Keandalan flash: diharapkan dan tidak terduga. Bagian 1. Konferensi XIV dari asosiasi USENIX. Teknologi penyimpanan fileKeandalan flash: diharapkan dan tidak terduga. Bagian 2. Konferensi XIV dari asosiasi USENIX. Teknologi penyimpanan file5.5. Kesalahan dan litografi yang tidak dapat dipulihkan
Menariknya, efek litografi pada kesalahan yang tidak dapat diperbaiki kurang jelas daripada dalam kasus RBER, di mana litografi yang lebih kecil, seperti yang diharapkan, mengarah ke RBER yang lebih tinggi. Sebagai contoh, Gambar 6 menunjukkan bahwa model SLC-B memiliki tingkat koreksi kesalahan yang lebih cepat daripada model SLC-A, meskipun SLC-B memiliki litografi yang lebih besar (50 nm dibandingkan dengan 34 nm untuk model SLC-A). Selain itu, model seri MLC dengan ukuran kerja yang lebih kecil (model MLC-B), sebagai aturan, tidak memiliki tingkat kesalahan fatal yang lebih tinggi daripada model lainnya.
Faktanya, selama sepertiga pertama masa pakainya (jumlah siklus PE dari 0 hingga 1000) dan di sepertiga terakhir masa pakainya (> 2200 siklus PE), model ini memiliki frekuensi UE lebih rendah daripada, misalnya, model MLC-D. Ingatlah bahwa semua drive MLC dan SLC menggunakan mekanisme ECC yang sama, sehingga konsekuensi ini tidak dapat dikaitkan dengan perbedaan dalam ECC.
Secara umum, kami menemukan bahwa litografi memiliki efek yang lebih rendah dari yang diharapkan dan efek yang lebih rendah pada kesalahan yang tidak dapat diperbaiki dibandingkan dengan apa yang kami amati ketika mempelajari efek RBER.
5.6. Dampak dari jenis kesalahan lainnya dibandingkan dengan kesalahan yang tidak dapat diperbaiki
Pertimbangkan apakah ada kesalahan lain meningkatkan kemungkinan kesalahan yang tidak dapat diperbaiki.
Gambar 7 menunjukkan probabilitas kesalahan fatal yang terjadi pada bulan tertentu operasi disk, tergantung pada apakah berbagai jenis kesalahan terjadi pada disk di beberapa titik pada periode operasi sebelumnya (warna kuning garis-garis) atau pada bulan sebelumnya (warna hijau garis-garis), dan perbandingan probabilitas ini dengan probabilitas terjadinya kesalahan yang tidak dapat diperbaiki (bilah merah) di bulan berikutnya.
Kami melihat bahwa semua jenis kesalahan meningkatkan kemungkinan kesalahan yang tidak dapat diperbaiki. Dalam kasus ini, peningkatan maksimum terjadi ketika kesalahan sebelumnya terlihat relatif baru-baru ini (mis., Pada bulan sebelumnya - bilah hijau pada bagan lebih tinggi daripada kuning) atau jika kesalahan sebelumnya juga merupakan kesalahan yang tidak dapat diperbaiki. Misalnya, probabilitas kesalahan yang tidak dapat diperbaiki terjadi satu bulan setelah kesalahan yang tidak dapat diperbaiki lainnya adalah hampir 30% dibandingkan dengan probabilitas 2% untuk melihat kesalahan yang tidak dapat diperbaiki pada bulan lainnya. Tetapi kesalahan penulisan akhir, kesalahan meta dan menghapus kesalahan juga meningkatkan kemungkinan UE lebih dari 5 kali.
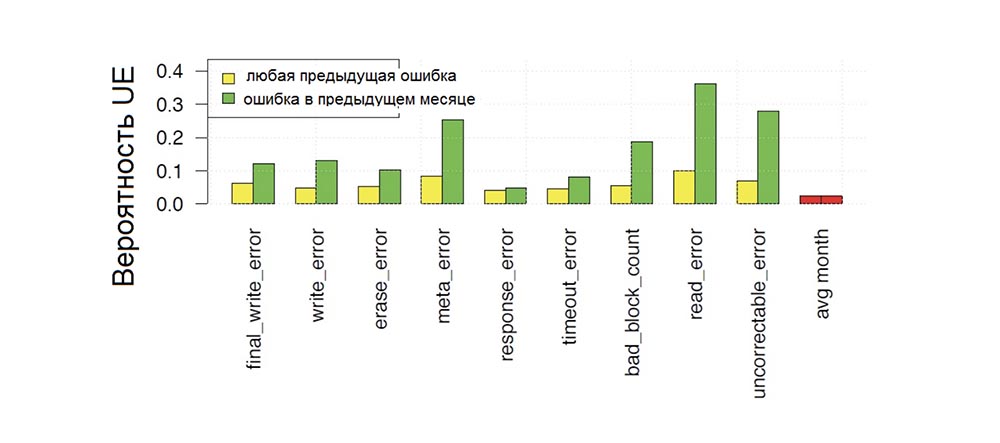 Fig. 7. Probabilitas bulanan terjadinya kesalahan drive yang tidak dapat diperbaiki sebagai fungsi ketergantungan pada adanya kesalahan sebelumnya dari berbagai jenis.
Fig. 7. Probabilitas bulanan terjadinya kesalahan drive yang tidak dapat diperbaiki sebagai fungsi ketergantungan pada adanya kesalahan sebelumnya dari berbagai jenis.Dengan demikian, kesalahan sebelumnya, khususnya kesalahan yang tidak dapat diperbaiki sebelumnya, meningkatkan kemungkinan terjadinya kesalahan yang tidak dapat diperbaiki lebih dari satu urutan besarnya.
6. Kegagalan Perangkat Keras
6.1. Blok yang rusak
Blok adalah bagian memori di mana operasi penghapusan dilakukan. Dalam penelitian kami, kami membedakan antara unit yang rusak di lapangan dan yang sudah memiliki kerusakan pabrik saat drive dikirim ke pengguna.
Dalam penelitian kami, drive menyatakan blok rusak setelah kesalahan akhir membaca, menulis atau menghapus, dan karenanya menugaskannya kembali (yaitu, blok dikeluarkan dari penggunaan lebih lanjut dan data apa pun yang ditempatkan di blok ini dan yang dapat dikembalikan diarahkan ke blok lain) .
 Tab. 4. Statistik tentang keberadaan blok yang rusak yang timbul dalam proses kondisi lapangan operasi, dan adanya blok yang rusak yang timbul dalam proses pembuatan disk di pabrik.
Tab. 4. Statistik tentang keberadaan blok yang rusak yang timbul dalam proses kondisi lapangan operasi, dan adanya blok yang rusak yang timbul dalam proses pembuatan disk di pabrik.Bagian atas dari Tabel 4 memberikan statistik tentang unit yang rusak di drive yang diuji di lapangan. Baris teratas menunjukkan proporsi drive dengan blok yang rusak untuk masing-masing dari 10 model drive, rata-rata menunjukkan jumlah rata-rata blok yang rusak untuk drive yang berisi blok yang rusak, garis bawah menunjukkan jumlah rata-rata blok yang rusak di antara disk dengan blok yang rusak.
Kami menganggap hanya drive yang dimasukkan ke dalam produksi setidaknya empat tahun lalu, dan hanya blok yang rusak yang muncul selama 4 tahun pertama pengujian lapangan. Setengah bagian bawah tabel memberikan statistik pada drive di mana ada blok yang rusak yang muncul selama pembuatan pabrik.
6.1.1. Terjadinya unit yang rusak di lapangan
Kami sampai pada kesimpulan bahwa blok yang rusak sering terjadi: di lapangan, tergantung pada model, mereka ditemukan di 30-80% dari disk. Studi tentang fungsi distribusi kumulatif (CDF) untuk jumlah blok drive yang rusak menunjukkan bahwa sebagian besar disk dengan blok yang rusak hanya memiliki sejumlah kecil blok seperti itu: jumlah rata-rata blok buruk untuk disk dengan blok yang rusak, tergantung pada model, dari 2 hingga 4. Namun, jika jumlah kerusakan blok drive lebih dari angka median, maka biasanya jauh lebih banyak. Fenomena ini diilustrasikan pada Gambar 8.
 Fig. 8. Gambar menunjukkan peningkatan jumlah blok yang rusak tergantung pada jumlah blok yang awalnya rusak.
Fig. 8. Gambar menunjukkan peningkatan jumlah blok yang rusak tergantung pada jumlah blok yang awalnya rusak.Gambar 8 menunjukkan bagaimana median jumlah blok drive yang rusak berkembang dengan peningkatan jumlah blok yang sudah rusak. Garis biru sesuai dengan model MLC, garis putus-putus merah sesuai dengan model SLC. Khususnya, untuk drive MLC, kami mengamati peningkatan tajam dalam jumlah blok yang rusak setelah blok kedua yang terdeteksi rusak, sedangkan angka median melonjak menjadi 200, yaitu, 50% dari disk yang memiliki 2 blok yang rusak terdeteksi, seiring waktu 200 atau lebih blok yang rusak muncul.
Selama kita tidak memiliki akses untuk penghitungan kesalahan pada tingkat chip, blok yang rusak dianggap ratusan, mungkin karena kegagalan chip itu sendiri, jadi Gambar 8 menunjukkan bahwa setelah munculnya beberapa blok yang rusak, ada kemungkinan besar seluruh chip gagal. Hasil ini dapat berfungsi sebagai peluang potensial untuk memprediksi kegagalan chip jika Anda mengandalkan perhitungan blok buruk sebelumnya dan mempertimbangkan faktor-faktor lain seperti usia, beban kerja, dan siklus PE.
Selain menentukan frekuensi terjadinya blok buruk, kami juga tertarik untuk mengetahui bagaimana blok yang rusak terdeteksi - selama operasi penulisan atau penghapusan, ketika kegagalan blok tidak terlihat oleh pengguna, atau ketika kesalahan pembacaan akhir terjadi yang terlihat oleh pengguna dan menciptakan risiko kehilangan data. Meskipun kami tidak memiliki data tentang kegagalan blok individu dan bagaimana mereka terdeteksi, kami dapat merujuk pada frekuensi yang diamati dari berbagai jenis kesalahan, yang menunjukkan kegagalan blok. Kembali ke Tabel 2, kita melihat bahwa untuk semua model, frekuensi kesalahan penghapusan dan kesalahan tulis lebih rendah daripada untuk kesalahan pembacaan akhir, yaitu, sebagian besar blok yang rusak terdeteksi sebagai akibat dari terjadinya kesalahan buram, yaitu selama operasi membaca.
6.1.2. Unit yang rusak di pabrik
Di atas, kami memeriksa dinamika terjadinya blok buruk di lapangan. Di sini kami mencatat bahwa hampir semua disk (> 99% untuk sebagian besar model) berisi cacat pabrik dalam bentuk blok yang rusak, dan jumlahnya sangat bervariasi di antara model, mulai dari angka median kurang dari 100 untuk 2 model SLC, dan diakhiri dengan nilai yang lebih khas yaitu lebih dari 800 untuk model lain. Distribusi blok pabrik yang rusak sesuai dengan distribusi normal, sedangkan nilai rata-rata dan median mendekati nilainya. Menariknya, jumlah unit pabrik yang rusak sampai batas tertentu memprediksi munculnya masalah drive lain di lapangan. Misalnya, kami perhatikan bahwa untuk semua kecuali satu model drive, 95% drive yang memiliki blok buruk pabrik memiliki proporsi blok rusak baru yang lebih tinggi di lapangan dan proporsi kesalahan penulisan akhir yang lebih tinggi daripada rata-rata disk yang sama. model. Mereka juga memiliki andil yang lebih tinggi dalam pengembangan jenis kesalahan membaca tertentu (baik final maupun non-final). Disk dalam persentase 5% memiliki bagian kesalahan batas waktu di bawah rata-rata. Dengan demikian, kami sampai pada kesimpulan berikut tentang blok buruk: kerusakan blok adalah kejadian yang cukup umum diamati pada 30-80% drive yang memiliki setidaknya satu blok seperti itu. Pada saat yang sama, ada ketergantungan yang kuat: jika disk berisi setidaknya 2-4 blok yang rusak, ada kemungkinan 50% bahwa ratusan blok yang rusak akan mengikuti. Hampir semua disk dilengkapi dengan blok yang rusak oleh pabrik, yang memberikan alasan untuk memprediksi perkembangannya di lapangan, serta pengembangan beberapa jenis kesalahan lainnya.
6.2. Chip memori yang rusak
Dalam penelitian kami, diyakini bahwa chip disk gagal jika lebih dari 5% dari blok gagal, atau jika jumlah kesalahan disk selama interval waktu terakhir melebihi nilai batas. Beberapa flash drive pabrik mengandung chip cadangan, jadi jika satu chip gagal, drive menggunakan yang kedua. Dalam penelitian kami, drive memiliki fungsi yang sama. Alih-alih bekerja pada chip cadangan, chip memori yang rusak dikeluarkan dari penggunaan lebih lanjut, dan drive terus bekerja dengan penurunan kinerja pada chip yang tersisa.
Baris pertama dari Tabel 5 menunjukkan prevalensi chip yang rusak. Kita melihat bahwa 2-7% disk mengalami kerusakan chip selama empat tahun pertama operasi. Drive yang tidak memiliki mekanisme untuk memetakan chip yang rusak memerlukan perbaikan dan dikembalikan ke pabrik.
 Tab. 5. Bagian berbagai model disk dengan chip rusak yang memerlukan perbaikan dan diganti selama 4 tahun pertama uji coba lapangan.
Tab. 5. Bagian berbagai model disk dengan chip rusak yang memerlukan perbaikan dan diganti selama 4 tahun pertama uji coba lapangan.Kami juga memeriksa gejala-gejala yang menyebabkan chip ditandai sebagai cacat: di semua model, sekitar dua pertiga dari chip ditandai rusak setelah 5% dari blok yang rusak terbentuk, dan sepertiga dari chip ditandai gagal setelah mencapai batas hari dengan kesalahan.
Kami perhatikan bahwa pemasok semua chip memori flash untuk drive ini memberikan jaminan bahwa jumlah blok per chip yang rusak tidak akan melebihi 2% hingga batas siklus PE tercapai. Oleh karena itu, dua pertiga dari chip yang rusak, di mana lebih dari 5% dari blok gagal, tidak memenuhi garansi pabrik.
6.3. Perbaikan dan penggantian drive
Drive harus diganti atau diperbaiki jika muncul masalah yang memerlukan intervensi dari tenaga teknis. Baris kedua Tabel 5 menunjukkan persentase disk yang perlu diperbaiki pada beberapa titik waktu selama 4 tahun pertama operasi. Kami mengamati perbedaan yang signifikan dalam kebutuhan perbaikan cakram dari berbagai model. Sementara untuk sebagian besar model, hanya 6-9% yang membutuhkan perbaikan di beberapa titik waktu, beberapa model drive, seperti SLC-B dan SLC-C, masing-masing membutuhkan perbaikan dalam 30% dan 26% kasus. Melihat frekuensi relatif perbaikan, yaitu, rasio hari-hari operasi drive dengan jumlah kasus perbaikan, baris ketiga dari Tabel 5), kami mengamati rentang dari beberapa ribu hari antara peristiwa perbaikan untuk model terburuk hingga 15.000 hari antara perbaikan untuk model terbaik.
Kami juga memeriksa frekuensi perbaikan berulang: selama seluruh periode operasi, 96% disk hanya mengalami 1 perbaikan. Sebuah studi tentang armada disk yang beroperasi menunjukkan bahwa sekitar 5% dari drive secara konstan diganti dalam waktu 4 tahun sejak tanggal commissioning (baris keempat dari Tabel 5), sementara di antara model terburuk (MLC - B dan SLC-B), sekitar 10% drive. Di antara disk yang diganti, sekitar setengahnya untuk diperbaiki, dan dipahami bahwa setidaknya setengah dari semua perbaikan akan berhasil.
7. Perbandingan drive MLC, eMLC dan SLC
Aktuator seperti eMLC dan SLC menarik pasar konsumen dengan harga lebih tinggi.Selain fakta bahwa mereka dicirikan oleh daya tahan tertinggi, yaitu, sejumlah besar siklus penulisan ulang, pelanggan menganggap bahwa produk seperti segmen SSD tertinggi dicirikan oleh keandalan dan daya tahan umum. Di bagian artikel ini, kami mencoba menilai kewajaran pendapat ini.
Kembali ke Tabel 3, kita melihat bahwa pendapat ini benar dalam kaitannya dengan disk SLC relatif terhadap RBER, karena koefisien ini adalah urutan besarnya lebih rendah daripada MLC dan drive eMLC. Namun, tabel 2 dan 5 menunjukkan bahwa disk SLC tidak memiliki keandalan terbaik: frekuensi penggantian dan perbaikannya, serta frekuensi kesalahan buram tidak lebih rendah dari indikator serupa drive yang dibuat menggunakan teknologi lain.
Drive EMLC menunjukkan RBER yang lebih tinggi daripada MLC, bahkan mengingat bahwa batas RBER yang lebih rendah untuk drive MLC bisa 16 kali lebih tinggi dalam kasus terburuk. Namun, ada kemungkinan bahwa perbedaan ini terjadi karena litografi yang lebih sedikit daripada perbedaan teknologi lainnya. Berdasarkan pengamatan di atas, kami menyimpulkan bahwa drive SLC biasanya tidak lebih dapat diandalkan daripada drive MLC.
8. Perbandingan dengan HDD
Pertanyaan yang jelas adalah bagaimana keandalan flash drive dibandingkan dengan keandalan pesaing utama mereka - HDD.
Kami menemukan bahwa ketika sampai pada frekuensi penggantian disk, flash drive menang. Menurut penelitian sebelumnya yang dilakukan pada tahun 2007, sekitar 2-9% dari jumlah total HDD diganti setiap tahun, yang secara signifikan lebih dari 4-10% dari SSD diganti 4 tahun setelah dimulainya operasi. Namun, flash drive kurang menarik ketika datang ke tingkat kesalahan. Lebih dari 20% flash drive mengembangkan kesalahan yang tidak dapat dipulihkan selama 4 tahun beroperasi, blok yang rusak muncul di 30-80%, dan chip gagal di 2-7%. Data dari salah satu makalah penelitian 2007 menunjukkan munculnya sektor yang rusak hanya dalam 3,5% HDD selama 32 bulan. Ini adalah angka yang cukup rendah, tetapi mengingat bahwa jumlah total sektor HDD adalah urutan besarnya lebih besar dari jumlah blok atau chip SSD, dan sektor-sektor ini lebih kecil dari blok, karakteristik terburuk dari SSD tampaknya tidak begitu serius.
Secara umum, kami sampai pada kesimpulan bahwa flash drive memerlukan penggantian jauh lebih jarang dalam masa kerja normal daripada hard drive. Di sisi lain, dibandingkan dengan HDD, SSD memiliki lebih banyak kesalahan yang tidak dapat diperbaiki.
9. Studi lain di bidang ini
Ada sejumlah besar penelitian tentang keandalan chip flash berdasarkan percobaan laboratorium terkontrol dengan sejumlah kecil chip, yang berfokus pada mengidentifikasi tren kesalahan dan sumbernya. Sebagai contoh, beberapa karya awal 2002-2006 mempelajari pelestarian, pemrograman, dan pelanggaran operasi baca chip flash, dan dalam beberapa karya terbaru, tren munculnya kesalahan pada chip MLC terbaru dipelajari. Kami tertarik dengan perilaku flash drive di lapangan, sehingga hasil pengamatan kami terkadang berbeda dari hasil penelitian yang diterbitkan sebelumnya. Sebagai contoh, kami percaya bahwa RBER bukanlah indikator yang andal dari kemungkinan terjadinya kesalahan yang tidak dapat diperbaiki dan bahwa RBER tumbuh dengan siklus PE secara linier, bukan secara eksponensial.
Hanya ada satu studi lapangan yang baru-baru ini diterbitkan tentang kesalahan memori flash berdasarkan data yang dikumpulkan di Facebook - “Studi skala besar tentang kegagalan memori flash di lapangan” (MEZA, J., WU, Q., KUMAR, S., MUTLU, O. “Studi skala besar tentang kegagalan memori flash di lapangan.” Dalam Prosiding Konferensi Internasional ACM SIGMETRICS 2015 tentang Pengukuran dan Pemodelan Sistem Komputer, New York, 2015, SIGMETRICS '15, ACM, hlm. 177–190 ) Ini dan penelitian kami saling melengkapi, karena mereka tumpang tindih sangat sedikit.
Data survei Facebook terdiri dari satu pandangan cepat pada armada media flash, yang terdiri dari disk yang sangat muda (dalam hal penggunaannya dibandingkan dengan batas nilai siklus PE), dan berisi informasi hanya tentang kesalahan yang tidak dapat diperbaiki, sementara penelitian kami didasarkan pada , , , , (MLC, eMLC, SLC). , .
, Facebook (, , DRAM), .
, :
- Facebook , . « » , « » « », . , « », , Facebook ( PE , PE ). ;
- Facebook , . , , , RBER .
10.
, - . , . , .
- 20 — 63% , – 6 1000 .
- , , . . , , .
- , RBER , . , RBER .
- , UBER , UE . - .
- RBER, PE, , , , , PE, .
- , , , , , , , .
- SLC, , , MLC, SSD-.
- , RBER, , , .
- , SSD , HDD, , , , .
- . , .
- : , 30-80% 2-7% . () , .
- , , , , , (, , ). , , .
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada server entry-level analog unik yang kami ciptakan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps mulai dari $ 20 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?