 Anda dapat mengunduh file dengan kode dan data di posting asli di blog saya
Anda dapat mengunduh file dengan kode dan data di posting asli di blog sayaAda proyek yang sangat menarik - "
Kode Rosetta" . Tujuan mereka adalah "untuk menyajikan solusi dari masalah yang sama dalam jumlah terbesar yang mungkin dari berbagai bahasa pemrograman untuk menunjukkan tempat dan perbedaan umum mereka dan membantu seseorang yang memiliki pengetahuan untuk memecahkan masalah dengan satu metode untuk belajar yang lain."
Sumber daya ini memberikan peluang unik untuk membandingkan kode program dalam berbagai bahasa, yang akan kami lakukan dalam artikel ini. Ini adalah revisi lengkap dan penyempurnaan artikel oleh John MacLoon "
Panjang Kode Diukur dalam 14 Bahasa ".
Impor dan parsing data
Mari kita mulai dengan membuat modifikasi pada fungsi
Impor yang akan menyimpan data untuk digunakan di masa depan agar tidak meminta nanti dari server.
Clear[importOnce]; importOnce[args___]:=importOnce[args]=Import[args]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "importOnce.mx"}]
Buat parser untuk mengimpor data.
Clear[createPageLinkDataset]; createPageLinkDataset[baseLink_]:=createPageLinkDataset[baseLink]=Cases[Cases[Import[baseLink, "XMLObject"], XMLElement["div", {"class"->"mw-content-ltr", "dir"->"ltr", "lang"->"en"}, data_]:>data, Infinity], XMLElement["li", {}, {XMLElement["a", {___, "href"->link_, ___}, {name_}]}]:><|"name"->name, "link"->"http://rosettacode.org"<>link|>, Infinity]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "createPageLinkDataset.mx"}]
Kami mengimpor daftar semua bahasa pemrograman yang didukung oleh proyek (sudah ada lebih dari 750 bahasa):
$Languages=createPageLinkDataset["http://rosettacode.org/wiki/Category:Programming_Languages"]; Dataset@$Languages

Kami akan membuat fungsi untuk menerjemahkan nama menjadi tautan dan sebaliknya, ini akan berguna bagi kami nanti:
langLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Languages, #[["link"]]==link&]["name"]; langNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Languages, #[["name"]]==name&]["link"];
Kami akan memuat daftar tugas yang diselesaikan di masing-masing bahasa pemrograman. Parsing dirancang agar tidak semua tautan ke halaman menjadi tugas. Kami akan membersihkannya nanti.
$LangTasksAllPre=Map[<|"name"->#["name"], "link"->#["link"], "tasks"->createPageLinkDataset[#["link"]][[All, "link"]]|>&, $Languages]; Dataset@$LangTasksAllPre

Kami menghitung daftar semua tugas potensial yang dapat diselesaikan dalam proyek (hanya ada lebih dari 2600 di antaranya):
$TasksPre=DeleteDuplicates[Flatten[$LangTasksAllPre[[;;, "tasks"]]]]; Length[$TasksPre]

Buat fungsi yang menangkap semua fragmen kode pada halaman tugas.
ClearAll[codeExtractor]; codeExtractor[link_String]:=Module[{code, positions, rawData}, code=importOnce[link, "XMLObject"]; positions=Map[{#[[1, 1;;-2]], Partition[#[[;;, -1]], 2, 1]}&, DeleteCases[ Gather[ Position[code, XMLElement["h2", _, title_]], And[Length[#1]==Length[#2], #1[[1;;-2]]==#2[[1;;-2]]]&], x_/; Length[x]==1]]; rawData=Framed/@Flatten[Map[ With[{pos=#[[1]]}, Map[Extract[code, pos][[#[[1]];;#[[2]]-1]]&, #[[2]]]]&, positions], 1]; Association@DeleteCases[Map[langLinkToName[("link"/.#)]->("code"/.#)&, Map[ KeyValueMap[If[#1==="link", #1->#2[[1]], #1->#2]&, Merge[SequenceSplit[Cases[#, Highlighted[x_, ___]:>x, Infinity], {"Output"}][[1]], Identity]]&, rawData/.{XMLElement["h2", _, title_]:>Cases[title, XMLElement["a", {___, "href"->linkInner_/; MemberQ[$Languages[[;;, "link"]], "http://rosettacode.org"<>linkInner], ___}, {___}]:>Highlighted[<|"link"->"http://rosettacode.org"<>linkInner|>], Infinity], XMLElement["div", {}, x_/; Not[FreeQ[x, "Output:"]]]:>Highlighted["Output"], XMLElement["pre", _, code_]:>Highlighted[<|"code"->Check[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]], Echo[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]]]]|>, Background->Red]} ]], _->"code"]];
Sekarang kami akan memproses semua halaman:
ClearAll[taskCodes]; taskCodes[link_]:=taskCodes[link]=Check[codeExtractor[link], Echo[link]]; If[FileExistsQ[#], Get[#], taskCodes/@$TasksPre; DumpSave[#, taskCodes]]&@FileNameJoin[{NotebookDirectory[], "taskCodes.mx"}];
Contoh fungsi yang dihasilkan:
Dataset[taskCodes[$TasksPre[[20]]]]
Pilih halaman tugas (yang memiliki setidaknya satu kode):
$taskLangs=DeleteCases[{#, taskCodes[#]}&/@$TasksPre, {_, <||>}];
$langTasks=Map[<|"name"->#[["name"]], "link"->#[["link"]], "tasks"->With[{lang=#[["name"]]}, Select[$taskLangs, MemberQ[Keys[#[[2]]], lang]&][[;;, 1]]]|>&, $Languages]; Dataset[$langTasks]

Daftar tugas dan fungsi yang menerjemahkan nama tugas menjadi tautan, dan sebaliknya:
$Tasks=<|"name"->StringReplace[URLDecode[StringReplace[#, "http://rosettacode.org/wiki/"->""]], {"_"->" ", "/"->" -> "}], "link"->#|>&/@$taskLangs[[;;, 1]]; taskLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Tasks, #[["link"]]==link&]["name"]; taskNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Tasks, #[["name"]]==name&]["link"];
Statistik sederhana
Untuk sejumlah bahasa, masih belum ada masalah yang terpecahkan:
WordCloud[1/StringLength[#]->#&/@Select[$langTasks, Length[#["tasks"]]==0&][[All, "name"]], ImageSize->{1200, 800}, MaxItems->All, WordOrientation->{

Daftar bahasa yang telah memecahkan masalah:
$LanguagesWithTasks=Select[$langTasks, Length[#["tasks"]]=!=0&][[All, "name"]]; Length[$LanguagesWithTasks]
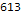
Distribusi jumlah masalah yang diselesaikan berdasarkan bahasa:
Histogram[Length/@$langTasks[[;;, "tasks"]], 50, PlotRange->All, BarOrigin->Bottom, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", lg[" "]}], ScalingFunctions->"Log10", PlotLabel->Style[" ", 20]]
Distribusi jumlah bahasa berdasarkan tugas yang diselesaikan:
Histogram[Length/@$taskLangs[[;;, 2]], 50, PlotRange->All, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", " "}], PlotLabel->Style[" ", 20]]

Bahasa di mana masalah yang paling dipecahkan adalah:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.1, BarOrigin -> Left, AspectRatio -> 1, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last], {_, x_/; x<200}]

Tugas diselesaikan dalam jumlah terbesar bahasa pemrograman:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.2, BarOrigin -> Left, AspectRatio -> 1.6, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last], {_, x_/; x<100}]

Tugas yang memiliki solusi untuk sekumpulan bahasa pemrograman tertentu
Fungsi yang menampilkan tugas diselesaikan dalam satu atau lebih bahasa pemrograman sekaligus:
commonTasks[lang_String]:=commonTasks[lang]=Sort[SelectFirst[$langTasks, #["name"]==lang&][["tasks"]]]; commonTasks["Mathematica"]:=commonTasks["Mathematica"]=Union[commonTasks["Wolfram Language"], Sort[SelectFirst[$langTasks, #["name"]=="Mathematica"&][["tasks"]]]]; commonTasks[lang_List]:=commonTasks[lang]=Sort[Intersection@@(commonTasks/@lang)];
Tugas-tugas umum untuk 25 bahasa paling populer pertama (ukuran font sesuai dengan jumlah relatif bahasa di mana masalah diselesaikan):
WordCloud[With[{tasks=taskLinkToName/@commonTasks[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-25;;-1]][[;;, 1]]]}, Transpose@{tasks, tasks/.Rule@@@SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last]}], ImageSize->{1000, 1000}, MaxItems->All, WordOrientation->{

Berfungsi untuk mengukur panjang kode
Selanjutnya, kita membutuhkan metrik untuk memperkirakan panjang kode. Secara umum diyakini bahwa ini adalah jumlah baris kode:
SetAttributes[lineCount, Listable] lineCount[str_String]:=StringCount[StringReplace[StringReplace[str, {" "->"", "\t"->""}], "\n"..->"\n"], "\n"]+1;
Tetapi karena parameter ini secara signifikan dipengaruhi oleh markup kode (pada akhirnya, katakanlah, dalam Bahasa Wolfram (
Mathematica ) Anda dapat menulis beberapa perintah dalam satu baris sekaligus), kami akan menggunakan jumlah karakter yang bukan spasi sebagai metrik.
SetAttributes[characterCount, Listable] characterCount[str_String]:=StringLength[StringReplace[str, WhitespaceCharacter->""]];
Metrik semacam itu tidak berlaku di tangan
Mathematica dengan nama-nama perintah deskriptif yang panjang (yang tidak diragukan lagi merupakan nilai tambah yang besar di luar blog ini), oleh karena itu, kami juga menerapkan metrik berdasarkan penghitungan token (objek "simbolik"), yang dengannya kami akan mengambil kata individual yang dipisahkan oleh karakter apa pun yang bukan surat itu.
SetAttributes[tokens, Listable] tokens[str_String]:=DeleteCases[StringSplit[str, Complement[Characters@FromCharacterCode[Range[1, 127]], CharacterRange["a", "z"], CharacterRange["A", "Z"], CharacterRange["0", "9"], {"."}]], ""]; tokenCount[str_String]:=Length[tokens[str]];
Pengukuran Panjang Kode
Kami mendapatkan satu set data tentang setiap tugas:
$taskData=Map[<|"name"->#[[1]], "lineCount"->Map[lineCount, #[[2]]], "characterCount"->Map[characterCount, #[[2]]], "tokens"->Map[Flatten[tokens[#]]&, #[[2]]]|>&, $taskLangs]; Dataset[$taskData]

Fungsi yang mengumpulkan statistik untuk setiap bahasa mengenai semua tugas yang diselesaikan di atasnya:
Clear[langData]; langData[name_]:=langData[name]=<|"name"->name, "lineCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]], "characterCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]], "tokens"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]|>&@(With[{task=#}, SelectFirst[$taskData, #[["name"]]==task&]]&/@commonTasks[name]); Map[langData, $LanguagesWithTasks];
Fungsi yang membandingkan metrik perbandingan untuk dua (atau lebih) bahasa pemrograman berdasarkan semua tugas umum:
ClearAll[compareLanguagesData, compareLanguages]; compareLanguagesData[langs_List/; Length[langs]>=2]:=compareLanguagesData[langs]=Module[{tasks, data}, tasks=commonTasks[langs]; data=langData/@langs; <|"lineCount"->Transpose[Lookup[#[["lineCount"]], tasks][[;;, 1]]&/@data], "characterCount"->Transpose[Lookup[#[["characterCount"]], tasks][[;;, 1]]&/@data], "tokensCount"->Transpose[Lookup[Map[Length, #[["tokens"]]], tasks]&/@data]|> ]; compareLanguages[langs_List/; Length[langs]>=2, function_]:=Module[{data}, data=compareLanguagesData[langs]; Map[Map[function, #]&, data] ];
Analisis dan visualisasi
Sekarang kita bisa mendapatkan banyak analitik.
Untuk mulai dengan, kami membandingkan indikator absolut. Fungsi di bawah ini membuat grafik di mana titik-titik menunjukkan nilai yang sesuai untuk dua bahasa. Jika titik di bawah garis diagonal (skala di sepanjang sumbu berbeda, seringkali jika panjang kode sangat bervariasi), ini berarti bahwa bahasa dari bawah "menang", sebaliknya bahasa "dari atas".
compareGraphic[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[Graphics[{Map[{If[#[[1]]<#[[2]], Orange, Darker@Green], Point[#]}&, #2], AbsoluteThickness[2], Gray, InfiniteLine[{{0, 0}, {1, 1}}]}, PlotRangePadding->0, GridLines->Automatic, AspectRatio->1, PlotRange->All, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"])]&, compareLanguages[{lang1, lang2}, Identity]], Background->White]
Anda dapat melihat dengan jelas bahwa kode Bahasa Wolfram hampir selalu lebih pendek daripada kode C:
compareGraphic[{"Mathematica", "C"}]

Atau Pytnon:
compareGraphic[{"Mathematica", "Python"}]

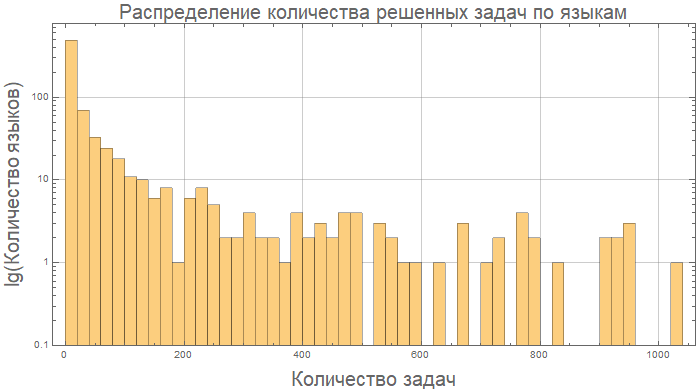
Dan di sini, misalnya, Kotlin dan Java pada dasarnya "sama" dalam hal panjang kode:
compareGraphic[{"Kotlin", "Java"}]
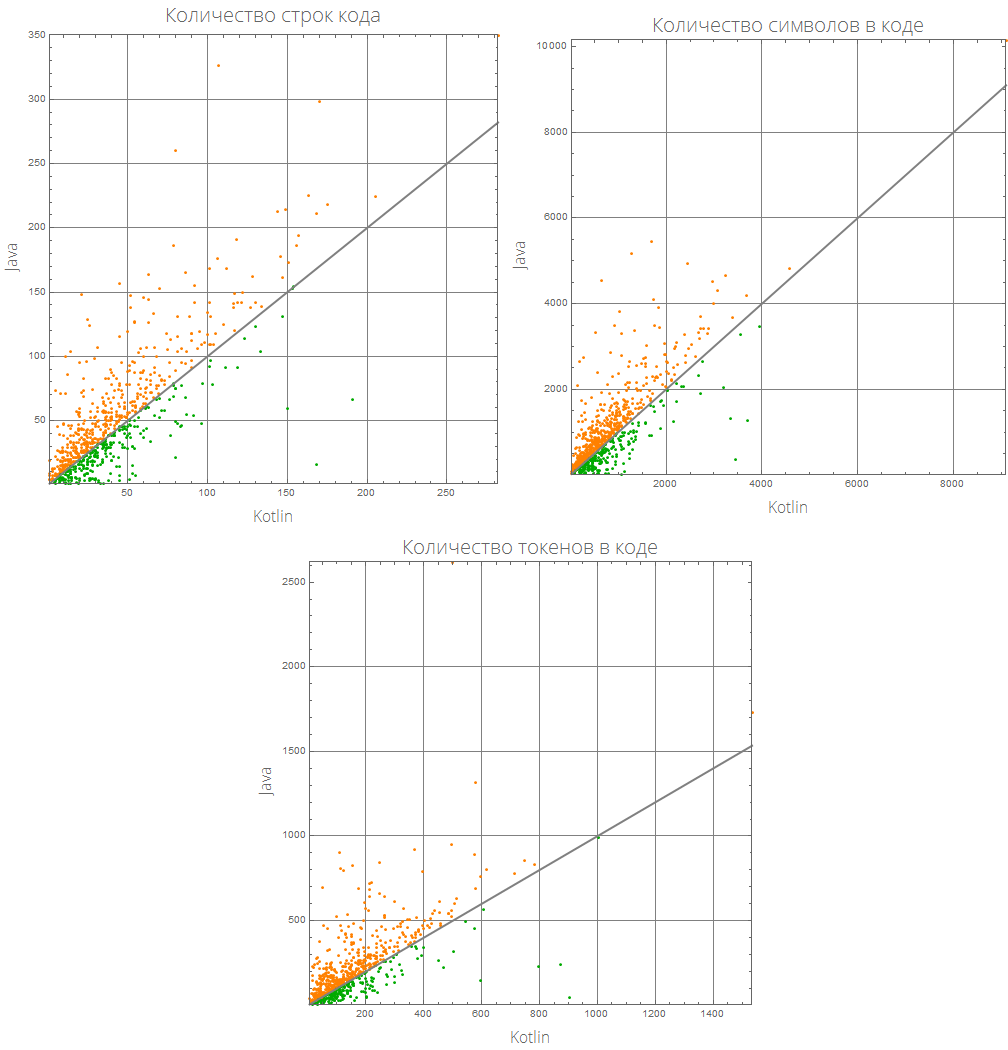
Representasi grafis ini dapat dibuat lebih informatif:
comparePlot[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[ListLinePlot[Sort@#2, GridLines->Automatic, AspectRatio->1, PlotRange->{Automatic, {0, 2}}, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"]), ColorFunction->(If[#2>1, Orange, Darker@Green]&), ColorFunctionScaling->False, PlotStyle->AbsoluteThickness[3]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]], Background->White]
comparePlot[{"Mathematica", "R"}]
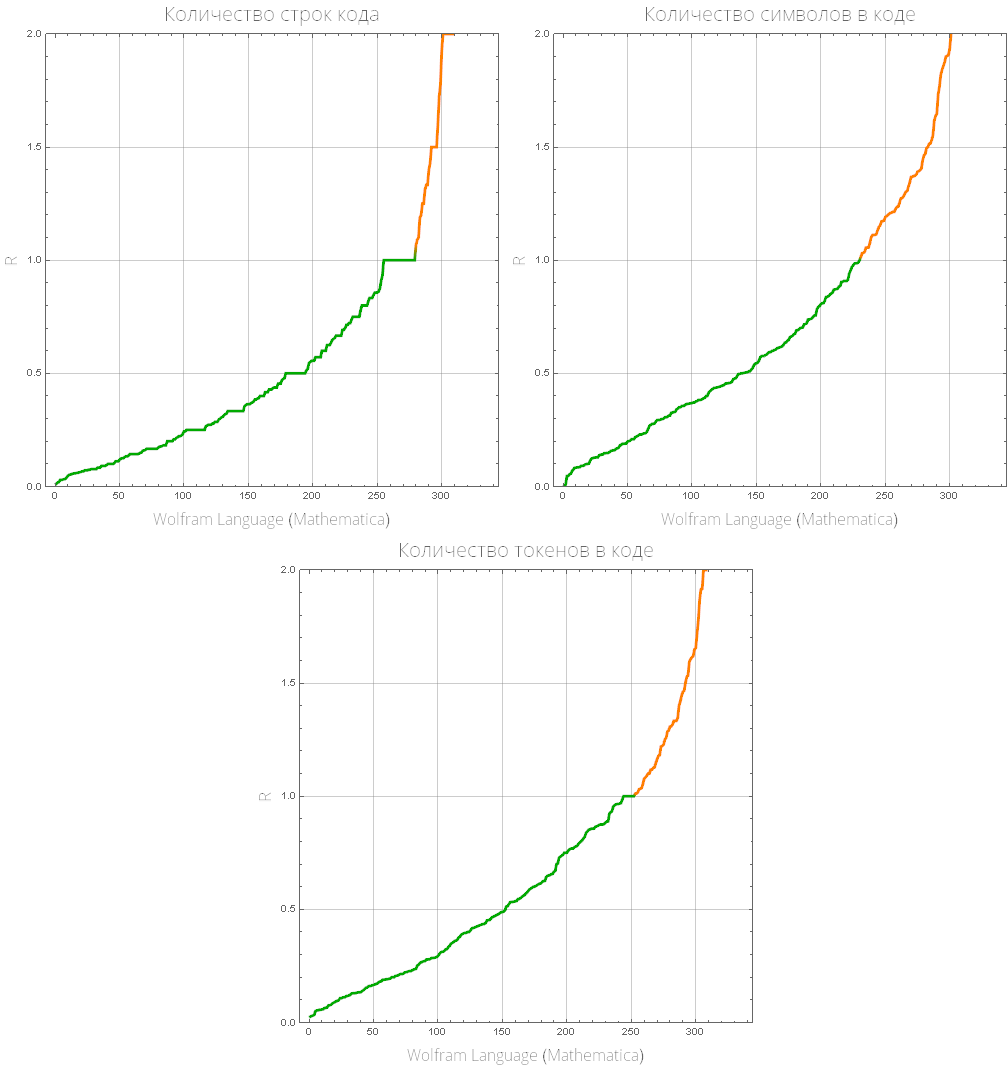
comparePlot[{"BASIC", "ALGOL 68"}]
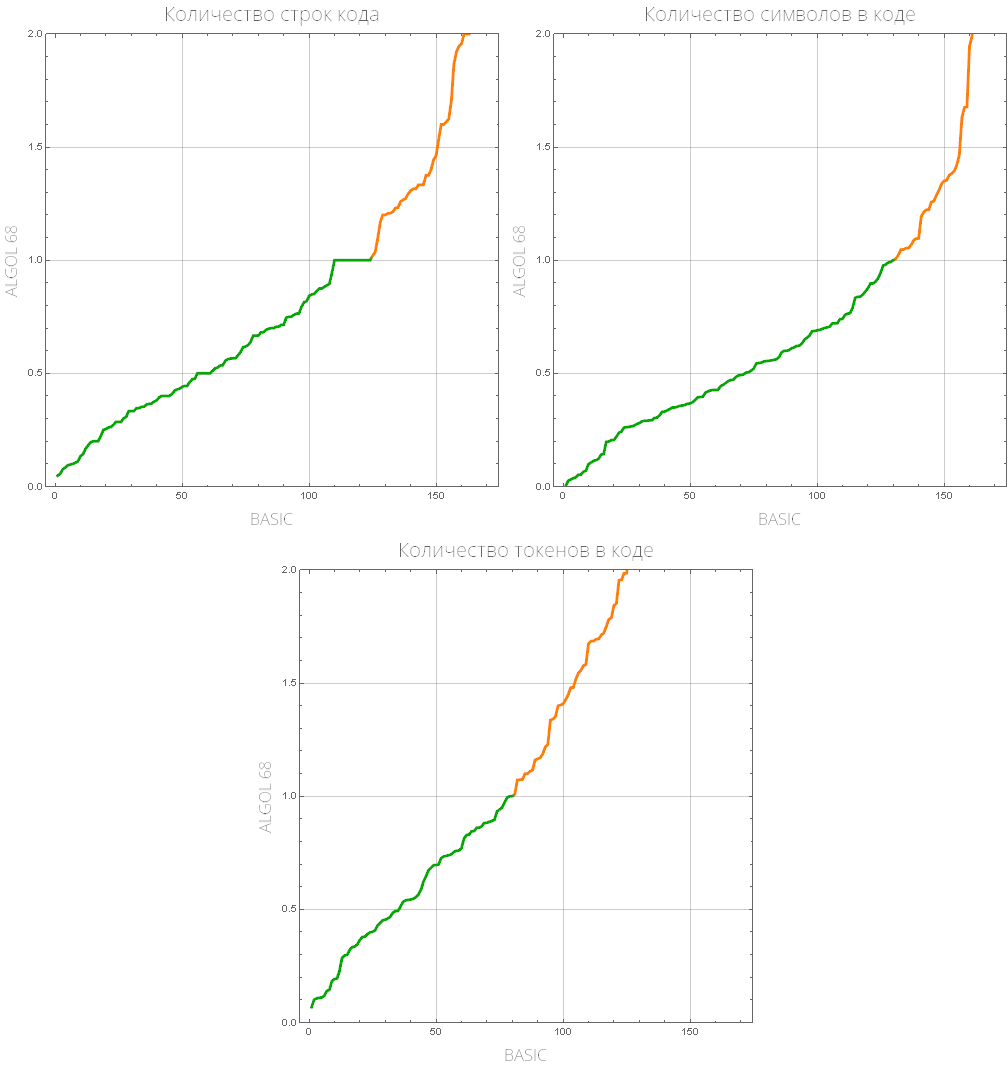
Kami mendefinisikan fungsi yang akan menampilkan daftar bahasa pemrograman "populer" (yang memiliki jumlah tugas terbesar yang diselesaikan):
Clear[$popularLanguages]; $popularLanguages[n_/; n>2]:=$popularLanguages[n]=Reverse[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-n;;-1]]]
$popularLanguages[25]

Kami memvisualisasikan daftar 350 bahasa pertama (ini adalah bagaimana screensaver untuk posting ini dibuat di awal):
WordCloud[$popularLanguages[350], ColorNegate@Binarize@ImageCrop@Import@"D:\\YandexDisk\\WolframMathematicaRuFiles\\388-3885229_rosetta-stone-silhouette-stone-silhouette-png-transparent-png.png", ImageSize->1000, MaxItems->All, WordOrientation->{

Fungsi yang menampilkan analisis panjang kode dalam metrik yang berbeda untuk n bahasa populer pertama:
ClearAll[langMetricsGrid]; langMetricsGrid[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]<OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; orderedMeans=Round[If[OptionValue["SortQ"], Map[Mean, tableData/.""->Nothing][[order]], Map[Mean, tableData/.""->Nothing]], 1/1000]//N; {min, max}=MinMax[Cases[Flatten[tableData], _?NumericQ]]; scale=Function[Evaluate[Rescale[#, {min, max}, {0, 1}]]]; fullTableData=Transpose[{{""}~Join~$pl[[order]]}~Join~{{""}~Join~orderedMeans}~Join~Transpose[{Map[Rotate[#, 90Degree]&, $pl]}~Join~ReplaceAll[tableData, x_?NumericQ:>Item[Round[x, 1/100]//N, Background->Which[x<1, LightGreen, x==1, LightBlue, x>1, LightRed]]][[order]]/.""->Item["", Background->Gray]]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], Grid[fullTableData, Background->White, ItemStyle->Directive[FontSize -> 12, FontFamily->"Open Sans Light"], Dividers->White]], FrameStyle->None, Background->White]];
Nilai median dari rasio jumlah baris kode dalam menyelesaikan masalah dalam berbagai bahasa pemrograman:
langMetricsGrid[25, "lineCount", "SortQ"->False]

Jika Anda mengurutkan tabel berdasarkan kolom "Rata-rata", itu akan menjadi lebih jelas - Wolfram Language (Mathematica) mengarah:
langMetricsGrid[25, "lineCount", "SortQ"->True]
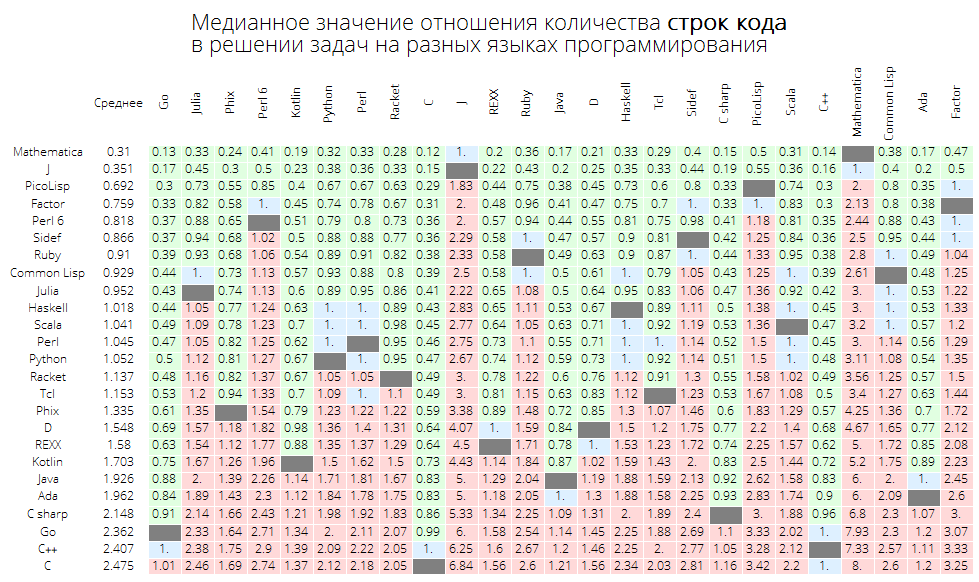
Nilai median rasio jumlah karakter dalam kode dalam memecahkan masalah dalam berbagai bahasa pemrograman:
langMetricsGrid[25, "characterCount", "SortQ"->True]

Nilai median dari rasio jumlah token dalam kode dalam memecahkan masalah dalam berbagai bahasa pemrograman:
langMetricsGrid[25, "tokensCount", "SortQ"->True]

Tabel yang sama dapat dibangun, misalnya, untuk 50 bahasa pertama yang paling populer:
langMetricsGrid[50, "lineCount", "SortQ"->True] langMetricsGrid[50, "characterCount", "SortQ"->True] langMetricsGrid[50, "tokensCount", "SortQ"->True]



Kita dapat membayangkan informasi yang sama lebih kompak - dalam bentuk kotak dengan kumis (diagram kotak-dan-kumis):
ClearAll[langMetricsBoxWhiskerChart]; langMetricsBoxWhiskerChart[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=Reverse@$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]>OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], BoxWhiskerChart[tableData[[order]], "Outliers", ChartLabels->$pl[[order]], BarOrigin->Left, ImageSize->1000, AspectRatio->1, GridLines->{Range[0, 20, 1/2], None}, FrameTicks->{Range[0, 20, 0.5], Automatic}, PlotRangePadding->0, PlotRange->{{0, 8}, Automatic}, Background->White] ], FrameStyle->None, Background->White]];
Bahasa diurutkan berdasarkan popularitas (diagram menunjukkan rasio jumlah baris kode antar bahasa):
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->False]
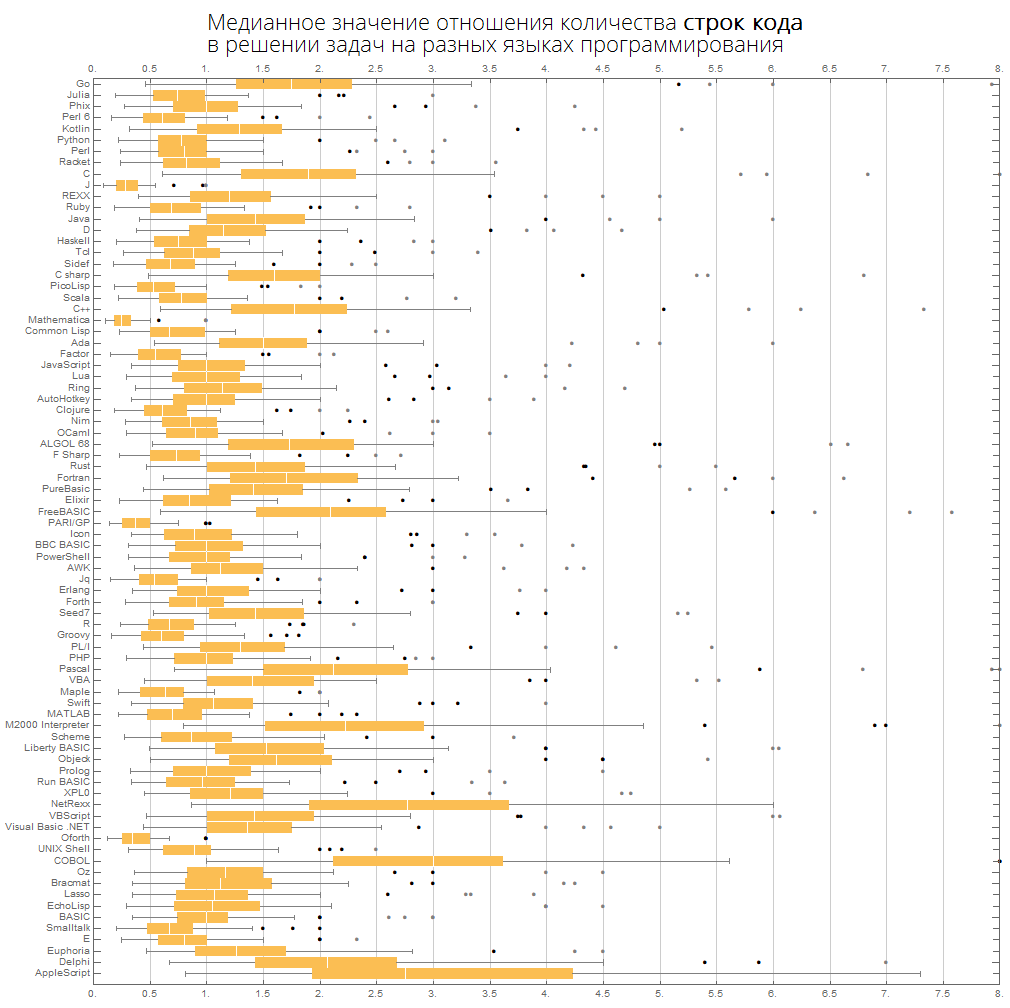
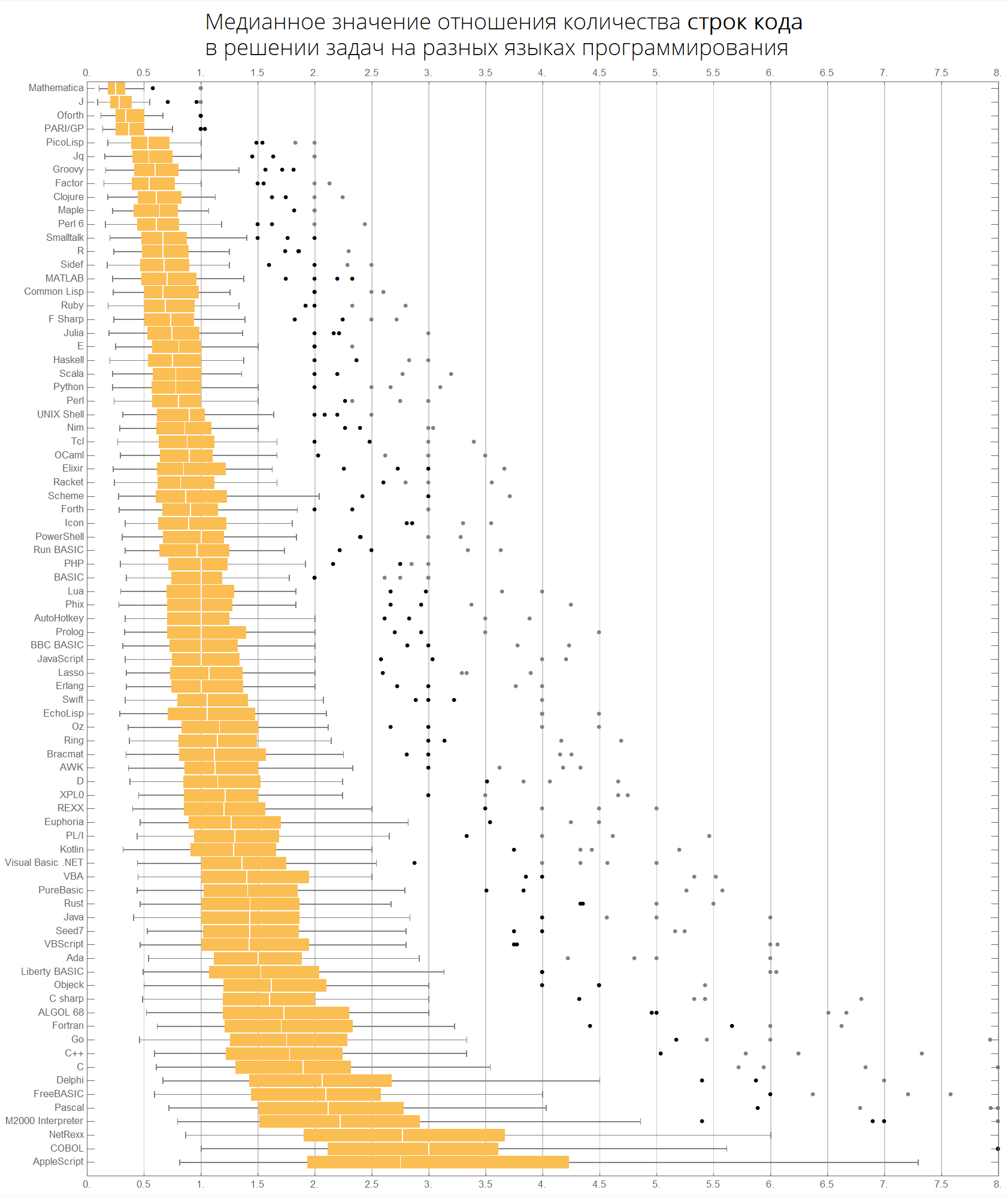
Dengan nilai median:
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->True]
Akhirnya, bagan tentang jumlah karakter dan token:
langMetricsBoxWhiskerChart[80, "characterCount", "SortQ"->True] langMetricsBoxWhiskerChart[80, "tokensCount", "SortQ"->True]
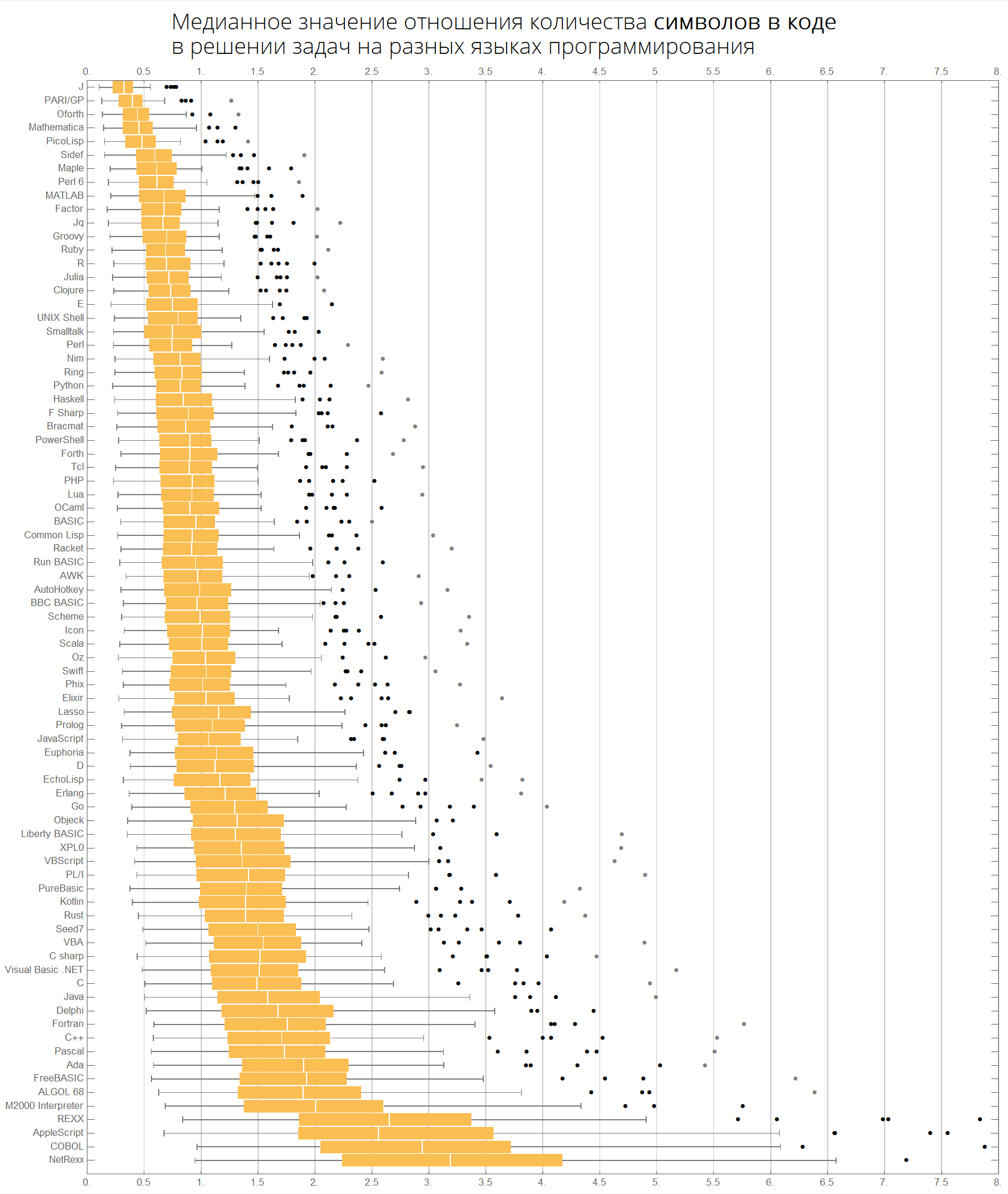
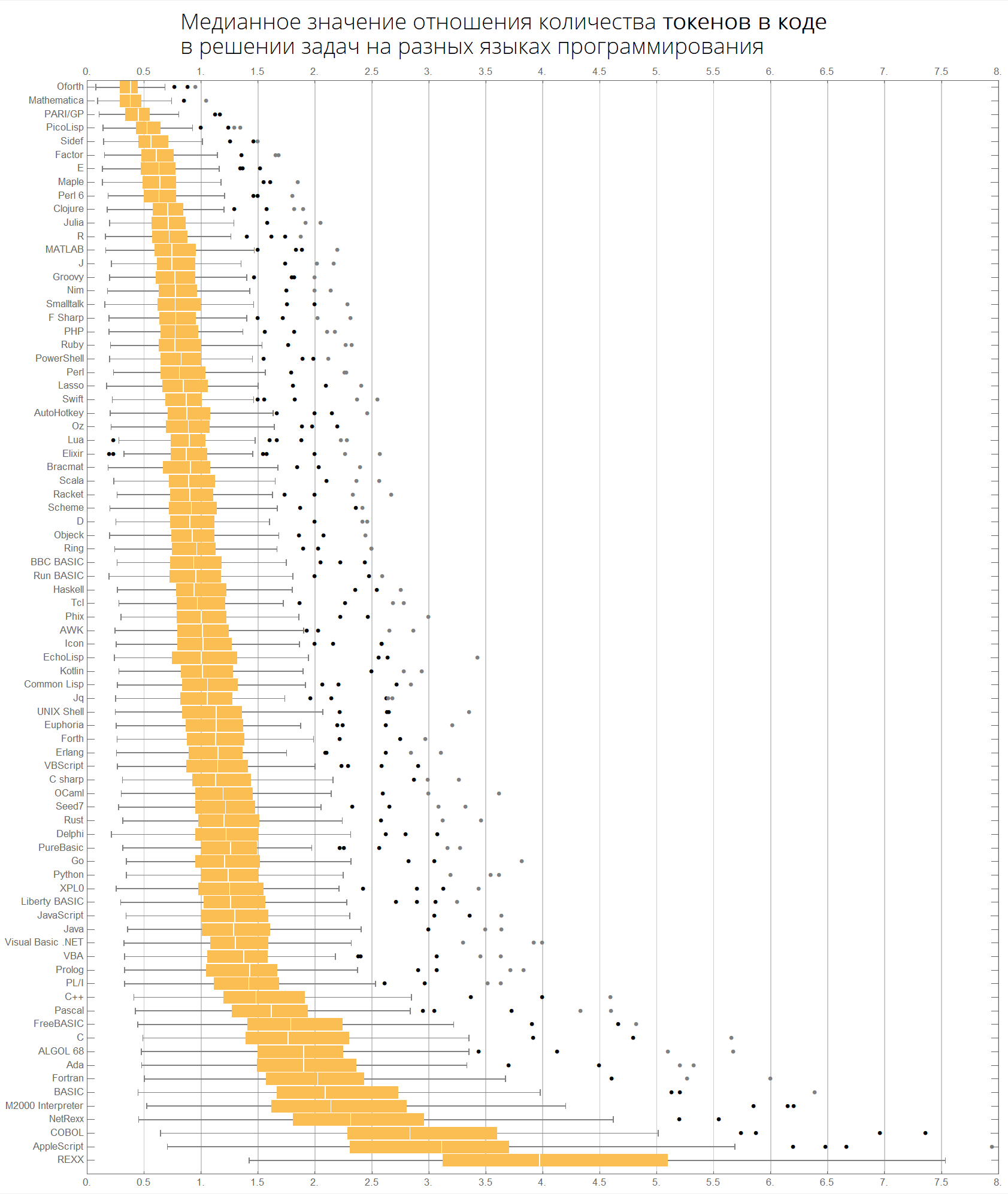
Mari kita lihat token mana yang populer dalam berbagai bahasa:
languagePopularTokens[lang_, nMin_:50]:=Framed[Labeled[Style[Row[{" ", Style[lang, Bold]}], FontFamily->"Open Sans Light", 24], WordCloud[Cases[SortBy[Tally[Flatten[Values[langData[lang][["tokens"]]]]], -Last[#]&], {x_/; (StringLength[x]>1&&StringMatchQ[x, RegularExpression["[a-zA-Z0-9.]+"]]&&Not[StringMatchQ[x, RegularExpression["[0-9.]+"]]]), y_/; y>nMin}], ImageSize->{1000, 500}, MaxItems->200, WordOrientation->{
clouds=Grid[{Image[#, ImageSize->All]&@Rasterize[languagePopularTokens[#, 10]]}&/@{"Mathematica", "C", "Python", "Go", "JavaScript"}]

Dan akhirnya, perbandingan bahasa yang sangat menarik berdasarkan kedekatan token mereka.
Fungsi langSimilarity berfungsi sebagai berikut: pertama, "token bermakna" dipilih (yang dianggap semua string karakter Latin dengan panjang setidaknya 2 karakter yang dapat berisi suatu periode); kemudian token dicari sepasang bahasa lang1 dan lang2; setelah itu, ukuran "kesamaan" mereka dianggap, sebagai produk ukuran Jacquard dari dua set token dengan jumlah yang bertanggung jawab atas kedekatan token antara satu sama lain (jumlah elemen bentuk
dimana
Apakah jumlah tampilan token di semua solusi untuk masalah bahasa lang1 dan lang2, masing-masing).
Clear[langSimilarity]; langSimilarity[{lang1_,lang2_},clearTokens_]:=langSimilarity@@(Sort[{lang1,lang2}]~Join~{clearTokens}); langSimilarity[lang1_,lang2_,clearTokens_:False]:=langSimilarity[lang1,lang2,clearTokens]=Module[{tokens,t1,t2,t1W,t2W,intersection}, tokens[lang_]:=Module[{values,tokensPre,allValues,replacements,n}, values=Values[langData[lang][["tokens"]]]; n=Length[values]; allValues=DeleteDuplicates[Flatten[values]]; tokensPre=If[clearTokens,Cases[allValues,x_/;(StringLength[x]>1&&StringMatchQ[x,RegularExpression["[a-zA-Z0-9._$]+"]]&&Not[StringMatchQ[x,RegularExpression["[0-9.,eE]+"]]])],allValues]; replacements=Dispatch@ Thread[Complement[allValues,tokensPre]->Nothing]; Cases[Tally@Flatten@(values/.replacements),{t_,x_/;x>=n/10}:>{t,x}]]; {t1,t2}=tokens/@{lang1,lang2}; {t1W,t2W}=Dispatch/@{Rule@@@t1,Rule@@@t2}; intersection=Intersection[t1[[;;,1]],t2[[;;,1]]]; Times@@{Total[(#[[1]]+#[[2]])/(1+Abs[#[[1]]-#[[2]]])&/@Transpose@N[{intersection/.t1W,intersection/.t2W}]],Length[intersection]/Length[Union[t1[[;;,1]],t2[[;;,1]]]]}]
ClearAll[langSimilarityGrid]; langSimilarityGrid[n_Integer, OptionsPattern[{"SortQ" -> True, "measureFunction" -> Mean, "clearTokens" -> True}]] := Module[{$nPL, $pl, tableData, notSortedTableData, order, fullTableData, min, max, orderedMeans, median, rescale}, $nPL = n; $pl = $popularLanguages[$nPL][[;; , 1]]; tableData = Quiet@Table[ If[i == j, "", langSimilarity[{$pl[[i]], $pl[[j]]}, OptionValue["clearTokens"]]], {i, 1, $nPL}, {j, 1, $nPL}]; {min, max} = MinMax[Flatten[tableData] /. "" -> Nothing]; median = 10^Median@Log10@Flatten[tableData /. "" -> Nothing]; rescale = Function[Evaluate[Rescale[#, {median, max}, {0, 1}]]]; order = If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1 /. "" -> Nothing] > OptionValue["measureFunction"][#2 /. "" -> Nothing] &], Range[1, $nPL]]; fullTableData = Transpose[{{""}~Join~$pl[[order]]}~Join~ Transpose[{Map[Rotate[#, 90 Degree] &, $pl]}~Join~ ReplaceAll[tableData[[order]], x_?NumericQ :> Item[Style[Round[x, 1], If[x < median, Black, White]], Background -> If[x < median, LightGray, ColorData["Rainbow"][rescale[x]]]]] /. "" -> Item["", Background -> Gray]]]; Framed[ Labeled[Style[ Row[{" ( )", "\n", "(", Style[If[OptionValue["clearTokens"], " ", " "], Bold], ")"}], 22, FontFamily -> "Open Sans Light", TextAlignment -> Center], Grid[fullTableData, Background -> White, ItemStyle -> Directive[FontSize -> 12, FontFamily -> "Open Sans Light"], Dividers -> White]], FrameStyle -> None, Background -> White]];
UPD: setelah komentar yang berharga, berkumpul memutuskan untuk membuat dua tabel: dengan token yang sudah dibersihkan dan dengan semua token, tanpa segala macam pembersihan, untuk mempengaruhi hasil sesedikit mungkin. Hasilnya sedikit berbeda, seperti yang Anda lihat sendiri, meskipun beberapa dependensi menjadi lebih jelas.
Inilah yang kami dapatkan (tabel tidak disortir):
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> True] langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> False]
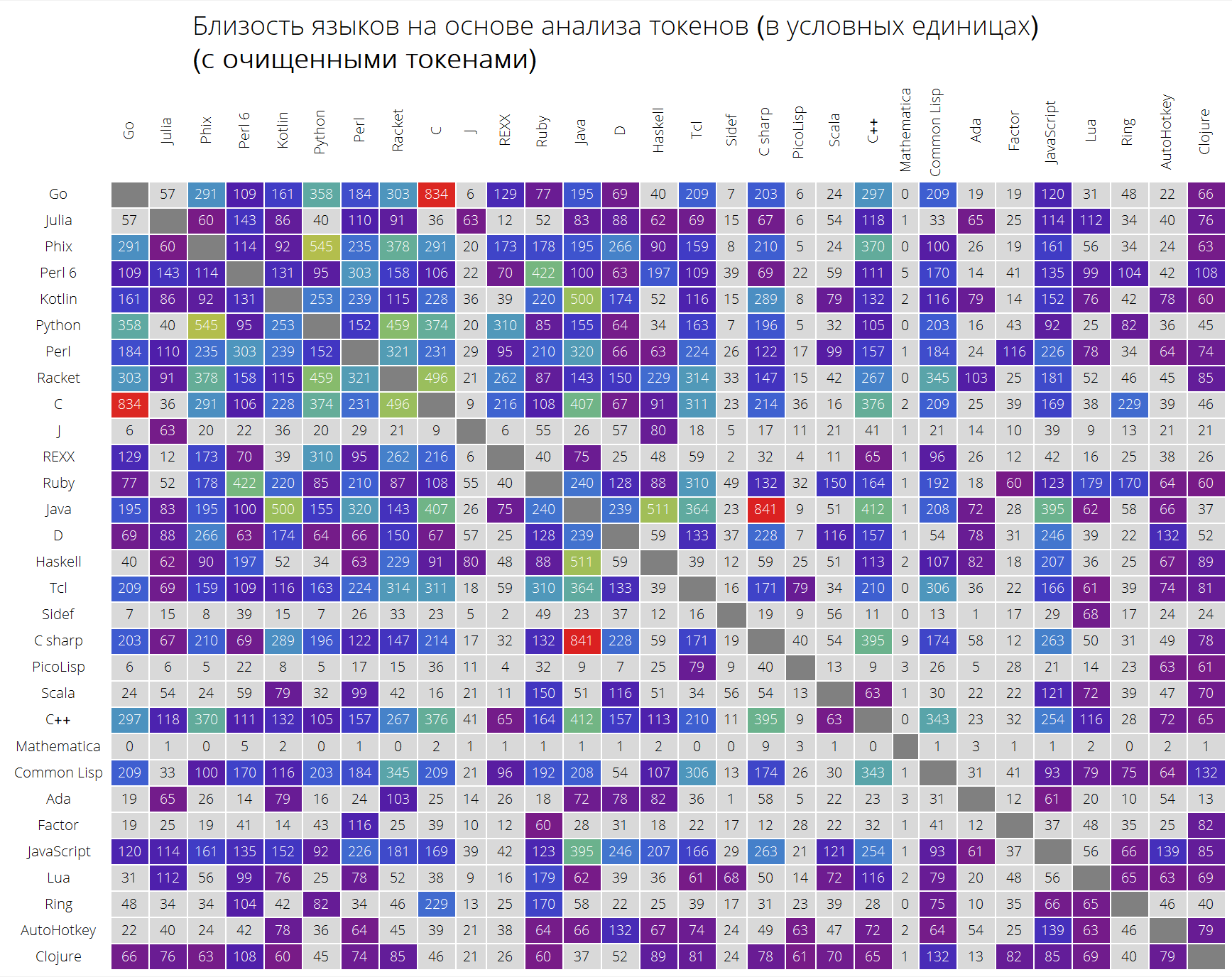

Tabel yang diurutkan (dalam hal kesamaan rata-rata dengan bahasa lain - semakin tinggi barisnya, semakin besar jumlah bahasa pemrograman lain yang terlihat seperti bahasa ini):
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> False]


Akhirnya, sebuah meja besar untuk 50 bahasa pertama dalam popularitas.
Diharapkan bahwa bahasa "kunci" seperti Java, C, C ++, C # berada di atas. Racket (sebelumnya PLTScheme) ada di sana, salah satu yang tujuannya adalah pembuatan, pengembangan, dan implementasi bahasa pemrograman.
Menariknya, Bahasa Wolfram pada dasarnya adalah bahasa yang berbeda.
Tautan antar bahasa juga terlihat, katakanlah tautan antara Java dan C #, Go dan C, C dan Java, Haskell dan Java, Kotlin dan Java, Python dan Phix, Python dan Racket dan banyak lagi yang sangat terlihat.
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> False]
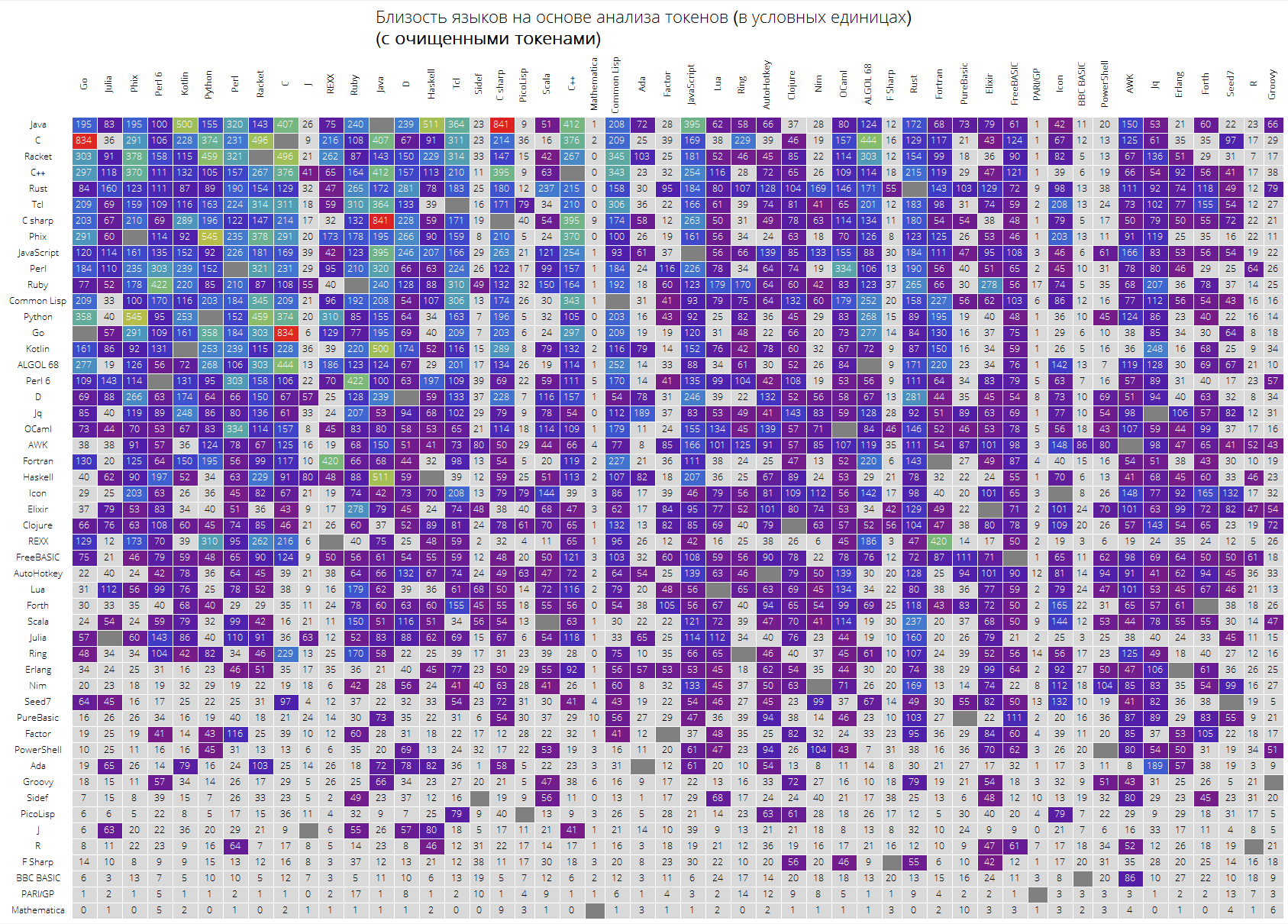
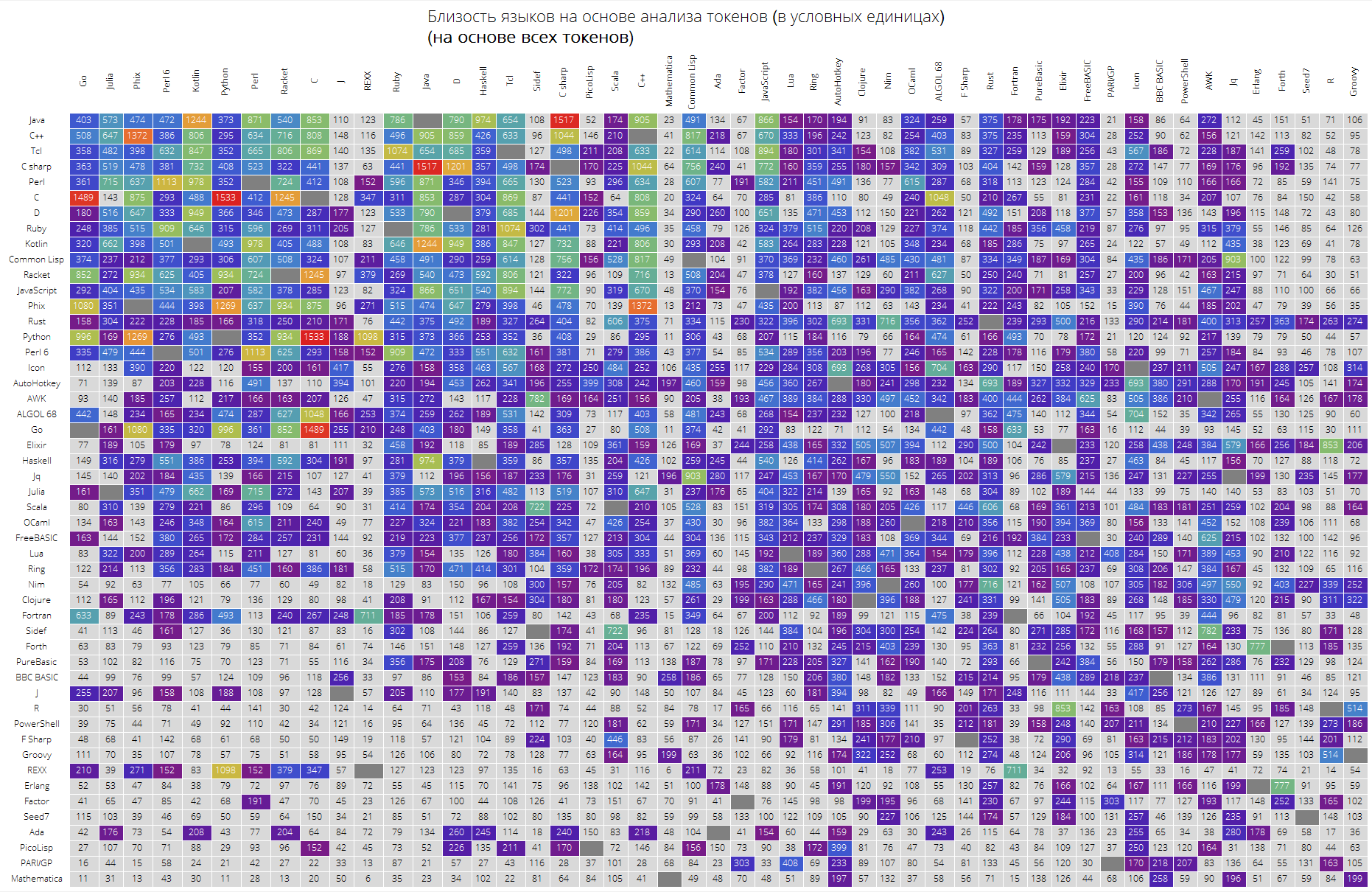
Saya harap pelajaran ini akan menarik bagi Anda dan Anda akan dapat menemukan sesuatu yang baru. Bagi saya, sebagai orang yang terus-menerus menggunakan Bahasa Wolfram, senang mengetahui bahwa itu ternyata merupakan bahasa yang paling "kompak", di satu sisi, di sisi lain, tujuannya "ketidaksamaan" dengan bahasa lain, jelas, membuatnya sedikit lebih sulit memasukkannya.
Ingin belajar cara memprogram dalam Bahasa Wolfram?
Tonton webinar mingguan.
Pendaftaran untuk kursus baru . Kursus online siap.