Habr conference - ceritanya bukan debut. Kami biasanya mengadakan acara pemanggang roti yang agak besar untuk 300-400 orang, tetapi sekarang kami memutuskan bahwa pertemuan tematik kecil akan relevan, arah yang juga dapat Anda tetapkan - misalnya, dalam komentar. Konferensi pertama format ini diadakan pada bulan Juli dan didedikasikan untuk pengembangan backend. Peserta mendengarkan laporan tentang fitur-fitur transisi dari backend ke ML dan pada desain layanan Quadrupel di portal State Services, dan juga mengambil bagian dalam sebuah meja bundar yang ditujukan untuk Serverless. Bagi yang tidak bisa menghadiri acara tersebut secara pribadi, dalam posting ini kami sampaikan yang paling menarik.

Dari pengembangan backend ke pembelajaran mesin
Apa yang dilakukan insinyur data ML? Apa persamaan dan perbedaan antara tugas pengembang backend dan insinyur ML? Jalur apa yang perlu Anda tempuh untuk mengubah profesi pertama ke yang kedua? Ini diceritakan oleh Alexander Parinov, yang masuk ke pembelajaran mesin setelah 10 tahun backend.
 Alexander Parinov
Alexander ParinovSaat ini, Alexander bekerja sebagai arsitek sistem visi komputer di X5 Retail Group dan berkontribusi pada proyek sumber terbuka yang terkait dengan visi komputer dan pembelajaran mendalam (github.com/creafz). Keahliannya dikonfirmasi oleh partisipasinya di 100 teratas Master Kaggle peringkat dunia (kaggle.com/creafz) - platform paling populer yang menyelenggarakan kompetisi pembelajaran mesin.
Mengapa beralih ke pembelajaran mesin
Setahun setengah yang lalu, Jeff Dean, kepala Google Brain, proyek penelitian kecerdasan buatan dalam belajar Google, memberi tahu Google bagaimana setengah juta baris kode dalam Google Translate digantikan oleh jaringan saraf dengan Tensor Flow, yang hanya terdiri dari 500 baris. Setelah pelatihan jaringan, kualitas data telah berkembang dan infrastruktur telah disederhanakan. Tampaknya inilah masa depan kita yang cerah: tidak perlu lagi menulis kode, cukup membuat neuron dan membuangnya dengan data. Namun dalam praktiknya, semuanya jauh lebih rumit.
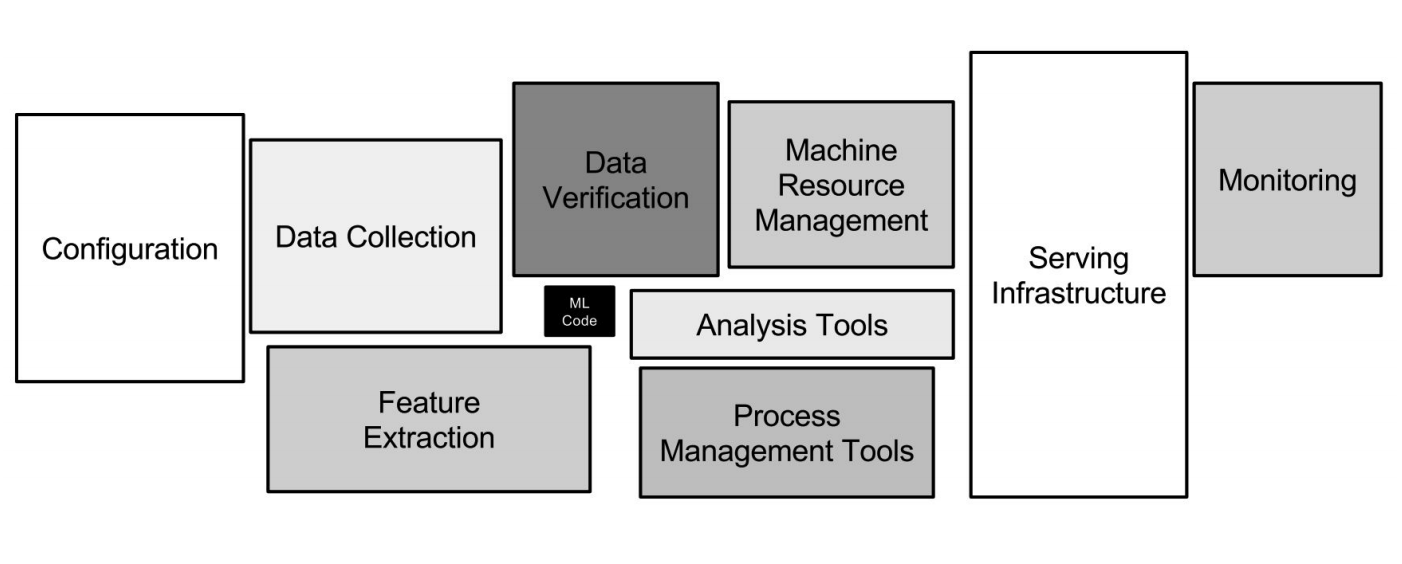 Infrastruktur Google ML
Infrastruktur Google MLJaringan saraf hanyalah sebagian kecil dari infrastruktur (kotak hitam kecil pada gambar di atas). Banyak sistem tambahan yang diperlukan untuk menerima data, mengolahnya, menyimpannya, memeriksa kualitasnya, dll., Kita membutuhkan infrastruktur untuk pelatihan, menyebarkan kode pembelajaran mesin dalam produksi, menguji kode ini. Semua tugas ini persis seperti yang dilakukan pengembang backend.
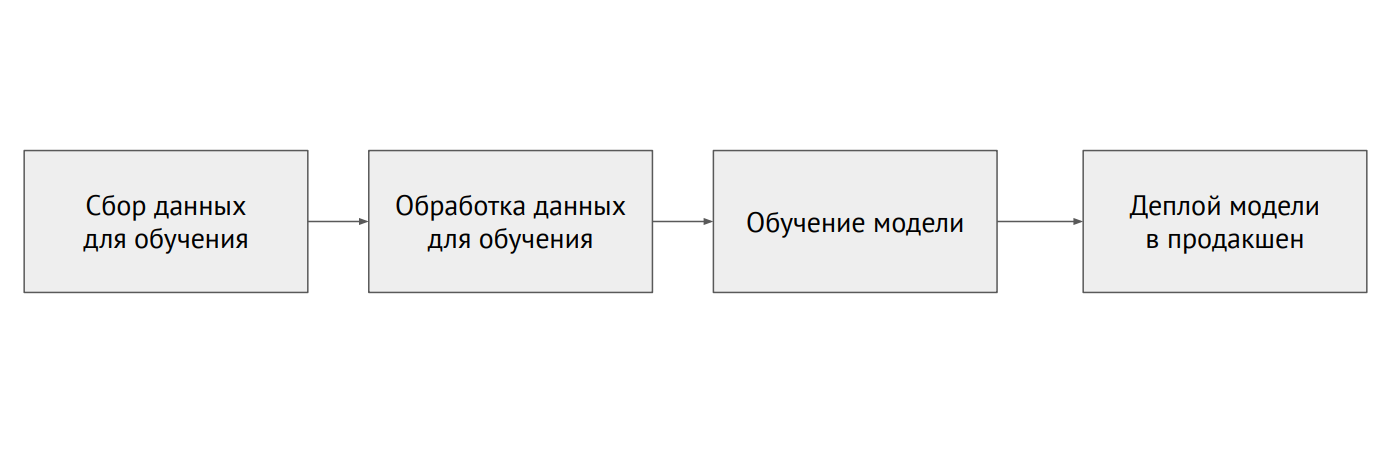 Proses pembelajaran mesin
Proses pembelajaran mesinApa perbedaan antara ML dan backend
Dalam pemrograman klasik, kita menulis kode, dan ini menentukan perilaku program. Dalam ML, kami memiliki kode model kecil dan banyak data yang digunakan untuk menjatuhkan model. Data dalam ML sangat penting: model yang sama, dilatih dengan data yang berbeda, dapat menunjukkan hasil yang sama sekali berbeda. Masalahnya adalah bahwa hampir selalu data terfragmentasi dan terletak pada sistem yang berbeda (database relasional, database NoSQL, log, file).
 Versi data
Versi dataML membutuhkan versi tidak hanya dari kode, seperti dalam pengembangan klasik, tetapi juga data: perlu untuk memahami dengan jelas apa model yang dilatih. Anda dapat menggunakan pustaka Kontrol Versi Versi Data Ilmu Pengetahuan (dvc.org) untuk ini.
 Markup data
Markup dataTugas selanjutnya adalah markup data. Misalnya, tandai semua objek dalam gambar atau katakan kelasnya milik siapa. Ini dilakukan oleh layanan khusus seperti Yandex.Tolki, pekerjaan yang sangat menyederhanakan ketersediaan API. Kesulitan timbul karena "faktor manusia": adalah mungkin untuk meningkatkan kualitas data dan meminimalkan kesalahan dengan mempercayakan tugas yang sama kepada beberapa pemain.
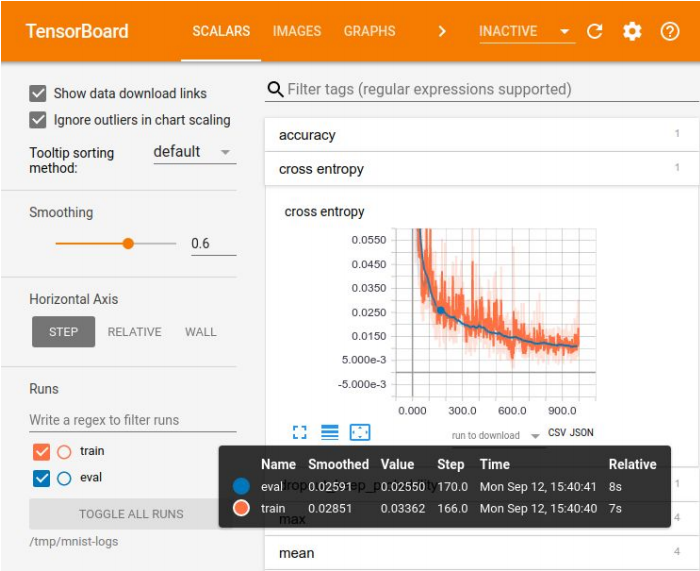 Visualisasi dalam Papan Tensor
Visualisasi dalam Papan TensorPencatatan eksperimen diperlukan untuk membandingkan hasil, memilih model terbaik untuk beberapa metrik. Untuk visualisasi ada seperangkat alat besar - misalnya, Tensor Board. Tetapi tidak ada metode yang ideal untuk menyimpan eksperimen. Di perusahaan kecil, mereka sering menghabiskan biaya yang sangat tinggi, di perusahaan besar mereka menggunakan platform khusus untuk menyimpan hasil dalam database.
 Ada banyak platform untuk pembelajaran mesin, tetapi tidak satu pun yang mencakup bahkan 70% dari kebutuhan
Ada banyak platform untuk pembelajaran mesin, tetapi tidak satu pun yang mencakup bahkan 70% dari kebutuhanMasalah pertama yang harus Anda hadapi ketika Anda membawa model terlatih untuk produksi terkait dengan alat ilmuwan data favorit Anda - Jupyter Notebook. Tidak ada modularitas di dalamnya, yaitu, output seperti "kaki-jatuh" kode yang tidak dipecah menjadi potongan-potongan logis - modul. Semuanya tercampur aduk: kelas, fungsi, konfigurasi, dll. Kode ini sulit untuk versi dan diuji.
Bagaimana cara mengatasinya? Anda dapat memasang Netflix dan membuat platform Anda sendiri yang memungkinkan Anda untuk menjalankan laptop ini secara langsung dalam produksi, mentransfer data kepada mereka dan mendapatkan hasilnya. Anda dapat memaksa pengembang yang menggulung model menjadi produksi untuk menulis ulang kode secara normal, memecahnya menjadi modul. Tetapi dengan pendekatan ini, mudah untuk membuat kesalahan, dan model tidak akan berfungsi sebagaimana dimaksud. Oleh karena itu, opsi yang ideal adalah untuk melarang penggunaan Notebook Jupyter untuk kode model. Jika, tentu saja, Ilmuwan Data menyetujui hal ini.
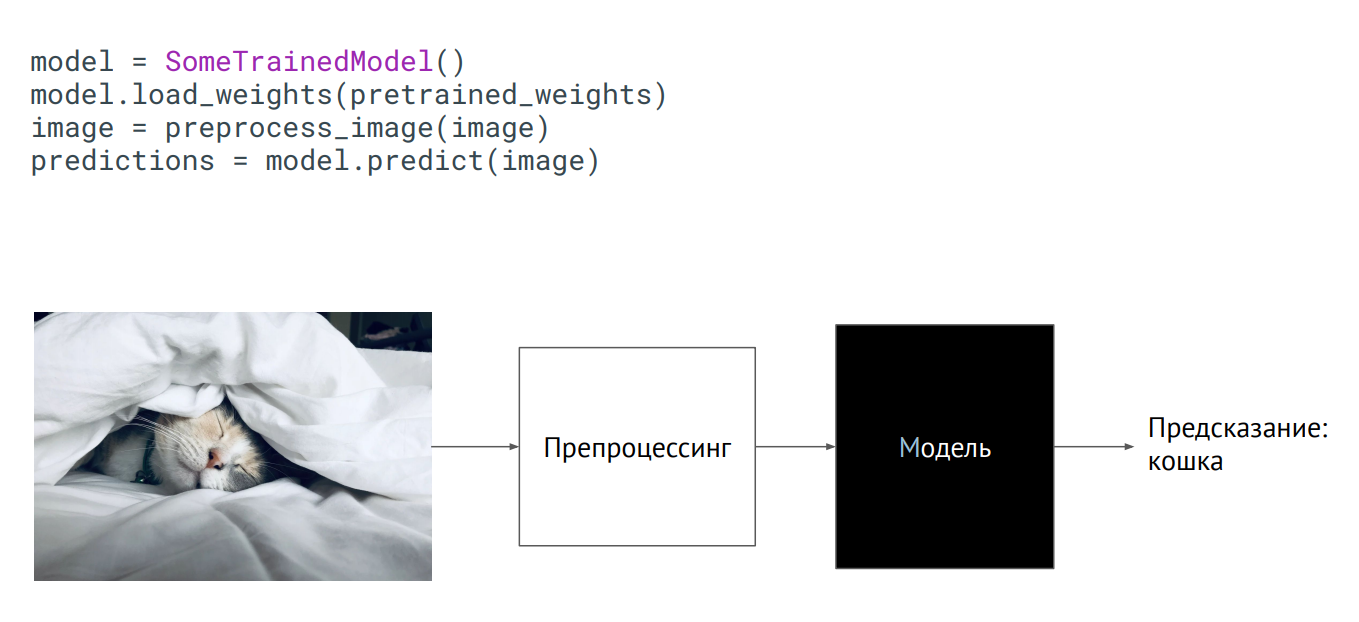 Model sebagai kotak hitam
Model sebagai kotak hitamCara termudah untuk membawa model ke produksi adalah menggunakannya sebagai kotak hitam. Anda memiliki beberapa kelas model, bobot model (parameter neuron dari jaringan terlatih) diteruskan kepada Anda, dan jika Anda menginisialisasi kelas ini (panggil metode prediksi, letakkan gambar di atasnya), maka output akan mendapatkan semacam prediksi. Apa yang terjadi di dalam tidak masalah.
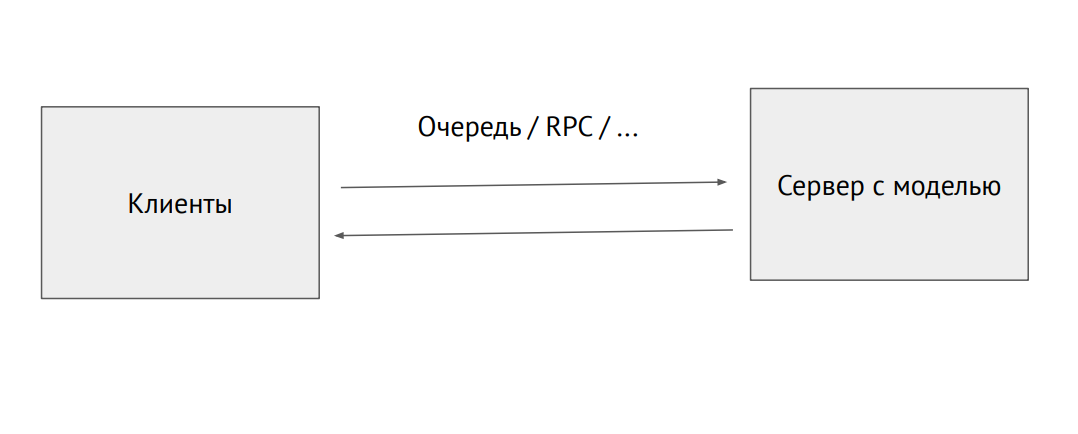 Pisahkan proses server dengan model
Pisahkan proses server dengan modelAnda juga dapat mengambil proses terpisah dan mengirimkannya melalui antrian RPC (dengan gambar atau data sumber lainnya. Pada output, kami akan menerima prediksi.
Contoh menggunakan model dalam Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
Masalah dengan pendekatan ini adalah keterbatasan kinerja. Misalkan kita memiliki kode Phyton yang ditulis oleh para ilmuwan data yang melambat, dan kami ingin memeras kinerja maksimum. Untuk melakukan ini, Anda dapat menggunakan alat yang mengubah kode menjadi asli atau mengubahnya ke kerangka kerja lain, dipertajam untuk produksi. Ada alat seperti itu untuk setiap kerangka kerja, tetapi tidak ada alat yang ideal, Anda harus menyelesaikannya sendiri.
Infrastruktur dalam ML sama dengan backend biasa. Ada Docker dan Kubernetes, hanya untuk Docker Anda perlu mengatur runtime NVIDIA, yang memungkinkan proses di dalam wadah untuk mengakses kartu video di host. Kubernetes membutuhkan plugin sehingga dapat mengelola server dengan kartu video.
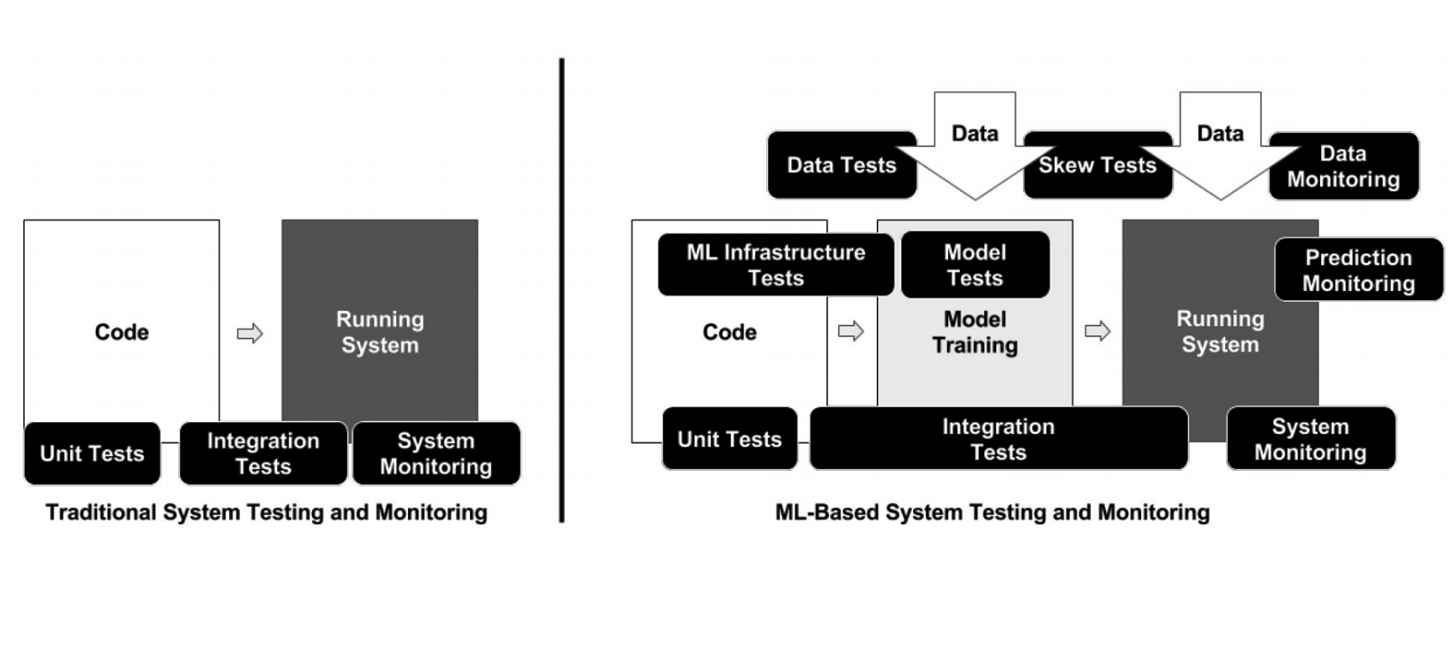
Tidak seperti pemrograman klasik, dalam kasus ML, infrastruktur memiliki banyak elemen bergerak yang berbeda yang perlu diperiksa dan diuji - misalnya, kode pemrosesan data, model pipa pelatihan dan produksi (lihat diagram di atas). Penting untuk menguji kode yang menghubungkan potongan pipa yang berbeda: ada banyak potongan, dan masalah sangat sering muncul di perbatasan modul.
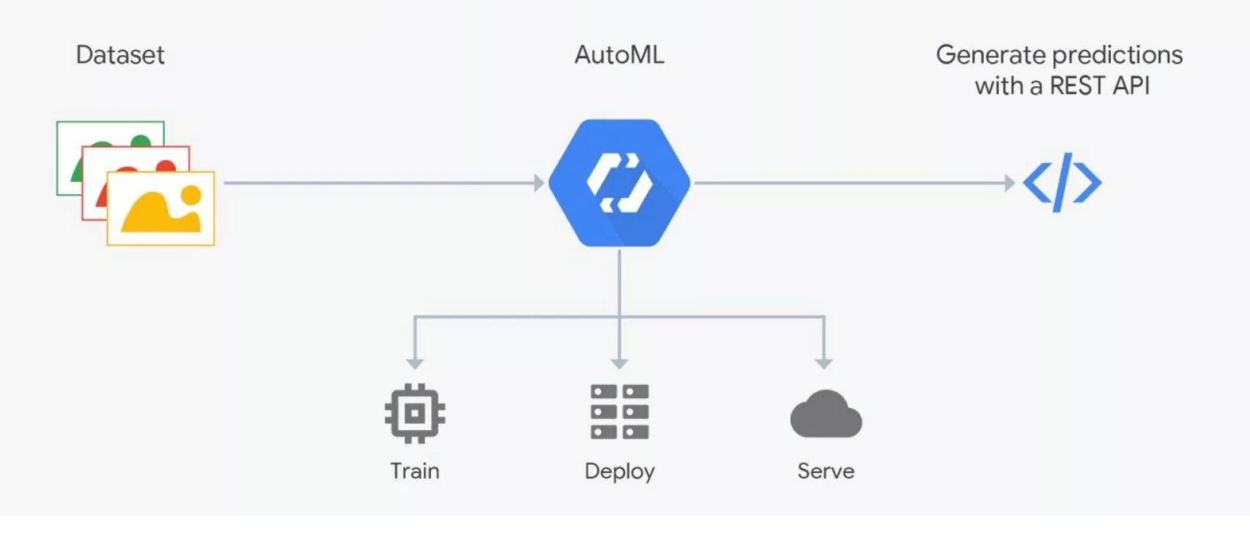 Cara Kerja AutoML
Cara Kerja AutoMLLayanan AutoML berjanji untuk memilih model terbaik untuk tujuan Anda dan melatihnya. Tetapi Anda perlu memahami: dalam data ML sangat penting, hasilnya tergantung pada persiapan mereka. Orang-orang menandai, yang penuh dengan kesalahan. Tanpa kontrol yang ketat, sampah dapat berubah, tetapi otomatisasi belum berhasil, verifikasi oleh para ahli - ilmuwan data diperlukan. Di sinilah AutoML "istirahat". Tetapi dapat berguna untuk pemilihan arsitektur - ketika Anda telah menyiapkan data dan ingin melakukan serangkaian percobaan untuk menemukan model terbaik.
Cara masuk ke pembelajaran mesin
Masuk ke ML paling mudah jika Anda berkembang di Python, yang digunakan di semua kerangka pembelajaran yang mendalam (dan kerangka kerja biasa). Bahasa ini praktis diperlukan untuk bidang kegiatan ini. C ++ digunakan untuk beberapa tugas dengan visi komputer - misalnya, dalam sistem kontrol kendaraan tak berawak. JavaScript dan Shell - untuk visualisasi dan hal-hal aneh seperti meluncurkan neuron di browser. Java dan Scala digunakan ketika bekerja dengan Big Data dan untuk pembelajaran mesin. R dan Julia dicintai oleh orang-orang yang melakukan statistik.
Mendapatkan pengalaman praktis untuk memulai adalah yang paling nyaman di Kaggle, partisipasi dalam salah satu kontes platform memberi lebih dari satu tahun mempelajari teori. Pada platform ini, Anda dapat mengambil kode seseorang yang ditata dan dikomentari dan mencoba memperbaikinya, mengoptimalkan untuk tujuan Anda. Peringkat bonus di Kaggle memengaruhi gaji Anda.
Pilihan lain adalah pergi sebagai pengembang backend ke tim ML. Sekarang ada banyak startup yang terlibat dalam pembelajaran mesin, di mana Anda mendapatkan pengalaman dengan membantu rekan kerja dalam memecahkan masalah mereka. Terakhir, Anda dapat bergabung dengan salah satu komunitas ilmuwan data - Open Data Science (ods.ai) dan lainnya.
Pembicara menempatkan informasi tambahan pada topik di https://bit.ly/backend-to-ml
"Quadrupel" - layanan pemberitahuan yang ditargetkan dari portal "Layanan Negara"

Evgeny Smirnov
Pembicara berikutnya adalah Yevgeny Smirnov, kepala departemen pengembangan infrastruktur e-government, yang berbicara tentang Quadrupel. Ini adalah layanan notifikasi yang ditargetkan dari portal Gosuslugi (gosuslugi.ru), sumber daya negara yang paling banyak dikunjungi di Internet Rusia. Pemirsa harian adalah 2,6 juta, semuanya, 90 juta pengguna terdaftar di situs, yang 60 juta di antaranya dikonfirmasi. Beban pada API portal adalah 30 ribu RPS.
 Teknologi yang digunakan dalam backend Gosuslug
Teknologi yang digunakan dalam backend Gosuslug"Quadruple" adalah layanan pemberitahuan alamat, dengan bantuan yang pengguna menerima tawaran layanan pada saat yang paling tepat baginya dengan menyiapkan aturan informasi khusus. Persyaratan utama dalam pengembangan layanan adalah pengaturan yang fleksibel dan waktu yang cukup untuk pengiriman.
Bagaimana cara Quadruple bekerja?

Diagram di atas menunjukkan salah satu aturan “Quadruple” pada contoh situasi dengan kebutuhan untuk mengganti SIM. Pertama, layanan mencari pengguna yang tanggal kedaluwarsanya habis dalam sebulan. Mereka memasang spanduk dengan tawaran untuk menerima layanan yang sesuai dan mengirim pesan email. Bagi pengguna yang sudah kedaluwarsa, spanduk dan email berubah. Setelah pertukaran hak berhasil, pengguna menerima pemberitahuan lain - dengan proposal untuk memperbarui data dalam sertifikat.
Dari sudut pandang teknis, ini adalah skrip asyik di mana kode ditulis. Pada input - data, pada output - benar / salah, cocok / tidak cocok. Secara total, lebih dari 50 aturan - mulai dari menentukan ulang tahun pengguna (tanggal saat ini sama dengan ulang tahun pengguna) hingga situasi sulit. Setiap hari, menurut aturan ini, sekitar satu juta pertandingan ditentukan - orang yang perlu diberi tahu.
 Saluran Pemberitahuan Quadruple
Saluran Pemberitahuan QuadrupleDi bawah kap Quadrupel ada database di mana data pengguna disimpan, dan tiga aplikasi:
- Pekerja dirancang untuk memperbarui data.
- API Istirahat mengambil dan memberikan spanduk sendiri ke portal dan ke aplikasi seluler.
- Penjadwal meluncurkan penghitungan ulang spanduk atau pengiriman massal.
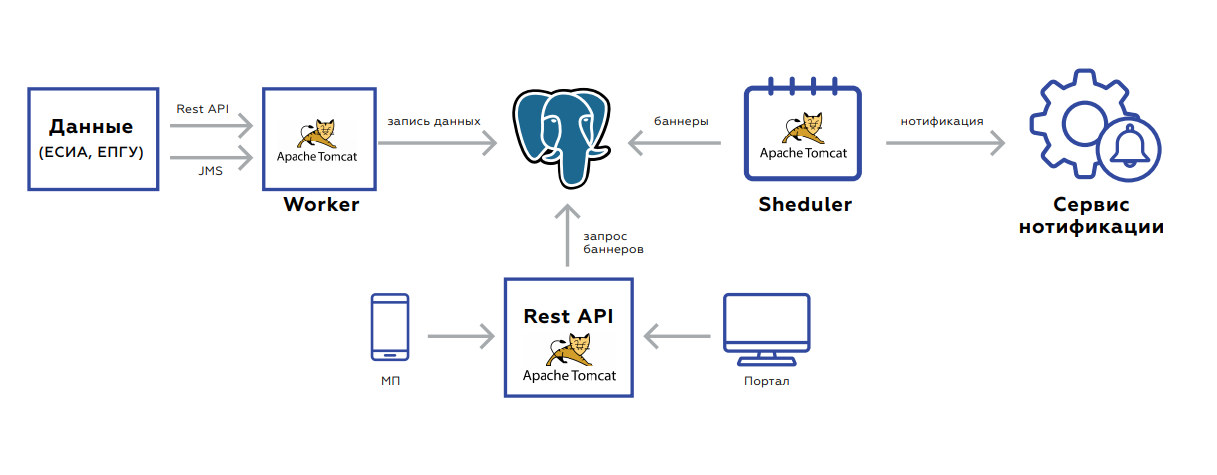
Backend berorientasi pada peristiwa untuk memperbarui data. Dua antarmuka - istirahat atau JMS. Ada banyak acara, sebelum disimpan dan diproses, mereka dikumpulkan agar tidak membuat permintaan yang tidak perlu. Basis data itu sendiri, pelat tempat data disimpan, tampak seperti penyimpanan nilai kunci - kunci pengguna dan nilai itu sendiri: bendera yang menunjukkan ada atau tidaknya dokumen yang relevan, periode validitasnya, statistik agregat pada urutan layanan oleh pengguna ini, dan sebagainya.

Setelah menyimpan data, tugas diatur dalam JMS sehingga spanduk segera dihitung ulang - ini harus segera ditampilkan di web. Sistem dimulai pada malam hari: dalam tugas JMS dilemparkan pada interval pengguna, sesuai dengan yang Anda perlu menceritakan aturan. Ini diambil oleh recounters. Selanjutnya, hasil pemrosesan jatuh ke antrian berikutnya, yang menyimpan spanduk di database, atau mengirim tugas kepada pengguna untuk memberi tahu pengguna. Proses ini memakan waktu 5-7 jam, mudah untuk diskalakan karena Anda selalu dapat menjatuhkan prosesor atau meningkatkan instans dengan prosesor baru.

Layanan bekerja dengan sangat baik. Tetapi jumlah data bertambah karena semakin banyak pengguna. Hal ini menyebabkan peningkatan beban pada basis data - bahkan dengan mempertimbangkan fakta bahwa API Istirahat sedang melihat replika. Poin kedua adalah JMS, yang, ternyata, sangat tidak cocok karena konsumsi memori yang besar. Ada risiko tinggi overflow antrian dengan crash JMS dan pemrosesan berhenti. Tidak mungkin untuk meningkatkan JMS setelah ini tanpa membersihkan log.
Direncanakan untuk memecahkan masalah menggunakan sharding, yang akan memungkinkan menyeimbangkan beban di pangkalan. Ada juga rencana untuk mengubah skema penyimpanan data, dan mengubah JMS ke Kafka - solusi yang lebih toleran terhadap kesalahan yang akan menyelesaikan masalah memori.
Backend-as-a-Service Vs. Tanpa server
 Dari kiri ke kanan: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
Dari kiri ke kanan: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara IsraelyanBackend sebagai solusi layanan atau serverless? Orang-orang berikut berpartisipasi dalam diskusi tentang masalah mendesak ini di meja bundar:
- Ara Israelyan, CTO CTO dan pendiri Scorocode.
- Nikolay Markov, Insinyur Data Senior di Aligned Research Group.
- Andrey Tomilenko, Kepala Departemen Pengembangan RUVDS.
Percakapan dimoderatori oleh pengembang senior Alexander Borgart. Kami menyajikan debat, di mana audiens berpartisipasi, dalam versi singkat.
- Apa yang dimaksud dengan Serverless dalam pemahaman Anda?
Andrei : Ini adalah model komputasi - fungsi Lambda yang harus memproses data sehingga hasilnya hanya bergantung pada data. Istilah ini berasal dari Google, atau dari Amazon dan layanan AWS Lambda. Lebih mudah bagi penyedia untuk memproses fungsi seperti itu dengan mengalokasikan kumpulan kapasitas untuk ini. Pengguna yang berbeda dapat dipertimbangkan secara mandiri di server yang sama.
Nikolay : Jika sederhana, kami mentransfer sebagian dari infrastruktur TI kami, logika bisnis ke cloud, untuk melakukan outsourcing.
Ara : Pada bagian pengembang - upaya yang baik untuk menghemat sumber daya, pada bagian dari pemasar - untuk mendapatkan lebih banyak uang.
- Serverless - sama dengan microservices?
Nikolai : Tidak, Serverless lebih merupakan organisasi arsitektur. Microservice adalah unit atom dari logika tertentu. Serverless adalah pendekatan, bukan "entitas yang terpisah."
Ara : Fungsi Serverless dapat dikemas dalam microservice, tetapi dari sini akan berhenti menjadi Serverless, berhenti menjadi fungsi Lambda. Di Serverless, suatu fungsi hanya dimulai ketika diminta.
Andrew : Mereka berbeda dalam waktu hidup. Kami meluncurkan dan melupakan fungsi Lambda. Itu berfungsi selama beberapa detik, dan klien berikutnya dapat memproses permintaannya pada mesin fisik lain.
- Timbangan mana yang lebih baik?
Ara : Dengan penskalaan horizontal, fungsi Lambda berperilaku persis sama dengan layanan microser.
Nikolai : Berapa banyak replika yang Anda tanyakan - akan ada begitu banyak, tidak ada masalah dengan penskalaan Serverless. Kubernetes membuat set replika, meluncurkan 20 contoh "di suatu tempat", dan 20 tautan anonim kembali ke Anda. Silakan!
- Apakah mungkin untuk menulis backend di Serverless?
Andrew : Secara teoritis, tetapi tidak ada gunanya dalam hal ini. Fungsi Lambda akan bersandar pada repositori tunggal - kita perlu memberikan jaminan. Misalnya, jika pengguna melakukan transaksi tertentu, maka saat berikutnya ia akan melihat: transaksi telah selesai, dana telah dikreditkan. Semua fungsi Lambda akan diblokir pada panggilan ini. Bahkan, sekelompok fungsi Serverless akan berubah menjadi satu layanan dengan satu titik sempit akses ke database.
- Dalam situasi apa masuk akal untuk menggunakan arsitektur tanpa server?
Andrew : Tugas di mana penyimpanan umum tidak diperlukan - penambangan yang sama, blockchain. Di mana Anda perlu banyak menghitung. Jika Anda memiliki banyak daya komputasi, maka Anda dapat mendefinisikan fungsi seperti "menghitung hash dari sesuatu di sana ..." Tetapi Anda dapat memecahkan masalah penyimpanan data dengan mengambil, misalnya, fungsi Amazon dan Lambda, dan penyimpanan terdistribusi mereka. Dan ternyata Anda menulis layanan reguler. Fungsi Lambda akan mengakses repositori dan memberikan semacam respons kepada pengguna.
Nikolai : Kontainer yang berjalan di Serverless sangat terbatas sumber daya. Ada sedikit memori dan yang lainnya. Tetapi jika Anda memiliki semua infrastruktur yang digunakan sepenuhnya pada beberapa jenis cloud - Google, Amazon - dan Anda memiliki kontrak permanen dengan mereka, ada anggaran untuk semua ini, maka untuk beberapa tugas Anda dapat menggunakan wadah tanpa Server. Penting untuk ditempatkan tepat di dalam infrastruktur ini, karena semuanya dirancang untuk digunakan dalam lingkungan tertentu. Artinya, jika Anda siap untuk mengikat semuanya dengan infrastruktur cloud, Anda bisa bereksperimen. Kelebihannya adalah Anda tidak harus mengelola infrastruktur ini.
Ara : Serverless itu tidak mengharuskan Anda untuk mengelola Kubernetes, Docker, menginstal Kafka, dan sebagainya, adalah penipuan diri sendiri. Amazon dan Google yang sama adalah manajer dan mereka menaruhnya. Hal lain adalah Anda memiliki SLA. Dengan kesuksesan yang sama, Anda dapat melakukan outsourcing semua, dan tidak memprogramnya sendiri.
Andrew : Serverless itu sendiri tidak mahal, tetapi Anda harus membayar banyak untuk sisa layanan Amazon - misalnya, database. Orang-orang sudah menggugat mereka karena fakta bahwa mereka merobek uang gila untuk gerbang API.
Ara : Jika kita berbicara tentang uang, maka Anda perlu mempertimbangkan hal ini: Anda harus menggunakan 180 derajat seluruh metodologi pengembangan di perusahaan untuk mentransfer semua kode ke Serverless. Itu akan memakan banyak waktu dan uang.
- Apakah ada alternatif yang layak untuk Amazon Serverless dan Google berbayar?
Nikolay : Di Kubernetes, Anda memulai beberapa jenis pekerjaan, memenuhi dan mati - ini cukup Serverless dari sudut pandang arsitektur. Jika Anda ingin membuat logika bisnis yang benar-benar menarik dengan antrian, dengan basis, maka Anda perlu berpikir lebih banyak tentangnya. Ini semua diselesaikan tanpa meninggalkan Kubernetes. Saya tidak akan mulai menyeret implementasi tambahan.
- Seberapa pentingkah untuk memantau apa yang terjadi di Serverless?
Ara : Tergantung pada arsitektur sistem dan persyaratan bisnis. Bahkan, penyedia harus menyediakan laporan yang akan membantu devo mengetahui kemungkinan masalah.
Nikolai : Di Amazon ada CloudWatch, tempat semua log dialirkan, termasuk dengan Lambda. Integrasikan penerusan log dan gunakan beberapa alat terpisah untuk melihat, mengingatkan, dan sebagainya. Dalam wadah yang Anda mulai, Anda bisa menjejalkan agen.
 - Mari kita simpulkan.
- Mari kita simpulkan.
Andrew : Memikirkan fungsi Lambda bermanfaat. Jika Anda membuat layanan dengan lutut - bukan layanan microser, tetapi layanan yang menulis permintaan, mengakses database dan mengirim jawaban - fungsi Lambda memecahkan sejumlah masalah: multithreading, skalabilitas, dan banyak lagi. Jika logika Anda dibangun dengan cara ini, maka di masa depan Anda akan dapat mentransfer Lambda ini ke layanan microser atau menggunakan layanan pihak ketiga seperti Amazon. Teknologi ini bermanfaat, ide yang menarik. Berapa banyak dibenarkan untuk bisnis masih merupakan pertanyaan terbuka.
Nikolai: Serverless lebih baik digunakan untuk operasi-tugas daripada menghitung semacam logika bisnis. Saya selalu menganggap ini sebagai pemrosesan acara. Jika Anda memilikinya di Amazon, jika Anda berada di Kubernetes - ya. Jika tidak, Anda harus melakukan banyak upaya untuk meningkatkan Serverless sendiri. Anda perlu menonton kasus bisnis tertentu. Sebagai contoh, saya memiliki salah satu tugas sekarang: ketika file muncul pada disk dalam format tertentu, Anda perlu mengunggahnya ke Kafka. Saya bisa menggunakan WatchDog atau Lambda ini. Secara logis, keduanya cocok, tetapi Serverless lebih sulit untuk diimplementasikan, dan saya lebih suka cara yang lebih sederhana, tanpa Lambda.
Ara : Serverless - ide yang menarik, dapat diterapkan, sangat indah secara teknis. Cepat atau lambat, teknologi akan mencapai titik di mana fungsi apa pun akan naik dalam waktu kurang dari 100 milidetik. Kemudian, pada prinsipnya, tidak akan ada pertanyaan apakah waktu tunggu sangat penting bagi pengguna. Pada saat yang sama, penerapan Serverless, seperti yang telah dikatakan rekan kerja, sepenuhnya tergantung pada tugas bisnis.
Kami berterima kasih kepada para sponsor kami yang telah banyak membantu kami:
- Ruang konferensi TI " Spring " di belakang platform untuk konferensi.
- Kalender acara TI Runet-ID dan publikasi " Internet dalam angka " untuk dukungan informasi dan berita.
- Akronis untuk hadiah.
- Avito untuk kreasi bersama.
- RAEC "Asosiasi Komunikasi Elektronik" untuk keterlibatan dan pengalaman.
- Sponsor utama RUVDS - untuk semuanya!
