
Halo, Habr! Kami terus mempublikasikan ulasan artikel ilmiah dari anggota komunitas Open Data Science dari saluran #article_essense. Jika Anda ingin menerimanya sebelum orang lain - bergabunglah dengan komunitas !
Artikel untuk hari ini:
- Rotasi lapisan: indikator generalisasi yang sangat kuat di jaringan yang dalam? (Université catholique de Louvain, Belgia, 2018)
- Pembelajaran Transfer Parameter-Efisien untuk NLP (Google Research, Jagiellonian University, 2019)
- RoBERTa: Pendekatan Pretraining BERT Dioptimalkan Kuat (University of Washington, Facebook AI, 2019)
- EfficientNet: Memikirkan Kembali Penskalaan Model untuk Jaringan Syaraf Konvolusional (Google Research, 2019)
- Bagaimana Transisi Otak dari Sadar ke Persepsi Subliminal (AS, Argentina, Spanyol, 2019)
- Lapisan Memori Besar dengan Kunci Produk (Facebook AI Research, 2019)
- Apakah Kita Benar-Benar Membuat Banyak Kemajuan? Analisis Khawatir tentang Pendekatan Rekomendasi Saraf Baru (Politecnico di Milano, University of Klagenfurt, 2019)
- Pembelajaran Fitur Omni-Skala untuk Identifikasi Ulang Orang (University of Surrey, Universitas Queen Mary, Samsung AI, 2019)
- Reparameterisasi saraf meningkatkan optimisasi struktural (Google Research, 2019)
Tautan ke koleksi seri terakhir: 1. Rotasi layer: indikator generalisasi yang sangat kuat di jaringan yang dalam?
Penulis: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Belgia, 2018)
→ Artikel asli
Penulis ulasan: Svyatoslav Skoblov (dalam slack error_derivative)

Dalam artikel ini, penulis menarik perhatian pada pengamatan yang agak sederhana: jarak kosinus antara bobot lapisan selama inisialisasi dan setelah pelatihan (proses peningkatan jarak selama pelatihan disebut rotasi lapisan). Tuan-tuan mengatakan bahwa dalam sebagian besar percobaan, jaringan yang telah mencapai jarak 1 di semua lapisan secara konsisten unggul dalam akurasi dibandingkan konfigurasi lainnya. Makalah ini juga menyajikan algoritma Layca (Level-Controlled Controlled Amount of the Weight Rotation ), yang memungkinkan penggunaan tingkat pembelajaran layer-wise ini untuk mengontrol rotasi layer yang sama ini. Bahkan, itu berbeda dari algoritma SGD yang biasa dengan adanya proyeksi dan normalisasi ortogonal. Daftar rinci dari algoritma bersama dengan skema pelatihan dapat ditemukan di artikel.
Gagasan utama yang penulis simpulkan adalah: semakin besar rotasi lapisan, semakin baik kinerja generalisasi . Sebagian besar artikel adalah catatan percobaan di mana berbagai skenario pelatihan dipelajari: MNIST, CIFAR-10 / CIFAR-100, ImageNet kecil dengan arsitektur yang berbeda digunakan, dari jaringan single-layer ke keluarga ResNet.
Serangkaian percobaan dipecah menjadi beberapa tahap:
- Vanilla SGD Ternyata , secara keseluruhan, perilaku timbangan bertepatan dengan hipotesis (perubahan besar dalam jarak sesuai dengan nilai metrik terbaik), namun, masalah juga diperhatikan: rotasi lapisan berhenti jauh sebelum nilai yang diinginkan; ketidakstabilan dalam mengubah jarak juga diperhatikan.
- SGD + penurunan berat badan Penurunan norma berat sangat meningkatkan gambar pelatihan: sebagian besar lapisan mencapai jarak maksimum, dan kinerja tes mirip dengan Layca yang diusulkan. Keuntungan yang tidak diragukan dari metode penulis adalah kurangnya hyperparameter tambahan.
- Pemanasan LR Ternyata pemanasan membantu SGD mengatasi masalah rotasi lapisan yang tidak stabil, namun tidak berpengaruh pada Layca.
- Metode Gradien Adaptif Selain kebenaran yang terkenal (bahwa menggunakan metode ini lebih sulit untuk mencapai tingkat generalisasi yang dapat diberikan oleh pembusukan SGD + berat), ternyata efek rotasi lapisan sangat berbeda: peningkatan rotasi pertama pada lapisan terakhir, sedangkan SGD pada lapisan awal . Para penulis mengisyaratkan bahwa ini mungkin kekejaman dari metode adaptif. Dan mereka menyarankan menggunakan Layca bersama dengan mereka (meningkatkan kemampuan untuk menggeneralisasi dalam metode adaptif dan mempercepat pembelajaran dalam SGD).
Artikel diakhiri dengan upaya untuk menafsirkan fenomena tersebut. Untuk melakukan ini, penulis melatih jaringan dengan 1 lapisan tersembunyi pada versi MNIST yang dipreteli, setelah itu mereka memvisualisasikan neuron acak, mencapai kesimpulan yang cukup logis: derajat rotasi lapisan yang lebih besar sesuai dengan efek inisialisasi yang lebih rendah dan studi fitur yang lebih baik, yang berkontribusi pada peningkatan generalisasi.
Kode algoritma yang diterapkan (tf / keras) dan kode untuk eksperimen mereproduksi diunggah .
2. Transfer Transfer Parameter-Efisien untuk NLP
Penulis artikel: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Google Research, Jagiellonian University, 2019)
→ Artikel asli
Penulis ulasan: Alexey Karnachev (in slack zhirzemli)
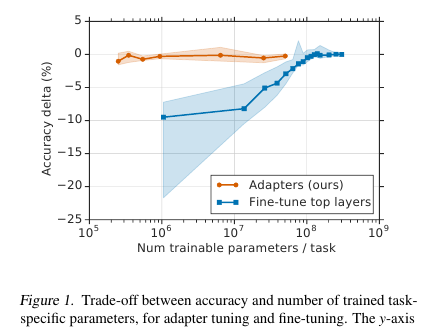
Di sini pria menawarkan teknik fine-tuning yang sederhana namun efektif untuk model NLP (dalam hal ini, BERT). Idenya adalah untuk menanamkan lapisan pembelajaran (adapter) langsung ke jaringan. Setiap lapisan tersebut adalah jaringan dengan bottleneck, yang mengadaptasi status laten dari model asli ke tugas hilir spesifik. Berat dari model asli, pada gilirannya, tetap beku.
Motivasi
Dalam kondisi pelatihan streaming (atau pelatihan dekat-online), di mana ada banyak tugas hilir, saya tidak benar-benar ingin mengajukan seluruh model. Pertama, untuk waktu yang lama, dan kedua, itu sulit, dan ketiga, bahkan jika itu ketat, model perlu disimpan entah bagaimana: untuk dibuang atau disimpan dalam memori. Dan kita tidak akan dapat menggunakan kembali model ini untuk tugas berikut: setiap kali kita harus mencari cara baru. Sebagai hasilnya, kita dapat mencoba untuk menyesuaikan status jaringan tersembunyi dengan masalah saat ini. Selain itu, model asli tetap tidak tersentuh, dan adaptor itu sendiri jauh lebih luas daripada model utama (~ 4% dari total jumlah parameter)
Implementasi
Masalahnya diselesaikan dengan cara yang sangat sederhana: kami menambahkan 2 adapter ke setiap lapisan model. Sebelum normalisasi lapisan dalam model berbasis transformator, terjadi skip-koneksi: input yang diubah (kondisi tersembunyi saat ini) ditambahkan ke input asli.
Ada 2 bagian seperti itu di setiap lapisan transformator, satu setelah multi-head attention, yang kedua setelah umpan maju. Dengan demikian, keadaan tersembunyi dari bagian-bagian ini juga dilewatkan melalui Adaptor: jaringan dangkal dengan lapisan tersembunyi 1-bottleneck dan dengan output dimensi yang sama dengan input. Nonlinier diterapkan pada status bottleneck, dan Input (lewati-koneksi) ditambahkan ke output. Ternyata jumlah total parameter terlatih adalah: 2md + m + d, di mana d adalah dimensi keadaan tersembunyi dari model asli, m adalah ukuran lapisan adaptor bottleneck. Ternyata untuk model BERT-base (12 layer, parameter 110M) dan untuk ukuran bottlneck'a 128 adaptor, kami mendapatkan 4,3% dari total jumlah parameter
Hasil
Perbandingan dibuat dengan penyetelan model penuh. Untuk semua tugas, pendekatan ini menunjukkan kerugian kecil dalam metrik (rata-rata kurang dari 1 poin), dengan jumlah bobot yang terlatih - 3% dari total. Saya tidak akan mencantumkan tugasnya sendiri, ada banyak di antaranya, ada tablet di artikel.
Penyetelan yang bagus
Dalam model ini, hanya bagian Adaptor yang disetel (+ pengklasifikasi keluaran itu sendiri). Untuk skala adaptor, mereka mengusulkan untuk melakukan inisialisasi identitas dekat. Dengan demikian, model yang tidak terlatih tidak akan mengubah status jaringan tersembunyi dengan cara apa pun, dan ini akan memungkinkan dalam proses pelatihan model untuk memutuskan negara mana yang akan beradaptasi untuk tugas tersebut dan yang tidak berubah.
Tingkat pembelajaran merekomendasikan mengambil lebih banyak daripada dengan finetuning BERT standar. Secara pribadi, pada tugas saya, 1e-04 lr bekerja dengan baik. Selain itu, (sudah pengamatan saya pribadi) selama proses tuning, model hampir selalu meledak gradien, jadi Anda harus ingat untuk melakukan kliping. Pengoptimal - Adam dengan pemanasan 10%
Kode
Kode dalam artikel mereka terlampir. Implementasi pada Tensorflow .
Untuk Torch, penulis ulasan bercabang pytorch-transformers dan menambahkan lapisan Adaptor (pada awal file README.md ada manual peluncuran kecil)
3. RoBERTa: Pendekatan Pretraining BERT yang Dioptimalkan dengan Kuat
Penulis artikel: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (Universitas Washington, Facebook AI, 2019)
→ Artikel asli
Penulis ulasan: Artem Rodichev (in slack fuckai)
Secara dramatis meningkatkan kualitas model BERT, tempat pertama di papan peringkat GLUE dan SOTA pada banyak tugas NLP. Mereka menyarankan sejumlah cara untuk melatih model BERT sebaik mungkin tanpa ada perubahan pada arsitektur model itu sendiri.
Perbedaan utama dengan BERT asli:
- Bangunan kereta meningkat 10 kali, dari 16 GB teks mentah menjadi 160 GB
- Membuat masking dinamis untuk setiap sampel
- Dihapus penggunaan kalimat berikutnya prediksi kerugian
- Meningkatkan ukuran mini-batch dari 256 sampel menjadi 8k
- Peningkatan pengkodean BPE dengan menerjemahkan database dari Unicode ke byte.
Model final terbaik dilatih pada 1024 kartu Nvidia V100 (128 server DGX-1) selama 5 hari.
Inti dari pendekatan:
Data Selain cangkang Wiki dan BookCorpus (total 16GB), yang mengajarkan BERT asli, mereka menambahkan 3 cangkang lebih besar, semuanya dalam bahasa Inggris:
- SS-News 63 juta berita dalam 2,5 tahun pada 76GB
- OpenWebText adalah kerangka kerja di mana OpenAI diajarkan model GPT2. Ini adalah artikel yang dirayapi dengan tautan yang diberikan dalam posting di reddit dengan setidaknya tiga pembaruan. Data 38GB
- Cerita - 31GB CommonCrawl Story Case
Masking dinamis. Dalam BERT asli, 15% token disembunyikan di setiap sampel dan token ini diprediksi menggunakan bagian kedok dari urutan tersebut. Topeng dihasilkan untuk setiap sampel satu kali selama preprocessing dan tidak berubah. Pada saat yang sama, sampel yang sama di kereta dapat terjadi beberapa kali, tergantung pada jumlah era dalam tubuh. Gagasan masking dinamis adalah membuat topeng baru untuk urutan setiap kali, daripada menggunakan topeng tetap dalam preprocessing.
Tujuan Prediksi Kalimat Berikutnya. Mari kita potong objektiv ini dan lihat apakah ini memburuk? Apakah menjadi lebih baik atau tetap - pada tugas SQuAD, MNLI, SST dan RACE.
Tambah ukuran mini-batch. Banyak tempat, khususnya dalam Terjemahan Mesin, menunjukkan bahwa semakin besar mini-batch, semakin baik hasil akhir kereta. Mereka menunjukkan bahwa jika Anda meningkatkan minibatch dari 256 sampel, seperti pada BERT asli, menjadi 2k, dan kemudian ke 8k, maka kebingungan pada tetes validasi, dan metrik pada MNLI dan SST-2 bertambah.
BPE BPE dari implementasi BERT asli menggunakan karakter Unicode sebagai dasar untuk unit kata kunci. Ini mengarah pada fakta bahwa pada kasus yang besar dan beragam, sebagian besar kamus akan ditempati oleh masing-masing karakter Unicode. OpenAI kembali di GPT2 disarankan menggunakan bukan karakter Unicode, tetapi byte sebagai basis untuk subwords. Jika kami menggunakan kamus BPE 50k, maka kami tidak akan memiliki token yang tidak dikenal. Dibandingkan dengan BERT asli, ukuran model telah tumbuh sebesar 15 juta parameter untuk model dasar dan 20 juta untuk ukuran besar, yaitu 5-10% lebih banyak.
Hasil:
BERT-large dan XLNet-large digunakan sebagai model untuk perbandingan. RoBERTa sendiri memiliki parameter yang sama dengan BERT-besar, sehingga mereka memenangkan tempat pertama pada benchmark GLUE. Kami menggunakan penyetelan file satu-tugas, tidak seperti banyak pendekatan lain dari tolok ukur GLUE yang melakukan penyetelan file multi-tugas. Pada gadis-gadis di GLUE, hasil model tunggal dibandingkan, mereka mendapat SOTA di semua 9 tugas. Pada set tes, ansambel model dibandingkan, SOTA untuk 4 dari 9 tugas dan kecepatan lem akhir. Pada dua versi SQuAD pada jaringan dev SOTA, pada uji yang ditetapkan di tingkat XLNet. Selain itu, tidak seperti XLNet, mereka tidak terjebak pada paket QA tambahan sebelum menyelesaikan SQuAD.

SOTA pada tugas RACE di mana sepotong teks diberikan, pertanyaan tentang teks ini dan 4 opsi jawaban di mana Anda harus memilih yang tepat. Untuk menyelesaikan tugas ini, mereka menggabungkan teks, tanya jawab, jalankan melalui BERT, dapatkan representasi dari token CLF, berlaku untuk satu lapisan yang terhubung sepenuhnya dan memprediksi apakah jawabannya benar. Ini dilakukan 4 kali - untuk masing-masing opsi jawaban.
Kami memposting kode dan pra-uji model RoBERTa di fairseq lobak . Anda bisa menggunakannya, semuanya terlihat rapi dan sederhana.
4. EfficientNet: Memikirkan Kembali Model Scaling untuk Jaringan Syaraf Konvolusional
Penulis: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Artikel asli
Ulasan penulis: Alexander Denisenko (in slack Alexander Denisenko)

Mereka mempelajari penskalaan (penskalaan) model dan menyeimbangkan antara mereka sendiri kedalaman dan lebar (jumlah saluran) dari jaringan, serta resolusi gambar dalam grid. Mereka menawarkan metode penskalaan baru yang secara seragam mengukur kedalaman / lebar / resolusi. Tunjukkan efektivitasnya di MobileNet dan ResNet.
Mereka juga menggunakan Pencarian Arsitektur Neural untuk membuat mesh baru dan skala itu, sehingga memperoleh kelas model baru - EfficientNets. Mereka lebih baik dan jauh lebih ekonomis daripada jaringan sebelumnya. Di ImageNet, EfficientNet-B7 mencapai 84,4% top-1 dan 97,1% top-5 yang canggih, menjadi 8,4 kali lebih sedikit dan 6,1 kali lebih cepat pada inferensi daripada ConvNet terbaik saat ini di kelasnya. Ini mentransfer dengan baik ke dataset lain - mereka mendapat SOTA pada 5 dari 8 dataset paling populer.
Penskalaan model majemuk
Penskalaan adalah ketika operasi yang dilakukan di dalam grid diperbaiki dan hanya kedalaman (jumlah pengulangan modul yang sama) d, lebar (jumlah saluran dalam konvolusi) dengan resolusi r yang diubah. Dalam pager, penskalaan dirumuskan sebagai masalah pengoptimalan - kami menginginkan Akurasi maksimum (Net (d, w, r)) meskipun kami tidak merangkak keluar dari memori dan FLOPS.
Kami melakukan percobaan dan memastikan bahwa itu benar-benar membantu juga untuk mengukur kedalaman dan resolusi saat penskalaan lebar. Dengan FLOPS yang sama, kami mencapai hasil yang jauh lebih baik di ImageNet (lihat gambar di atas). Secara umum, ini masuk akal, karena tampaknya dengan peningkatan resolusi gambar jaringan, lebih banyak lapisan diperlukan secara mendalam untuk meningkatkan bidang reseptif dan lebih banyak saluran untuk menangkap semua pola dalam gambar dengan resolusi yang lebih tinggi.
Inti dari penskalaan senyawa: kita ambil koefisien senyawa phi, yang secara merata mengukur d, w dan r dengan koefisien ini: dimana - konstanta yang diperoleh dari tampilan grid kecil pada grid sumber. - Koefisien yang mencirikan jumlah sumber daya komputasi yang tersedia.
Net yang efisien
Untuk membuat kisi-kisi, kami menggunakan pencarian arsitektur multi-objektif, dioptimalkan Akurasi dan FLOPS dengan parameter yang bertanggung jawab untuk trade-off di antara mereka. Pencarian seperti itu memberi EfficientNet-B0. Singkatnya - Conv diikuti oleh beberapa MBConv, di akhir Conv1x1, Pool, FC.
Kemudian lakukan penskalaan dalam dua langkah:
- Untuk memulai, kami perbaiki , lakukan pencarian kotak untuk pencarian .
- Skala grid menggunakan rumus untuk d, w dan r. Mendapat EffiientNet-B1. Begitu pula bertambah , dapatkan EfficientNet-B2, ... B7.
Dengan skala berbeda untuk ResNet dan MobileNet, di mana-mana menerima peningkatan signifikan pada ImageNet, penskalaan majemuk memberikan peningkatan yang signifikan dibandingkan penskalaan hanya dalam satu dimensi. Kami juga melakukan percobaan dengan EfficientNet pada delapan dataset lebih populer, di mana pun kami mendapatkan SOTA atau hasilnya mendekati itu dengan jumlah parameter yang jauh lebih kecil.
Kode
5. Bagaimana Transisi Otak dari Sadar ke Persepsi Subliminal
Penulis artikel: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (AS, Argentina, Spanyol, 2019)
→ Artikel asli
Penulis ulasan: Svyatoslav Skoblov (dalam slack error_derivative)
Artikel ini adalah kelanjutan dan pemikiran ulang dari karya Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB, & Rivie`re, D. Mekanisme kata kunci dari penyembunyian kata dan pengulangan priming , di dimana penulis mencoba untuk mempertimbangkan mode fungsi otak sadar dan tidak sadar.
Eksperimen:
Relawan ditampilkan gambar (kata-kata 4 huruf, atau layar kosong, atau coretan). Masing-masing ditampilkan selama 30 ms, secara umum, seluruh tindakan berlangsung 5 menit.
- Dalam mode "sadar" percobaan, layar kosong berganti dengan kata-kata, yang memungkinkan seseorang untuk secara sadar memahami teks.
- Dalam mode "bawah sadar", kata-kata bergantian dengan coretan, yang cukup efektif mengganggu persepsi teks pada tingkat sadar.
Data:
Selama presentasi ini, otak primata kami dipindai menggunakan fMRI. Secara total, para peneliti memiliki 15 sukarelawan, masing-masing mengulangi percobaan 5 kali, total 75 aliran fMRI. Perlu dicatat bahwa pemindaian voxel ternyata cukup besar (sangat disederhanakan: voxel adalah kubus 3D yang mengandung jumlah sel yang cukup besar) - 4x4x4mm.
Keajaiban:
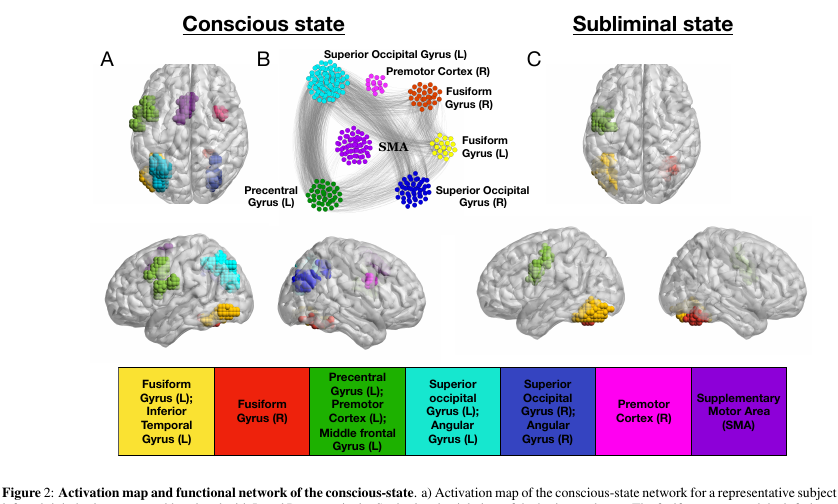
Mari kita panggil simpul aktif voxel dari aliran kita. Karena otak adalah kain lap modular, kami memperkenalkan dua jenis koneksi di dalamnya: eksternal dan internal (sesuai dengan pengaturan spasial node). Koneksi dirangkai dengan cara yang menarik: kami membangun matriks korelasi silang antara node dan menghubungkan node dengan koneksi jika korelasinya lebih besar dari beberapa parameter adaptif lambda. Parameter ini memengaruhi keluarnya jaringan kami.
Penyesuaian parameter dilakukan menggunakan prosedur "penyaringan". Jika kita sedikit goyang lambda kita, transisi yang tajam antara dimensi akhir jaringan menjadi terlihat (yaitu, perubahan parameter yang cukup kecil sesuai dengan peningkatan besar dalam ukuran).
Jadi: koneksi internal diaktifkan oleh nilai lambda-1, yang sesuai dengan nilai lambda tepat sebelum transisi yang tajam. Eksternal - nilai lambda-2 yang sesuai dengan nilai lambda segera setelah transisi yang tajam.
Keajaiban 2:
penyaringan k-core. Konsep k-core menggambarkan konektivitas jaringan dan dirumuskan cukup sederhana: subnet maksimum, semua node yang memiliki setidaknya tetangga k. Subnet seperti itu dapat diperoleh dengan menghapus secara berulang node dengan tetangga kurang dari k. Karena node yang tersisa akan kehilangan tetangga, proses berlanjut sampai tidak ada yang dihapus. Yang tersisa adalah jaringan k-core.
Hasil:
Menerapkan artileri ini ke otak kami, Anda dapat melihat sejumlah fitur yang sangat menarik.
- Jumlah node dalam k-core dengan k kecil / sangat besar sangat besar. Tetapi untuk medium k, sebaliknya, itu tidak cukup. Dalam gambar itu terlihat seperti bentuk U, yaitu, konfigurasi jaringan seperti itu memberikan stabilitas terbesar dari sistem (ketahanan terhadap kesalahan lokal dan global).
- dan Nodes yang paling penting milik k-core dengan k kecil dapat dilihat di hampir semua keadaan jaringan. Tetapi inti-k dengan k yang sangat besar adalah karakteristik hanya untuk bagian-bagian otak yang aktif dalam keadaan tidak sadar, fusiform gyrus, & gyrus prekursor kiri . Bagian yang sama dari korteks paling aktif dan dalam keadaan sadar.
Untuk memeriksa hasilnya, penulis membuat sejuta jaringan acak berdasarkan yang asli, melakukan rewiring acak, sambil mempertahankan tingkat asli dari simpul (sama dengan tingkat simpul dalam grafik). Jaringan nyata berbeda dari yang acak dengan nilai maksimum k yang jauh lebih besar. Pada saat yang sama, bentuk U dari jumlah node dalam cluster tetap terlihat dalam jaringan acak, yang mendorong penulis untuk gagasan bahwa itu adalah derajat dari node yang bertanggung jawab atas fenomena ini.
Kesimpulan:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. Yaitu query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
ReID OSNet ( 2 ) (Market: R1 93.6%, mAP 81.0% OSNet R1 87.0%, mAP 69.5% MobileNetV2) ResNet DenseNet (Market: R1 94.8%, mAP 84.9% OSNet R1 94.8%, mAP 86.0% ResNet).
Tantangan lain adalah adaptasi domain : model yang dilatih pada satu dataset memiliki kualitas yang buruk pada yang lain. OSNet juga menunjukkan hasil yang baik di segmen ini tanpa menggunakan "adaptasi domain tanpa pengawasan" (menggunakan data uji dalam bentuk yang tidak dialokasikan untuk meratakan distribusi data).
Arsitektur juga diuji di ImageNet, di mana ia mencapai akurasi yang sama dengan MobileNetV2 dengan parameter lebih sedikit, tetapi lebih banyak operasi.
9. Neural reparameterization meningkatkan optimasi struktural
Penulis: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Artikel asli
Penulis ulasan: Alexey (di Arech slack)
Dalam konstruksi dan teknologi lainnya, ada tugas mengoptimalkan struktur / topologi beberapa solusi. Secara kasar, ini adalah jawaban komputer untuk pertanyaan seperti, misalnya, bagaimana merancang jembatan / bangunan / sayap pesawat terbang / pisau turbin / blablabla, sehingga batasan tertentu terpenuhi dan strukturnya cukup kuat. Ada satu set metode solusi "standar" - ini berfungsi, tetapi semuanya tidak selalu mulus di sana.
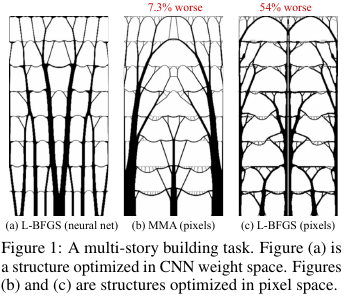
Apa yang orang-orang dari Google ini hasilkan? Mereka berkata: mari kita menghasilkan solusi dengan jaringan saraf (bagian upampling dari UNet), dan kemudian menggunakan model fisik terdiferensiasi, yang akan menghitung perilaku solusi di bawah pengaruh semua kekuatan dan gravitasi, menghitung fungsi tujuan - kekuatan (lebih tepatnya, kebalikannya - kepatuhan) ) desain. Kemudian, karena semuanya terdiferensiasi secara otomatis, kita mendapatkan gradien dari fungsi objektif, yang didorong melalui seluruh struktur kembali ke bobot dan input dari jaringan saraf. Kami mengubah bobot dan entri dan melanjutkan siklus hingga konvergensi ke solusi yang stabil.
Hasilnya ternyata pada masalah kecil (dalam hal ukuran ruang solusi yang mungkin) dibandingkan dengan metode tradisional untuk mengoptimalkan topologi, dan untuk masalah besar, mereka terlihat lebih baik daripada yang tradisional (kelebihan berat badan di 99 banding 66 dari 66 masalah). Selain itu, solusi yang dihasilkan seringkali jauh lebih berteknologi dan optimal daripada keputusan baseline.
Yaitu pada kenyataannya, mereka menggunakan NS sebagai cara yang rumit untuk parameterisasi model fisik struktur, yang secara implisit (berkat arsitektur NS) mampu memaksakan beberapa pembatasan yang berguna pada nilai parameter (dikontrol dengan menghapus NS dari metode dan optimalisasi langsung nilai piksel).
Kode sumber.
Tinjauan yang lebih rinci dari artikel ini di habr.