Bagaimana cara menguji ide, arsitektur dan algoritma tanpa menulis kode? Bagaimana cara merumuskan dan memverifikasi propertinya? Apa itu pemeriksa model dan pencari model? Apa yang harus dilakukan ketika kemampuan pengujian tidak cukup?
Hai Nama saya Vasil Dyadov, sekarang saya bekerja sebagai programmer di Yandex.Mail, sebelum saya bekerja di Intel, saya sebelumnya telah mengembangkan kode RTL (register transfer level) pada Verilog / VHDL untuk ASIC / FPGA. Saya telah lama menyukai topik keandalan perangkat lunak dan perangkat keras, matematika, alat, dan metode yang digunakan untuk mengembangkan perangkat lunak dan logika dengan properti yang telah ditentukan sebelumnya.
Ini adalah artikel kedua dalam seri (artikel pertama di sini ), yang dirancang untuk menarik perhatian pengembang dan manajer terhadap pendekatan rekayasa untuk pengembangan perangkat lunak. Baru-baru ini, ia telah diabaikan dengan tidak patut, meskipun ada perubahan revolusioner dalam pendekatan dan alat pendukungnya.
Artikel pertama bagi sebagian pembaca tampaknya terlalu abstrak. Banyak yang ingin melihat contoh penggunaan pendekatan teknik dan spesifikasi formal dalam kondisi yang dekat dengan kenyataan.
Pada artikel ini, kita akan melihat contoh aplikasi nyata dari TLA + untuk memecahkan masalah praktis.
Saya selalu terbuka untuk membahas masalah yang terkait dengan pengembangan perangkat lunak, dan saya akan senang mengobrol dengan pembaca (koordinat untuk komunikasi ada di profil saya).
Apa itu TLA +?
Untuk mulai dengan, saya ingin mengatakan beberapa kata tentang TLA + dan TLC.
TLA + (Temporal Logic of Actions + Data) adalah formalisme yang didasarkan pada semacam logika temporal. Dirancang oleh Leslie Lamport.
Dalam kerangka formalisme ini, seseorang dapat menggambarkan ruang varian perilaku sistem dan sifat-sifat perilaku ini.
Untuk kesederhanaan, kita dapat mengasumsikan bahwa perilaku sistem diwakili oleh urutan keadaannya (seperti manik-manik yang tak terbatas, bola pada tali), dan rumus TLA + mendefinisikan kelas rantai yang menggambarkan semua varian yang mungkin dari perilaku sistem (sejumlah besar manik-manik).
TLA + sangat cocok untuk menggambarkan mesin negara hingga non-deterministik yang berinteraksi (misalnya, interaksi layanan dalam suatu sistem), meskipun ekspresifitasnya cukup untuk menggambarkan banyak hal lain (yang dapat diekspresikan dalam logika orde pertama).
Dan TLC adalah pemeriksa model keadaan eksplisit: sebuah program yang, sesuai dengan deskripsi sistem TLA + dan rumus properti yang diberikan, beralih ke status sistem dan menentukan apakah sistem memenuhi properti yang ditentukan.
Biasanya, bekerja dengan TLA + / TLC dibangun dengan cara ini: kami menggambarkan sistem dalam TLA +, memformalkan properti menarik di TLA +, menjalankan TLC untuk verifikasi.
Karena tidak mudah untuk secara langsung menggambarkan sistem yang lebih atau kurang kompleks dalam TLA +, bahasa tingkat yang lebih tinggi diciptakan - PlusCal, yang diterjemahkan ke dalam TLA +. PlusCal ada dalam dua cara: dengan sintaks Pascal dan C-like. Dalam artikel yang saya gunakan sintaksis seperti Pascal, menurut saya lebih baik dibaca. PlusCal sehubungan dengan TLA + kira-kira sama dengan C sehubungan dengan assembler.
Di sini kita tidak akan masuk jauh ke dalam teori. Literatur untuk pencelupan dalam TLA + / PlusCal / TLC disediakan di akhir artikel.
Tugas utama saya adalah menunjukkan aplikasi TLA + / TLC dalam contoh kehidupan nyata yang sederhana dan mudah dipahami.
Dalam beberapa komentar pada artikel sebelumnya, saya ditegur bahwa saya tidak melukis fondasi teoritis alat, tetapi tujuan dari seri artikel ini adalah untuk menunjukkan aplikasi praktis alat untuk pendekatan teknik dalam pengembangan perangkat lunak.
Saya pikir perendaman mendalam dalam teori ini tidak terlalu menarik bagi siapa pun, tetapi jika Anda tertarik, Anda selalu dapat pergi ke PM untuk tautan dan penjelasan, dan sejauh yang saya punya cukup pengetahuan (lagipula, saya bukan ahli teori matematika, tetapi seorang insinyur perangkat lunak), saya akan mencoba menjawab .
Pernyataan masalah
Pertama, saya akan berbicara sedikit tentang tugas yang digunakan TLA +.
Tugas tersebut terkait dengan pemrosesan aliran peristiwa. Yaitu, untuk membuat antrian untuk menyimpan acara dan mengirim pemberitahuan tentang acara ini.
Gudang data diatur secara fisik berdasarkan DBMS PostgreSQL.
Hal utama yang perlu Anda ketahui:
- Ada sumber acara. Untuk tujuan kita, kita dapat membatasi diri pada kenyataan bahwa setiap peristiwa dicirikan oleh waktu di mana prosesnya direncanakan. Sumber-sumber ini menulis peristiwa ke database. Biasanya waktu penulisan ke basis data dan waktu pemrosesan yang direncanakan tidak berhubungan dengan cara apa pun.
- Ada proses koordinasi yang membaca acara dari database dan mengirim pemberitahuan acara mendatang ke komponen-komponen sistem yang harus menanggapi pemberitahuan ini.
- Persyaratan mendasar: kita tidak boleh kehilangan acara. Pemberitahuan acara dalam kasus ekstrem dapat diulangi, yaitu harus ada jaminan setidaknya satu kali . Dalam sistem terdistribusi, sangat sulit untuk menerapkan jaminan hanya sekali (bahkan mungkin tidak mungkin, tetapi perlu dibuktikan) tanpa mekanisme konsensus, dan mereka (setidaknya semua yang saya tahu) memiliki efek yang sangat kuat pada sistem dalam hal keterlambatan dan throughput.
Sekarang beberapa detail:
- Ada banyak proses sumber, mereka dapat menghasilkan jutaan (dalam kasus terburuk) peristiwa jatuh ke dalam interval waktu yang sempit.
- Acara dapat dihasilkan baik untuk masa depan dan untuk waktu yang lalu (misalnya, jika proses sumber telah melambat dan merekam acara untuk saat yang telah berlalu).
- Prioritas pemrosesan acara adalah dalam waktu, mis., Kita harus terlebih dahulu memproses acara yang paling awal.
- Untuk setiap peristiwa, proses sumber menghasilkan angka acak worker_id , karena peristiwa yang didistribusikan di antara koordinator.
- Ada beberapa proses koordinasi (skala sesuai dengan kebutuhan berdasarkan beban sistem).
- Setiap proses koordinator memproses acara untuk set worker_id sendiri, yaitu, karena worker_id, kami menghindari persaingan antara koordinator dan kebutuhan akan kunci.
Seperti yang dapat dilihat dari deskripsi, kita hanya dapat mempertimbangkan satu proses koordinasi dan tidak memperhitungkan pekerja_id dalam tugas kita.
Artinya, untuk kesederhanaan, kami menganggap bahwa:
- Ada banyak proses sumber.
- Proses koordinasi adalah satu.
Saya akan menjelaskan evolusi ide untuk menyelesaikan masalah ini secara bertahap, sehingga lebih mudah dipahami bagaimana pemikiran berkembang dari implementasi yang sederhana menjadi yang dioptimalkan.
Keputusan dahi
Kami akan membuat piring untuk acara di mana kami akan menyimpan acara dalam bentuk hanya stempel waktu (kami tidak tertarik pada parameter lain dalam tugas ini). Mari kita membangun indeks pada bidang cap waktu .
Tampaknya menjadi solusi yang sangat normal.
Hanya ada masalah dengan skalabilitas: semakin banyak peristiwa, semakin lambat operasi basis data.
Acara dapat datang untuk waktu yang lalu, sehingga koordinator harus terus meninjau seluruh waktu.
Masalahnya dapat dipecahkan secara luas dengan memecah basis data menjadi pecahan oleh waktu, dll. Tapi ini adalah cara yang intensif sumber daya.
Akibatnya, pekerjaan koordinator akan melambat, karena Anda harus membaca dan menggabungkan data dari beberapa basis data.
Sulit untuk menerapkan caching acara di koordinator sehingga tidak pergi ke pangkalan untuk memproses setiap acara.
Lebih banyak basis data - lebih banyak masalah toleransi kesalahan.
Dan sebagainya.
Kami tidak akan membahas solusi frontal ini secara terperinci, karena ini sepele dan tidak menarik.
Optimasi pertama
Mari kita lihat bagaimana cara meningkatkan solusi frontal.
Untuk mengoptimalkan akses ke basis data, Anda dapat sedikit mempersulit indeks, menambahkan pengenal yang meningkat secara monoton ke peristiwa yang akan dihasilkan saat melakukan transaksi dalam basis data. Artinya, acara sekarang ditandai oleh pasangan {time, id} , di mana waktu adalah waktu di mana acara dijadwalkan, id adalah penghitung yang meningkat secara monoton. Ada jaminan keunikan id untuk setiap peristiwa, tetapi tidak ada jaminan bahwa nilai id berjalan tanpa lubang (yaitu, bisa ada urutan seperti itu: 1 , 2 , 7 , 15 ).
Tampaknya sekarang kita dapat menyimpan pengidentifikasi peristiwa baca terakhir dalam proses koordinator dan, saat mengambil, pilih peristiwa dengan pengidentifikasi lebih besar dari peristiwa yang diproses terakhir.
Tapi di sini masalah segera muncul: proses sumber dapat merekam acara dengan timestamp jauh di masa depan. Maka kita harus terus-menerus mempertimbangkan serangkaian peristiwa dengan pengidentifikasi kecil dalam proses koordinasi, waktu pemrosesan yang belum tiba.
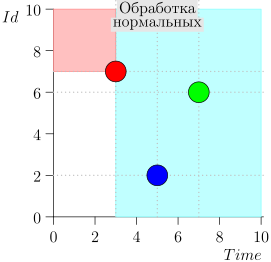
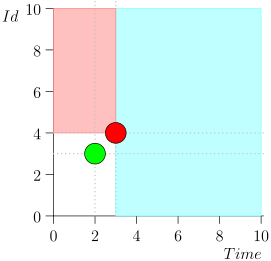
Anda dapat melihat bahwa peristiwa relatif terhadap waktu saat ini dibagi menjadi dua kelas:
- Acara dengan stempel waktu di masa lalu, tetapi dengan pengidentifikasi besar. Mereka ditulis ke database baru-baru ini, setelah kami memproses interval waktu itu. Ini adalah acara dengan prioritas tinggi, dan harus diproses terlebih dahulu agar notifikasi - yang sudah terlambat - bahkan tidak terlambat.
- Acara direkam sekali waktu dengan perangko waktu dekat dengan saat ini. Peristiwa semacam itu akan memiliki nilai pengidentifikasi rendah.
Dengan demikian, keadaan saat ini dari proses koordinator ditandai oleh pasangan {state.time, state.id}.
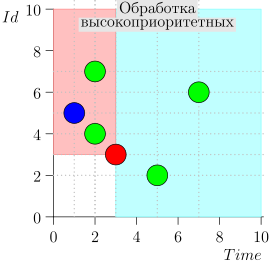
Ternyata peristiwa dengan prioritas tinggi di sebelah kiri dan di atas titik ini (wilayah merah muda), dan acara normal di sebelah kanan (biru muda):
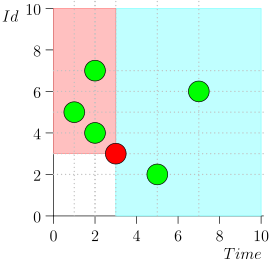
Bagan arus
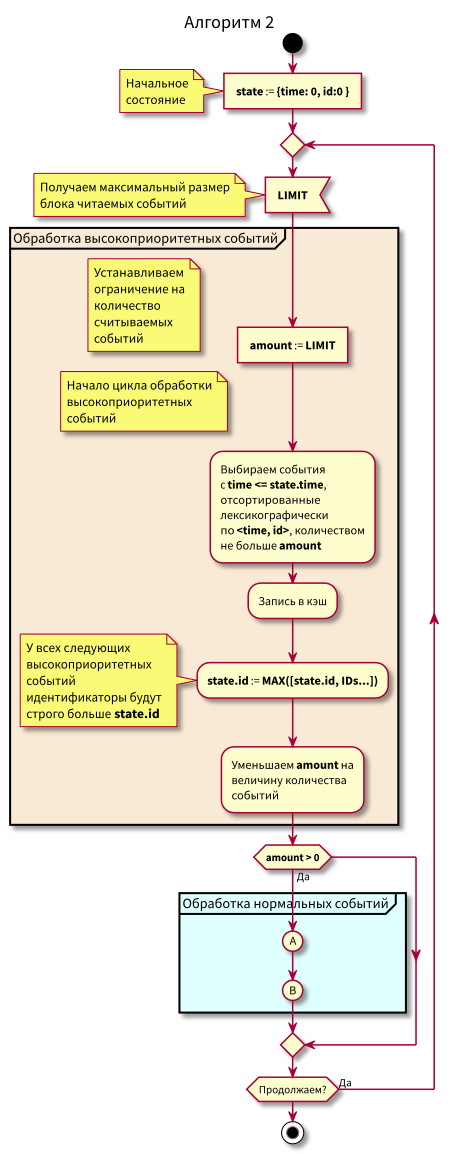
Algoritma kerja koordinator adalah sebagai berikut:
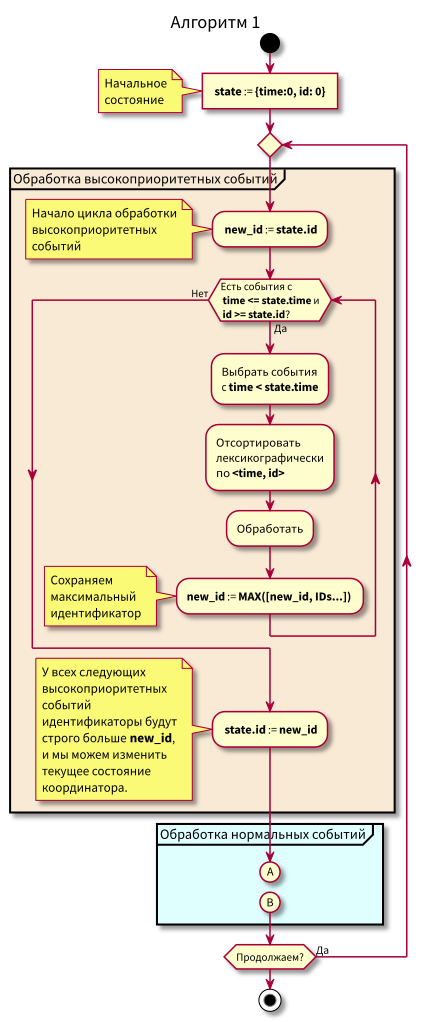
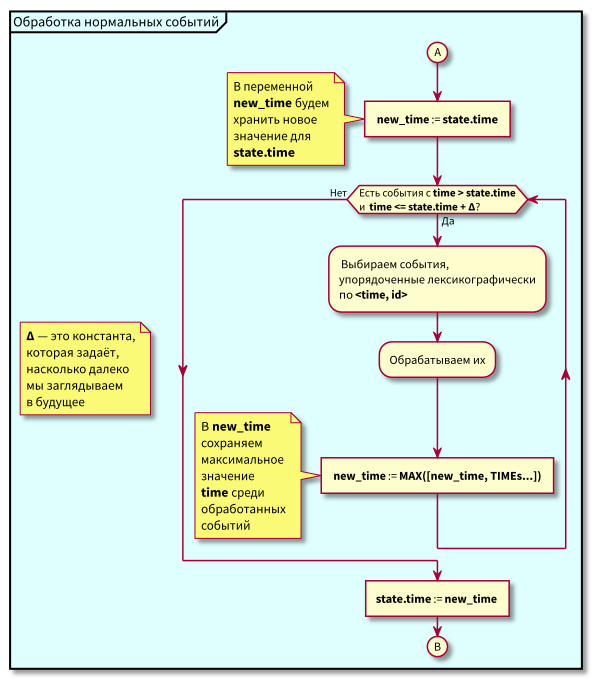
Saat mempelajari algoritme, pertanyaan dapat muncul:
- Bagaimana jika pemrosesan peristiwa normal dimulai dan pada saat itu peristiwa baru di masa lalu tiba (di wilayah merah muda), tidakkah mereka akan hilang? Jawab: mereka akan diproses dalam siklus berikutnya untuk memproses acara dengan prioritas tinggi. Mereka tidak bisa tersesat, karena id mereka dijamin lebih tinggi dari state.id.
- Bagaimana jika setelah memproses semua peristiwa normal - pada saat beralih ke pemrosesan acara prioritas tinggi - peristiwa baru dengan stempel waktu dari interval [state.time, state.time + Delta] tiba, apakah kita kehilangan mereka? Jawaban: mereka akan jatuh ke area merah muda, karena mereka akan punya waktu <state.time dan id > state.id: mereka tiba baru-baru ini, dan id meningkat secara monoton.
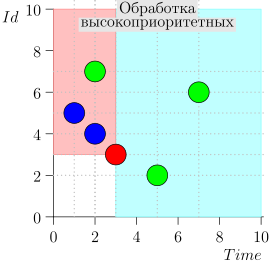
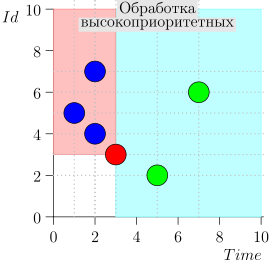
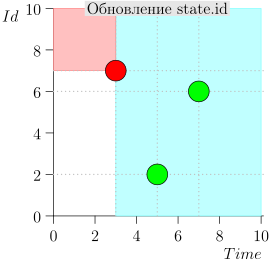
Contoh Pengoperasian Algoritma
Mari kita lihat beberapa langkah dari algoritma ini:
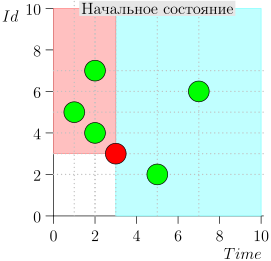
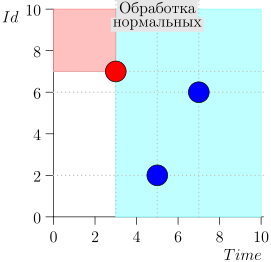
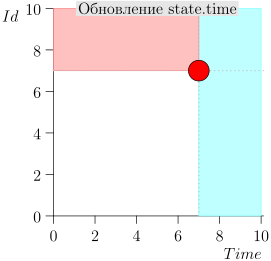
Model
Kami akan memastikan bahwa algoritme tidak ketinggalan acara dan semua pemberitahuan akan dikirim: kami akan membuat model sederhana dan memverifikasinya.
Untuk model kami menggunakan TLA +, lebih tepatnya PlusCal, yang diterjemahkan menjadi TLA +.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
Seperti yang Anda lihat, uraiannya relatif kecil, meskipun ada bagian definisi yang agak banyak (definisikan), yang dapat diambil dalam modul terpisah, dan kemudian digunakan kembali.
Dalam komentar saya mencoba menjelaskan apa yang terjadi dalam model. Semoga ini
Saya berhasil dan tidak perlu melukis model lebih detail.
Saya hanya ingin mengklarifikasi satu hal mengenai atomitas transisi antara status dan fitur pemodelan.
Pemodelan dilakukan dengan melakukan langkah-langkah proses atom. Dalam satu transisi, satu langkah atom dari suatu proses dilakukan di mana langkah ini dapat dilakukan. Pilihan langkah dan proses adalah non-deterministik: selama pemodelan, semua rantai langkah atom yang mungkin dari semua proses diurutkan.
Mungkin timbul pertanyaan: bagaimana dengan memodelkan paralelisme sejati, ketika kita secara bersamaan melakukan beberapa langkah atom dalam proses yang berbeda?
Pertanyaan ini Leslie Lamport telah lama dijawab dalam buku Specifying Systems dan karya-karya lainnya.
Saya tidak akan mengutip jawaban sepenuhnya, secara singkat intinya adalah: jika tidak ada skala waktu yang tepat di mana setiap peristiwa terkait dengan momen tertentu, maka tidak ada perbedaan dalam pemodelan peristiwa paralel sebagai peristiwa sekuensial yang terjadi secara non-deterministik, karena kita selalu dapat berasumsi bahwa satu peristiwa terjadi lebih awal daripada yang lain nilai sangat kecil.
Tetapi yang benar-benar penting adalah alokasi langkah-langkah atom yang kompeten. Jika jumlahnya terlalu banyak, maka ledakan kombinatorial ruang negara akan terjadi. Jika Anda mengambil langkah yang lebih sedikit dari yang diperlukan, atau memilihnya secara tidak benar - yaitu, probabilitas kehilangan status / transisi yang tidak valid (mis., Kami akan kehilangan kesalahan pada model).
Untuk memecah proses menjadi langkah-langkah atom, Anda harus memiliki ide yang bagus tentang bagaimana sistem bekerja dalam hal ketergantungan proses pada data dan mekanisme sinkronisasi.
Sebagai aturan, proses pemisahan menjadi langkah-langkah atom tidak menyebabkan masalah besar. Dan jika ya, maka itu menunjukkan kurangnya pemahaman tentang masalah, dan bukan tentang masalah dengan menyusun model dan menulis spesifikasi TLA +. Ini adalah fitur lain yang sangat berguna dari spesifikasi formal: mereka memerlukan studi dan analisis menyeluruh.
masalah Sebagai aturan, jika tugas itu bermakna dan dipahami dengan baik, tidak ada masalah dengan formalisasi.
Cek model
Untuk pemodelan saya akan menggunakan TLA-toolbox. Anda tentu saja dapat menjalankan semuanya dari baris perintah, tetapi IDE masih lebih nyaman, terutama untuk mulai belajar tentang pemodelan menggunakan TLA +.
Penciptaan proyek dijelaskan dengan baik dalam manual, artikel dan buku, tautan yang saya kutip di akhir artikel, jadi saya tidak akan mengulangi lagi. Satu-satunya hal yang saya akan menarik perhatian Anda adalah pengaturan simulasi.
TLC adalah pemeriksa model dengan pemeriksaan keadaan eksplisit. Jelas bahwa ruang negara harus dibatasi oleh batasan yang masuk akal. Di satu sisi, itu harus cukup besar untuk dapat memverifikasi properti yang menarik bagi kami, dan di sisi lain, cukup kecil untuk simulasi diselesaikan dalam waktu yang dapat diterima menggunakan sumber daya yang dapat diterima.
Ini adalah titik yang cukup rumit, di sini Anda perlu memahami sifat-sifat sistem dan model. Tetapi dengan cepat disertai dengan pengalaman. Sebagai permulaan, Anda cukup menetapkan batas maksimum yang mungkin masih dapat diterima dalam hal waktu simulasi dan sumber daya yang dikonsumsi.
Ada juga mode memeriksa bukan seluruh ruang negara, tetapi rantai selektif ke kedalaman tertentu. Terkadang juga mungkin dan perlu untuk digunakan.
Kami kembali ke pengaturan simulasi.
Pertama, kami mendefinisikan batasan ruang keadaan sistem. Keterbatasan diatur di bagian Advanced Options / State constraintaint simulasi simulasi.
Di sana saya menunjukkan ekspresi TLA +: Cardinality(Events) <= 5 /\ Event_Id <= 5 ,
di mana Event_Id adalah batas atas pada nilai pengidentifikasi acara, Cardinality(Events) adalah ukuran kumpulan catatan acara (terbatas model dasar
data oleh lima catatan dalam piring).
Dalam simulasi, TLC hanya akan melihat kondisi di mana rumus ini benar.
Anda masih dapat mengizinkan transisi status yang valid ( Opsi Lanjut / Kendala Tindakan ),
tapi kami tidak membutuhkannya.
Selanjutnya, kami menunjukkan rumus TLA + yang menggambarkan sistem kami: Model Overview / Temporal Formula = Spec , di mana Spec adalah nama rumus TLA + yang diautogasi secara otomatis oleh PlusCal (dalam kode model di atas bukan: untuk menghemat ruang, saya tidak mengutip hasil menerjemahkan PlusCal ke TLA +) .
Pengaturan selanjutnya yang perlu diperhatikan adalah pemeriksaan kebuntuan.
(centang pada Model Overview / Deadlock ). Ketika bendera ini diaktifkan, TLC akan memeriksa model untuk status "menggantung", yaitu yang tidak ada transisi keluar. Jika ada keadaan seperti itu di ruang keadaan, ini berarti kesalahan yang jelas dalam model. Atau di TLC, yang, seperti program non-sepele lainnya, tidak kebal dari kesalahan :) Dalam praktik saya (tidak begitu besar), saya belum menemukan kebuntuan.
Dan akhirnya, untuk semua pengujian ini dimulai, rumus keamanan dalam Model Overview / Invariants = ALL_EVENTS_PROCESSED(state) .
TLC akan memverifikasi validitas rumus di setiap negara, dan jika itu menjadi salah,
akan menampilkan pesan kesalahan dan menampilkan urutan status yang menyebabkan kesalahan.
Setelah memulai TLC, setelah bekerja selama sekitar 8 menit, dilaporkan "Tidak ada kesalahan". Ini berarti bahwa model diuji dan memenuhi properti yang ditentukan.
TLC juga menampilkan banyak statistik menarik. Sebagai contoh, untuk model ini, 7 677 824 keadaan unik diperoleh, secara total, TLC tampak pada 27109 029 negara, diameter ruang keadaan adalah 47 (ini adalah panjang maksimum rantai keadaan sebelum pengulangan,
panjang siklus maksimum dari kondisi tidak berulang dalam kondisi dan grafik transisi).
Jika kita membagi 27 juta negara bagian menjadi 8 menit, kita memperoleh sekitar 56 ribu negara bagian per detik, yang mungkin kelihatannya tidak terlalu cepat. Tetapi perlu diingat bahwa saya menjalankan simulasi pada laptop yang bekerja dalam mode hemat energi (saya memaksakan frekuensi inti menjadi 800 MHz, karena saya bepergian pada saat itu di kereta listrik), dan tidak mengoptimalkan model untuk kecepatan simulasi sama sekali.
Ada banyak cara untuk mempercepat simulasi: mulai dari mem-porting bagian dari kode model TLA + ke Jawa dan menghubungkan ke TLC dengan cepat (berguna untuk mempercepat semua jenis fungsi pembantu) hingga menjalankan TLC di awan dan pada kluster (Dukungan cloud Amazon dan Azure dibangun langsung ke TLC itu sendiri).
Optimasi kedua
Dalam algoritma sebelumnya, semuanya baik-baik saja, kecuali untuk beberapa masalah:
- Sampai kami memproses semua peristiwa dari zona biru dalam interval
[state.time, state.time + Delta] , kami tidak dapat beralih ke acara prioritas tinggi. Artinya, acara terlambat akan terlambat bahkan lebih. Dan biasanya penundaan itu tidak dapat diprediksi. Karena itu, state.time dapat jauh tertinggal dari waktu saat ini, dan ini adalah penyebab masalah berikutnya. - Acara yang tiba di wilayah acara normal mungkin terlambat ( id > state.id). Mereka sudah menjadi prioritas tinggi dan harus dianggap peristiwa dari wilayah merah muda, dan kami masih menganggapnya normal dan memperlakukannya seperti biasa.
- Sulit untuk mengatur penyimpanan acara caching dan cache (membaca dari database).
Jika dua poin pertama jelas, maka yang ketiga mungkin akan memunculkan sebagian besar pertanyaan. Mari kita bahas lebih detail.
Misalkan kita ingin terlebih dahulu membaca sejumlah peristiwa tetap ke dalam memori dan kemudian memprosesnya.
Setelah diproses, kami ingin menandai peristiwa dalam database dengan kueri blok yang diproses, karena jika Anda bekerja bukan dengan blok, tetapi dengan peristiwa tunggal, maka tidak akan ada keuntungan besar dari caching.
Misalkan kita telah memproses sebagian dari blok dan ingin menambah cache. Kemudian, jika terlambat acara prioritas tinggi tiba selama pemrosesan, kami dapat memprosesnya lebih awal.
Artinya, sangat diinginkan untuk dapat membaca peristiwa dalam blok kecil untuk memproses yang terlambat secepat mungkin, tetapi untuk memperbarui atribut pemrosesan dalam database dengan blok besar sekaligus - untuk efisiensi.
Apa yang harus dilakukan dalam kasus ini?
Cobalah untuk bekerja dengan database dalam blok kecil dengan area biru dan merah muda dan pindahkan titik negara bagian dalam langkah-langkah kecil.
Dengan demikian, cache diperkenalkan dan dibaca ke dalamnya dari basis data potongan data, setelah masing-masing membaca, titik status digeser agar tidak membaca kembali peristiwa yang sudah dibaca.
Sekarang algoritme telah menjadi sedikit lebih rumit, kami mulai membaca dalam porsi terbatas.
Bagan arus
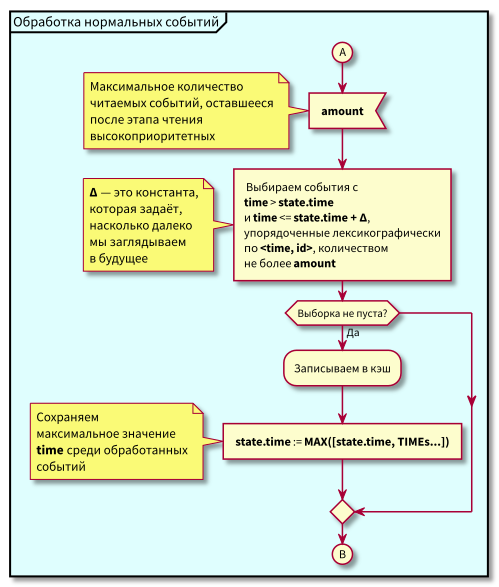
Dalam algoritma ini, dapat dilihat bahwa karena pembatasan pada blok peristiwa yang dapat dibaca, penundaan maksimum dalam transisi dari pemrosesan prioritas rendah ke pemrosesan prioritas tinggi akan sama dengan waktu pemrosesan maksimum blok.
Yaitu, sekarang kita dapat membaca peristiwa ke dalam cache dalam blok kecil, dan mengontrol penundaan maksimum dalam transisi untuk memproses peristiwa prioritas tinggi melalui kontrol ukuran blok maksimum untuk membaca.
Contoh Pengoperasian Algoritma
Mari kita lihat algoritma dalam pekerjaan, dalam langkah-langkah. Untuk kenyamanan, ambil LIMIT = 2 .
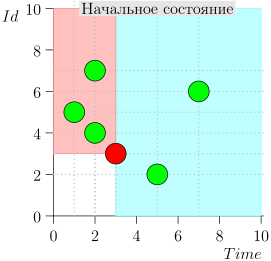
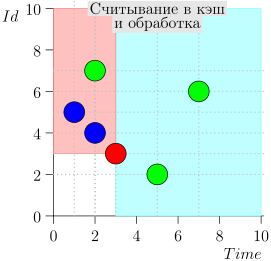
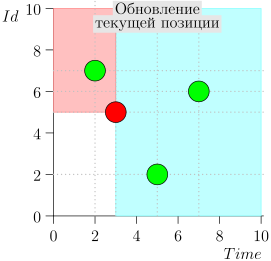
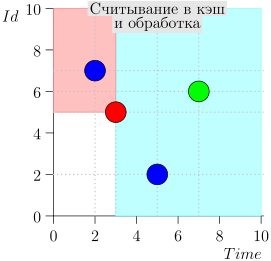
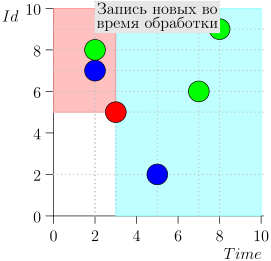
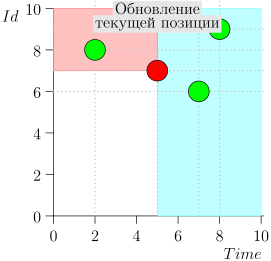
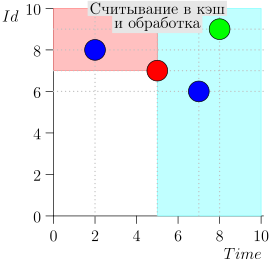
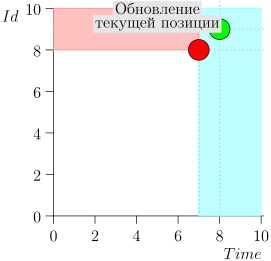
Ternyata masalah terpecahkan? Tapi tidak. (Jelas bahwa jika masalah telah dipecahkan sepenuhnya pada tahap ini, maka
artikel ini tidak akan :))
Kesalahannya?
Dalam bentuk ini, algoritma bekerja untuk waktu yang agak lama. Semua tes berjalan dengan baik. Tidak ada masalah dalam produksi juga.
Tetapi pengembang algoritma dan implementasinya (kolega saya Peter Reznikov) sangat berpengalaman, dan dia secara intuitif merasa ada sesuatu yang salah di sini. Oleh karena itu, pemeriksa dibuat di sebelah kode utama, yang diperiksa sesekali pada timer untuk melihat apakah ada peristiwa yang terlewat, dan
jika ada, saya memprosesnya.
Dalam bentuk ini, sistem bekerja dengan sukses. Benar, tidak ada yang menyimpan statistik tentang jumlah acara yang dipilih oleh pemeriksa. Jadi kami, sayangnya, tidak tahu berapa banyak kegagalan yang terkait dengan pemrosesan acara yang tidak tepat waktu.
Saya menerapkan antrian objek terikat waktu yang serupa. Membahas implementasi dan optimalisasi algoritma dengan Peter Reznikov, kami berbicara tentang algoritma ini untuk bekerja dengan acara. Mereka meragukan bahwa algoritme itu benar. Kami memutuskan untuk membuat model kecil untuk mengkonfirmasi atau menghilangkan keraguan. Akibatnya, kami menemukan kesalahan.
Model
Sebelum membongkar jejak dengan kesalahan, saya akan memberikan kode sumber model di mana kesalahan terdeteksi.
Perbedaan dari model sebelumnya sangat kecil, hanya ada batasan pada ukuran blok baca: operator Batas ditambahkan dan, oleh karena itu, operator pemilihan acara diubah.
Untuk menghemat ruang, saya hanya meninggalkan komentar pada bagian-bagian model yang berubah.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Pembaca yang penuh perhatian mungkin memperhatikan bahwa, selain memperkenalkan Limit, label pada event_processor juga telah diubah. Tujuannya adalah sedikit lebih baik untuk mensimulasikan kode nyata yang dieksekusi oleh dua pilihan dalam satu transaksi, yaitu, pemilihan peristiwa dapat dikatakan dilakukan secara atom.
Nah, dan jika kita menemukan kesalahan dalam model dengan operasi atom yang lebih besar, ini praktis menjamin bahwa kesalahan yang sama terjadi pada model yang sama, tetapi dengan langkah-langkah atom yang lebih kecil (pernyataan yang agak kuat, tapi saya pikir itu intuitif; meskipun itu harus baik jika tidak terbukti, kemudian diperiksa pada berbagai pilihan model).
Cek model
Kami memulai simulasi dengan parameter yang sama seperti pada perwujudan pertama.
Dan kami mendapatkan pelanggaran pada properti ALL_EVENTS_PROCESSED pada langkah ke-19 dari simulasi saat mencari dengan lebar.
Untuk data awal yang diberikan (ini adalah ruang keadaan yang sangat kecil), kesalahan pada langkah ke-19 menunjukkan bahwa kesalahan itu sangat jarang dan sulit untuk dideteksi, karena sebelum itu semua rantai negara dengan panjang kurang dari 19 diperiksa.
Karenanya, kesalahan ini sulit ditangkap dalam tes. Hanya jika Anda tahu ke mana harus mencari, dan secara khusus pilih tes dan pondok sementara.
Saya tidak akan membawa seluruh rute demi menghemat ruang dan waktu. Berikut adalah segmen dari beberapa negara bersama dengan kesalahan:
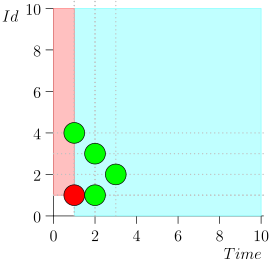

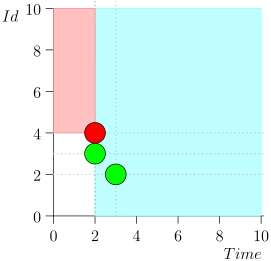
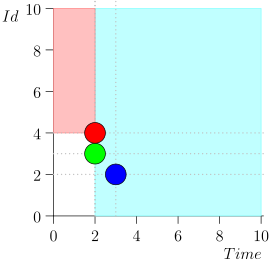
Analisis dan Koreksi
Apa yang terjadi
Seperti yang dapat Anda lihat, kesalahan itu memanifestasikan dirinya dalam kenyataan bahwa kami melewatkan acara {2, 3} karena fakta bahwa batas berakhir pada acara {2, 1}, dan setelah itu kami mengubah status koordinator. Ini bisa terjadi hanya jika pada suatu saat ada beberapa peristiwa.
Itu sebabnya kesalahan sulit dipahami dalam tes. Untuk manifestasinya, perlu bahwa hal-hal yang sangat jarang terjadi bersamaan:
- Beberapa peristiwa mencapai titik waktu yang sama.
- Batas pemilihan acara berakhir sebelum saat membaca semua acara ini.
Kesalahan dapat relatif mudah diperbaiki jika keadaan koordinator sedikit diperluas: tambahkan waktu dan pengidentifikasi acara baca terakhir dari area acara normal dengan id maksimum jika waktu acara ini sesuai dengan nilai state.time berikutnya.
Jika tidak ada acara seperti itu, maka kami mengatur status ekstra (extra_state) ke keadaan tidak valid (UNDEF_EVT) dan tidak memperhitungkannya saat bekerja.
Peristiwa-peristiwa dari wilayah normal yang tidak diproses pada langkah sebelumnya dari koordinator, kami akan mempertimbangkan prioritas yang sudah tinggi dan dengan demikian memperbaiki pemilihan predikat prioritas tinggi dan keselamatan.
Dimungkinkan untuk memperkenalkan area lain yang menengah antara prioritas tinggi dan normal, dan mengubah algoritme. Pertama, ia akan memproses yang berprioritas tinggi, kemudian yang menengah, dan kemudian beralih ke yang normal dengan perubahan status selanjutnya.
Tetapi perubahan seperti itu akan menghasilkan volume refactoring yang lebih besar dengan manfaat yang tidak terlihat (algoritme akan sedikit lebih jelas; keuntungan lainnya tidak langsung terlihat).
Oleh karena itu, kami memutuskan untuk hanya sedikit menyesuaikan keadaan saat ini dan pemilihan acara dari database.
Model yang disesuaikan
Berikut adalah model yang diperbaiki.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Seperti yang Anda lihat, perubahannya sangat kecil:
- Menambahkan data ekstra ke status extra_state.
- Mengubah pemilihan acara dengan prioritas tinggi.
- UpdateExtraState extra_state.
- safety - .
, . , (, , , ).
, , TLA+/TLC . :)
Kesimpulan
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
Buku
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Blog
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .