Catatan perev. : Insinyur terkemuka dari Zalando, Henning Jacobs, telah berulang kali memperhatikan masalah dengan pengguna Kubernetes dalam memahami tujuan penyelidikan liveness (dan kesiapan) dan aplikasi yang benar. Oleh karena itu, ia mengumpulkan pemikirannya dalam artikel luas ini, yang seiring waktu akan menjadi bagian dari dokumentasi K8.
Pemeriksaan kesehatan, yang dikenal dalam Kubernetes sebagai
penyelidikan liveness (yaitu, secara harfiah, "tes viabilitas" - kira-kira. Terjemahan) , bisa sangat berbahaya. Saya sarankan untuk menghindarinya sedapat mungkin: satu-satunya pengecualian adalah kasus ketika mereka benar-benar diperlukan dan Anda sepenuhnya menyadari secara spesifik dan konsekuensi dari penggunaannya. Publikasi ini akan fokus pada pemeriksaan liveness dan readiness, dan juga akan menjelaskan dalam hal apa
layak dan tidak layak menggunakannya.
Kolega saya, Sandor, baru-baru ini berbagi di Twitter tentang kesalahan paling umum yang ia temui, termasuk yang terkait dengan penggunaan kesiapan / penyelidikan:
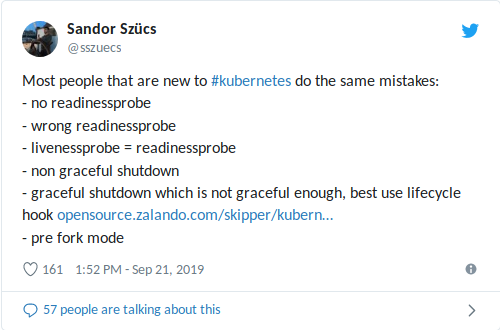
livenessProbe dikonfigurasi dengan tidak tepat dapat memperburuk situasi dengan beban tinggi (penutupan longsor + kemungkinan peluncuran jangka panjang dari wadah / aplikasi) dan menyebabkan konsekuensi negatif lainnya seperti penurunan dependensi
(lihat juga artikel terakhir saya tentang membatasi jumlah permintaan dalam bundel K3s + ACME) . Lebih buruk lagi, ketika penyelidikan liveness digabungkan dengan pemeriksaan kesehatan, yang bertindak sebagai basis data eksternal:
satu -
satunya kegagalan basis data akan memulai kembali semua wadah Anda !
Pesan umum
“Jangan gunakan probe lives” dalam kasus ini sedikit membantu, oleh karena itu, kami akan mempertimbangkan untuk apa kesiapan dan pemeriksaan liveness.
Catatan: Sebagian besar tes di bawah ini awalnya termasuk dalam dokumentasi internal untuk pengembang Zalando.Pemeriksaan Kesiapan dan Lives
Kubernetes menyediakan dua mekanisme penting yang disebut
probe liveness dan probe readiness . Mereka secara berkala melakukan beberapa tindakan - misalnya, mengirim permintaan HTTP, membuka koneksi TCP, atau menjalankan perintah dalam wadah - untuk mengonfirmasi bahwa aplikasi berfungsi dengan baik.
Kubernetes menggunakan
probe kesiapan untuk memahami kapan sebuah kontainer siap menerima lalu lintas. Sebuah pod dianggap siap untuk digunakan jika semua kontainernya sudah siap. Salah satu aplikasi mekanisme ini adalah untuk mengontrol pod mana yang digunakan sebagai backend untuk layanan Kubernetes (dan terutama Ingress).
Probe Liveness membantu Kubernet memahami kapan saatnya memulai ulang wadah. Misalnya, pemeriksaan semacam itu memungkinkan Anda untuk mencegat kebuntuan ketika aplikasi "macet" di satu tempat. Restart wadah dalam keadaan ini membantu memindahkan aplikasi dari tanah, meskipun ada kesalahan, tetapi juga dapat menyebabkan kegagalan berjenjang (lihat di bawah).
Jika Anda mencoba menyebarkan pembaruan ke aplikasi yang gagal memeriksa liveness / readiness, meluncurkannya akan berhenti karena Kubernetes akan menunggu status
Ready dari semua pod.
Contoh
Berikut adalah contoh pemeriksaan kesiapan yang memeriksa jalur
/health melalui HTTP dengan pengaturan default (
interval : 10 detik,
batas waktu : 1 detik,
ambang batas keberhasilan : 1,
ambang batas kegagalan : 3):
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
Rekomendasi
- Untuk layanan microser dengan titik akhir HTTP (REST, dll.) Selalu tentukan probe kesiapan yang memeriksa apakah aplikasi (pod) siap menerima lalu lintas.
- Pastikan probe kesiapan mencakup ketersediaan port server web yang sebenarnya :
- Menggunakan port untuk kebutuhan administratif yang disebut "admin" atau "manajemen" (misalnya, 9090) untuk
readinessProbe , pastikan bahwa endpoint mengembalikan OK hanya jika port HTTP utama (seperti 8080) siap menerima lalu lintas *;
* Saya tahu setidaknya satu kasus di Zalando ketika ini tidak terjadi, yaitu, readinessProbe memeriksa port “management”, tetapi server itu sendiri tidak memulai karena masalah dengan memuat cache. - menggantung pemeriksaan kesiapan pada port terpisah dapat mengarah pada fakta bahwa kemacetan di port utama tidak akan tercermin dalam pemeriksaan kesehatan (yaitu, kumpulan utas di server penuh, tetapi pemeriksaan kesehatan masih menunjukkan bahwa semuanya baik-baik saja).
- Pastikan pemeriksaan kesiapan memungkinkan inisialisasi / migrasi basis data ;
- cara termudah untuk mencapai ini adalah dengan mengakses server HTTP hanya setelah inisialisasi selesai (misalnya, migrasi basis data dari Flyway , dll.); yaitu, alih-alih mengubah status pemeriksaan kesehatan, cukup jangan memulai server web sampai migrasi database * selesai.
* Anda juga dapat menjalankan migrasi basis data dari wadah init di luar pod. Saya masih penggemar aplikasi mandiri, yaitu di mana wadah aplikasi, tanpa koordinasi eksternal, tahu bagaimana membawa database ke keadaan yang diinginkan.
- Gunakan
httpGet untuk pemeriksaan kesiapan melalui titik akhir khas pemeriksaan kesehatan (mis. /health ). successThreshold: 1 pengaturan successThreshold: 1 ( interval: 10s , timeout: 1s , successThreshold: 1 , failureThreshold: 3 ):- parameter default berarti bahwa pod akan menjadi tidak siap setelah sekitar 30 detik (3 pemeriksaan kesehatan gagal).
- Gunakan port terpisah untuk "admin" atau "manajemen" jika tumpukan teknologi (misalnya, Java / Spring) memungkinkan ini untuk memisahkan manajemen kesehatan dan metrik dari lalu lintas normal:
- tapi jangan lupa tentang paragraf 2.
- Jika perlu, probe kesiapan dapat digunakan untuk menghangatkan / memuat cache dan mengembalikan kode status 503 sampai wadah "dihangatkan":
- Saya juga merekomendasikan agar Anda membiasakan diri dengan pemeriksaan
startupProbe baru, yang muncul dalam versi 1.16 (kami menulis tentang itu dalam bahasa Rusia di sini - sekitar terjemahan.) .
Peringatan
- Jangan mengandalkan dependensi eksternal (seperti penyimpanan data) saat melakukan tes kesiapan / semangat - ini dapat menyebabkan kegagalan cascading:
- sebagai contoh, mari kita ambil layanan REST stateful dengan 10 pod tergantung pada satu database Postgres: ketika cek tergantung pada koneksi yang bekerja ke database, semua 10 pod dapat jatuh jika ada keterlambatan dalam jaringan / di sisi database - biasanya semuanya berakhir lebih buruk daripada yang bisa;
- perhatikan bahwa Spring Data secara default memeriksa koneksi ke database *;
* Ini adalah perilaku default dari Spring Data Redis (setidaknya seperti ketika saya memeriksa terakhir kali), yang menyebabkan kegagalan "bencana": ketika Redis tidak tersedia untuk waktu yang singkat, semua polong "jatuh". - "Eksternal" dalam pengertian ini juga dapat berarti polong lain dari aplikasi yang sama, yaitu, idealnya, cek tidak harus tergantung pada keadaan polong lain dari kluster yang sama untuk mencegah crash cascading:
- hasil dapat bervariasi untuk aplikasi status terdistribusi (mis. cache dalam-memori dalam pod).
- Jangan gunakan probe liveness untuk polong (pengecualian adalah kasus ketika mereka benar-benar diperlukan dan Anda sepenuhnya menyadari spesifik dan konsekuensi dari penggunaannya):
- penyelidikan liveness dapat membantu memulihkan wadah yang "hang", tetapi karena Anda memiliki kontrol penuh atas aplikasi Anda, hal-hal seperti proses "hang" dan kebuntuan idealnya tidak terjadi: alternatif terbaik adalah dengan sengaja menjatuhkan aplikasi dan mengembalikannya ke kondisi stabil sebelumnya;
- penyelidikan liveness yang gagal akan memulai ulang wadah, sehingga berpotensi memperburuk konsekuensi dari kesalahan pemuatan: memulai kembali wadah akan menghasilkan waktu henti (setidaknya untuk waktu peluncuran aplikasi, katakanlah, selama lebih dari 30 detik), menyebabkan kesalahan baru, menambah beban pada wadah lain dan meningkatkan kemungkinan kegagalannya, dll.
- pemeriksaan liveness dikombinasikan dengan ketergantungan eksternal adalah kombinasi yang paling buruk, yang dapat menyebabkan kegagalan berjenjang: sedikit keterlambatan di sisi database akan menyebabkan semua wadah Anda untuk memulai kembali!
- Parameter untuk pemeriksaan vitalitas dan kesiapan harus berbeda :
- Anda dapat menggunakan probe liveness dengan pemeriksaan kesehatan yang sama, tetapi ambang yang lebih tinggi (
failureThreshold ), misalnya, menetapkan status tidak siap setelah 3 upaya dan menganggap bahwa probe liveness gagal setelah 10 upaya;
- Jangan gunakan cek exec , karena terkait dengan masalah yang diketahui yang menyebabkan munculnya proses zombie:
Ringkasan
- Gunakan probe kesiapan untuk menentukan kapan pod siap menerima lalu lintas.
- Gunakan probe liveness hanya ketika mereka benar-benar dibutuhkan.
- Penggunaan kesiapan / penyelidikan yang salah dapat menyebabkan berkurangnya ketersediaan dan kegagalan.

Materi tambahan tentang topik tersebut
Perbarui No1 dari 2019-09-29
Tentang wadah init untuk migrasi basis data : catatan kaki ditambahkan.
EJ mengingatkan saya pada PDB: salah satu masalah pemeriksaan liveness adalah kurangnya koordinasi antara polong. Kubernetes memiliki
Anggaran Gangguan Pod (PDB) untuk membatasi jumlah kegagalan bersamaan yang mungkin dialami aplikasi, tetapi pemeriksaan tidak memperhitungkan PDB akun. Idealnya, kita dapat memesan K8: "Restart satu pod jika verifikasi gagal, tetapi jangan restart semuanya agar tidak membuatnya lebih buruk."
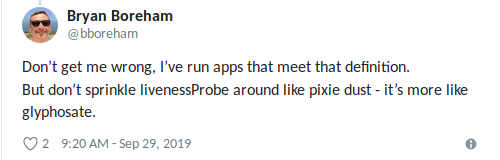
Bryan diformulasikan dengan sempurna : "Gunakan liveness terdengar ketika Anda tahu pasti bahwa
hal terbaik yang dapat Anda lakukan adalah" membunuh "aplikasi " (sekali lagi, jangan terbawa suasana).
Perbarui No.2 dari 2019-09-29
Mengenai membaca dokumentasi sebelum digunakan : Saya membuat
permintaan fitur untuk melengkapi dokumentasi tentang probe liveness.
PS dari penerjemah
Baca juga di blog kami: