Pembelajaran mesin modern memungkinkan Anda melakukan hal-hal luar biasa. Jaringan saraf berfungsi untuk kepentingan masyarakat: mereka menemukan penjahat, mengenali ancaman, membantu mendiagnosis penyakit dan membuat keputusan sulit. Algoritma dapat melampaui seseorang dalam kreativitas: mereka melukis gambar, menulis lagu dan membuat karya dari gambar biasa. Dan mereka yang mengembangkan algoritma ini sering disajikan sebagai ilmuwan karikatur.
Tidak semuanya menakutkan! Siapa pun yang agak terbiasa dengan pemrograman dapat membangun jaringan saraf dari model dasar. Dan bahkan tidak perlu mempelajari Python, semuanya dapat dilakukan dalam JavaScript asli. Sangat mudah untuk memulai dan mengapa pembelajaran mesin
diperlukan untuk
vendor front-end, kata
Aleksey Okhrimenko (
obenjiro ) di FrontendConf, dan kami mentransfernya ke teks sehingga nama arsitektur dan tautan yang berguna tersedia.
Spoiler. Peringatan!
Cerita ini:
- Bukan untuk mereka yang sudah bekerja dengan Machine Learning. Sesuatu yang menarik akan terjadi, tetapi tidak mungkin bahwa di bawah potongan Anda sedang menunggu pembukaan.
- Bukan Tentang Transfer Pembelajaran. Kami tidak akan berbicara tentang cara menulis jaringan saraf dengan Python, dan kemudian bekerja dengannya dari JavaScript. Tanpa curang - kami akan menulis jaringan saraf yang dalam khusus di JS.
- Tidak semua detailnya. Secara umum, semua konsep tidak akan masuk ke dalam satu artikel, tetapi tentu saja kami akan menganalisis yang diperlukan.
Tentang pembicara: Alexei Okhrimenko bekerja di Avito di departemen Arsitektur Frontend, dan dalam waktu luangnya mengadakan Pertemuan Angular Moskow dan merilis "Lima Menit Angular". Selama karirnya yang panjang, ia telah mengembangkan pola desain MALEVICH, pengurai tata bahasa PEG SimplePEG. Alexey CSSComb maintainer secara teratur berbagi pengetahuan tentang teknologi baru di konferensi dan
saluran telegram pembelajaran mesin JS-nya.
Pembelajaran mesin sangat populer.
Asisten suara, Siri, Asisten Google, Alice, sangat populer dan sering ditemukan dalam kehidupan kita. Banyak produk telah beralih dari pemrosesan data algoritmik konvensional ke pembelajaran mesin. Contoh yang mencolok adalah Google Translate.
Semua inovasi dan chip paling keren di smartphone didasarkan pada pembelajaran mesin.

Misalnya, Google NightSight menggunakan pembelajaran mesin. Foto-foto keren yang kami lihat tidak diperoleh dengan lensa, sensor, atau stabilisasi, tetapi dengan bantuan pembelajaran mesin. Mesin akhirnya mengalahkan orang-orang di DOTA2, yang berarti bahwa kita memiliki sedikit peluang untuk mengalahkan kecerdasan buatan. Karena itu, kita harus menguasai pembelajaran mesin secepat mungkin.
Mari kita mulai dengan yang sederhana
Apa rutin pemrograman harian kita, bagaimana biasanya kita menulis fungsi?

Kami mengambil data dan algoritme yang kami temukan atau ambil sendiri dari yang sudah jadi, menggabungkan, melakukan sedikit keajaiban dan mendapatkan fungsi yang memberi kami jawaban yang tepat dalam situasi tertentu.
Kami terbiasa dengan urutan hal-hal ini, tetapi akan ada kesempatan seperti itu, tanpa mengetahui algoritma, tetapi hanya memiliki data dan jawabannya, dapatkan algoritma dari mereka.

Anda dapat mengatakan: "Saya seorang programmer, saya selalu bisa menulis algoritma."
Oke, tapi misalnya, algoritma apa yang diperlukan di sini?

Misalkan kucing memiliki telinga yang tajam, dan telinga anjing itu kusam, kecil, seperti pesek.

Mari kita coba memahami siapa yang mendengarnya. Tetapi pada titik tertentu, kami menemukan bahwa anjing dapat memiliki telinga yang tajam.

Hipotesis kami tidak baik, kami membutuhkan karakteristik lain. Seiring waktu, kita akan belajar lebih banyak dan lebih banyak detail, dengan demikian mendemotivasi diri kita sendiri semakin banyak, dan pada titik tertentu kita akan ingin keluar dari bisnis ini sama sekali.
Saya membayangkan gambar yang ideal seperti ini: sebelumnya ada jawaban (kita tahu gambar seperti apa itu), ada data (kita tahu bahwa kucing digambar), kita ingin mendapatkan algoritma yang dapat memberi makan data dan mendapatkan jawaban pada output.
Ada solusi - ini adalah pembelajaran mesin, yaitu salah satu bagiannya - jaringan saraf yang dalam.
Jaringan saraf yang mendalam
Pembelajaran mesin adalah bidang yang sangat luas. Ini menawarkan sejumlah besar metode, dan masing-masing bagus dengan caranya sendiri.
Salah satunya adalah Deep Neural Networks. Pembelajaran mendalam memiliki keunggulan yang tak dapat disangkal karena telah menjadi populer.
Untuk memahami keunggulan ini, mari kita lihat masalah klasifikasi klasik menggunakan kucing dan anjing sebagai contoh.
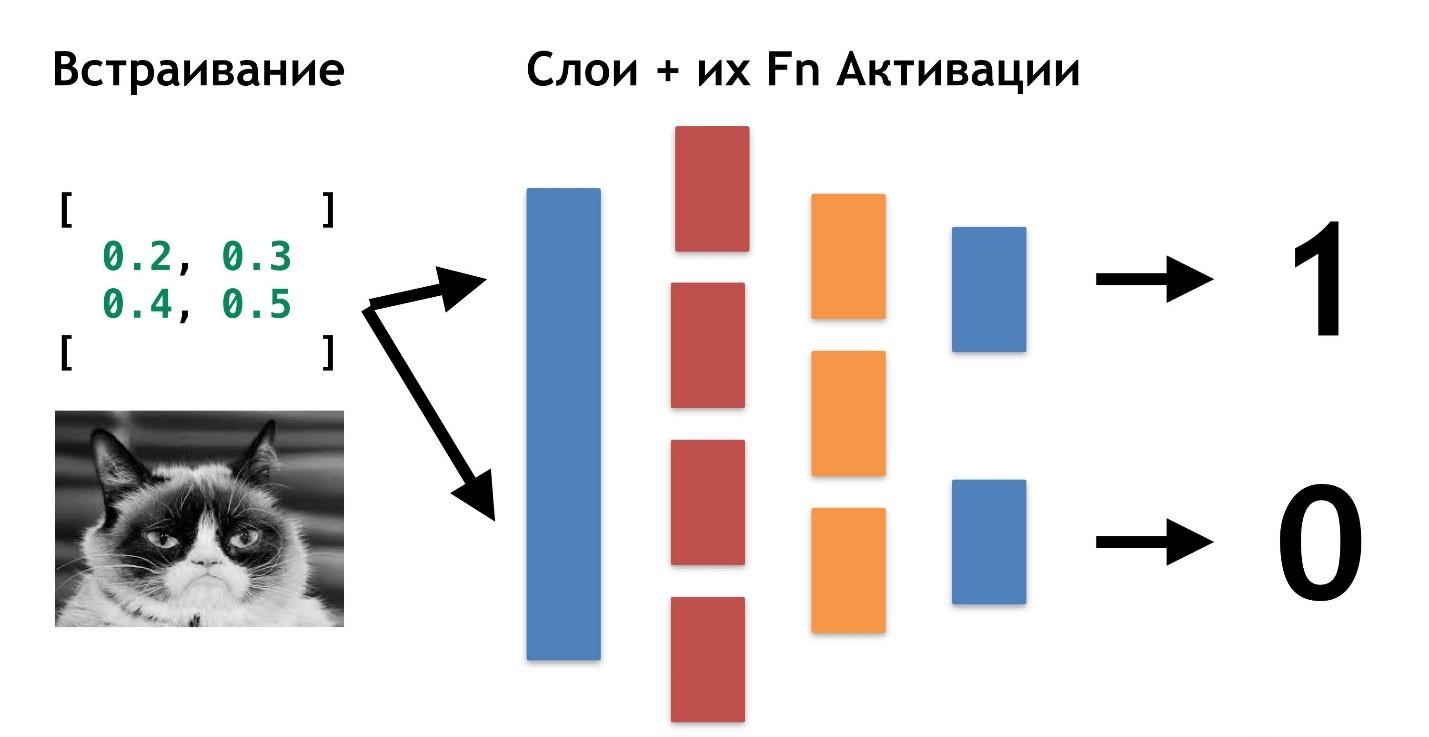
Ada data: gambar atau foto. Hal pertama yang harus dilakukan adalah menanamkan (embedding), yaitu mengubah data sehingga mesin nyaman bekerja dengan mereka. Tidak nyaman bekerja dengan gambar, mobil membutuhkan sesuatu yang lebih sederhana.
Pertama, luruskan gambar dan hapus warnanya. Tidak peduli apa warna anjing atau kucing itu, penting untuk menentukan jenis hewan. Kemudian kita mengubah gambar menjadi array, di mana, misalnya, 0 gelap, 1 terang.

Dengan penyajian data ini, jaringan saraf sudah dapat bekerja.
Mari kita membuat dua array lagi dan menggabungkannya menjadi "lapisan" tertentu. Selanjutnya, kita akan mengalikan masing-masing elemen layer dan array data satu sama lain menggunakan perkalian matriks sederhana, dan mengarahkan hasilnya menjadi dua fungsi aktivasi (nanti kita akan menganalisis apa fungsi-fungsi ini). Jika fungsi aktivasi menerima sejumlah nilai yang cukup, maka itu "diaktifkan" dan akan menghasilkan hasil:
- fungsi pertama akan mengembalikan 1 jika kucing, dan 0 jika bukan kucing.
- fungsi kedua akan mengembalikan 1 jika itu anjing, dan 0 jika bukan anjing.
Pendekatan pengkodean respons ini disebut
One-Hot Encoding .

Beberapa fitur jaringan syaraf yang dalam sudah terlihat:
- Untuk bekerja dengan jaringan saraf, Anda perlu menyandikan data pada input dan mendekode pada output.
- Pengkodean memungkinkan kita untuk abstrak dari data.
- Dengan mengubah data input, kita dapat menghasilkan jaringan saraf untuk berbagai domain domain. Bahkan mereka yang kami bukan ahli.
Tidak perlu tahu apa itu kucing, apa itu anjing. Cukup untuk memilih nomor yang diperlukan untuk lapisan tambahan.
Sejauh ini, satu-satunya hal yang masih belum jelas adalah mengapa jaringan ini disebut "dalam."
Semuanya sangat sederhana: kita dapat membuat layer lain (array dan fungsi aktivasi mereka). Dan mentransfer hasil dari satu lapisan ke lapisan lain.
Anda dapat berbaring satu sama lain karena banyak lapisan ini dan fungsinya untuk aktivasi. Menggabungkan arsitektur berlapis, kita mendapatkan jaringan saraf yang dalam. Kedalamannya adalah banyak lapisan. Dan secara kolektif disebut
"model .
"Sekarang mari kita lihat bagaimana nilai-nilai dipilih untuk semua lapisan ini. Ada
visualisasi keren yang memungkinkan Anda memahami bagaimana proses pembelajaran terjadi.
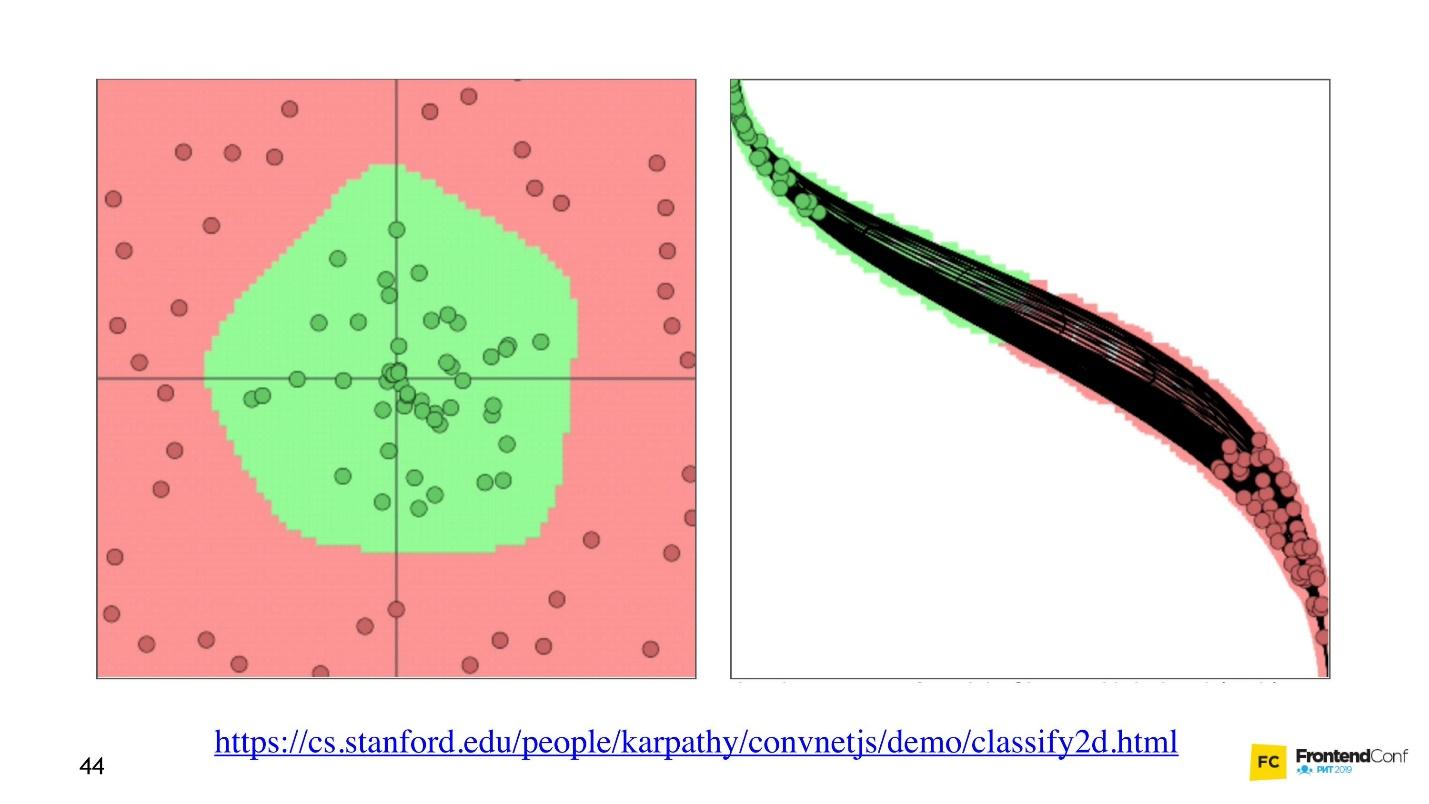
Di sebelah kiri adalah data, dan di sebelah kanan adalah salah satu lapisan. Dapat dilihat bahwa mengubah nilai-nilai di dalam array lapisan, kita tampaknya mengubah sistem koordinat. Sehingga beradaptasi dengan data dan pembelajaran. Dengan demikian, pembelajaran adalah proses memilih nilai yang tepat untuk layer array. Nilai-nilai ini disebut bobot atau bobot.
Belajar mesin itu sulit
Saya ingin membuat Anda marah, pembelajaran mesin itu sulit. Semua hal di atas adalah penyederhanaan yang bagus. Di masa depan, Anda akan menemukan sejumlah besar aljabar linier, dan cukup kompleks. Sayangnya, tidak ada jalan keluar dari ini.
Tentu saja, ada kursus, tetapi bahkan pelatihan tercepat berlangsung beberapa bulan dan tidak murah. Plus, Anda masih harus mencari tahu sendiri. Bidang pembelajaran mesin telah tumbuh sangat banyak sehingga melacak segala sesuatu hampir mustahil. Misalnya, di bawah ini adalah seperangkat model untuk menyelesaikan hanya satu tugas (deteksi objek):

Secara pribadi, saya sangat kehilangan motivasi. Saya tidak bisa mendekati jaringan saraf dan mulai bekerja dengan mereka. Tetapi saya telah menemukan cara dan ingin membaginya dengan Anda. Ini bukan revolusioner, tidak ada yang seperti itu di dalamnya, Anda sudah terbiasa dengannya.
Blackbox - Pendekatan Sederhana
Anda tidak perlu memahami sepenuhnya semua aspek pembelajaran mesin untuk mempelajari cara menerapkan jaringan saraf pada tugas bisnis Anda. Saya akan menunjukkan beberapa contoh yang semoga menginspirasi Anda.
Bagi banyak orang, mobil juga kotak hitam. Tetapi bahkan jika Anda tidak tahu cara kerjanya, Anda perlu mempelajari aturannya. Jadi dengan pembelajaran mesin - Anda masih perlu tahu beberapa aturan:
- Pelajari TensorFlow JS (perpustakaan untuk bekerja dengan jaringan saraf).
- Belajar memilih model.
Kami fokus pada tugas-tugas ini dan mulai dengan kode.
Belajar dengan membuat kode
Perpustakaan TensorFlow ditulis untuk sejumlah besar bahasa: Python, C / C ++, JavaScript, Go, Java, Swift, C #, Haskell, Julia, R, Scala, Karat, OCaml, Crystal. Tapi kami pasti akan memilih yang terbaik - JavaScript.
TensorFlow dapat dihubungkan ke halaman kami dengan menghubungkan skrip dengan CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
Atau gunakan npm:
npm install @tensorflow/tfjs-node - untuk proses node (situs web);npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - untuk GPU, tetapi hanya jika mesin Linux dan kartu video mendukung teknologi CUDA. Pastikan untuk memastikan bahwa Kemampuan Komputasi CUDA cocok dengan perpustakaan Anda sehingga tidak terbukti bahwa perangkat keras yang mahal tidak cocok.npm install @tensorflow/tfjs ( npm install @tensorflow/tfjs / Browser) - untuk browser tanpa menggunakan Node.js.
Untuk bekerja dengan TensorFlow JS, cukup mengimpor satu dari modul di atas. Anda akan melihat banyak contoh kode tempat semuanya diimpor. Tidak perlu melakukan ini, pilih dan impor hanya satu.
Tensor
Ketika data awal siap, hal pertama yang harus dilakukan adalah
mengimpor TensorFlow . Kami akan menggunakan tensorflow / tfjs-node-gpu untuk mendapatkan akselerasi karena kekuatan kartu video.
Ada array data dua dimensi - kami akan bekerja dengannya.
Hal penting berikutnya yang harus dilakukan adalah
membuat tensor . Dalam hal ini, tensor dibuat dari peringkat 2, yaitu, sebenarnya array dua dimensi. Kami mentransfer data dan mendapatkan tensor 2x2.
Perhatikan bahwa metode
print disebut, bukan
console.log , karena
b (tensor yang kami buat) bukan objek biasa, yaitu tensor. Dia memiliki metode dan propertinya sendiri.
Anda juga dapat membuat tensor dari array planar dan mengingat bentuknya, katakanlah. Yaitu, untuk mendeklarasikan bentuk - array dua dimensi - untuk mentransmisikan hanya sebuah array datar dan menunjukkan secara langsung formulir. Hasilnya akan sama.
Karena kenyataan bahwa data dan formulir dapat disimpan secara terpisah, Anda dapat mengubah bentuk tensor. Kita dapat memanggil metode
reshape dan mengubah bentuk dari 2x2 ke 4x1.
Langkah penting berikutnya adalah
mengeluarkan data , mengembalikannya kembali ke dunia nyata.
Kode untuk ketiga langkah.Metode
data mengembalikan janji. Setelah diselesaikan, kami mendapatkan nilai langsung dari nilai mentah, tetapi mendapatkannya secara tidak sinkron. Jika kita mau, kita bisa mendapatkannya secara sinkron, tetapi ingat bahwa di sini Anda dapat kehilangan kinerja, jadi gunakan metode asinkron bila memungkinkan.
Metode
dataSync selalu mengembalikan data dalam format array datar. Dan jika kita ingin mengembalikan data dalam format penyimpanannya, kita perlu memanggil
arraySync .
Operator
Semua operator di TensorFlow tidak
dapat diubah secara default , yaitu, dalam setiap operasi tensor baru selalu dikembalikan. Di atas, ambil saja array kami dan buat persegi semua elemennya.
Mengapa kesulitan seperti itu untuk operasi matematika sederhana? Semua operator yang kita butuhkan - jumlah, median, dll - ada di sana. Ini diperlukan karena, pada kenyataannya, tensor dan pendekatan ini memungkinkan Anda untuk membuat grafik perhitungan dan melakukan perhitungan tidak segera, tetapi pada WebGL (di browser) atau CUDA (Node.js pada mesin). Artinya, sebenarnya menggunakan Akselerasi Perangkat Keras tidak terlihat oleh kami dan, jika perlu, melakukan fallback pada CPU. Yang hebat adalah kita tidak perlu memikirkan apa pun tentang itu. Kita hanya perlu mempelajari API tfjs.
Sekarang yang paling penting adalah modelnya.
Model
Cara termudah untuk membuat model adalah Berurutan, yaitu, model berurutan, ketika data dari satu lapisan ditransfer ke lapisan berikutnya, dan dari itu ke lapisan berikutnya. Lapisan paling sederhana yang digunakan di sini digunakan.
Lapisan itu sendiri hanyalah abstraksi dari tensor dan operator. Secara kasar, ini adalah fungsi pembantu yang menyembunyikan sejumlah besar matematika dari Anda.
Mari kita coba memahami cara bekerja dengan model tanpa masuk ke detail implementasi.
Pertama, kami menunjukkan bentuk data yang jatuh ke dalam jaringan saraf -
inputShape adalah parameter yang diperlukan. Kami menunjukkan
units - jumlah array multidimensi dan fungsi aktivasi.
Fungsi
relu luar biasa karena ditemukan secara kebetulan - dicoba, bekerja lebih baik, dan untuk waktu yang sangat lama kemudian mereka mencari penjelasan matematis mengapa hal ini terjadi.
Untuk lapisan terakhir, ketika kita membuat kategori, fungsi softmax sering digunakan - sangat cocok untuk menampilkan jawaban dalam format One-Hot Encoding. Setelah model dibuat, panggil
model.summary() untuk memastikan bahwa model tersebut dipasang dengan cara yang benar. Dalam situasi yang sangat sulit, Anda dapat mendekati pembuatan model menggunakan pemrograman fungsional.
Jika Anda perlu membuat model yang sangat kompleks, Anda dapat menggunakan pendekatan fungsional: setiap kali setiap layer adalah variabel baru. Sebagai contoh, kita secara manual mengambil layer berikutnya dan menerapkan layer sebelumnya, sehingga kita dapat membangun arsitektur yang lebih kompleks. Saya akan tunjukkan nanti di mana ini bisa berguna.
Detail yang sangat penting berikutnya adalah bahwa kita melewatkan lapisan input dan output ke dalam model, yaitu lapisan yang memasuki jaringan saraf dan lapisan yang merupakan lapisan untuk jawabannya.
Setelah ini, langkah penting adalah
mengkompilasi model . Mari kita coba untuk memahami apa kompilasi dalam hal tfjs.
Ingat, kami mencoba menemukan nilai yang tepat di jaringan saraf kami. Tidak perlu mengambilnya. Mereka dipilih dengan cara tertentu, seperti fungsi pengoptimal mengatakan.
Kode untuk deskripsi lapisan berurutan dan kompilasi.Saya akan menggambarkan apa itu pengoptimal dan apa fungsi kerugiannya.
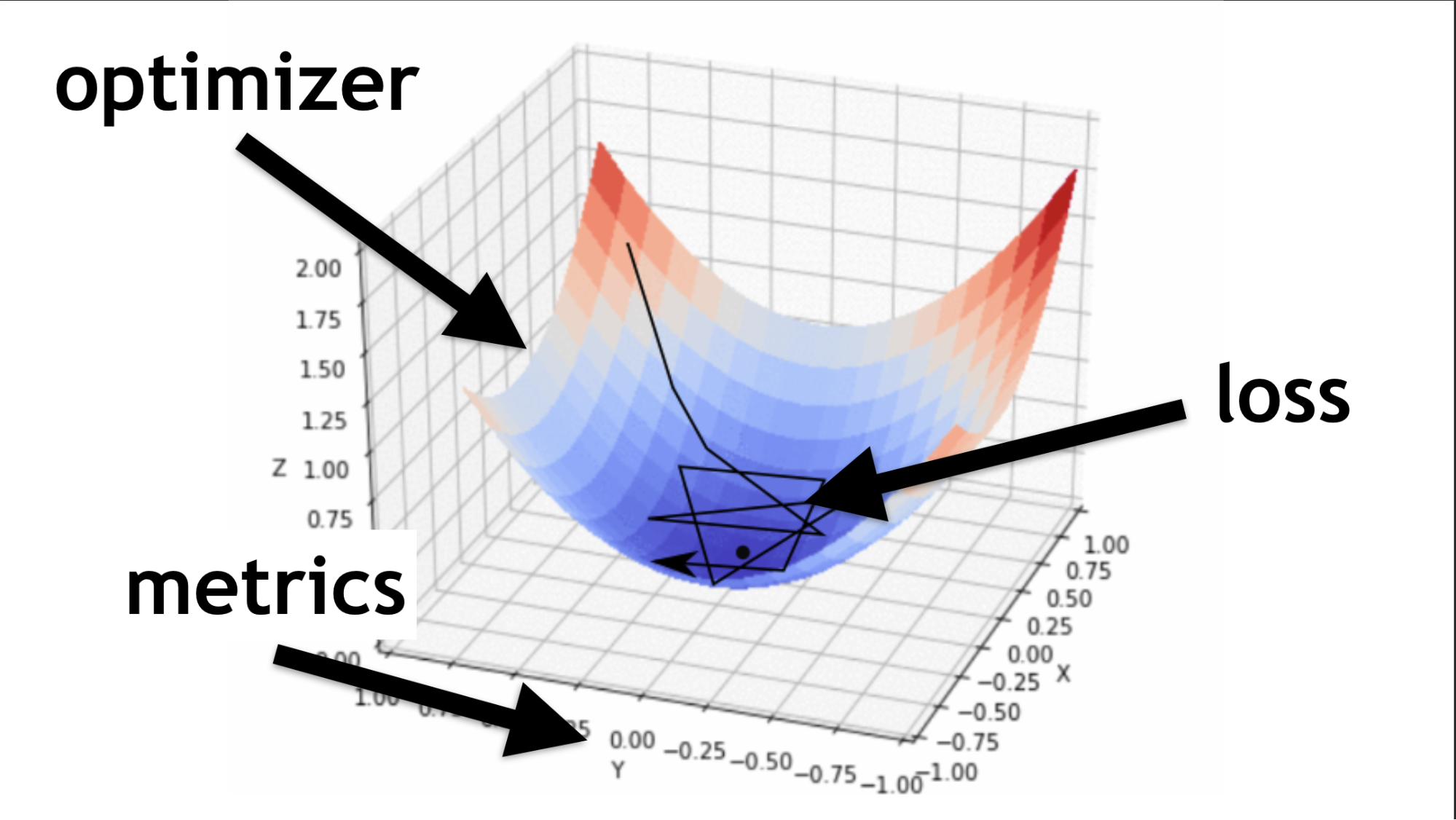
Pengoptimal adalah seluruh peta. Ini memungkinkan Anda untuk tidak hanya berjalan secara acak dan mencari nilai, tetapi melakukannya dengan bijak, menurut algoritma tertentu.
Fungsi kerugian adalah cara kita mencari nilai optimal (panah hitam kecil). Ini membantu untuk memahami nilai gradien mana yang digunakan untuk melatih jaringan saraf kita.
Di masa depan, ketika Anda menguasai jaringan saraf, Anda akan menulis sendiri fungsi kerugian. Sebagian besar keberhasilan jaringan saraf tergantung pada seberapa baik fungsi ini ditulis. Tapi ini cerita lain. Mari kita mulai dari yang sederhana.
Contoh Pembelajaran Jaringan
Kami akan menghasilkan data acak dan jawaban acak (label). Kami memanggil modul
fit , meneruskan data, jawaban, dan beberapa parameter penting:
epochs - 5 kali, yaitu, kira-kira, 5 kali kita akan melakukan pelatihan penuh;batchSize , yang mengatakan berapa banyak bobot yang dapat diubah pada satu waktu untuk mengangkat - berapa banyak elemen yang diproses pada saat yang sama. Semakin baik kartu video, semakin banyak memori yang dimilikinya, semakin banyak batchSize dapat diatur.
Kode semua langkah terakhir.Metode asinkron
Model.fit , mengembalikan janji. Tetapi Anda dapat menggunakan async / menunggu dan menunggu eksekusi seperti itu.
Selanjutnya adalah
penggunaan . Kami melatih model kami, lalu kami mengambil data yang ingin kami proses, dan kami menyebut metode
predict , kami berkata: "Prediksi apa yang sebenarnya ada di sana?", Dan terima kasih untuk ini kami mendapatkan hasilnya.
Struktur standar
Setiap jaringan saraf memiliki tiga file utama:
- index.js - file di mana semua parameter jaringan saraf disimpan;
- model.js - file di mana model dan arsitekturnya disimpan secara langsung;
- data.js - file tempat data dikumpulkan, diproses, dan disematkan dalam sistem kami.
Jadi, saya berbicara tentang cara belajar TensorFlow.js. Usaha kecil, tetap
memilih model .
Sayangnya, ini tidak sepenuhnya benar. Bahkan, setiap kali Anda memilih model, Anda harus mengulangi langkah-langkah tertentu.
- Siapkan data untuk itu, yaitu, buat penyematan, sesuaikan dengan arsitekturnya.
- Konfigurasikan pengaturan Hyper (Saya akan memberi tahu Anda nanti apa artinya ini).
- Latih / latih setiap jaringan saraf (masing-masing model mungkin memiliki nuansa sendiri).
- Terapkan model saraf, dan sekali lagi, Anda bisa menerapkannya dengan berbagai cara.
Pilih model
Mari kita mulai dengan opsi dasar yang sering Anda temui.
Akal sehat
Ini adalah contoh populer dari jaringan saraf yang dalam. Semuanya dilakukan dengan cukup sederhana: ada dataset yang tersedia untuk umum - dataset MNIST.
Ini adalah gambar-gambar berlabel dengan angka-angka, atas dasar yang nyaman untuk melatih jaringan saraf.
Sesuai dengan arsitektur One-Hot Encoding, kami menyandikan setiap lapisan terakhir. Digit 10 - dengan demikian, akan ada 10 lapisan terakhir di akhir. Kami hanya mengirimkan gambar hitam dan putih ke pintu masuk, semua ini sangat mirip dengan apa yang kita bicarakan di awal.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
Kami meluruskan gambar menjadi array satu dimensi, kami mendapatkan 784 elemen. Dalam satu lapisan, 512 array. Fungsi aktivasi
'relu' .
Lapisan array selanjutnya sedikit lebih kecil (256), lapisan aktivasi juga
'relu' . Kami mengurangi jumlah array untuk mencari karakteristik yang lebih umum. Jaringan saraf harus didorong bagaimana belajar, dan dipaksa untuk membuat keputusan umum yang lebih serius, karena dia sendiri tidak akan melakukannya.
Pada akhirnya kami membuat 10 matriks dan menggunakan aktivasi softmax untuk One-Hot Encoding - jenis aktivasi ini bekerja dengan baik dengan jenis pengkodean respons ini.
Jaringan yang dalam memungkinkan Anda mengenali 80-90% gambar dengan benar - Saya ingin lebih banyak. Seseorang mengenali dengan kualitas sekitar 96%. Dapatkah jaringan saraf menangkap dan menyalip seseorang?
CNN (Jaringan Neural Konvolusional)
Jaringan konvolusional bekerja sangat sederhana. Pada akhirnya, mereka memiliki arsitektur yang sama seperti pada contoh sebelumnya. Tetapi pada awalnya, sesuatu yang lain terjadi. Array, alih-alih hanya memberikan beberapa solusi, kurangi gambarnya. Mereka mengambil bagian dari gambar dan mengurangi, runtuh, menjadi satu digit. Kemudian mereka dikumpulkan bersama-sama dan sekali lagi dikurangi.
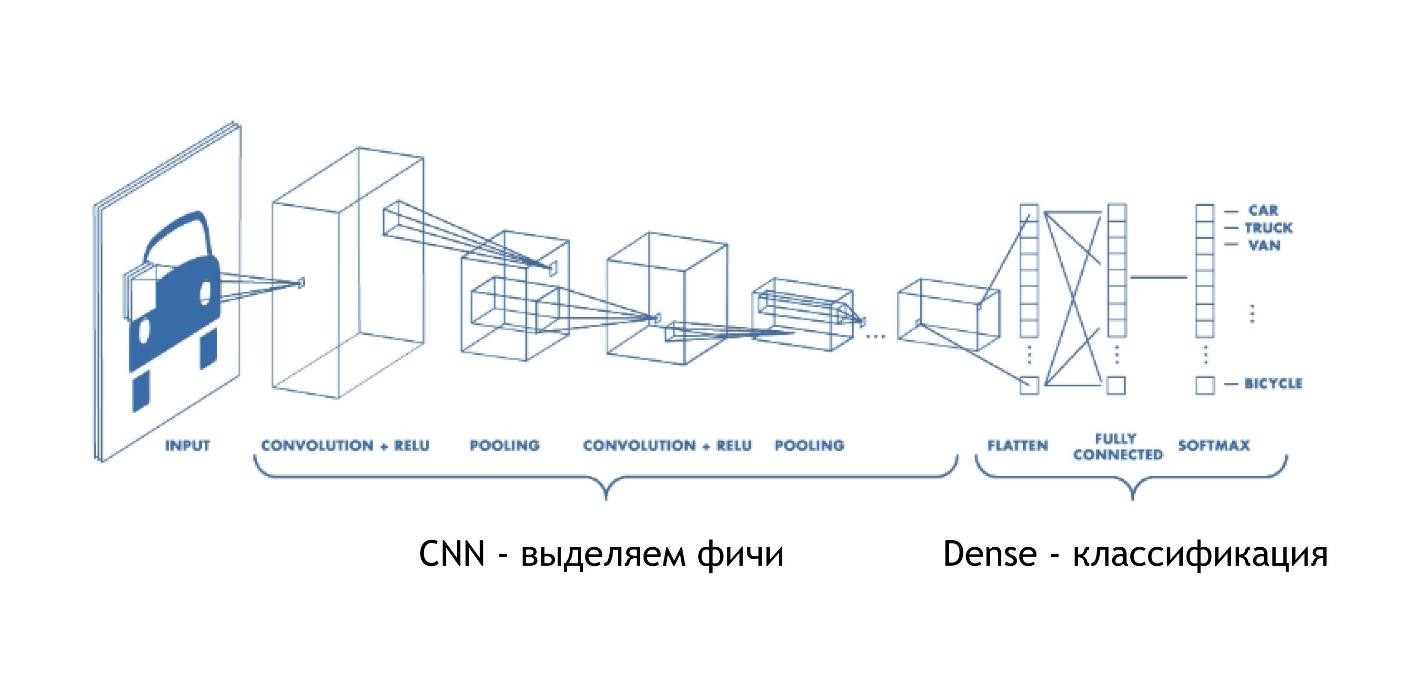
Dengan demikian, ukuran gambar berkurang, tetapi pada saat yang sama bagian gambar dikenali lebih baik dan lebih baik. Jaringan konvolusi bekerja sangat baik untuk pengenalan pola, bahkan lebih baik daripada manusia.
Mengenali gambar lebih baik dipercayakan pada mobil daripada seseorang. Ada penelitian khusus, dan orang itu, sayangnya, hilang.
CNN bekerja sangat sederhana:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
Kami memasukkan larik multidimensi tertentu: gambar 28x28 piksel, ditambah satu dimensi untuk kecerahan, dalam hal ini gambarnya hitam dan putih, sehingga dimensi ketiga adalah 1.
Selanjutnya, kami menetapkan jumlah
filters dan
kernelSize - berapa banyak piksel akan menyempit. Fungsi aktivasi
relu mana-mana.
Ada
maxPooling2d lapisan lain, yang diperlukan untuk mengurangi ukuran lebih efisien. Jaringan konvolusional mempersempit ukurannya secara bertahap, dan seringkali tidak perlu membuat jaringan konvolusional yang sangat dalam.
Saya akan menjelaskan mengapa tidak mungkin untuk melakukan jaringan konvolusi yang sangat dalam nanti, tetapi untuk sekarang, ingat: kadang-kadang mereka perlu digulung sedikit lebih cepat. Ada lapisan maxPooling terpisah untuk ini.
Pada akhirnya ada lapisan padat yang sama. Artinya, menggunakan jaringan saraf convolutional, kami menarik berbagai tanda dari data, setelah itu kami menggunakan pendekatan standar dan mengkategorikan hasil kami, berkat itu kami mengenali gambar.
U net
Model arsitektur ini dikaitkan dengan jaringan konvolusi. Dengan bantuannya, banyak penemuan telah dibuat dalam bidang pengendalian kanker, misalnya, dalam pengenalan sel kanker dan glaukoma. Selain itu, model ini dapat menemukan sel-sel ganas tidak lebih buruk daripada seorang profesor di bidang ini.
Contoh sederhana: di antara data berisik Anda perlu menemukan sel kanker (lingkaran).

U-Net sangat bagus sehingga dapat menemukan mereka hampir dengan sempurna. Arsitekturnya sangat sederhana:
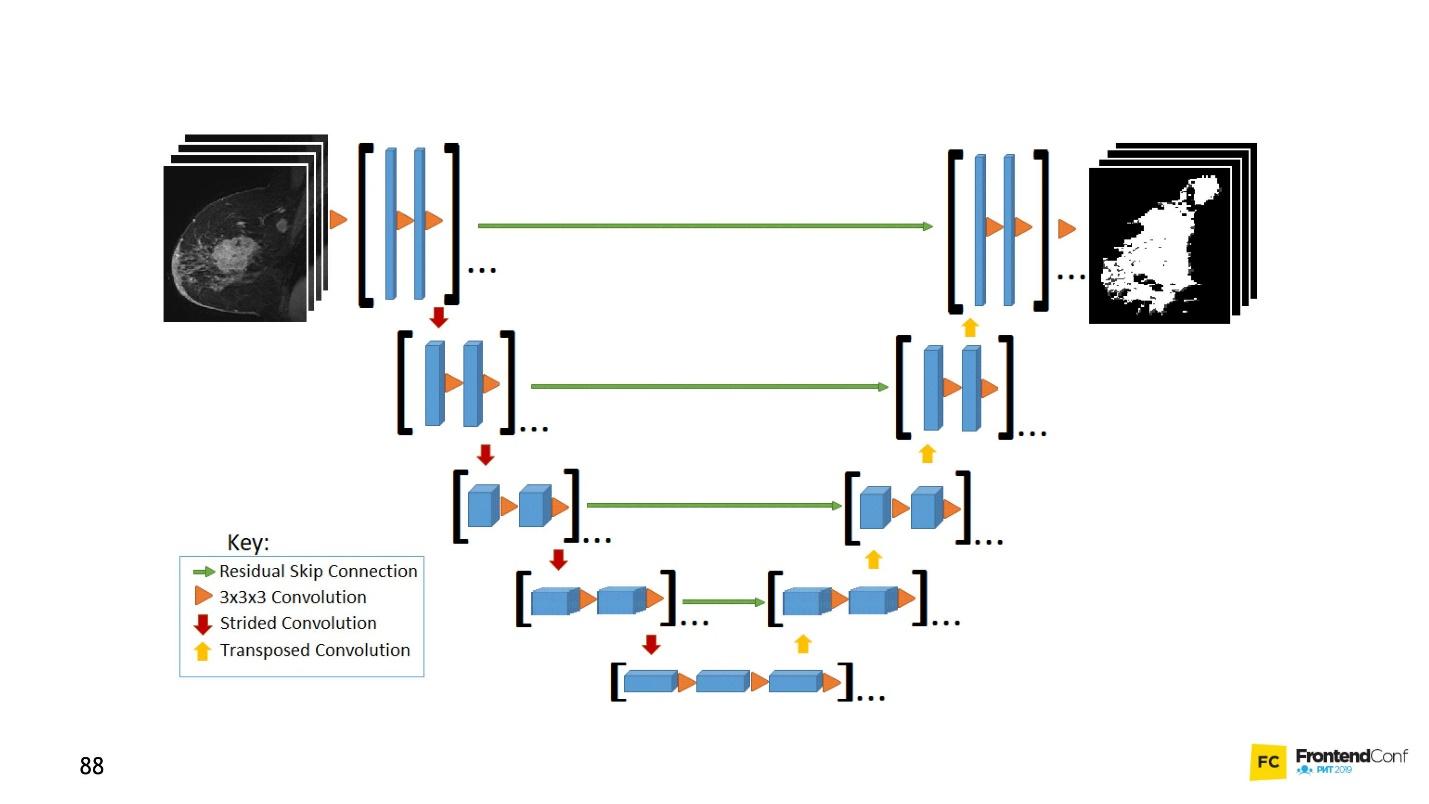
Ada jaringan konvolusi yang sama, seperti halnya MaxPooling, yang mengurangi ukurannya. Satu-satunya perbedaan: model ini juga menggunakan jaringan
pindai -
jaringan dekonvolusional .
Selain pemindaian konvolusi, masing-masing lapisan tingkat tinggi digabungkan satu sama lain (mulai dan keluar), karena itu muncul sejumlah besar hubungan. U-Net seperti itu bekerja dengan baik bahkan pada sejumlah kecil data.
Kode ini lebih mudah dipelajari di editor. Secara umum, sejumlah besar jaringan konvolusi dibuat di sini, dan kemudian, untuk menyebarkannya kembali, kami
concatenate dan menggabungkan beberapa lapisan. Ini hanya visualisasi gambar, hanya dalam bentuk kode. Semuanya cukup sederhana - menyalin dan mereproduksi model seperti itu mudah.
LSTM (Memori Jangka Pendek Panjang)
Perhatikan bahwa semua contoh dianggap memiliki satu fitur - format data input diperbaiki. Input ke jaringan, data harus berukuran sama dan cocok satu sama lain. Model LSTM berfokus pada bagaimana menghadapi hal ini.
Misalnya, ada layanan Yandex.Referats, yang menghasilkan abstrak.
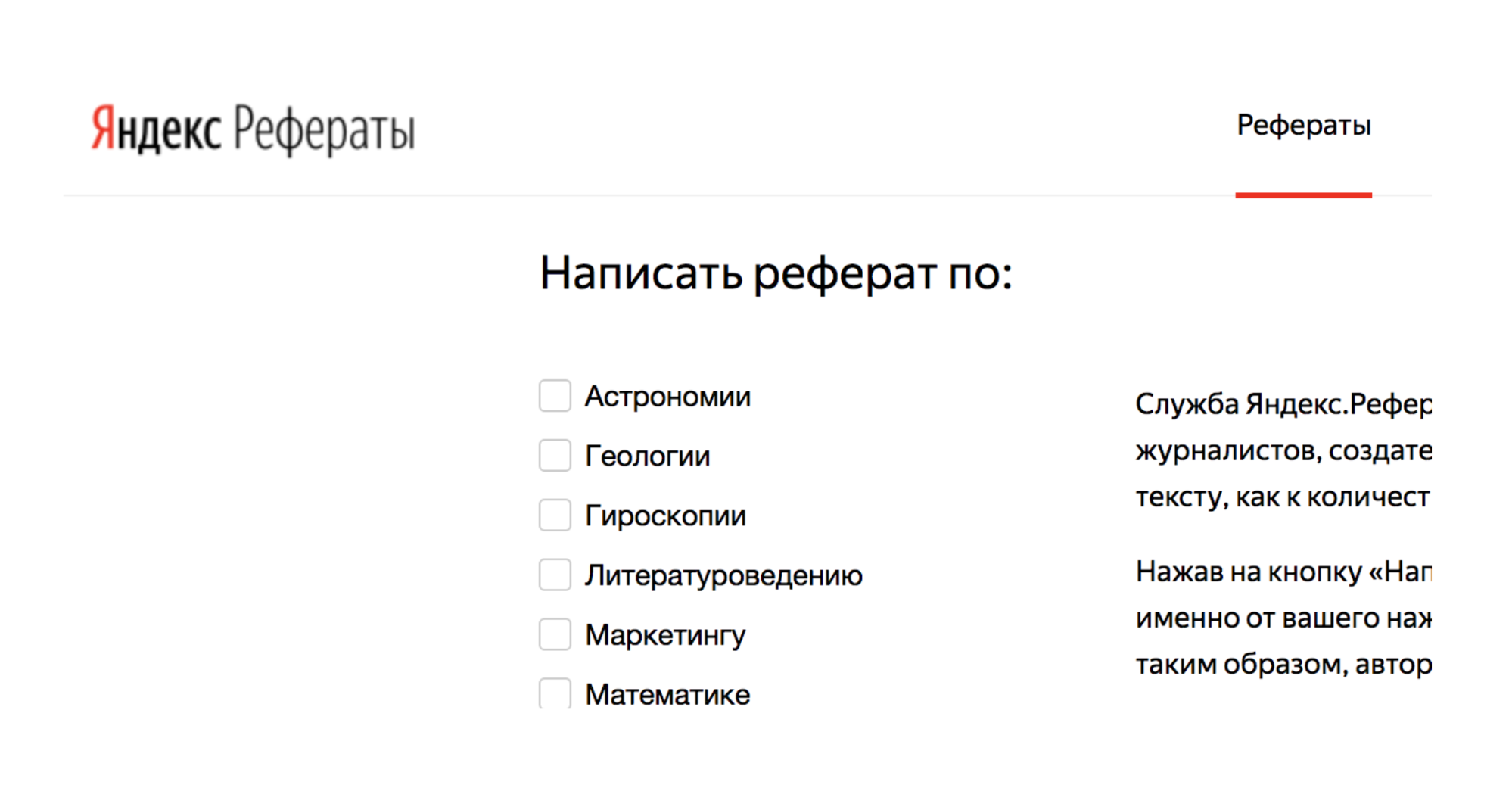
Dia memberikan abracadabra lengkap, tetapi pada saat yang sama sangat mirip dengan kebenaran:
Abstrak dalam matematika dengan tema: “Binomial Newton sebagai aksioma”
Menurut pendahulunya, integral permukaan menghasilkan integral lengkung. Fungsi cembung ke bawah masih diminati.
Secara alami dari sini bahwa normal ke permukaan masih dalam permintaan. Menurut sebelumnya, integral Poisson pada dasarnya menentukan integral trigonometri Poisson.
Layanan ini didasarkan pada jaringan saraf Seq-to-Seq. Arsitektur mereka lebih kompleks.

Lapisan disusun dalam sistem yang agak rumit. Tapi jangan khawatir - Anda tidak harus melakukan semua panah ini sendiri. Jika mau, Anda bisa, tetapi tidak perlu. Ada penolong yang akan melakukan ini untuk Anda.
Hal utama yang harus dipahami adalah bahwa masing-masing bagian ini digabungkan dengan yang sebelumnya. Dibutuhkan data tidak hanya dari data awal, tetapi juga dari lapisan saraf sebelumnya. Secara kasar, adalah mungkin untuk membangun semacam memori - untuk menghafal urutan data, mereproduksinya, dan karena pekerjaan ini "urutan ke urutan". Selain itu, urutannya dapat berbeda ukuran baik pada input maupun pada output.
Semuanya terlihat indah dalam kode:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
Ada pembantu khusus yang mengatakan bahwa kita memiliki 512 objek (array). Selanjutnya, kembalikan urutan dan formulir input (
inputShape: [10000, 64] ). Selanjutnya kami memperkenalkan lapisan lain, tetapi kami tidak mengembalikan urutan (
returnSequences: false ), karena pada akhirnya kami mengatakan bahwa sekarang kami perlu menggunakan fungsi aktivasi untuk 64 karakter yang berbeda (huruf kecil dan huruf besar). 64 opsi diaktifkan menggunakan One-Hot Encoding.
Paling menarik
Sekarang, Anda mungkin bertanya-tanya: “Ini semua, tentu saja, bagus, tetapi mengapa saya membutuhkannya? "Memerangi kanker itu baik, tetapi mengapa saya membutuhkannya di garis depan?"
Dan tarian dengan rebana dimulai: untuk mencari tahu bagaimana menerapkan jaringan saraf untuk tata letak, misalnya.
Dengan bantuan jaringan saraf dimungkinkan untuk memecahkan masalah yang sebelumnya tidak mungkin untuk dipecahkan. Beberapa yang bahkan tidak dapat Anda pikirkan. Itu semua tergantung pada Anda, imajinasi Anda dan sedikit latihan.
Sekarang saya akan menunjukkan contoh menarik langsung dari penggunaan model yang kami periksa.
CNN Tim audio
Dengan menggunakan jaringan konvolusi, Anda tidak hanya dapat mengenali gambar, tetapi juga perintah audio, dan dengan kualitas pengenalan 97%, yaitu di level Google Assistant dan Yandex-Alice.
Di jaringan saja, tentu saja, tidak mungkin mengenali ucapan, kalimat yang lengkap, tetapi Anda dapat membuat asisten suara yang sederhana.
Informasi lebih lanjut tentang Alice dapat ditemukan di
laporan oleh Nikita Dubko, dan tentang asisten Google, cara bekerja dengan suara di dalamnya, dan tentang standar browser, di
sini .
Faktanya adalah bahwa kata apa pun, perintah apa pun dapat diubah menjadi spektrogram.
Anda dapat mengubah informasi audio apa pun menjadi spektrogram tersebut. Dan kemudian Anda dapat menyandikan audio dalam gambar, dan menerapkan CNN ke gambar dan mengenali perintah suara sederhana.
U-net. Pengujian Screenshot
U-Net bermanfaat tidak hanya untuk diagnosis kanker yang berhasil, tetapi juga, misalnya, untuk menguji tangkapan layar. Untuk perinciannya, lihat
laporan Lyudmila Mzhachikh, dan saya akan memberi tahu pangkalan itu sendiri.
Untuk pengujian dengan tangkapan layar, diperlukan dua tangkapan layar:
- dasar (referensi) yang kami bandingkan;
- tangkapan layar untuk pengujian.

Sayangnya, dalam pengujian tangkapan layar, sering ada banyak jatuh negatif (false positive). Tapi ini bisa dihindari dengan menerapkan teknologi kontrol kanker canggih ke ujung depan.
Ingat, kami menandai gambar pada area di mana ada kanker dan tidak. Hal yang sama dapat dilakukan di sini.
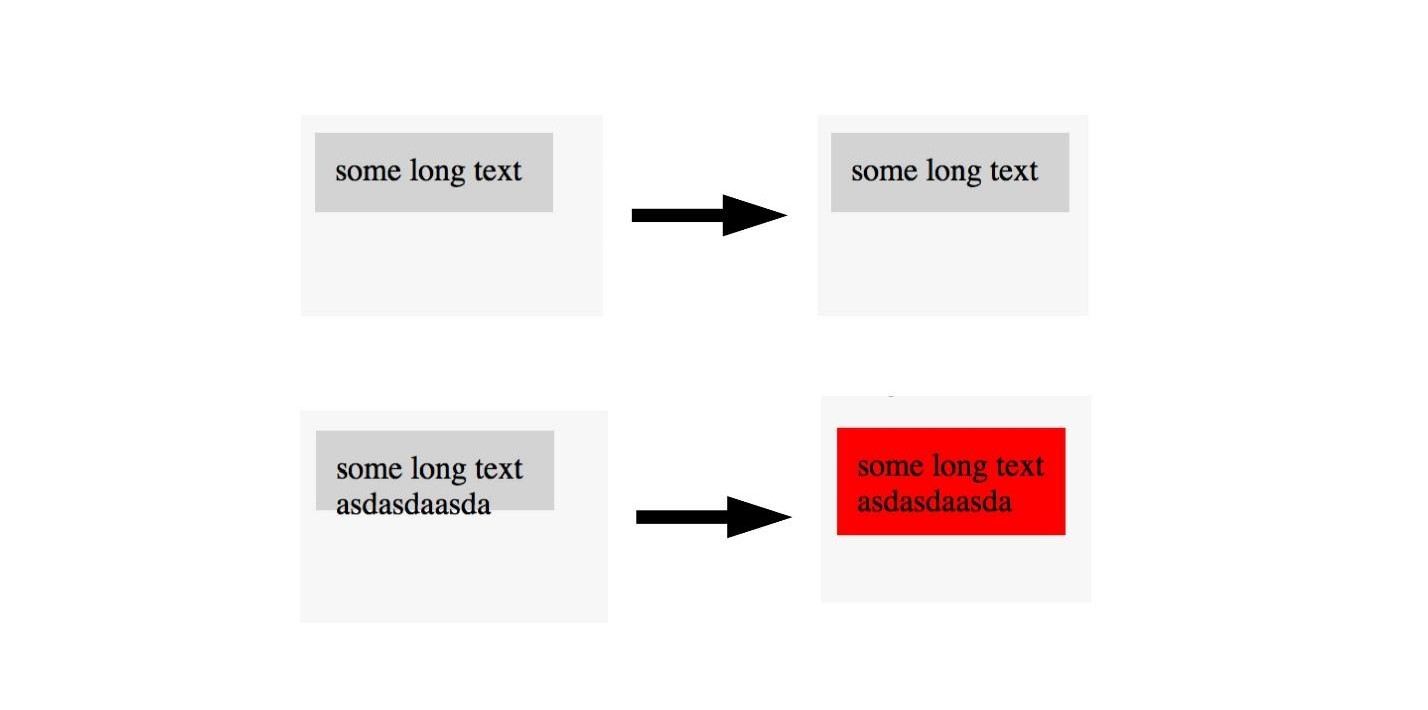
Jika kami melihat gambar dengan tata letak yang baik, maka kami tidak menandainya, dan kami menandai gambar dengan tata letak yang buruk. Dengan demikian, Anda dapat menguji tata letak dengan satu gambar. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
Alih-alih kesimpulan
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .