
Toleransi kesalahan dan ketersediaan tinggi adalah topik besar, sehingga RabbitMQ dan Kafka akan mencurahkan artikel terpisah. Artikel ini tentang RabbitMQ, dan yang berikutnya adalah tentang Kafka, dibandingkan dengan RabbitMQ. Artikelnya panjang, jadi buat dirimu nyaman.
Pertimbangkan strategi untuk toleransi kesalahan, konsistensi, dan ketersediaan tinggi (HA), serta pengorbanan yang harus dilakukan masing-masing strategi. RabbitMQ dapat berjalan di sekelompok node - dan kemudian diklasifikasikan sebagai sistem terdistribusi. Ketika datang ke sistem terdistribusi, kita sering berbicara tentang konsistensi dan aksesibilitas.
Konsep-konsep ini menggambarkan bagaimana sistem berperilaku jika terjadi kegagalan. Kegagalan koneksi jaringan, kegagalan server, kegagalan hard disk, tidak tersedianya server sementara karena pengumpulan sampah, kehilangan paket atau perlambatan koneksi jaringan. Semua ini dapat menyebabkan kehilangan data atau konflik. Ternyata hampir tidak mungkin untuk meningkatkan sistem yang keduanya sepenuhnya konsisten (tanpa kehilangan data, tanpa perbedaan data), dan dapat diakses (akan menerima operasi baca dan tulis) untuk semua jenis kegagalan.
Kita akan melihat bahwa konsistensi dan aksesibilitas berada di ujung spektrum yang berbeda, dan Anda perlu memilih cara mana untuk mengoptimalkan. Berita baiknya adalah bahwa dengan RabbitMQ pilihan seperti itu dimungkinkan. Anda memiliki semacam leverage "Nerd" untuk menggeser keseimbangan menuju koherensi yang lebih besar atau aksesibilitas yang lebih besar.
Kami akan memberikan perhatian khusus pada konfigurasi apa yang menyebabkan hilangnya data karena catatan yang dikonfirmasi. Ada rantai tanggung jawab antara penerbit, broker, dan konsumen. Setelah pesan dikirimkan ke broker, tugasnya adalah untuk tidak kehilangan pesan. Ketika pialang mengkonfirmasi kepada penerbit penerimaan pesan, kami tidak berharap itu hilang. Tetapi kami akan melihat bahwa ini benar-benar dapat terjadi tergantung pada konfigurasi broker dan penerbit Anda.
Primitif stabilitas satu node
Antrian / Routing Berkelanjutan
Ada dua jenis antrian di RabbitMQ: tahan lama / tidak tahan lama. Semua antrian disimpan dalam basis data Mnesia. Antrian persisten dideklarasikan ulang ketika node mulai dan dengan demikian selamat dari restart, sistem crash, atau server crash (selama data disimpan). Ini berarti bahwa saat Anda mendeklarasikan perutean (pertukaran) dan antrian tangguh, infrastruktur antrian / perutean akan kembali ke mode online.
Antrian dan perutean yang mudah dihapus dihapus ketika host memulai kembali.
Posting persisten
Hanya karena antriannya panjang tidak berarti bahwa semua pesannya akan selamat dari simpul restart. Hanya pesan yang ditetapkan oleh penerbit sebagai persisten yang akan dipulihkan. Pesan yang terus-menerus memang membuat beban tambahan pada broker, tetapi jika kehilangan pesan tidak dapat diterima, maka tidak ada cara lain.
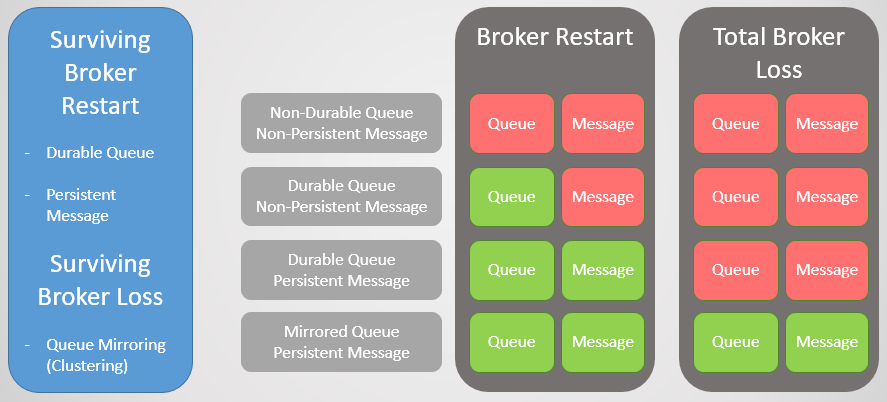 Fig. 1. Matriks stabilitas
Fig. 1. Matriks stabilitasAntrian Mirroring Clustering
Untuk bertahan dari kehilangan broker, kita perlu redundansi. Kita bisa menggabungkan beberapa node RabbitMQ menjadi sebuah cluster, dan kemudian menambahkan redundansi tambahan dengan mereplikasi antrian di antara beberapa node. Dengan demikian, jika satu node jatuh, kami tidak kehilangan data dan tetap tersedia.
Mirroring Antrian:
- satu antrian utama (master), yang menerima semua perintah tulis dan baca
- satu atau lebih mirror yang menerima semua pesan dan metadata dari antrian utama. Cermin ini tidak ada untuk penskalaan, tetapi hanya untuk redundansi.
 Fig. 2. Mencerminkan antrian
Fig. 2. Mencerminkan antrianMirroring diatur oleh kebijakan yang sesuai. Di dalamnya, Anda dapat memilih tingkat replikasi dan bahkan node di mana antrian harus ditempatkan. Contoh:
ha-mode: all
ha-mode: exactly, ha-params: 2 (satu master dan satu mirror)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Konfirmasi kepada penerbit
Untuk mencapai rekaman berurutan, Konfirmasi Penerbit harus dikonfirmasi. Tanpa mereka, ada kemungkinan kehilangan pesan. Konfirmasi dikirim ke penerbit setelah menulis pesan ke disk. RabbitMQ menulis pesan ke disk bukan pada saat diterima, tetapi secara berkala, di wilayah beberapa ratus milidetik. Ketika antrian dicerminkan, konfirmasi dikirim hanya setelah semua mirror juga menulis salinan pesan mereka ke disk. Ini berarti bahwa penggunaan ucapan terima kasih menambah keterlambatan, tetapi jika keamanan data penting, maka itu perlu.
Antrian Failover
Ketika broker dimatikan atau crash, semua antrian (master) terkemuka pada simpul ini jatuh bersamanya. Cluster kemudian memilih cermin tertua dari masing-masing master dan mempromosikannya sebagai master baru.
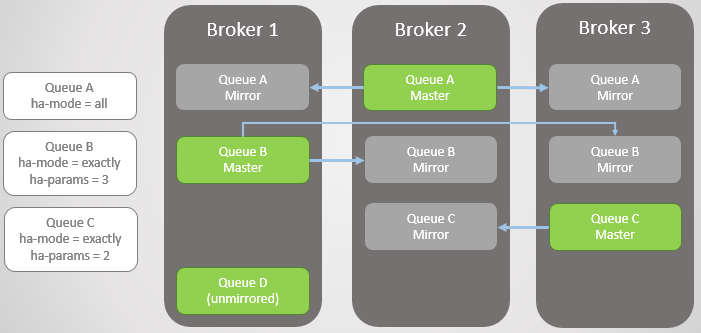 Fig. 3. Beberapa antrian cermin dan kebijakan mereka
Fig. 3. Beberapa antrian cermin dan kebijakan merekaBroker 3 tetes. Perhatikan bahwa mirror Antrian C pada Broker 2 ditingkatkan ke master. Perhatikan juga bahwa mirror baru telah dibuat untuk Antrian C pada Broker 1. RabbitMQ selalu berusaha untuk mempertahankan tingkat replikasi yang ditentukan dalam kebijakan Anda.
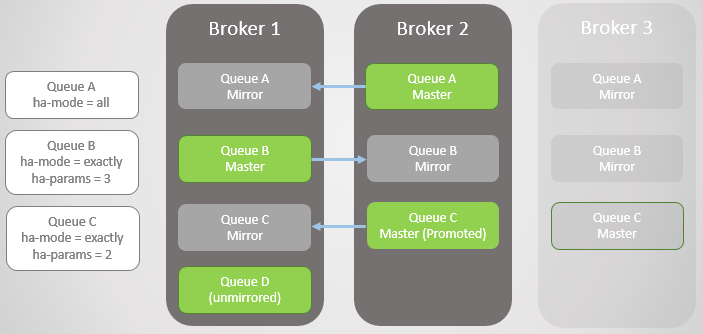 Fig. 4. Broker 3 jatuh, menyebabkan antrian C gagal
Fig. 4. Broker 3 jatuh, menyebabkan antrian C gagalBroker 1 berikutnya jatuh! Kami hanya memiliki satu broker yang tersisa. Cermin Antrian B naik ke master.
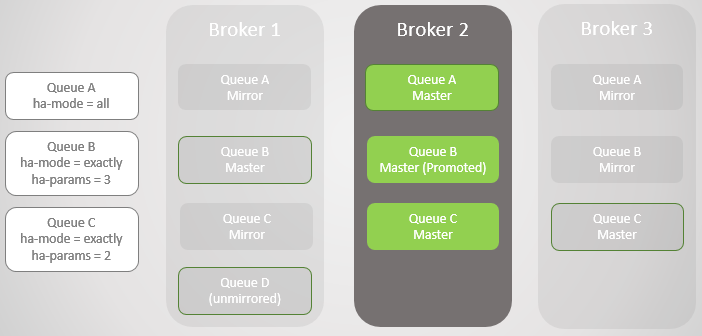 Fig. 5
Fig. 5Kami mengembalikan Broker 1. Tidak peduli seberapa berhasil data selamat dari kehilangan dan pemulihan broker, semua pesan antrian cermin dibuang setelah dimulai ulang. Ini penting untuk dicatat, karena akan ada konsekuensinya. Kami akan segera mempertimbangkan konsekuensi ini. Dengan demikian, Broker 1 sekarang menjadi anggota cluster, dan cluster berusaha untuk mematuhi kebijakan dan karenanya menciptakan mirror pada Broker 1.
Dalam hal ini, hilangnya Broker 1 selesai, serta data, sehingga Antrian D yang tidak mirroring benar-benar hilang.
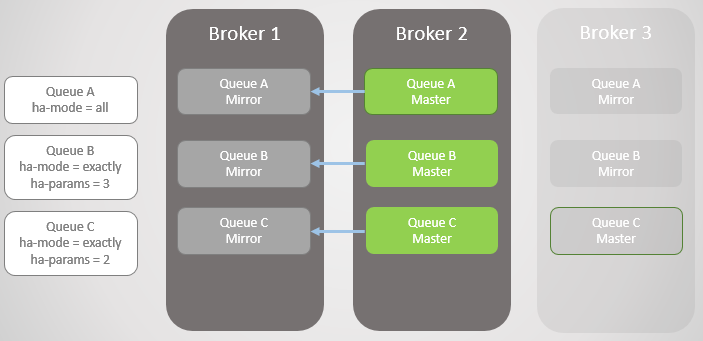 Fig. 6. Broker 1 kembali beroperasi
Fig. 6. Broker 1 kembali beroperasiBroker 3 kembali online, jadi jalur A dan B membuat mirror dibuat kembali sesuai dengan kebijakan HA mereka. Tapi sekarang semua jalur utama ada di satu simpul! Ini tidak ideal, distribusi seragam antara node lebih baik. Sayangnya, tidak ada opsi khusus untuk menyeimbangkan master. Kami akan kembali ke masalah ini nanti, karena kami harus mempertimbangkan sinkronisasi antrian terlebih dahulu.
 Fig. 7. Broker 3 kembali beroperasi. Semua antrian utama pada satu simpul!
Fig. 7. Broker 3 kembali beroperasi. Semua antrian utama pada satu simpul!Dengan demikian, Anda sekarang harus memiliki ide tentang bagaimana mirror memberikan redundansi dan toleransi kesalahan. Ini memastikan ketersediaan jika terjadi kegagalan simpul tunggal dan melindungi terhadap kehilangan data. Tapi kami belum selesai, karena pada kenyataannya semuanya jauh lebih rumit.
Sinkronkan
Saat membuat cermin baru, semua pesan baru akan selalu direplikasi ke cermin ini dan yang lainnya. Sedangkan untuk data yang ada dalam antrian utama, kita dapat mereplikasi dalam mirror baru, yang menjadi salinan master lengkap. Kami juga tidak dapat mereplikasi pesan yang ada dan memungkinkan antrian utama dan mirror baru untuk menyatu pada waktunya ketika pesan baru tiba di ekor dan pesan yang ada meninggalkan kepala antrian utama.
Sinkronisasi ini dilakukan secara otomatis atau manual dan dikendalikan menggunakan kebijakan antrian. Pertimbangkan sebuah contoh.
Kami memiliki dua garis cermin. Antrian A menyinkronkan secara otomatis, dan Antrian B secara manual. Kedua baris masing-masing memiliki sepuluh pesan.
 Fig. 8. Dua antrian dengan mode sinkronisasi yang berbeda
Fig. 8. Dua antrian dengan mode sinkronisasi yang berbedaSekarang kita kehilangan Broker 3.
 Fig. 9. Broker 3 jatuh
Fig. 9. Broker 3 jatuhBroker 3 kembali beroperasi. Cluster menciptakan cermin untuk setiap antrian pada node baru dan secara otomatis menyinkronkan Antrian A baru dengan master. Namun, cermin dari Turn B yang baru tetap kosong. Dengan demikian, kami memiliki redundansi lengkap untuk Antrian A dan hanya satu cermin untuk pesan Antrian B.
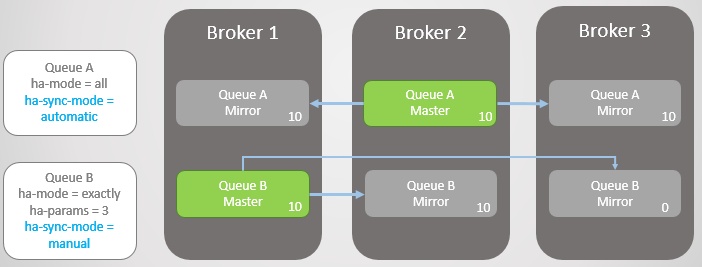 Fig. 10. Mirror baru dari Queue A menerima semua pesan yang ada, tetapi mirror baru dari Queue B tidak
Fig. 10. Mirror baru dari Queue A menerima semua pesan yang ada, tetapi mirror baru dari Queue B tidakKedua baris menerima sepuluh pesan lagi. Kemudian Broker 2 jatuh, dan Queue A kembali ke mirror tertua, yang terletak di Broker 1. Jika terjadi kegagalan, tidak ada kehilangan data. Ada dua puluh pesan dalam Antrian B di wisaya dan hanya sepuluh di cermin, karena antrian ini tidak pernah mereplikasi sepuluh pesan asli.
 Fig. 11. Jalur A digulung kembali ke Broker 1 tanpa kehilangan pesan
Fig. 11. Jalur A digulung kembali ke Broker 1 tanpa kehilangan pesanKedua baris menerima sepuluh pesan lagi. Broker 1 sekarang macet. Antrian A beralih ke cermin tanpa masalah tanpa kehilangan pesan. Namun, Antrian B memiliki masalah. Pada titik ini, kita dapat mengoptimalkan aksesibilitas atau konsistensi.
Jika kita ingin mengoptimalkan aksesibilitas, maka kebijakan
ha-promot-on-failure harus ditetapkan
selalu . Ini adalah nilai default, jadi Anda bisa menghilangkan kebijakan sama sekali. Dalam hal ini, pada kenyataannya, kami mengizinkan kegagalan pada mirror yang tidak disinkronkan. Ini akan menyebabkan hilangnya pesan, tetapi antrian tetap dapat dibaca dan ditulis.
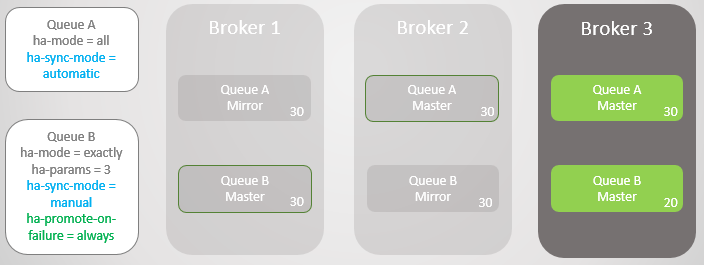 Fig. 12. Jalur A digulung kembali ke Broker 3 tanpa kehilangan pesan. Jalur B kembali ke Broker 3 dengan hilangnya sepuluh pesan
Fig. 12. Jalur A digulung kembali ke Broker 3 tanpa kehilangan pesan. Jalur B kembali ke Broker 3 dengan hilangnya sepuluh pesanKami juga dapat mengatur
ha-promote-on-failure menjadi
when-synced . Dalam hal ini, alih-alih memutar kembali ke cermin, antrian akan menunggu sampai Broker 1 dengan datanya kembali ke mode online. Setelah kembali, antrian utama kembali muncul di Broker 1 tanpa kehilangan data. Aksesibilitas dikorbankan untuk keamanan data. Tapi ini adalah mode berisiko, yang bahkan dapat menyebabkan hilangnya data, yang akan kami pertimbangkan dalam waktu dekat.
 Fig. 13. Jalur B tetap tidak tersedia setelah kehilangan Pialang 1
Fig. 13. Jalur B tetap tidak tersedia setelah kehilangan Pialang 1Anda dapat mengajukan pertanyaan: "Mungkin lebih baik tidak pernah menggunakan sinkronisasi otomatis?". Jawabannya adalah sinkronisasi adalah operasi pemblokiran. Selama sinkronisasi, antrian utama tidak dapat melakukan operasi baca atau tulis!
Pertimbangkan sebuah contoh. Sekarang kami memiliki garis yang sangat panjang. Bagaimana mereka bisa tumbuh dengan ukuran ini? Karena beberapa alasan:
- Antrian tidak digunakan secara aktif.
- Ini adalah jalur kecepatan tinggi, dan saat ini konsumen lambat
- Ini adalah antrian berkecepatan tinggi, kegagalan telah terjadi dan konsumen mengejar ketinggalan
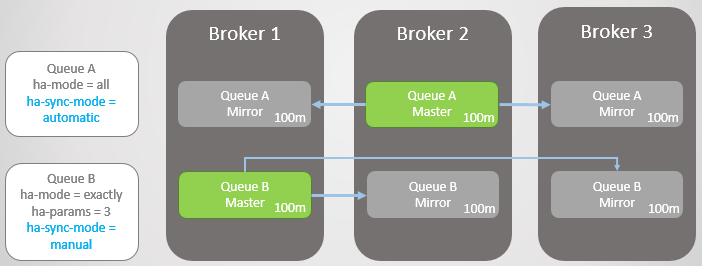 Fig. 14. Dua antrian besar dengan mode sinkronisasi yang berbeda
Fig. 14. Dua antrian besar dengan mode sinkronisasi yang berbedaSekarang Broker 3 mogok.
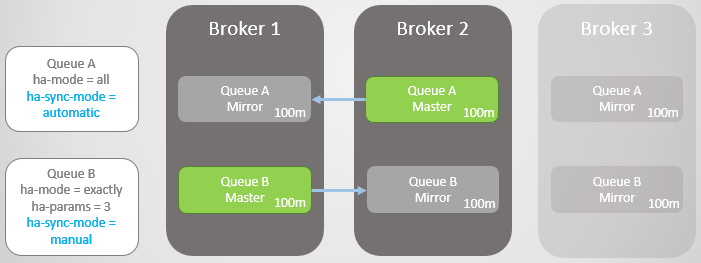 Fig. 15. Broker 3 jatuh, meninggalkan satu master dan cermin di setiap antrian
Fig. 15. Broker 3 jatuh, meninggalkan satu master dan cermin di setiap antrianBroker 3 kembali, dan mirror baru dibuat. Antrian Utama A mulai mereplikasi pesan yang ada ke mirror baru, dan selama ini, Antrian A tidak tersedia. Replikasi data membutuhkan dua jam, menghasilkan dua jam downtime untuk Antrian ini!
Namun, Jalur B tetap tersedia sepanjang seluruh periode. Dia mengorbankan beberapa redundansi demi aksesibilitas.
 Fig. 16. Antrian tetap tidak tersedia selama sinkronisasi
Fig. 16. Antrian tetap tidak tersedia selama sinkronisasiSetelah dua jam, Antrian A juga tersedia dan dapat kembali menerima operasi baca dan tulis.
Pembaruan
Perilaku pemblokiran ini selama sinkronisasi membuatnya sulit untuk meningkatkan cluster dengan antrian yang sangat besar. Pada titik tertentu, node dengan wizard perlu direstart, yang berarti beralih ke mirror atau mematikan antrian selama pembaruan server. Jika kami memilih transisi, kami akan kehilangan pesan jika mirror tidak disinkronkan. Secara default, selama pemutusan broker, transisi ke mirror yang tidak disinkronkan tidak dilakukan. Ini berarti bahwa segera setelah broker kembali, kami tidak kehilangan pesan apa pun, satu-satunya kerusakan hanyalah antrian sederhana. Calon
ha-promote-on-shutdown diatur oleh kebijakan
ha-promote-on-shutdown . Anda dapat menetapkan salah satu dari dua nilai:
always = diaktifkan untuk beralih ke mirror yang tidak disinkronkan
when-synced = beralih hanya ke cermin yang disinkronkan, jika tidak, antrian menjadi tidak dapat diakses untuk membaca dan menulis. Antrian kembali segera setelah broker kembali
Dengan satu atau lain cara, dengan antrian yang besar, Anda harus memilih antara kehilangan data dan tidak dapat diaksesnya.
Ketika Ketersediaan Meningkatkan Keamanan Data
Sebelum membuat keputusan, satu komplikasi lagi harus diperhitungkan. Meskipun sinkronisasi otomatis lebih baik untuk redundansi, bagaimana pengaruhnya terhadap keamanan data? Tentu saja, berkat redundansi yang lebih baik, RabbitMQ cenderung kehilangan pesan yang ada, tetapi bagaimana dengan pesan baru dari penerbit?
Di sini Anda perlu mempertimbangkan yang berikut:
- Bisakah penerbit hanya mengembalikan kesalahan, dan layanan yang lebih tinggi atau pengguna akan mencoba lagi nanti?
- Bisakah penerbit menyimpan pesan secara lokal atau dalam database untuk mencoba lagi nanti?
Jika penerbit hanya dapat menjatuhkan pesan, maka, pada kenyataannya, meningkatkan aksesibilitas juga meningkatkan keamanan data.
Dengan demikian, Anda perlu mencari keseimbangan, dan keputusan tergantung pada situasi tertentu.
Masalah dengan ha-promot-on-failure = saat-disinkronkan
Gagasan
ha-promot-on-failure =
saat-disinkronkan adalah bahwa kami mencegah beralih ke cermin yang tidak disinkronkan dan dengan demikian menghindari kehilangan data. Antrian tetap tidak dapat diakses untuk membaca atau menulis. Alih-alih, kami mencoba mengembalikan broker yang jatuh dengan data yang tidak rusak sehingga kembali berfungsi sebagai master tanpa kehilangan data.
Tapi (dan ini besar tapi) jika broker kehilangan datanya, maka kita memiliki masalah besar: antriannya hilang! Semua data hilang! Bahkan jika Anda memiliki cermin yang pada dasarnya mengejar ketinggalan dengan antrian utama, cermin ini juga dibuang.
Untuk menambahkan kembali sebuah node dengan nama yang sama, kami memberitahu cluster untuk melupakan node yang hilang (dengan perintah
rabbitmqctl forget_cluster_node ) dan memulai broker baru dengan nama host yang sama. Selama cluster mengingat simpul yang hilang, ia mengingat antrian lama dan cermin yang tidak disinkronkan. Ketika sebuah cluster diberitahu untuk melupakan simpul yang hilang, antrian ini juga dilupakan. Sekarang Anda perlu mendeklarasikannya kembali. Kami kehilangan semua data, meskipun kami memiliki cermin dengan kumpulan data parsial. Akan lebih baik untuk beralih ke cermin yang tidak disinkronkan!
Oleh karena itu, sinkronisasi manual (dan kegagalan sinkronisasi) dalam kombinasi dengan
ha-promote-on-failure=when-synced , menurut saya, cukup berisiko. Dokumen mengatakan opsi ini ada untuk keamanan data, tapi itu pisau bermata dua.
Master Penyeimbang
Seperti yang dijanjikan, kita kembali ke masalah akumulasi semua master pada satu atau lebih node. Ini dapat terjadi bahkan sebagai akibat dari bergulirnya pembaruan kluster bergulir. Dalam sebuah cluster dengan tiga node, semua antrian utama akan terakumulasi pada satu atau dua node.
Master Rebalancing dapat bermasalah karena dua alasan:
- Tidak ada alat penyeimbang yang baik
- Sinkronisasi Antrian
Untuk penyeimbangan kembali, ada
plugin pihak ketiga yang tidak didukung secara resmi. Mengenai plug-in pihak ketiga, manual RabbitMQ
mengatakan : “Plug-in menyediakan beberapa konfigurasi tambahan dan alat pelaporan, tetapi tidak didukung dan tidak diuji oleh tim RabbitMQ. Gunakan dengan risiko Anda sendiri. "
Ada trik lain untuk memindahkan antrian utama melalui kebijakan HA. Manual menyebutkan
naskah untuk ini. Ia bekerja sebagai berikut:
- Menghapus semua mirror menggunakan kebijakan sementara dengan prioritas lebih tinggi dari kebijakan HA yang ada.
- Mengubah kebijakan sementara HA untuk menggunakan mode node dengan node yang harus dipindahkan dari antrian utama.
- Menyinkronkan antrian untuk migrasi paksa.
- Setelah migrasi selesai, hapus kebijakan sementara. Kebijakan awal HA mulai berlaku dan jumlah cermin yang diperlukan dibuat.
Kerugiannya adalah bahwa pendekatan ini mungkin tidak berfungsi jika Anda memiliki antrian yang besar atau persyaratan redundansi yang ketat.
Sekarang mari kita lihat bagaimana cluster RabbitMQ bekerja dengan partisi jaringan.
Gangguan konektivitas
Node dari sistem terdistribusi dihubungkan oleh tautan jaringan, dan tautan jaringan dapat dan akan terputus. Frekuensi pemadaman tergantung pada infrastruktur lokal atau keandalan cloud yang dipilih. Bagaimanapun, sistem terdistribusi harus dapat menanganinya. Sekali lagi kami memiliki pilihan antara aksesibilitas dan konsistensi, dan sekali lagi berita baiknya adalah bahwa RabbitMQ menyediakan keduanya (hanya saja tidak pada saat yang bersamaan).
Dengan RabbitMQ, kami memiliki dua opsi utama:
- Biarkan pemisahan logis (otak-terpisah). Ini memberikan aksesibilitas, tetapi dapat menyebabkan kehilangan data.
- Larang pemisahan logis. Dapat mengakibatkan hilangnya ketersediaan jangka pendek tergantung pada bagaimana klien terhubung ke cluster. Hal ini juga dapat menyebabkan tidak dapat diaksesnya secara penuh dalam sekelompok dua node.
Tetapi apakah pemisahan logis itu? Ini adalah ketika sebuah cluster terbelah dua karena kehilangan koneksi jaringan. Di setiap sisi, cermin naik ke master, jadi pada akhirnya, ada beberapa master di setiap belokan.
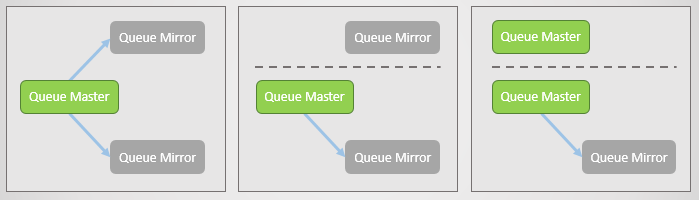 Fig. 17. Garis utama dan dua mirror, masing-masing pada node yang terpisah. Kemudian terjadi kegagalan jaringan dan satu cermin terpisah. Node terpisah melihat bahwa dua lainnya jatuh, dan memajukan mirror-nya ke master. Sekarang kami memiliki dua baris utama, dan keduanya memungkinkan menulis dan membaca.
Fig. 17. Garis utama dan dua mirror, masing-masing pada node yang terpisah. Kemudian terjadi kegagalan jaringan dan satu cermin terpisah. Node terpisah melihat bahwa dua lainnya jatuh, dan memajukan mirror-nya ke master. Sekarang kami memiliki dua baris utama, dan keduanya memungkinkan menulis dan membaca.Jika penerbit mengirim data ke kedua master, kami mendapatkan dua salinan antrian yang berbeda.
Berbagai mode RabbitMQ menyediakan aksesibilitas atau konsistensi.
Mode abaikan (default)
Mode ini menyediakan aksesibilitas. Setelah kehilangan konektivitas, pemisahan logis terjadi. Setelah menyambung kembali, administrator harus memutuskan partisi mana yang lebih disukai. Sisi yang hilang akan direstart, dan semua data yang terakumulasi dari sisi ini akan hilang.
 Fig. 18. Tiga penerbit dikaitkan dengan tiga broker. Secara internal, kluster meneruskan semua permintaan ke antrian utama di Broker 2.
Fig. 18. Tiga penerbit dikaitkan dengan tiga broker. Secara internal, kluster meneruskan semua permintaan ke antrian utama di Broker 2.Sekarang kita kehilangan Broker 3. Dia melihat bahwa broker lain telah jatuh, dan memindahkan cerminnya ke master. Ini adalah pemisahan yang logis.
 Fig. 19. Pemisahan logis (split-otak). Catatan masuk dalam dua baris utama, dan dua salinan berbeda.
Fig. 19. Pemisahan logis (split-otak). Catatan masuk dalam dua baris utama, dan dua salinan berbeda.Konektivitas dipulihkan, tetapi pemisahan logis tetap ada. Administrator harus secara manual memilih sisi yang kalah. Dalam kasus berikut, administrator me-reboot Broker 3. Semua pesan yang tidak berhasil ia kirimkan hilang.
 Fig. 20. Administrator menonaktifkan Broker 3.
Fig. 20. Administrator menonaktifkan Broker 3. Fig. 21. Administrator memulai Broker 3, dan ia bergabung dengan cluster, kehilangan semua pesan yang tersisa di sana.
Fig. 21. Administrator memulai Broker 3, dan ia bergabung dengan cluster, kehilangan semua pesan yang tersisa di sana.Selama kehilangan konektivitas dan setelah pemulihannya, cluster dan antrian ini tersedia untuk membaca dan menulis.
Mode Autoheal
Ini bekerja mirip dengan mode Abaikan, kecuali bahwa cluster itu sendiri secara otomatis memilih sisi yang hilang setelah pemisahan dan memulihkan konektivitas. Sisi yang hilang kembali ke cluster kosong, dan antrian kehilangan semua pesan yang dikirim hanya ke sisi itu.
Jeda Mode Minoritas
Jika kita tidak ingin mengizinkan pemisahan logis, maka satu-satunya pilihan kita adalah menolak untuk membaca dan menulis di sisi yang lebih kecil setelah partisi gugus. Ketika seorang broker melihat bahwa dia berada di pihak yang lebih rendah, dia berhenti sebentar, yaitu, menutup semua koneksi yang ada dan menolak yang baru. Sekali per detik, ia memeriksa koneksi ulang. Setelah konektivitas dipulihkan, ia kembali berfungsi dan bergabung dengan cluster.
 Fig. 22. Tiga penerbit dikaitkan dengan tiga broker. Secara internal, kluster meneruskan semua permintaan ke antrian utama di Broker 2.
Fig. 22. Tiga penerbit dikaitkan dengan tiga broker. Secara internal, kluster meneruskan semua permintaan ke antrian utama di Broker 2.Kemudian Pialang 1 dan 2 dipisahkan dari Pialang 3. Alih-alih memutakhirkan cermin mereka ke master, Pialang 3 berhenti dan menjadi tidak dapat diakses.
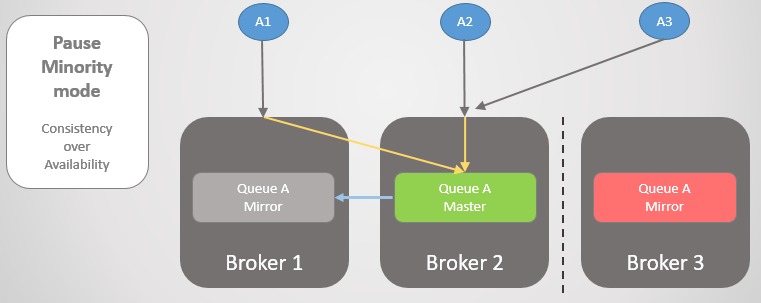 Fig. 23. Pialang 3 menjeda, memutus semua klien, dan menolak permintaan koneksi.
Fig. 23. Pialang 3 menjeda, memutus semua klien, dan menolak permintaan koneksi.Setelah konektivitas dipulihkan, ia kembali ke cluster.
Mari kita lihat contoh lain, di mana jalur utama ada di Broker 3.
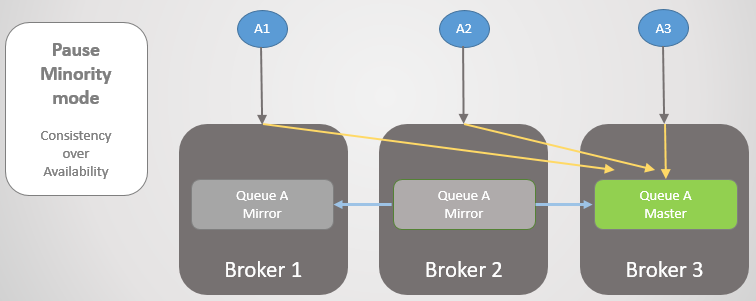 Fig. 24. Jalur utama di Broker 3.
Fig. 24. Jalur utama di Broker 3.Kemudian hilangnya konektivitas yang sama terjadi. Broker 3 berhenti karena berada di sisi yang lebih kecil. Di sisi lain, node melihat bahwa Broker 3 telah jatuh, sehingga cermin yang lebih tua dari Broker 1 dan 2 naik ke master.
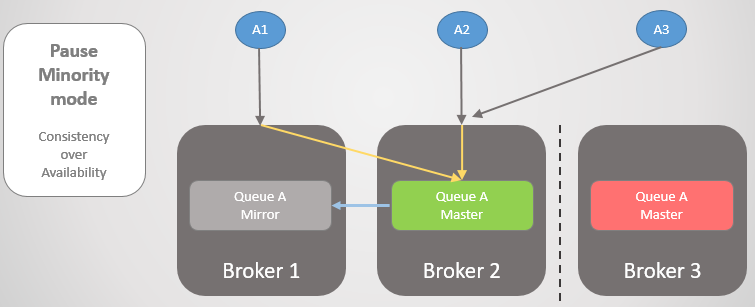 Fig. 25. Transisi ke Broker 2 jika Broker 3 tidak tersedia.
Fig. 25. Transisi ke Broker 2 jika Broker 3 tidak tersedia.Ketika konektivitas dipulihkan, Broker 3 akan bergabung dengan kluster.
 Fig. 26. Cluster kembali ke operasi normal.
Fig. 26. Cluster kembali ke operasi normal.Penting untuk dipahami bahwa kami mendapatkan konsistensi, tetapi kami juga dapat memperoleh aksesibilitas
jika kami berhasil mentransfer klien ke sebagian besar bagian. Untuk sebagian besar situasi, saya pribadi akan memilih mode Jeda Minoritas, tetapi itu benar-benar tergantung pada kasus tertentu.
Untuk memastikan ketersediaan, penting untuk memastikan bahwa klien berhasil terhubung ke situs. Pertimbangkan opsi kami.
Konektivitas Pelanggan
Kami memiliki beberapa opsi untuk bagaimana, setelah kehilangan konektivitas, mengirim klien ke bagian utama cluster atau ke node yang berfungsi (setelah kegagalan satu node). Pertama, mari kita ingat bahwa antrian tertentu di-host pada host tertentu, tetapi perutean dan kebijakan direplikasi pada semua host. Klien dapat terhubung ke simpul apa pun, dan perutean internal akan mengarahkan mereka jika perlu. Tetapi ketika sebuah node ditangguhkan, ia menolak koneksi, sehingga klien harus terhubung ke node lain. Jika sebuah simpul jatuh, ia dapat melakukan sedikit sekali.
Pilihan kami:
- Cluster diakses menggunakan penyeimbang beban, yang hanya siklus melalui node dan klien melakukan upaya berulang untuk menghubungkan sampai mereka berhasil diselesaikan. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
Kesimpulan
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446