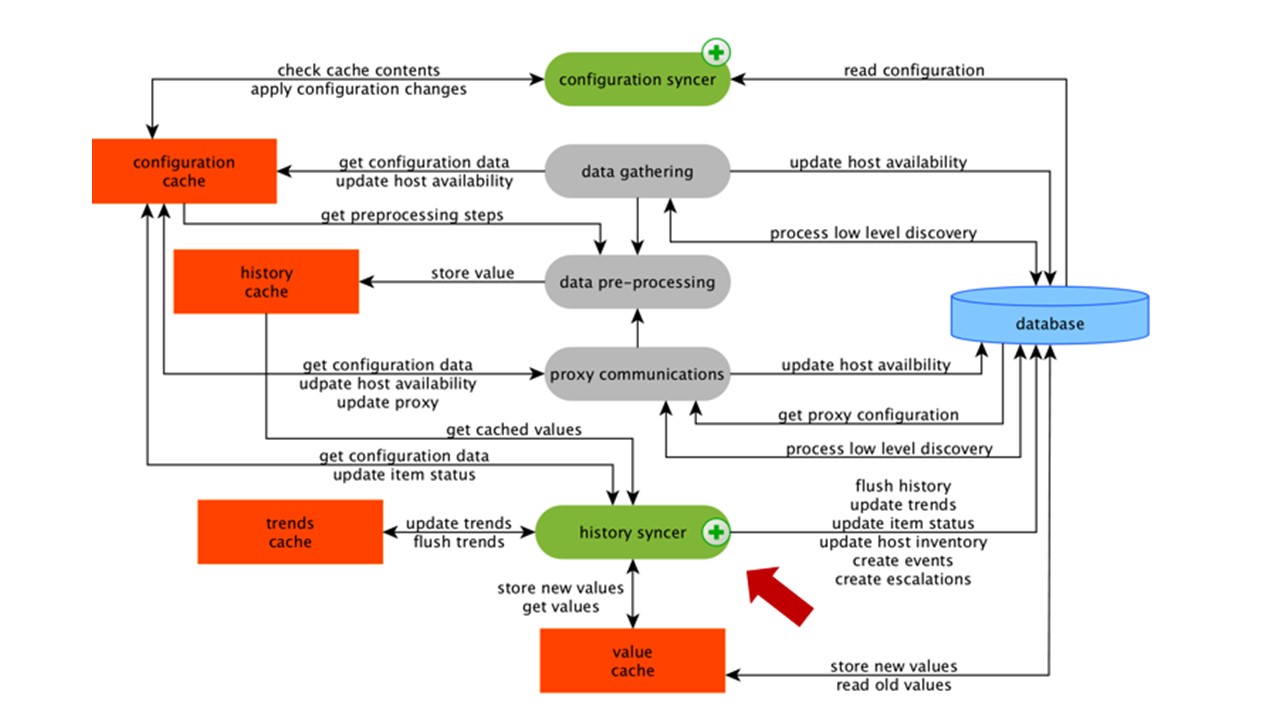
Caching DB
Di sisi DB, ada berbagai cache ketika Anda ingin menonton grafik atau laporan acara:
Innodb_buffer_pool di sisi MySQL;shared_buffers di sisi PostgreSQL;effective_cache_size di sisi Oracle;shared_pool di sisi DB2.
Ada banyak cache lainnya, tetapi ini adalah yang utama untuk semua database. Mereka memungkinkan Anda untuk menyimpan dalam memori data yang sering dibutuhkan untuk permintaan. Mereka memiliki teknologi sendiri untuk ini.
Kinerja basis data sangat penting
Zabbix-server terus-menerus mengumpulkan data dan menulisnya. Saat memulai ulang, itu juga membaca dari riwayat untuk mengisi ValueCache. Skrip dan laporan menggunakan
Zabbix API , yang dibangun berdasarkan antarmuka Web. Zabbix API menghubungi basis data dan menerima data yang diperlukan untuk grafik, laporan, daftar acara, dan masalah terkini.
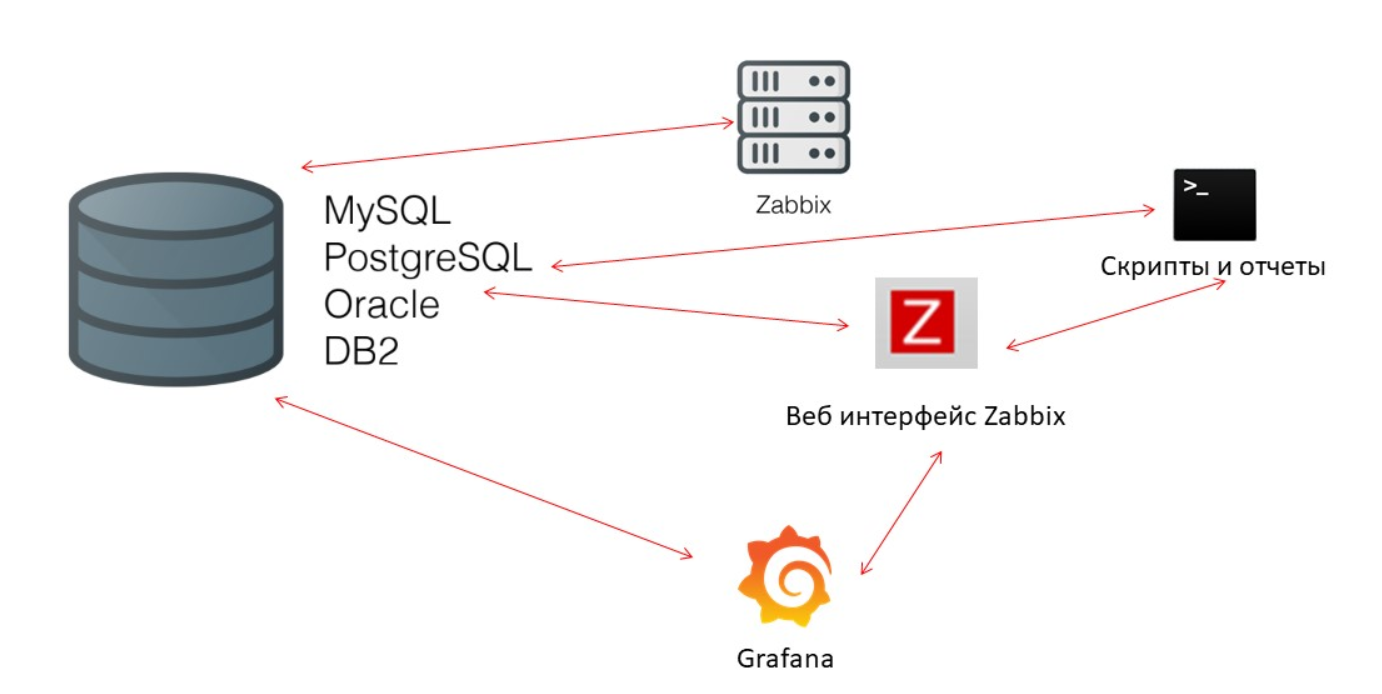
Untuk visualisasi -
Grafana . Di antara pengguna kami, ini adalah solusi populer. Itu dapat langsung mengirim permintaan melalui Zabbix API dan ke database, dan menciptakan daya saing tertentu untuk menerima data. Oleh karena itu, kita memerlukan penyempurnaan basis data yang lebih baik dan lebih baik agar sesuai dengan hasil dan pengujian yang cepat.
Pengurus rumah tangga
Tantangan kinerja ketiga di Zabbix adalah membersihkan sejarah dengan Housekeeper. Ini mengikuti semua pengaturan - elemen data menunjukkan berapa banyak untuk menjaga dinamika perubahan (tren) dalam beberapa hari.
Kami menghitung TrendsCache dengan cepat. Ketika data tiba, kami mengumpulkannya dalam satu jam dan menuliskannya dalam tabel untuk dinamika perubahan tren.
Pengurus rumah memulai dan menghapus informasi dari database dengan "select" yang biasa. Ini tidak selalu efektif, yang dapat dipahami dari grafik kinerja proses internal.
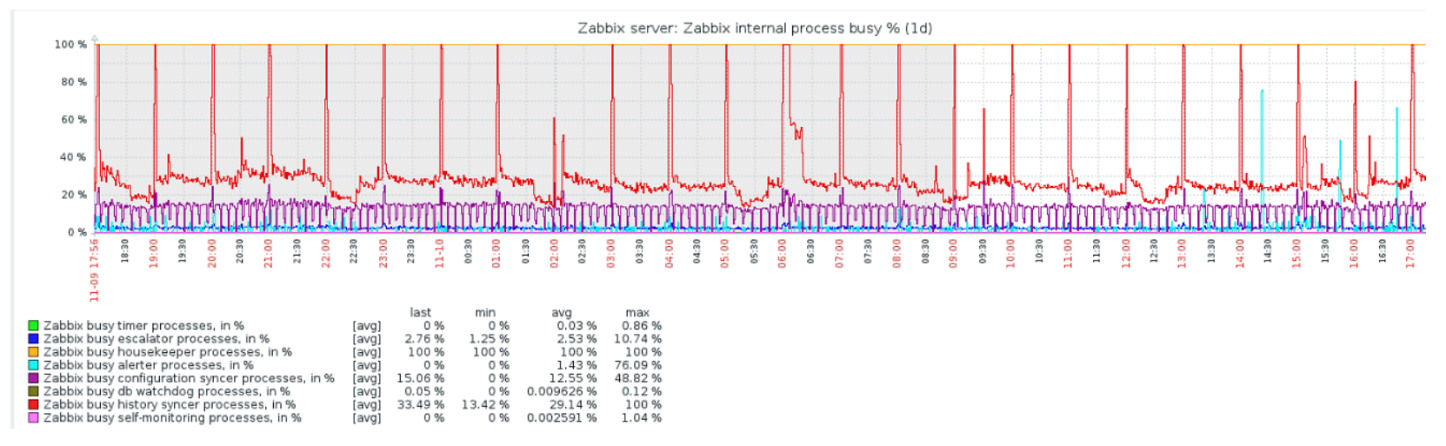
Grafik merah menunjukkan bahwa penyelia Sejarah terus-menerus sibuk. Grafik oranye di atas adalah Housekeeper, yang terus berjalan. Dia mengharapkan database untuk menghapus semua baris yang dia tentukan.
Kapan mematikan Housekeeper? Misalnya, ada "Item ID" dan Anda perlu menghapus 5 ribu baris terakhir dalam waktu tertentu. Tentu saja, ini terjadi dengan indeks. Tetapi biasanya dataset sangat besar, dan database masih membaca dari disk dan menaikkannya ke cache. Ini selalu merupakan operasi yang sangat mahal untuk database dan, tergantung pada ukuran database, dapat menyebabkan masalah kinerja.
Pengurus rumah tangga hanya putuskan. Di antarmuka Web ada pengaturan di "Administrasi umum" untuk Pengurus Rumah Tangga. Nonaktifkan housekeeping internal untuk sejarah tren internal dan tidak lagi mengelola ini.
Pengurus rumah tangga dimatikan, grafik diratakan - apa yang bisa menjadi masalah dalam kasus ini, dan apa yang bisa membantu dalam menyelesaikan panggilan kinerja ketiga?
Partisi - mempartisi atau mempartisi
Biasanya, partisi dikonfigurasi dengan cara yang berbeda pada setiap basis data relasional yang telah saya daftarkan. Masing-masing memiliki teknologinya sendiri, tetapi mereka serupa, secara umum. Membuat partisi baru sering menyebabkan masalah tertentu.
Partisi biasanya dikonfigurasi tergantung pada "pengaturan" - jumlah data yang dibuat dalam satu hari. Sebagai aturan, Partisi terbuka dalam satu hari, ini adalah minimum. Untuk tren partisi baru - selama 1 bulan.
Nilai dapat berubah jika "pengaturan" sangat besar. Jika "pengaturan" kecil hingga 5.000 nvps (nilai baru per detik), rata-rata dari 5.000 hingga 25.000, maka besar di atas 25.000 nvps. Ini adalah instalasi besar dan sangat besar yang membutuhkan konfigurasi database yang cermat.
Pada instalasi yang sangat besar, proses satu hari mungkin tidak optimal. Saya melihat partisi MySQL sebesar 40 GB atau lebih per hari. Ini adalah jumlah data yang sangat besar yang dapat menyebabkan masalah, dan ini perlu dikurangi.
Apa yang memberi Partisi?
Tabel partisi . Seringkali ini adalah file yang terpisah pada disk. Rencana kueri lebih optimal memilih satu partisi. Partisi biasanya digunakan dalam rentang - untuk Zabbix ini juga benar. Kami menggunakan "timestamp" di sana - waktu dari awal era. Kami memiliki nomor biasa. Anda mengatur awal dan akhir hari - ini adalah partisi.
Hapus cepat -
DELETE . Satu file / subtable dipilih, bukan pilihan baris untuk dihapus.
Tampak mempercepat pengambilan data SELECT - menggunakan satu atau lebih partisi, bukan seluruh tabel. Jika Anda meminta data dua hari lalu, mereka dipilih dari database lebih cepat karena Anda perlu memuat ke dalam cache dan mengeluarkan hanya satu file, bukan tabel besar.
Seringkali, banyak basis data juga mempercepat sisipan
INSERT ke dalam tabel anak.
Timescaledb
Untuk v 4.2, kami mengalihkan perhatian kami ke TimescaleDB. Ini adalah ekstensi untuk PostgreSQL dengan antarmuka asli. Ekstensi bekerja secara efektif dengan data deret waktu, tanpa kehilangan manfaat dari basis data relasional. TimescaleDB juga secara otomatis partisi.
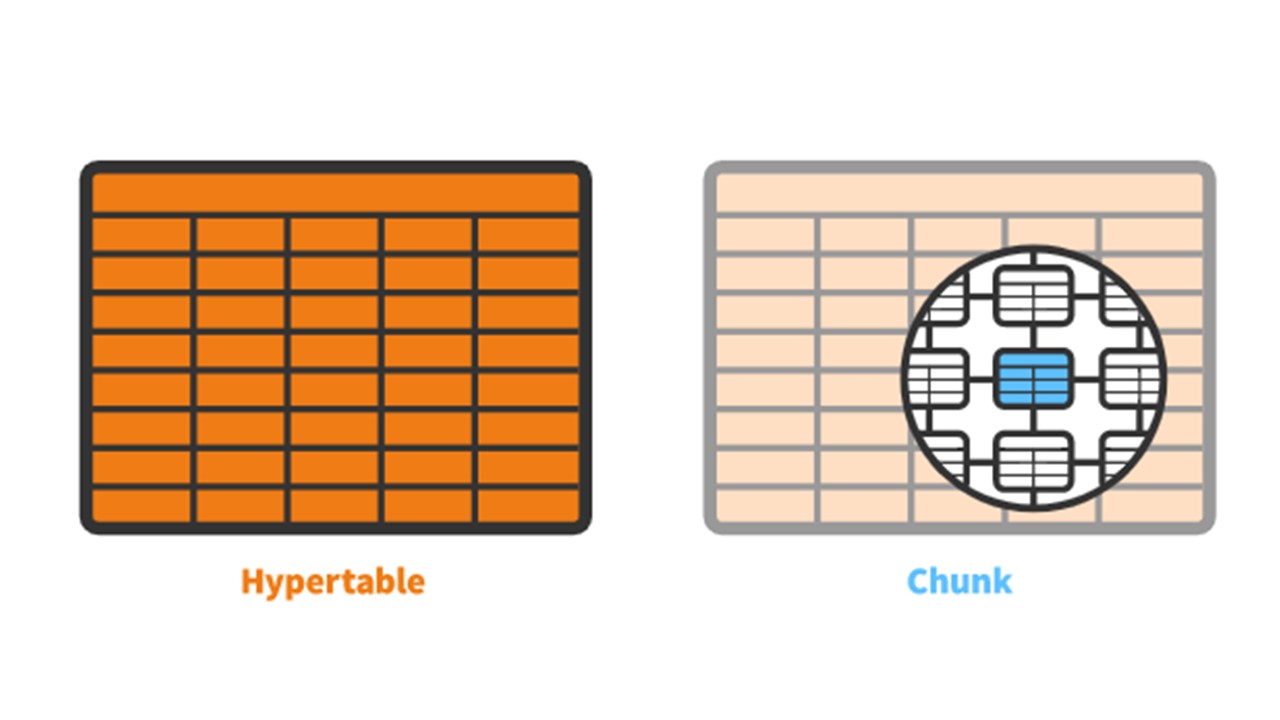
TimescaleDB memiliki konsep
hipertensi yang Anda buat. Ini berisi
potongan - partisi. Bongkahan secara otomatis dikendalikan fragmen hipertensi yang tidak mempengaruhi fragmen lainnya. Setiap chunk memiliki rentang waktunya sendiri.
TimescaleDB vs PostgreSQL
TimescaleDB bekerja sangat efisien. Pembuat ekstensi mengklaim bahwa mereka menggunakan algoritma pemrosesan permintaan yang lebih benar, khususnya, <code> sisipan </code>. Ketika dimensi sisipan dataset bertambah, algoritma mempertahankan kinerja konstan.
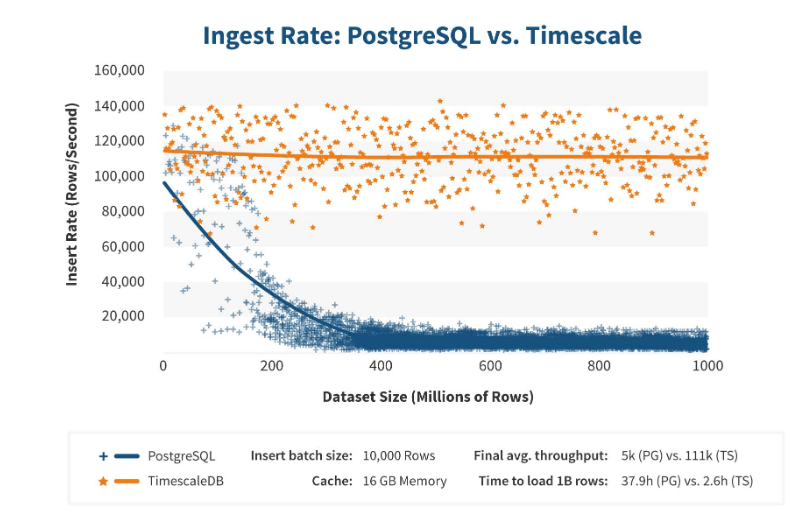
Setelah 200 juta baris, PostgreSQL biasanya mulai sangat melorot dan kehilangan kinerja hingga 0. TimescaleDB memungkinkan Anda untuk secara efisien memasukkan "sisipan" untuk sejumlah data.
Instalasi
Menginstal TimescaleDB cukup mudah untuk semua paket.
Dokumentasi menjelaskan semuanya secara rinci - itu tergantung pada paket-paket resmi PostgreSQL. TimescaleDB juga dapat dikompilasi dan dikompilasi secara manual.
Untuk basis data Zabbix, kami cukup mengaktifkan ekstensi:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
Anda mengaktifkan
extension dan membuatnya untuk basis data Zabbix. Langkah terakhir adalah membuat hipertensi.
Migrasi tabel histori ke TimescaleDB
Ada fungsi khusus
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
Fungsi ini memiliki tiga parameter. Yang pertama adalah
tabel dalam database yang Anda butuhkan untuk membuat hipertensi. Yang kedua adalah
bidang yang digunakan untuk membuat
chunk_time_interval - interval potongan partisi yang ingin Anda gunakan. Dalam kasus saya, intervalnya satu hari - 86.400.
Parameter ketiga adalah
migrate_data . Jika disetel ke
true , maka semua data saat ini ditransfer ke potongan yang dibuat sebelumnya. Saya sendiri menggunakan
migrate_data . Saya memiliki sekitar 1 TB, yang membutuhkan waktu lebih dari satu jam. Bahkan dalam beberapa kasus, saat pengujian, saya menghapus data historis tipe karakter yang opsional untuk penyimpanan, agar tidak mentransfernya.
Langkah terakhir adalah
UPDATE : kami menetapkan
timescaledb di
db_extension sehingga database memahami bahwa ada ekstensi ini. Zabbix mengaktifkannya dan sudah menggunakan sintaks dan query dengan benar ke database - fitur-fitur yang diperlukan untuk TimescaleDB.
Konfigurasi besi
Saya menggunakan dua server. Yang pertama adalah
mesin VMware . Cukup kecil: 20 Prosesor Intel® Xeon® E5-2630 v 4 @ 2.20GHz, RAM 16 GB, dan SSD 200 GB.
Saya menginstal PostgreSQL 10.8 di atasnya dengan Debian 10.8-1.pgdg90 +1 dan sistem file xfs. Saya mengkonfigurasi semuanya secara minimal untuk menggunakan database khusus ini, minus apa yang akan digunakan Zabbix sendiri.
Pada mesin yang sama adalah server Zabbix, PostgreSQL, dan
agen beban . Saya memiliki 50 agen aktif yang menggunakan
LoadableModule untuk dengan sangat cepat menghasilkan berbagai hasil: angka, string. Saya menyumbat database dengan banyak data.
Awalnya, konfigurasi berisi
5.000 item data per host. Hampir setiap elemen mengandung pemicu, sehingga mirip dengan instalasi nyata. Dalam beberapa kasus, ada lebih dari satu pemicu. Ada
3.000-7.000 pemicu per node jaringan.
Interval untuk memperbarui item data adalah
4-7 detik . Saya mengatur beban itu sendiri dengan menggunakan tidak hanya 50 agen, tetapi juga menambahkan lebih banyak. Juga, dengan bantuan elemen data, saya menyesuaikan beban secara dinamis dan mengurangi interval pembaruan menjadi 4 detik.
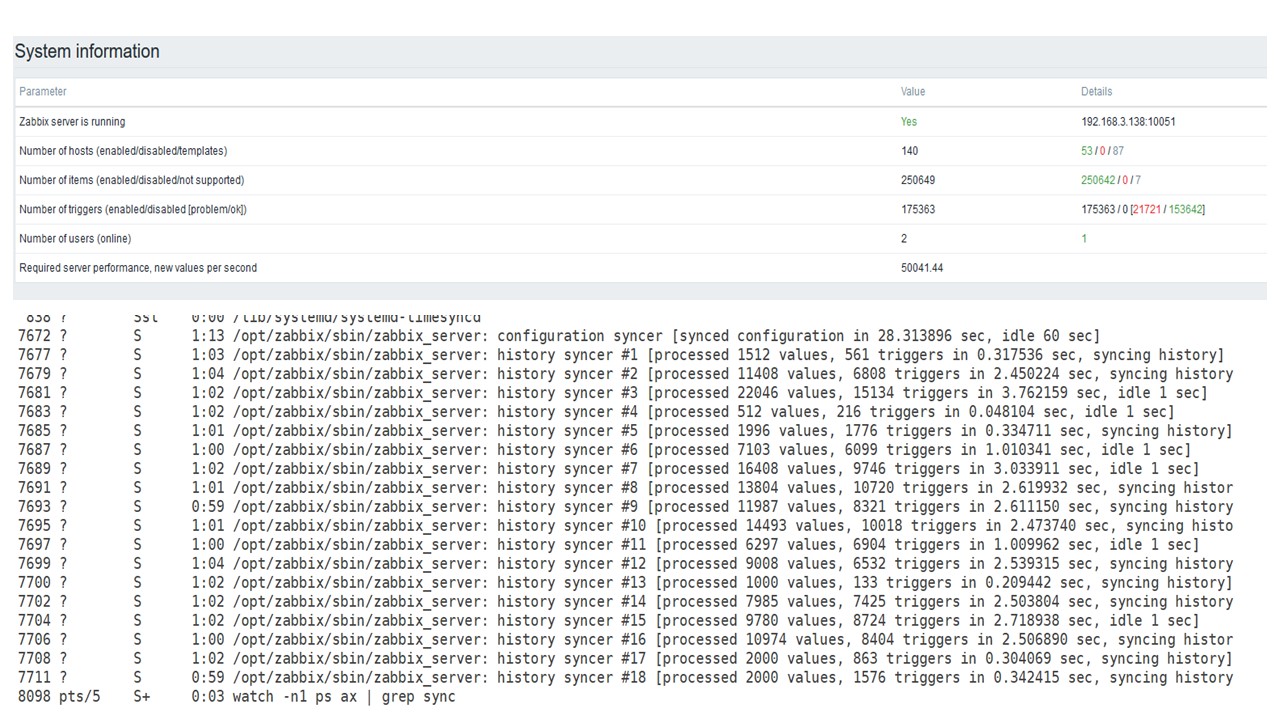
PostgreSQL 35.000 nvps
Jalankan pertama pada perangkat keras ini saya miliki di PostgreSQL murni - 35 ribu nilai per detik. Seperti yang Anda lihat, memasukkan data membutuhkan sepersekian detik - semuanya baik dan cepat. Satu-satunya hal yang mengisi 200 GB SSD dengan cepat.
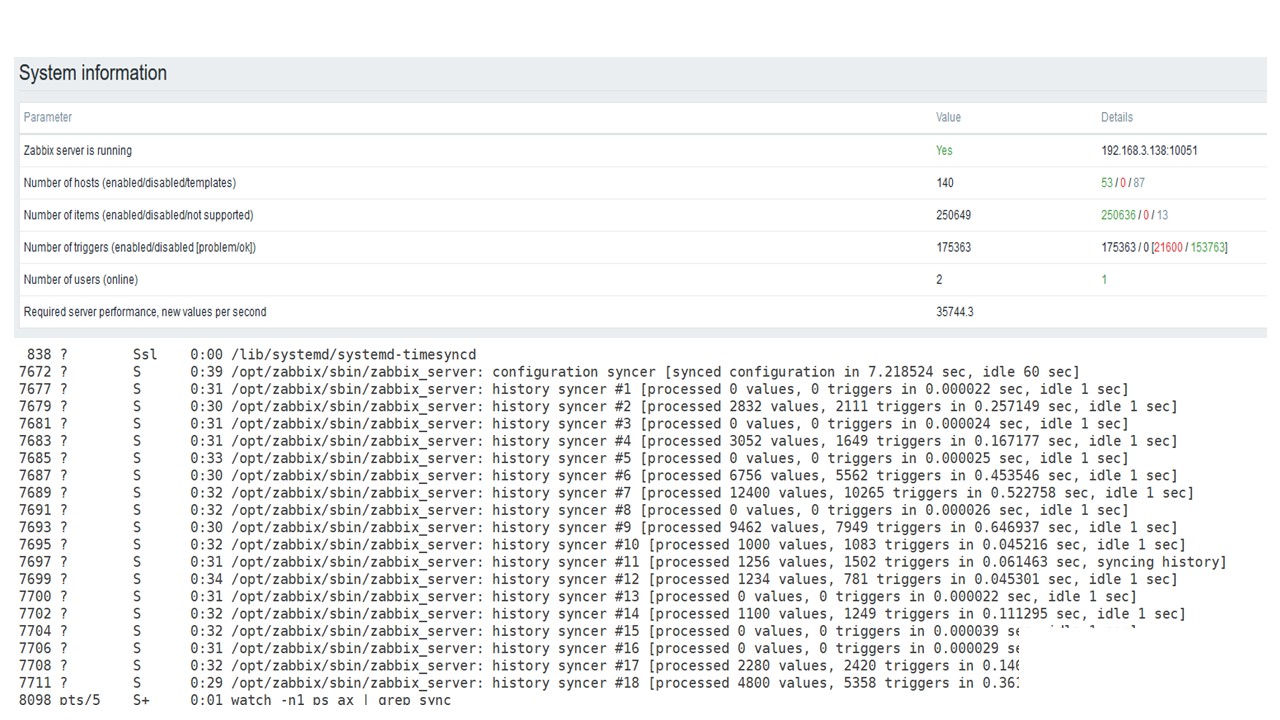
Ini adalah dasbor kinerja server standar Zabbix.
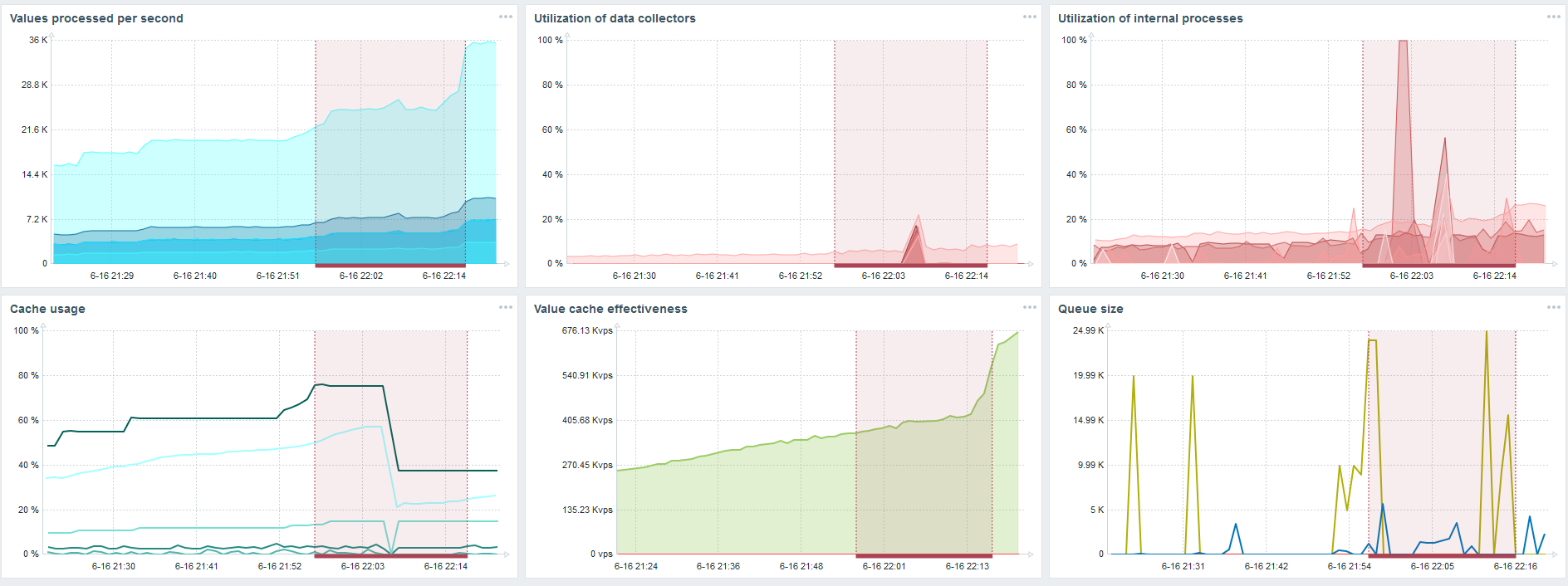
Grafik biru pertama adalah jumlah nilai per detik. Grafik kedua di sebelah kanan adalah pemuatan proses perakitan. Yang ketiga adalah memuat proses perakitan internal: sinkronisasi riwayat dan Housekeeper, yang telah berjalan cukup lama di sini.
Grafik keempat menunjukkan penggunaan HistoryCache. Ini adalah buffer sebelum memasukkan ke dalam database. Grafik hijau kelima menunjukkan penggunaan ValueCache, yaitu, berapa banyak hit ValueCache untuk pemicu beberapa ribu nilai per detik.
PostgreSQL 50.000 nvps
Lalu saya menambah beban menjadi 50 ribu nilai per detik pada perangkat keras yang sama.
Saat memuat dari Housekeeper, sisipan 10 ribu nilai dicatat selama 2-3 detik.
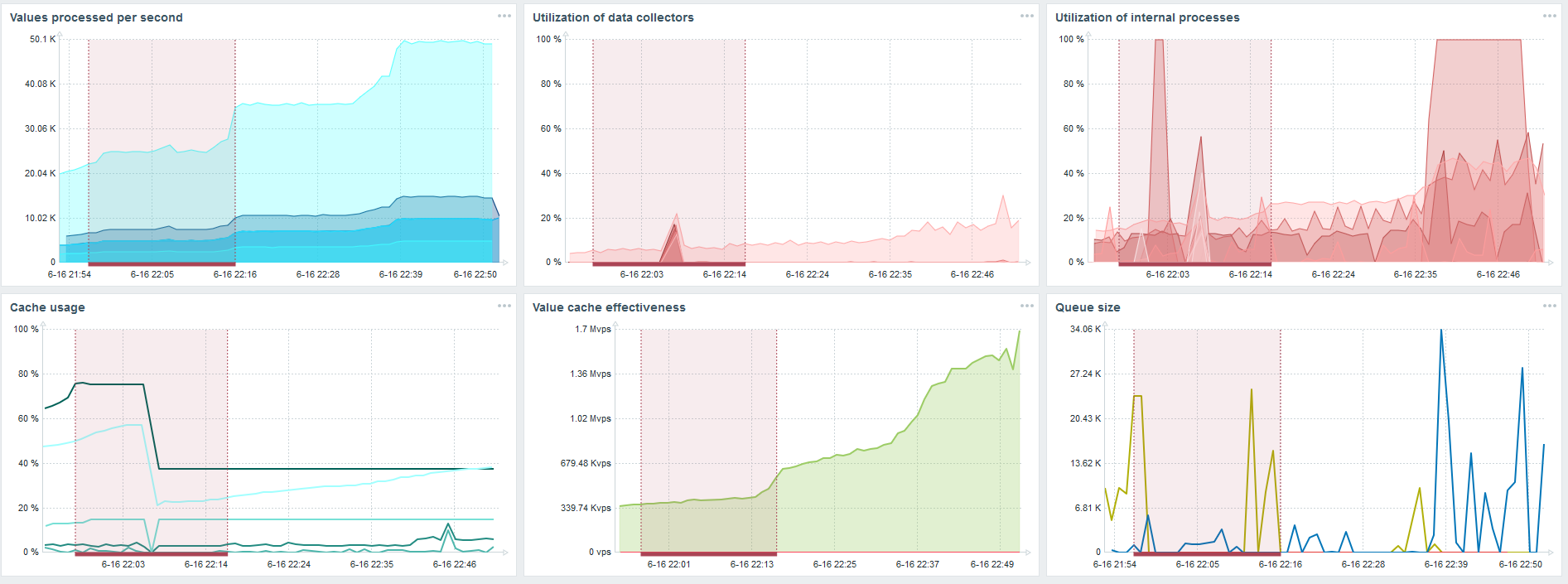 Pengurus rumah tangga sudah mulai menghalangi.
Pengurus rumah tangga sudah mulai menghalangi.Grafik ketiga menunjukkan bahwa, secara umum, memuat penjerat dan penyelarasan riwayat masih di 60%. Pada bagan keempat, HistoryCache sudah mulai terisi cukup aktif selama pekerjaan Housekeeper. Ini 20% penuh - sekitar 0,5 GB.
PostgreSQL 80.000 nvps
Lalu saya menambah beban menjadi 80 ribu nilai per detik. Ini adalah sekitar 400 ribu elemen data dan 280 ribu pemicu.
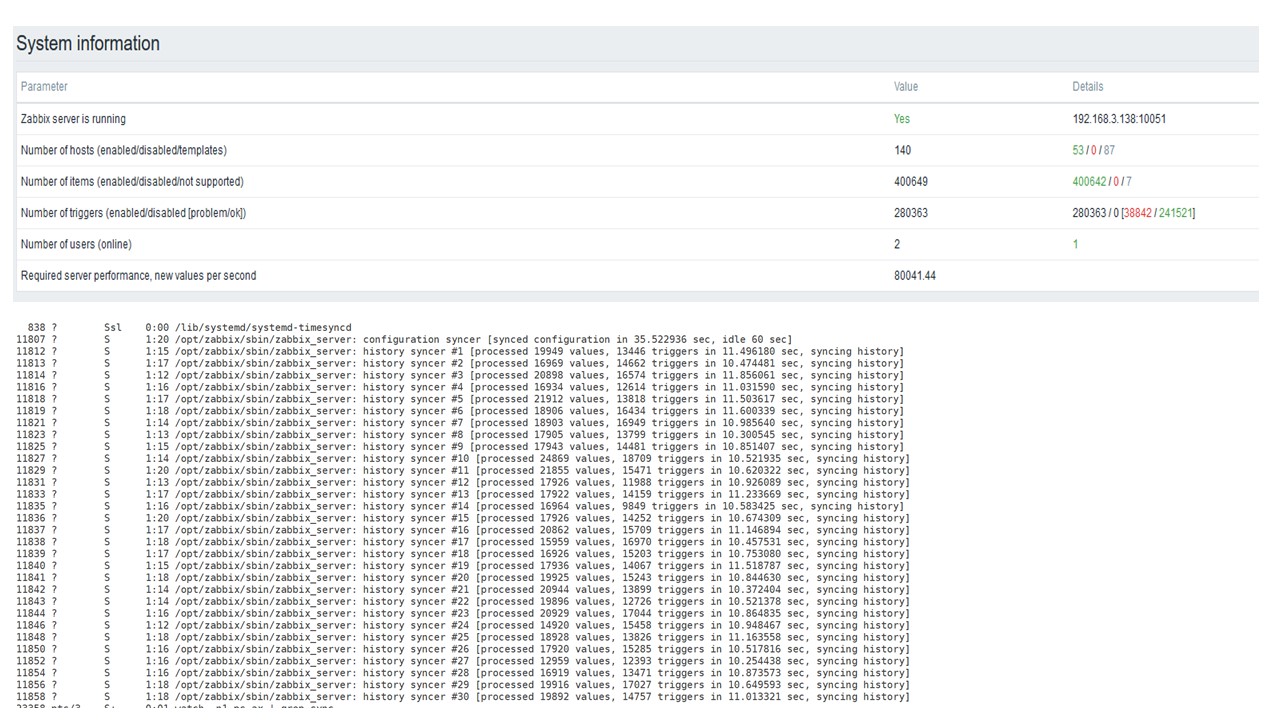 Sisipan untuk memuat tiga puluh sinkronisasi riwayat sudah cukup tinggi.
Sisipan untuk memuat tiga puluh sinkronisasi riwayat sudah cukup tinggi.Saya juga meningkatkan berbagai parameter: sinkronisasi riwayat, cache.
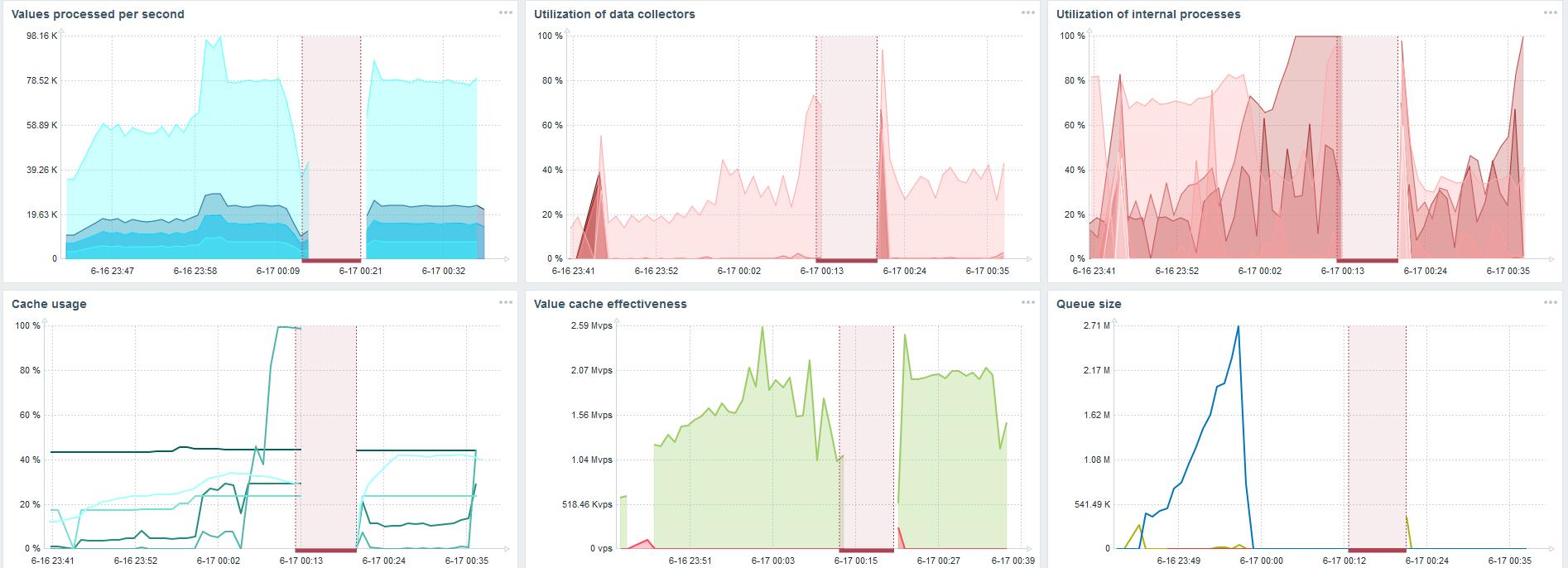
Di perangkat keras saya, beban sinkronisasi riwayat meningkat secara maksimal. HistoryCache dengan cepat diisi dengan data - data untuk diproses terakumulasi dalam buffer.
Selama ini saya mengamati bagaimana prosesor, RAM dan parameter sistem lainnya digunakan, dan menemukan bahwa pemanfaatan disk dimaksimalkan.
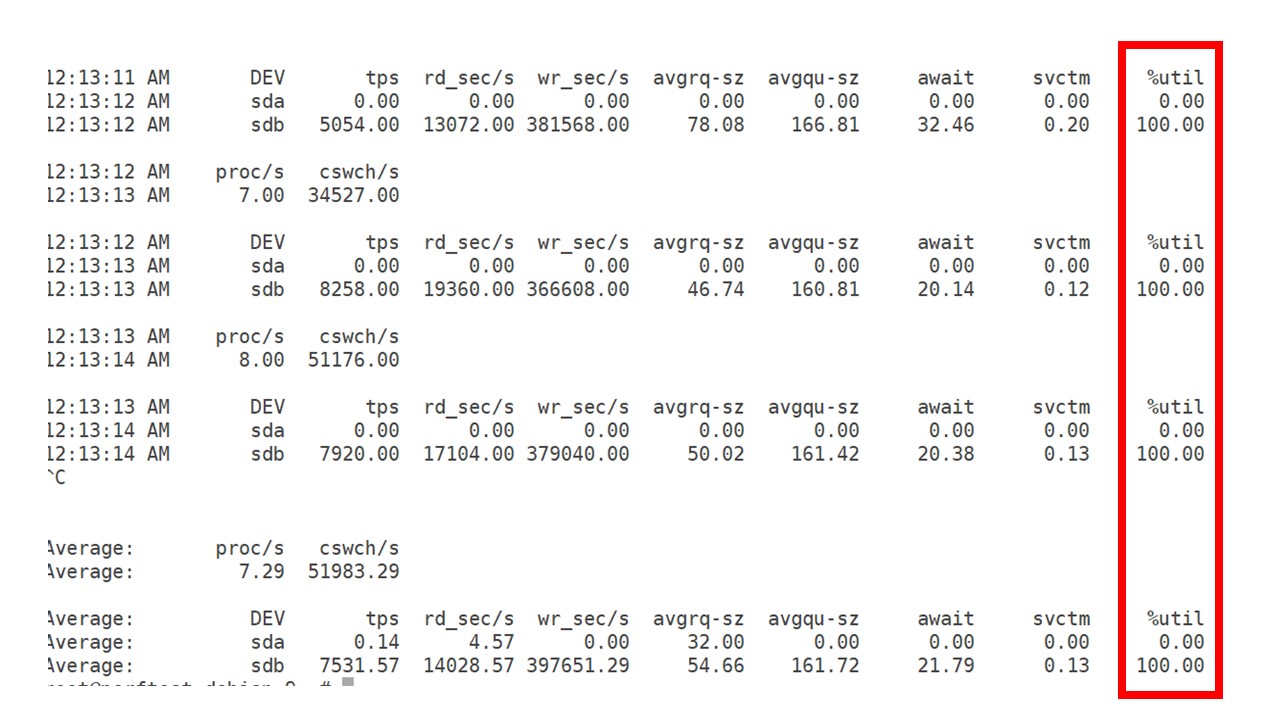
Saya mendapatkan yang
terbaik dari drive pada perangkat keras ini dan pada mesin virtual ini. Pada intensitas ini, PostgreSQL mulai membuang data dengan cukup aktif, dan disk tidak lagi punya waktu untuk menulis dan membaca.
Server kedua
Saya mengambil server lain yang sudah memiliki 48 prosesor dan RAM 128 GB. Tune-up - atur 60 syncer history, dan dapatkan kinerja yang bisa diterima
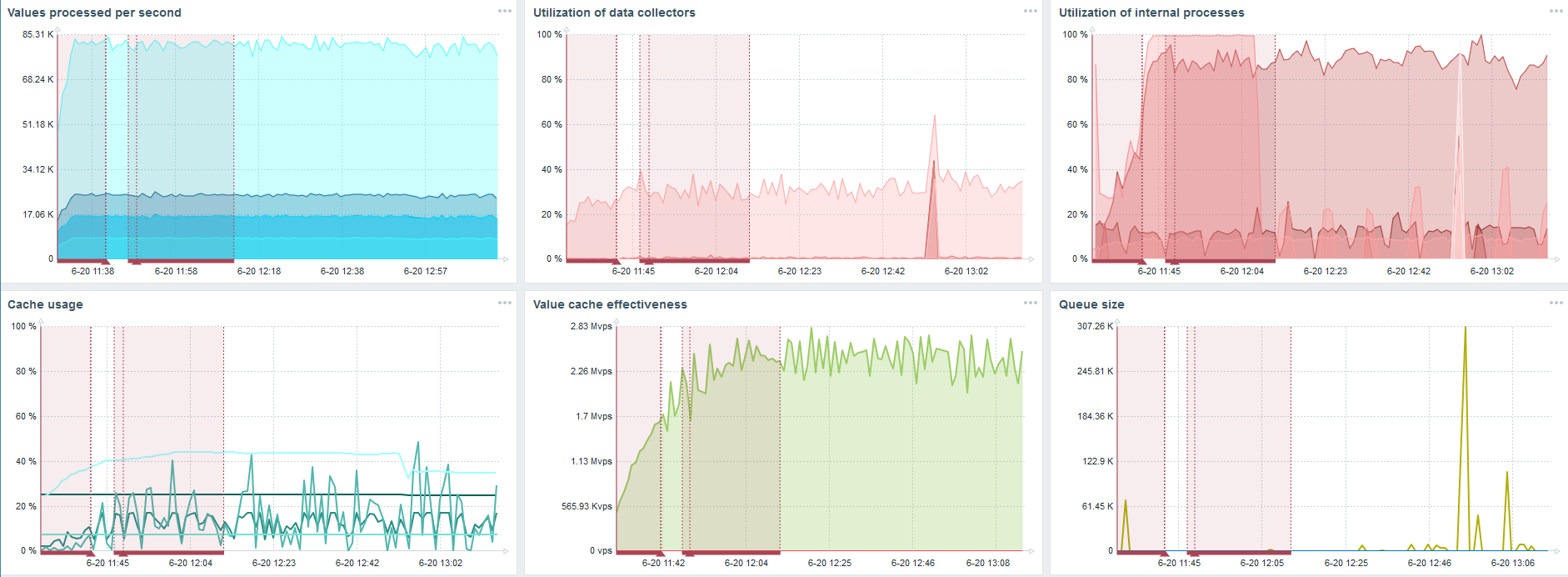
Bahkan, ini sudah menjadi batas kinerja di mana sesuatu harus dilakukan.
TimescaleDB. 80.000 nvps
Tugas utama saya adalah menguji kemampuan TimescaleDB dari beban Zabbix. 80 ribu nilai per detik banyak, frekuensi mengumpulkan metrik (kecuali Yandex, tentu saja) dan "pengaturan" yang cukup besar.
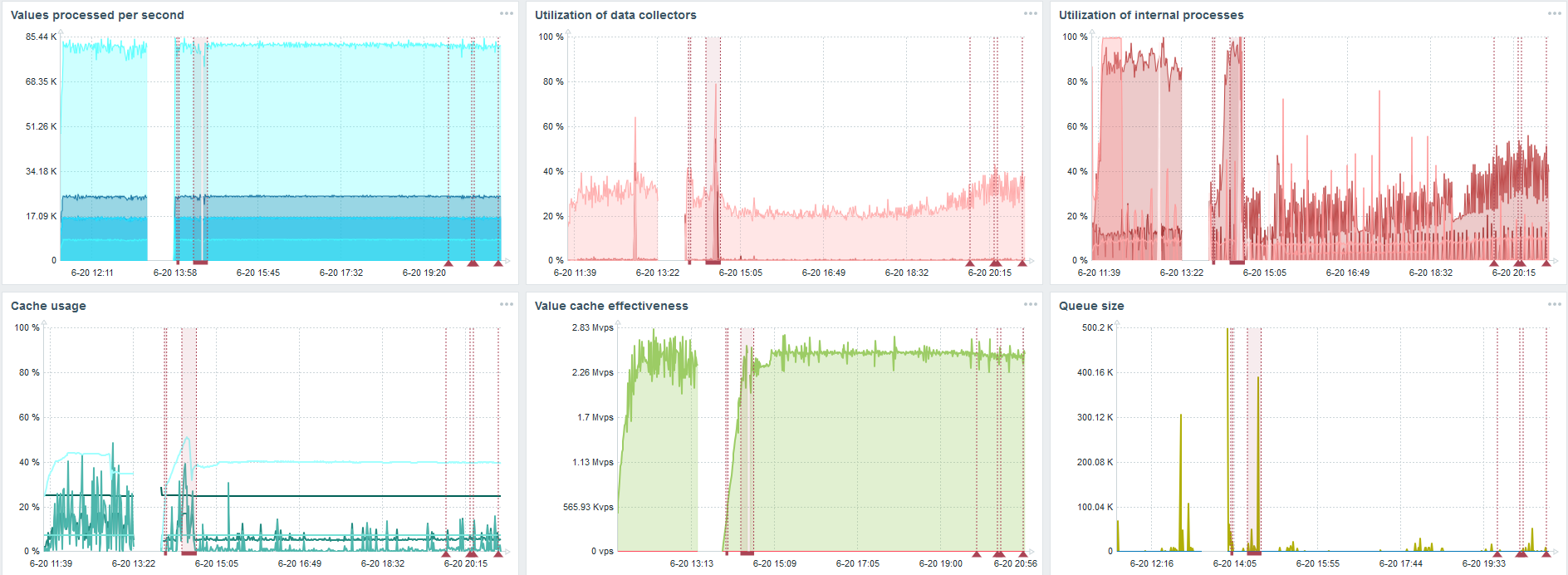
Ada kegagalan pada setiap bagan - ini hanya migrasi data. Setelah kegagalan di server Zabbix, profil boot syncer sejarah telah banyak berubah - itu telah jatuh tiga kali.
TimescaleDB memungkinkan Anda untuk memasukkan data hampir 3 kali lebih cepat dan menggunakan lebih sedikit HistoryCache.
Dengan demikian, data akan dikirimkan kepada Anda tepat waktu.
TimescaleDB. 120.000 nvps
Lalu saya menambah jumlah elemen data menjadi 500 ribu.Tugas utama adalah memeriksa kemampuan TimescaleDB - saya mendapat nilai yang dihitung dari 125 ribu nilai per detik.
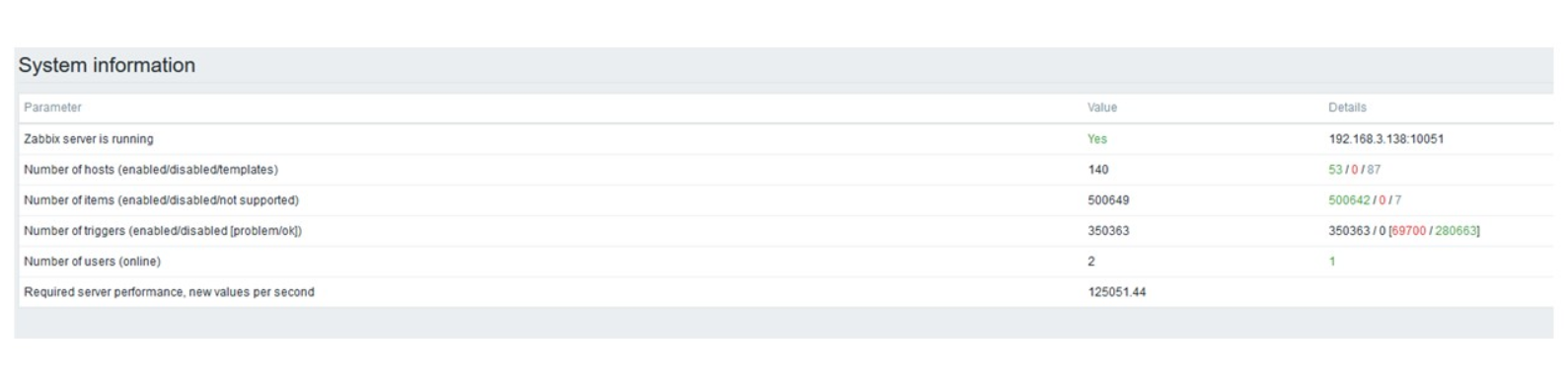
Ini adalah "pengaturan" yang berfungsi yang dapat bekerja untuk waktu yang lama. Tetapi karena disk saya hanya 1,5 TB, saya mengisinya dalam beberapa hari.
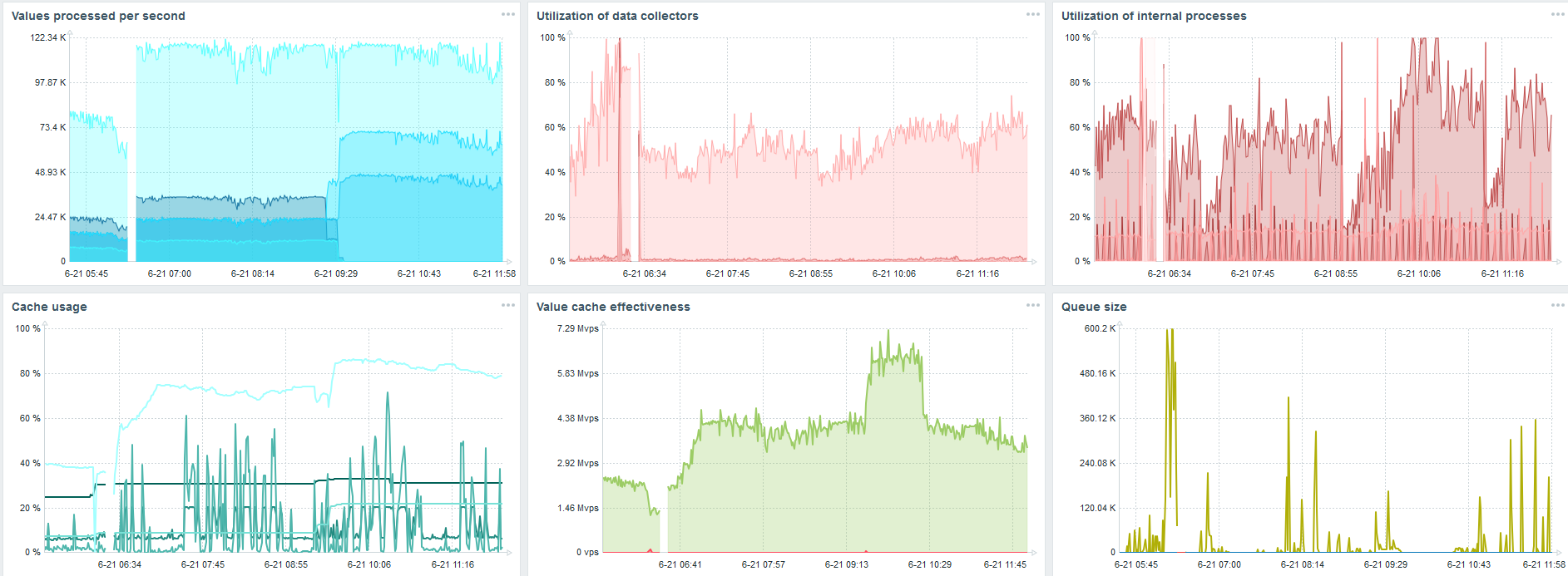
Yang paling penting, pada saat yang sama, partisi TimescaleDB baru dibuat.
Untuk kinerja, ini sama sekali tidak terlihat. Ketika partisi dibuat di MySQL, misalnya, semuanya berbeda. Biasanya ini terjadi pada malam hari, karena memblokir penyisipan umum, bekerja dengan tabel dan dapat membuat degradasi layanan. Dalam kasus TimescaleDB ini bukan.
Sebagai contoh saya akan menunjukkan satu bagan dari set di komunitas. TimescaleDB termasuk dalam gambar, karena ini beban penggunaan io.weight pada prosesor telah turun. Penggunaan elemen-elemen proses internal juga telah menurun. Dan ini adalah mesin virtual biasa pada disk pancake biasa, bukan SSD.
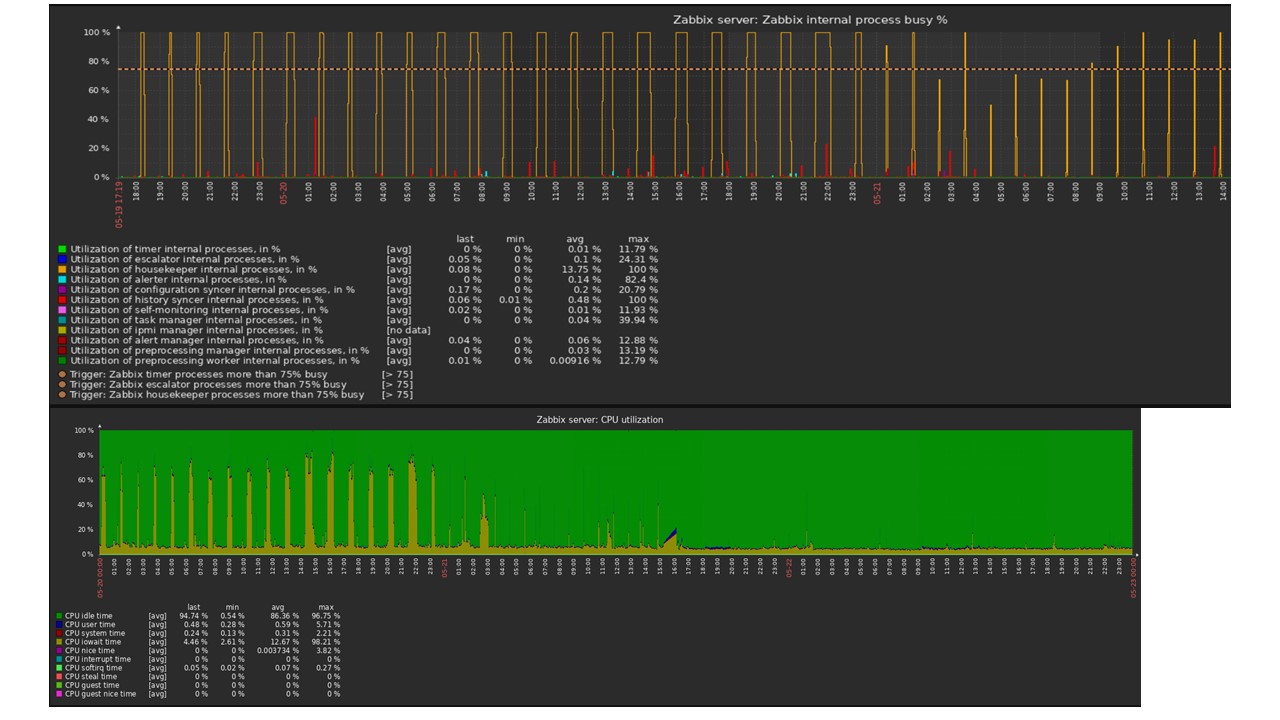
Kesimpulan
TimescaleDB adalah solusi yang bagus untuk "pengaturan" kecil yang mengandalkan kinerja disk. Ini akan memungkinkan Anda untuk terus bekerja dengan baik sampai database dimigrasi ke besi lebih cepat.
TimescaleDB mudah untuk dikonfigurasi, memberikan peningkatan kinerja, bekerja dengan baik dengan Zabbix dan
memiliki keunggulan dibandingkan PostgreSQL .
Jika Anda menggunakan PostgreSQL dan tidak berencana untuk mengubahnya, maka saya sarankan
menggunakan PostgreSQL dengan ekstensi TimescaleDB bersamaan dengan Zabbix . Solusi ini bekerja secara efektif untuk "pengaturan" menengah.
Kami mengatakan "kinerja tinggi" - maksud kami HighLoad ++ . Menunggu untuk berkenalan dengan teknologi dan praktik yang memungkinkan layanan untuk melayani jutaan pengguna, sangat singkat. Kami telah menyusun daftar laporan untuk 7 dan 8 November, tetapi mitaps masih dapat ditawarkan.
Berlangganan buletin dan telegram kami , tempat kami mengungkapkan keripik konferensi yang akan datang, dan pelajari cara memanfaatkannya sebaik mungkin.