Terakhir kali kami mendapat generator pengurai PEG sederhana. Sekarang saya akan menunjukkan apa sebenarnya parser yang dihasilkan ketika mem-parsing program. Saya terjun ke dunia retro seni ASCII, khususnya, perpustakaan yang disebut "kutukan", yang tersedia dalam distribusi Python standar untuk Linux dan Mac, serta tambahan untuk Windows.
Konten Seri Parser Python PEG 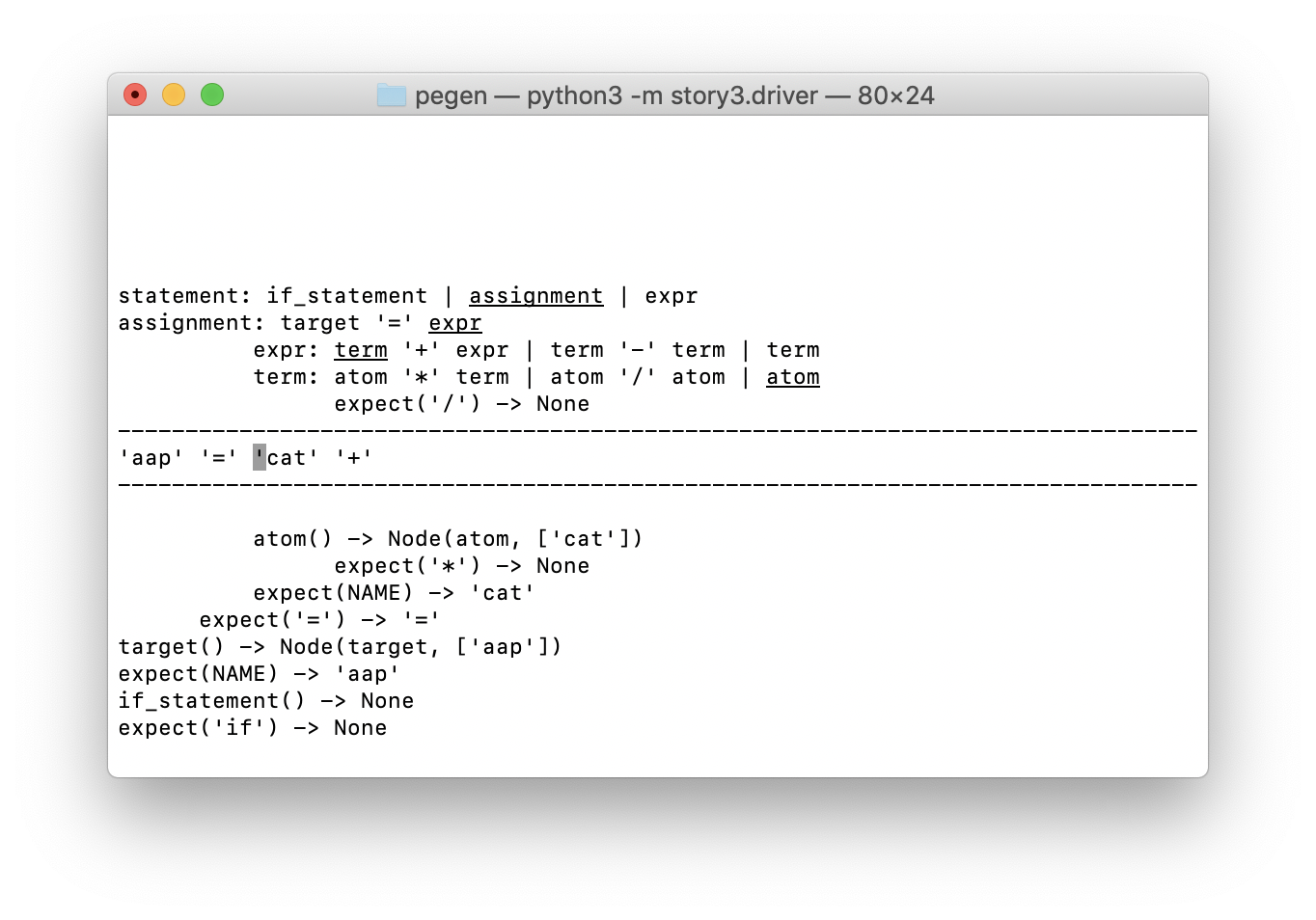
<Di akhir artikel, gif diberikan di bawah spoiler. Bagiku itu lebih dimengerti daripada gambaran statis>
Mari kita lihat visualisasi. Layar dibagi menjadi tiga bagian, seperti biasa di ASCII, dengan garis tanda hubung:
- Bagian atas menunjukkan tumpukan panggilan parser, yang, seperti yang Anda ingat, adalah penganalisa keturunan rekursif dengan pengembalian tanpa batas. Di bawah ini saya akan jelaskan lebih detail.
- Bagian single-line di tengah menunjukkan isi buffer token dengan kursor menunjuk ke token yang akan dianalisis selanjutnya.
- Di bawah ini kami memvisualisasikan cache yang digunakan oleh algoritma packrat parser. Merekam elemen-elemennya agak mirip dengan beberapa elemen stack parser (dengan hasil).
Hal utama yang perlu Anda ketahui untuk memahami visualisasi ini adalah bahwa lekukan garis di bagian atas dan bawah sesuai dengan token buffer.
- Dua baris pertama (dimulai dengan
statement dan assignment ) menunjukkan panggilan ke metode parser terkait yang sedang melakukan analisis sekarang. Mereka dipanggil ketika pointer tokenizer sebelum token pertama ( 'aap' ). - Dua baris berikutnya (dimulai dengan
expr dan term ) diselaraskan dengan awal token 'cat' , di mana metode parser yang sesuai dipanggil. - Baris kelima dan terakhir rendering tumpukan menunjukkan panggilan yang
expect('/') , yang mengembalikan None . Dia mengajukan diri pada posisi token '+' .
Lekukan item dalam cache juga sesuai dengan posisi di buffer token. Misalnya, di bagian bawah ada entri negatif di cache, mereka diperoleh ketika mencari token 'if' dan aturan if_statement di awal buffer token. Kami juga menemukan entri cache yang berhasil untuk token '=' dan untuk NAME (khususnya, 'cat' ) yang sesuai dengan posisi input lebih lanjut.
Baik di blok tumpukan analyzer dan di blok cache, panggilan yang dikembalikan ditampilkan sebagai function(args) -> result . Kadang-kadang, beberapa metode yang dikembalikan ditampilkan pada tumpukan parser - saya melakukan ini untuk mengurangi jitter teks dari perubahan konten yang sering.
(Berbicara tentang jitter, baris teratas tumpukan analyzer bergerak ke atas ketika panggilan ditambahkan ke tumpukan dan drop ketika dihapus dari tumpukan. Artinya, setiap panggilan baru dimasukkan di bagian paling bawah dari blok visualisasi tumpukan, menggeser garis yang ada ke atas. Tampaknya bagi saya bahwa menonton bagian layar ini bukan masalah, yah, setidaknya bagi saya. Mungkin, bagian penting dari otak kita dikhususkan untuk melacak objek bergerak. :-)
Cache diterjemahkan sebagai LRU, dengan item yang sering digunakan di bagian atas; yang lebih jarang muncul di layar. (Prototipe paket parser yang saya perlihatkan di artikel sebelumnya tidak menggunakan LRU, tetapi mungkin ide yang bagus untuk mengoptimalkan konsumsi memori.)
Mari kita lihat beberapa detail saat merender tumpukan parsing. Empat entri teratas sesuai dengan metode parser yang masih diproses, setiap baris adalah garis dari tata bahasa. Item yang disorot adalah item yang menghasilkan tantangan berikutnya.
Yaitu dilihat dari tangkapan layar, kita berada pada alternatif kedua untuk statement , yaitu assignment . Dalam aturan ini, kita berada pada poin ketiga, yaitu expr . Dalam aturan expr , kita hanya berada di paragraf pertama dari alternatif pertama ( term '+' expr ); dan dalam aturan untuk term kita berada dalam alternatif terakhir ( atom ).
Di bawah ini kita melihat hasil yang mengarah pada kegagalan alternatif kedua ( atom '/' term ): expect('/') -> None indentasi dengan token '+' . Pada langkah selanjutnya, kita akan melihat bagaimana ia masuk ke dalam cache.
Tapi tentunya Anda lebih suka melihat keseluruhan animasi sendiri!
Saya mencatat analisis lengkap dari program contoh kanonik Anda juga dapat bermain dengan kode yang sudah jadi , tetapi perlu diingat bahwa ini bukan olahraga.
Saat Anda melihat GIF yang direkam , mungkin tampak sedikit aneh bahwa kadang-kadang token berikutnya tidak ditampilkan (misalnya, di awal tumpukan tumbuh oleh beberapa catatan sebelum token 'aap' terdeteksi). Ini persis seperti yang dilihat oleh penganalisa: buffer token diisi dengan malas. Token tidak dipindai sampai parser memintanya dengan memanggil fungsi expect() . Segera setelah token memasuki buffer, token tetap ada, bahkan jika penganalisis memutar kembali urutan token kembali. Pelacakan terbalik ditampilkan di buffer token dengan kursor yang melompat ke kiri; ada banyak situasi seperti itu yang tercatat. Anda juga dapat mengamati pengisian cache ketika penganalisa tidak membuat panggilan rekursif tambahan. (Saya harus menyorot ketika ini terjadi, tetapi saya tidak punya cukup waktu.)
Minggu depan saya akan mengembangkan parser, mungkin menambahkan perspektif saya pada aturan kiri tata bahasa rekursif. (Mereka hebat!)
Ucapan ttygif : sebagai catatan saya menggunakan ttygif dari Ilya Choli dan ttyrec dari Matthew Jording.
Lisensi untuk artikel ini dan kode yang dikutip: CC BY-NC-SA 4.0