Cerpen ini akan dikhususkan untuk bagaimana tidak jatuh ke dalam perangkap kontrol imajiner atas proses memperkirakan tugas untuk sprint mendatang. Saya harus mengatakan segera bahwa data yang disajikan di bawah ini hanya bersifat indikatif dan komentar tentang tidak digunakannya angka Fibonacci untuk tujuan estimasi di sini akan berlebihan.
Tim kami terdiri dari analis, penguji, perancang, dan 2 pengembang, namun, untuk kejelasan yang lebih besar, kami hanya menyisakan pengembang.
Kami memulai lari baru dan dengan lancar melanjutkan ke penilaian cerita Pengguna. Tidak ada yang baru. Silakan ...

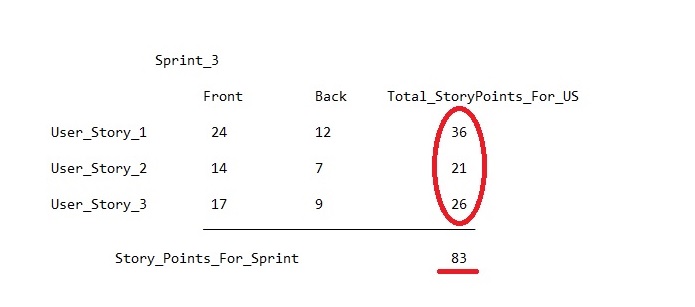
Perencanaan selesai dan hasilnya dapat dilihat di atas. Mereka mengambil 3 kisah Pengguna dengan nilai masing-masing 16, 20 dan 37 poin. Total - 73.
Lebih lanjut, seperti tim pengembangan yang menghargai diri sendiri yang menyukai semua kesenangan bekerja di Scrum, kami menambahkan peringkat ini ke Jira. Pada saat yang sama, kami hanya memperkenalkan Perkiraan umum (atau rata-rata - bahkan lebih buruk!) Untuk setiap cerita.
Bekerja selama dua minggu tanpa melepaskan tangan dari keyboard dan tanpa bangkit dari kursi kantor yang telah sangat dicintai selama bertahun-tahun, Anda dapat merenungkan fungsionalitas yang baru dibuat.
Tapi ada apa? Sprint telah berakhir dan kita melihat bahwa bagian depan melakukan segalanya sesuai rencana dan tidak akan punya waktu untuk melakukan satu keystroke, dan bagian belakang melampaui sprint dan melakukan lebih banyak tugas daripada yang direncanakan.
Dan kemudian Scrum dan XP dari PM Parit, yang baru saja selesai membaca, muncul dan berkata: “Semuanya jelas !!! Kita harus mengambil lebih banyak poin bangunan ke sprint berikutnya dan kemudian semuanya akan baik-baik saja dan tidak ada dukungan yang akan lari dari saya lagi, dengan mengambil mereka menyendok !! "
Kami sedang merencanakan sprint baru ....
Hebat! Mengambil 10 titik penyimpanan lebih banyak !!! Sekarang kami telah menghitung semuanya dengan pasti !!
Lain 2 minggu terbang dengan cepat dan saatnya untuk mengambil stok.
Tetapi untuk semua orang menyesal, sprint berakhir dengan cara yang sama sekali berbeda dari yang kita inginkan.
Untuk beberapa alasan, bagian belakang kembali bergerak maju, dan bagian depan tidak punya waktu untuk melakukan apa yang mereka rencanakan (kemungkinan bahwa bagian depan hanya bulan Juni yang tidak berpengalaman, dan kami akan menurunkan bagian belakang yang tidak tersentuh dan membayangkan bahwa semuanya hanya dalam perencanaan yang salah).
Sprint lain gagal !!! Tapi mengapa, kami mengambil storypots sedikit lebih banyak dan itu, hanya untuk tujuan yang baik - untuk memberikan jumlah pekerjaan yang diperlukan untuk sisi server ??!?
Bagaimana ini bisa terjadi ?? Jawabannya adalah tentang sistem evaluasi itu sendiri. Kembali ke sprint kami.

Apa yang kita lihat Ternyata dengan mengambil lebih banyak titik penyimpanan pada sprint baru untuk memuat bagian belakang, kami baru saja memuat bagian depan.
Setelah memahami hal ini, pikiran pertama di kepala PM yang gila adalah untuk mencari tahu berapa banyak poin cerita yang diambil sendiri dan berapa banyak dukungan. Tetapi melihat nilai keseluruhan di Jira sama sekali tidak mungkin, karena yang dapat Anda temukan hanyalah nilai keseluruhan (baik atau rata-rata) untuk setiap cerita, dan ingat siapa yang memberi nilai apa tidak mungkin lagi.

Dan kemudian solusinya datang dengan sendirinya. Agar berhasil mengatur beban tim, perlu untuk tidak hanya menyimpan catatan umum dalam poin sejarah, tetapi juga catatan terpisah dalam konteks beban di bagian depan dan belakang. Ini akan memungkinkan Anda untuk mengetahui jumlah pekerjaan optimal untuk setiap area dan bergantung padanya untuk mengisi tumpukan sprint. Sejauh ini, pendekatan ini tidak dapat diimplementasikan di Jira tanpa catatan terpisah di MS Excel, tetapi ini tidak berarti bahwa itu tidak boleh digunakan.
Saya yakin bahwa pengembang Atlassian akan menemukan solusi untuk masalah ini, tetapi untuk saat ini, jangan ulangi kesalahan kami!
PS Kesimpulan ini hanya berlaku untuk pengembangan aplikasi client-server, di mana ada pemisahan yang jelas antara pekerjaan di bagian depan dan bagian belakang. Masalah seperti itu seharusnya tidak muncul dalam tim pengembang Full-Stack, yang segera mengevaluasi pekerjaan dalam dua arah.