Artikel ini akan membahas klasifikasi nada suara dari pesan teks dalam bahasa Rusia (dan pada dasarnya setiap klasifikasi teks menggunakan teknologi yang sama). Kami akan mengambil artikel
ini sebagai dasar, di mana klasifikasi nada suara pada arsitektur CNN menggunakan model Word2vec dipertimbangkan. Dalam contoh kami, kami akan memecahkan masalah yang sama dengan memisahkan tweet menjadi positif dan negatif pada dataset yang sama menggunakan model
ULMFit . Hasil dari artikel (rata-rata skor F1 = 0,78142) akan diterima sebagai garis dasar.
Pendahuluan
Model ULMFIT diperkenalkan oleh pengembang fast.ai (Jeremy Howard, Sebastian Ruder) pada tahun 2018. Inti dari pendekatan ini adalah menggunakan pembelajaran transfer dalam tugas-tugas NLP ketika Anda menggunakan model pra-terlatih, mengurangi waktu untuk melatih model Anda dan mengurangi persyaratan untuk ukuran sampel uji berlabel.
Skema pelatihan dalam kasus kami akan terlihat seperti ini:

Arti model bahasa adalah untuk dapat memprediksi kata berikutnya secara berurutan. Memang bermasalah untuk mendapatkan teks yang lama terhubung dengan cara ini, namun demikian, model bahasa dapat menangkap sifat-sifat bahasa, memahami konteks penggunaan kata-kata, oleh karena itu model bahasa (dan bukan, misalnya tampilan vektor kata-kata) yang merupakan dasar teknologi. Untuk tugas pemodelan bahasa, ULMFit menggunakan arsitektur
AWD-LSTM , yang melibatkan penggunaan aktif dropout sedapat mungkin dan masuk akal. Jenis pelatihan model bahasa kadang-kadang disebut pembelajaran semi-diawasi, karena label di sini adalah kata berikutnya dan Anda tidak perlu menandai apa pun dengan tangan Anda.
Sebagai model bahasa pra-terlatih, kami akan menggunakan hampir satu-satunya yang
tersedia untuk umum.
Mari kita telusuri algoritma pembelajaran dari awal.
Kami memuat perpustakaan (kami memeriksa versi Fast.ai jika ada ketidaksesuaian):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
Kami menyiapkan data untuk pelatihan
Dengan analogi, kami akan melakukan pelatihan tentang
teks singkat RuTweetCorp oleh Yulia Rubtsova , yang dibentuk berdasarkan pesan-pesan berbahasa Rusia dari Twitter. Tubuh berisi 114.991 tweet positif dan 111.923 tweet negatif dalam format CSV. Selain itu, ada database tweet yang tidak terisi dengan volume 17 639 674 catatan dalam format SQL. Tugas classifier kami adalah menentukan apakah tweet itu positif atau negatif.
Karena
itu adalah waktu yang lama untuk melatih kembali model bahasa pada 17 juta tweet dan tugas menunjukkan pembelajaran transfer adalah
kemalasan , kami akan melatih model bahasa pada selembar teks dari set data pelatihan, sama sekali mengabaikan basis tweet yang tidak terisi. Mungkin, dengan menggunakan basis ini untuk "mengasah" model bahasa, Anda dapat meningkatkan hasil keseluruhan.
Kami membentuk kumpulan data untuk pelatihan dan pengujian dengan pengolah kata pendahuluan. Kami mengambil kode dari artikel
asli :
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
Kami melihat apa yang terjadi:
df_train.groupby('Label').count()
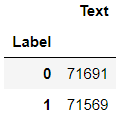
df_val.groupby('Label').count()
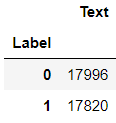
df_test.groupby('Label').count()

Belajar model bahasa
Memuat data:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
Kami melihat isinya:
data_lm.show_batch()

Kami menyediakan tautan ke bobot tersimpan dari model yang
sudah dilatih sebelumnya dan kamus:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
Kami membuat pelajar, tetapi sebelum itu - satu kruk untuk fast.ai. Model pra-terlatih dilatih pada versi perpustakaan yang lebih lama, jadi Anda perlu menyesuaikan jumlah node di lapisan tersembunyi dari jaringan saraf.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
Kami mencari tingkat pembelajaran yang optimal:
learn_lm.lr_find() learn_lm.recorder.plot()

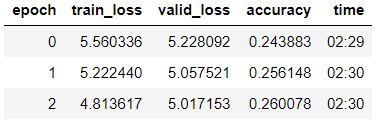
Kami melatih model era ke-3 (dalam model, hanya kelompok lapisan terakhir yang tidak dibekukan).
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
Mencairkan model, mengajar 5 era lagi dengan tingkat belajar yang lebih rendah:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
Kami mencoba membuat teks pada model yang terlatih.
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
Kami melihat - sesuatu yang dilakukan model. Tetapi tugas utama kami adalah klasifikasi, dan untuk solusinya kami akan mengambil encoder dari model.
learn_lm.save_encoder('ft_enc')
Kami melatih penggolongnya
Unduh data untuk pelatihan
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
Mari kita lihat data, kita melihat bahwa label berhasil dihitung (0 berarti negatif, dan 1 berarti komentar positif):
data_clas.show_batch()

Buat pelajar dengan kruk yang serupa:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
Kami memuat encoder yang dilatih pada tahap sebelumnya dan membekukan model, kecuali untuk kelompok bobot terakhir:
learn.load_encoder('ft_enc') learn.freeze()
Kami mencari tingkat pembelajaran yang optimal:
learn.lr_find() learn.recorder.plot(skip_start=0)

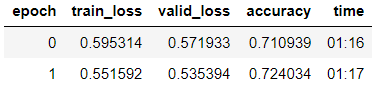
Kami melatih model dengan pencairan lapisan secara bertahap.
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
Kami melihat bahwa pada sampel validasi mereka mencapai akurasi = 80,1%.
Kami akan menguji model pada komentar
ZlodeiBaal pada artikel saya sebelumnya:
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
Kami melihat bahwa model mengaitkan komentar ini dengan negatif :-)
Memeriksa model pada sampel uji
Tugas utama pada tahap ini adalah menguji model untuk kemampuan generalisasi. Untuk melakukan ini, kami memvalidasi model pada dataset yang disimpan dalam DataFrame df_test, yang sampai saat itu tidak tersedia untuk model bahasa atau untuk pengklasifikasi.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
Kami melihat bahwa akurasi pada sampel uji ternyata 79,7%.
Lihatlah Confusion Matrix:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
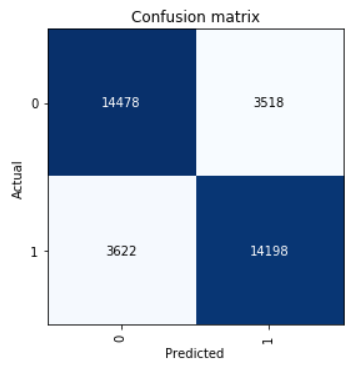
Kami menghitung parameter skor precision, recall, dan f1.
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
Hasil yang ditunjukkan dalam sampel uji rata-rata skor-F1 = 0,80064.
Bobot model yang disimpan dapat diambil di
sini .