Kami sedang dalam proses mempersiapkan versi utama Tokio berikutnya, lingkungan runtime asinkron untuk Rust. Pada 13 Oktober,
permintaan kumpulan dengan penjadwal tugas yang ditulis ulang sepenuhnya dikeluarkan untuk bergabung ke cabang. Hasilnya adalah peningkatan kinerja yang sangat besar dan latensi yang berkurang. Beberapa tes mencatat percepatan sepuluh kali lipat! Seperti biasa, tes sintetik tidak mencerminkan manfaat aktual dalam kenyataan. Karena itu, kami juga memeriksa bagaimana perubahan pada penjadwal memengaruhi tugas nyata, seperti
Hyper dan
Tonic (spoiler: hasilnya luar biasa).
Bersiap untuk bekerja pada perencana baru, saya menghabiskan waktu mencari sumber daya tematik. Terlepas dari implementasi yang sebenarnya, tidak ada yang istimewa yang ditemukan. Saya juga menemukan bahwa kode sumber untuk implementasi yang ada sulit dinavigasi. Untuk mengatasinya, kami mencoba menulis sheduler Tokio sebersih mungkin. Saya harap artikel terperinci tentang implementasi penjadwal ini akan membantu mereka yang berada di posisi yang sama dan tidak berhasil mencari informasi tentang topik ini.
Artikel ini dimulai dengan tinjauan desain tingkat tinggi, termasuk kebijakan penangkapan pekerjaan. Kemudian selami rincian optimasi khusus dalam penjadwal Tokio baru.
Optimasi yang dipertimbangkan:
Seperti yang Anda lihat, tema utamanya adalah "pengurangan." Bagaimanapun, kode tercepat adalah kekurangannya!
Kami juga akan berbicara tentang
pengujian penjadwal baru . Sangat sulit untuk menulis kode paralel yang benar tanpa kunci. Lebih baik bekerja lambat, tetapi benar, daripada cepat, tetapi dengan gangguan, terutama jika bug berhubungan dengan keamanan memori. Opsi terbaik, bagaimanapun, harus bekerja dengan cepat dan tanpa kesalahan, jadi kami menulis
alat tenun , alat pengujian konkurensi.
Sebelum terjun ke topik, saya ingin mengucapkan terima kasih:
- @withoutboats dan lainnya yang mengerjakan fungsi
async / await di Rust. Anda melakukan pekerjaan dengan baik. Ini adalah fitur pembunuh.
- @cramertj dan lainnya yang mengembangkan
std::task . Ini merupakan peningkatan besar dibandingkan sebelumnya. Dan kode yang bagus.
- Buoyant , pencipta Linkerd, dan yang lebih penting, atasan saya. Terima kasih telah mengizinkan saya menghabiskan begitu banyak waktu untuk pekerjaan ini. Jika ada yang tertarik dengan layanan mesh, lihat Linkerd. Segera itu akan mencakup semua manfaat yang dibahas dalam artikel ini.
- Pergi untuk implementasi perencana yang baik.
Ambil secangkir kopi dan duduk. Ini akan menjadi artikel yang panjang.
Bagaimana cara kerja perencana?
Tugas sheduler adalah merencanakan pekerjaan. Aplikasi ini dibagi menjadi beberapa unit kerja, yang akan kita sebut
tugas . Suatu tugas dianggap runnable ketika dapat maju dalam pelaksanaannya, tetapi tidak lagi dilakukan atau dalam mode siaga, ketika itu dikunci pada sumber daya eksternal. Tugas bersifat independen dalam arti bahwa sejumlah tugas dapat dilakukan secara bersamaan. Penjadwal bertanggung jawab untuk menjalankan tugas dalam keadaan berjalan sampai mereka kembali ke mode siaga. Eksekusi tugas menyiratkan menetapkan waktu prosesor untuk tugas - sumber daya global.
Artikel ini membahas penjadwal ruang pengguna, yaitu, bekerja di atas utas sistem operasi (yang, pada gilirannya, dikendalikan oleh penjadwal level kernel). Penjadwal Tokio mengeksekusi Rust futures, yang dapat dianggap sebagai "thread hijau asinkron." Ini adalah pola
streaming campuran M: N di mana banyak tugas antarmuka pengguna di-multiplex ke banyak utas sistem operasi.
Ada banyak cara berbeda untuk mensimulasikan sheduler, masing-masing dengan pro dan kontra sendiri. Pada tingkat paling dasar, penjadwal dapat dimodelkan sebagai
run antrian dan
prosesor yang menariknya terpisah. Prosesor adalah bagian dari kode yang berjalan di utas. Dalam kode semu, ia melakukan hal berikut:
while let Some(task) = self.queue.pop() { task.run(); }
Ketika suatu tugas menjadi layak, itu dimasukkan ke dalam antrian eksekusi.
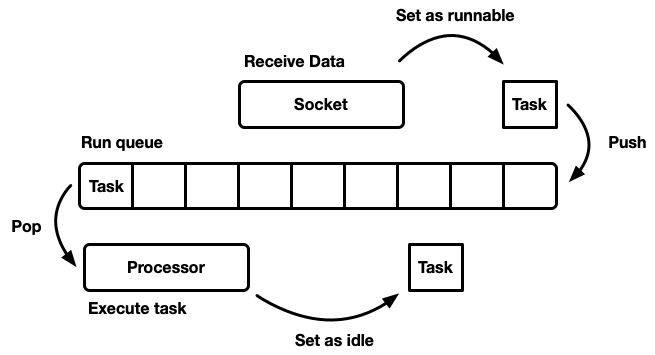
Meskipun Anda dapat merancang sistem di mana sumber daya, tugas, dan prosesor ada di utas yang sama, Tokio lebih suka menggunakan beberapa utas. Kita hidup di dunia di mana komputer memiliki banyak prosesor. Pengembangan penjadwal single-threaded akan menyebabkan pemuatan besi yang tidak mencukupi. Kami ingin menggunakan semua CPU. Ada beberapa cara untuk melakukan ini:
- Satu antrian eksekusi global, banyak prosesor.
- Banyak prosesor, masing-masing dengan menjalankan antrian sendiri.
Satu putaran, banyak prosesor
Model ini memiliki satu antrian eksekusi global. Ketika tugas menjadi selesai, mereka ditempatkan di ujung antrian. Ada beberapa prosesor, masing-masing di utas terpisah. Setiap prosesor mengambil tugas dari kepala antrian atau memblokir utas jika tidak ada tugas yang tersedia.
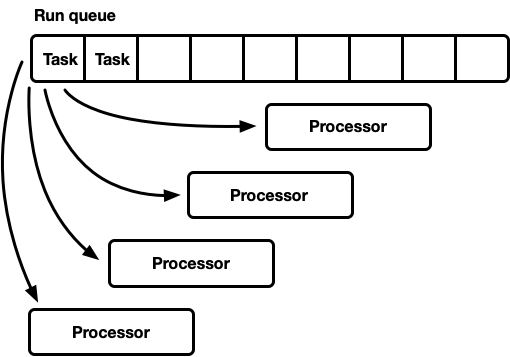
Garis eksekusi harus didukung oleh banyak produsen dan konsumen. Biasanya daftar
intrusif digunakan, di mana struktur setiap tugas menyertakan pointer ke tugas berikutnya dalam antrian (alih-alih membungkus tugas dalam daftar tertaut). Dengan demikian, alokasi memori untuk operasi push dan pop dapat dihindari. Anda dapat menggunakan
operasi push tanpa mengunci , tetapi untuk mengoordinasikan konsumen, mutex diperlukan untuk operasi pop (secara teknis dimungkinkan untuk menerapkan antrian multi-pengguna tanpa mengunci).
Namun, dalam praktiknya, overhead untuk perlindungan yang tepat terhadap kunci lebih dari sekadar menggunakan mutex.
Pendekatan ini sering digunakan untuk thread pool tujuan umum, karena memiliki beberapa keuntungan:
- Tugas cukup terencana.
- Implementasi yang relatif sederhana. Antrian standar kurang lebih dihubungkan dengan siklus prosesor yang dijelaskan di atas.
Catatan singkat tentang perencanaan yang adil (adil). Ini berarti bahwa tugas dilakukan dengan jujur: siapa pun yang datang lebih awal adalah orang yang pergi lebih awal. Perencana tujuan umum mencoba bersikap adil, tetapi ada pengecualian, seperti paralelisasi melalui pertigaan, di mana kecepatan menghitung hasilnya, dan bukannya keadilan untuk setiap subtugas, merupakan faktor penting.
Model ini memiliki kelemahan. Semua prosesor melamar untuk tugas dari kepala antrian. Untuk utas keperluan umum, ini biasanya bukan masalah. Waktu untuk menyelesaikan tugas jauh melebihi waktu untuk mengambilnya dari antrian. Ketika tugas dilakukan dalam jangka waktu yang lama, kompetisi dalam antrian berkurang. Namun, tugas Karat asinkron diharapkan selesai dengan sangat cepat. Dalam hal ini, biaya overhead untuk pertarungan dalam antrian meningkat secara signifikan.
Konkurensi dan simpati mekanis
Untuk mencapai kinerja maksimum, kita harus memaksimalkan fitur perangkat keras. Istilah "simpati mekanis" untuk perangkat lunak pertama kali digunakan oleh
Martin Thompson (yang blognya tidak lagi diperbarui, tetapi masih sangat informatif).
Diskusi rinci tentang penerapan paralelisme dalam peralatan modern berada di luar ruang lingkup artikel ini. Secara umum, zat besi meningkatkan produktivitas bukan karena akselerasi, tetapi karena pengenalan sejumlah besar inti CPU (bahkan laptop saya memiliki enam!). Setiap core dapat melakukan komputasi dalam jumlah besar dalam interval waktu yang sangat kecil. Tindakan seperti mengakses cache dan memori membutuhkan
waktu lebih banyak dibandingkan waktu eksekusi pada CPU. Karena itu, untuk mempercepat aplikasi, Anda perlu memaksimalkan jumlah instruksi CPU untuk setiap akses memori. Meskipun kompiler banyak membantu, kita masih harus memikirkan hal-hal seperti penyelarasan dan pola akses memori.
Utas terpisah secara terpisah bekerja sangat mirip dengan utas tunggal yang terisolasi,
hingga beberapa utas secara bersamaan memodifikasi garis cache yang sama (mutasi bersamaan) atau diperlukan
konsistensi yang konsisten . Dalam hal ini,
protokol koherensi cache CPU diaktifkan. Ini menjamin relevansi cache dari setiap CPU.
Kesimpulannya jelas: sejauh mungkin, hindari sinkronisasi antara utas, karena lambat.
Banyak prosesor, masing-masing dengan antrian eksekusi sendiri
Model lain adalah beberapa penjadwal single-threaded. Setiap prosesor menerima antrian eksekusi sendiri, dan tugas diperbaiki pada prosesor tertentu. Ini sepenuhnya menghindari masalah sinkronisasi. Karena model tugas Rust memerlukan kemampuan untuk mengantri tugas dari utas apa pun, masih harus ada cara aman untuk memasukkan tugas ke penjadwal. Baik antrian eksekusi dari masing-masing prosesor mendukung operasi push-safe-thread (MPSC), atau setiap prosesor memiliki
dua antrian eksekusi: tidak tersinkronisasi dan aman-thread.
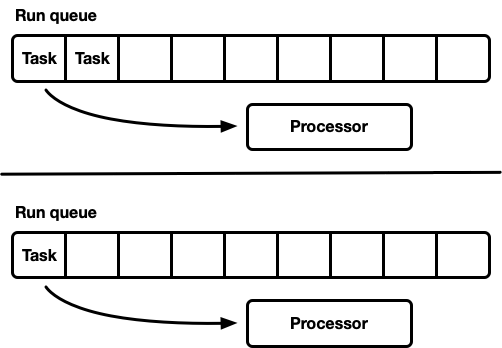
Strategi ini menggunakan
Seastar . Karena kita hampir sepenuhnya menghindari sinkronisasi, strategi ini memberikan kecepatan yang sangat baik. Tapi dia tidak menyelesaikan semua masalah. Jika beban kerja tidak sepenuhnya homogen, maka beberapa prosesor berada di bawah beban, sementara yang lain menganggur, yang mengarah pada penggunaan sumber daya yang tidak optimal. Ini terjadi karena tugas diperbaiki pada prosesor tertentu. Ketika sekelompok tugas direncanakan dalam satu paket pada satu prosesor, itu sendiri memenuhi beban puncak, bahkan jika yang lain menganggur.
Sebagian besar beban kerja “nyata” tidak homogen. Oleh karena itu, perencana tujuan umum biasanya menghindari model ini.
Penjadwal Pengambilan Pekerjaan
Penjadwal dengan penjadwalan pencurian-kerja didasarkan pada model penjadwalan berjuntai dan menyelesaikan masalah pemuatan sumber daya perangkat keras yang tidak lengkap. Setiap prosesor mendukung antrian eksekusi sendiri. Tugas-tugas yang menjadi dilakukan ditempatkan dalam antrian eksekusi prosesor saat ini, dan berfungsi di atasnya. Tetapi ketika prosesor dalam keadaan diam, ia memeriksa antrian dari prosesor saudara perempuan dan mencoba untuk mengambil sesuatu dari sana. Prosesor masuk ke mode tidur hanya setelah tidak dapat menemukan pekerjaan dari antrian eksekusi peer-to-peer.

Pada level model, ini adalah pendekatan "terbaik dari kedua dunia". Di bawah beban, prosesor bekerja secara independen, menghindari sinkronisasi overhead. Dalam kasus di mana beban antara prosesor didistribusikan secara tidak merata, penjadwal dapat mendistribusikannya kembali. Inilah sebabnya mengapa penjadwal tersebut digunakan dalam bahasa
Go ,
Erlang ,
Java, dan lainnya.
Kerugiannya adalah bahwa pendekatan ini jauh lebih rumit. Algoritme antrian harus mendukung tangkapan pekerjaan, dan untuk kelancaran pelaksanaan
beberapa sinkronisasi antara prosesor diperlukan. Jika tidak diimplementasikan dengan benar, maka overhead untuk menangkap bisa lebih dari keuntungan.
Pertimbangkan situasi ini: prosesor A sedang menjalankan tugas, dan memiliki antrian eksekusi yang kosong. Prosesor B menganggur; dia mencoba menangkap beberapa tugas, tetapi gagal, jadi dia beralih ke mode tidur. Kemudian 20 tugas muncul dari tugas prosesor A. Idealnya, prosesor B harus bangun dan mengambil beberapa dari mereka. Untuk ini, perlu menerapkan heuristik tertentu dalam penjadwal, di mana prosesor memberi sinyal ke prosesor rekan tidur tentang penampilan tugas baru dalam antrian mereka. Tentu saja, ini membutuhkan sinkronisasi tambahan, jadi operasi seperti itu sebaiknya diminimalkan.
Singkatnya:
- Semakin sedikit sinkronisasi, semakin baik.
- Job capture adalah algoritma optimal untuk perencana tujuan umum.
- Setiap prosesor bekerja secara independen dari yang lain, tetapi beberapa sinkronisasi diperlukan untuk menangkap pekerjaan.
Penjadwal Tokio 0.1
Penjadwal kerja pertama untuk Tokio dirilis pada Maret 2018. Ini adalah upaya pertama, berdasarkan pada beberapa asumsi yang ternyata salah.
Pertama, penjadwal Tokio 0.1 menyarankan agar utas prosesor harus ditutup jika tidak digunakan dalam waktu tertentu. Penjadwal awalnya dibuat sebagai sistem "tujuan umum" untuk kumpulan thread Rust. Pada saat itu, runtime Tokio masih pada tahap awal pengembangan. Kemudian model mengasumsikan bahwa tugas I / O akan dilakukan pada utas yang sama dengan pemilih I / O (epoll, kqueue, iocp ...). Lebih banyak tugas komputasi dapat diarahkan ke kumpulan utas. Dalam konteks ini, konfigurasi fleksibel dari jumlah utas aktif diasumsikan, sehingga lebih masuk akal untuk menonaktifkan utas menganggur. Namun, dalam penjadwal dengan tangkapan pekerjaan, model beralih untuk melakukan
semua tugas asinkron, dan dalam hal ini masuk akal untuk selalu mempertahankan sejumlah kecil utas dalam keadaan aktif.
Kedua, garis
silang dua arah diterapkan di
sana . Implementasi ini didasarkan pada jalur
Chase-Lev dua arah , dan tidak cocok untuk merencanakan tugas asinkron independen karena alasan yang dijelaskan di bawah ini.
Ketiga, implementasinya ternyata terlalu rumit. Ini sebagian disebabkan oleh fakta bahwa ini adalah penjadwal tugas pertama saya. Selain itu, saya terlalu tidak sabar ketika menggunakan atom di cabang, di mana mutex akan baik-baik saja. Pelajaran penting adalah bahwa sering kali mutex yang paling berhasil.
Akhirnya, ada banyak kelemahan kecil dalam implementasi awal. Pada tahun-tahun awal, detail implementasi dari model Rust asinkron berkembang secara signifikan, tetapi pustaka menjaga API stabil sepanjang waktu. Ini menyebabkan akumulasi beberapa hutang teknis.
Sekarang Tokio mendekati rilis besar pertama - dan kita dapat membayar semua hutang ini, serta belajar dari pengalaman yang diperoleh selama bertahun-tahun pembangunan. Ini adalah waktu yang menyenangkan!
Penjadwal Tokio Generasi Selanjutnya
Sekarang saatnya untuk melihat lebih dekat apa yang telah berubah di penjadwal baru.
Sistem tugas baru
Pertama, penting untuk menyoroti apa yang
bukan bagian dari Tokio, tetapi sangat penting dalam hal meningkatkan efisiensi: ini adalah
sistem tugas baru di
std , yang awalnya dikembangkan oleh
Taylor Kramer . Sistem ini menyediakan kait yang harus diimplementasikan oleh penjadwal untuk melakukan tugas-tugas Karat asinkron, dan sistem dirancang dan diimplementasikan dengan luar biasa. Ini jauh lebih ringan dan lebih fleksibel daripada iterasi sebelumnya.
Struktur
Waker dari sumber daya menandakan bahwa ada tugas yang
layak yang harus ditempatkan dalam antrian scheduler. Dalam sistem tugas yang baru, ini adalah struktur dua-pointer, padahal sebelumnya jauh lebih besar. Mengurangi ukuran penting untuk meminimalkan overhead menyalin nilai
Waker di tempat yang berbeda, dan itu memakan lebih sedikit ruang dalam struktur, yang memungkinkan Anda untuk memasukkan lebih banyak data penting ke dalam garis cache. Desain
vtable membuat sejumlah optimasi, yang akan kita bahas nanti.
Memilih algoritma antrian terbaik
Antrian eksekusi berada di tengah-tengah penjadwal. Oleh karena itu, ini adalah komponen yang paling penting untuk diperbaiki. Penjadwal Tokio asli menggunakan
antrian balok -
silang dua arah: implementasi sumber tunggal (produsen) dan banyak konsumen. Sebuah tugas ditempatkan di satu ujung, dan nilai diambil dari yang lain. Sebagian besar waktu, utas “mendorong” nilai dari akhir antrian, tetapi kadang-kadang utas lain mencegat pekerjaan, melakukan operasi yang sama. Antrian dua arah didukung oleh array dan serangkaian indeks yang melacak kepala dan ekor. Ketika antrian penuh, pengenalan itu akan menyebabkan peningkatan ruang penyimpanan. Array baru yang lebih besar dialokasikan, dan nilainya dipindahkan ke penyimpanan baru.
Kemampuan untuk tumbuh dicapai melalui kompleksitas dan overhead. Operasi push / pop harus memperhitungkan pertumbuhan ini. Selain itu, membebaskan array asli penuh dengan kesulitan tambahan. Dalam bahasa pengumpulan sampah (GC), array lama akan keluar dari ruang lingkup dan akhirnya GC akan menghapusnya. Namun, kapal Rust tanpa GC. Ini berarti bahwa kita sendiri bertanggung jawab untuk membebaskan array, tetapi utas dapat mencoba mengakses memori pada saat yang sama. Untuk mengatasi masalah ini, crossbeam menggunakan strategi reklamasi berbasis zaman. Meskipun tidak memerlukan banyak sumber daya, ia menambahkan overhead non-sepele ke jalur utama (hot path). Setiap operasi sekarang harus melakukan operasi atom RMW (baca-modifikasi-tulis) di pintu masuk dan keluar dari bagian kritis untuk memberi sinyal ke utas lain bahwa memori sedang digunakan dan tidak dapat dihapus.
Karena overhead untuk pertumbuhan antrian eksekusi, masuk akal untuk berpikir: apakah dukungan untuk pertumbuhan ini benar-benar diperlukan? Pertanyaan ini akhirnya mendorong saya untuk menulis ulang perencana. Strategi baru adalah memiliki ukuran antrian tetap untuk setiap proses. Ketika antrian penuh, alih-alih menambah antrian lokal, tugas berpindah ke antrian global dengan beberapa konsumen dan beberapa produsen. Prosesor akan memeriksa antrian global ini secara berkala, tetapi pada frekuensi yang jauh lebih rendah daripada yang lokal.
Sebagai bagian dari salah satu percobaan pertama, kami mengganti balok silang dengan
mpmc . Ini tidak mengarah pada peningkatan yang signifikan karena jumlah sinkronisasi untuk push dan pop. Kunci untuk menangkap pekerjaan adalah bahwa hampir tidak ada persaingan dalam antrian di bawah beban, karena setiap prosesor hanya mengakses antriannya sendiri.
Pada tahap ini, saya memutuskan untuk mempelajari sumber Go dengan hati-hati - dan menemukan bahwa mereka menggunakan ukuran antrian tetap dengan satu produsen dan beberapa konsumen, dengan sinkronisasi minimal, yang sangat mengesankan. Untuk menyesuaikan algoritme dengan penjadwal Tokio, saya membuat beberapa perubahan. Perlu dicatat bahwa implementasi Go menggunakan operasi atom berurutan (seperti yang saya mengerti). Versi Tokio juga mengurangi jumlah beberapa operasi penyalinan di cabang kode yang lebih jarang.
Implementasi antrian adalah buffer melingkar yang menyimpan nilai dalam array. Kepala dan ekor antrian dilacak oleh operasi atom dengan nilai integer.
struct Queue {
Antrian dilakukan oleh satu utas:
loop { let head = self.head.load(Acquire);
Perhatikan bahwa dalam fungsi
push ini, satu-satunya operasi atom memuat dengan memesan
Acquire dan menyimpan dengan pesanan
Release . Tidak ada operasi RMW (
compare_and_swap ,
fetch_and ...) atau urutan berurutan, seperti sebelumnya. Ini penting karena pada chip x86 semua unduhan / penyimpanan sudah “atomik”. Jadi, pada level CPU,
fungsi ini tidak akan disinkronkan . Operasi atom akan mencegah optimasi tertentu dalam kompiler, tetapi hanya itu saja. Kemungkinan besar, operasi
load pertama dapat dilakukan dengan aman dengan pemesanan
Relaxed , tetapi penggantian tidak membawa overhead yang terlihat.
Ketika antrian penuh,
push_overflow .
Fungsi ini memindahkan setengah dari tugas dari antrian lokal ke global. Antrian global adalah daftar intrusif yang dilindungi oleh mutex. Saat pindah ke antrian global, tugas pertama kali dihubungkan bersama, kemudian dibuat mutex, dan semua tugas dimasukkan dengan memperbarui pointer ke ujung antrian global. Ini menyimpan ukuran bagian kritis kecil.Jika Anda terbiasa dengan rincian pemesanan memori atom, Anda mungkin melihat "masalah" potensial dengan fungsi yang ditunjukkan di atas push. Operasi loadpemesanan atom Acquireagak lemah. Ini dapat mengembalikan nilai yang usang, mis., Operasi penangkapan paralel mungkin sudah meningkatkan nilai self.head, tetapi dalam cache aliranpushnilai lama akan tetap, sehingga tidak akan melihat operasi penangkapan. Ini bukan masalah dengan kebenaran dari algoritma. Dengan cara utama (cepat), pushkami hanya peduli apakah antrian lokal penuh atau tidak. Karena hanya utas saat ini yang dapat mendorong antrian, operasi yang sudah ketinggalan zaman loadhanya akan membuat antrian terlihat lebih penuh daripada yang sebenarnya. Ini mungkin salah menentukan bahwa antrian penuh, dan menyebabkan push_overflow, tetapi fungsi ini termasuk operasi atom yang lebih kuat. Jika push_overflowmenentukan bahwa antrian sebenarnya tidak penuh, maka kembali w / Err, dan operasi pushdimulai lagi. Ini adalah alasan lain mengapapush_overflowmemindahkan setengah dari antrian eksekusi ke antrian global. Setelah gerakan ini, kesalahan positif semacam itu terjadi jauh lebih jarang.Lokal pop(dari prosesor yang menjadi antrian) juga diimplementasikan secara sederhana: loop { let head = self.head.load(Acquire);
Dalam fungsi ini, satu singlet loaddan satu compare_and_swapdengan Release. Overhead utama berasal compare_and_swap.Fungsinya stealmirip dengan pop, tetapi self.tailmuatan atom harus ditransfer dari . Selain itu, sama halnya push_overflow, operasi stealmencoba berpura-pura menjadi setengah antrian alih-alih satu tugas. Ini memiliki efek yang baik pada kinerja, yang akan kita bahas nanti.Bagian terakhir yang hilang adalah analisis antrian global, yang menerima tugas yang melebihi antrian lokal, serta untuk mentransfer tugas ke penjadwal dari utas non-prosesor. Jika prosesor berada di bawah beban, yaitu, ada tugas di antrian lokal, prosesor akan mencoba menarik tugas keluar dari antrian global setelah setiap 60 tugas dalam antrian lokal. Itu juga memeriksa antrian global ketika berada dalam keadaan "pencarian" yang dijelaskan di bawah ini.Streamline Templat Pesan
Aplikasi Tokio biasanya terdiri dari banyak tugas kecil yang independen. Mereka berinteraksi satu sama lain melalui pesan. Templat semacam itu mirip dengan bahasa lain seperti Go dan Erlang. Mengingat betapa umum template itu, masuk akal bagi perencana untuk mengoptimalkannya.Misalkan tugas A dan B diberikan. Tugas A sekarang menjalankan dan mengirim pesan ke tugas B melalui saluran transmisi. Saluran adalah sumber daya tempat tugas B saat ini dikunci, sehingga tindakan mengirim pesan akan menyebabkan tugas B beralih ke status yang dapat dieksekusi - dan itu akan ditempatkan dalam antrian eksekusi prosesor saat ini. Kemudian prosesor akan menyimpulkan tugas berikutnya dari antrian eksekusi, jalankan, dan ulangi siklus ini hingga mencapai tugas B.Masalahnya adalah bahwa mungkin ada penundaan yang signifikan antara mengirim pesan dan menyelesaikan tugas B. Selain itu, data panas, seperti pesan, disimpan dalam cache CPU, tetapi pada saat tugas selesai, ada kemungkinan bahwa cache yang sesuai akan dihapus.Untuk mengatasi masalah ini, penjadwal Tokio baru mengimplementasikan optimasi (seperti pada penjadwal Go dan Kotlin). Ketika tugas masuk ke status yang dapat dieksekusi, itu tidak ditempatkan di akhir antrian, tetapi disimpan dalam slot "tugas berikutnya" khusus. Prosesor selalu memeriksa slot ini sebelum memeriksa antrian. Jika sudah ada tugas lama di sana saat memasukkan ke dalam slot, itu dihapus dari slot dan pindah ke akhir antrian. Dengan demikian, tugas pengiriman pesan akan selesai tanpa penundaan.
Pengambilan throttle
Dalam penjadwalan tangkapan pekerjaan, jika antrian eksekusi prosesor kosong, prosesor mencoba untuk menangkap tugas dari peer CPU. Pertama, CPU rekan acak dipilih, jika tidak ada tugas yang ditemukan untuk itu, yang berikutnya dicari, dan seterusnya, sampai tugas ditemukan.Dalam prakteknya, beberapa prosesor sering selesai memproses antrian eksekusi pada waktu yang hampir bersamaan. Ini terjadi ketika paket pekerjaan tiba (misalnya, kapanepolldisurvei untuk kesiapan soket). Prosesor bangun, menerima tugas, memulai dan menyelesaikan. Ini mengarah pada fakta bahwa semua prosesor secara bersamaan mencoba menangkap tugas orang lain, yaitu, banyak utas yang mencoba mengakses antrian yang sama. Ada konflik. Pilihan titik awal yang acak membantu mengurangi persaingan, tetapi situasinya masih belum terlalu baik.Untuk mengatasi masalah ini, penjadwal baru membatasi jumlah prosesor paralel yang melakukan operasi penangkapan. Kami menyebut status prosesor di mana ia mencoba menangkap tugas orang lain sebagai "pencarian pekerjaan" atau "pencarian" singkat (lebih lanjut tentang itu nanti). Optimalisasi semacam itu dilakukan dengan menggunakan nilai atomint, yang meningkat oleh prosesor sebelum memulai pencarian dan berkurang saat keluar dari kondisi pencarian. Sebisa mungkin dalam kondisi pencarian bisa setengah dari jumlah total prosesor. Yaitu, batas perkiraan ditetapkan, dan ini normal. Kami tidak perlu batasan keras pada jumlah CPU dalam pencarian, hanya pelambatan. Kami mengorbankan akurasi demi efisiensi algoritma.Setelah memasuki kondisi pencarian, prosesor mencoba menangkap pekerjaan dari peer CPU dan memeriksa antrian global.Kurangi sinkronisasi antar utas
Bagian penting lain dari penjadwal adalah memberi tahu rekan CPU tentang tugas baru. Jika "saudara" itu tertidur, ia bangun dan mengambil tugas. Pemberitahuan memainkan peran penting lainnya. Ingat bahwa algoritma antrian menggunakan urutan atom lemah ( Acquire/ Release). Karena alokasi memori atom, tidak ada jaminan bahwa prosesor peer akan pernah melihat tugas dalam antrian tanpa sinkronisasi tambahan. Karena itu, notifikasi juga bertanggung jawab untuk itu. Karena alasan ini, notifikasi menjadi mahal. Tujuannya adalah untuk meminimalkan jumlah mereka agar tidak menggunakan sumber daya CPU, yaitu, prosesor memiliki tugas, dan saudara tidak dapat mencurinya. Jumlah pemberitahuan yang berlebihan menyebabkan masalah kawanan guntur .Perencana Tokio yang asli mengambil pendekatan naif terhadap notifikasi. Setiap kali tugas baru ditempatkan dalam antrian eksekusi, prosesor menerima pemberitahuan. Setiap kali CPU diberi tahu dan melihat tugas setelah bangun, itu memberi tahu CPU lain. Logika ini sangat cepat menyebabkan semua prosesor bangun dan mencari pekerjaan (menyebabkan konflik). Seringkali, sebagian besar prosesor tidak menemukan pekerjaan dan tertidur lagi.Penjadwal baru sangat memperbaiki pola ini, mirip dengan penjadwal Go. Pemberitahuan dikirim seperti sebelumnya, tetapi hanya jika tidak ada CPU dalam kondisi pencarian (lihat bagian sebelumnya). Ketika prosesor menerima notifikasi, ia segera memasuki kondisi pencarian. Ketika prosesor dalam kondisi pencarian menemukan tugas baru, ia terlebih dahulu meninggalkan status pencarian dan kemudian memberitahu prosesor lainnya.Logika ini membatasi kecepatan prosesor bangun. Jika seluruh paket tugas direncanakan segera (misalnya, kapanepolldisurvei untuk kesiapan soket), maka tugas pertama akan menghasilkan pemberitahuan kepada prosesor. Dia sekarang dalam kondisi pencarian. Tugas terjadwal yang tersisa dalam paket tidak akan memberi tahu prosesor, karena setidaknya ada satu CPU dalam kondisi pencarian. Prosesor yang diberitahukan ini akan menangkap setengah tugas dalam batch dan, pada gilirannya, akan memberi tahu prosesor lainnya. Prosesor ketiga bangun, menemukan tugas salah satu dari dua prosesor pertama dan menangkap setengah dari mereka. Hal ini menyebabkan peningkatan yang lancar dalam jumlah CPU yang bekerja, serta penyeimbangan beban yang cepat.Kurangi alokasi memori
Penjadwal Tokio baru hanya membutuhkan satu alokasi memori untuk setiap tugas yang dimunculkan, sedangkan yang lama membutuhkan dua. Sebelumnya, struktur tugas terlihat seperti ini: struct Task {
Struktur Taskjuga akan disorot dalam Box. Untuk waktu yang sangat lama saya ingin memperbaiki sambungan ini (saya pertama kali mencoba pada tahun 2014). Dua hal telah berubah sejak perencana Tokio lama. Pertama, stabil std::alloc. Kedua, sistem tugas masa depan telah beralih ke strategi vtable eksplisit . Dua hal inilah yang akhirnya hilang, untuk menyingkirkan alokasi memori ganda yang tidak efisien untuk setiap tugas.Sekarang struktur Taskdisajikan dalam bentuk berikut: struct Task<T> { header: Header, future: T, trailer: Trailer, }
Untuk tugas-tugas yang diperlukan dan Headerdan Trailer, tetapi mereka dibagi antara "panas" Data (kepala) dan "dingin" (ekor), m. E. Sekitar antara data yang sering diakses dan orang-orang yang jarang digunakan. Data "Hot" ditempatkan di kepala struktur dan disimpan sesedikit mungkin. Saat prosesor meringkas penunjuk tugas, ia segera memuat garis cache (dari 64 hingga 128 byte). Kami ingin data ini serelevan mungkin.Mengurangi penghitungan tautan atom
Optimalisasi terakhir yang kita bahas dalam artikel ini adalah mengurangi jumlah tautan atom. Ada banyak referensi untuk struktur tugas, termasuk dari penjadwal dan dari setiap pembuat. Strategi umum untuk mengelola memori ini adalah penghitungan tautan atom . Strategi ini membutuhkan operasi atom setiap kali tautan dikloning dan setiap kali tautan dihapus. Ketika tautan terakhir keluar dari ruang lingkup, memori dibebaskan.Di penjadwal Tokio lama, penjadwal dan semua pembuat berisi tautan ke deskriptor tugas, kira-kira: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Ketika tugas bangun, tautan diklon (terjadi peningkatan atom). Kemudian tautan ditempatkan di antrian eksekusi. Saat prosesor menerima tugas dan menyelesaikan eksekusi, prosesor membuang tautan, yang mengarah ke pengurangan atom. Operasi atomik ini (bertambah dan berkurang) bertambah.Masalah ini sebelumnya diidentifikasi oleh pengembang sistem tugas std::future. Mereka memperhatikan bahwa ketika menelepon, Waker::waketautan asli ke wakersering tidak lagi diperlukan. Ini memungkinkan Anda untuk menggunakan kembali penghitung tautan atom saat memindahkan tugas ke antrian eksekusi. Sistem tugas std::futuresekarang mencakup dua panggilan API untuk "bangun":Konstruksi API seperti itu membuat kami menggunakannya saat menelepon wake, menghindari kenaikan atom. Implementasinya menjadi seperti ini: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Ini menghindari overhead dari jumlah tautan tambahan hanya jika Anda dapat bertanggung jawab untuk bangun. Dalam pengalaman saya, sebaliknya, hampir selalu disarankan untuk bangun bersama &self. Kebangkitan selfmencegah penggunaan kembali waker (berguna dalam kasus-kasus di mana sumber daya mengirimkan banyak nilai, misalnya saluran, soket, ...). Juga dalam kasus ini selflebih sulit untuk menerapkan bangun dengan aman (kami akan meninggalkan detail untuk artikel lain).Perencana baru memecahkan masalah "waking through self" dengan menghindari kenaikan atom wake_by_ref, yang membuatnya seefektifwake(self). Untuk melakukan ini, penjadwal menyimpan daftar semua tugas yang saat ini aktif (belum selesai). Daftar tersebut mewakili penghitung referensi yang diperlukan untuk mengirimkan tugas ke antrian eksekusi.Kompleksitas dari optimasi ini terletak pada kenyataan bahwa penjadwal tidak akan menghapus tugas dari daftar sampai ia menerima jaminan bahwa tugas akan ditempatkan di antrian eksekusi lagi. Detail implementasi skema ini berada di luar cakupan artikel ini, tetapi saya sangat menyarankan Anda melihat sumbernya.Konkurensi tebal (tidak aman) dengan Loom
Sangat sulit untuk menulis kode paralel yang benar tanpa kunci. Lebih baik bekerja perlahan, tetapi dengan benar, daripada dengan cepat, tetapi dengan gangguan, terutama jika bug berhubungan dengan keamanan memori. Opsi terbaik, bagaimanapun, harus bekerja dengan cepat dan tanpa kesalahan. Penjadwal baru membuat beberapa optimasi yang agak agresif dan menghindari sebagian besar tipe stddemi spesialisasi. Secara umum, ada cukup banyak kode tidak aman di dalamnya unsafe.Ada beberapa cara untuk menguji kode paralel. Salah satunya adalah bagi pengguna untuk menguji dan men-debug bukan Anda (opsi yang menarik, itu pasti). Lain adalah menulis unit test yang dijalankan dalam satu lingkaran dan dapat menangkap kesalahan. Mungkin bahkan menggunakan TSAN. Tentu saja, jika ia menemukan kesalahan, itu tidak dapat dengan mudah direproduksi tanpa memulai kembali siklus tes. Juga, berapa lama siklus ini? Sepuluh detik? Sepuluh menit? Sepuluh hari? Sebelumnya, Anda harus menguji kode paralel di Rust.Kami menemukan situasi ini tidak dapat diterima. Ketika kami merilis kode, kami ingin merasa percaya diri (sebanyak mungkin), terutama dalam kasus kode paralel tanpa kunci. Pengguna Tokio membutuhkan keandalan.Oleh karena itu, kami mengembangkan Loom : alat untuk pengujian permutasi kode paralel. Tes ditulis seperti biasa, tetapiloomIni akan menjalankannya berkali-kali, mengatur ulang semua opsi yang mungkin untuk dieksekusi dan perilaku yang mungkin ditemui tes dalam lingkungan streaming. Itu juga memeriksa akses memori yang benar, membebaskan memori, dll.Sebagai contoh, di sini adalah tes alat tenun untuk penjadwal baru: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
Itu terlihat sangat normal, tetapi sepotong kode dalam sebuah blok loom::modelberjalan ribuan kali (mungkin jutaan), setiap kali dengan sedikit perubahan perilaku. Setiap proses mengubah urutan persis dari utas. Selain itu, untuk setiap operasi atom, alat tenun mencoba semua perilaku berbeda yang diizinkan dalam model memori C ++ 11. Ingat bahwa muatan atom Acquireagak lemah dan dapat mengembalikan nilai yang usang. Tes loomakan mencoba semua nilai yang mungkin dapat dimuat.loommenjadi alat yang tak ternilai dalam mengembangkan perencana baru. Dia menangkap lebih dari sepuluh bug yang lulus semua pengujian unit, pengujian manual dan pengujian beban.Pembaca yang cerdas mungkin ragu bahwa alat tenun memeriksa "semua permutasi yang mungkin," dan ia akan benar. Permutasi naif akan menyebabkan ledakan kombinatorial. Tes non-sepele tidak akan pernah berakhir. Masalah ini telah dipelajari selama bertahun-tahun dan sejumlah algoritma telah dikembangkan untuk mencegah ledakan kombinatorial. Loom dasar algoritma berdasarkan pengurangan dinamis dengan memesan parsial (pengurangan parsial-order dinamis). Algoritma ini menghilangkan permutasi yang mengarah ke hasil yang sama. Tetapi ruang keadaan masih dapat tumbuh sedemikian rupa sehingga tidak akan diproses dalam jumlah waktu yang wajar (beberapa menit). Loom memungkinkan Anda untuk membatasi penggunaan pengurangan dinamis dengan pemesanan parsial.Secara umum, berkat pengujian ekstensif dengan Loom, saya sekarang jauh lebih percaya diri dalam kebenaran penjadwal.Hasil
Jadi, kami melihat penjadwal apa dan bagaimana penjadwal Tokio baru mencapai peningkatan kinerja besar ... tapi seperti apa pertumbuhannya? Mengingat bahwa penjadwal baru hanya dikembangkan, di dunia nyata belum diuji secara penuh. Inilah yang kita ketahui.Pertama, penjadwal baru jauh lebih cepat dalam tolok ukur mikro:Perencana tua
test chained_spawn ... bangku: 2,019,796 ns / iter (+/- 302,168)
test ping_pong ... bench: 1.279.948 ns / iter (+/- 154.365)
test spawn_many ... bangku: 10.283.608 ns / iter (+/- 1.284.275)
test yield_many ... bangku: 21,450,748 ns / iter (+/- 1,201,337)
Perencana baru
test chained_spawn ... bench: 168,854 ns / iter (+/- 8,339)
test ping_pong ... bench: 562.659 ns / iter (+/- 34.410)
test spawn_many ... bangku: 7.320.737 ns / iter (+/- 264.620)
test yield_many ... bangku: 14.638.563 ns / iter (+/- 1.573.678)
Benchmark ini meliputi:chained_spawn secara rekursif menelurkan tugas baru, mis., menghasilkan tugas yang menghasilkan tugas lain, yang juga menghasilkan tugas, dll.
ping_pongmemilih saluran oneshotdan memunculkan tugas yang mengirim pesan pada saluran itu. Tugas asli sedang menunggu pesan. Ini adalah ujian yang paling dekat dengan "dunia nyata".
spawn_many Memeriksa pelaksanaan tugas dalam penjadwal, mis. Menghasilkan tugas dari luar konteksnya.
yield_many memeriksa kebangkitan tugas independen.
Perbedaan dalam tolok ukur sangat mengesankan. Tetapi bagaimana ini akan tercermin dalam "dunia nyata"? Sulit untuk mengatakannya dengan pasti, tetapi saya mencoba menjalankan tolok ukur Hyper .Berikut adalah server Hyper paling sederhana, yang kinerjanya diukur menggunakan wrk -t1 -c50 -d10:Perencana tua
Menjalankan uji 10s @ http://127.0.0.1 {000
1 utas dan 50 koneksi
Thread Stats Rata-rata Stdev Max +/- Stdev
Latency 371.53us 99.05us 1.97ms 60.53%
Req / Sec 114.61k 8.45k 133.85k 67.00%
1139307 permintaan dalam 10.00, baca 95.61MB
Permintaan / dtk: 113923.19
Transfer / dtk: 9.56MB Perencana baru
Menjalankan uji 10s @ http://127.0.0.1 {000
1 utas dan 50 koneksi
Thread Stats Rata-rata Stdev Max +/- Stdev
Latency 275.05us 69.81us 1.09ms 73.57%
Req / Sec 153.17k 10.68k 171.51k 71.00%
1522671 permintaan dalam 10.00, baca 127.79MB
Permintaan / dtk: 152258.70
Transfer / dtk: 12,78MB Kami melihat peningkatan 34% dalam permintaan per detik setelah perubahan scheduler! Pertama kali saya melihat ini, saya sangat senang, karena saya mengharapkan peningkatan maksimal 5-10%. Tapi kemudian saya merasa sedih, karena hasil ini juga menunjukkan bahwa penjadwal Tokio lama tidak begitu baik. Lalu saya ingat bahwa Hyper sudah menjadi pemimpin dalam peringkat TechEmpower . Sangat menarik untuk melihat bagaimana perencana baru akan mempengaruhi peringkat.Tonic , klien dan server gRPC, dengan penjadwal baru telah dipercepat sekitar 10%, yang cukup mengesankan mengingat bahwa Tonic belum sepenuhnya dioptimalkan.Kesimpulan
Saya sangat senang akhirnya menyelesaikan proyek ini setelah beberapa bulan bekerja. Ini adalah peningkatan besar pada Rust I / O yang tidak sinkron. Saya sangat senang dengan perbaikan yang dilakukan. Masih ada banyak ruang untuk optimasi dalam kode Tokio, jadi kami belum selesai dengan peningkatan kinerja.Saya berharap bahwa materi dalam artikel ini akan bermanfaat bagi kolega yang mencoba menulis penjadwal tugas mereka.