
Pendahuluan
Halo, orang Khabrovit terkasih!
Dua tahun terakhir pekerjaan saya di
Synesis telah terhubung erat dengan proses membuat dan mengembangkan
Synet - perpustakaan terbuka untuk menjalankan jaringan saraf convolutional pra-terlatih pada CPU. Dalam proses pekerjaan ini, saya harus menemukan sejumlah poin menarik yang berhubungan dengan optimalisasi algoritma propagasi sinyal langsung dalam jaringan saraf. Tampak bagi saya bahwa deskripsi poin-poin ini akan sangat menarik bagi para pembaca Habrahabr. Yang ingin saya persembahkan adalah serangkaian artikel saya. Durasi siklus akan tergantung pada minat Anda pada topik ini dan, tentu saja, pada kemampuan saya untuk mengatasi kemalasan. Saya ingin memulai siklus dengan deskripsi kerangka
sepeda itu sendiri. Pertanyaan-pertanyaan dari algoritma yang mendasari itu akan diungkapkan dalam artikel berikut:
- Lapisan Konvolusi: Teknik Optimalisasi Penggandaan Matriks
- Lapisan konvolusional: konvolusi cepat sesuai dengan metode Shmuel Vinograd
Jawaban atas pertanyaan
Sebelum memulai deskripsi terperinci tentang kerangka kerja, saya akan mencoba untuk segera menjawab sejumlah pertanyaan yang mungkin dimiliki pembaca. Pengalaman menunjukkan bahwa lebih baik melakukan ini sebelumnya, karena banyak yang segera mulai menulis komentar yang marah, tidak membaca sampai akhir.
Pertanyaan pertama yang biasanya muncul dalam kasus seperti itu:
Siapa yang menjalankan jaringan pada prosesor konvensional sekarang, kapan ada akselerator grafis dan akselerator tensor (matriks)?Saya akan menjawab ya - benar-benar tidak disarankan untuk melakukan pelatihan jaringan saraf pada CPU, tetapi menjalankan jaringan saraf siap pakai cukup diminati, terutama jika jaringannya cukup kecil. Alasan untuk ini mungkin berbeda, tetapi yang utama:
- CPU lebih umum. Tidak semua mesin memiliki GPU, terutama server.
- Pada jaringan saraf kecil, keuntungan dari menggunakan GPU kecil, dan kadang-kadang sama sekali tidak ada.
- Melibatkan GPU secara efektif untuk mempercepat jaringan saraf biasanya memerlukan struktur aplikasi yang jauh lebih kompleks.
Pertanyaan berikutnya yang mungkin:
Mengapa menggunakan solusi khusus untuk meluncurkan ketika ada Tensorflow , Caffe atau MXNet ?Anda dapat menjawab yang berikut:
- Berbagai kerangka kerja tidak selalu baik - jadi jika ada beberapa model yang dilatih dalam kerangka kerja yang berbeda dalam suatu proyek, maka Anda harus menanamkan semuanya ke dalam solusi siap pakai, yang sangat merepotkan.
- Kerangka kerja klasik dirancang untuk melatih model GPU - dan mereka pasti pandai dalam hal itu! Tetapi untuk menjalankan model yang terlatih pada CPU, fungsionalitasnya berlebihan dan tidak optimal.
- Konfirmasi kebutuhan akan solusi khusus adalah popularitas OpenVINO - kerangka kerja dari Intel, yang melakukan fungsi yang sama.
Di sini segera muncul pertanyaan logis tentang penemuan sepeda:
Mengapa menggunakan kerajinan Anda ketika ada solusi yang sepenuhnya profesional dari pemimpin dunia yang diakui?Jawaban saya adalah:
- Pada awal bekerja di Synet, OpenVINO masih dalam masa pertumbuhan. Dan sebenarnya, jika pada saat itu OpenVINO dalam keadaan saat ini, maka dengan tingkat probabilitas yang tinggi saya tidak akan terlibat dalam proyek saya sendiri.
- Anda dapat menyesuaikan kerangka kerja Anda sendiri dengan kebutuhan Anda. Jadi dalam kasus saya, persyaratan utama adalah kinerja single-threaded maksimum.
- Anda dapat memberikan dukungan untuk fungsionalitas baru secepat mungkin jika Anda tiba-tiba membutuhkannya (misalnya, menambahkan layer baru dan menghilangkan kesalahan kinerja).
- Mudah diintegrasikan ke dalam solusi turnkey.
- Fungsi perpustakaan pada platform selain x86 / x86_64 - misalnya, pada ARM.
Kemungkinan pembaca akan memiliki pertanyaan atau keberatan lain - tetapi saya masih tidak dapat memprediksikannya, dan karena itu saya akan menjawab dalam komentar di artikel tersebut. Sementara itu, mari kita mulai dengan deskripsi langsung Synet.
Deskripsi Singkat Sinkronisasi
Synet ditulis dalam
C ++ dan hanya berisi
file header . Optimalisasi platform-level rendah diimplementasikan di
Simd , proyek open-source lain yang didedikasikan untuk mempercepat pemrosesan gambar pada CPU. Dan ini adalah satu-satunya ketergantungan eksternal Synet (skema seperti itu dipilih untuk memfasilitasi integrasi perpustakaan ke dalam proyek pihak ketiga). Untuk meluncurkan jaringan saraf, model format internal mereka sendiri digunakan.
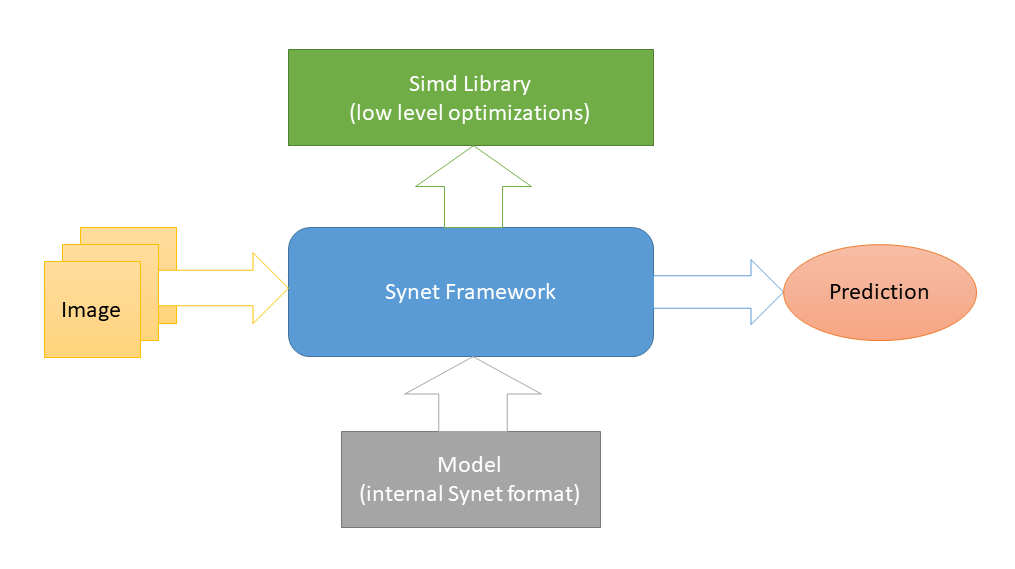
Konversi model pra-terlatih ke format internal dilakukan sesuai dengan skema dua langkah: 1) Pertama, konversi model ke format Inference Engine (baik
OpenVINO memiliki semua
alat yang diperlukan untuk ini). 2) Kemudian, dari representasi perantara ini, konversikan langsung ke format Synet internal.

Model Synet berisi dua file: 1) * .XML - file dengan deskripsi struktur model. 2) * .BIN - file dengan bobot yang terlatih.

Contoh sinkronisasi
Berikut ini adalah contoh penggunaan Synet untuk mendeteksi wajah. Model Mesin Inferensi asli diambil di
sini .
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
Sebagai hasil dari contoh, gambar dengan wajah beranotasi akan muncul:

Sekarang, mari kita ambil contoh langkah-langkahnya:
- Pertama, model dikonversi dari format Inference Engine ke Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
Pada kenyataannya, langkah ini dilakukan sekali, dan kemudian model yang sudah dikonversi digunakan di mana-mana. - Unduh model yang dikonversi:
Net net; net.Load("synet.xml", "synet.bin");
- Langkah opsional untuk mengubah ukuran gambar input dan batch (tentu saja, model harus mendukung ukuran gambar input):
net.Reshape(256, 256, 1);
- Memuat gambar dan membawanya ke ukuran input model:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- Memuat gambar ke dalam model:
net.SetInput(resized, 0.0f, 255.0f);
- Memulai propagasi sinyal langsung di jaringan:
net.Forward();
- Mendapatkan serangkaian wilayah dengan wajah yang ditemukan:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Perbandingan kinerja
Mungkin tidak sepenuhnya benar untuk membandingkan Synet dengan kerangka kerja klasik untuk pembelajaran mesin, misalnya, Mesin Inferensi
melewati mereka beberapa kali pada sejumlah tes .
Oleh karena itu, berikut ini adalah contoh membandingkan kinerja single-threaded dari Inference Engine (produk dengan fungsi serupa) dan Synet pada sampel dari
serangkaian model terbuka :
Seperti dapat dilihat dari tabel, dalam pengujian ini pada mesin dengan dukungan untuk AVX2 (i7-6700), kinerja Synet umumnya sesuai dengan kinerja Mesin Inferensi (meskipun sangat bervariasi dari model ke model). Pada mesin dengan dukungan untuk AVX-512 (i9-7900X), kinerja Synet rata-rata 25% lebih tinggi daripada Mesin Inference.
Semua pengukuran dilakukan oleh aplikasi uji, yang ada di Synet. Jadi, jika diinginkan, pembaca akan dapat mereproduksi tes sendiri:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
Keuntungan dan kerugian
Saya akan mulai dengan pro:
- Proyek ini berukuran kecil, mudah diimplementasikan dalam proyek pihak ketiga.
- Menunjukkan kinerja single-threaded tinggi.
- Bekerja pada pemroses seluler (mendukung ARM-NEON).
Nah dan kontra, di mana tanpa mereka:
- Tidak ada dukungan untuk GPU dan akselerator khusus lainnya.
- Paralelisasi yang buruk dari satu tugas pada CPU multi-core.
- Tidak ada dukungan untuk INT8 (kuantisasi bobot).
Kesimpulan
Synet saat ini digunakan sebagai bagian dari proyek
Kipod , platform berbasis cloud untuk analitik video. Mungkin dia memiliki pengguna lain, tapi itu tidak pasti :). Di masa depan, seiring dengan perkembangan proyek, saya ingin menambahkan hal-hal berikut ke dalamnya:
- Dukungan untuk model, lapisan, algoritma baru.
- Dukungan untuk perhitungan integer dalam format INT8 (bobot terkuantisasi).
- Dukungan komputasi GPU.
- Konversi dari format ONNX.
Daftar ini jauh dari lengkap, dan saya ingin menambahkannya dengan mempertimbangkan pendapat masyarakat - karena itu saya menunggu tanggapan Anda! Untuk membuat alat ini bermanfaat tidak hanya untuk perusahaan kami, tetapi juga untuk berbagai pengguna. Juga, penulis tidak akan menolak bantuan masyarakat dalam proses pembangunan.
Saat menjelaskan Synet, yang saya buat dalam artikel ini, saya sengaja tidak menyelidiki detail implementasi internalnya - ada banyak algoritma yang enak di bawah tenda, tetapi saya ingin mengungkapkan detail implementasi mereka dalam artikel berikut dari seri ini:
- Lapisan Konvolusi: Teknik Optimalisasi Penggandaan Matriks
- Lapisan konvolusional: konvolusi cepat sesuai dengan metode Shmuel Vinograd