
Halo, Habr! Saya memimpin pengembangan platform
Visi - ini adalah platform publik kami, yang menyediakan akses ke model visi komputer dan memungkinkan Anda untuk menyelesaikan tugas-tugas seperti mengenali wajah, angka, objek, dan seluruh adegan. Dan hari ini saya ingin memberi tahu dengan contoh Visi bagaimana mengimplementasikan layanan yang cepat dan penuh muatan menggunakan kartu video, cara menggunakan dan mengoperasikannya.
Apa itu Visi?
Ini pada dasarnya adalah REST API. Pengguna menghasilkan permintaan HTTP dengan foto dan mengirimkannya ke server.
Misalkan Anda perlu mengenali wajah dalam sebuah gambar. Sistem menemukannya, memotongnya, mengekstrak beberapa properti dari wajah, menyimpannya di database dan memberikan nomor bersyarat. Misalnya, orang42. Pengguna kemudian mengunggah foto berikutnya, yang memiliki orang yang sama. Sistem mengekstrak properti dari wajahnya, mencari basis data dan mengembalikan nomor bersyarat yang ditugaskan untuk orang tersebut pada awalnya, yaitu orang42.
Saat ini, pengguna utama Visi adalah berbagai proyek dari Grup Mail.ru. Sebagian besar permintaan datang dari Mail dan Cloud.
Di Cloud, pengguna memiliki folder tempat foto diunggah. Cloud menjalankan file melalui Visi dan mengelompokkannya ke dalam kategori. Setelah itu, pengguna dapat dengan mudah membolak-balik foto-fotonya. Misalnya, ketika Anda ingin menunjukkan foto kepada teman atau keluarga, Anda dapat dengan cepat menemukan yang Anda butuhkan.
Baik Mail dan Cloud adalah layanan yang sangat besar dengan jutaan orang, sehingga Visi memproses ratusan ribu permintaan per menit. Artinya, ini adalah layanan klasik yang sarat muatan, tetapi dengan twist: ia memiliki nginx, server web, database, dan antrian, tetapi pada level terendah layanan ini adalah inferensi - menjalankan gambar melalui jaringan saraf. Ini adalah jalannya jaringan saraf yang menghabiskan sebagian besar waktu dan membutuhkan sumber daya. Jaringan komputer terdiri dari serangkaian operasi matriks yang biasanya memakan waktu lama pada CPU, tetapi semuanya diparalelkan dengan sempurna pada GPU. Untuk menjalankan jaringan secara efektif, kami menggunakan sekelompok server dengan kartu video.
Pada artikel ini saya ingin berbagi sekumpulan tips yang dapat berguna saat membuat layanan seperti itu.
Pengembangan Layanan
Waktu pemrosesan untuk satu permintaan
Untuk sistem dengan beban berat, waktu pemrosesan satu permintaan dan throughput sistem penting. Kecepatan tinggi pemrosesan query disediakan, pertama-tama, dengan pemilihan arsitektur jaringan saraf yang benar. Dalam ML, seperti pada tugas pemrograman lainnya, tugas yang sama dapat diselesaikan dengan cara yang berbeda. Mari kita deteksi wajah: untuk mengatasi masalah ini, pertama-tama kita mengambil jaringan saraf dengan arsitektur R-FCN. Mereka menunjukkan kualitas yang cukup tinggi, tetapi mengambil sekitar 40 ms pada satu gambar, yang tidak sesuai dengan kita.Kemudian kita beralih ke arsitektur MTCNN dan mendapat peningkatan dua kali lipat dalam kecepatan dengan sedikit kehilangan kualitas.
Kadang-kadang, untuk mengoptimalkan waktu komputasi jaringan saraf, mungkin menguntungkan untuk menerapkan inferensi dalam kerangka kerja lain, bukan dalam kerangka yang diajarkan. Misalnya, terkadang masuk akal untuk mengonversi model Anda ke NVIDIA TensorRT. Ini menerapkan sejumlah optimasi dan sangat baik pada model yang agak rumit. Misalnya, entah bagaimana dapat mengatur ulang beberapa lapisan, menggabungkan dan bahkan membuangnya; hasilnya tidak akan berubah, dan kecepatan perhitungan inferensi akan meningkat. TensorRT juga memungkinkan Anda untuk mengelola memori dengan lebih baik dan, setelah beberapa trik, dapat menguranginya menjadi penghitungan angka dengan akurasi yang lebih rendah, yang juga meningkatkan kecepatan penghitungan inferensi.
Unduh kartu video
Kesimpulan jaringan dilakukan pada GPU, kartu video adalah bagian paling mahal dari server, jadi penting untuk menggunakannya seefisien mungkin. Bagaimana cara memahami, sudahkah kita memuat GPU sepenuhnya atau dapatkah kita menambah beban? Pertanyaan ini dapat dijawab, misalnya, menggunakan parameter Utilisasi GPU di utilitas nvidia-smi dari paket driver video standar. Angka ini, tentu saja, tidak menunjukkan berapa banyak core CUDA yang dimuat secara langsung pada kartu video, tetapi berapa banyak yang menganggur, tetapi itu memungkinkan Anda untuk entah bagaimana mengevaluasi pemuatan GPU. Dari pengalaman, kita dapat mengatakan bahwa pemuatan 80-90% baik. Jika dimuat 10-20%, maka ini buruk, dan masih ada potensi.
Konsekuensi penting dari pengamatan ini: Anda perlu mencoba mengatur sistem untuk memaksimalkan pemuatan kartu video. Selain itu, jika Anda memiliki 10 kartu video, yang masing-masing dimuat pada 10-20%, maka, kemungkinan besar, dua kartu video beban tinggi dapat menyelesaikan masalah yang sama.
Throughput sistem
Ketika Anda mengirimkan gambar ke input jaringan saraf, pemrosesan gambar dikurangi menjadi berbagai operasi matriks. Kartu video adalah sistem multi-core, dan gambar input yang biasanya kami kirimkan berukuran kecil. Katakanlah ada 1.000 core pada kartu video kami, dan kami memiliki 250 x 250 piksel dalam gambar. Sendiri, mereka tidak akan dapat memuat semua core karena ukurannya yang sederhana. Dan jika kami mengirimkan gambar-gambar tersebut ke model satu per satu, maka memuat kartu video tidak akan melebihi 25%.
Oleh karena itu, Anda perlu mengunggah beberapa gambar untuk menyimpulkan sekaligus dan membentuk batch dari mereka.
Dalam hal ini, beban kartu video naik menjadi 95%, dan perhitungan inferensi akan memakan waktu seperti untuk satu gambar.
Tetapi bagaimana jika tidak ada 10 gambar dalam antrian sehingga kita dapat menggabungkannya menjadi satu batch? Anda bisa menunggu sedikit, misalnya, 50-100 ms dengan harapan permintaan akan datang. Strategi ini disebut strategi memperbaiki latensi. Ini memungkinkan Anda untuk menggabungkan permintaan dari klien dalam buffer internal. Sebagai hasilnya, kami meningkatkan penundaan kami dengan jumlah tetap, tetapi secara signifikan meningkatkan throughput sistem.
Luncurkan inferensi
Kami melatih model pada gambar dengan format dan ukuran tetap (misalnya, 200 x 200 piksel), tetapi layanan harus mendukung kemampuan untuk mengunggah berbagai gambar. Oleh karena itu, semua gambar sebelum mengirimkan kesimpulan, Anda perlu mempersiapkan dengan benar (mengubah ukuran, memusatkan, menormalkan, menerjemahkan ke float, dll.). Jika semua operasi ini dilakukan dalam proses yang meluncurkan inferensi, maka siklus kerjanya akan terlihat seperti ini:
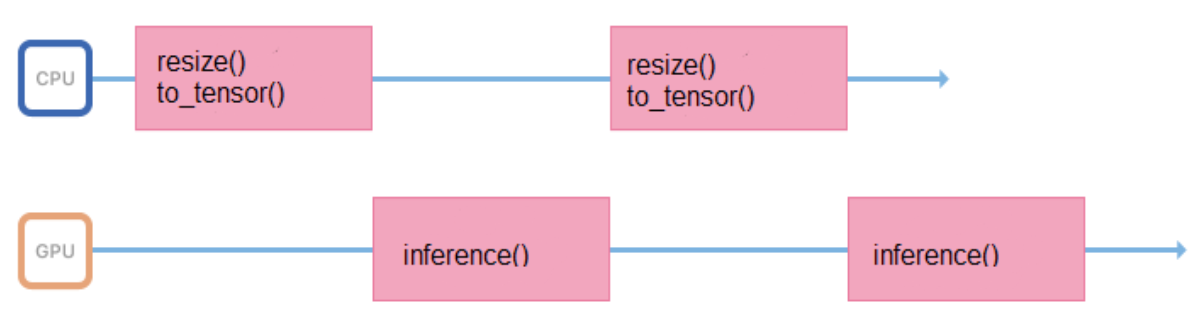
Dia menghabiskan waktu di prosesor, menyiapkan data input, untuk beberapa waktu menunggu jawaban dari GPU. Lebih baik meminimalkan interval antar inferensi sehingga GPU lebih sedikit menganggur.
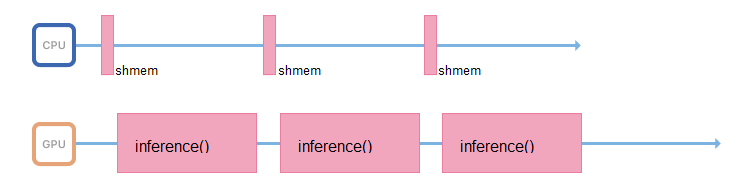
Untuk melakukan ini, Anda dapat memulai streaming lain, atau mentransfer persiapan gambar ke server lain, tanpa kartu video, tetapi dengan prosesor yang kuat.
Jika memungkinkan, proses yang bertanggung jawab untuk inferensi harus hanya berurusan dengan itu: mengakses memori bersama, mengumpulkan data input, segera menyalinnya ke memori kartu video dan menjalankan inferensi.
Turbo boost
Meluncurkan jaringan saraf adalah operasi yang menggunakan sumber daya tidak hanya dari GPU, tetapi juga dari prosesor. Bahkan jika semuanya diatur dengan benar dalam hal bandwidth, dan utas yang melakukan inferensi sudah menunggu data baru, pada prosesor yang lemah Anda tidak akan punya waktu untuk menjenuhkan aliran ini dengan data baru.
Banyak prosesor mendukung teknologi Turbo Boost. Ini memungkinkan Anda untuk meningkatkan frekuensi prosesor, tetapi tidak selalu diaktifkan secara default. Ada baiknya memeriksanya. Untuk ini, Linux memiliki utilitas Power CPU:
$ cpupower frequency-info -m .
Prosesor juga memiliki mode konsumsi daya yang dapat dikenali oleh perintah CPU Power:
performance .
Dalam mode hemat daya, prosesor dapat membatasi frekuensi dan berjalan lebih lambat. Anda harus masuk ke BIOS dan memilih mode kinerja. Maka prosesor akan selalu bekerja pada frekuensi maksimum.
Penerapan Aplikasi
Docker sangat bagus untuk menyebarkan aplikasi, memungkinkan Anda untuk menjalankan aplikasi pada GPU di dalam wadah. Untuk mengakses kartu video, pertama-tama Anda perlu menginstal driver untuk kartu video pada sistem host - server fisik. Kemudian, untuk memulai wadah, Anda perlu melakukan banyak pekerjaan manual: dengan benar melemparkan kartu video ke dalam wadah dengan parameter yang tepat. Setelah memulai wadah, masih perlu menginstal driver video di dalamnya. Dan hanya setelah itu Anda dapat menggunakan aplikasi Anda.

Pendekatan ini memiliki satu peringatan. Server dapat menghilang dari cluster dan ditambahkan. Ada kemungkinan bahwa server yang berbeda akan memiliki versi driver yang berbeda, dan mereka akan berbeda dari versi yang diinstal di dalam wadah. Dalam hal ini, Docker sederhana akan rusak: aplikasi akan menerima kesalahan ketidakcocokan versi driver ketika mencoba mengakses kartu video.

Bagaimana cara mengatasinya? Ada versi Docker dari NVIDIA, berkat itu menjadi lebih mudah dan lebih menyenangkan untuk menggunakan wadah. Menurut NVIDIA itu sendiri dan menurut pengamatan praktis, biaya penggunaan nvidia-docker sekitar 1%.
Dalam hal ini, driver harus diinstal hanya pada mesin host. Saat memulai wadah, Anda tidak perlu membuang apa pun di dalam, dan aplikasi akan segera memiliki akses ke kartu video.

"Kemandirian" nvidia-docker dari driver memungkinkan Anda untuk menjalankan wadah dari gambar yang sama pada mesin yang berbeda di mana berbagai versi driver diinstal. Bagaimana ini diterapkan? Docker memiliki konsep yang disebut docker-runtime: ini adalah sekumpulan standar yang menjelaskan bagaimana suatu wadah harus berkomunikasi dengan kernel host, bagaimana ia harus memulai dan berhenti, bagaimana berinteraksi dengan kernel dan driver. Dimulai dengan versi Docker tertentu, dimungkinkan untuk mengganti runtime ini. Inilah yang dilakukan NVIDIA: mereka mengganti runtime, menangkap panggilan ke driver video di dalam dan mengonversi versi yang benar menjadi panggilan ke driver video.
Orkestrasi
Kami memilih Kubernetes sebagai orkestra. Ini mendukung banyak fitur yang sangat bagus yang berguna untuk sistem yang sarat muatan. Misalnya, autodiscovering memungkinkan layanan untuk mengakses satu sama lain dalam sebuah cluster tanpa aturan routing yang rumit. Atau toleransi kesalahan - ketika Kubernetes selalu menyiapkan beberapa wadah, dan jika sesuatu terjadi pada Anda, Kubernetes akan segera meluncurkan wadah baru.
Jika Anda sudah mengonfigurasi kluster Kubernetes, maka Anda tidak perlu banyak menggunakan kartu video di dalam kluster:
- driver yang relatif baru
- menginstal nvidia-docker versi 2
- runtime docker diatur secara default ke `nvidia` di /etc/docker/daemon.json:
"default-runtime": "nvidia"
- Plugin terinstal,
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
Setelah mengkonfigurasi cluster dan menginstal plugin perangkat, Anda dapat menentukan kartu video sebagai sumber daya.
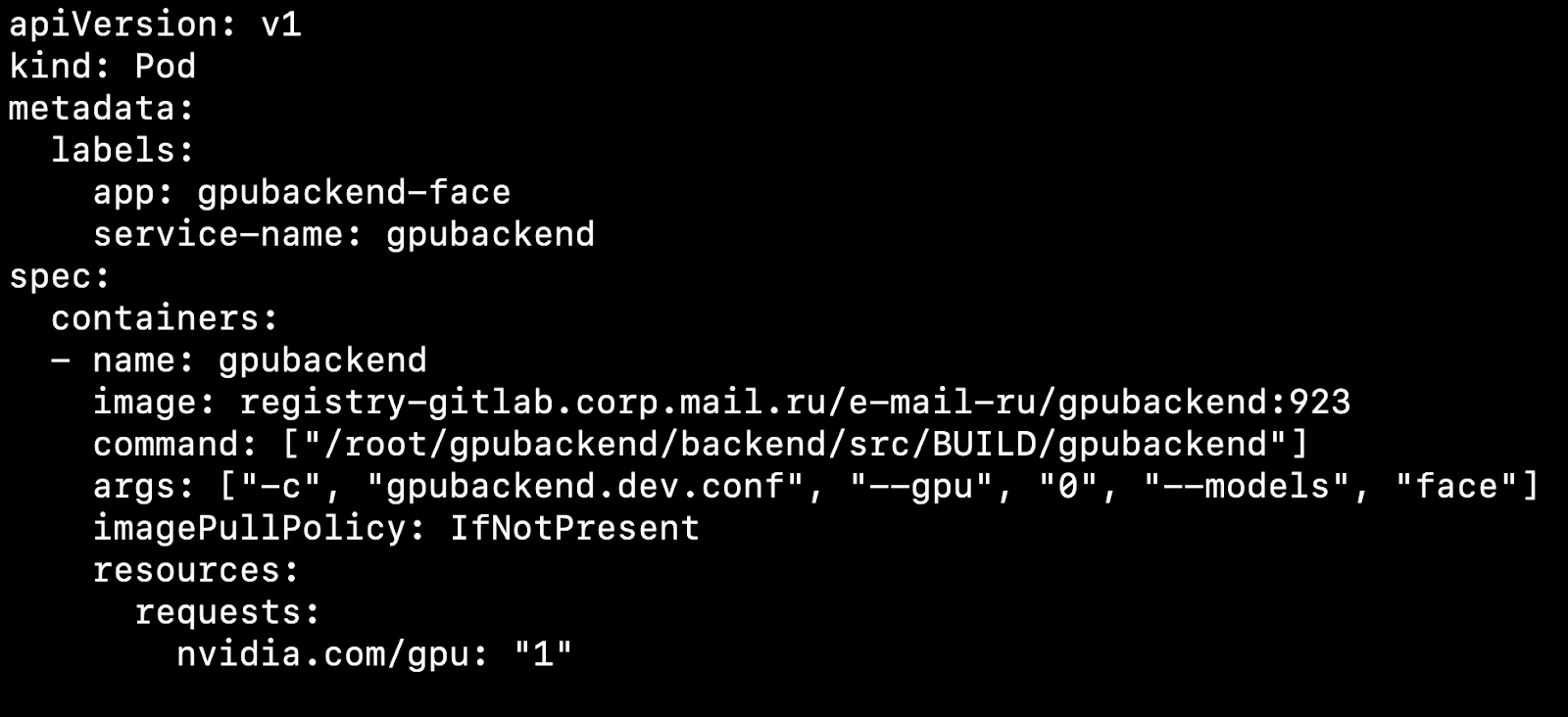
Apa pengaruhnya? Katakanlah kita memiliki dua node, mesin fisik. Di satu ada kartu video, di sisi lain tidak. Kubernetes akan mendeteksi mesin dengan kartu video dan mengambil pod kami di atasnya.
Penting untuk dicatat bahwa Kubernetes tidak tahu cara kompeten meraba-raba kartu video di antara pod. Jika Anda memiliki 4 kartu video dan Anda membutuhkan 1 GPU untuk memulai wadah, maka Anda tidak dapat menaikkan lebih dari 4 pod pada kluster Anda.
Kami mengambil aturan 1 Pod = 1 Model = 1 GPU.
Ada opsi untuk menjalankan lebih banyak instance pada 4 kartu video, tetapi kami tidak akan mempertimbangkannya dalam artikel ini, karena opsi ini tidak keluar dari kotak.
Jika beberapa model harus berputar sekaligus, akan lebih mudah untuk membuat Penempatan di Kubernetes untuk setiap model. Dalam file konfigurasinya, Anda dapat menentukan jumlah perapian untuk setiap model, dengan mempertimbangkan popularitas model. Jika banyak permintaan datang ke model, maka Anda perlu menentukan banyak pod untuk itu, jika ada beberapa permintaan, ada beberapa pod. Secara total, jumlah perapian harus sama dengan jumlah kartu video di cluster.
Pertimbangkan hal yang menarik. Katakanlah kita memiliki 4 kartu video dan 3 model.
Pada dua kartu video pertama, biarkan inferensi model pengenalan wajah meningkat, pada pengenalan objek lain dan pada pengakuan lain pada nomor mobil.
Anda bekerja, klien datang dan pergi, dan sekali, misalnya pada malam hari, situasi muncul ketika kartu video dengan objek inferensi tidak dimuat, sejumlah kecil permintaan datang ke sana, dan kartu video dengan pengenalan wajah kelebihan beban. Saya ingin mengeluarkan model dengan objek pada saat ini dan meluncurkan wajah di tempatnya untuk menurunkan garis.
Untuk penskalaan otomatis model pada kartu video, ada alat di dalam Kubernetes - penskalaan otomatis hearth horizontal (HPA, autoscaler pod horizontal).
Out of the box, Kubernetes mendukung penskalaan otomatis pada pemanfaatan CPU. Tetapi dalam tugas dengan kartu video akan jauh lebih masuk akal untuk menggunakan informasi tentang jumlah tugas untuk setiap model untuk penskalaan.
Kami melakukan ini: menempatkan permintaan untuk setiap model dalam antrian. Ketika permintaan selesai, kami menghapusnya dari antrian ini. Jika kami berhasil memproses permintaan model-model populer dengan cepat, maka antrian tidak bertambah. Jika jumlah permintaan untuk model tertentu tiba-tiba meningkat, maka antrian mulai bertambah. Menjadi jelas bahwa Anda perlu menambahkan kartu video yang akan membantu menyapu garis.
Informasi tentang antrian yang kami proksi melalui HPA melalui Prometheus:
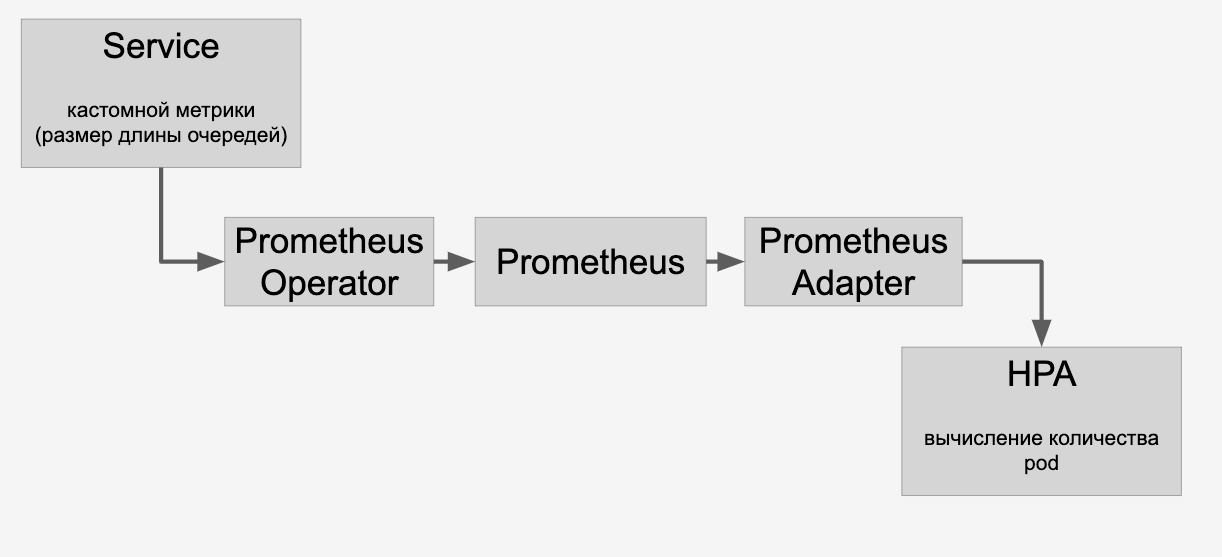
Dan kemudian kami melakukan penskalaan otomatis model pada kartu video di kluster tergantung pada jumlah permintaan kepada mereka.
CI / CD
Setelah Anda melampirkan aplikasi dan membungkusnya dalam Kubernetes, Anda benar-benar memiliki satu langkah tersisa ke atas proyek. Anda dapat menambahkan CI / CD, berikut ini adalah contoh dari pipeline kami:
Di sini programmer meluncurkan kode baru ke cabang master, setelah itu gambar Docker dengan daemon backend kami dikumpulkan secara otomatis dan tes dijalankan. Jika semua tanda centang berwarna hijau, maka aplikasi dituangkan ke lingkungan pengujian. Jika tidak ada masalah di dalamnya, maka Anda dapat mengirim gambar ke dalam operasi tanpa kesulitan.
Kesimpulan
Dalam artikel saya, saya menyentuh beberapa aspek pekerjaan dari layanan yang sangat banyak menggunakan GPU. Kami berbicara tentang cara untuk mengurangi waktu respons suatu layanan, seperti:
- pemilihan arsitektur jaringan saraf optimal untuk mengurangi latensi;
- Aplikasi kerangka kerja optimalisasi seperti TensorRT.
Mengangkat masalah peningkatan throughput:
- penggunaan batching gambar;
- menerapkan strategi perbaikan latensi sehingga jumlah inferensi berjalan berkurang, tetapi setiap inferensi akan memproses lebih banyak gambar;
- optimalisasi jalur input data untuk meminimalkan waktu henti GPU;
- "Fight" dengan pelacakan prosesor, penghapusan operasi cpu-terikat ke server lain.
Kami melihat proses penerapan aplikasi dengan GPU:
- Menggunakan nvidia-docker di dalam Kubernetes
- penskalaan berdasarkan jumlah permintaan dan HPA (horizontal pod autoscaler).