Kereta Terbang, Afu ChanSaya bekerja di
Mail.ru Cloud Solutons sebagai arsitek dan pengembang, termasuk cloud saya. Diketahui bahwa infrastruktur cloud terdistribusi membutuhkan penyimpanan blok produktif, di mana pengoperasian layanan PaaS dan solusi yang dibangun menggunakannya.
Awalnya, ketika menggunakan infrastruktur seperti itu, kami hanya menggunakan Ceph, tetapi secara bertahap penyimpanan blok berkembang. Kami ingin
basis data , penyimpanan file, dan berbagai layanan kami bekerja pada kinerja maksimum, jadi kami menambahkan penyimpanan lokal dan mengatur pemantauan Ceph tingkat lanjut.
Saya akan memberi tahu Anda bagaimana keadaannya - mungkin kisah ini, masalah yang kami temui, dan solusi kami akan bermanfaat bagi mereka yang juga menggunakan Ceph. Omong-omong,
ini adalah versi video dari laporan ini.
Dari Proses DevOps ke Cloud Anda Sendiri
Praktik DevOps ditujukan untuk meluncurkan produk secepat mungkin:
- Otomatisasi proses - seluruh siklus hidup: perakitan, pengujian, pengiriman ke pengujian dan produktif. Otomatiskan proses secara bertahap, dimulai dengan langkah-langkah kecil.
- Infrastruktur sebagai kode adalah model ketika proses konfigurasi infrastruktur mirip dengan proses pemrograman perangkat lunak. Pertama mereka menguji produk, produk memiliki persyaratan tertentu untuk infrastruktur, dan infrastruktur perlu diuji. Pada tahap ini, keinginan untuk penampilannya, saya ingin "mengubah" infrastruktur - pertama di lingkungan pengujian, kemudian di toko kelontong. Pada tahap pertama, ini dapat dilakukan secara manual, tetapi kemudian mereka beralih ke otomatisasi - ke model "infrastruktur sebagai kode".
- Virtualisasi dan wadah - muncul di perusahaan ketika jelas bahwa Anda perlu menempatkan proses pada jalur industri, meluncurkan fitur baru lebih cepat dengan intervensi manual minimal.
 Arsitektur semua lingkungan virtual serupa: mesin tamu dengan wadah, aplikasi, jaringan publik dan pribadi, penyimpanan.
Arsitektur semua lingkungan virtual serupa: mesin tamu dengan wadah, aplikasi, jaringan publik dan pribadi, penyimpanan.Secara bertahap, semakin banyak layanan yang digunakan dalam infrastruktur virtual yang dibangun di dalam dan di sekitar proses DevOps, dan lingkungan virtual menjadi tidak hanya tes (digunakan untuk pengembangan dan pengujian), tetapi juga produktif.
Sebagai aturan, pada tahap awal mereka dilewati oleh alat otomatisasi dasar yang paling sederhana. Tetapi ketika alat baru tertarik, cepat atau lambat ada kebutuhan untuk menggunakan platform cloud yang lengkap untuk menggunakan alat yang paling canggih seperti Terraform.
Pada tahap ini, infrastruktur virtual dari “hypervisors, networks and storage” berubah menjadi infrastruktur cloud yang lengkap dengan alat dan komponen yang dikembangkan untuk mengatur proses. Kemudian cloud mereka sendiri muncul, di mana proses pengujian dan pengiriman pembaruan otomatis ke layanan yang ada dan penyebaran layanan baru terjadi.
Cara kedua untuk cloud Anda sendiri adalah kebutuhan untuk tidak bergantung pada sumber daya eksternal dan penyedia layanan eksternal, yaitu, memberikan beberapa kemandirian teknis untuk layanan Anda sendiri.
 Cloud pertama terlihat hampir seperti infrastruktur virtual - hypervisor (satu atau beberapa), mesin virtual dengan wadah, penyimpanan bersama: jika Anda membangun cloud bukan berdasarkan solusi eksklusif, biasanya Ceph atau DRBD.
Cloud pertama terlihat hampir seperti infrastruktur virtual - hypervisor (satu atau beberapa), mesin virtual dengan wadah, penyimpanan bersama: jika Anda membangun cloud bukan berdasarkan solusi eksklusif, biasanya Ceph atau DRBD.Ketahanan dan Kinerja Cloud Pribadi
Awan tumbuh, bisnis semakin bergantung padanya, perusahaan mulai menuntut keandalan yang lebih besar.
Di sini, penyebaran ditambahkan ke cloud pribadi, infrastruktur cloud terdistribusi muncul: titik tambahan di mana peralatan berada. Cloud mengelola dua, tiga atau lebih instalasi yang dibangun untuk memberikan solusi toleran-kesalahan.
Pada saat yang sama, data diperlukan dari semua situs, dan ada masalah: dalam satu situs tidak ada penundaan besar dalam transfer data, tetapi antara situs data ditransmisikan lebih lambat.
 Situs instalasi dan penyimpanan umum. Persegi panjang merah adalah hambatan di tingkat jaringan.
Situs instalasi dan penyimpanan umum. Persegi panjang merah adalah hambatan di tingkat jaringan.Bagian eksternal dari infrastruktur dari sudut pandang jaringan manajemen atau jaringan publik tidak begitu sibuk, tetapi pada jaringan internal volume data yang ditransfer jauh lebih besar. Dan dalam sistem terdistribusi, masalah mulai, dinyatakan dalam waktu layanan yang lama. Jika klien datang ke satu grup node penyimpanan, data harus langsung direplikasi ke grup kedua sehingga perubahan tidak hilang.
Untuk beberapa proses, latensi replikasi data dapat diterima, tetapi dalam kasus seperti pemrosesan transaksi, transaksi tidak dapat hilang. Jika replikasi asinkron digunakan, terjadi jeda waktu yang dapat menyebabkan hilangnya sebagian data jika salah satu "ekor" sistem penyimpanan (sistem penyimpanan) gagal. Jika replikasi sinkron digunakan, waktu layanan meningkat.
Juga wajar bahwa ketika waktu pemrosesan (latensi) penyimpanan meningkat, basis data mulai melambat dan ada efek negatif yang harus diperangi.
Di cloud kami, kami mencari solusi seimbang untuk menjaga keandalan dan kinerja. Teknik paling sederhana adalah dengan melokalkan data - dan kemudian kami menambahkan cluster Ceph terlokalisasi tambahan.
 Warna hijau menunjukkan tambahan cluster Ceph yang terlokalisasi.
Warna hijau menunjukkan tambahan cluster Ceph yang terlokalisasi.Keuntungan dari arsitektur yang sedemikian kompleks adalah mereka yang membutuhkan input / output data cepat dapat menggunakan penyimpanan lokal. Data yang ketersediaan penuhnya sangat penting dalam dua situs terletak di cluster terdistribusi. Ini bekerja lebih lambat - tetapi data di dalamnya direplikasi ke kedua situs. Jika kinerjanya tidak cukup, Anda dapat menggunakan cluster Ceph yang terlokalisasi.
Sebagian besar awan publik dan pribadi pada akhirnya memiliki pola kerja yang hampir sama, ketika, tergantung pada persyaratan, beban digunakan dalam berbagai jenis penyimpanan (berbagai jenis disk).
Diagnostik Ceph: cara membangun pemantauan
Ketika kami menggunakan dan meluncurkan infrastruktur, sudah waktunya untuk memastikan fungsinya, untuk meminimalkan waktu dan jumlah kegagalan. Oleh karena itu, langkah selanjutnya dalam pengembangan infrastruktur adalah pembangunan diagnostik dan pemantauan.
Pertimbangkan tugas pemantauan di seluruh - kami memiliki setumpuk aplikasi di lingkungan cloud virtual: aplikasi, sistem operasi tamu, perangkat blok, driver perangkat blok ini pada hypervisor, jaringan penyimpanan, dan sistem penyimpanan aktual (sistem penyimpanan). Dan semua ini belum tercakup oleh pemantauan.
 Elemen tidak tercakup oleh pemantauan.
Elemen tidak tercakup oleh pemantauan.Pemantauan diimplementasikan dalam beberapa tahap, kami mulai dengan disk. Kami mendapatkan jumlah operasi baca / tulis, hingga keakuratan, waktu layanan (megabita per detik), kedalaman antrian, karakteristik lainnya, dan kami juga mengumpulkan SMART tentang keadaan disk.
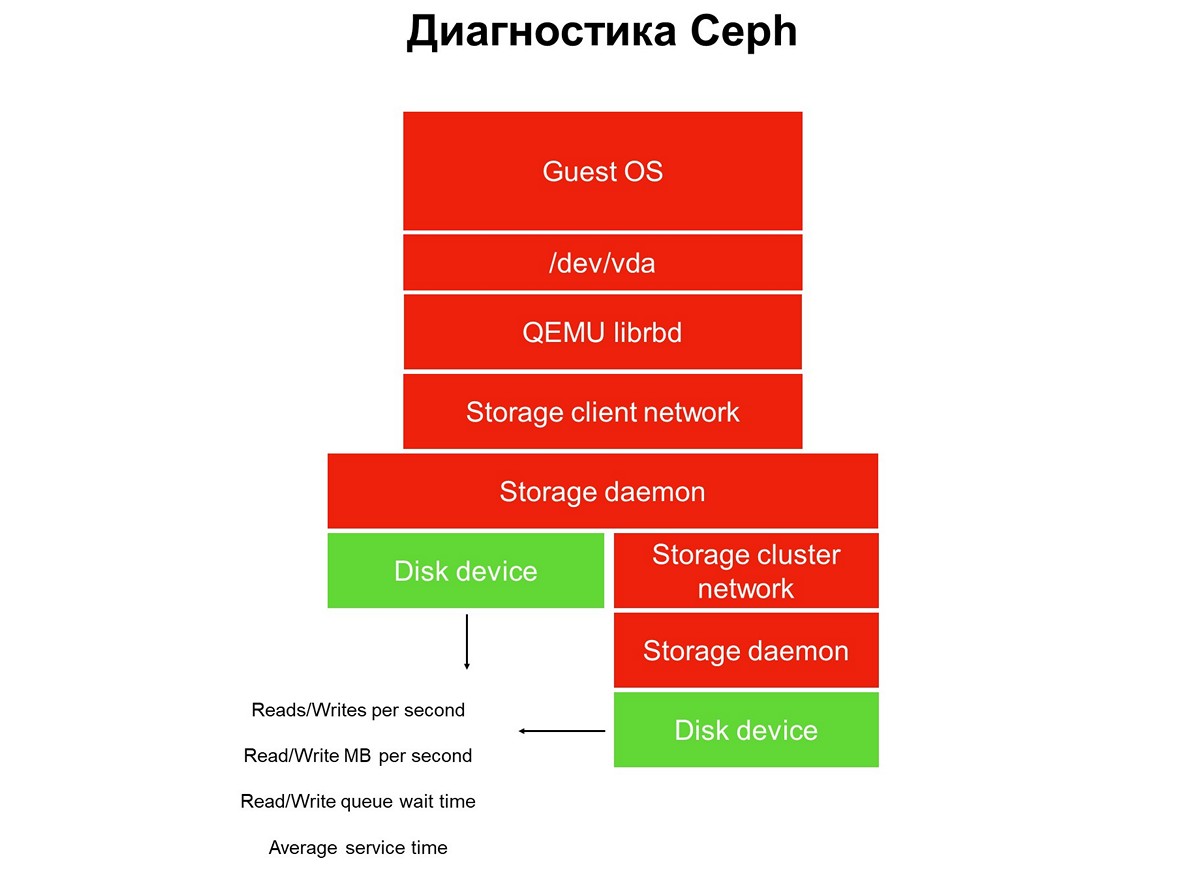 Tahap pertama: kita membahas disk pemantauan.
Tahap pertama: kita membahas disk pemantauan.Pemantauan disk tidak cukup untuk mendapatkan gambaran lengkap tentang apa yang terjadi di sistem. Oleh karena itu, kami beralih ke pemantauan elemen penting dari infrastruktur - jaringan sistem penyimpanan. Sebenarnya ada dua dari mereka - cluster internal dan klien, yang menghubungkan cluster penyimpanan dengan hypervisor. Di sini kita mendapatkan kecepatan transfer paket data (megabyte per detik, paket per detik), ukuran antrian jaringan, buffer, dan mungkin jalur data.
 Tahap kedua: pemantauan jaringan.
Tahap kedua: pemantauan jaringan.Mereka sering berhenti pada ini, tetapi ini tidak dapat dilakukan, karena sebagian besar infrastruktur belum ditutup oleh pemantauan.
Semua penyimpanan terdistribusi yang digunakan dalam cloud publik dan pribadi adalah SDS, penyimpanan yang ditentukan oleh perangkat lunak. Mereka dapat diimplementasikan pada solusi dari vendor tertentu, solusi open source, Anda dapat melakukan sesuatu sendiri menggunakan setumpuk teknologi yang sudah dikenal. Tetapi selalu SDS, dan pekerjaan bagian-bagian perangkat lunak ini harus dipantau.
 Langkah ketiga: memonitor Storage daemon.
Langkah ketiga: memonitor Storage daemon.Sebagian besar operator Ceph menggunakan data yang dikumpulkan dari daemon pemantauan dan kontrol Ceph (monitor dan manajer, alias mgr). Awalnya, kami pergi dengan cara yang sama, tetapi sangat cepat menyadari bahwa informasi ini tidak cukup - peringatan tentang permintaan menggantung terlambat: permintaan tergantung selama 30 detik, hanya kemudian kami melihatnya. Selama pemantauan, sementara pemantauan meningkatkan alarm, setidaknya tiga menit akan berlalu. Dalam kasus terbaik, ini berarti bahwa bagian dari penyimpanan dan aplikasi akan menganggur selama tiga menit.
Secara alami, kami memutuskan untuk memperluas pemantauan dan turun ke elemen utama Ceph - daemon OSD. Dari pemantauan daemon Object Storage, kami mendapatkan perkiraan waktu operasi seperti yang dilihat OSD, serta statistik tentang permintaan yang digantung - siapa, kapan, dalam PG berapa, berapa lama.
Mengapa hanya Ceph saja tidak cukup dan apa yang harus dilakukan
Ceph sendiri tidak cukup untuk sejumlah alasan. Misalnya, kami memiliki klien dengan profil basis data. Dia mengerahkan semua database di kluster all-flash, latensi operasi yang dikeluarkan di sana cocok untuknya, namun, ada keluhan downtime.
Sistem pemantauan tidak memungkinkan Anda untuk melihat apa yang terjadi di dalam lingkungan klien virtual. Sebagai hasilnya, untuk mengidentifikasi masalah, kami menggunakan analisis lanjutan, yang diminta menggunakan utilitas blktrace dari mesin virtualnya.
 Hasil analisis yang diperluas.
Hasil analisis yang diperluas.Hasil analisis berisi operasi yang ditandai dengan bendera W dan WS. Bendera W adalah catatan, bendera WS adalah catatan yang sinkron, menunggu perangkat menyelesaikan operasi. Ketika kita bekerja dengan basis data, hampir semua basis data SQL memiliki hambatan - WAL (write-ahead log).
Basis data selalu terlebih dahulu menulis data ke log, menerima konfirmasi dari disk dengan buffer pembilasan, kemudian menulis data ke basis data itu sendiri. Jika dia belum menerima konfirmasi tentang penyetelan ulang penyangga, dia yakin bahwa penyetelan daya dapat menghapus transaksi yang dikonfirmasi oleh klien. Ini tidak dapat diterima untuk database, jadi ini menampilkan "tulis SYNC / FLUSH", lalu tulis datanya. Ketika log penuh, pergantian mereka terjadi, dan semua yang masuk ke cache halaman juga secara paksa di-flash.
Ditambahkan: tidak ada reset dalam gambar itu sendiri - yaitu, operasi dengan flag pre-flush. Mereka terlihat seperti FWS - pre-flush + write + sync atau FWSF - pre-flush + write + sync + FUAKetika seorang klien memiliki banyak transaksi kecil, hampir semua I / O-nya berubah menjadi rantai berurutan: write-flush - write-flush. Karena Anda tidak dapat melakukan sesuatu dengan database, kami mulai bekerja dengan sistem penyimpanan. Pada saat ini, kami memahami bahwa kemampuan Ceph tidak cukup.
Bagi kami, pada tahap ini, solusi terbaik adalah menambahkan repositori lokal kecil dan cepat yang tidak diimplementasikan menggunakan alat Ceph (kami pada dasarnya kehabisan kemampuannya). Dan kami mengubah penyimpanan cloud menjadi sesuatu yang lebih dari Ceph. Dalam kasus kami, kami telah menambahkan banyak cerita lokal (lokal dalam hal pusat data, bukan hypervisor).
 Repositori lokal tambahan, Target A dan B.
Repositori lokal tambahan, Target A dan B.Waktu layanan penyimpanan lokal tersebut sekitar 0,3 ms per aliran. Jika terletak di pusat data lain, ia bekerja lebih lambat - dengan kinerja sekitar 0,7 ms. Ini adalah peningkatan yang signifikan dibandingkan dengan Ceph, yang menghasilkan 1,2 ms, dan didistribusikan di pusat data - 2 ms. Kinerja pabrik kecil seperti itu, yang kami miliki lebih dari selusin, adalah sekitar 100 ribu per modul, 100 ribu IOPS per catatan.
Setelah perubahan infrastruktur seperti itu, cloud kami meremas di bawah satu juta IOPS untuk ditulis, atau sekitar dua hingga tiga juta IOPS untuk dibaca secara total untuk semua klien:

Penting untuk dicatat bahwa jenis penyimpanan ini bukan metode utama ekspansi, kami menempatkan taruhan utama pada Ceph, dan keberadaan penyimpanan cepat hanya penting untuk layanan yang memerlukan waktu respons disk.
Iterasi baru: peningkatan kode dan infrastruktur
Semua cerita kami adalah sumber yang dibagikan. Infrastruktur semacam itu mengharuskan kami untuk
menerapkan kebijakan tingkat layanan : kami harus menyediakan tingkat layanan tertentu dan tidak mengizinkan satu klien mengganggu yang lain secara tidak sengaja atau sengaja, dengan menonaktifkan penyimpanan.
Untuk melakukan ini, kami harus melakukan finalisasi dan peluncuran non-sepele - pengiriman iteratif ke yang produktif.
Peluncuran ini berbeda dari praktik DevOps yang biasa, ketika semua proses: perakitan, pengujian, peluncuran kode, memulai kembali layanan, jika perlu, mulai dengan klik tombol, dan kemudian semuanya berfungsi. Jika Anda meluncurkan praktik DevOps ke infrastruktur, infrastruktur akan hidup hingga kesalahan pertama.
Itulah sebabnya "otomatisasi penuh" tidak secara khusus berakar pada tim infrastruktur. Tentu saja, ada pendekatan tertentu untuk pengujian dan otomatisasi pengiriman - tetapi selalu dikontrol dan pengiriman diprakarsai oleh insinyur SRE dari tim cloud.
Kami meluncurkan perubahan di beberapa layanan: di backend Cinder, frontend Cinder (klien Cinder) dan layanan Nova. Perubahan diterapkan dalam beberapa iterasi - satu iterasi pada satu waktu. Setelah iterasi ketiga, perubahan yang sesuai diterapkan pada mesin tamu klien: seseorang bermigrasi, seseorang sendiri me-restart VM (hard reboot) atau migrasi yang direncanakan untuk melayani hypervisor.
Masalah selanjutnya yang muncul adalah
lompatan dalam kecepatan tulis . Ketika kami bekerja dengan penyimpanan yang terpasang di jaringan, hypervisor default menganggap jaringan menjadi lambat, dan karenanya cache semua data. Dia menulis dengan cepat, hingga beberapa puluh megabyte, dan kemudian mulai membersihkan cache. Ada banyak momen tidak menyenangkan karena lompatan seperti itu.
Kami menemukan bahwa jika Anda menghidupkan cache, kinerja SSD turun 15%, dan jika Anda mematikan cache, kinerja HDD turun 35%. Butuh pengembangan lain, meluncurkan manajemen cache terkelola, ketika caching ditetapkan secara eksplisit untuk setiap jenis disk. Ini memungkinkan kami untuk menggerakkan SSD tanpa cache, dan HDD - dengan cache, sebagai hasilnya, kami berhenti kehilangan kinerja.
Praktek penyampaian pengembangan ke produktif serupa - iterasi. Kami meluncurkan kode, me-restart daemon, dan kemudian, jika perlu, me-restart atau memigrasi mesin virtual guest, yang seharusnya dapat berubah. Klien VM bermigrasi dari HDD, cache-nya dihidupkan - semuanya berfungsi, atau, sebaliknya, klien bermigrasi dengan SSD, cache dimatikan - semuanya berfungsi.
Masalah ketiga adalah
operasi yang salah dari mesin virtual yang digunakan dari gambar EMAS ke HDD .
Ada banyak klien seperti itu, dan kekhasan situasinya adalah bahwa pekerjaan VM disesuaikan dengan sendirinya: masalah dijamin terjadi selama penyebaran, tetapi diselesaikan saat klien mencapai dukungan teknis. Pada awalnya, kami meminta pelanggan untuk menunggu setengah jam sampai VM distabilkan, tetapi kemudian kami mulai bekerja pada kualitas layanan.
Dalam proses penelitian, kami menyadari bahwa kemampuan infrastruktur pemantauan kami masih belum cukup.
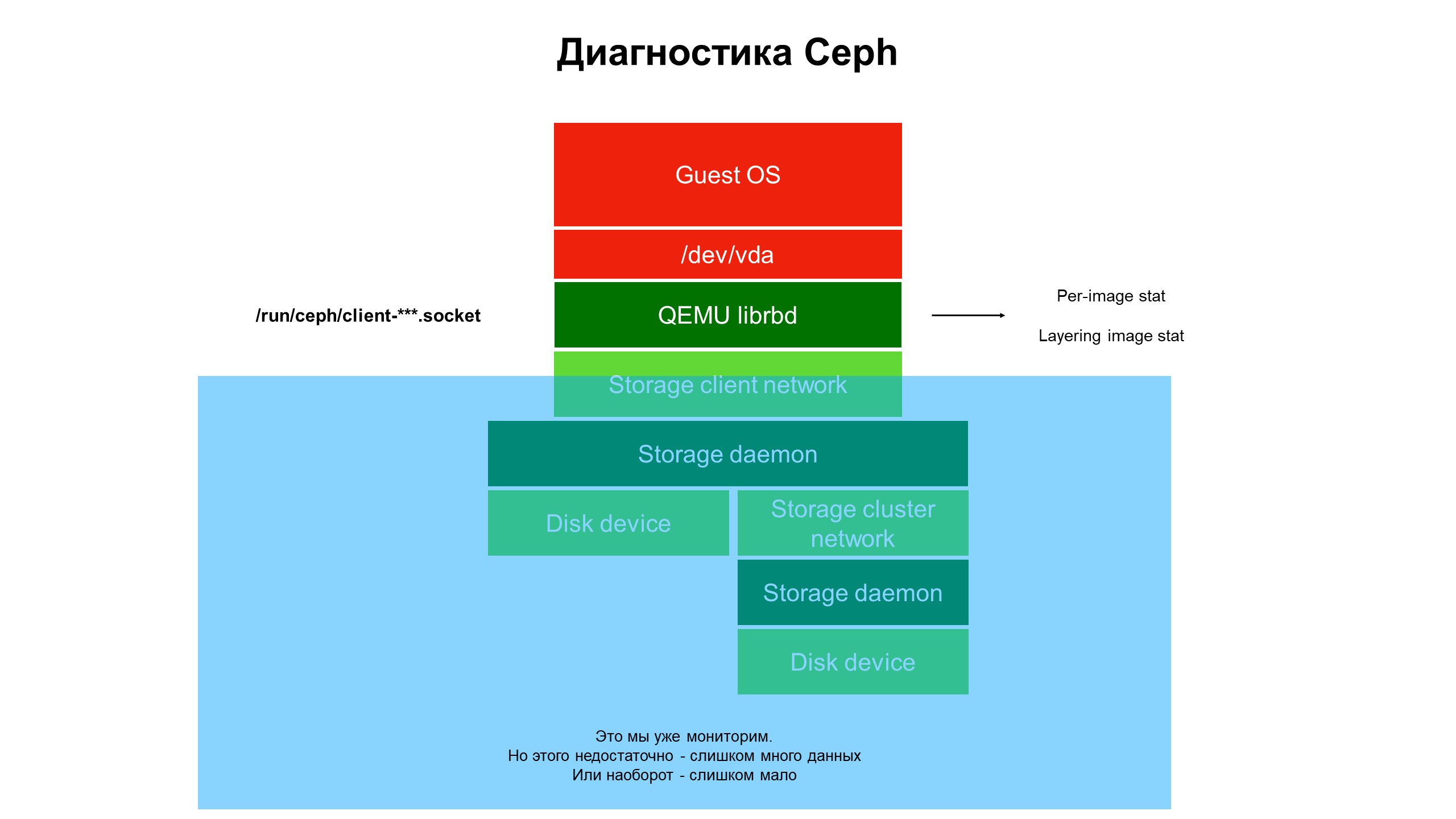 Pemantauan menutup bagian biru, dan masalahnya ada di bagian atas infrastruktur, tidak tercakup oleh pemantauan.
Pemantauan menutup bagian biru, dan masalahnya ada di bagian atas infrastruktur, tidak tercakup oleh pemantauan.Kami mulai berurusan dengan apa yang terjadi di bagian infrastruktur yang tidak tercakup oleh pemantauan. Untuk melakukan ini, kami menggunakan diagnostik Ceph tingkat lanjut (atau lebih tepatnya, salah satu varietas klien Ceph - librbd). Menggunakan alat otomatisasi, kami membuat perubahan pada konfigurasi klien Ceph untuk mengakses struktur data internal melalui soket domain Unix, dan mulai mengambil statistik dari klien Ceph pada hypervisor.
Apa yang kita lihat? Kami tidak melihat statistik pada Ceph cluster / OSD / cluster, tetapi statistik pada setiap disk dari mesin virtual klien yang disk-nya ada di Ceph - yaitu, statistik yang terkait dengan perangkat.
 Hasil statistik pemantauan lanjutan.
Hasil statistik pemantauan lanjutan.Itu statistik diperluas yang membuatnya jelas bahwa masalah hanya terjadi pada disk yang dikloning dari disk lain.
Selanjutnya, kami melihat statistik operasi, khususnya operasi baca-tulis. Ternyata beban pada gambar tingkat atas relatif kecil, dan pada gambar awal, dari mana klon berasal, itu besar tetapi tidak ada kalibrasi: sejumlah besar bacaan tanpa rekaman sama sekali.
Masalahnya terlokalisasi, sekarang solusi diperlukan - kode atau infrastruktur?
Tidak ada yang bisa dilakukan dengan kode Ceph, itu "sulit". Selain itu, keamanan data pelanggan tergantung padanya. Tetapi ada masalah, itu harus dipecahkan, dan kami mengubah arsitektur repositori. Cluster HDD berubah menjadi cluster hybrid - sejumlah SSD ditambahkan ke HDD, kemudian prioritas daemon OSD diubah sehingga SSD selalu menjadi prioritas dan menjadi OSD utama di dalam grup penempatan (PG).
Sekarang, ketika klien menyebarkan mesin virtual dari disk kloning, operasi pembacaannya pergi ke SSD. Akibatnya, pemulihan dari disk menjadi cepat, dan hanya data klien selain gambar asli yang ditulis ke HDD. Kami menerima peningkatan tiga kali lipat dalam produktivitas yang hampir tanpa biaya (relatif terhadap biaya awal infrastruktur).
Mengapa pemantauan infrastruktur penting
- Infrastruktur pemantauan harus dimasukkan ke maksimum di seluruh tumpukan, dimulai dengan mesin virtual dan diakhiri dengan disk. Bagaimanapun, ketika klien menggunakan cloud pribadi atau publik mengakses infrastruktur mereka dan memberikan informasi yang diperlukan, masalahnya akan berubah atau pindah ke tempat lain.
- Memantau seluruh hypervisor, mesin virtual, atau wadah "secara keseluruhan" hampir tidak menghasilkan apa-apa. Kami mencoba memahami dari lalu lintas jaringan apa yang terjadi dengan Ceph - tidak ada gunanya, data terbang dengan kecepatan tinggi (dari 500 megabita per detik), sangat sulit untuk memilih yang diperlukan. Dibutuhkan volume disk yang sangat besar untuk menyimpan statistik seperti itu dan banyak waktu untuk menganalisisnya.
- Penting untuk mengumpulkan data pemantauan sebanyak mungkin, jika tidak ada risiko kehilangan sesuatu yang penting. Dan sisi sebaliknya: jika Anda mengumpulkan banyak data, tetapi kemudian Anda tidak dapat menganalisisnya dan menemukan apa yang Anda butuhkan di antara mereka, ini membuat statistik yang terakumulasi menjadi tidak berguna, data yang dikumpulkan hanya akan menghabiskan ruang disk Anda tanpa tujuan.
- Tujuan pemantauan bukan hanya penentuan kegagalan infrastruktur. Kegagalan Anda akan melihat ketika itu terjadi. Tujuan utamanya adalah untuk memprediksi kegagalan dan melihat tren, mengumpulkan statistik untuk meningkatkan kualitas layanan. Untuk melakukan ini, kita perlu aliran data yang terorganisir dengan baik dalam pemantauan, terkait dengan infrastruktur. Idealnya, dari disk mesin virtual spesifik ke level terendah - ke disk penyimpanan di mana data yang diakses oleh mesin virtual klien berada.
- Cloud MCS Cloud Solutions adalah infrastruktur yang keputusan evolusinya dibuat sebagian besar berdasarkan data yang diakumulasikan oleh pemantauan. Kami meningkatkan pemantauan dan menggunakan datanya untuk meningkatkan tingkat layanan bagi pelanggan.