
Halo, Habr! Kami terus mempublikasikan ulasan artikel ilmiah dari anggota komunitas Open Data Science dari saluran #article_essense. Jika Anda ingin menerimanya sebelum orang lain - bergabunglah dengan komunitas !
Artikel untuk hari ini:
- Persamaan Diferensial Biasa Neural (University of Toronto, 2018)
- Pembelajaran Semi-Unsupervised dengan Deep Generative Models: Clustering dan Klasifikasi menggunakan Label Ultra-Sparse (University of Oxford, The Alan Turing Institute, London, 2019)
- Mengungkap dan Mengurangi Bias Algoritma melalui Struktur Laten yang Dipelajari (Massachusetts Institute of Technology, Universitas Harvard, 2019)
- Penguatan pembelajaran yang mendalam dari preferensi manusia (OpenAI, DeepMind, 2017)
- Menjelajahi Jaringan Saraf Tiruan Secara Acak untuk Pengenalan Gambar (Facebook AI Research, 2019)
- Photofeeler-D3: Jaringan Saraf Tiruan dengan Pemodelan Pemilih untuk Peringkat Foto Kencan (Photofeeler Inc., 2019)
- MixMatch: Pendekatan Holistik untuk Pembelajaran Semi-Supervisi (Google Reasearch, 2019)
- Membagi dan Taklukkan Ruang Sematan untuk Pembelajaran Metrik (Universitas Heidelberg, 2019)
Tautan ke koleksi seri terakhir: 1. Persamaan Diferensial Biasa Neural
Penulis: Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud (University of Toronto, 2018)
→ Artikel asli
Penulis ulasan: George Ignatov (dalam slack a2dy2n7okhtp)
Penghargaan Kertas Terbaik NIPS

Para penulis artikel mencatat bahwa jaringan seperti-ResNet sangat mirip dengan metode Euler untuk menyelesaikan persamaan diferensial. Jika demikian, lalu mengapa tidak segera membawa ide ke maksimal: bayangkan jaringan saraf dalam bentuk persamaan diferensial dan dapatkan
- Sebuah jaringan dengan jumlah lapisan yang berubah-ubah, yang dapat diubah kapan saja selama pelatihan dan inferensi. Lebih banyak lapisan -> konversi yang lebih presisi dan lebih lancar (dan sebaliknya).
- Jumlah parameter yang jauh lebih kecil, oleh karena itu, menurunkan biaya memori.
NODE melalui analogi:
- - ini adalah bagaimana definisi output dari layer n dalam jaringan seperti resnet terlihat seperti, W - parameter.
- - ini akan terlihat seperti jaringan seperti NODE, asalkan n adalah kuantitas tersendiri.
- , - Metode Euler.
- - ta-da! Jaringan saraf bertenaga ODE.
Kami menyelesaikannya dengan ODEsolver kotak hitam, melempar gradien menggunakan metode sensitivitas adjoint (Pontryagin et al., 1962). Karena diferensiabilitasnya yang lengkap, NODE dapat dikombinasikan dengan jaringan saraf konvensional. Para penulis memposting kode di pytorch.
Artikel ini membahas 3 aplikasi:
- Perbandingan dengan arsitektur seperti-Net (di MNIST). NODE bekerja hampir tidak lebih buruk, sementara menggunakan parameter 3 kali lebih sedikit.
- Mengganti aliran yang dinormalisasi melalui NODE - Continous Normalalized Flows (dataset sintetis). Model baru mengurangi biaya komputasi dari O (n_hidden_units ^ 3) ke linier.
- Pemodelan kejadian sementara dengan pengamatan tidak teratur (dataset sintetis). Dataset lintasan spiral dihasilkan dari titik-titik sampel acak yang ditaburi dengan: garam: Gaussian noise untuk masuk akal. Ini menguji RNN dan NODE biasa, dan yang kedua lagi terbukti lebih baik.
Dalam cetakan kecil:
- Pelatihan minibatch menyebabkan semacam overhead komputasi, tetapi penulis berpendapat bahwa dalam praktiknya ini hampir tidak terlihat.
- Muncul dua hiperparameter baru: kedalaman jaringan dan toleransi kesalahan saat menyelesaikan ODE.
- Agar solusi ODE tetap unik, jaringan harus memiliki bobot yang terbatas dan menggunakan non-linear Lipshitz, seperti tanh atau relu.
Tautan ke ikhtisar yang lebih rinci tentang habr.
2. Pembelajaran Semi-Unsupervised dengan Deep Generative Model: Clustering dan Klasifikasi menggunakan Label Ultra-Sparse
Penulis Artikel: Matthew Willetts, Stephen Roberts dan Christopher Holmes
(Universitas Oxford, The Alan Turing Institute, London, 2019)
→ Artikel asli
Penulis ulasan: Alex Chiron (in sliron shiron8bit)
Para penulis mempertimbangkan kasus semi-tidak diawasi untuk masalah klasifikasi, ketika bagian dari kelas yang ada dalam markup karena bias seleksi tidak diberi label sama sekali, dan tidak begitu banyak yang diberi label sesuai dengan kelas data yang diketahui. Ini menciptakan masalah tambahan, karena sebagian besar model biasanya bekerja baik dalam mode semi-diawasi / diawasi (klasifikasi) atau tidak diawasi (clustering), dan dalam hal ini kita perlu mempertimbangkan kedua opsi. Selain itu, penggunaan algoritma semi-diawasi dapat menyebabkan fakta bahwa data yang tidak terisi akan ditugaskan sesuai dengan beberapa metrik kedekatan dengan kelas yang salah. Contoh hipotetis dari data tersebut adalah serangkaian pemindaian tumor. Kami mengambil bagian dari data dan menandai semua jenis tumor yang ada di bagian ini, tetapi ternyata jenis tumor lain hadir dalam data yang tersisa, dan variabilitas spesies yang dikenal dalam markup tidak sepenuhnya tercermin.
Para penulis terinspirasi oleh model generatif mendalam (contoh paling sederhana dari model seperti itu dengan kedalaman lapisan tunggal variabel tersembunyi adalah auto-encoder variasional, alias VAE): dalam karya sebelumnya, model tersebut berhasil diatasi dengan baik kasus semi-diawasi (M2, ADGM) dan pengelompokan ( VaDE, GM-VAE).
Mengapa tidak menyelesaikan 2 masalah pada saat yang sama (pembelajaran semi-diawasi pada kelas yang jarang diberi label dan tidak diawasi pada kelas yang tidak ditempatkan), menjaga ruang variabel laten terpelajar menjadi umum dan menggabungkan ide dari model di atas? Gagasan inilah yang mendasari model GM-DGM / AGM-DGM yang diusulkan dalam artikel.
Pertimbangkan model M2 dalam kasing semi-diawasi. Disebut demikian, karena di bawah M1, pencipta menyiratkan pelatihan berurutan VAE dan beberapa classifier (svm) untuk representasi laten yang dihasilkan dari z, tetapi M2 sudah diperoleh dari VAE dengan menambahkan ke lapisan variabel tersembunyi variabel y, yang bertanggung jawab untuk kelas yang kadang-kadang diamati.
,
dimana ,
Di sini q adalah encoder, p adalah decoder, bagian - Penggolong langsung terlatih.
Untuk kasus tanpa pengawasan / semi-tidak diawasi, M2 tidak berfungsi - keruntuhan posterior terjadi, bagian klasifikasi q_phi (y | x) runtuh ke distribusi a priori p (y). Penulis GM-VAE dalam artikelnya juga menunjukkan ketidakmampuan M2 dalam praktek dan mencatat bahwa seringkali ketika mengimplementasikan M2, lapisan pertama dari dekoder h1 sangat mirip dengan campuran Gaussians.
Berdasarkan pengamatan ini, GM-VAE menggunakan lapisan eksplisit dari variabel tersembunyi untuk mengelompokkan campuran Gaussian untuk pengelompokan, yang juga diulangi oleh penulis artikel yang sedang ditinjau. Dengan demikian, model GM-DGM, yang memungkinkan operasi yang sukses dalam mode semi-tanpa pengawasan, adalah modifikasi VAE menggunakan campuran Gaussians dalam lapisan tersembunyi, tergantung pada variabel kelas y, dengan fungsi dua istilah di atas untuk menghitung dan memaksimalkan ELBO.
Para penulis artikel melakukan percobaan pada versi semi-tanpa pengawasan dari Mode-MNIST: mereka menghapus label dari 5 kelas pertama, 5 kelas yang tersisa meninggalkan 5% dari label, sementara mereka menerima akurasi total 77,2% terhadap 53% untuk M2. Kemungkinan menggunakan model untuk pengelompokan juga ditunjukkan (yang tidak mengejutkan, karena hampir GM-VAE).
3. Mengungkap dan Mengurangi Bias Algoritma melalui Struktur Laten yang Dipelajari
Penulis: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N. Bhatia, Daniela Rus (Institut Teknologi Massachusetts, Universitas Harvard, 2019)
→ Artikel asli
Penulis ulasan: Alex Chiron (in sliron shiron8bit)
Baru-baru ini, semakin sering di media Anda dapat menemukan berita yang menyentuh topik bias dalam data, terutama mengenai algoritma yang terkait dengan individu - dengan pertumbuhan penerapannya, risiko dampak negatif yang kuat pada kategori dan kelompok orang yang tidak cukup (atau berlebihan) disajikan dalam dataset. Salah satu contoh terakhir adalah studi yang menunjukkan akurasi kurang dalam mendeteksi pejalan kaki dengan warna kulit gelap (dalam konteks deteksi objek pada dataset BDD100K dan MSCOCO standar, tautan ). Pendekatan dasar untuk menghilangkan bias:
- Penyeimbangan kelas menggunakan resampling (membutuhkan pemahaman apriori tentang struktur data tersembunyi).
- Pembuatan data yang tidak bias (misalnya, penggunaan GAN untuk menghasilkan individu dengan beragam warna kulit ).
- Clustering dan resampling selanjutnya.
- Anda masih bisa menunggu hingga set data IBM Diversity in Faces dibawa ke academictorrents.
Para penulis artikel menawarkan modifikasi VAE dan pengambilan sampel, dengan mempertimbangkan distribusi variabel laten z, yang dapat mengurangi pengaruh bias dalam data pada tahap pelatihan.
Jadi, ide utama di balik DB-VAE adalah:
- Pertimbangkan masalah klasifikasi di mana kita memiliki dataset pelatihan {(x, y)}, x adalah fitur m-dimensi, y adalah label d-dimensi, dan tugas kita adalah memperkirakan pemetaan X-> Y.
- Ambil VAE, tetapi selain vektor z variabel tersembunyi z dari dimensi 2k kita akan memaksa pembuat enkode (saya ingat 2 di sini karena kita berurusan dengan rata-rata dan varian) untuk juga belajar vektor dimensi d, yang bertanggung jawab untuk label yang disebutkan di atas. Dalam hal ini, decoder hanya menerima vektor z sebagai input. Dengan demikian, kita mendapatkan kemiripan pembelajaran semi-diawasi, di mana bagian dari model dipelajari untuk merekonstruksi input, dan sebagian adalah untuk memecahkan masalah tertentu (klasifikasi).
- Kami mengontrol pelatihan model karena kerugian gabungan, menggabungkan standar untuk kehilangan VAE (rekonstruksi + KL divergensi) dan kehilangan untuk masalah tambahan (misalnya, cross-entropy untuk masalah klasifikasi biner).
- Perhatian khusus diberikan pada fakta bahwa Anda perlu mengontrol pelatihan tentang data yang tidak ingin Anda debiasing (yaitu, jangan mundur dari dekoder).
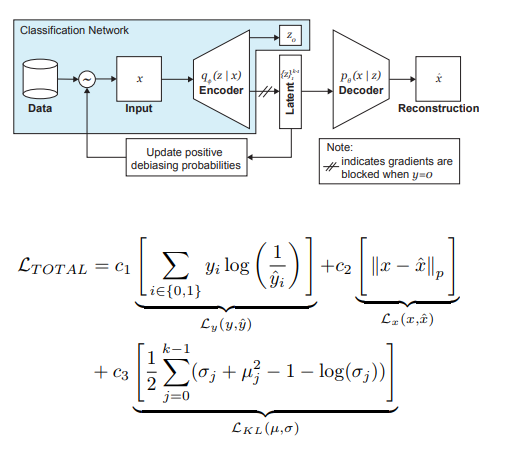
Peran paling penting dalam menghilangkan rasa sakit orang kulit hitam dimainkan dengan pengambilan sampel adaptif pada tahap pelatihan. Kami ingin memilih sampel langka (dari sudut pandang beberapa faktor tersembunyi, tidak diidentifikasi secara eksplisit), jadi kami beralih ke histogram untuk setiap dimensi ruang variabel tersembunyi z, produk yang dapat mendekati perkiraan distribusi Q (z | X) data di seluruh ruang Z. Saat membentuk batch baru, kami akan memperhitungkan distribusi 'kebalikan' ke Q (z | X) W (z (x) | X), yang menentukan probabilitas memilih contoh dalam batch (alfa adalah parameter hiper yang menentukan tingkat debiasing), memperbarui Q (z | X) di setiap era. Seperti yang Anda lihat, debiasing tidak dipilih sebelumnya, tetapi didasarkan pada variabel laten yang dipelajari.
Sebagai percobaan, penulis memecahkan masalah klasifikasi biner (menemukan wajah di foto). Untuk pelatihan, kami mengumpulkan dataset, yang terdiri dari 200 ribu orang dengan CelebA dan 200 ribu bukan orang dengan Imagenet, mengubah ukuran gambar menjadi 64x64. Seperti disebutkan sebelumnya, selama pelatihan, backpropagation dari decoder untuk foto tanpa wajah diblokir (y = 0). Setelah pelatihan, mereka divalidasi di Pilot Benchmark Parlemen (PPB) (1.270 foto orang dari parlemen Afrika Selatan, Rwanda, Senegal, Swedia, Finlandia, Islandia): untuk semua alpha> 0, akurasi deteksi dalam kategori laki-laki gelap, perempuan gelap, perempuan muda meningkat dibandingkan dengan opsi tanpa debiasing.
4. Penguatan pembelajaran yang mendalam dari preferensi manusia
Penulis: Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (OpenAI, DeepMind, 2017)
→ Artikel asli
Penulis ulasan: Dmitry Nikulin (in dniku slack)
Artikel ini adalah tentang bagaimana menerapkan ide lama dalam konteks deep reinforcement learning (RL). Ide: mari kita minta seseorang untuk mengevaluasi perilaku agen, dan berdasarkan ini kita akan mempelajari fungsi hadiah. Masalahnya adalah bahwa RL yang dalam sangat rakus, dan waktu manusia mahal. Artikel ini menyediakan serangkaian peretasan yang memungkinkan Anda mengurangi jam kerja menjadi nilai wajar.
Fungsi hadiah adalah fungsi berpasangan (observasi, tindakan). Ini diatur dengan rata-rata prediksi ansambel jaringan saraf. Algoritma RL yang digunakan (dalam artikel A2C untuk Atari dan TRPO untuk Mujoco) percaya bahwa rata-rata ini adalah hadiah nyata, dan dilatih untuk itu. Dengan demikian, artikel ini berfokus pada masalah pelatihan ansambel ini.
Ansambel dilatih tentang evaluasi manusia. Setiap peringkat disusun sebagai berikut. Seseorang ditampilkan dua video dengan panjang 1-2 detik. Dia dapat menilai pasangan seperti itu dalam 4 cara: kiri lebih baik / kanan lebih baik / terlalu mirip / tidak bisa dibandingkan. Jika seseorang berkata "tidak bisa dibandingkan", maka penilaian seperti itu dibuang. Kalau tidak, triple (σ¹, σ², μ) diingat, di mana σⁱ adalah lintasan agen dalam video yang sesuai (mis., Daftar pasangan (obs, act)), dan μ adalah pasangan (1, 0), (0, 1 ) atau (½, ½). Lebih lanjut, diyakini bahwa prediksi hadiah untuk lintasan sama dengan jumlah prediksi untuk masing-masing pasangan (obs, act). Terakhir, kami cukup mengoptimalkan softmax_cross_entropy_with_logits.
Diyakini bahwa seseorang dengan probabilitas 10% memilih jawaban acak, dan ini diperhitungkan saat membuat sampel pelatihan. Bagian 2.2.3 dari artikel ini memberikan beberapa trik dan menulis semua formula.
Pasang klip untuk didemonstrasikan kepada seseorang dipilih sebagai berikut: sejumlah besar klip diambil sampelnya, dispersi ensembel dipertimbangkan pada mereka, dan pasangan acak klip dengan dispersi tinggi ditunjukkan kepada orang-orang. Para penulis mengatakan bahwa saya ingin memilih sesuai dengan nilai informasi, tetapi ini adalah pekerjaan di masa depan.
Para penulis menjalankan tes pada Atari dan Mujoco, dengan peringkat manusia nyata (kontraktor yang disewa) dan sintetis (peringkat dihasilkan sesuai dengan fungsi hadiah yang sebenarnya), dan pada saat yang sama mereka dibandingkan dengan RL biasa. Dengan jumlah penilaian yang kurang lebih sama, tes sintetis dan nyata bekerja dengan cara yang sama. Selain itu, yang mengejutkan, RL reguler (yang melihat fungsi hadiah yang sebenarnya) tidak selalu bekerja lebih baik.
Akhirnya, selain mencoba melatih agen untuk mendapatkan banyak hadiah dalam arti biasa, artikel itu juga memberikan contoh dua tugas lain: Hopper di Mujoco melakukan backflip, dan mesin di Atari Enduro tidak menyalip mobil lain, tetapi berjalan paralel dengan mereka. Ternyata untuk menyelesaikan kedua masalah tersebut.
Kesimpulannya: contoh ini menggambarkan upaya mereproduksi artikel ini. Upaya itu berhasil, tetapi butuh 8 bulan kerja di waktu luang dan 220 jam waktu murni, yang setengahnya lagi untuk debug versi paling sederhana.
5. Menjelajahi Jaringan Saraf Kabel Secara Acak untuk Pengenalan Gambar
Penulis: Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He (Penelitian AI Facebook, 2019)
→ Artikel asli
Penulis ulasan: Egor Panfilov (dalam slack tutk1ja)
Pendahuluan:
Pekerjaan ini mengangkat masalah menghasilkan arsitektur jaringan saraf. Saat ini, banyak trik arsitektur yang diketahui (LSTM, Inception, ResNet, DenseNet), yang dapat meningkatkan kualitas banyak tugas, tetapi mereka juga memperkenalkan arsitektur tertentu yang kuat sebelum masuk ke dalam model. Alih-alih solusi yang disebutkan, google mendorong maju dengan pencarian arsitektur neural (NAS), di mana pencarian arsitektur untuk tugas tertentu dilakukan dari modul yang telah ditentukan melalui RL-NASNet, AmoebaNet.
Para penulis berpendapat bahwa kedua pendekatan di mana desain ditentukan oleh manusia dan NAS diperkenalkan terlalu ketat sebelum arsitektur. Dalam upaya untuk menguranginya, mereka mencoba menggunakan pendekatan generatif parametrik dari jaringan saraf, di mana pengkabelan (koneksi) elemen dilakukan secara acak. Ternyata pendekatan pengkabelan acak telah dieksplorasi sejak 1940-an oleh para ilmuwan seperti A. Turing, M. Minsky, F. Rosenblatt. Sebagai argumen lain, penulis ingat bahwa dalam studi neuroscientific terungkap bahwa struktur koneksi neuronal pada organisme dari satu spesies berbeda (hingga tingkat tertentu, tentu saja). Ini berlaku untuk cacing dan bayi manusia. Secara umum, gagasan pembentukan prosedural dari jaringan saraf kedengarannya menarik dan menjanjikan, seperti itulah pekerjaannya.
Metode:
Mari kita coba memodulasi proses pembuatan prosedural arsitektur jaringan saraf melalui pendekatan grafik. Langkah-langkah awal adalah sebagai berikut:
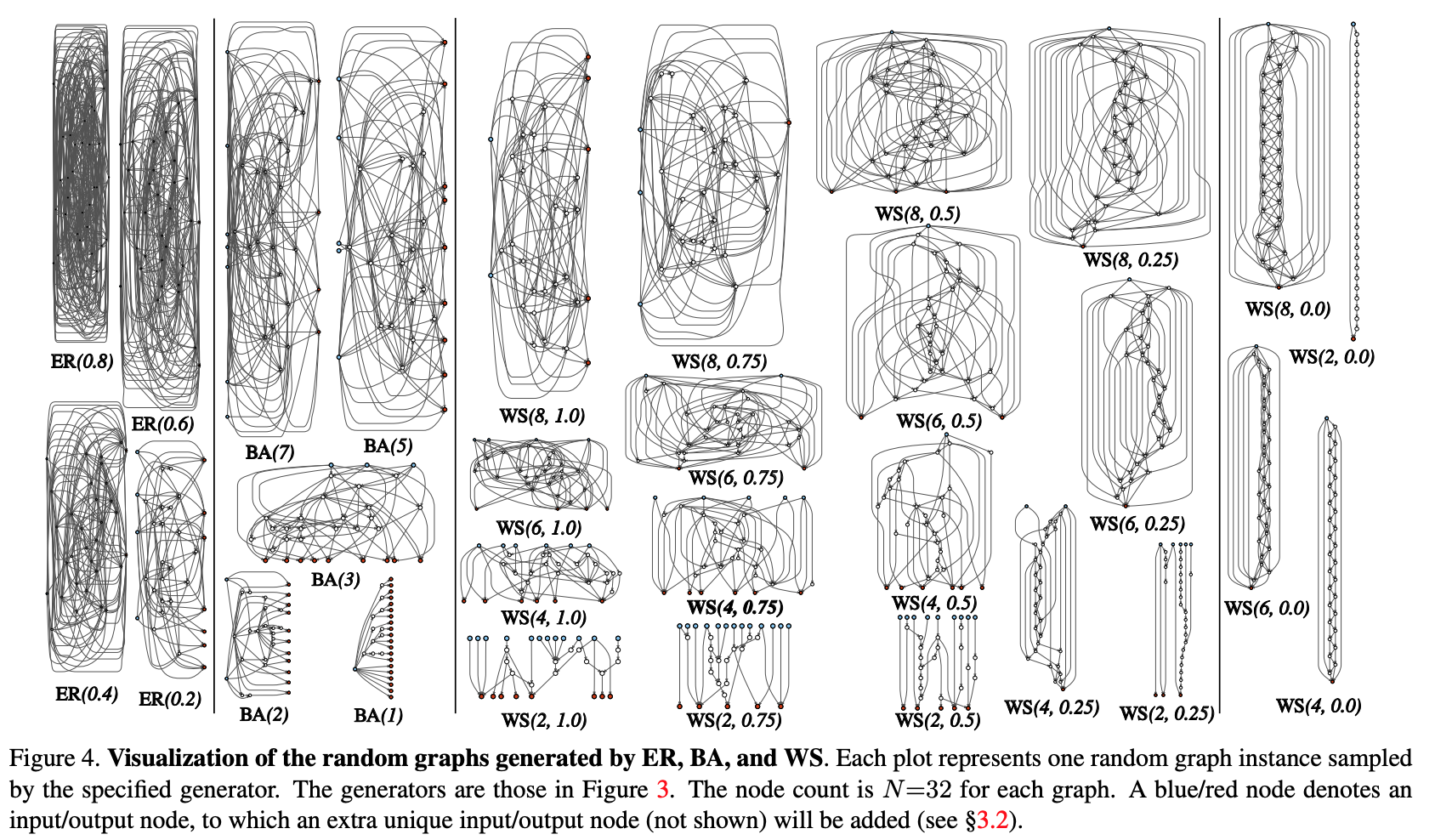
- Grafik stokastik dihasilkan dari keluarga parameter. Metode klasik yang digunakan: Erdos-Renyi (ER), Barabasi-Albert (BA), dan Watts-Strogatz (WS).
- Grafik dikonversi ke jaringan saraf:
- semua tepi grafik diasumsikan sebagai pembawa dari tensor data;
- untuk setiap simpul grafik, jenis operasi yang dilakukan ditentukan: (I) agregasi dengan menjumlahkan dengan bobot yang terlatih, (II) transformasi - ReLU + konvolusi + BN, (III) distribusi - transfer tensor di sepanjang setiap tepi output;
- menurut hasil dari subclause sebelumnya, bisa ada beberapa input dan output simpul, tetapi saya ingin memiliki 1 titik masuk dalam grafik dan 1 titik output. Node tersebut dibuat secara terpisah. Input satu hanya menyebar salinan tensor ke semua simpul input dari grafik, output satu mempertimbangkan rata-rata tertimbang dari semua simpul output. Sebagai hasil dari langkah 1 dan 2, pada kenyataannya, bukan jaringan lengkap dibuat, tetapi hanya satu dari modul (seperti conv_1, ... di populer pembuat kode konvolusional). Untuk mendapatkan jaringan saraf sepenuhnya:
- Beberapa modul dibuat dan dihubungkan secara seri. Untuk mengurangi jumlah parameter jaringan, transformasi di semua simpul input modul dilakukan dengan langkah 2x2. Jumlah saluran dalam transisi ke modul berikutnya bertambah 2 kali. Untuk melakukan percobaan pada tugas tertentu:
- Pada output jaringan, head ditambahkan untuk klasifikasi.
Hasil:
Pengujian metode dilakukan pada masalah klasifikasi di ImageNet. Kualitas jaringan saraf yang dihasilkan ternyata setara dengan arsitektur SotA, kalah sedikit dari Google DeepBrain AmoebaNet baru-baru ini: (dengan jumlah parameter yang sebanding).
Kami memeriksa apa yang akan terjadi jika kami menghapus simpul / tepi acak dari grafik yang dihasilkan. Pengurangan kualitas metrik, masing-masing bergantung pada jumlah sisi keluaran / simpul input yang berdekatan. Secara umum, kualitasnya menurun, tetapi tidak kritis.
Para penulis juga memeriksa apakah transfer belajar berfungsi dengan arsitektur ini. Dalam tugas deteksi COCO, tulang punggung Lebih Cepat R-CNN dengan FPN diganti dengan jaringan yang dibuat dan dilatih sebelumnya. Hasil penelitian menunjukkan bahwa kualitas model tidak lebih buruk daripada ResNeXt-50 / -101. Tetapi bahkan fakta bahwa pembelajaran transfer dimulai, cukup menghibur.
6. Photofeeler-D3: Jaringan Saraf Tiruan dengan Pemodelan Pemilih untuk Peringkat Foto Kencan
Penulis artikel: Agastya Kalra dan Ben Peterson (Photofeeler Inc., 2019)
→ Artikel asli
Penulis ulasan: Alex Chiron (in sliron shiron8bit)
Para penulis menyarankan Photofeeler-D3: arsitektur jaringan untuk mengevaluasi foto dari situs kencan dalam 3 arah / ciri - seberapa pintar seseorang, dapat dipercaya dan menarik (mengabaikan efek halo!). Tugas tersebut muncul berdasarkan survei oleh The Guardian, yang menurutnya 90% orang memutuskan untuk masa depan semata-mata berdasarkan evaluasi foto-foto satelit yang potensial.
Jadi, jaringan terdiri dari blok-blok berikut:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
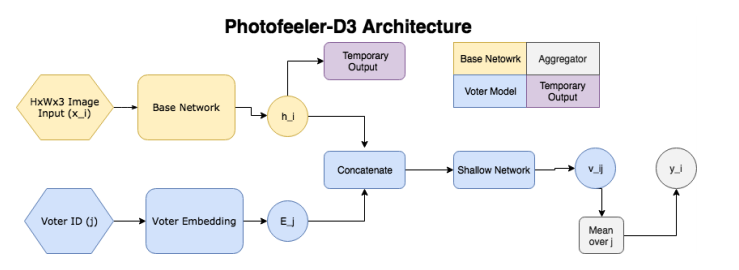
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
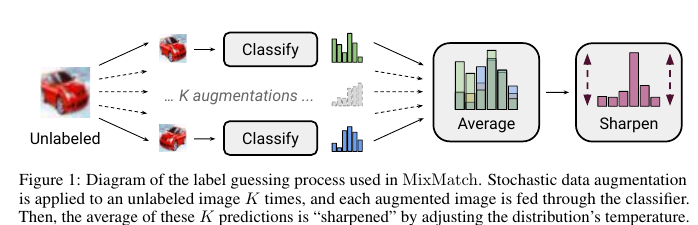
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
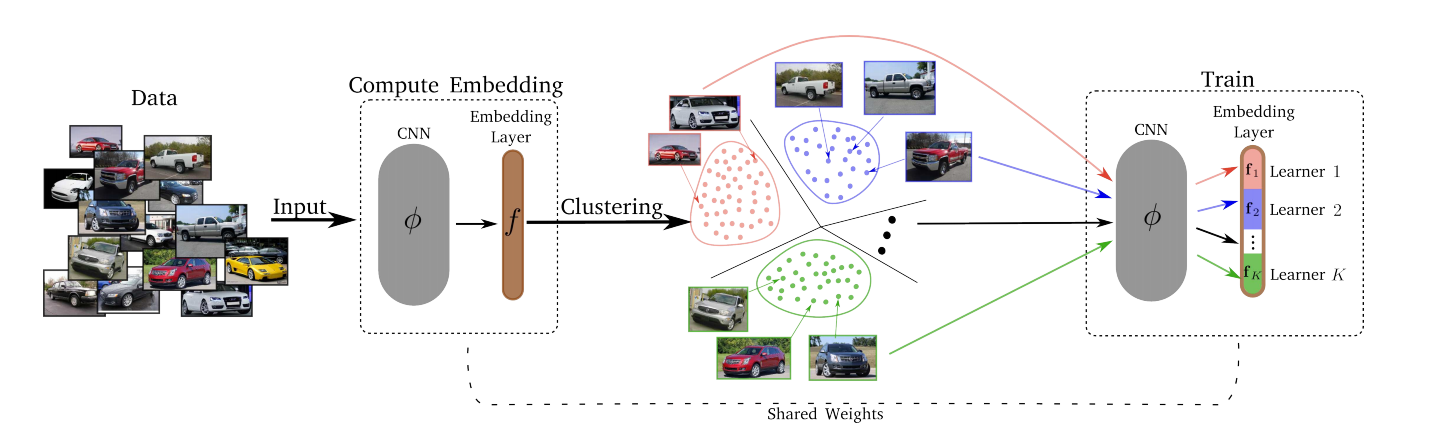
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Conquer.
Divide K K . , , , -, , . , T (Divide) . - Merjim - kami menggabungkan semua Lerners (irisan lapisan embedding). Lalu kita latih layer embedding pada seluruh dataset untuk membuat teman Lerners.
Hasil eksperimental: semua orang memenangkan beberapa set data.
Kehilangan bisa berupa apa saja - Kehilangan Triplet, Kehilangan Margin, Proxy-NCA, dll.
Jumlah optimal K Lerners ternyata 8 (dimensi seluruh ruang penyematan adalah 128, sehingga masing-masing Lerner memecahkan subtugasnya dalam ruang 16 dimensi).
Perubahan T dari 1 menjadi 10 tidak secara signifikan mempengaruhi apa pun, jadi T = 2 digunakan.