Masalah pencarian otomatis untuk teks dalam gambar telah ada sejak lama, setidaknya sejak awal tahun sembilan puluhan abad terakhir. Mereka dapat diingat oleh orang-orang tua oleh distribusi luas ABBYY FineReader, yang dapat menerjemahkan pindaian dokumen ke dalam versi yang dapat diedit.
Pemindai yang terhubung ke komputer pribadi berfungsi baik di perusahaan, tetapi kemajuan tidak berhenti, dan perangkat seluler telah mengambil alih dunia. Rentang tugas untuk bekerja dengan teks juga telah berubah. Sekarang Anda perlu mencari teks tidak pada lembar A4 lurus sempurna dengan teks hitam pada latar belakang putih, tetapi pada berbagai kartu nama, menu warna-warni, tanda-tanda toko dan banyak lagi tentang apa yang seseorang dapat temui di hutan kota modern.
 Sebuah contoh nyata dari karya jaringan saraf kita. Gambar bisa diklik.
Sebuah contoh nyata dari karya jaringan saraf kita. Gambar bisa diklik.Persyaratan dan batasan dasar
Dengan berbagai kondisi untuk penyajian teks, algoritma tulisan tangan tidak bisa lagi mengatasinya. Di sini, jaringan saraf dengan kemampuan mereka untuk menggeneralisasi datang untuk menyelamatkan. Dalam posting ini, kita akan berbicara tentang pendekatan kami untuk menciptakan arsitektur jaringan saraf yang mendeteksi teks dalam gambar kompleks dengan kualitas baik dan kecepatan tinggi.
Perangkat seluler memberlakukan batasan tambahan pada pilihan pendekatan:
- Pengguna tidak selalu memiliki kesempatan untuk menggunakan jaringan seluler untuk berkomunikasi dengan server karena lalu lintas roaming yang mahal atau masalah privasi. Jadi solusi seperti Google Lens tidak akan membantu di sini.
- Karena kami fokus pada pemrosesan data lokal, akan lebih baik untuk solusi kami:
- Butuh sedikit memori;
- Ini bekerja dengan cepat menggunakan kemampuan teknis dari smartphone.
- Teks dapat diputar dan berada di latar belakang acak.
- Kata-kata bisa sangat panjang. Dalam jaringan saraf convolutional, ruang lingkup kernel konvolusi biasanya tidak mencakup keseluruhan kata, jadi diperlukan beberapa trik untuk mengatasi batasan ini.

- Ukuran teks pada satu foto mungkin berbeda:

Solusi
Solusi paling sederhana untuk masalah pencarian teks yang muncul dalam pikiran adalah untuk mengambil jaringan terbaik dari kompetisi
ICDAR (Konferensi Internasional tentang Analisis dan Pengakuan Dokumen) yang mengkhususkan diri dalam tugas dan bisnis ini! Sayangnya, jaringan tersebut mencapai kualitas karena kekompakan dan kompleksitas komputasinya, dan hanya cocok sebagai solusi cloud, yang tidak memenuhi paragraf 1 dan 2 dari persyaratan kami. Tetapi bagaimana jika kita mengambil jaringan besar yang bekerja dengan baik dalam skenario yang perlu kita bahas dan mencoba menguranginya? Pendekatan ini sudah lebih menarik.
Baoguang Shi et al. Dalam jaringan saraf mereka
SegLink [1] mengusulkan yang berikut:
- Untuk menemukan tidak seluruh kata sekaligus (area hijau pada gambar a ), tetapi bagian-bagiannya, disebut segmen, dengan prediksi rotasi, kemiringan, dan pergeserannya. Mari pinjam ide ini.
- Anda perlu mencari segmen kata pada beberapa skala sekaligus untuk memenuhi persyaratan 5. Segmen ditunjukkan oleh segi empat hijau pada gambar b .
- Untuk menyelamatkan seseorang dari menciptakan cara menggabungkan segmen-segmen ini, kami cukup membuat jaringan saraf memprediksi koneksi (tautan) antara segmen yang terkait dengan kata yang sama
a. dalam skala yang sama (garis merah pada gambar c )
b. dan di antara skala (garis merah pada gambar d ), menyelesaikan masalah klausa 4 persyaratan.
Kotak biru pada gambar di bawah ini menunjukkan area visibilitas piksel dari lapisan output dari jaringan saraf skala yang berbeda, yang "melihat" setidaknya sebagian kata.
 Contoh Segmen dan Tautan
Contoh Segmen dan TautanSegLink menggunakan arsitektur VGG-16 yang terkenal sebagai fondasinya. Prediksi segmen dan tautan di dalamnya dilakukan pada 6 skala. Sebagai percobaan pertama, kami mulai dengan implementasi arsitektur asli. Ternyata jaringan tersebut mengandung 23 juta parameter (bobot) yang perlu disimpan dalam file berukuran 88 megabyte. Jika Anda membuat aplikasi berdasarkan VGG, maka itu akan menjadi salah satu kandidat pertama untuk dihapus jika tidak ada cukup ruang, dan pencarian teks itu sendiri akan bekerja sangat lambat, sehingga jaringan harus segera menurunkan berat badan.
 Arsitektur Jaringan SegLink
Arsitektur Jaringan SegLinkRahasia diet kita
Anda dapat mengurangi ukuran jaringan hanya dengan mengubah jumlah lapisan dan saluran di dalamnya atau dengan mengubah konvolusi itu sendiri dan koneksi di antara mereka. Mark Sandler dan
kawan -
kawan tepat pada waktunya mengambil arsitektur di jaringan
MobileNetV2 mereka [2] sehingga dapat bekerja dengan cepat pada perangkat seluler, membutuhkan sedikit ruang, dan masih tidak ketinggalan dalam kualitas pekerjaan dari VGG yang sama. Rahasia untuk mempercepat dan mengurangi konsumsi memori ada dalam tiga langkah utama:
- Jumlah saluran dengan peta fitur di pintu masuk ke blok dikurangi dengan konvolusi titik ke seluruh kedalaman (yang disebut bottleneck) tanpa fungsi aktivasi.
- Konvolusi klasik digantikan oleh konvolusi yang dapat dipisahkan per saluran. Konvolusi seperti itu membutuhkan bobot yang lebih sedikit dan komputasi yang lebih sedikit.
- Kartu karakter setelah bottleneck diteruskan ke input blok berikutnya untuk dijumlahkan tanpa konvolusi tambahan.
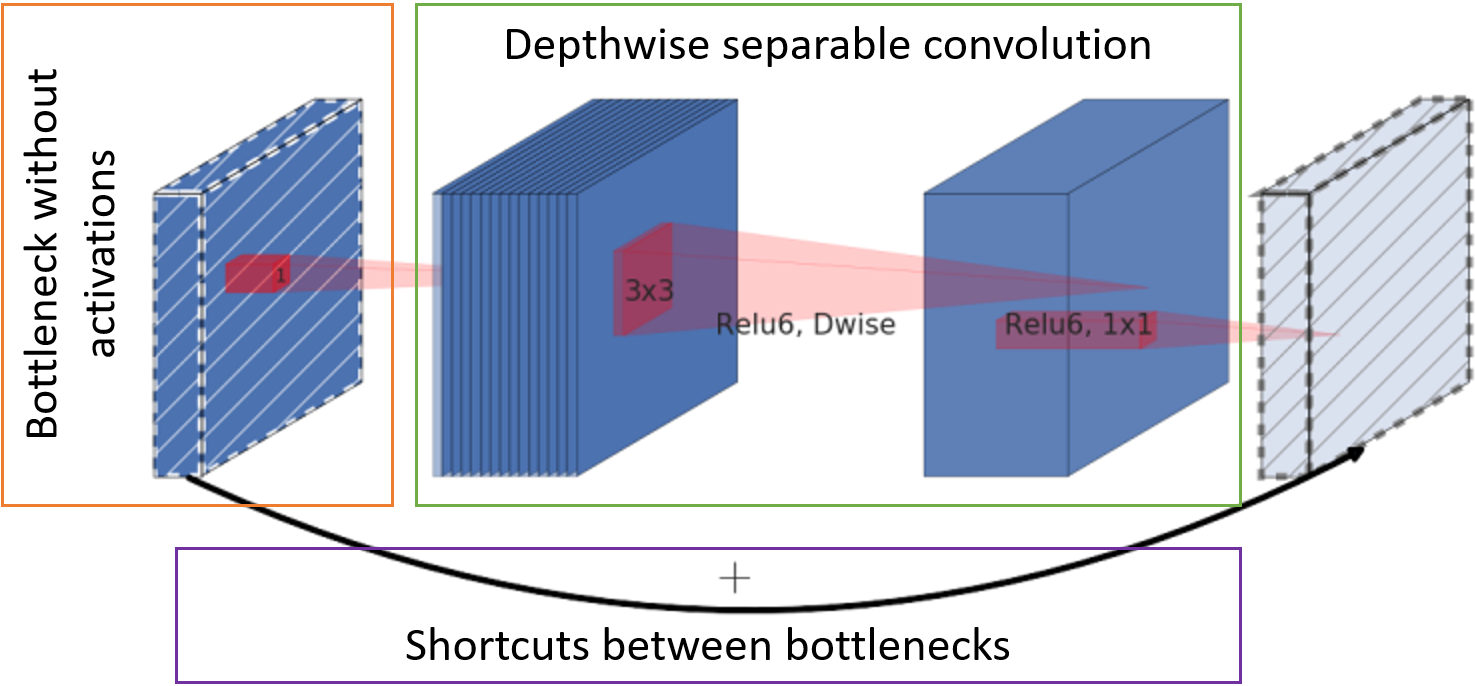 Unit Dasar MobileNetV2
Unit Dasar MobileNetV2
Jaringan saraf yang dihasilkan
Dengan menggunakan pendekatan di atas, kami sampai pada struktur jaringan berikut:
- Kami menggunakan segmen dan tautan dari SegLink
- Ganti VGG dengan MobileNetV2 yang kurang rakus
- Kurangi jumlah skala pencarian teks dari 6 menjadi 5 untuk kecepatan
 Jaringan Ringkasan Pencarian Teks
Jaringan Ringkasan Pencarian Teks
Dekripsi nilai dalam blok arsitektur jaringan
Langkah langkah dan jumlah dasar saluran di saluran ditunjukkan sebagai s <stride> c <channels>, masing-masing. Misalnya, s2c32 berarti 32 saluran dengan pergeseran 2. Jumlah aktual saluran dalam lapisan konvolusi diperoleh dengan mengalikan angka dasar mereka dengan faktor penskalaan α, yang memungkinkan Anda untuk dengan cepat mensimulasikan berbagai “ketebalan” jaringan. Di bawah ini adalah tabel dengan jumlah parameter dalam jaringan tergantung pada α.

Jenis blok:
- Conv2D - operasi konvolusi lengkap;
- D-wise Conv - per-saluran konvolusi yang dapat dipisahkan;
- Blok - sekelompok blok MobileNetV2;
- Output - konvolusi untuk mendapatkan lapisan output. Nilai numerik tipe NxN menunjukkan ukuran bidang reseptif piksel.
Sebagai fungsi aktivasi, blok menggunakan ReLU6.

Lapisan keluaran memiliki 31 saluran:
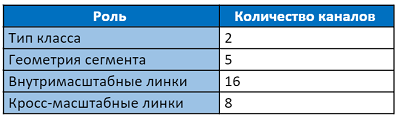
Dua saluran pertama dari lapisan keluaran memilih pixel untuk menjadi milik teks dan bukan teks. Lima saluran berikut berisi informasi untuk secara akurat membuat kembali geometri segmen: pergeseran vertikal dan horizontal relatif terhadap posisi piksel, faktor lebar dan tinggi (karena segmen biasanya tidak persegi) dan sudut rotasi. 16 nilai tautan intra-saluran menunjukkan apakah ada koneksi antara delapan piksel yang berdekatan pada skala yang sama. 8 saluran terakhir memberi tahu kami tentang keberadaan tautan ke empat piksel dari skala sebelumnya (skala sebelumnya selalu 2 kali lebih besar). Setiap 2 nilai segmen, tautan intra dan lintas-skala dinormalisasi oleh fungsi softmax. Akses ke skala pertama tidak memiliki tautan lintas-skala.
Perakitan kata
Jaringan memprediksi apakah segmen tertentu dan tetangganya milik teks. Masih mengumpulkan mereka menjadi kata-kata.
Untuk memulai, gabungkan semua segmen yang ditautkan oleh tautan. Untuk melakukan ini, kami membuat grafik di mana simpul semua segmen di semua skala, dan ujungnya adalah tautan. Kemudian kita menemukan komponen yang terhubung dari grafik. Untuk setiap komponen, sekarang dimungkinkan untuk menghitung persegi panjang kata terlampir sebagai berikut:
- Kami menghitung sudut rotasi kata θ
- Atau sebagai rata-rata prediksi sudut rotasi segmen, jika ada banyak dari mereka,
- Atau sebagai sudut rotasi garis diperoleh dengan regresi pada titik-titik pusat segmen, jika ada beberapa segmen.
- Pusat kata dipilih sebagai pusat massa titik pusat segmen.
- Perluas semua segmen dengan -θ untuk mengaturnya secara horizontal. Temukan batasan kata.
- Batas kiri dan kanan kata dipilih sebagai batas segmen paling kiri dan paling kanan.
- Untuk mendapatkan batas kata atas, segmen diurutkan berdasarkan ketinggian tepi atas, 20% dari yang tertinggi terputus, dan nilai segmen pertama dari daftar tersisa setelah pemfilteran dipilih.
- Batas bawah diperoleh dari segmen terendah dengan cutoff 20% dari terendah, dengan analogi dengan batas atas.
- Putar kembali persegi panjang yang dihasilkan ke θ.
Solusi terakhir disebut
FaSTExt : Fast dan Small Text Extractor [3]
Waktu percobaan!
Detail Pelatihan
Jaringan itu sendiri dan parameternya dipilih untuk pekerjaan yang baik pada sampel internal yang besar, yang mencerminkan skenario utama menggunakan aplikasi pada telepon - ia mengarahkan kamera ke objek dengan teks dan mengambil foto. Ternyata jaringan besar dengan α = 1 mem-bypass kualitas versi dengan α = 0,5 hanya 2%. Sampel ini tidak dalam domain publik, oleh karena itu, untuk kejelasan, saya harus melatih jaringan pada sampel publik
ICDAR2013 , di mana kondisi pemotretan mirip dengan milik kami. Sampel sangat kecil, sehingga jaringan sebelumnya dilatih pada sejumlah besar data sintetik dari
SynthText di Wild Dataset . Proses pra-pelatihan memakan waktu sekitar 20 hari perhitungan untuk setiap percobaan pada GTX 1080 Ti, sehingga operasi jaringan pada data publik diperiksa hanya untuk opsi α = 0,75, 1 dan 2.
Sebagai pengoptimal, versi
AMSGrad dari Adam digunakan.
Fungsi Kesalahan:
- Cross entropy untuk klasifikasi segmen dan tautan;
- Fungsi kehilangan Huber untuk geometri segmen.
Hasil
Dalam hal kualitas kinerja jaringan dalam skenario target, kita dapat mengatakan bahwa itu tidak jauh tertinggal dari pesaing dalam hal kualitas, dan bahkan menyalip beberapa. MS adalah jaringan pesaing berskala besar.
 * Dalam artikel tentang TIMUR tidak ada hasil pada sampel yang kami butuhkan, jadi kami melakukan percobaan sendiri.
* Dalam artikel tentang TIMUR tidak ada hasil pada sampel yang kami butuhkan, jadi kami melakukan percobaan sendiri.Gambar di bawah ini menunjukkan contoh bagaimana FaSTExt bekerja pada gambar dari ICDAR2013. Baris pertama menunjukkan bahwa huruf-huruf menyala dari kata ESPMOTO tidak ditandai, tetapi jaringan dapat menemukannya. Versi yang kurang luas dengan α = 0,75 diatasi dengan teks kecil lebih buruk daripada versi yang lebih "tebal". Intinya lagi menunjukkan cacat markup dalam sampel dengan teks yang hilang dalam refleksi. FaSTExt pada saat yang sama melihat teks seperti itu.

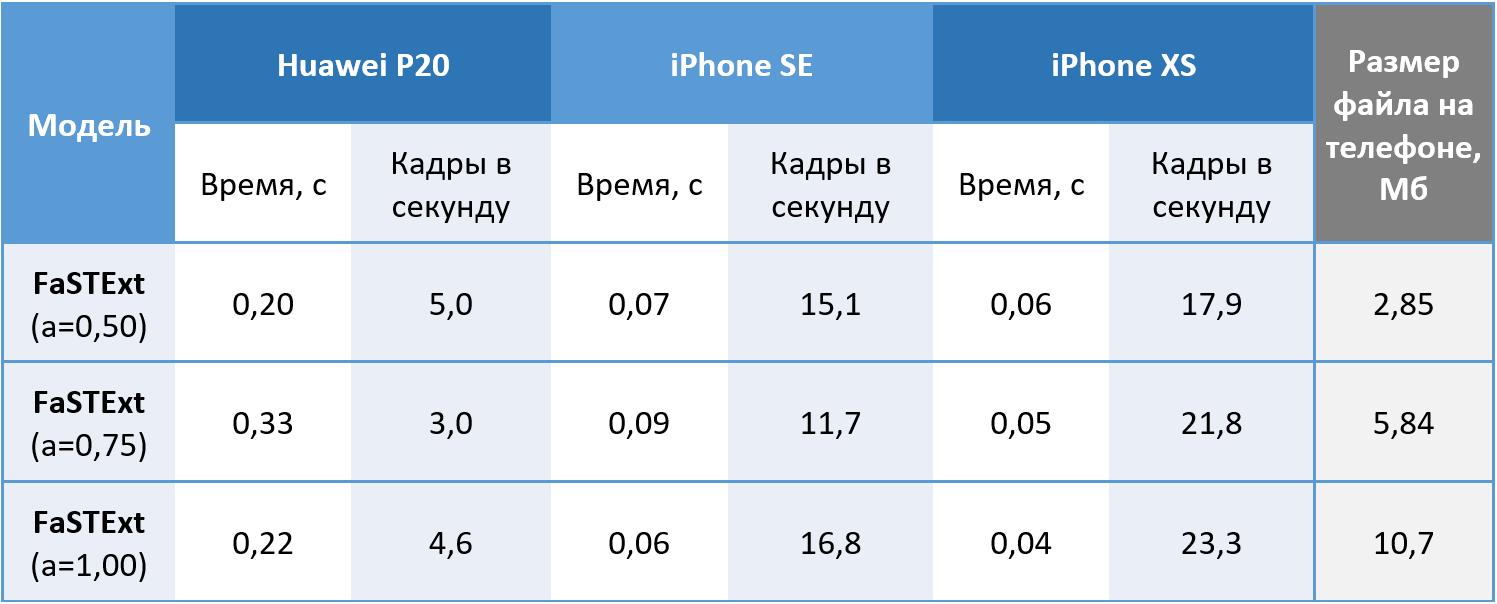
Jadi, jaringan melakukan tugasnya. Masih memeriksa apakah itu benar-benar dapat digunakan pada ponsel? Model diluncurkan pada gambar berwarna 512x512 pada Huawei P20 menggunakan CPU, dan pada iPhone SE dan iPhone XS menggunakan GPU, karena sistem pembelajaran mesin kami masih memungkinkan menggunakan GPU pada iOS saja. Nilai yang diperoleh dengan rata-rata 100 dimulai. Di Android, kami berhasil mencapai kecepatan 5 frame per detik yang dapat diterima untuk tugas kami. IPhone XS menunjukkan efek yang menarik dengan penurunan waktu rata-rata yang diperlukan untuk perhitungan saat menyulitkan jaringan. IPhone modern mendeteksi teks dengan penundaan minimal, yang bisa disebut kemenangan.
Referensi
[1] B. Shi, X. Bai dan S. Belongie, "Mendeteksi Teks Berorientasi pada Gambar Alami dengan Menghubungkan Segmen," Hawaii, 2017.
tautan[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov dan L.-C. Chen, "MobileNetV2: Residual Terbalik dan Hambatan Linear," Salt Lake City, 2018.
tautan[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov dan I. Zagaynov, “FaSTExt: Extractor Teks Cepat dan Kecil,” dalam Lokakarya Internasional ke-8 tentang Analisis & Pengakuan Dokumen Berbasis Kamera, Sydney, 2019
tautan[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu dan X. Bai, "Pendeteksian teks multi-berorientasi dengan jaringan convolutional penuh," Las Vegas, 2016.
tautan[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. Ia dan J. Liang, "EAST: Sebuah Detektor Teks Adegan yang Efisien dan Akurat," pada Konferensi IEEE 2017 tentang Komputer Visi dan Pola, Honolulu, 2017.
tautan[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia dan X. Bai, "Regresi Rotasi-Sensitif untuk Deteksi Teks Adegan Berorientasi," pada Konferensi IEEE / CVF 2018 tentang Visi dan Pola Komputer, Salt Lake City, 2018.
link[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao dan J. Yan, "Fots: Teks berorientasi cepat bercak dengan jaringan terpadu," pada Konferensi IEEE / CVF 2018 tentang Visi Komputer dan Pattern, Salt Lake City, 2018.
tautanKelompok visi komputer