Kami menyajikan lembar contekan lengkap di mana kami memberi tahu dengan kata-kata sederhana apa kecerdasan buatan “membuat” dan bagaimana semuanya bekerja.
Apa perbedaan antara Kecerdasan Buatan, Pembelajaran Mesin, dan Ilmu Data?
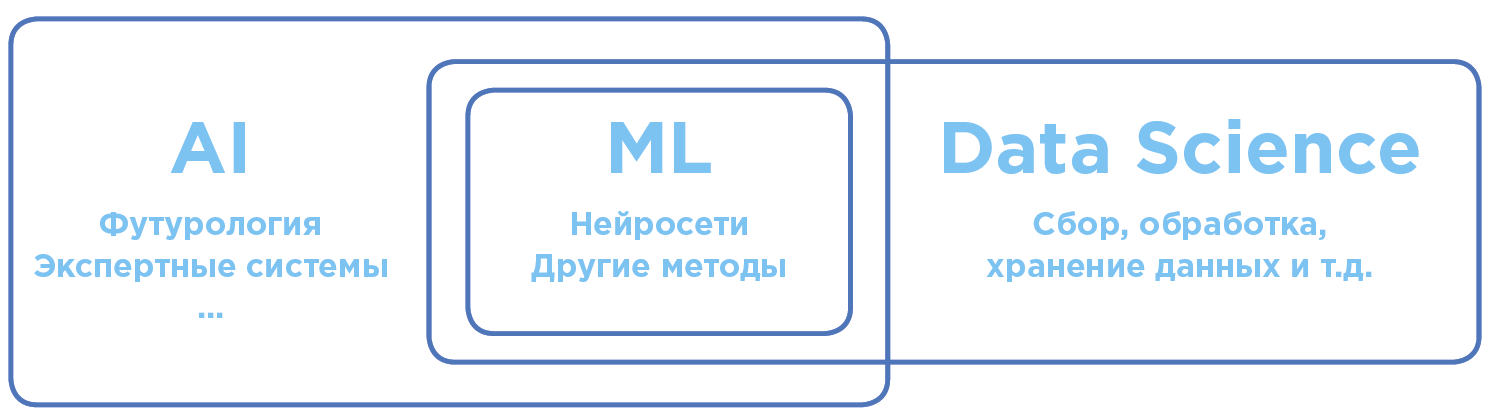 Diferensiasi konsep di bidang kecerdasan buatan dan analisis data.
Diferensiasi konsep di bidang kecerdasan buatan dan analisis data.Kecerdasan Buatan - AI (Kecerdasan Buatan)
Dalam pengertian universal global, AI adalah istilah seluas mungkin. Ini mencakup teori ilmiah dan praktik teknologi spesifik untuk membuat program yang dekat dengan kecerdasan manusia.
Pembelajaran Mesin - ML (Pembelajaran Mesin)
Bagian AI, diterapkan secara aktif dalam praktik. Hari ini, ketika datang untuk menggunakan AI dalam bisnis atau manufaktur, paling sering kita maksudkan Machine Learning.
Algoritma ML, sebagai aturan, bekerja berdasarkan prinsip model matematika pembelajaran yang melakukan analisis berdasarkan sejumlah besar data, sementara kesimpulan diambil tanpa mengikuti aturan yang ditetapkan secara kaku.
Jenis tugas yang paling umum dalam pembelajaran mesin adalah belajar dengan seorang guru. Untuk mengatasi masalah seperti ini, pelatihan digunakan pada berbagai data yang jawabannya diketahui sebelumnya (lihat di bawah).
Ilmu Data - DS (Ilmu Data)
Ilmu dan praktik menganalisis sejumlah besar data menggunakan semua jenis metode matematika, termasuk pembelajaran mesin, serta menyelesaikan tugas terkait yang berkaitan dengan pengumpulan, penyimpanan, dan pemrosesan array data.
Data Para ilmuwan adalah pakar data, khususnya, yang menganalisis menggunakan pembelajaran mesin.

Bagaimana cara kerja pembelajaran mesin?
Pertimbangkan pekerjaan ML pada contoh tugas penilaian perbankan. Bank memiliki data tentang pelanggan yang ada. Dia tahu jika seseorang memiliki pembayaran pinjaman yang terlambat. Tugasnya adalah menentukan apakah pelanggan potensial baru akan melakukan pembayaran tepat waktu. Untuk setiap klien, bank memiliki kombinasi ciri / karakteristik tertentu: jenis kelamin, usia, pendapatan bulanan, profesi, tempat tinggal, pendidikan, dll. Di antara karakteristiknya mungkin parameter yang tidak terstruktur dengan baik, seperti data dari jejaring sosial atau riwayat pembelian. Selain itu, data dapat diperkaya dengan informasi dari sumber eksternal: nilai tukar, data dari biro kredit, dll.
Mesin melihat klien apa pun sebagai kombinasi fitur:
. Di mana misalnya
- umur
- penghasilan, dan
- jumlah foto pembelian mahal per bulan (dalam praktiknya, sebagai bagian dari tugas serupa, Data Scientist bekerja dengan lebih dari seratus fitur). Setiap klien memiliki satu variabel lagi -
dengan dua kemungkinan hasil: 1 (ada pembayaran terlambat) atau 0 (tidak ada pembayaran terlambat).
Totalitas semua data
dan
- ada Set Data. Dengan menggunakan data ini, Data Scientist membuat model
, memilih dan memodifikasi algoritma pembelajaran mesin.
Dalam hal ini, model analisisnya terlihat seperti ini:
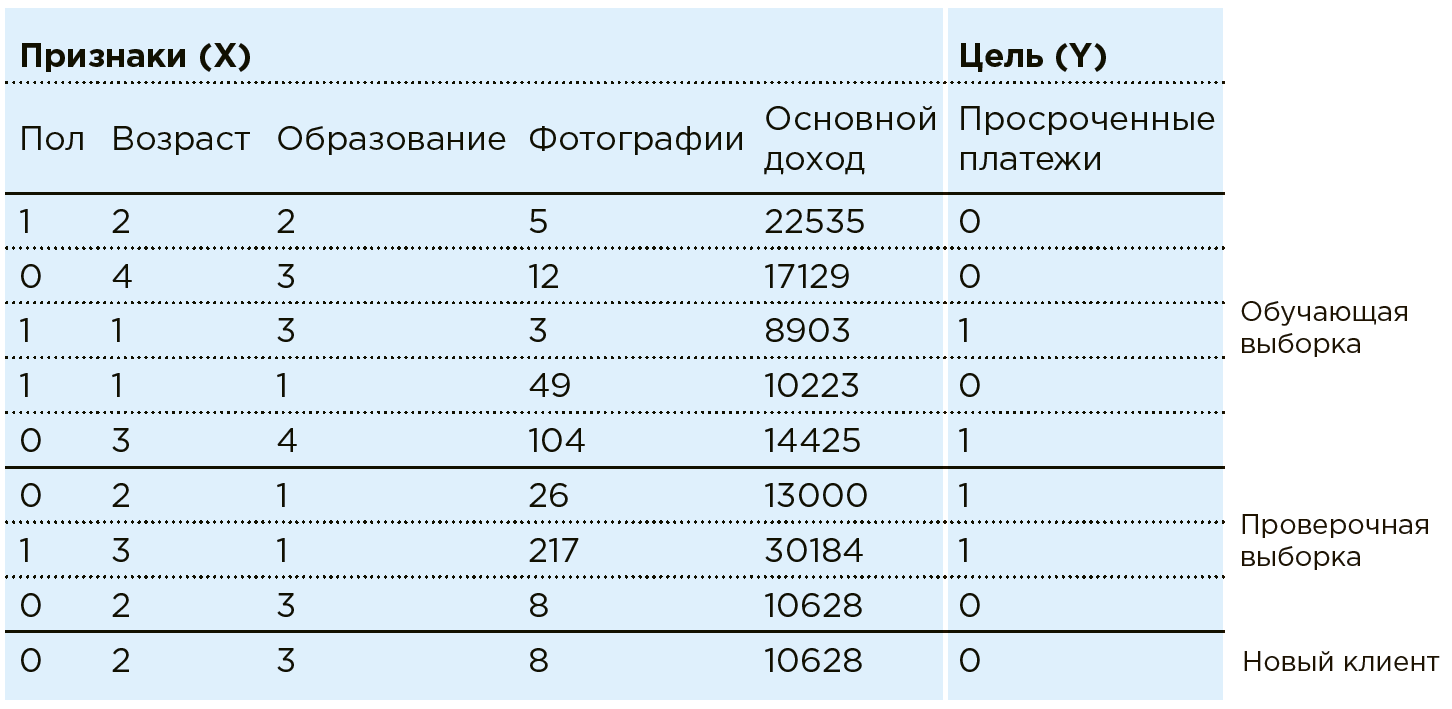
Algoritma pembelajaran mesin menyiratkan pendekatan bertahap dari respon model
untuk jawaban yang benar (yang diketahui sebelumnya dalam Kumpulan Data pelatihan). Ini adalah pelatihan dengan seorang guru dalam sampel tertentu.
Dalam praktiknya, paling sering mesin hanya belajar pada bagian array (80%), menggunakan sisanya (20%) untuk memverifikasi kebenaran dari algoritma yang dipilih. Sebagai contoh, suatu sistem dapat dilatih pada larik yang darinya data pasangan wilayah dikecualikan, di mana keakuratan model diverifikasi setelahnya.
Sekarang, ketika klien baru datang ke bank, sesuai dengan yang
bank belum dikenal, sistem akan memberi tahu keandalan pembayar berdasarkan data yang diketahui tentang itu
.
Namun, mengajar dengan seorang guru bukanlah satu-satunya kelas masalah yang dapat diselesaikan ML.
Rangkaian tugas lain adalah pengelompokan, yang dapat memisahkan objek sesuai dengan atributnya, misalnya, untuk mengidentifikasi berbagai kategori pelanggan agar mereka dapat membuat penawaran individual.
Juga, dengan bantuan algoritma-ML, tugas-tugas seperti pemodelan komunikasi spesialis pendukung atau menciptakan karya seni yang tidak dapat dibedakan dari kreasi manusia (misalnya, jaringan saraf melukis gambar) diselesaikan.
Kelas tugas yang baru dan populer adalah pelatihan penguatan, yang berlangsung di lingkungan terbatas yang mengevaluasi tindakan agen (misalnya, menggunakan algoritma ini, AlphaGo diciptakan yang mengalahkan orang di Go).

Jaringan saraf
Salah satu metode Machine Learning. Algoritme terinspirasi oleh struktur otak manusia, yang didasarkan pada neuron dan koneksi di antara mereka. Dalam proses pembelajaran, koneksi antar neuron disesuaikan sedemikian rupa untuk meminimalkan kesalahan seluruh jaringan.
Fitur dari jaringan saraf adalah keberadaan arsitektur yang cocok untuk hampir semua format data: jaringan saraf konvolusional untuk menganalisis gambar, jaringan saraf berulang untuk menganalisis teks dan urutan, auto-encoders untuk kompresi data, jaringan saraf generatif untuk membuat objek baru, dll.
Pada saat yang sama, hampir semua jaringan saraf memiliki batasan yang signifikan - untuk pelatihan mereka, sejumlah besar data diperlukan (urutan besarnya lebih besar dari jumlah koneksi antara neuron dalam jaringan ini). Karena kenyataan bahwa baru-baru ini volume data yang siap untuk analisis telah tumbuh secara signifikan, cakupannya juga bertambah. Dengan bantuan jaringan saraf saat ini, misalnya, tugas pengenalan gambar diselesaikan, seperti menentukan usia dan jenis kelamin seseorang dari sebuah video, atau memiliki helm pada pekerja.
Interpretasi hasil
Bagian Ilmu Data, yang memungkinkan untuk memahami alasan untuk memilih satu atau solusi lain dengan model ML.
Ada dua bidang utama penelitian:
- Mempelajari model sebagai kotak hitam. Menganalisis contoh-contoh yang dimuat ke dalamnya, algoritma membandingkan fitur dari contoh-contoh ini dan kesimpulan dari algoritma, membuat kesimpulan tentang prioritas dari salah satu dari mereka. Dalam kasus jaringan saraf, kotak hitam biasanya digunakan.
- Mempelajari sifat-sifat model itu sendiri. Studi tentang karakteristik yang digunakan model untuk menentukan tingkat kepentingannya. Paling sering diterapkan pada algoritma berdasarkan metode pohon keputusan.
Misalnya, ketika memperkirakan cacat dalam produksi, tanda-tanda benda
- ini adalah data tentang pengaturan mesin, komposisi kimia bahan baku, indikator sensor, video dari conveyor, dll. Dan jawabannya
- ini adalah jawaban untuk pertanyaan apakah akan ada pernikahan atau tidak.
Secara alami, produksi tidak hanya tertarik pada ramalan pernikahan itu sendiri, tetapi juga pada interpretasi hasil, yaitu, alasan pernikahan untuk eliminasi berikutnya. Ini mungkin karena tidak adanya perawatan mesin, kualitas bahan baku, atau pembacaan yang tidak normal dari beberapa sensor yang harus diperhatikan oleh teknolog.
Oleh karena itu, dalam kerangka proyek untuk prakiraan pernikahan dalam produksi, model ML tidak hanya dibuat, tetapi pekerjaan juga harus dilakukan untuk menafsirkannya, yaitu, untuk mengidentifikasi faktor-faktor yang mempengaruhi pernikahan.

Kapan pembelajaran mesin efektif?
Ketika ada satu set besar data statistik, tetapi tidak mungkin atau sangat melelahkan untuk menemukan dependensi menggunakan metode matematika ahli atau klasik. Jadi, jika ada lebih dari seribu parameter pada input (termasuk numerik dan teks, serta video, audio dan gambar), maka tidak mungkin untuk menemukan ketergantungan hasilnya pada mereka tanpa mesin.
Sebagai contoh, di samping zat itu sendiri yang memasuki interaksi, reaksi kimia dipengaruhi oleh banyak parameter: suhu, kelembaban, bahan wadah di mana itu terjadi, dll. Sulit bagi seorang ahli kimia untuk memperhitungkan semua tanda-tanda ini untuk menghitung waktu reaksi secara akurat. Kemungkinan besar, dia akan mempertimbangkan beberapa parameter kunci dan akan didasarkan pada pengalamannya. Pada saat yang sama, berdasarkan data dari reaksi sebelumnya, pembelajaran mesin akan dapat memperhitungkan semua tanda dan memberikan perkiraan yang lebih akurat.
Bagaimana Big Data dan pembelajaran mesin terkait?
Untuk membangun model pembelajaran mesin, dalam kasus yang berbeda, numerik, tekstual, foto, video, audio dan data lainnya diperlukan. Untuk menyimpan dan menganalisis informasi ini, ada seluruh area teknologi - Big Data. Untuk penyimpanan dan analisis data yang optimal, mereka menciptakan "Danau Data" - penyimpanan terdistribusi khusus untuk volume besar informasi yang tidak terstruktur berdasarkan teknologi Big Data.
Digital ganda sebagai paspor elektronik
Digital ganda adalah salinan virtual objek material, proses atau organisasi, yang memungkinkan Anda untuk mensimulasikan perilaku objek / proses yang dipelajari. Misalnya, Anda dapat melihat hasil awal dari perubahan komposisi kimia di pabrik setelah perubahan dalam pengaturan jalur produksi, perubahan penjualan setelah kampanye iklan dengan karakteristik tertentu, dll. Dalam hal ini, perkiraan dibuat oleh digital ganda berdasarkan akumulasi data, dan skenario serta situasi masa depan dimodelkan termasuk metode pembelajaran mesin.
Apa yang dibutuhkan untuk pembelajaran mesin yang berkualitas?
Data Ilmiah! Merekalah yang membuat algoritma ramalan: mereka mempelajari data yang tersedia, mengajukan hipotesis, membangun model berdasarkan Set Data. Mereka harus memiliki tiga kelompok keterampilan utama: Melek TI, pengetahuan matematika dan statistik, dan pengalaman substantif dalam bidang tertentu.
Pembelajaran mesin berdiri di atas tiga pilar
Pengambilan dataDapat digunakan data dari sistem terkait: jadwal kerja, rencana penjualan. Data juga dapat diperkaya oleh sumber eksternal: nilai tukar, cuaca, kalender hari libur, dll. Adalah penting untuk mengembangkan metodologi untuk bekerja dengan masing-masing jenis data dan berpikir melalui pipa untuk mengubahnya menjadi format model pembelajaran mesin (satu set angka).
KarakterisasiIni dilakukan bersama dengan para ahli dari bidang yang dibutuhkan. Ini membantu untuk menghitung data yang cocok untuk keperluan perkiraan: statistik dan perubahan dalam jumlah penjualan selama sebulan terakhir untuk perkiraan pasar.
Model pembelajaran mesinMetode pemecahan masalah bisnis ini dipilih oleh ilmuwan data secara independen berdasarkan pengalaman dan kemampuan berbagai model. Untuk setiap tugas tertentu, Anda harus memilih algoritma yang terpisah. Kecepatan dan akurasi hasil pengolahan data sumber secara langsung tergantung pada metode yang dipilih.
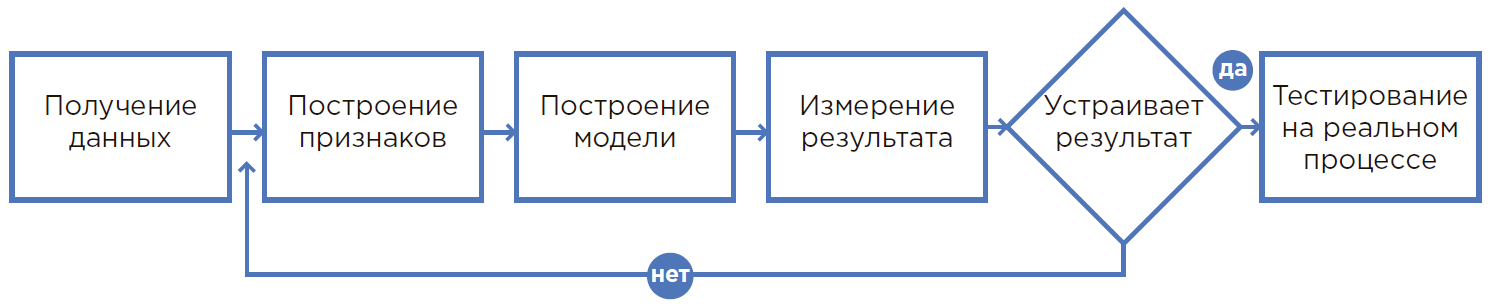 Proses menciptakan model ML.
Proses menciptakan model ML.Dari hipotesis ke hasil
1. Semuanya dimulai dengan hipotesis
Sebuah hipotesis muncul ketika menganalisis proses masalah, pengalaman karyawan, atau dengan pandangan segar pada produksi. Biasanya, hipotesis mempengaruhi proses di mana seseorang secara fisik tidak dapat memperhitungkan banyak faktor dan menggunakan pembulatan, asumsi, atau hanya melakukan seperti biasa.
Dalam proses ini, penggunaan pembelajaran mesin memungkinkan Anda untuk menggunakan lebih banyak informasi secara signifikan ketika membuat keputusan, oleh karena itu, dimungkinkan untuk mencapai hasil yang jauh lebih baik. Selain itu, otomatisasi proses menggunakan ML dan pengurangan ketergantungan pada orang tertentu secara signifikan meminimalkan faktor manusia (penyakit, konsentrasi rendah, dll.).
2. Penilaian hipotesis
Berdasarkan hipotesis yang dirumuskan, data yang diperlukan untuk pengembangan model pembelajaran mesin dipilih. Pencarian dilakukan untuk data yang relevan dan penilaian kesesuaian mereka untuk menanamkan model dalam proses saat ini ditentukan siapa yang akan menjadi penggunanya dan karena efek yang dicapai. Jika perlu, perubahan organisasi dan lainnya dilakukan.
3. Perhitungan dampak ekonomi dan pengembalian investasi (ROI)
Evaluasi dampak ekonomi dari solusi yang diterapkan dilakukan oleh spesialis bersama dengan departemen terkait: efisiensi, keuangan, dll. Pada tahap ini, Anda perlu memahami apa sebenarnya metrik (jumlah pelanggan yang diidentifikasi dengan benar / peningkatan output / penghematan bahan habis pakai, dll) dan mengartikulasikan tujuan yang diukur dengan jelas.
4. Rumusan matematis masalah
Setelah memahami hasil bisnis, perlu untuk memindahkannya ke bidang matematika - untuk menentukan metrik dan batasan pengukuran yang tidak dapat dilanggar. Data tahapan data
Seorang ilmuwan melakukan dalam hubungannya dengan pelanggan bisnis.
5. Pengumpulan dan analisis data
Penting untuk mengumpulkan data di satu tempat, menganalisisnya, mempertimbangkan berbagai statistik, memahami struktur dan hubungan tersembunyi dari data ini untuk membentuk tanda-tanda.
6. Membuat prototipe
Faktanya, ini adalah tes hipotesis. Ini adalah kesempatan untuk membangun model pada data saat ini dan awalnya memverifikasi hasil kerjanya. Biasanya, prototipe dibuat pada data yang ada tanpa mengembangkan integrasi dan bekerja dengan aliran secara real time.
Prototyping adalah cara cepat dan murah untuk memeriksa apakah masalah sedang diselesaikan. Ini sangat berguna ketika tidak mungkin untuk memahami terlebih dahulu apakah akan mungkin untuk mencapai efek ekonomi yang diinginkan. Selain itu, proses pembuatan prototipe memungkinkan Anda untuk menilai dengan lebih baik ruang lingkup dan detail proyek untuk mengimplementasikan solusi, untuk mempersiapkan pembenaran ekonomi untuk implementasi semacam itu.
DevOps dan DataOps
Selama operasi, tipe data baru dapat muncul (misalnya, sensor lain akan muncul di mesin atau jenis barang baru akan muncul di gudang) maka model perlu dilatih. DevOps dan DataOps adalah metodologi yang membantu mengatur kolaborasi dan proses end-to-end antara tim Ilmu Data, insinyur persiapan data, pengembangan TI dan layanan operasi, dan membantu menjadikan penambahan seperti itu bagian dari proses saat ini dengan cepat, tanpa kesalahan dan tanpa menyelesaikan setiap waktu dengan unik masalah.
7. Menciptakan solusi
Pada saat itu, ketika hasil pekerjaan prototipe menunjukkan pencapaian indikator yang meyakinkan, solusi lengkap dibuat di mana model pembelajaran mesin hanya merupakan komponen dari proses yang dipelajari. Selanjutnya, integrasi, pemasangan peralatan yang diperlukan, pelatihan staf, mengubah proses pengambilan keputusan, dll.
8. Pilot dan operasi industri
Selama operasi uji coba, sistem beroperasi dalam mode saran, sementara spesialis masih mengulangi tindakan yang biasa, setiap kali memberikan umpan balik pada perbaikan yang diperlukan untuk sistem dan meningkatkan akurasi perkiraan.
Bagian terakhir adalah operasi industri, ketika proses yang ditetapkan beralih ke pemeliharaan otomatis penuh.
Anda dapat mengunduh lembar cheat dari
tautan .
Besok di forum sistem kecerdasan buatan
RAIF 2019 pukul 09:30 - 10:45 akan ada diskusi panel: "AI untuk orang-orang: kami mengerti dengan kata-kata sederhana."
Pada bagian ini, dalam format debat, pembicara akan menjelaskan teknologi kompleks dengan kata-kata sederhana pada contoh kehidupan. Dan juga bahas topik-topik berikut:
- Apa perbedaan antara Kecerdasan Buatan, Pembelajaran Mesin, dan Ilmu Data?
- Bagaimana cara kerja pembelajaran mesin?
- Bagaimana cara kerja jaringan saraf?
- Apa yang dibutuhkan untuk pembelajaran mesin yang berkualitas?
- Apa itu markup, pelabelan data?
- Apa itu digital double dan bagaimana cara bekerja dengan salinan virtual dari objek material nyata?
- Apa esensi dari hipotesis? Bagaimana cara mendapatkan dari cara itu diajukan untuk evaluasi dan interpretasi hasil?
Diskusi dihadiri oleh:
Nikolay Marine, Direktur Teknologi, IBM di Rusia dan CIS
Alexey Natekin, Pendiri, Open Data Science x Data Souls
Alexey Hakhunov, CTO, Dbrain
Evgeny Kolesnikov, Direktur, Pusat Pembelajaran Mesin, Jet Infosystems
Pavel Doronin, CEO, AI Hari Ini
Diskusi akan tersedia di
saluran YouTube Jet Infosystems pada akhir Oktober.