
Selamat siang, saya ingin berbagi dengan Anda pengalaman saya dalam menyiapkan dan menggunakan layanan AWS EKS (Elastic Kubernetes Service) untuk wadah Windows, atau lebih tepatnya tentang ketidakmungkinan menggunakannya, dan bug yang ditemukan dalam wadah sistem AWS, bagi mereka yang tertarik dengan layanan ini untuk wadah Windows, silakan di bawah kucing.
Saya tahu bahwa wadah windows bukan topik populer, dan hanya sedikit orang yang menggunakannya, tetapi tetap memutuskan untuk menulis artikel ini, karena ada beberapa artikel tentang kubernet dan windows tentang Habré dan masih ada orang-orang seperti itu.
Mulai
Semuanya dimulai dengan fakta bahwa layanan di perusahaan kami, diputuskan untuk bermigrasi ke kubernetes, itu adalah 70% windows dan 30% linux. Untuk ini, layanan cloud AWS EKS dianggap sebagai salah satu opsi yang memungkinkan. Sampai 8 Oktober 2019 AWS EKS Windows berada dalam Pratinjau Publik, saya mulai dengan itu, versi kubernet menggunakan 1,11 yang lama, tetapi saya memutuskan untuk memeriksanya dan melihat pada tahap apa layanan cloud ini bekerja, jika ternyata berfungsi sama sekali, itu ternyata tidak berfungsi sama sekali. bug dengan tambahan menghapus perapian, sementara yang lama berhenti merespons melalui ip internal dari subnet yang sama dengan node pekerja windows.
Oleh karena itu, diputuskan untuk meninggalkan penggunaan AWS EKS demi cluster mereka sendiri pada kubernet pada EC2 yang sama, hanya semua penyeimbang dan HA harus dijelaskan sendiri melalui CloudFormation.
Amazon EKS Windows Container Support sekarang Tersedia Secara Umum
oleh Martin Beeby | pada 08 OCT 2019Saya tidak punya waktu untuk menambahkan templat ke CloudFormation untuk kluster saya sendiri, karena saya melihat berita ini
Amazon EKS Windows Container Support sekarang Tersedia secara UmumTentu saja, saya menunda semua perkembangan saya, dan mulai mempelajari apa yang mereka lakukan untuk GA, dan bagaimana semuanya berubah dari Pratinjau Publik. Ya orang aws memperbarui gambar untuk node pekerja windows ke versi 1.14 serta versi cluster 1.14 di EKS sekarang dengan dukungan untuk windows node. Mereka menutup proyek Pratinjau Publik di
github dan berkata sekarang menggunakan dokumentasi resmi di sini:
Dukungan EKS WindowsMengintegrasikan Cluster EKS ke dalam VPC dan Subnet Saat Ini
Di semua sumber, di tautan di atas pengumuman dan juga dalam dokumentasi, diusulkan untuk menyebarkan cluster baik melalui utilitas utilitas eksklusif atau melalui CloudFormation + kubectl setelah, hanya menggunakan subnet publik di Amazon, serta membuat VPC terpisah untuk cluster baru.
Opsi ini tidak cocok untuk banyak orang, pertama, VPC terpisah adalah biaya tambahan dari biaya + mengintip lalu lintas ke VPC Anda saat ini. Apa yang harus dilakukan bagi mereka yang sudah memiliki infrastruktur siap pakai di AWS dengan beberapa akun AWS, VPC, subnet, tabel rute, gateway transit, dan sebagainya? Tentu saja, saya tidak ingin memecah atau mengulang semuanya, dan saya perlu mengintegrasikan cluster EKS baru ke dalam infrastruktur jaringan saat ini menggunakan VPC yang ada dan, untuk membagi maksimum, buat subnet baru untuk cluster.
Dalam kasus saya, jalur ini dipilih, saya menggunakan VPC yang ada, menambahkan hanya 2 subnet publik dan 2 subnet pribadi untuk sebuah cluster baru, tentu saja, semua aturan diperhitungkan sesuai dengan dokumentasi
Buat dokumentasi
Amazon EKS Cluster VPC Anda .
Ada juga satu syarat untuk tidak ada simpul pekerja di subnet publik menggunakan EIP.eksctl vs CloudFormation
Saya akan membuat reservasi segera bahwa saya mencoba kedua metode penyebaran cluster, dalam kedua kasus gambarnya sama.
Saya akan menunjukkan contoh hanya dengan penggunaan eksctl karena kode lebih pendek di sini. Menggunakan penyebaran kluster eksctl dalam 3 langkah:
1. Buat cluster itu sendiri + simpul pekerja Linux di mana wadah sistem dan vpc-controller yang malang nantinya akan ditempatkan.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
Untuk menyebar ke VPC yang ada, cukup tentukan id dari subnet Anda, dan eksctl akan menentukan VPC itu sendiri.
Agar node pekerja Anda hanya menggunakan subnet pribadi, Anda perlu menentukan --node-private-networking untuk nodegroup.
2. Instal vpc-controller di cluster kami, yang kemudian akan memproses node pekerja kami dengan menghitung jumlah alamat ip gratis, serta jumlah ENI pada instance, menambah dan menghapusnya.
eksctl utils install-vpc-controllers --name yyy --approve
3.Setelah wadah sistem Anda telah berhasil dimulai pada node pekerja linux Anda termasuk vpc-controller, itu tetap hanya untuk membuat nodegroup lain dengan windows pekerja.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
Setelah simpul Anda berhasil terhubung ke cluster Anda dan semuanya tampak baik-baik saja, itu dalam status Ready, tetapi tidak.
Kesalahan dalam vpc-controller
Jika kami mencoba menjalankan pod pada node Windows Pekerja, kami mendapatkan kesalahan:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
Melihat lebih dalam, kita melihat bahwa contoh AWS kami terlihat seperti ini:

Dan seharusnya seperti ini:

Dari sini jelas bahwa vpc-controller tidak mengerjakan bagiannya untuk beberapa alasan dan tidak dapat menambahkan alamat ip baru ke instance sehingga pod dapat menggunakannya.
Kami memanjat untuk melihat log pod vpc-controller dan ini yang kami lihat:
kubectl log <vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Pencarian Google tidak mengarah ke apa pun, karena tampaknya belum ada yang menangkap bug seperti itu, baik, atau memposting masalah di atasnya, saya harus memikirkan dulu semua opsi sendiri. Hal pertama yang terlintas dalam pikiran adalah mungkin vpc-controller tidak bisa menghilangkan ip-10-xxx.ap-xxx.compute.internal dan menyelesaikannya dan karena itu kesalahannya menurun.
Ya, memang, kami menggunakan server dns khusus di VPC dan kami tidak menggunakan server Amazon, jadi bahkan penerusan tidak dikonfigurasi pada domain ini ap-xxx.compute.internal. Saya memeriksa opsi ini, dan itu tidak membawa hasil, mungkin tesnya tidak bersih, dan karena itu, ketika berkomunikasi dengan dukungan teknis, saya menyerah pada ide mereka.
Karena tidak ada ide, semua grup keamanan dibuat oleh eksctl itu sendiri, sehingga tidak ada keraguan bahwa mereka bekerja, tabel rute juga benar, nat, dns, ada juga akses internet dengan node pekerja.
Pada saat yang sama, jika Anda menggunakan node pekerja ke subnet publik tanpa menggunakan --node-private-networking, node ini segera diperbarui oleh vpc-controller dan semuanya bekerja seperti jam.
Ada dua opsi:
- Hammer dan tunggu sampai seseorang menjelaskan bug ini di AWS dan mereka memperbaikinya dan kemudian Anda dapat dengan aman menggunakan AWS EKS Windows, karena mereka baru saja masuk ke GA (butuh 8 hari pada saat penulisan), kemungkinan besar banyak yang akan pergi dengan cara yang sama seperti saya .
- Menulis ke Dukungan AWS dan menjelaskan kepada mereka esensi masalah dengan sejumlah besar log dari mana-mana dan membuktikan kepada mereka bahwa layanan mereka tidak berfungsi ketika menggunakan VPC dan subnet mereka, tidak sia-sia bahwa kita memiliki dukungan Bisnis, kita harus menggunakannya setidaknya sekali :-)
Komunikasi dengan Insinyur AWS
Setelah membuat tiket di portal, saya secara keliru memilih untuk membalas saya melalui Web - email atau pusat dukungan, melalui opsi ini mereka dapat menjawab Anda setelah beberapa hari, meskipun faktanya tiket saya memiliki Kerusakan - Sistem rusak, yang menyiratkan respons dalam waktu <12 berjam-jam, dan karena rencana dukungan Bisnis memiliki dukungan 24/7, saya berharap yang terbaik, tetapi ternyata seperti biasa.
Tiket saya mendarat di Unassigned dari Jumat ke Mon, kemudian saya memutuskan untuk menulisnya lagi dan memilih opsi jawaban Obrolan. Setelah menunggu sebentar, Harshad Madhav ditunjuk untuk saya, dan kemudian mulai ...
Kami berdebat dengannya secara online selama 3 jam berturut-turut, mentransfer log, menyebarkan kluster yang sama ke laboratorium AWS untuk meniru masalah, menciptakan kembali kluster di pihak saya, dan seterusnya, satu-satunya hal yang kami temukan adalah bahwa log menunjukkan bahwa resolusi tidak berfungsi. Nama domain internal AWS seperti yang saya tulis di atas, dan Harshad Madhav meminta saya untuk membuat penerusan, konon kami menggunakan custom dns dan ini bisa menjadi masalah.
Penerusan
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
Apa yang dilakukan, hari telah berakhir, Harshad Madhav berhenti berlangganan cek itu dan itu akan berhasil, tetapi tidak, resolusi tidak membantu.
Lalu ada percakapan dengan 2 insinyur lagi, satu baru saja keluar dari obrolan, tampaknya takut akan kasus yang sulit, yang kedua menghabiskan hari saya lagi pada siklus debug penuh, mengirim log, membuat cluster di kedua sisi, pada akhirnya dia hanya berkata baik, itu bekerja untuk saya, inilah saya dokumentasi resmi saya melakukan semuanya langkah demi langkah melakukannya dan Anda dan Anda akan berhasil.
Ke mana saya dengan sopan memintanya pergi, dan menugaskan orang lain ke tiket saya jika Anda tidak tahu ke mana harus mencari masalah.
Terakhir
Pada hari ketiga, seorang insinyur baru Arun B. ditunjuk untuk saya, dan sejak awal komunikasi dengan dia segera jelas bahwa ini bukan 3 insinyur sebelumnya. Dia membaca seluruh sejarah dan segera meminta untuk mengumpulkan log dengan skripnya sendiri pada ps1 yang terletak di github-nya. Kemudian semua iterasi membuat cluster, mengeluarkan hasil tim, mengumpulkan log diikuti lagi, tetapi Arun B. bergerak ke arah yang benar menilai dari pertanyaan yang diajukan kepada saya.
Ketika kita memasukkan -stderrthreshold = debug di vpc-controller mereka, dan apa yang terjadi selanjutnya? pasti tidak berfungsi) pod tidak dimulai dengan opsi ini, hanya -stderrthreshold = info berfungsi.
Di sinilah kami berakhir dan Arun B. mengatakan bahwa ia akan mencoba mereproduksi langkah saya untuk mendapatkan kesalahan yang sama. Hari berikutnya saya mendapat tanggapan dari Arun B. Dia tidak menjatuhkan kasus ini, tetapi mengambil kode review dari vpc-controller mereka dan menemukan tempat yang sama di mana ia bekerja dan mengapa tidak bekerja:
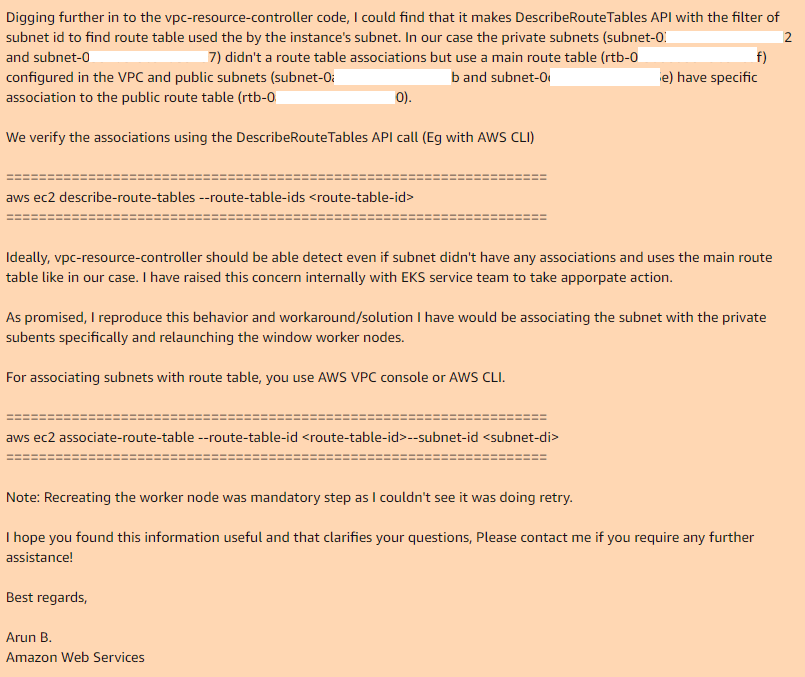
Jadi, jika Anda menggunakan tabel rute utama di VPC Anda, maka secara default tidak memiliki asosiasi dengan subnet yang diperlukan, jadi vpc-controller yang diperlukan, dalam kasus subnet publik, ia memiliki tabel rute kustom yang memiliki asosiasi.
Dengan menambahkan asosiasi secara manual untuk tabel rute utama dengan subnet yang diinginkan, dan menciptakan kembali nodegroup, semuanya bekerja dengan sempurna.
Saya berharap Arun B. memang akan melaporkan bug ini ke pengembang EKS dan kami akan melihat versi baru vpc-controller, dan di mana semuanya akan berjalan di luar kotak. Saat ini versi terbaru: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
memiliki masalah ini.
Terima kasih kepada semua orang yang membaca sampai akhir, uji semua yang akan Anda gunakan dalam produksi, sebelum implementasi.
Pembaruan: Bug Baru # 2
Setelah menemukan solusi untuk masalah pertama, kami terus menyiapkan layanan ini untuk kebutuhan kami, dan sekarang pada tahap terakhir, kami menemukan bug lain yang tidak kompatibel dengan kehidupan.
Masalah:Sebarkan aplikasi ke Kubernetes, atur penyebaran Anda, replika> 1, dan lihat gambar berikut. Pod baru mulai normal dan berfungsi, sedangkan pod lama kehilangan antarmuka jaringannya. Ya, ya, pod lama sama sekali tanpa jaringan, meskipun podcast itu terus menggantung dalam status Menjalankan. Kurangi atau tambah replika, hapus pod sehingga Anda tidak selalu hanya membuat pod yang yang terakhir masuk ke status Running akan berfungsi, sisanya tidak. Apapun, polong atau yang berbeda mulai pada node yang sama.
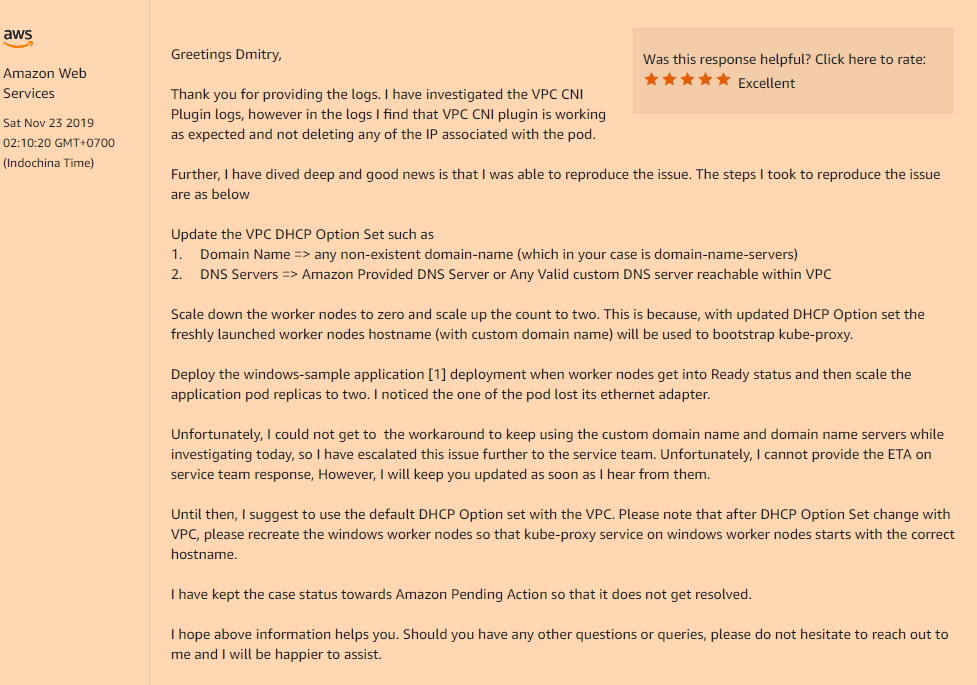
Solusi:Ya, masalahnya lagi ternyata dalam konfigurasi khusus VPC kami, yaitu jika Anda menggunakan set DHCP Options yang menunjukkan nilai khusus dari bidang nama domain, atau benar-benar kosong (seperti dalam kasus saya, saya hanya mengubah server-nama-server, Saya tidak butuh sisanya) Anda akan mendapatkan masalah yang tidak bisa dipahami dengan hilangnya antarmuka jaringan di dalam pod Anda setelah peluncuran.
Anda harus mendaftarkannya di set Opsi DHCP Anda:
domain-name = <aws-region-name>.compute.internal;
Dan setelah itu adalah menginstal ulang semua node pekerja Anda sehingga selama bootstrap semua komponen mendaftarkan pengaturan yang benar.
Berikut adalah detail tentang bagaimana opsi nama-domain ini memengaruhi node pekerja Anda:
Kali ini, saya meminta mereka untuk menambahkan setidaknya dokumentasi ke AWS EKS untuk Windows, "fitur" dari layanan mereka.