Pavel Selivanov, Southbridge Solution Architect dan Slurm Lecturer, memberikan ceramah di DevOpsConf 2019. Ceramah ini adalah bagian dari Kubernetes Slur Mega, kursus mendalam tentang Kubernetes.
Dasar Slurm: Pengantar Kubernetes berlangsung di Moskow pada 18-20 November.
Slurm Mega: Kami mencari di bawah tenda Kubernetes - Moskow, 22-24 November.
Slurm Online: Kedua kursus Kubernetes selalu tersedia.
Di bawah transkrip laporan.
Selamat siang, kolega dan simpatisan. Hari ini saya akan berbicara tentang keamanan.
Saya melihat bahwa ada banyak penjaga keamanan di aula hari ini. Saya minta maaf kepada Anda terlebih dahulu jika saya tidak akan menggunakan ketentuan dari dunia keamanan dengan cara yang biasa bagi Anda.
Kebetulan sekitar enam bulan yang lalu saya jatuh ke tangan salah satu kluster publik Kubernet. Publik - berarti ada sejumlah namespace, di namespace ini ada pengguna yang terisolasi di namespace mereka. Semua pengguna ini milik perusahaan yang berbeda. Nah, seharusnya kluster ini harus digunakan sebagai CDN. Artinya, mereka memberi Anda sebuah cluster, mereka memberikan pengguna di sana, Anda pergi ke sana di namespace Anda, menyebarkan front Anda.
Mereka mencoba menjual layanan seperti itu ke perusahaan saya sebelumnya. Dan saya diminta untuk menyodok kluster pada subjek - apakah solusi ini cocok atau tidak.
Saya datang ke kluster ini. Saya diberi hak terbatas, namespace terbatas. Di sana, orang-orang mengerti apa itu keamanan. Mereka membaca apa kontrol akses berbasis Rober (RBAC) untuk Kubernetes - dan mereka memutarnya sehingga saya tidak bisa menjalankan pod secara terpisah dari penyebaran. Saya tidak ingat tugas yang saya coba selesaikan dengan menjalankan di bawah tanpa penempatan, tetapi saya benar-benar ingin berjalan di bawah. Saya memutuskan untuk keberuntungan untuk melihat hak apa yang saya miliki di cluster, apa yang saya bisa, apa yang saya tidak bisa, apa yang mereka lakukan di sana. Pada saat yang sama saya akan memberi tahu Anda apa yang telah mereka konfigurasi di RBAC secara tidak benar.
Kebetulan bahwa dalam dua menit saya mendapatkan admin ke kluster mereka, melihat semua ruang nama tetangga, melihat front produksi perusahaan yang sudah membeli layanan dan terjebak di sana. Aku nyaris berhenti, agar tidak mendatangi seseorang di depan dan tidak menaruh kata cabul di halaman utama.
Saya akan memberi tahu Anda dengan contoh bagaimana saya melakukan ini dan bagaimana melindungi diri saya dari ini.
Tapi pertama-tama, perkenalkan diri saya. Nama saya Pavel Selivanov. Saya seorang arsitek di Southbridge. Saya mengerti Kubernetes, DevOps dan segala macam hal mewah. Insinyur Southbridge dan saya sedang membangun semua ini, dan saya menyarankan.
Selain bisnis inti kami, kami baru-baru ini meluncurkan proyek yang disebut Slory. Kami mencoba untuk membawa kemampuan kami untuk bekerja dengan Kubernetes kepada massa, untuk mengajar orang lain bagaimana bekerja dengan K8 juga.
Apa yang akan saya bicarakan hari ini. Topik laporan ini jelas - tentang keamanan cluster Kubernetes. Tetapi saya ingin segera mengatakan bahwa topik ini sangat besar - dan karena itu saya ingin segera menetapkan apa yang tidak akan saya ceritakan dengan pasti. Saya tidak akan berbicara tentang istilah basi yang sudah seratus kali terlalu banyak di Internet. Setiap RBAC dan sertifikat.
Saya akan berbicara tentang bagaimana rekan-rekan saya dan saya muak dengan keamanan di kluster Kubernetes. Kami melihat masalah ini baik dengan penyedia yang menyediakan kluster Kubernetes dan dengan pelanggan yang datang kepada kami. Dan bahkan dengan klien yang datang kepada kami dari perusahaan admin konsultasi lainnya. Artinya, skala tragedi itu sebenarnya sangat besar.
Secara harfiah tiga poin, yang akan saya bicarakan hari ini:
- Hak pengguna vs hak pod. Hak pengguna dan hak jantung bukan hal yang sama.
- Pengumpulan informasi cluster. Saya akan menunjukkan bahwa dari cluster Anda dapat mengumpulkan semua informasi yang Anda butuhkan tanpa memiliki hak khusus di cluster ini.
- Serangan DoS pada cluster. Jika kami tidak dapat mengumpulkan informasi, kami dapat menempatkan cluster dalam hal apa pun. Saya akan berbicara tentang serangan DoS pada kontrol cluster.
Hal umum lain yang akan saya sebutkan adalah di mana saya menguji semuanya, apa yang dapat saya katakan dengan pasti bahwa semuanya bekerja
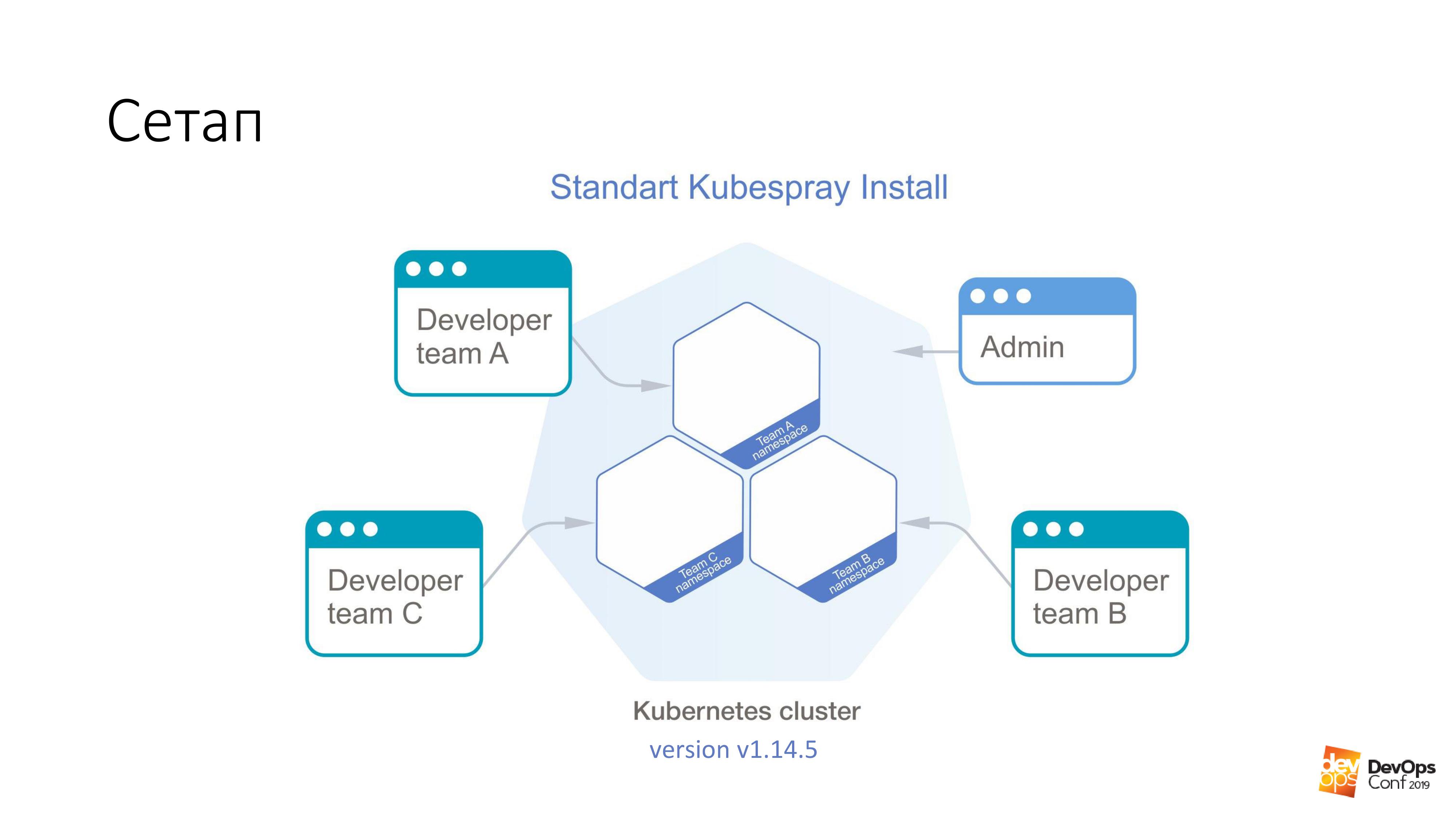
Sebagai dasar, kami mengambil instalasi cluster Kubernetes menggunakan Kubespray. Jika seseorang tidak tahu, ini sebenarnya adalah seperangkat peran untuk Ansible. Kami terus menggunakannya dalam pekerjaan kami. Hal yang baik adalah Anda bisa berguling di mana saja - Anda bisa berguling di kelenjar, dan di suatu tempat di awan. Satu metode pemasangan pada prinsipnya cocok untuk semuanya.
Di kluster ini, saya akan memiliki Kubernetes v1.14.5. Seluruh kelompok Kuba, yang akan kami pertimbangkan, dibagi menjadi ruang nama, setiap ruang nama milik tim yang terpisah, anggota tim ini memiliki akses ke setiap ruang nama. Mereka tidak bisa pergi ke ruang nama yang berbeda, hanya ke tempat mereka sendiri. Tetapi ada beberapa akun admin yang memiliki hak untuk seluruh cluster.
Saya berjanji bahwa hal pertama yang akan kita miliki adalah mendapatkan hak admin ke cluster. Kami membutuhkan pod yang disiapkan khusus yang akan memecah kluster Kubernetes. Yang perlu kita lakukan adalah menerapkannya ke kluster Kubernetes.
kubectl apply -f pod.yaml
Pod ini akan tiba di salah satu master dari cluster Kubernetes. Dan setelah itu cluster akan dengan senang hati mengembalikan file bernama admin.conf kepada kami. Di Kuba, semua sertifikat admin disimpan dalam file ini, dan pada saat yang sama, API cluster dikonfigurasikan. Itulah cara Anda bisa mendapatkan akses admin, saya pikir, untuk 98% dari cluster Kubernetes.
Saya ulangi, pod ini dibuat oleh satu pengembang di cluster Anda yang memiliki akses untuk menyebarkan proposal ke satu namespace kecil, ia semua dijepit oleh RBAC. Dia tidak punya hak. Meskipun demikian, sertifikat telah kembali.
Dan sekarang tentang perapian yang disiapkan khusus. Jalankan pada gambar apa pun. Misalnya, ambil debian: jessie.
Kami memiliki hal seperti itu:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
Apa itu toleransi? Para master di kluster Kubernetes biasanya ditandai dengan sesuatu yang disebut taint ("infeksi" dalam bahasa Inggris). Dan esensi dari "infeksi" ini - dia mengatakan bahwa pod tidak dapat ditugaskan ke master node. Tapi tidak ada yang mengganggu untuk menunjukkan dengan cara apa pun bahwa ia toleran terhadap "infeksi". Bagian Toleration hanya mengatakan bahwa jika NoSchedule ada di beberapa simpul, maka infeksi kami yang di bawah itu toleran - dan tidak ada masalah.
Lebih lanjut, kita mengatakan bahwa bawah kita tidak hanya toleran, tetapi juga ingin secara khusus jatuh pada tuan. Karena tuan adalah yang paling enak yang kita butuhkan - semua sertifikat. Oleh karena itu, kami mengatakan nodeSelector - dan kami memiliki label standar pada penyihir, yang memungkinkan kami untuk memilih secara tepat simpul-simpul yang merupakan penyihir dari semua simpul cluster.
Dengan dua bagian seperti itu, dia pasti akan datang ke master. Dan dia akan diizinkan untuk tinggal di sana.
Tetapi datang ke tuan saja tidak cukup bagi kita. Itu tidak akan memberi kita apa pun. Karena itu, lebih jauh kita memiliki dua hal ini:
hostNetwork: true hostPID: true
Kami mengindikasikan bahwa di bawah kami, yang kami luncurkan, akan hidup di namespace kernel, di namespace jaringan dan di namespace PID. Begitu dimulai pada wizard, ia akan dapat melihat semua antarmuka nyata dari node ini, mendengarkan semua lalu lintas dan melihat PID dari semua proses.
Selanjutnya, ini kecil. Ambil etcd dan baca yang Anda inginkan.
Yang paling menarik adalah fitur Kubernetes ini, yang hadir di sana secara default.
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
Dan intinya adalah bahwa kita dapat mengatakan bahwa kita ingin membuat volume tipe hostPath di pod yang kita jalankan, bahkan tanpa hak untuk cluster ini. Ini berarti mengambil jalur dari host yang akan kita mulai - dan menganggapnya sebagai volume. Dan kemudian beri nama: host. Semua hostPath ini kita pasang di dalam perapian. Dalam contoh ini, ke direktori / host.
Saya ulangi sekali lagi. Kami menyuruh pod untuk datang ke master, dapatkan hostNetwork dan hostPID di sana - dan pasang seluruh root master di dalam pod ini.
Anda mengerti bahwa di debian kami memiliki bash running, dan bash ini berfungsi di bawah root kami. Artinya, kami baru saja mendapatkan root untuk master, sementara tidak memiliki hak apa pun di kluster Kubernetes.
Maka seluruh tugas adalah untuk masuk ke direktori di bawah / host / etc / kubernetes / pki, jika saya tidak salah, ambil semua sertifikat master dari cluster di sana dan, dengan demikian, menjadi admin cluster.
Jika Anda melihat ke arah sini, ini adalah beberapa hak paling berbahaya di pod - terlepas dari hak pengguna:

Jika saya memiliki hak untuk dijalankan di dalam beberapa namespace cluster, maka sub ini memiliki hak-hak ini secara default. Saya dapat menjalankan pod istimewa, dan ini umumnya semua hak, praktis root pada node.
Favorit saya adalah pengguna Root. Dan Kubernetes memiliki opsi Run As Non-Root. Ini adalah jenis perlindungan hacker. Apakah Anda tahu apa "virus Moldavia" itu? Jika Anda seorang peretas dan datang ke kluster Kubernetes saya, maka kami, administrator yang buruk, tanyakan: “Harap sebutkan di pod Anda yang akan digunakan untuk meretas kluster saya, jalankan sebagai non-root. Dan kebetulan Anda memulai proses di perapian di bawah root, dan akan sangat mudah bagi Anda untuk meretas saya. Tolong lindungi dirimu dari dirimu sendiri. ”
Host volume jalan - menurut saya, cara tercepat untuk mendapatkan hasil yang diinginkan dari kluster Kubernetes.
Tetapi apa yang harus dilakukan dengan semua ini?
Pikiran yang harus datang ke administrator normal yang bertemu Kubernetes: “Ya, saya katakan, Kubernetes tidak berfungsi. Ada lubang di dalamnya. Dan seluruh kubus itu omong kosong. " Bahkan, ada yang namanya dokumentasi, dan jika Anda melihatnya di sana, maka ada bagian Kebijakan Keamanan Pod .
Ini adalah objek yaml - kita bisa membuatnya di cluster Kubernetes - yang mengontrol aspek keamanan dalam deskripsi perapian. Faktanya, ia mengontrol hak-hak tersebut untuk menggunakan semua jenis hostNetwork, hostPID, jenis volume tertentu, yang ada di pod saat startup. Dengan Kebijakan Keamanan Pod, semua ini dapat dijelaskan.
Hal yang paling menarik dalam Kebijakan Keamanan Pod adalah bahwa di kluster Kubernetes, semua penginstal PSP tidak dijelaskan dengan cara apa pun, mereka hanya dimatikan secara default. Kebijakan Keamanan Pod diaktifkan menggunakan plugin penerimaan.
Oke, mari kita berakhir di Kebijakan Polis Pod cluster, katakanlah kita memiliki semacam pod layanan di namespace, yang hanya dapat diakses oleh admin. Katakanlah di semua pod lain mereka memiliki hak terbatas. Karena kemungkinan besar, pengembang tidak perlu menjalankan pod istimewa di cluster Anda.
Dan semuanya tampak baik-baik saja dengan kita. Dan kluster Kubernet kami tidak dapat diretas dalam dua menit.
Ada masalah. Kemungkinan besar, jika Anda memiliki kluster Kubernetes, maka pemantauan diinstal di kluster Anda. Saya bahkan beranggapan bahwa jika ada pemantauan di cluster Anda, maka itu disebut Prometheus.
Apa yang akan saya sampaikan kepada Anda sekarang akan berlaku untuk operator Prometheus dan untuk Prometheus yang dikirimkan dalam bentuk murni. Pertanyaannya adalah jika saya tidak bisa mendapatkan admin dengan cepat ke dalam cluster, itu berarti saya perlu mencari lebih banyak. Dan saya dapat mencari menggunakan pemantauan Anda.
Mungkin, semua orang membaca artikel yang sama tentang Habré, dan pemantauan adalah pemantauan. Helm chart disebut kira-kira sama untuk semua orang. Saya berasumsi bahwa jika Anda menginstal helm stable / prometheus, maka Anda akan mendapatkan kira-kira nama yang sama. Dan bahkan kemungkinan besar saya tidak perlu menebak nama DNS di cluster Anda. Karena itu standar.
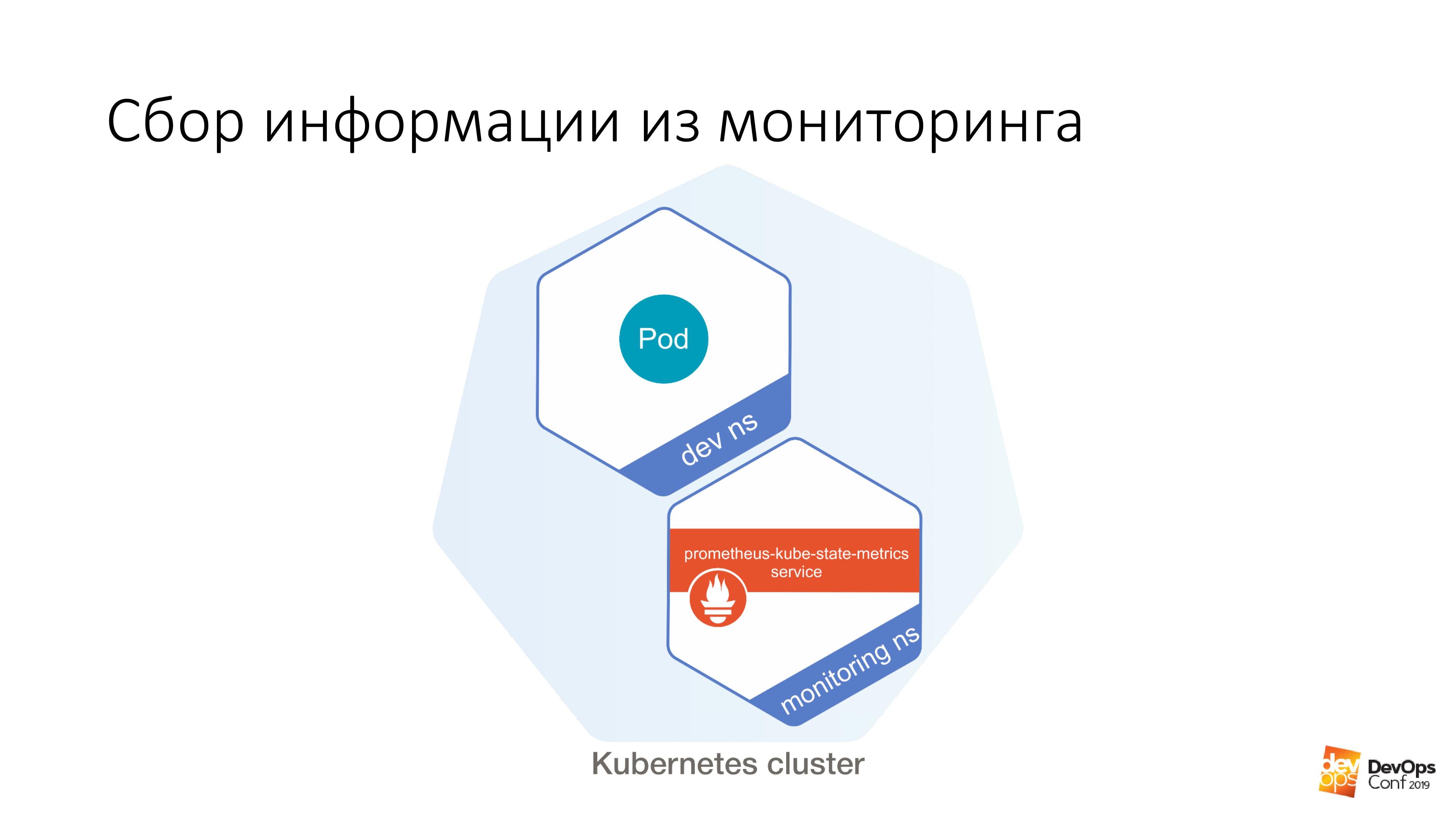
Selanjutnya kami memiliki pengembang tertentu, di dalamnya dimungkinkan untuk meluncurkan di bawah tertentu. Dan lebih jauh dari perapian ini sangat mudah dilakukan seperti ini:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state-metrics adalah salah satu eksportir prometheus yang mengumpulkan metrik dari API Kubernetes. Ada banyak data yang berjalan di cluster Anda, apa itu, masalah apa yang Anda miliki dengannya.
Sebagai contoh sederhana:
kube_pod_container_info {namespace = "kube-system", pod = "kube-apiserver-k8s-1", container = "kube-apiserver", image =
"gcr.io/google-containers/kube-apiserver:v1.14.5"
, Image_id = "docker-pullable: //gcr.io/google-containers/kube- apiserver @ SHA256: e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989", container_id = "docker: // 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b"} 1
Setelah membuat permintaan ikal sederhana dari file yang tidak terjangkau, Anda dapat memperoleh informasi tersebut. Jika Anda tidak tahu versi Kubernet mana yang Anda jalankan, maka ia akan dengan mudah memberi tahu Anda.
Dan yang paling menarik adalah selain fakta bahwa Anda beralih ke metrik kube-state, Anda bisa langsung menerapkannya ke Prometheus sendiri. Anda dapat mengumpulkan metrik dari sana. Anda bahkan dapat membuat metrik dari sana. Bahkan secara teoritis, Anda dapat membuat permintaan seperti itu dari sebuah cluster di Prometheus, yang cukup mematikannya. Dan pemantauan Anda biasanya berhenti bekerja dari cluster.
Dan di sini muncul pertanyaan apakah ada pemantauan eksternal yang memantau pemantauan Anda. Saya baru saja mendapat kesempatan untuk bertindak di kluster Kubernetes tanpa konsekuensi apa pun untuk diri saya sendiri. Anda bahkan tidak akan tahu bahwa saya bertindak di sana, karena tidak ada pemantauan lagi.
Sama seperti dengan PSP, rasanya masalahnya adalah bahwa semua teknologi yang trendi ini - Kubernetes, Prometheus - semuanya tidak berfungsi dan penuh lubang. Tidak juga.
Ada hal seperti itu - Kebijakan Jaringan .
Jika Anda adalah admin normal, maka kemungkinan besar tentang Kebijakan Jaringan Anda tahu bahwa ini adalah yaml lain, yang dalam cluster sudah dofig. Dan beberapa kebijakan jaringan jelas tidak diperlukan. Dan bahkan jika Anda membaca apa itu Kebijakan Jaringan, apa itu Kubernetes yaml-firewall, itu memungkinkan Anda untuk membatasi hak akses antara ruang nama, di antara pod, maka Anda tentu memutuskan bahwa firewall jenis yaml di Kubernetes adalah abstraksi berikutnya ... Tidak, tidak . Ini jelas tidak perlu.
Bahkan jika spesialis keamanan Anda tidak diberi tahu bahwa menggunakan Kubernetes Anda, Anda dapat membangun firewall dengan sangat mudah dan sederhana, dan itu sangat terperinci. Jika mereka masih tidak mengetahui hal ini dan tidak menarik Anda: "Baiklah, beri, berikan ..." Dalam hal apa pun, Anda memerlukan Kebijakan Jaringan untuk memblokir akses ke beberapa tempat layanan yang dapat Anda tarik dari cluster Anda tanpa izin apa pun.
Seperti dalam contoh yang saya kutip, Anda bisa menarik metrik status kubus dari namespace apa pun di kluster Kubernetes tanpa memiliki hak apa pun padanya. Kebijakan jaringan menutup akses dari semua ruang nama lain ke pemantauan namespace dan, seolah-olah, semuanya: tidak ada akses, tidak ada masalah. Di semua grafik yang ada, baik prometeus standar, dan prometeus yang ada di operator, di sana hanya di nilai-nilai helm ada pilihan untuk dengan mudah mengaktifkan kebijakan jaringan untuk mereka. Anda hanya perlu menyalakannya dan mereka akan bekerja.
Sebenarnya ada satu masalah di sini. Menjadi admin berjanggut normal, Anda kemungkinan besar memutuskan bahwa kebijakan jaringan tidak diperlukan. Dan setelah membaca semua jenis artikel tentang sumber daya seperti Habr, Anda memutuskan bahwa kain flanel terutama dengan mode host-gateway adalah hal terbaik yang dapat Anda pilih.
Apa yang harus dilakukan
Anda dapat mencoba untuk menggunakan kembali solusi jaringan yang ada di cluster Kubernetes Anda, cobalah menggantinya dengan sesuatu yang lebih fungsional. Di Calico yang sama, misalnya. Tapi segera saya ingin mengatakan bahwa tugas mengubah solusi jaringan di kluster kerja Kubernetes cukup non-trivial. Saya menyelesaikannya dua kali (namun, secara teoritis, dua kali), tetapi kami bahkan menunjukkan bagaimana melakukan ini pada Slurms. Untuk siswa kami, kami menunjukkan cara mengubah solusi jaringan di kluster Kubernetes. Pada prinsipnya, Anda dapat mencoba memastikan bahwa tidak ada downtime pada kluster produksi. Tetapi Anda mungkin tidak akan berhasil.
Dan masalahnya sebenarnya diselesaikan dengan sangat sederhana. Ada sertifikat di cluster, dan Anda tahu bahwa sertifikat Anda akan memburuk dalam setahun. Nah, dan biasanya solusi normal dengan sertifikat di cluster - mengapa kita harus menguapkan, kami akan menaikkan cluster baru di sebelahnya, biarkan busuk di yang lama, dan kami akan mengulang semuanya. Benar, ketika itu memburuk, semuanya akan berbaring di zaman kita, tetapi kemudian cluster baru.
Saat Anda akan memunculkan cluster baru, pada saat yang sama masukkan Calico, bukan flanel.
Apa yang harus dilakukan jika Anda memiliki sertifikat yang dikeluarkan selama seratus tahun dan Anda tidak akan mengelompokkan kembali kluster? Ada hal seperti itu Kube-RBAC-Proxy. Ini adalah pengembangan yang sangat keren, memungkinkan Anda untuk menanamkan diri Anda sebagai wadah sespan ke perapian di kluster Kubernetes. Dan dia benar-benar menambahkan otorisasi melalui Kubernetes RBAC ke pod ini.
Ada satu masalah. Sebelumnya, Kube-RBAC-Proxy dibangun ke dalam prometheus operator. Tapi kemudian dia pergi. Sekarang, versi modern bergantung pada fakta bahwa Anda memiliki kebijakan jaringan dan tutup menggunakannya. Jadi Anda harus menulis ulang bagan sedikit. Bahkan, jika Anda pergi ke repositori ini , ada beberapa contoh bagaimana menggunakannya sebagai sidecars, dan Anda harus menulis ulang grafik secara minimal.
Ada masalah kecil lainnya. Tidak hanya Prometheus memberikan metriknya kepada siapa pun yang mendapatkannya. Kami memiliki semua komponen cluster Kubernetes, mereka juga dapat memberikan metrik mereka.
Tetapi seperti yang saya katakan, jika Anda tidak bisa mendapatkan akses ke kluster dan mengumpulkan informasi, maka Anda setidaknya dapat membahayakan.
Jadi saya akan segera menunjukkan kepada Anda dua cara Anda dapat merusak kluster Kubernet Anda.
Anda akan tertawa ketika saya memberi tahu Anda, ini adalah dua kasus dari kehidupan nyata.
Cara pertama. Kehabisan sumber daya.
Kami meluncurkan satu lagi istimewa di bawah. Dia akan memiliki bagian seperti itu.
resources: requests: cpu: 4 memory: 4Gi
Seperti yang Anda ketahui, permintaan adalah jumlah CPU dan memori yang disediakan pada host untuk pod tertentu dengan permintaan. Jika kita memiliki host empat inti di kluster Kubernetes, dan empat CPU datang ke sana dengan permintaan, maka itu berarti tidak ada lagi pod dengan permintaan ke host ini.
Jika saya menjalankan ini di bawah, maka saya akan membuat perintah:
$ kubectl scale special-pod --replicas=...
Maka tidak ada orang lain yang akan dapat digunakan untuk cluster Kubernetes. Karena di semua node permintaan akan berakhir. Jadi saya menghentikan kluster Kubernet Anda. Jika saya melakukan ini di malam hari, maka saya dapat menghentikan penyebaran untuk beberapa waktu.
Jika kita melihat kembali pada dokumentasi Kubernetes, kita akan melihat hal seperti itu yang disebut Batas Rentang. Ini menetapkan sumber daya untuk objek cluster. Anda dapat menulis objek Batas Rentang dalam yaml, menerapkannya ke ruang nama tertentu - dan lebih lanjut dalam ruang nama ini Anda dapat mengatakan bahwa Anda memiliki sumber daya untuk pod default, maksimum, dan minimum.
Dengan bantuan hal semacam itu, kami dapat membatasi pengguna dalam ruang nama produk khusus tim dalam kemampuan untuk menunjukkan hal-hal buruk di pod mereka. Namun sayangnya, bahkan jika Anda memberi tahu pengguna bahwa tidak mungkin untuk menjalankan pod dengan permintaan lebih dari satu CPU, ada perintah skala yang luar biasa, atau melalui dashboard mereka dapat melakukan skala.
Dan dari sini muncul metode nomor dua. Kami meluncurkan 11 111 111 111 111 perapian. Itu sebelas miliar. Ini bukan karena saya datang dengan nomor seperti itu, tetapi karena saya melihatnya sendiri.
Kisah nyata. Menjelang sore saya akan meninggalkan kantor. Saya melihat, sekelompok pengembang duduk di sudut dan melakukan sesuatu dengan panik dengan laptop. Saya pergi ke orang-orang dan bertanya: "Apa yang terjadi padamu?"
Sedikit lebih awal, pada pukul sembilan malam, salah satu pengembang akan pulang. Dan dia memutuskan: "Saya akan melewatkan aplikasi saya sekarang." Saya mengklik sedikit, dan internet sedikit membosankan. Dia sekali lagi mengklik unit, dia menekan unit, mengklik Enter. Mengejek segala yang dia bisa. Kemudian Internet hidup kembali - dan semuanya mulai meningkat hingga saat ini.
Benar, kisah ini tidak terjadi di Kubernetes, pada waktu itu adalah Nomad. Itu berakhir dengan fakta bahwa setelah satu jam upaya kami untuk menghentikan Nomad dari upaya keras kepala untuk tetap bersatu, Nomad menjawab bahwa ia tidak akan berhenti menempel dan tidak akan melakukan hal lain. "Aku lelah, aku akan pergi." Dan meringkuk.
Saya secara alami mencoba melakukan hal yang sama di Kubernetes. Sebelas miliar polong Kubernet tidak senang, katanya: "Aku tidak bisa. Melebihi penjaga mulut internal. " Tapi 1.000.000.000 perapian bisa.
Menanggapi satu miliar, Cube tidak masuk ke dalam. Dia benar-benar mulai berkembang. Semakin jauh prosesnya, semakin banyak waktu yang dibutuhkannya untuk membuat perapian baru. Namun prosesnya tetap berjalan. Satu-satunya masalah adalah bahwa jika saya dapat menjalankan pod tanpa batas di namespace saya, maka bahkan tanpa permintaan dan batasan saya dapat memulai sejumlah pod dengan beberapa tugas yang dengan tugas-tugas ini node akan mulai bertambah dari memori, dari CPU. Ketika saya menjalankan begitu banyak perapian, informasi dari mereka harus pergi ke repositori, yaitu, etcd. Dan ketika terlalu banyak informasi tiba di sana, gudang mulai memberikan terlalu lambat - dan di Kubernetes segalanya mulai tumpul.
Dan satu masalah lagi ... Seperti yang Anda tahu, elemen kontrol Kubernetes bukan hanya satu hal utama, tetapi beberapa komponen. Di sana, khususnya, ada manajer pengontrol, penjadwal, dan sebagainya. Semua orang ini akan mulai melakukan pekerjaan bodoh yang tidak perlu pada saat yang sama, yang seiring waktu akan mulai mengambil lebih banyak waktu. Manajer pengontrol akan membuat pod baru. Penjadwal akan mencoba menemukan mereka simpul baru. Node baru di cluster Anda kemungkinan besar akan segera berakhir. Cluster Kubernetes akan mulai bekerja lebih lambat dan lambat.
Tetapi saya memutuskan untuk melangkah lebih jauh. Seperti yang Anda tahu, di Kubernetes ada yang namanya layanan. Yah, dan secara default di cluster Anda, kemungkinan besar, layanan ini bekerja menggunakan tabel IP.
Jika Anda menjalankan satu miliar perapian, misalnya, lalu gunakan skrip untuk memaksa Kubernetis membuat layanan baru:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
Pada semua node cluster, kira-kira aturan iptables baru akan dihasilkan kira-kira secara bersamaan. Selain itu, untuk setiap layanan, satu miliar aturan iptables akan dihasilkan.
Saya memeriksa semua ini pada beberapa ribu, hingga selusin. Dan masalahnya adalah bahwa sudah pada ambang ini ssh pada node cukup bermasalah untuk dilakukan. Karena paket-paket, melewati sejumlah rantai, mulai terasa tidak enak.
Dan semua ini juga diselesaikan dengan bantuan Kubernetes. Ada objek kuota Sumber Daya seperti itu. Menetapkan jumlah sumber daya dan objek yang tersedia untuk namespace di sebuah cluster. Kita bisa membuat objek yaml di setiap namespace cluster Kubernetes. Dengan menggunakan objek ini, kita dapat mengatakan bahwa kita telah mengalokasikan sejumlah permintaan, batasan untuk namespace ini, dan kemudian kita dapat mengatakan bahwa dalam namespace ini dimungkinkan untuk membuat 10 layanan dan 10 pod. Dan satu pengembang setidaknya bisa menekan di malam hari. Kubernetes akan berkata kepadanya: "Anda tidak dapat menempelkan pod Anda ke jumlah seperti itu karena melebihi kuota sumber daya." Semuanya, masalah terpecahkan. Dokumentasinya ada di sini .
Satu masalah muncul sehubungan dengan ini. Anda merasakan betapa sulitnya membuat namespace di Kubernetes. Untuk membuatnya, kita perlu mempertimbangkan banyak hal.
Kuota sumber daya + Rentang Batas + RBAC
• Buat namespace
• Buat batasan dalam
• Buat kuota sumber daya di dalam
• Buat akun layanan untuk CI
• Buat rolebinding untuk CI dan pengguna
• Secara opsional jalankan pod layanan yang diperlukan
Oleh karena itu, mengambil kesempatan ini, saya ingin berbagi perkembangan saya. Ada hal seperti itu, yang disebut operator SDK. Ini adalah cara di cluster Kubernetes untuk menulis operator untuk itu. Anda dapat menulis pernyataan menggunakan Ansible.
Pertama, ditulis dalam Ansible, dan kemudian saya melihat bahwa ada operator SDK dan menulis ulang peran Ansible dalam operator. Operator ini memungkinkan Anda untuk membuat objek di kluster Kubernet yang disebut tim. yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.