
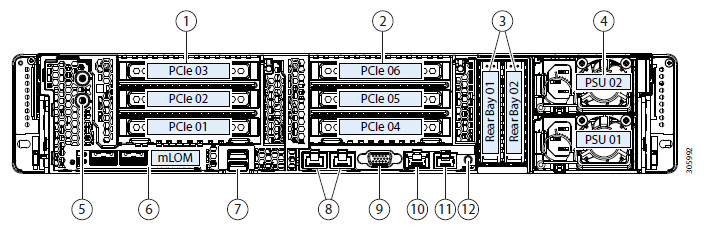
Ini adalah mitos yang cukup umum di bidang perangkat keras server. Dalam praktiknya, solusi hyperconverged (ketika semuanya) membutuhkan banyak untuk apa. Secara historis, arsitektur pertama dikembangkan oleh Amazon dan Google untuk layanan mereka. Kemudian idenya adalah membuat pertanian komputasi dari node yang sama, masing-masing memiliki drive sendiri. Semua ini dikombinasikan oleh beberapa perangkat lunak pembentuk sistem (hypervisor) dan sudah dibagi menjadi mesin virtual. Tugas utama adalah upaya minimal untuk mempertahankan satu node dan minimal masalah penskalaan: kami baru saja membeli seribu atau dua server yang sama dan terhubung di dekatnya. Dalam praktiknya, ini adalah kasus yang terisolasi, dan lebih sering kita berbicara tentang jumlah node yang lebih sedikit dan arsitektur yang sedikit berbeda.
Namun plus tetap sama - kemudahan penskalaan dan kontrol yang luar biasa. Minus - tugas yang berbeda menggunakan sumber daya secara berbeda, dan di suatu tempat akan ada banyak disk lokal, di suatu tempat akan ada sedikit RAM, dan seterusnya, yaitu, dengan berbagai jenis tugas, pemanfaatan sumber daya akan turun.
Ternyata Anda membayar 10-15% lebih untuk kemudahan pengaturan. Ini menyebabkan mitos judul. Kami mencari waktu yang lama di mana teknologi akan diterapkan secara optimal, dan menemukannya. Faktanya adalah bahwa Tsiska tidak memiliki sistem penyimpanan sendiri, tetapi mereka menginginkan pasar server yang lengkap. Dan mereka membuat Cisco Hyperflex, solusi penyimpanan lokal pada node.
Dan ini tiba-tiba menjadi solusi yang sangat bagus untuk pusat data cadangan (Disaster Recovery). Mengapa dan bagaimana - sekarang saya akan memberi tahu. Dan saya akan menunjukkan tes cluster.
Kemana?
Konvergensi hiper adalah:
- Transfer disk untuk menghitung node.
- Integrasi penuh dari subsistem penyimpanan dengan subsistem virtualisasi.
- Transfer / integrasi dengan subsistem jaringan.
Kombinasi seperti itu memungkinkan Anda untuk mengimplementasikan banyak fitur sistem penyimpanan di tingkat virtualisasi dan semuanya dari satu jendela kontrol.
Di perusahaan kami, proyek untuk mendesain pusat data yang berlebihan sangat populer, dan seringkali itu adalah solusi hyperconverged yang sering dipilih karena tumpukan opsi replikasi (hingga cluster metro) di luar kotak.
Dalam kasus pusat data cadangan, biasanya pertanyaan tentang fasilitas jarak jauh di situs di sisi lain kota atau di kota lain pada umumnya. Ini memungkinkan Anda untuk mengembalikan sistem penting jika terjadi kegagalan sebagian atau seluruhnya dari pusat data utama. Data penjualan terus-menerus direplikasi di sana, dan replikasi ini bisa di level aplikasi atau di level perangkat blok (SHD).
Jadi sekarang saya akan berbicara tentang perangkat dan pengujian sistem, dan kemudian tentang beberapa skenario kehidupan nyata dengan data tentang penghematan.
Tes
Salinan kami terdiri dari empat server, yang masing-masing memiliki 10 disk SSD per 960 GB. Ada disk khusus untuk operasi penulisan caching dan penyimpanan mesin virtual layanan. Solusinya sendiri adalah versi keempat. Yang pertama terus terang mentah (dilihat dari ulasan), yang kedua lembab, yang ketiga sudah cukup stabil, dan yang ini bisa disebut rilis setelah akhir pengujian beta untuk masyarakat umum. Selama pengujian masalah yang tidak saya lihat, semuanya bekerja seperti jam.
Perubahan pada v4Memperbaiki banyak bug.
Awalnya, platform hanya bisa bekerja dengan hypervisor VMware ESXi dan mendukung sejumlah kecil node. Selain itu, proses penyebaran tidak selalu berakhir dengan sukses, saya harus memulai kembali beberapa langkah, ada masalah memperbarui dari versi lama, data dalam GUI tidak selalu ditampilkan dengan benar (walaupun saya masih tidak senang dengan menampilkan grafik kinerja), kadang-kadang ada masalah di persimpangan dengan virtualisasi .
Sekarang semua luka anak-anak telah diperbaiki, HyperFlex dapat melakukan ESXi dan Hyper-V, ditambah ini dimungkinkan:
- Membuat kluster yang diregangkan.
- Membuat cluster untuk kantor tanpa menggunakan Fabric Interconnect, dari dua hingga empat node (kami hanya membeli server).
- Kemampuan untuk bekerja dengan penyimpanan eksternal.
- Dukungan untuk kontainer dan Kubernet.
- Pembuatan zona aksesibilitas.
- Integrasi dengan VMware SRM, jika fungsionalitas bawaan tidak sesuai.
Arsitekturnya tidak jauh berbeda dengan keputusan para pesaing utama, mereka tidak mulai membuat sepeda. Semuanya berfungsi pada platform virtualisasi VMware atau Hyper-V. Perangkat keras di-host di server milik Cisco UCS. Ada orang yang membenci platform karena kompleksitas relatif dari pengaturan awal, banyak tombol, sistem templat dan dependensi yang tidak sepele, tetapi ada juga yang telah mempelajari Zen, terinspirasi oleh ide tersebut dan tidak lagi ingin bekerja dengan server lain.
Kami akan mempertimbangkan solusi khusus untuk VMware, karena solusi ini awalnya dibuat untuk itu dan memiliki lebih banyak fungsi, Hyper-V ditambahkan sepanjang jalan untuk bersaing dengan pesaing dan memenuhi harapan pasar.
Ada sekelompok server yang penuh dengan disk. Ada disk untuk penyimpanan data (SSD atau HDD - sesuai selera dan kebutuhan Anda), ada satu disk SSD untuk cache. Ketika data ditulis ke datastore, data disimpan pada lapisan caching (SSD-disk khusus dan layanan VM RAM). Secara paralel, blok data dikirim ke node dalam cluster (jumlah node tergantung pada faktor replikasi cluster). Setelah konfirmasi dari semua node tentang rekaman yang sukses, konfirmasi rekaman dikirim ke hypervisor dan kemudian ke VM. Data yang direkam di latar belakang dideduplikasi, dikompresi, dan ditulis ke disk penyimpanan. Pada saat yang sama, blok besar selalu ditulis ke disk penyimpanan dan secara berurutan, yang mengurangi beban pada disk penyimpanan.
Deduplikasi dan kompresi selalu aktif dan tidak dapat dinonaktifkan. Data dibaca langsung dari disk penyimpanan atau dari cache RAM. Jika konfigurasi hibrid digunakan, pembacaan juga di-cache pada SSD.
Data tidak terikat ke lokasi saat ini dari mesin virtual dan didistribusikan secara merata antara node. Pendekatan ini memungkinkan Anda memuat semua drive dan antarmuka jaringan secara merata. Minus yang jelas meminta: kami tidak dapat meminimalkan penundaan baca, karena tidak ada jaminan ketersediaan data secara lokal. Tetapi saya percaya bahwa ini adalah pengorbanan yang tidak penting dibandingkan dengan nilai plus yang diterima. Terlebih lagi, keterlambatan jaringan telah mencapai nilai sedemikian rupa sehingga secara praktis tidak mempengaruhi hasil keseluruhan.
Untuk semua logika subsistem disk, VM layanan khusus pengontrol Platform Data HyperFlex Cisco bertanggung jawab, yang dibuat pada setiap node penyimpanan. Dalam konfigurasi VM layanan kami, delapan vCPU dan 72 GB RAM dialokasikan, yang tidak begitu kecil. Biarkan saya mengingatkan Anda bahwa host itu sendiri memiliki 28 core fisik dan RAM 512 GB.
Layanan VM memiliki akses ke disk fisik secara langsung dengan meneruskan pengontrol SAS ke VM. Komunikasi dengan hypervisor terjadi melalui modul IOVisor khusus, yang mencegat operasi I / O, dan menggunakan agen yang memungkinkan Anda untuk mentransfer perintah ke API hypervisor. Agen bertanggung jawab untuk bekerja dengan snapshot dan klon HyperFlex.
Di hypervisor, sumber daya disk dipasang sebagai bola NFS atau SMB (tergantung pada jenis hypervisor, tebak yang mana). Dan di bawah tenda, ini adalah sistem file terdistribusi yang memungkinkan Anda untuk menambahkan fitur sistem penyimpanan dewasa penuh: alokasi volume tipis, kompresi dan deduplikasi, snapshot menggunakan teknologi Redirect-on-Write, replikasi sinkron / asinkron.
Layanan VM menyediakan akses ke antarmuka WEB dari manajemen subsistem HyperFlex. Ada integrasi dengan vCenter, dan sebagian besar tugas sehari-hari dapat dilakukan darinya, tetapi datastore, misalnya, lebih nyaman untuk memotong dari webcam terpisah jika Anda telah beralih ke antarmuka HTML5 yang cepat, atau menggunakan klien Flash lengkap dengan integrasi penuh. Di webcam layanan, Anda dapat melihat kinerja dan status terperinci sistem.
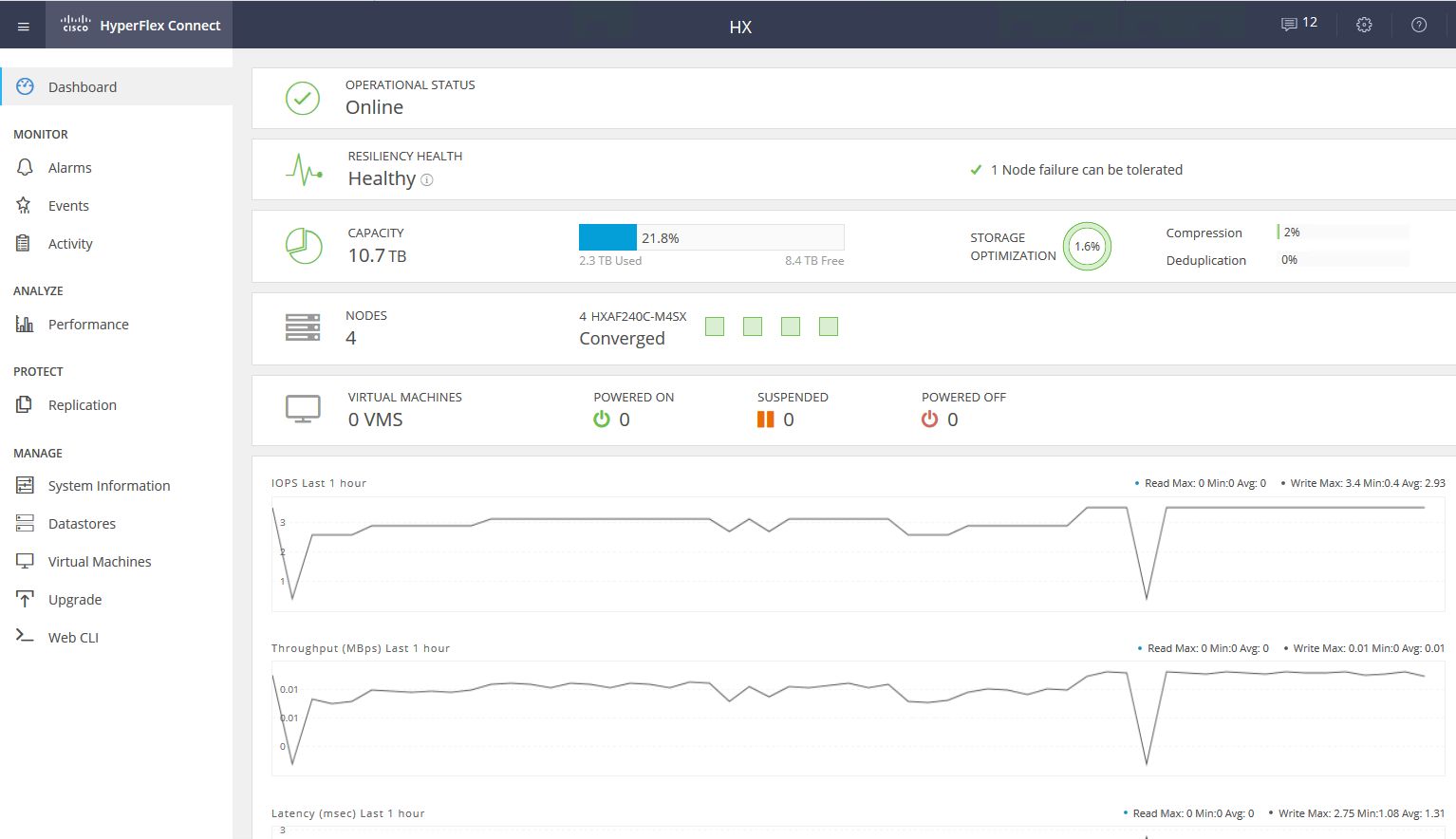
Ada jenis lain dari node dalam sebuah cluster - node komputasi. Ini bisa berupa server rak atau blade tanpa drive internal. Di server ini, Anda dapat menjalankan VM yang datanya disimpan di server dengan disk. Dari sudut pandang akses data, tidak ada perbedaan antara jenis-jenis node, karena arsitektur melibatkan abstrak dari lokasi fisik data. Rasio maksimum node komputasi dan node penyimpanan adalah 2: 1.
Menggunakan node komputasi meningkatkan fleksibilitas saat scaling sumber daya cluster: kita tidak perlu membeli node dengan disk jika kita hanya membutuhkan CPU / RAM. Selain itu, kita dapat menambahkan keranjang blade dan menghemat ruang server rak.
Hasilnya, kami memiliki platform hyperconverged dengan fitur-fitur berikut:
- Hingga 64 node dalam satu cluster (hingga 32 node penyimpanan).
- Jumlah minimum node dalam sebuah cluster adalah tiga (dua untuk cluster Edge).
- Mekanisme redundansi data: mirroring dengan faktor replikasi 2 dan 3.
- Cluster metro.
- Replikasi VM asinkron ke kluster HyperFlex lain.
- Orkestrasi untuk mengalihkan VM ke pusat data jarak jauh.
- Jepretan asli menggunakan teknologi Redirect-on-Write.
- Hingga 1 PB ruang yang dapat digunakan dengan faktor replikasi 3 dan tanpa deduplikasi. Kami tidak memperhitungkan faktor replikasi akun 2, karena ini bukan opsi untuk penjualan serius.
Nilai tambah besar lainnya adalah kemudahan manajemen dan penyebaran. Semua kompleksitas konfigurasi server UCS ditangani oleh VM khusus yang disiapkan oleh para insinyur Cisco.
Konfigurasi yang diuji:
- 2 x Cisco UCS Fabric Interconnect 6248UP sebagai cluster manajemen dan komponen jaringan (48 port yang beroperasi dalam mode Ethernet 10G / FC 16G).
- Empat Server Cisco UCS HXAF240 M4.
Fitur Server:
Opsi konfigurasi lainnyaSelain setrika yang dipilih, opsi berikut saat ini tersedia:
- HXAF240c M5.
- Satu atau dua CPU mulai dari Intel Silver 4110 hingga Intel Platinum I8260Y. Generasi kedua tersedia.
- 24 slot memori, bilah dari 16 GB RDIMM 2600 hingga 128 GB LRDIMM 2933.
- Dari 6 hingga 23 disk untuk data, satu disk caching, satu sistem, dan satu disk boot.
Drive kapasitas- HX-SD960G61X-EV 960GB 2.5 Inch Nilai Perusahaan 6G SATA SSD (daya tahan 1X) SAS 960 GB.
- HX-SD38T61X-EV 3.8TB Nilai Perusahaan 2,5 inci 6G SATA SSD (daya tahan 1X) SAS 3,8 TB.
- Driver caching
- HX-NVMEXPB-I375 375GB 2,5 inci Intel Optane Drive, Extreme Perf & Endurance.
- HX-NVMEHW-H1600 * 1.6TB 2,5 inci Ent. Perf NVMe SSD (daya tahan 3X) NVMe 1.6 TB.
- HX-SD400G12TX-EP 400GB 2,5 inci Ent. Perf SSD SAS 12G (daya tahan 10X) SAS 400 GB.
- HX-SD800GBENK9 ** 800GB 2,5 inci Ent. Perf SSD SED 12G SAS (daya tahan 10X) SAS 800 GB.
- HX-SD16T123X-EP 1.6TB 2.5 inch Kinerja perusahaan 12G SAS SSD (daya tahan 3X).
Sistem / Drive Log- HX-SD240GM1X-EV 240GB 2,5 inci Nilai Perusahaan 6G SATA SSD (Membutuhkan peningkatan).
Driver boot- HX-M2-240GB 240GB SATA M.2 SSD SATA 240 GB.
Koneksi ke jaringan pada port Ethernet 40G, 25G atau 10G.
Karena FI dapat berupa HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G / 100G).
Tes sendiri
Untuk menguji subsistem disk, saya menggunakan HCIBench 2.2.1. Ini adalah utilitas gratis yang memungkinkan Anda untuk mengotomatisasi pembuatan beban dari banyak mesin virtual. Beban itu sendiri dihasilkan oleh fio biasa.
Cluster kami terdiri dari empat node, faktor replikasi 3, semua drive Flash.
Untuk pengujian, saya membuat empat datastore dan delapan mesin virtual. Untuk tes tulis, diasumsikan bahwa disk caching tidak penuh.
Hasil tes adalah sebagai berikut:
Nilai tebal ditunjukkan, setelah itu tidak ada peningkatan produktivitas, kadang-kadang bahkan degradasi terlihat. Karena kenyataan bahwa kita bersandar pada kinerja jaringan / pengontrol / drive.- Sequential read 4432 MB / s.
- Menulis berurutan 804 MB / s.
- Jika satu controller gagal (mesin virtual atau kegagalan host), drawdown kinerja digandakan.
- Jika drive penyimpanan gagal, drawdownnya adalah 1/3. Disk rebild mengambil 5% sumber daya dari setiap pengontrol.
Pada blok kecil, kita mengalami kinerja controller (mesin virtual), CPU-nya 100% dimuat, sementara meningkatkan blok kita lari ke port bandwidth. 10 Gbps tidak cukup untuk membuka kunci potensi sistem AllFlash. Sayangnya, parameter dari demo stand yang disediakan tidak memungkinkan memeriksa pekerjaan pada 40 Gb / s.
Dalam kesan saya tentang tes dan studi arsitektur, karena algoritma yang menempatkan data antara semua host, kami mendapatkan kinerja yang dapat diprediksi terukur, tetapi ini juga merupakan batasan saat membaca, karena mungkin untuk memeras lebih banyak dari disk lokal dan banyak lagi, di sini untuk menyimpan jaringan yang lebih produktif, misalnya, 40 Gbps FI tersedia.
Juga, satu disk untuk caching dan deduplikasi dapat menjadi batasan, pada kenyataannya, dalam stand ini kita dapat menulis pada empat disk SSD. Akan sangat bagus untuk dapat meningkatkan jumlah disk yang di-cache dan melihat perbedaannya.
Penggunaan nyata
Dua pendekatan dapat digunakan untuk mengatur pusat data cadangan (kami tidak mempertimbangkan menempatkan cadangan di situs jarak jauh):
- Pasif aktif Semua aplikasi di-host di pusat data utama. Replikasi sinkron atau asinkron. Jika terjadi penurunan di pusat data utama, kita perlu mengaktifkan yang cadangan. Ini dapat dilakukan secara manual / skrip / aplikasi orkestrasi. Di sini kita mendapatkan RPO yang sepadan dengan frekuensi replikasi, dan RTO tergantung pada reaksi dan keterampilan administrator dan kualitas pengembangan / debugging dari rencana switching.
- Aktif Aktif Dalam hal ini, hanya replikasi sinkron hadir, ketersediaan pusat data ditentukan oleh kuorum / arbiter, ditempatkan secara ketat pada platform ketiga. RPO = 0, dan RTO dapat mencapai 0 (jika aplikasi memungkinkan) atau sama dengan waktu gagal atas sebuah node dalam cluster virtualisasi. Pada tingkat virtualisasi, kluster terentang (Metro) dibuat yang memerlukan penyimpanan Active-Active.
Biasanya, kami melihat dengan pelanggan arsitektur yang sudah diterapkan dengan penyimpanan klasik di pusat data utama, jadi kami merancang yang lain untuk replikasi. Seperti yang saya sebutkan, Cisco HyperFlex menawarkan replikasi asinkron dan pembuatan cluster virtualisasi yang diperluas. Pada saat yang sama, kita tidak memerlukan sistem penyimpanan Midrange atau yang lebih tinggi dengan fungsi replikasi yang mahal dan akses data Aktif-Aktif pada dua sistem penyimpanan.
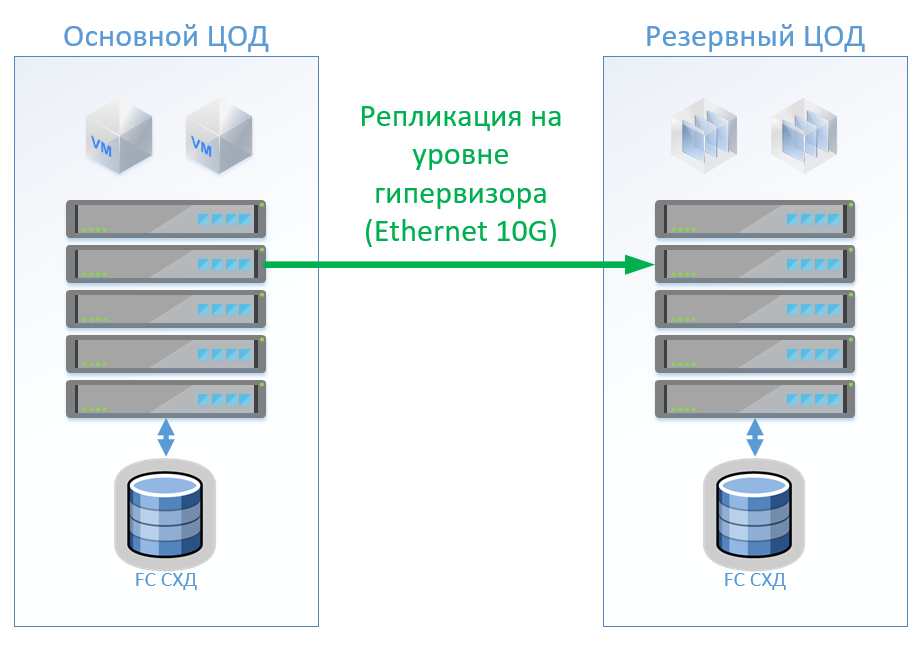
Skenario 1: Kami memiliki pusat data primer dan cadangan, platform virtualisasi di VMware vSphere. Semua sistem produktif terletak terutama di pusat data, dan replikasi mesin virtual dilakukan di tingkat hypervisor, ini akan memungkinkan untuk tidak membuat VM diaktifkan di pusat data cadangan. Kami mereplikasi basis data dan aplikasi khusus dengan alat bawaan dan menjaga VM tetap hidup. Jika pusat data utama gagal, kami memulai sistem di pusat data cadangan. Kami percaya bahwa kami memiliki sekitar 100 mesin virtual. Selama pusat data utama beroperasi, lingkungan pengujian dan sistem lainnya dapat diluncurkan di pusat data cadangan, yang dapat dinonaktifkan jika pusat data utama diaktifkan. Mungkin juga kita menggunakan replikasi dua arah. Dari sudut pandang peralatan, tidak ada yang akan berubah.
Dalam kasus arsitektur klasik, kami akan menempatkan sistem penyimpanan hybrid di setiap pusat data dengan akses melalui FibreChannel, merobek, deduplikasi dan kompresi (tetapi tidak online), 8 server per situs, 2 sakelar FibreChannel, dan Ethernet 10G. Untuk kontrol replikasi dan switching dalam arsitektur klasik, kita dapat menggunakan alat VMware (Replikasi + SRM) atau alat pihak ketiga yang akan sedikit lebih murah dan terkadang lebih nyaman.
Gambar tersebut menunjukkan diagram.
Jika Anda menggunakan Cisco HyperFlex, Anda mendapatkan arsitektur berikut:
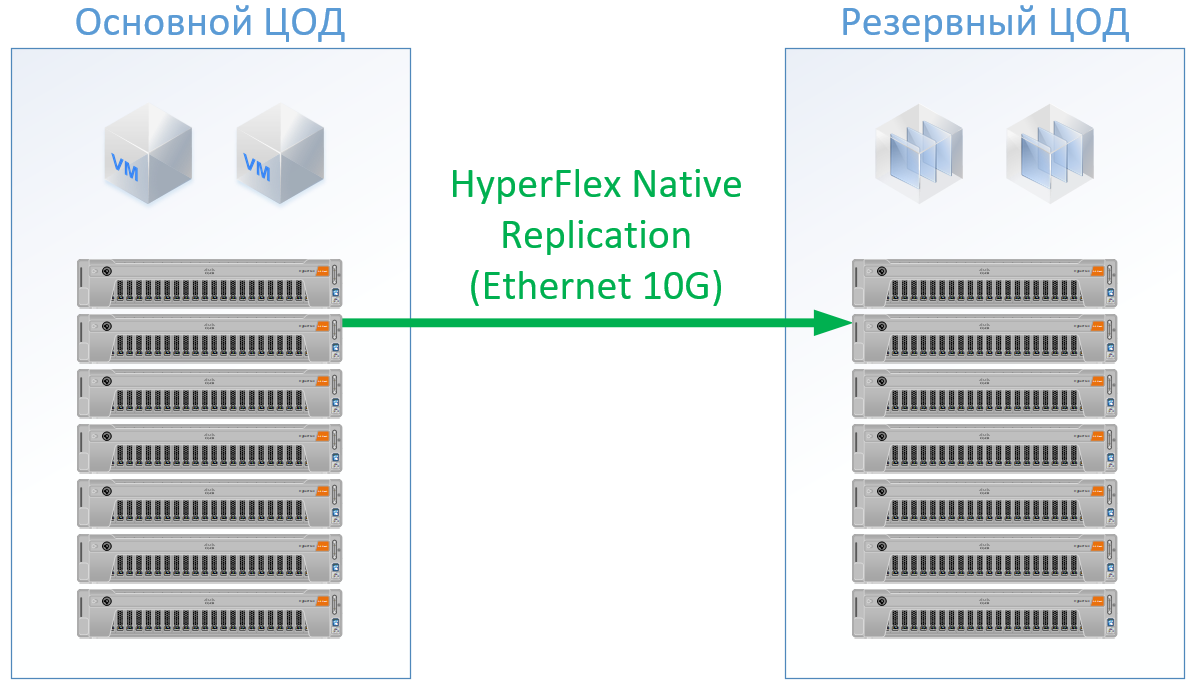
Untuk HyperFlex, saya menggunakan server dengan sumber daya CPU / RAM besar, sebagai bagian dari sumber daya akan pergi ke VM pengontrol HyperFlex, saya bahkan memuat ulang sedikit dalam konfigurasi HyperFlex pada CPU dan memori, agar tidak bermain bersama Cisco dan menjamin sumber daya untuk sisa VM. Tapi kita bisa menolak dari switch FibreChannel, dan kita tidak perlu port Ethernet untuk setiap server, lalu lintas lokal diaktifkan di dalam FI.
Hasilnya adalah konfigurasi berikut untuk setiap pusat data:
Untuk Hyperflex, saya tidak menjanjikan lisensi perangkat lunak replikasi, karena ini tersedia di luar kotak bersama kami.
Untuk arsitektur klasik, saya mengambil vendor yang memantapkan dirinya sebagai produsen yang berkualitas dan murah. Untuk kedua opsi, saya menggunakan standar untuk skid solusi spesifik, pada output saya mendapatkan harga riil.
Solusi pada Cisco HyperFlex adalah 13% lebih murah.
Skenario 2: membuat dua pusat data aktif. Dalam skenario ini, kami merancang cluster yang diperluas pada VMware.
Arsitektur klasik terdiri dari server virtualisasi, SAN (protokol FC) dan dua sistem penyimpanan yang dapat membaca dan menulis yang membentang di antara mereka. Pada setiap SHD kami memasang kapasitas yang berguna untuk kunci.
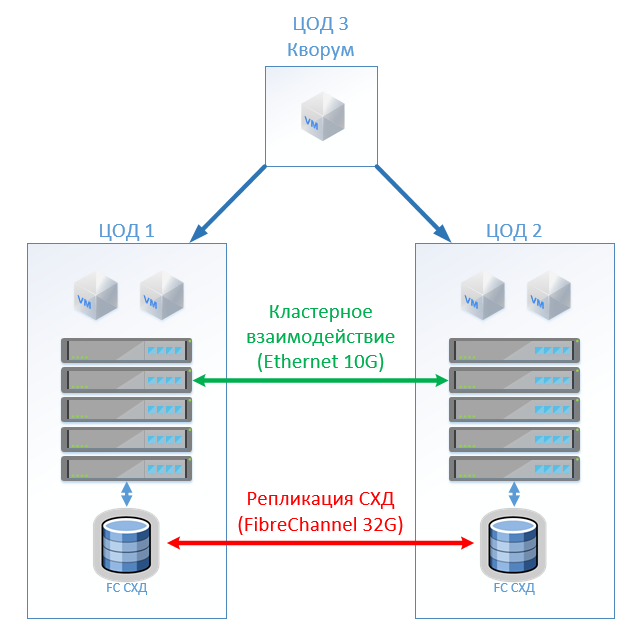
Di HyperFlex, kami cukup membuat Stretch Cluster dengan jumlah node yang sama di kedua situs. Dalam hal ini, faktor replikasi 2 + 2 digunakan.
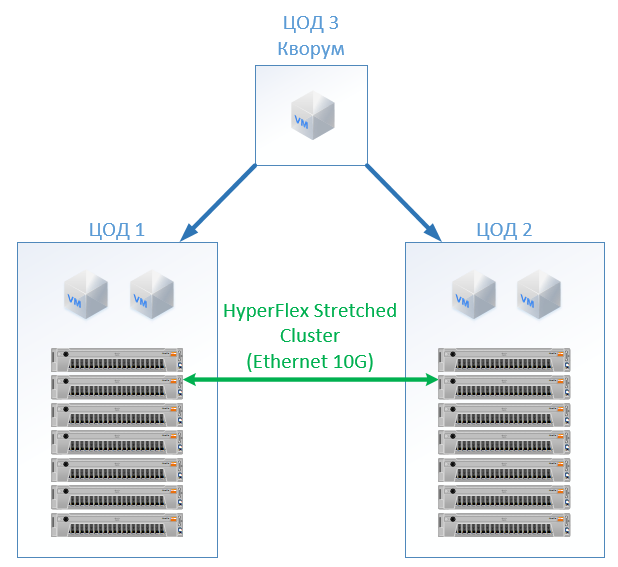
Konfigurasi berikut telah berubah:
Dalam semua perhitungan, saya tidak memperhitungkan infrastruktur jaringan, biaya pusat data, dll: semuanya akan sama untuk arsitektur klasik dan untuk solusi HyperFlex.
Pada biaya HyperFlex ternyata 5% lebih mahal. Perlu dicatat di sini bahwa untuk sumber daya CPU / RAM, saya mendapat bias untuk Cisco, karena dalam konfigurasi itu mengisi saluran pengendali memori secara merata. , , , « », . , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
Referensi