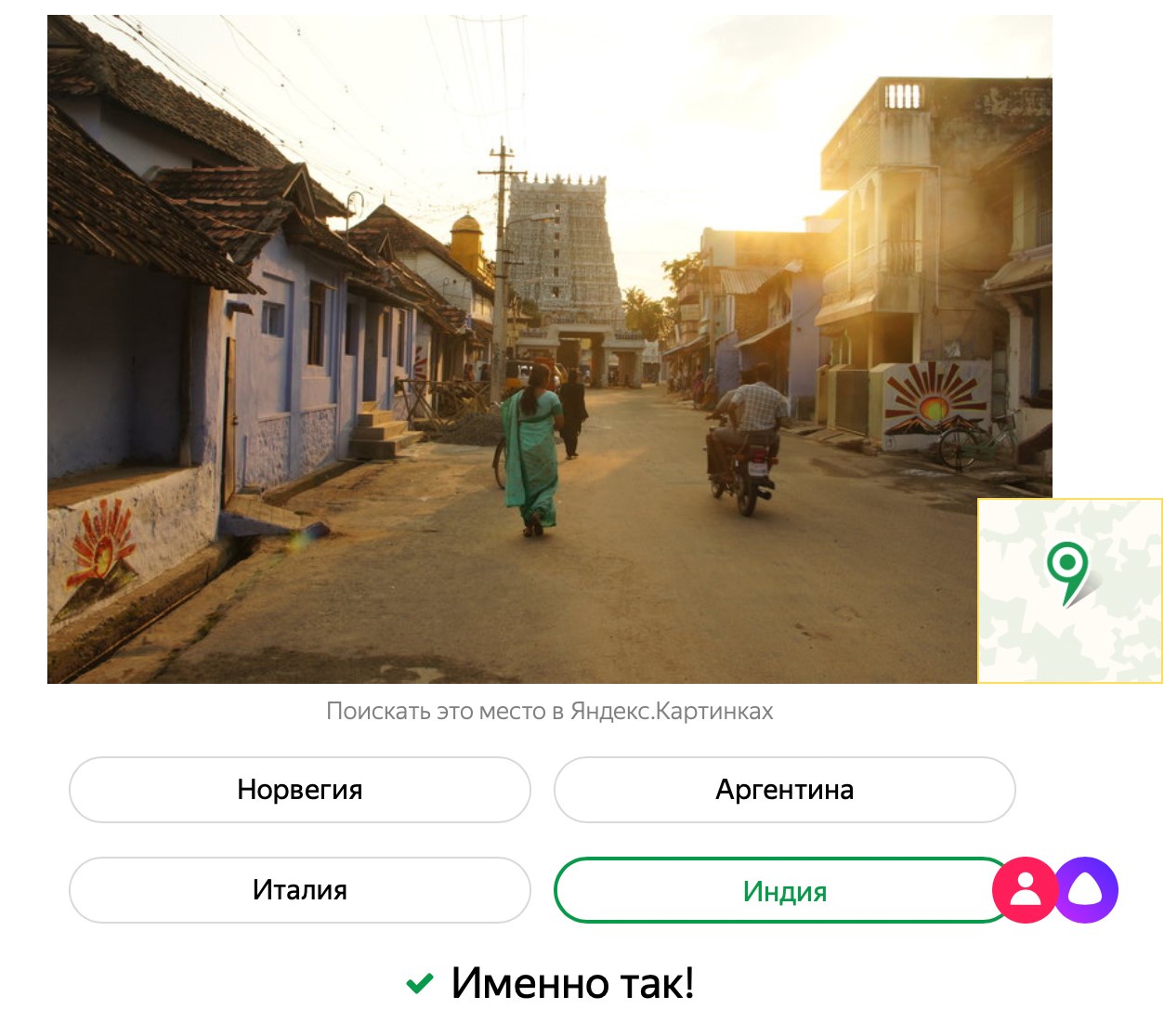
Hai Nama saya Evgeny Kashin, dan saya bekerja di laboratorium intelijen mesin Yandex. Kami baru-baru ini meluncurkan game di mana pengguna bersaing dengan Alice di negara-negara yang menebak dari foto.
Bagaimana orang bertindak dapat dimengerti: mereka mengenali tempat yang telah mereka lihat dalam perjalanan atau dalam film, bergantung pada pengetahuan dan akal sehat. Jaringan saraf tidak memiliki ini. Kami bertanya-tanya detail apa dalam gambar yang memberikan jawabannya. Kami melakukan penelitian, yang hasilnya hari ini akan kami bagikan dengan Habr.
Posting ini akan menarik baik untuk spesialis di bidang visi komputer, dan untuk semua orang yang ingin melihat ke dalam "kecerdasan buatan" dan memahami logika kerjanya.

Beberapa kata tentang permainan "
Tebak negara dengan foto ." Singkatnya, kami mengambil foto dari Yandex.Maps dan membaginya menjadi dua kelompok. Kelompok pertama ditunjukkan oleh jaringan saraf, mengatakan di mana masing-masing tembakan diambil. Setelah meninjau ribuan foto, jaringan saraf membuat ide masing-masing negara - yaitu, secara independen mengidentifikasi kombinasi tanda-tanda yang dapat dikenali. Kami menggunakan kelompok gambar kedua dalam permainan, Alice tidak melihat mereka dan tidak mengingatnya selama pertandingan. Alice bermain dengan baik, tetapi orang-orang memiliki keuntungan: kami tidak melatih jaringan saraf untuk mengenali nomor mesin, teks tanda dan tanda, bendera negara.
Untuk permainan, kami melatih model untuk memprediksi negara dari satu foto. Kami mengambil model visi komputer
SE-ResNeXt-101 , yang sudah
dilatih sebelumnya pada banyak tugas. Tanda-tanda yang diperoleh dari gambar menggunakan jaringan saraf convolutional ini cukup universal, jadi untuk pengelompokan negara itu perlu menambahkan hanya beberapa lapisan tambahan (yang disebut kepala). Data Yandex.Mart digunakan untuk pelatihan: sekitar 2,5 juta foto. Banyak gambar yang tidak sesuai dengan permainan sesuai dengan kriteria keindahan dan disaring. Keindahan dipahami sebagai kombinasi faktor: kualitas foto, keberadaan orang, teks, hutan, laut. Gambar yang sama dihapus dari tempat yang sama sehingga model tidak ingat pemandangan tertentu. Setelah semua pemfilteran, sekitar 1 juta foto tetap ada. Setelah melatih model tentang data ini, kami mendapat penggolong yang cukup akurat, yang menentukan negara hanya dengan foto, tanpa menggunakan informasi tambahan.
Karena klasifikasi dilakukan dengan menggunakan jaringan saraf, kami tidak dapat dengan mudah memperoleh interpretasi prediksi, berbeda dengan model linier sederhana atau pohon keputusan. Tetapi kami ingin mengetahui bagaimana jaringan saraf menentukan dari foto jalan atau rumah negara mana itu. Dan kasus yang paling menarik adalah tanpa atraksi dalam bingkai.
Untuk melakukan ini, kami melatih jaringan saraf dari awal, memberi makan tidak seluruh gambar, tetapi hanya potongan kecil (sehingga model tidak mengingat tempat atau objek besar tertentu).
Dengan demikian, tugas untuk model menjadi terasa lebih sulit (coba tebak negara dengan sepotong langit), akurasi pengakuan telah sangat menurun. Tetapi di sisi lain, jaringan saraf harus lebih memperhatikan detail kecil: pasangan bata yang tidak biasa, pola khusus, jenis atap, tanaman. Ukuran krop yang diterapkan pada model berubah, dan diperoleh berbagai model yang memandang foto pada berbagai tingkat abstraksi: semakin kecil krop, semakin sulit tugas dan semakin penuh perhatian model pada detail.

Algoritma untuk menafsirkan prediksi dapat diterapkan pada model yang dilatih tentang ukuran krop dengan ukuran yang berbeda. Saya ingin menafsirkan prediksi dalam sumber foto. Sebagian besar jaringan konvolusi modern menggunakan
Global Average Pooling (GAP) sebelum lapisan terakhir - ini memungkinkan untuk melatih jaringan pada satu ukuran dan menerapkannya pada yang lain. Ini disebabkan oleh fakta bahwa sebelum lapisan terakhir, fitur spasial, didistribusikan dalam lebar dan tinggi, dirata-rata menjadi satu nomor untuk setiap saluran (peta fitur). Oleh karena itu, model yang dilatih saat panen (misalnya, 160 × 160 piksel) dapat digunakan pada gambar asli berukuran besar (800 × 800).
Bahkan, lapisan GAP diperlukan tidak hanya untuk menggunakan model pada resolusi yang berbeda atau untuk regularisasi. Ini juga membantu jaringan saraf untuk menyimpan informasi tentang posisi objek hingga lapisan terakhir (hanya yang kita butuhkan).
Metode pertama yang kami coba adalah
Pemetaan Aktivasi Kelas (CAM).
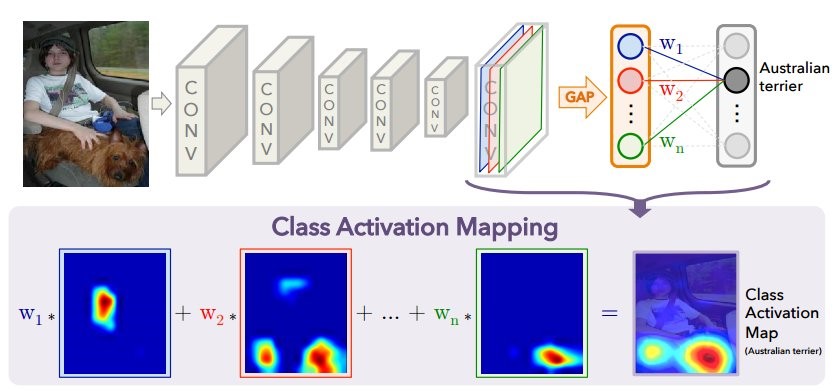
Ketika gambar diumpankan ke input jaringan saraf, maka pada lapisan kedua dari belakang, "gambar" berkurang diperoleh (pada kenyataannya, tensor aktivasi) dengan fitur yang paling penting untuk setiap kelas yang diprediksi. Menggunakan metode CAM, Anda dapat mengubah lapisan terakhir sehingga output adalah probabilitas setiap kelas di setiap wilayah. Sebagai contoh, jika Anda ingin memprediksi 60 kelas (negara), untuk gambar input 800 × 800, gambar akhir akan terdiri dari 60 kartu aktivasi dengan ukuran 25 × 25. Ini digambarkan dengan baik dalam publikasi
asli .
Diagram di atas menunjukkan model yang biasa dengan GAP: fitur spasial dikompresi ke satu nomor untuk setiap saluran (peta fitur), setelah itu ada lapisan yang sepenuhnya terhubung yang memprediksi kelas yang menemukan bobot optimal untuk setiap saluran. Berikut ini menunjukkan cara mengubah arsitektur untuk mendapatkan metode CAM: lapisan GAP dihapus, dan bobot lapisan yang terhubung sepenuhnya terakhir diperoleh selama pelatihan dengan GAP (di atas dalam diagram) digunakan untuk setiap saluran di setiap titik. Untuk setiap gambar, peta aktivasi N diperoleh untuk semua kelas prediksi. Untuk setiap negara, semakin terang area pada “peta”, semakin besar kontribusi bagian gambar ini pada keputusan untuk memilih negara tertentu. Yang menarik: jika setelah operasi ini kami rata-rata setiap peta aktivasi (pada dasarnya, menerapkan GAP), maka kami hanya mendapatkan prediksi awal untuk setiap kelas.

Pada gambar Anda melihat peta aktivasi untuk kelas yang paling mungkin (menurut model). Itu diperoleh dengan meregangkan peta aktivasi 25 × 25 dengan ukuran gambar asli 800 × 800.
Setelah menerima peta seperti itu untuk setiap gambar, kami dapat mengumpulkan hasil panen paling penting untuk negara-negara dari gambar yang berbeda. Ini memungkinkan Anda untuk melihat koleksi tanaman, menggambarkan negara dengan cara terbaik.
Metode kedua, dengan mana kami memutuskan untuk membandingkan yang pertama, adalah pencarian lengkap sederhana. Bagaimana jika kita mengambil model yang dilatih pada tanaman kecil (misalnya, 160 × 160 piksel) dan memprediksi masing-masing bagian pada gambar 800 × 800 besar dengan itu? Melewati jendela geser yang menutupi setiap area pada gambar, kami mendapatkan versi lain dari peta aktivasi, yang menunjukkan seberapa besar kemungkinan masing-masing bagian dari gambar termasuk dalam kelas negara yang diprediksi.

Gambar dipotong menjadi tanaman kecil dengan tumpang tindih 160 × 160. Untuk setiap tanam, jaringan saraf membuat prediksi, jumlah di atas tanam adalah kemungkinan milik kelas yang akhirnya diprediksi oleh model.
Seperti pada metode pertama, kita dapat kembali memilih potongan yang paling mungkin untuk masing-masing negara. Tetapi gambar yang diperoleh oleh kedua metode untuk negara tersebut dapat seragam (misalnya, bangunan dari sudut yang berbeda atau satu versi tekstur). Oleh karena itu, hasil panen terbaik untuk negara juga dikelompokkan - maka sebagian besar gambar yang sama akan dikumpulkan dalam satu cluster. Setelah itu, akan cukup untuk mengambil satu gambar dari masing-masing cluster dengan probabilitas maksimum - untuk setiap negara akan ada banyak gambar karena ada cluster yang ditentukan. Kami melakukan pengelompokan berdasarkan karakteristik yang diperoleh dari lapisan classifier terakhir. Pengelompokan aglomeratif dalam kasus kami terbukti menjadi yang terbaik.

Setelah menerima jalur pipa yang cukup mirip untuk kedua metode ini, Anda dapat beralih pada parameter algoritma untuk menemukan kombinasi optimal. Misalnya, kami memilih ukuran pemangkasan dan menetapkan dua opsi: 160 dan 256 piksel. Tanaman yang kurang dari 160 memberi tanda terlalu kecil, yang menurutnya seseorang sering tidak mengerti apa yang digambarkan. Dan crop lebih dari 256 terkadang mengandung beberapa objek sekaligus. Berbagai parameter perlu dipilih pada tahap pengelompokan: pilihan algoritma utama, serta fitur yang digunakan pengelompokan. Untuk banyak kombinasi parameter, segera jelas bahwa mereka memberikan tanaman yang "menarik" tidak cukup. Tetapi untuk memilih algoritme terakhir, kami melakukan eksperimen berdampingan di Tolok untuk memahami opsi mana, menurut orang-orang, yang mendeskripsikan negara tertentu lebih “tepat”.
Ternyata tidak intuitif bahwa metode yang lebih sederhana untuk menemukan krop dalam gambar (pencarian normal) menemukan objek yang lebih "menarik". Ini mungkin disebabkan oleh fakta bahwa dalam metode kedua (enumerasi) jaringan saraf tidak melihat bagian tetangga dari gambar, dan dalam metode CAM, lingkungan titik mempengaruhi hasil. Hasilnya, kami menerima visualisasi fitur karakteristik masing-masing negara dalam mode otomatis.
Jadi sekarang kita tahu bagian mana dari bingkai yang sangat penting untuk jaringan saraf, dan kita bisa melihat apa yang menimpa mereka. Misalnya, Belanda mengakui jaringan saraf dengan kombinasi dinding bata gelap dan kontur jendela putih, UEA - oleh gedung pencakar langit khusus dengan latar belakang pohon-pohon palem, dan Iran - dengan lengkungan dan ornamen khas pada fasad.