Sepertinya saya memiliki kebiasaan menulis tentang
mesin yang kuat , di mana banyak core
menganggur karena kunci yang salah. Jadi ... Ya. Lagi tentang itu.
Kisah ini sangat mengesankan. Bahkan, seberapa sering Anda memiliki satu putaran benang selama beberapa detik dalam siklus tujuh perintah, memegang kunci yang menghentikan pekerjaan 63 prosesor lainnya? Ini luar biasa, dalam arti yang mengerikan.
Bertentangan dengan kepercayaan umum, saya sebenarnya tidak memiliki mesin dengan 64 prosesor logis, dan saya belum pernah melihat masalah khusus ini. Tetapi teman saya menabraknya,
kutu buku ini mengaitkan saya, dia meminta bantuan, dan saya memutuskan bahwa masalahnya cukup menarik. Dia mengirim
jejak ETW dengan informasi yang cukup sehingga pikiran kolektif di Twitter dengan cepat menyelesaikan masalah.
Keluhan teman itu cukup sederhana: dia mengumpulkan bangunan menggunakan
ninja . Biasanya, ninja melakukan pekerjaan yang sangat baik untuk meningkatkan beban, terus mendukung proses n + 2 untuk menghindari downtime. Tapi di sini penggunaan CPU dalam 17 detik pertama perakitan terlihat seperti ini:

Jika Anda melihat lebih dekat (lelucon), Anda dapat melihat garis tipis di mana total beban CPU turun dari 100% menjadi 0% dalam beberapa detik. Hanya dalam setengah detik, beban dikurangi dari 64 menjadi dua atau tiga utas. Berikut adalah fragmen yang diperbesar dari salah satu jatuh ini - detik ditandai di sepanjang sumbu horizontal:
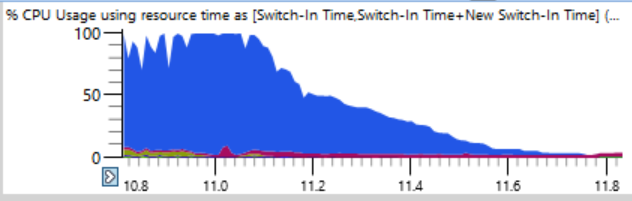
Pikiran pertama adalah bahwa ninja tidak dapat dengan cepat membuat proses. Saya telah melihat ini berkali-kali, biasanya karena intervensi perangkat lunak antivirus. Tetapi ketika saya mengurutkan grafik pada akhir waktu, saya menemukan bahwa selama crash seperti itu tidak ada proses yang diselesaikan, jadi ninja tidak bisa disalahkan.
Tabel
Penggunaan CPU (Precise) sangat ideal untuk mengidentifikasi penyebab downtime. Log semua sakelar konteks disimpan di sana, termasuk catatan akurat dari setiap permulaan aliran, termasuk tempat dan batas waktu.
Kuncinya adalah bahwa tidak ada yang salah dengan downtime. Masalah muncul ketika kita benar-benar ingin utas untuk melakukan pekerjaan, tetapi sebaliknya itu menganggur. Karena itu, Anda perlu memilih saat-saat downtime tertentu.
Saat menganalisis, penting untuk memahami bahwa pengalihan konteks terjadi ketika utas melanjutkan operasi. Jika kita melihat tempat-tempat itu ketika beban prosesor mulai turun, kita tidak akan menemukan apa pun. Sebagai gantinya, fokuslah pada saat sistem mulai bekerja kembali. Fase jejak ini bahkan lebih dramatis. Sementara penurunan beban CPU membutuhkan waktu setengah detik, proses kebalikan dari satu utas yang digunakan menjadi beban penuh hanya membutuhkan waktu dua belas milidetik! Grafik di bawah ini cukup diperbesar, namun transisi dari idle ke load hampir merupakan garis vertikal:

Saya memperbesar menjadi dua belas milidetik dan menemukan 500 switch konteks, analisis yang cermat diperlukan di sini.
Tabel saklar konteks memiliki banyak kolom yang telah saya
dokumentasikan di sini . Ketika suatu proses membeku, untuk menemukan alasannya, saya melakukan pengelompokan berdasarkan proses baru, utas baru, tumpukan utas baru, dll. (
Dibahas di sini ), tetapi ini tidak bekerja pada ratusan proses yang terhenti. Jika saya mempelajari salah satu proses yang salah, jelas bahwa itu disiapkan oleh proses sebelumnya, yang disiapkan oleh yang sebelumnya, dan saya akan memindai rantai panjang untuk menemukan tautan pertama yang (mungkin) memegang kunci penting untuk waktu yang lama.
Jadi, saya mencoba tata letak kolom yang berbeda dalam program:
- Waktu Switch-In (ketika perpindahan konteks terjadi)
- Proses Mempersiapkan (yang melepaskan kunci setelah menunggu)
- Proses Baru (yang mulai bekerja)
- Waktu Sejak Terakhir (berapa lama proses baru telah menunggu)
Ini memberikan daftar sakelar konteks yang disusun berdasarkan waktu dengan catatan siapa yang menyiapkan siapa dan berapa lama proses siap untuk bekerja.
Ternyata ini sudah cukup. Tabel di bawah berbicara sendiri jika Anda tahu cara membacanya. Beberapa sakelar konteks pertama tidak menarik, karena waktu tunggu untuk proses baru (Waktu Sejak Terakhir) cukup kecil, tetapi pada baris yang disorot (# 4) hal yang menarik dimulai:
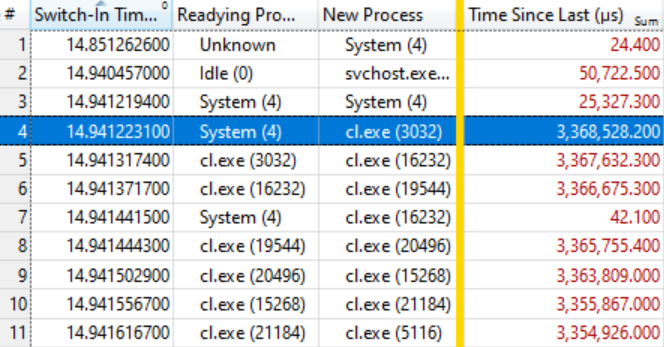
Baris ini mengatakan bahwa
System (4) menyiapkan
cl. Exe (3032) , yang menunggu 3,368 detik. Baris berikutnya mengatakan bahwa dalam waktu kurang dari 0,1 ms,
kr. Exe (3032) menyiapkan
cl.exe (16232) , yang menunggu 3,367 detik. Dan sebagainya.
Beberapa sakelar konteks, seperti pada baris # 7, tidak termasuk dalam rantai tunggu, tetapi hanya mencerminkan pekerjaan lain dalam sistem, tetapi secara umum rantai tersebut direntangkan ke banyak elemen.
Ini berarti bahwa semua proses ini menunggu pelepasan kunci yang sama. Ketika proses
Sistem (4) melepaskan kunci (setelah menahan selama 3.368 detik!), Proses menunggu, pada gilirannya, menangkapnya, melakukan pekerjaan kecil mereka dan meneruskan kunci. Antrian tunggu memiliki sekitar seratus proses, yang menunjukkan tingkat pengaruh satu kunci.
Sebuah studi kecil tentang
Ready Thread Stacks menunjukkan bahwa sebagian besar harapan berasal dari
KernelBase.dllWriteFile . Saya meminta WPA untuk menampilkan penelepon fungsi ini, dengan pengelompokan. Di sana Anda dapat melihat bahwa dalam 12 milidetik dari katarsis ini 174 utas keluar dari
WriteFile menunggu, dan mereka menunggu rata-rata 1.184 detik:
 174 utas menunggu WriteFile, waktu tunggu rata-rata 1.184 detik
174 utas menunggu WriteFile, waktu tunggu rata-rata 1.184 detikIni adalah kelambatan yang luar biasa, dan pada kenyataannya, bahkan tidak seluruh masalah, karena banyak utas dari fungsi lain, seperti
KernelBase.dll! GetQueuedCompletionStatus, mengharapkan rilis kunci yang sama.
Apa yang Sistem Lakukan (4)
Pada titik ini, saya tahu bahwa perkembangan build terhenti karena semua proses compiler dan yang lain mengharapkan
WriteFile , karena
System (4) memegang kunci. Kolom
Id Thread Ready lainnya menunjukkan bahwa thread 3276 melepaskan kunci dalam proses sistem.
Selama semua "hang" rakitan, thread 3276 adalah 100% dimuat, jadi jelas bahwa ia melakukan beberapa pekerjaan pada CPU sambil memegang kunci. Untuk mengetahui di mana waktu CPU dihabiskan, mari kita lihat
grafik Penggunaan CPU (Sampel) untuk thread 3276. Data penggunaan CPU secara mengejutkan jelas. Hampir sepanjang waktu dibutuhkan kerja satu fungsi
ntoskrnl.exe! RtlFindNextForwardRunClear (jumlah sampel ditunjukkan dalam kolom dengan angka):
 Tumpukan panggilan mengarah ke ntoskrnl.exe! RtlFindNextForwardRunClear
Tumpukan panggilan mengarah ke ntoskrnl.exe! RtlFindNextForwardRunClearMelihat tumpukan utas
Readying Thread Id mengkonfirmasi bahwa
NtfsCheckpointVolume melepaskan kunci setelah 3,368 s:
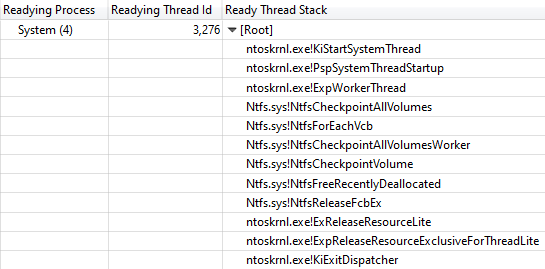 Panggil Stack dari NtfsCheckpointVolume ke ExReleaseResourceLite
Panggil Stack dari NtfsCheckpointVolume ke ExReleaseResourceLitePada saat ini, bagi saya sepertinya sudah waktunya untuk menggunakan pengetahuan yang kaya dari pengikut saya di Twitter, jadi saya memposting
pertanyaan ini dan menunjukkan tumpukan panggilan penuh. Tweet dengan pertanyaan seperti itu bisa sangat efektif jika Anda memberikan informasi yang cukup.
Dalam hal ini,
jawaban yang tepat dari
Caitlin Gadd datang dengan sangat cepat, bersama dengan banyak saran hebat lainnya. Dia mematikan fitur pemulihan sistem - dan tiba-tiba bangunannya dua atau tiga kali lebih cepat!
Tapi tunggu, lebih jauh lebih baik
Memblokir eksekusi di seluruh sistem selama 3+ detik cukup mengesankan, tetapi situasinya bahkan lebih mengesankan jika Anda menambahkan kolom
Alamat ke tabel
Penggunaan CPU (Sampel) dan mengurutkannya. Ini menunjukkan di mana tepatnya di sampel
RtlFindNextForwardRunClear dapatkan - dan 99% di antaranya jatuh pada satu instruksi!

Saya mengambil file
ntoskrnl.exe dan
ntkrnlmp.pdb (versi yang sama dengan teman saya) dan menjalankan
dumpbin /disasm untuk melihat fungsi yang diminati assembler. Digit pertama dari alamat berbeda karena kode bergerak saat boot, tetapi empat nilai hex terakhir adalah sama (tidak berubah setelah ASLR):
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx
140064652: 73 0F jae 0000000140064663
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663
140064659: 49 83 C0 04 tambahkan r8.4
14006465D: 41 83 C1 20 tambahkan r9d, 20j
140064661: EB EC jmp 000000014006464F
...
Kita melihat bahwa instruksi pada ... 4657 termasuk dalam siklus tujuh instruksi, yang ditemukan dalam sampel lain. Jumlah sampel tersebut ditunjukkan di sebelah kanan:
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx 4
140064652: 73 0F jae 0000000140064663 41
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663 7498
140064659: 49 83 C0 04 tambahkan r8.4 2
14006465D: 41 83 C1 20 tambahkan r9d, 20h 1
140064661: EB EC jmp 000000014006464F 1
...
Sebagai latihan untuk pembaca, mari kita tinggalkan interpretasi jumlah sampel pada prosesor superscalar dengan pelaksanaan instruksi yang luar biasa, meskipun beberapa ide bagus dapat ditemukan dalam
artikel ini . Dalam hal ini, kami memiliki AMD Ryzen Threadripper 2990WX 32-core. Rupanya, fungsi prosesor dari Micro-Up Fusion dengan pelaksanaan lima instruksi pada suatu waktu sebenarnya memungkinkan setiap siklus diselesaikan pada jne, karena instruksi setelah instruksi yang paling mahal masuk ke dalam sebagian besar gangguan dalam pemilihan.
Jadi ternyata sebuah mesin dengan 64 prosesor logis berhenti dalam siklus tujuh perintah dalam proses sistem, sambil memegang kunci NTFS yang vital, yang diperbaiki dengan menonaktifkan pemulihan sistem.
Coda
Tidak jelas mengapa kode ini berperilaku buruk pada mesin khusus ini. Saya kira ini terkait dengan distribusi data pada disk 2 TB yang hampir kosong. Ketika pemulihan sistem dihidupkan kembali, masalahnya juga kembali, tetapi tidak begitu parah. Mungkin ada semacam patologi untuk disk dengan fragmen besar ruang kosong?
Pengikut lain di Twitter menyebutkan bug Volume Shadow Copy dari Windows 7, yang memungkinkan
eksekusi selama O (n ^ 2) . Kesalahan ini diduga diperbaiki di Windows 8, tetapi mungkin telah dipertahankan dalam beberapa bentuk. Jejak stack saya dengan jelas menunjukkan bahwa
VspUpperFindNextForwardRunClearLimited (menemukan bit yang digunakan di area 16 megabyte ini) memanggil
VspUpperFindNextForwardRunClear (mencari bit yang digunakan berikutnya di mana saja, tetapi tidak mengembalikannya jika berada di luar area yang ditentukan). Tentu saja, ini menyebabkan rasa deja vu. Seperti yang
baru-baru ini saya
katakan , O (n ^ 2) adalah titik lemah dari algoritma yang tidak dapat diukur. Dua faktor bertepatan di sini: kode semacam itu cukup cepat untuk masuk ke produksi, tetapi cukup lambat untuk menghentikan produksi ini.
Ada laporan bahwa masalah serupa terjadi dengan
penghapusan file besar -
besaran , tetapi penelusuran kami tidak menunjukkan banyak penghapusan, jadi masalahnya, ternyata, bukan itu.
Sebagai kesimpulan, saya akan menduplikasi jadwal beban CPU di seluruh sistem dari awal artikel, tetapi kali ini menunjukkan penggunaan CPU oleh proses masalah
Sistem (berwarna hijau di bawah). Dalam gambaran seperti itu, masalahnya sangat jelas. Proses sistem secara teknis terlihat pada grafik atas, tetapi pada skala ini mudah untuk dilewatkan.
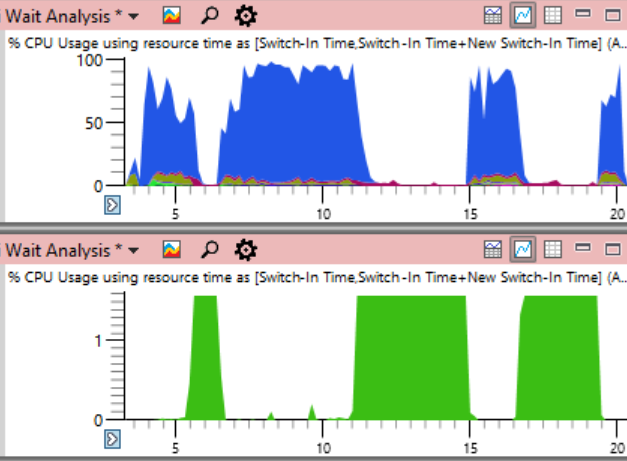
Meskipun masalah terlihat jelas pada grafik, sebenarnya tidak membuktikan apa-apa.
Seperti yang mereka katakan , korelasi bukanlah hubungan sebab akibat. Hanya analisis peristiwa pengalihan konteks yang menunjukkan bahwa streaming inilah yang memegang kunci kritis - dan kemudian Anda dapat yakin bahwa kami telah menemukan penyebab sebenarnya, dan bukan hanya korelasi acak.
Pertanyaan
Seperti biasa, saya mengakhiri penyelidikan ini dengan
panggilan untuk memberi nama thread yang lebih baik . Proses sistem memiliki lusinan utas, banyak di antaranya memiliki tujuan khusus, dan tidak ada yang memiliki nama. Utas sistem tersibuk dalam penelusuran ini adalah
MiZeroPageThread . Saya berulang kali terjun ke tumpukannya, dan setiap kali saya ingat itu tidak menarik. Kompilator VC ++ juga tidak memberi nama utasnya. Tidak perlu banyak waktu untuk mengubah nama aliran, dan ini sangat berguna. Berikan saja namanya.
Sederhana saja . Chromium bahkan menyertakan alat untuk
mencantumkan nama aliran dalam suatu proses .
Jika seseorang dari tim NTFS di Microsoft ingin membicarakan topik ini, beri tahu saya, dan saya dapat menghubungkan Anda dengan penulis laporan asli dan memberikan jejak ETW.
Referensi